Dissecting Deep Learning Networks—Visualizing Mutual Information


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Deep Learning Networks
2.2. Information Theory
2.3. Deep Learning Analysis via Visualization
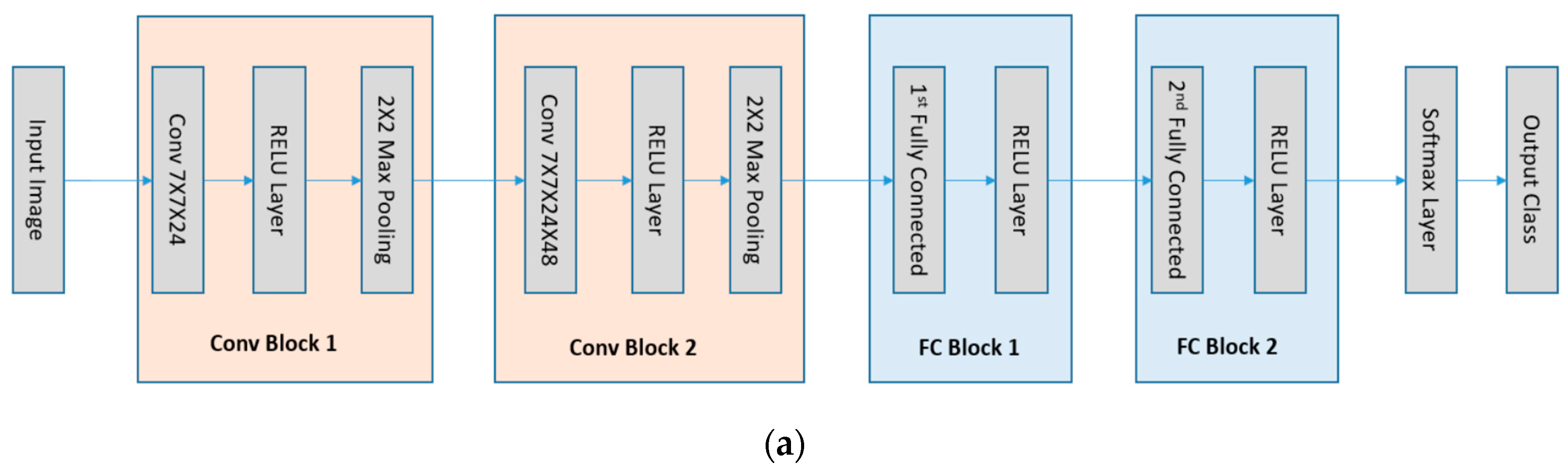
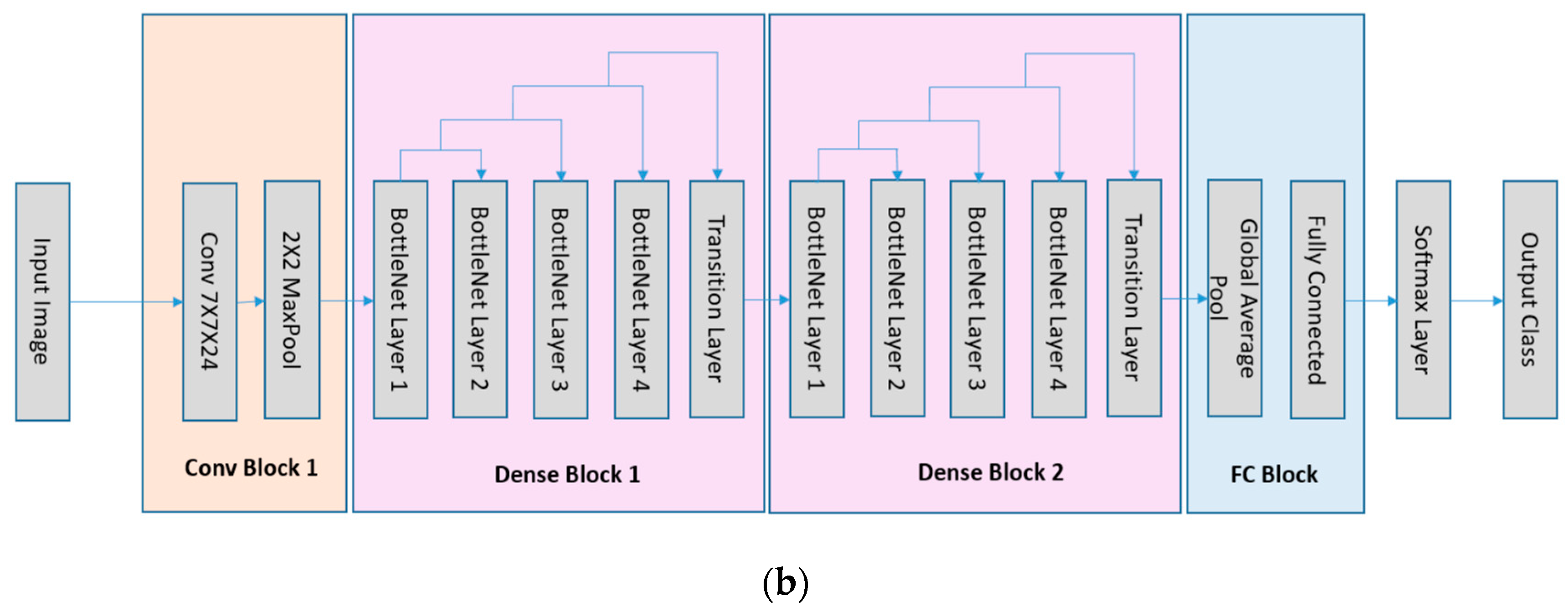
3. Deep Learning Networks
4. Mutual Information Estimation and Information Plane for DL Network Analysis
5. MI Visualization of Deep Learning Models
5.1. Information Plane Visualization
5.2. CNN Kernel Analysis via MI Visualization
5.3. Visualizing the Evolution of MI with Binary Label and MI Orders in CNNs
6. Further Analysis and Discussions
- In DL network design, it is assumed that a better network architecture is to preserve more useful information for classification and reduce the redundancy in the network. Illustrated in our work, MI, a theoretical measurement for quantifying the shared information between variables, can be used as an independent metric to evaluate the components in DL networks. Therefore, it is suggested that MI can be used in further research in two ways: (i) it can be used as an independent metric to evaluate new network architectures in addition to the accuracy rate; and (ii) it can be integrated into the optimization process for achieving better network performance.
