An Information-Theoretic Framework for Evaluating Edge Bundling Visualization


Abstract
:1. Introduction
2. Related Work
2.1. Graph Visualization and Evaluation Metrics
2.2. Edge Bundling Visualization
2.3. Studies of Information Theory in Visualization and Computer Graphics
3. Method
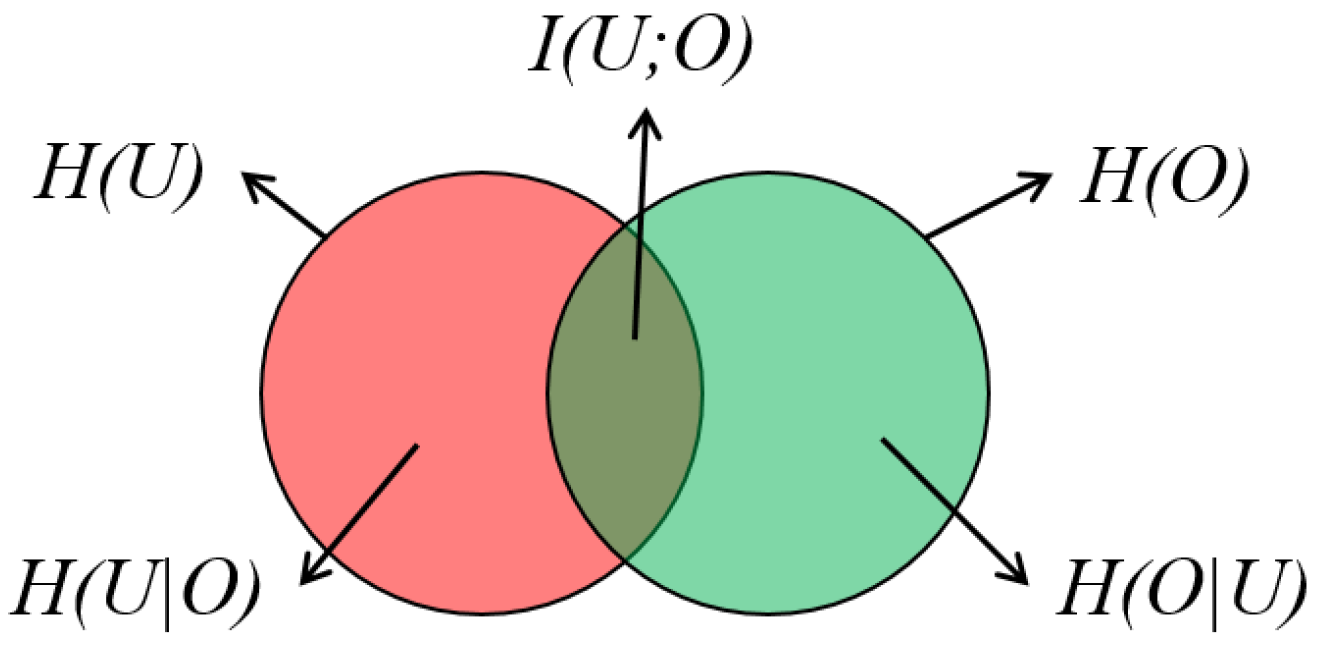
3.1. Background
3.2. Uncertainty in Edge Bundling Visualizations
3.3. An Information-Theoretic Metric for Edge Bundling Visualizations
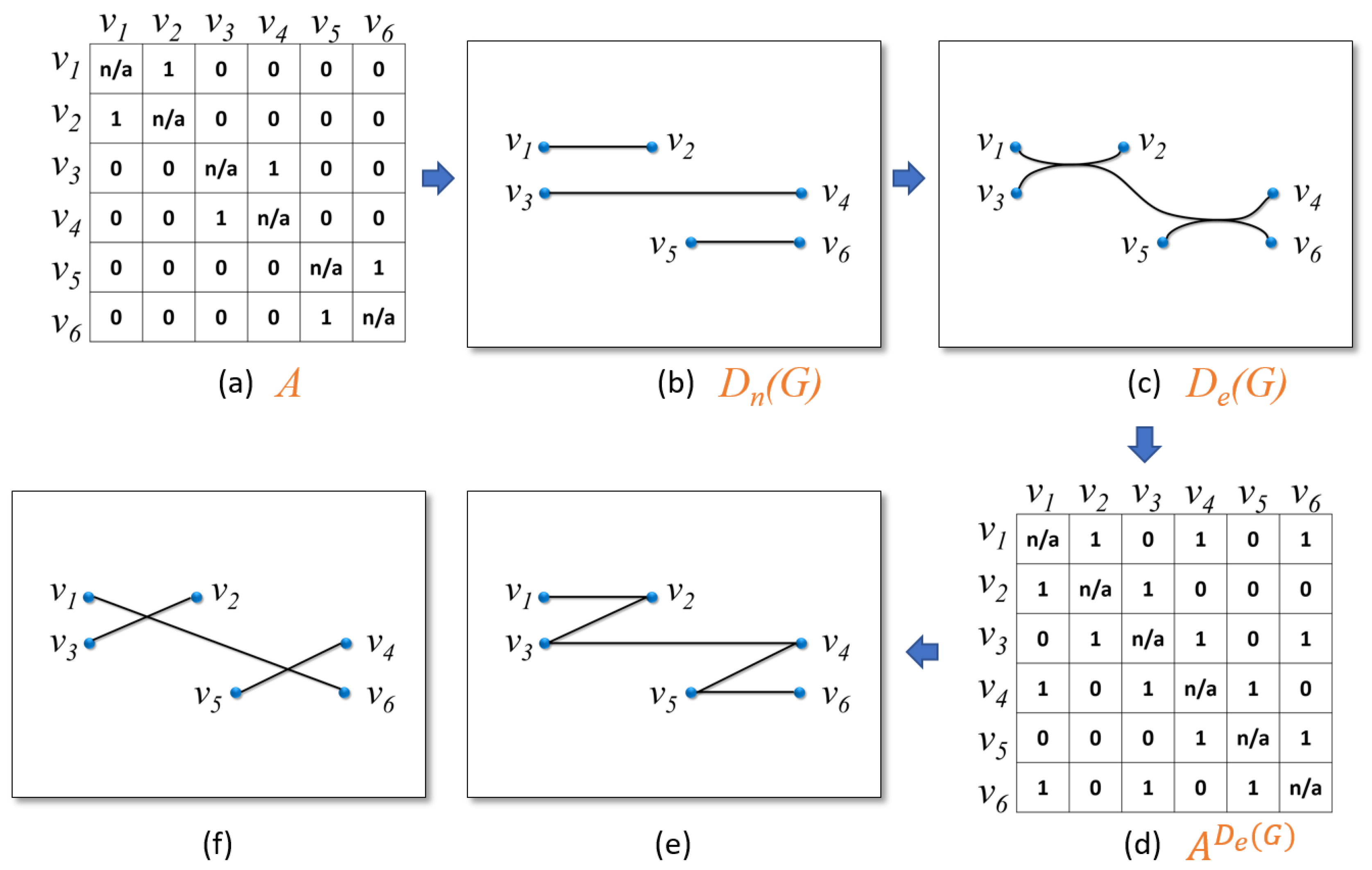