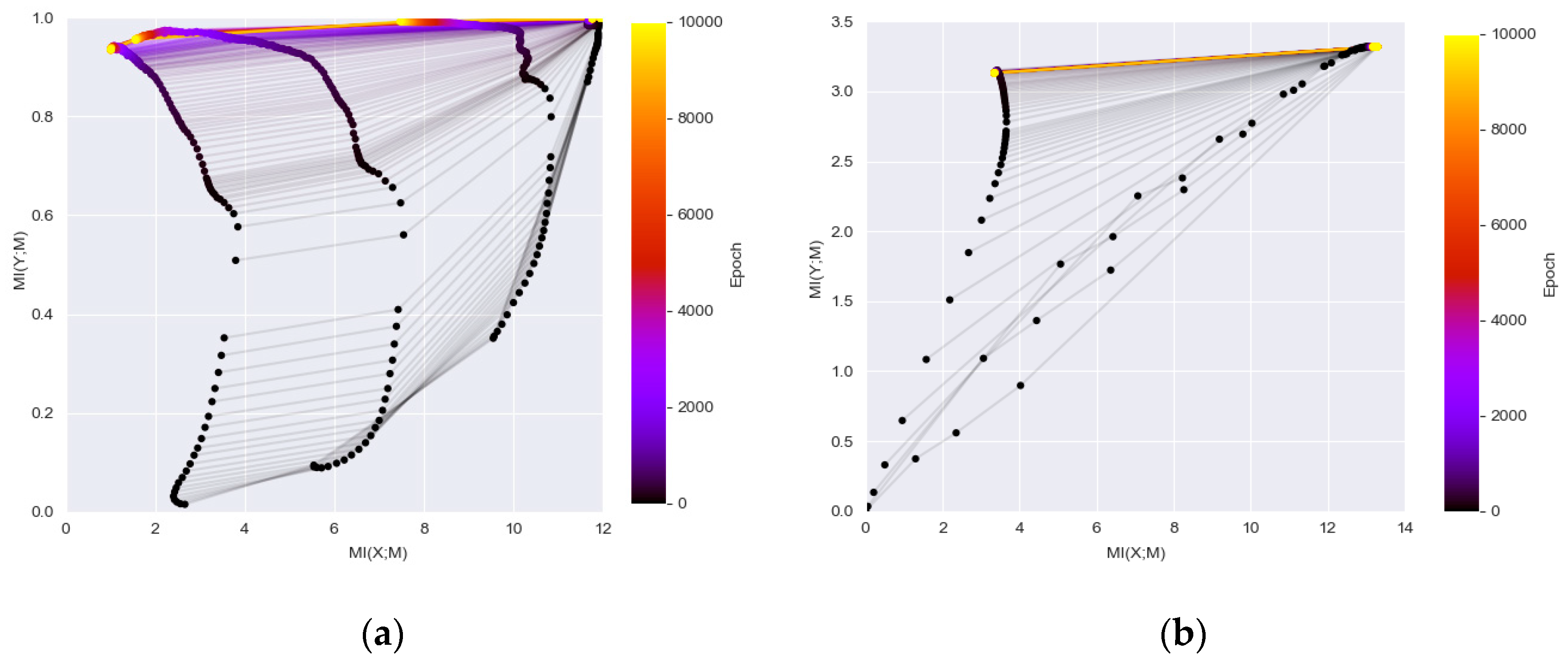
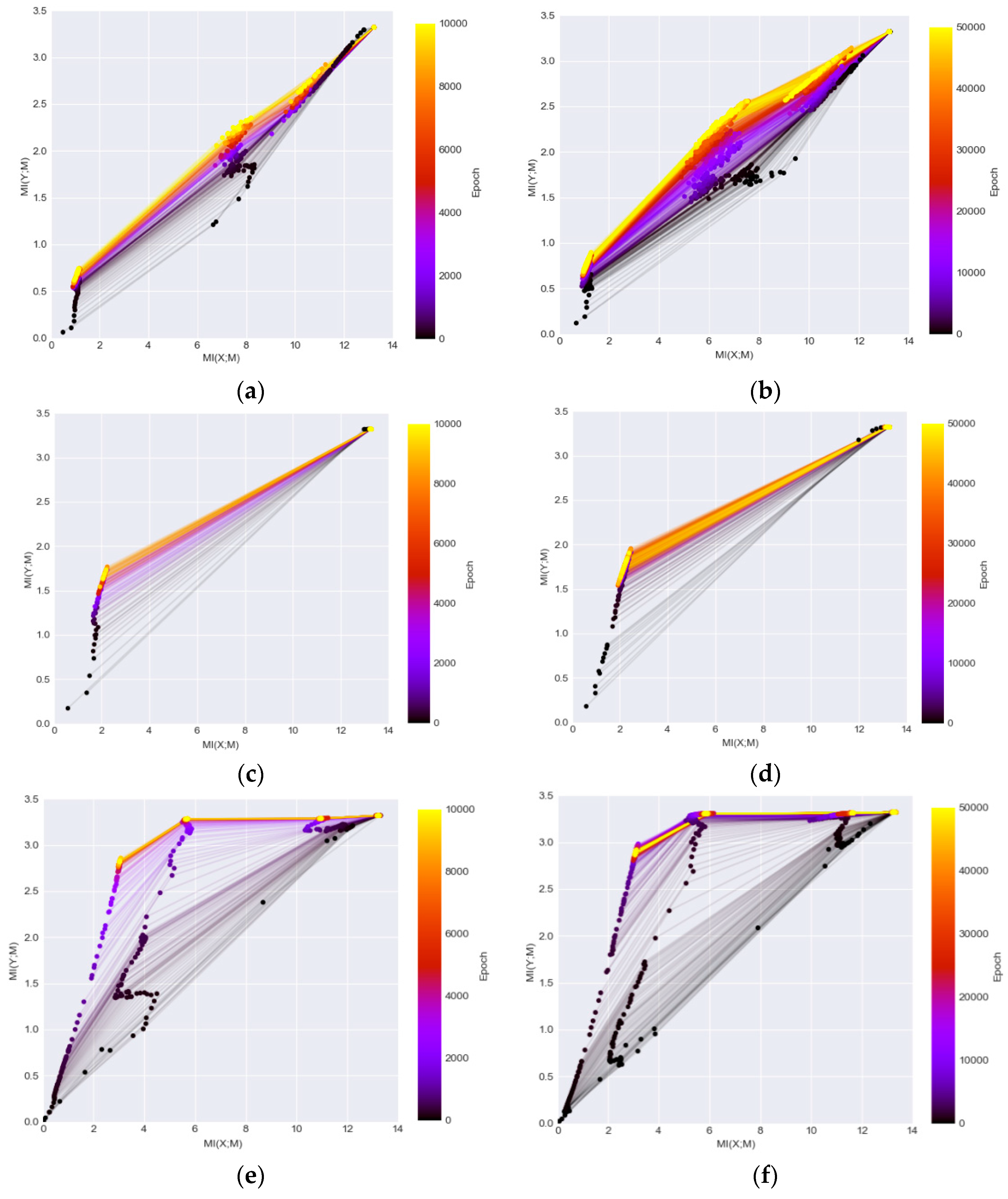
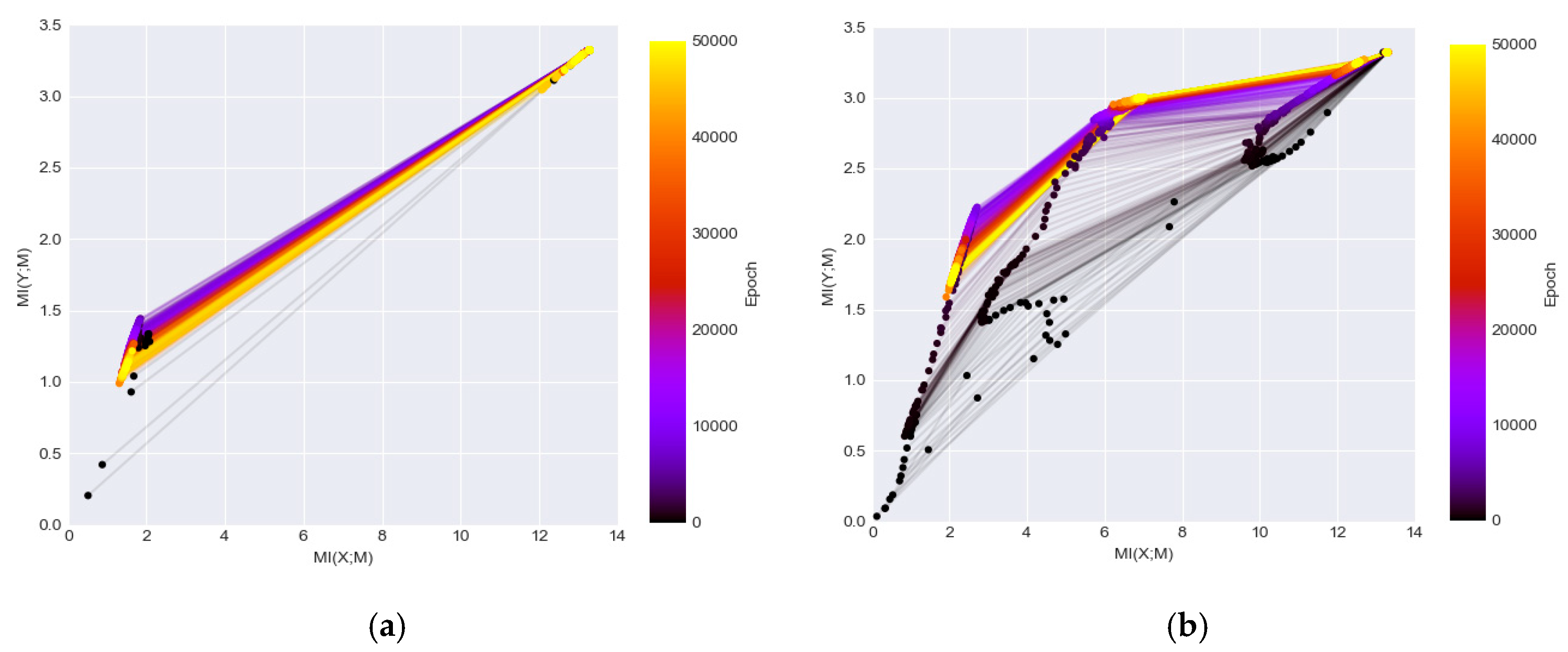
- It is found that MI can be used to evaluate whether the network architectures are suitable for particular tasks. In specific, the MI becomes relatively stable and close to its IB bound on the information plane plots, for a dataset that has been well solved by DL methods (i.e., MNIST dataset). However, the MI values drop significantly during training when processing a more difficult dataset (i.e., Fashion-MNIST) and the convergence is farther from the IB bound.
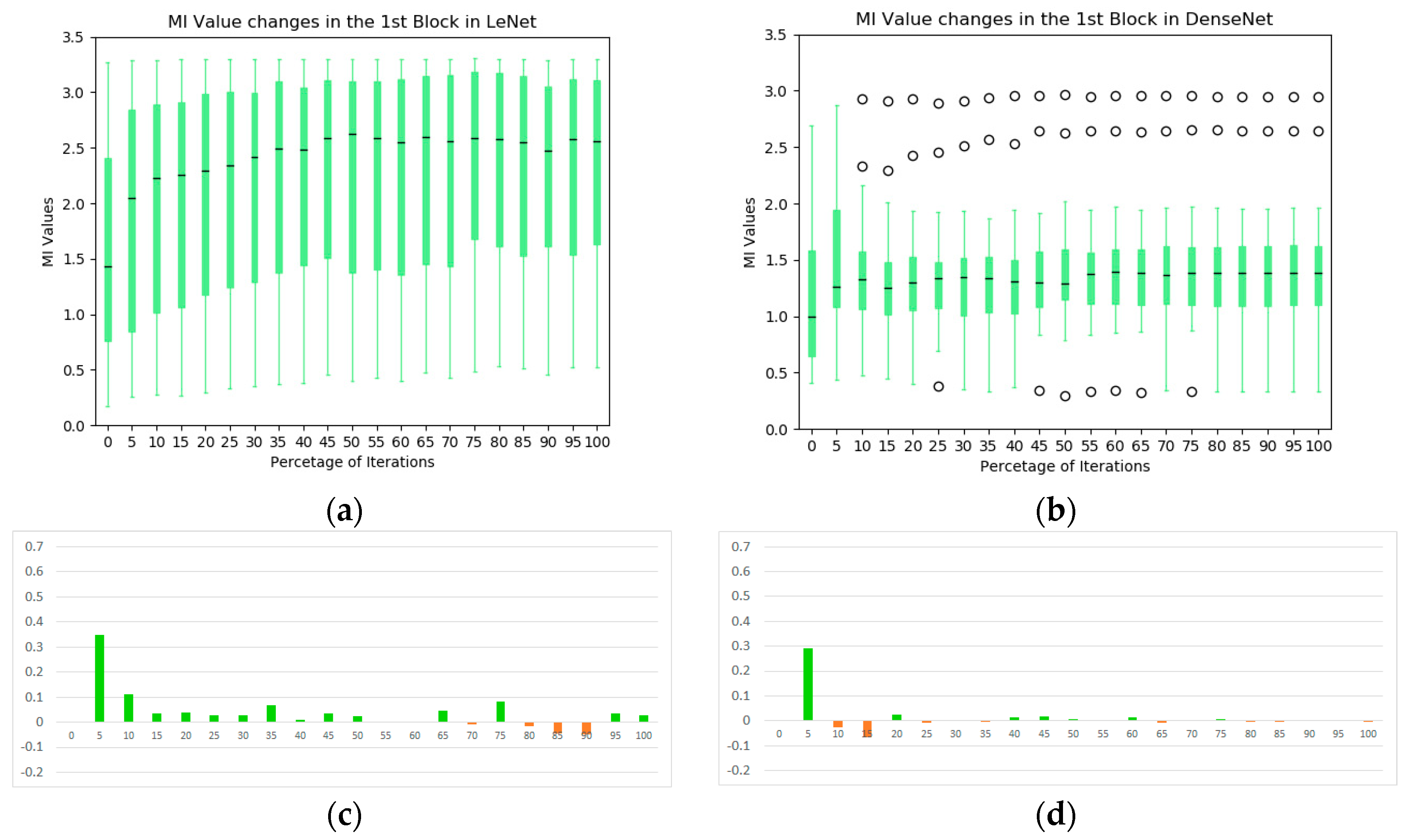
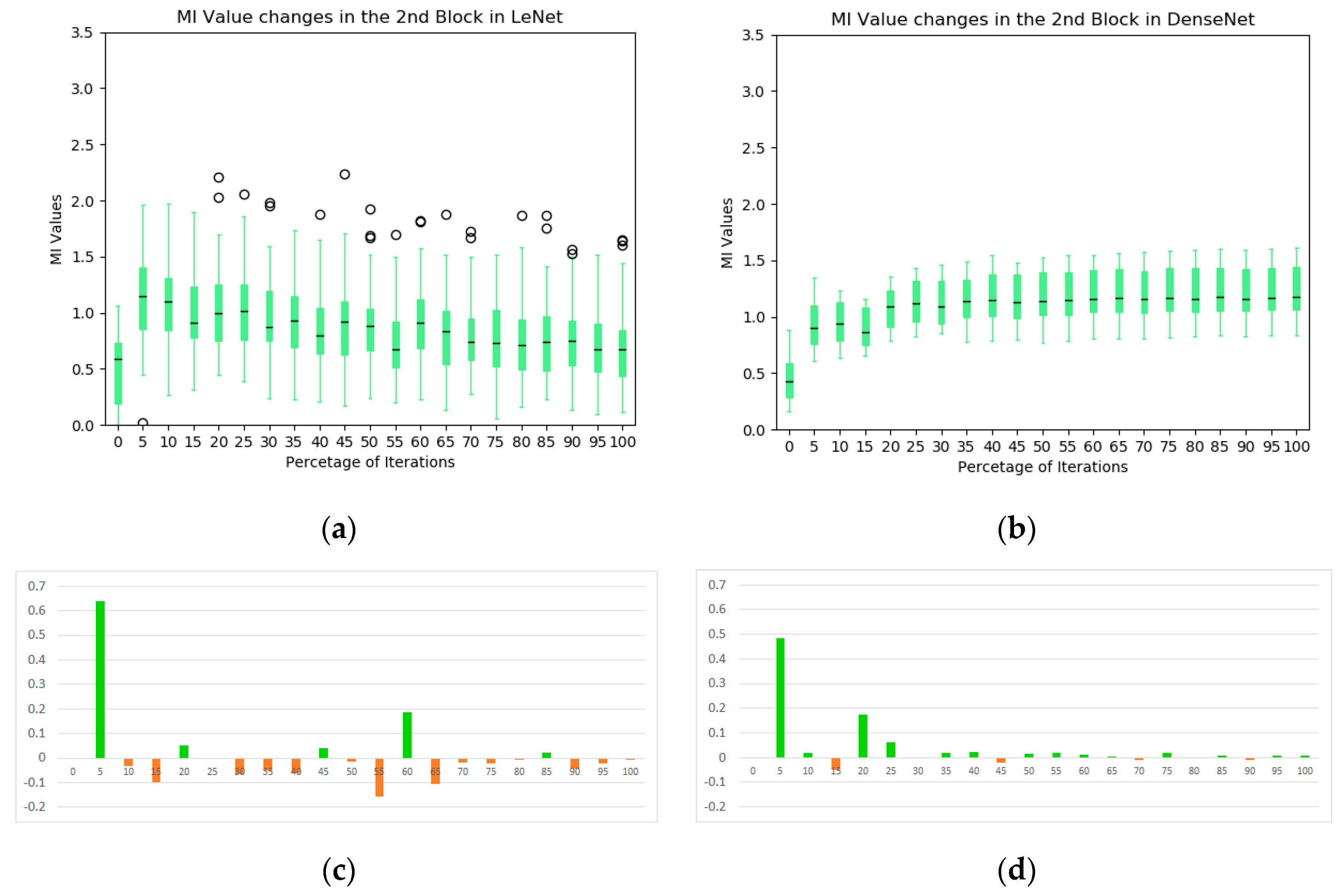
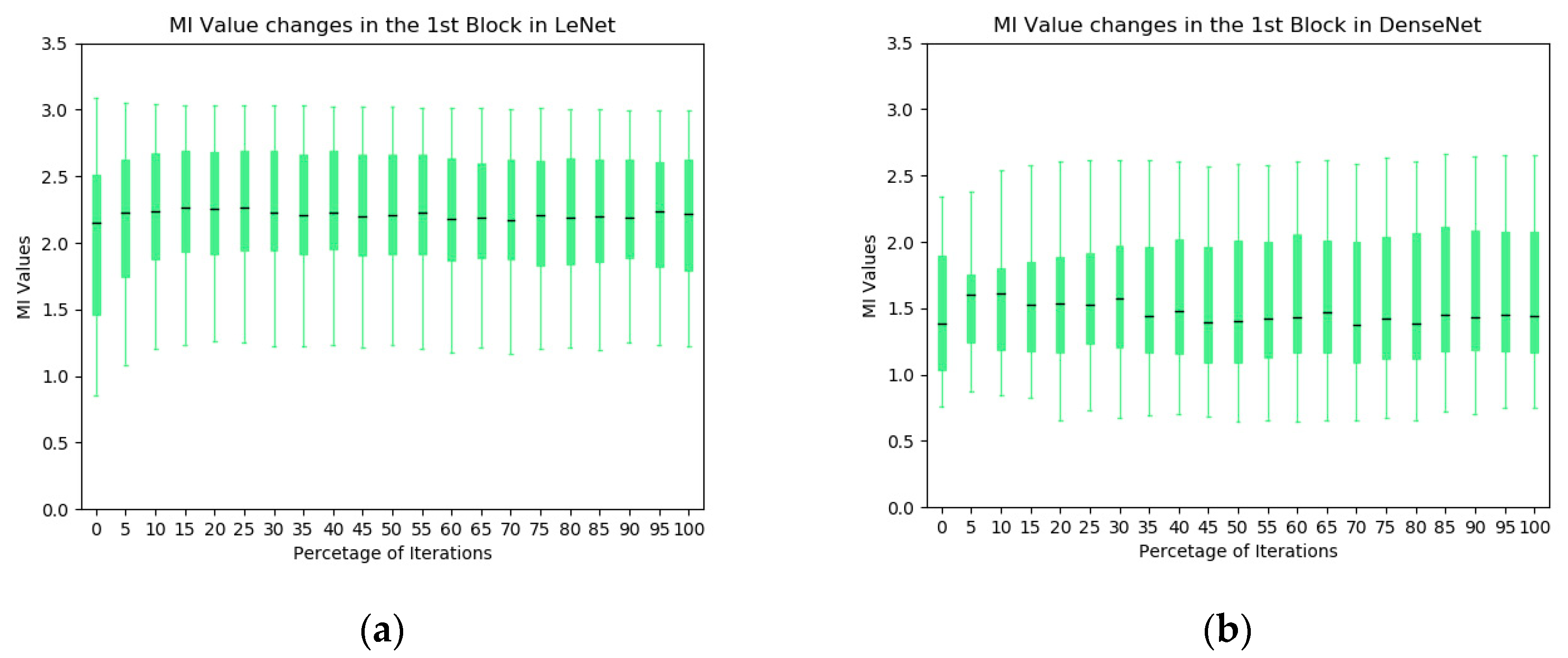
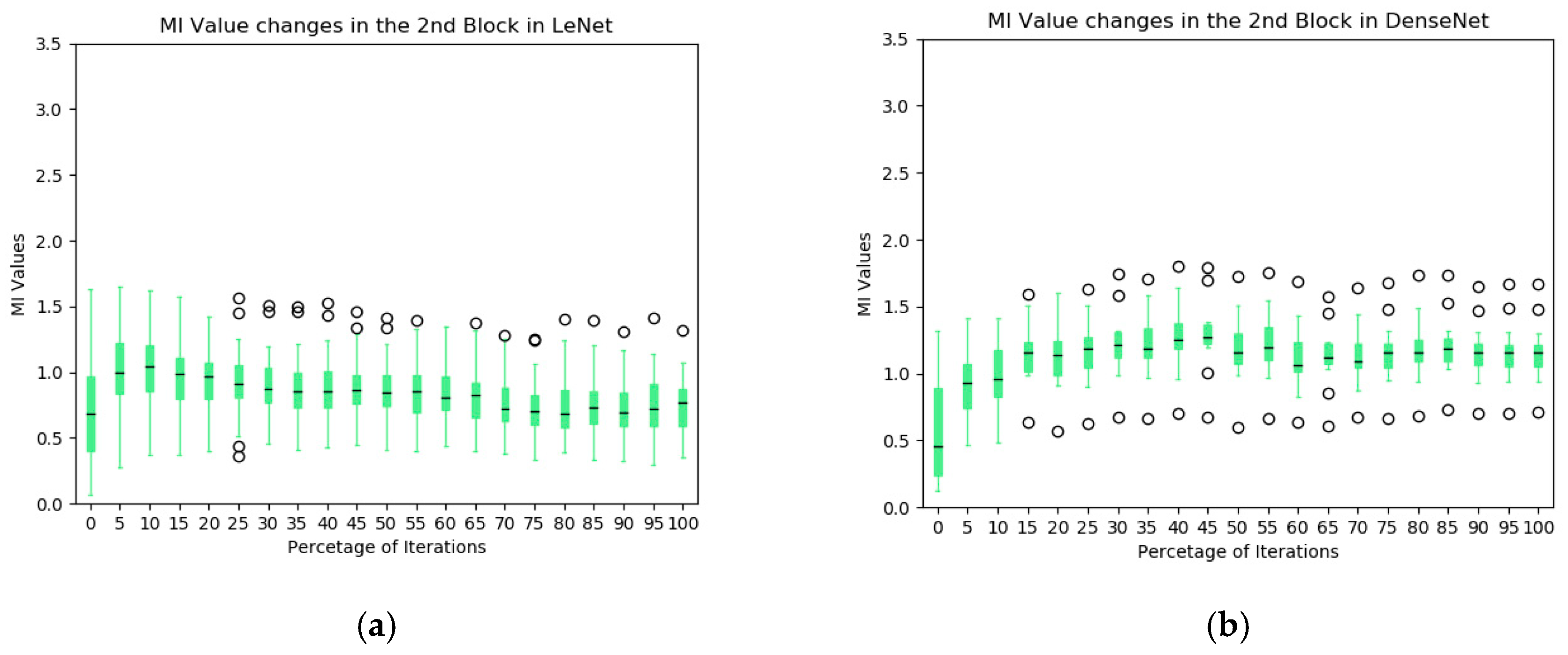
- Based on the observation from Section 5.2 and Section 5.3 and figures in the Appendix A, it is found that there are different types of redundancy identified in the networks. For example, in the LeNet, highly correlated kernels in the first convolutional block generate the redundancy while less-effective kernels in the second convolutional block are the redundant components. It suggests that MI has the potential to guide the network developers to optimize the number of network kernels by identifying the redundancy in the layers. The purpose of using a large number of convolutional kernels at initialization step is to generate a more reliable feature extraction scheme although some kernel parameters may be stuck on local minima, making less contribution to the task. With the help of the MI, more efficient networks could be designed by removing those kernels for better optimization.
- From the visualization results in Section 5.2 and Section 5.3, it is easy to find that the convolutional layers are able to diversify the feature representations. More specifically, the heat-map visualization is a useful tool to identify the redundancy in DL networks by evaluating the MI distribution. In our study, it shows that the concatenation of the convolutional layers (the dense blocks in the DenseNet) can provide more distinctive features for classification. It facilitates a better combination of the blocks to achieve an improved architecture.
- Based on the observation from Figure 4, Figure 5, Figure 6 and Figure 7, we believe that larger stride setting in the first convolutional layer has little impact to the final performance when training on the MNIST data set. As shown in the Figure 5, the overall MI values from the kernels of Densenet are lower than the MIs in the LeNet. This has been visually evidenced by the illustrations in Figure 6 and Figure 7. In these two figures, the response maps of convolving 10 image instances with the 8 kernels (4 highest MIs and 4 lowest MIs) in the two networks. However, the MI evolution in the following layers (illustrated in Figure 4) shows that the final convergence is not influenced by the different settings in the two networks. Therefore, a larger stride in the network is a better choice to process the dataset.
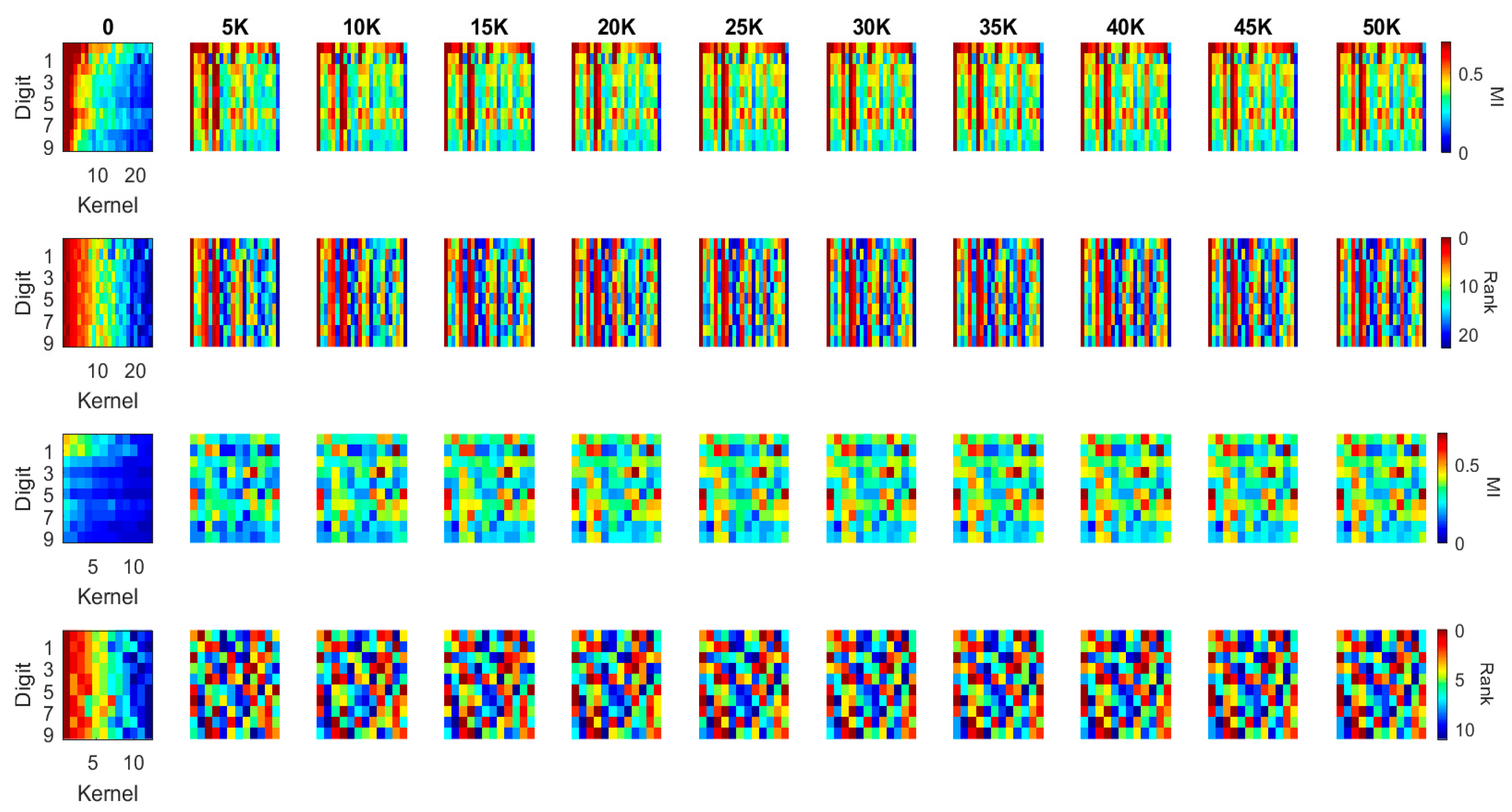
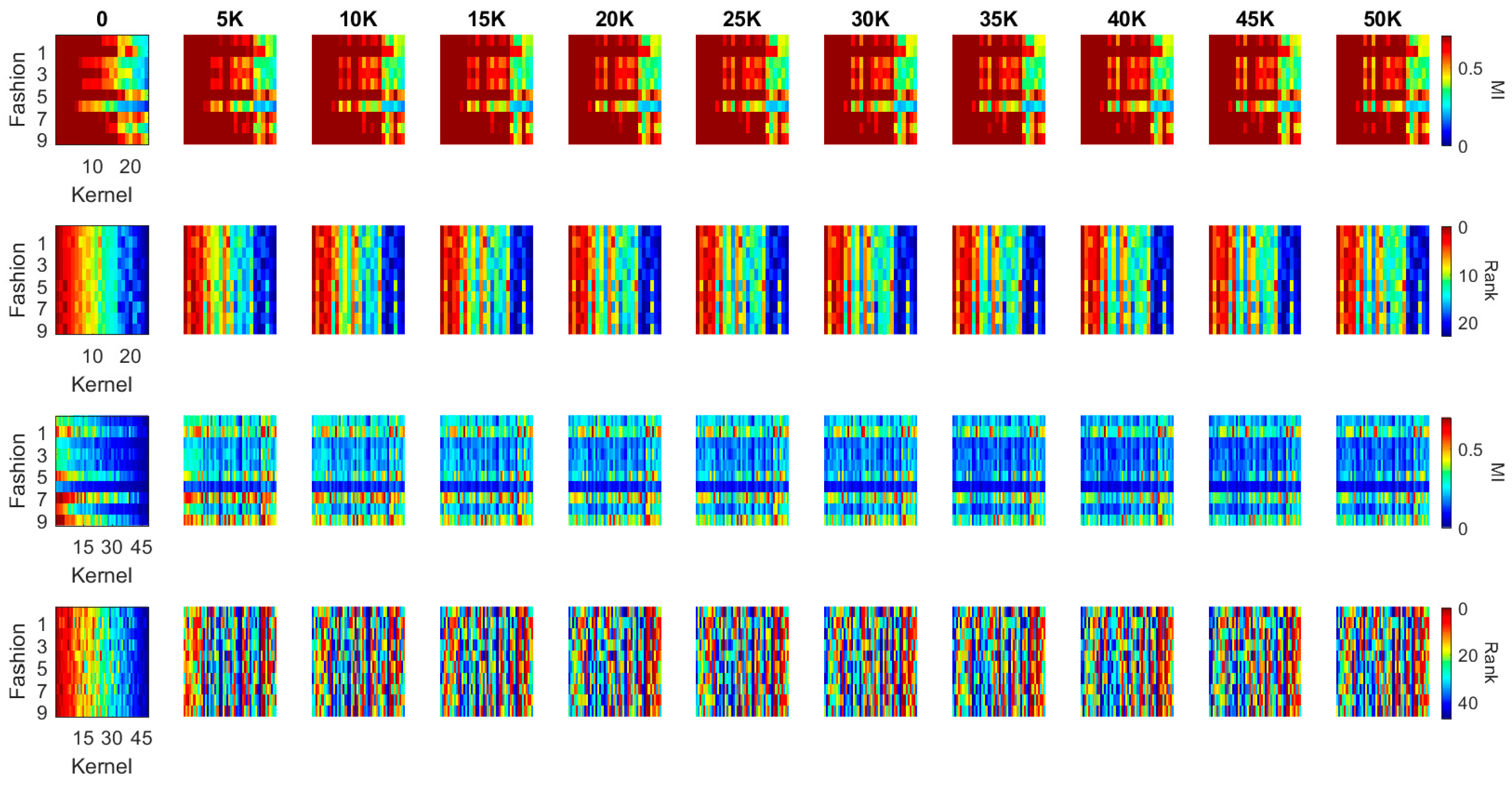
- The following analysis is summarized from Figure 9 and Figure 10, Figure A7 and Figure A8: (1) when comparing the second block of the two networks, it is found that LeNet has many kernels, which generate low MI values with all the 10 classes (3rd row of Figure 9 and Figure A7). It indicates that the network is not efficient as there are many redundant kernels in the network. While MI between the kernels in the Densenet and the classes are distributed well across all the classes (3rd row of Figure 10 and Figure A8), which means each kernel is specialized to particular characteristics of classes; and (2) From Figure A7 and Figure A8, it is found that the MI in the fashion dataset corresponding to the fact that T-shirt, Pullover, Dress, Coat, and Shirt have relatively lower values comparing to the trouser, sandals, sneaker, bag, and boots classes (here shirt has the lowest MI). The observation is consistent on the second block of both the networks. This is understandable from the perception perspective as the 5 classes share similar visual stimuli comparing to the other classes. It suggests that a hierarchical network is preferable to achieve better performance comparing to a generic deep network.
- Based on the observation in Section 5.3, the evolution of kernels in the heat-map suggests that the gradient descent optimization becomes less effective for the early blocks once the network become deeper. As a result, it is useful to have either links from early blocks to the output layer or a better initialization to improve the optimization process. In contrast, based on the observation from the MI order evolution visualization, it is found that the dense blocks learn more compact representation as the redundancy in the features is less comparing to the convolutional blocks. It reflects that the concatenation of response map from a sequential of convolutional layers is a better learning strategy which can be further used in more network architectures.
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. MI Visualization on Fashion-MNIST Dataset








References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Twenty-sixth Conference on Neural Information Processing Systems (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Yu, D.; Seide, F.; Li, G. Conversational Speech Transcription Using Context-Dependent Deep Neural Networks. In Proceedings of the 29th International Conference on Machine Learning (ICML 2012), Edinburgh, UK, 26 June–1 July 2012. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zong, C. Deep neural networks in machine translation: An overview. IEEE Intell. Syst. 2015, 30, 16–25. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Fang, H.; Thiyagalingam, J.; Bessis, N.; Edirisinghe, E. Fast and reliable human action recognition in video sequences by sequential analysis. In Proceedings of the International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv, 2017; arXiv:1703.00810. [Google Scholar]
- Saxe, A.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A. On the Information bottleneck theory of deep learning. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Vasudevan, S. Dynamic learning rate using Mutual Information. arXiv, 2018; arXiv:1805.07249. [Google Scholar]
- Hodas, N.O.; Stinis, P. Doing the impossible: Why neural networks can be trained at all. arXiv, 2018; arXiv:1805.04928. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv, 2018; arXiv:1808.06670. [Google Scholar]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning internal representations by error propagation. In Parallel Distributed Processing; MIT Press: Cambridge, MA, USA, 1986; Volume 1, Chapter 8; pp. 318–362. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Weinberger, K.Q.; van der Maaten, L. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 3. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Twenty-eighth Conference on Neural Information Processing Systems (NIPS 2014), Montreal, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Let there be color! Joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification. ACM Trans. Graph. 2016, 35, 110. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Twenty-eighth Conference on Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 2015; arXiv:1511.06434. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training very deep networks. In Proceedings of the Twenty-ninth Conference on Neural Information Processing Systems (NIPS 2015), Montreal, Canada, 7–12 December 2015; pp. 2377–2385. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Pluim, J.P.; Maintz, J.A.; Viergever, M.A. Mutual-information-based registration of medical images: A survey. IEEE Trans. Med. Imaging 2003, 22, 986–1004. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the Twenty-ninth Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 2172–2180. [Google Scholar]
- Chen, M.; Jaenicke, H. An information-theoretic framework for visualization. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1206–1215. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Lee, T.Y.; Shen, H.W. An information-theoretic framework for flow visualization. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1216–1224. [Google Scholar] [PubMed]
- Wang, C.; Shen, H.W. Information theory in scientific visualization. Entropy 2011, 13, 254–273. [Google Scholar] [CrossRef]
- Alsakran, J.; Huang, X.; Zhao, Y.; Yang, J.; Fast, K. Using entropy-related measures in categorical data visualization. In Proceedings of the IEEE Pacific Visualization Symposium (PacificVis), Yokohama, Japan, 4–7 March 2014; pp. 81–88. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Bau, D.; Zhou, B.; Khosla, A.; Oliva, A.; Torralba, A. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3319–3327. [Google Scholar]
- Liu, M.; Shi, J.; Li, Z.; Li, C.; Zhu, J.; Liu, S. Towards better analysis of deep convolutional neural networks. IEEE Trans. Vis. Comput. Graph. 2017, 23, 91–100. [Google Scholar] [CrossRef] [PubMed]
- Widrow, B.; Lehr, M.A. 30 years of adaptive neural networks: Perceptron, madaline, and backpropagation. Proc. IEEE 1990, 78, 1415–1442. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Gao, W.; Oh, S.; Viswanath, P. Demystifying fixed k-nearest neighbor information estimators. IEEE Trans. Inf. Theory 2018, 8, 5629–5661. [Google Scholar] [CrossRef]
- Kolchinsky, A.; Tracey, B. Estimating mixture entropy with pairwise distance. Entropy 2017, 19, 361. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the 37-th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September 1999. [Google Scholar]
- Quinlan, J.R. Bagging, boosting, and C4.5. In Proceedings of the Thirteenth National Conference on Artificial Intelligence and Eighth Innovative Applications of Artificial Intelligence Conference, Portland, OR, USA, 4–8 August 1996; Volume 1, pp. 725–730. [Google Scholar]
- Tam, G.K.; Fang, H.; Aubrey, A.J.; Grant, P.W.; Rosin, P.L.; Marshall, D.; Chen, M. Visualization of time-series data in parameter space for understanding facial dynamics. Comput. Graph. Forum 2011, 30, 901–910. [Google Scholar] [CrossRef]
- Saraiya, P.; North, C.; Duca, K. An evaluation of microarray visualization tools for biological insight. In Proceedings of the IEEE Symposium on Information Visualization, Austin, TX, USA, 10–12 October 2004; pp. 1–8. [Google Scholar]
- Fang, H.; Tam, G.K.L.; Borgo, R.; Aubrey, A.J.; Grant, P.W.; Rosin, P.L.; Wallraven, C.; Cunningham, D.; Marshall, D.; Chen, M. Visualizing natural image statistics. IEEE Trans. Vis. Comput. Graph. 2013, 19, 1228–1241. [Google Scholar] [CrossRef] [PubMed]
- Metsalu, T.; Vilo, J. ClustVis: A web tool for visualizing clustering of multivariate data using Principal Component Analysis and heatmap. Nucleic Acids Res. 2015, 43, 566–570. [Google Scholar] [CrossRef] [PubMed]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv, 2017; arXiv:1708.07747. [Google Scholar]











© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, H.; Wang, V.; Yamaguchi, M. Dissecting Deep Learning Networks—Visualizing Mutual Information. Entropy 2018, 20, 823. https://doi.org/10.3390/e20110823
Fang H, Wang V, Yamaguchi M. Dissecting Deep Learning Networks—Visualizing Mutual Information. Entropy. 2018; 20(11):823. https://doi.org/10.3390/e20110823
Chicago/Turabian StyleFang, Hui, Victoria Wang, and Motonori Yamaguchi. 2018. "Dissecting Deep Learning Networks—Visualizing Mutual Information" Entropy 20, no. 11: 823. https://doi.org/10.3390/e20110823
APA StyleFang, H., Wang, V., & Yamaguchi, M. (2018). Dissecting Deep Learning Networks—Visualizing Mutual Information. Entropy, 20(11), 823. https://doi.org/10.3390/e20110823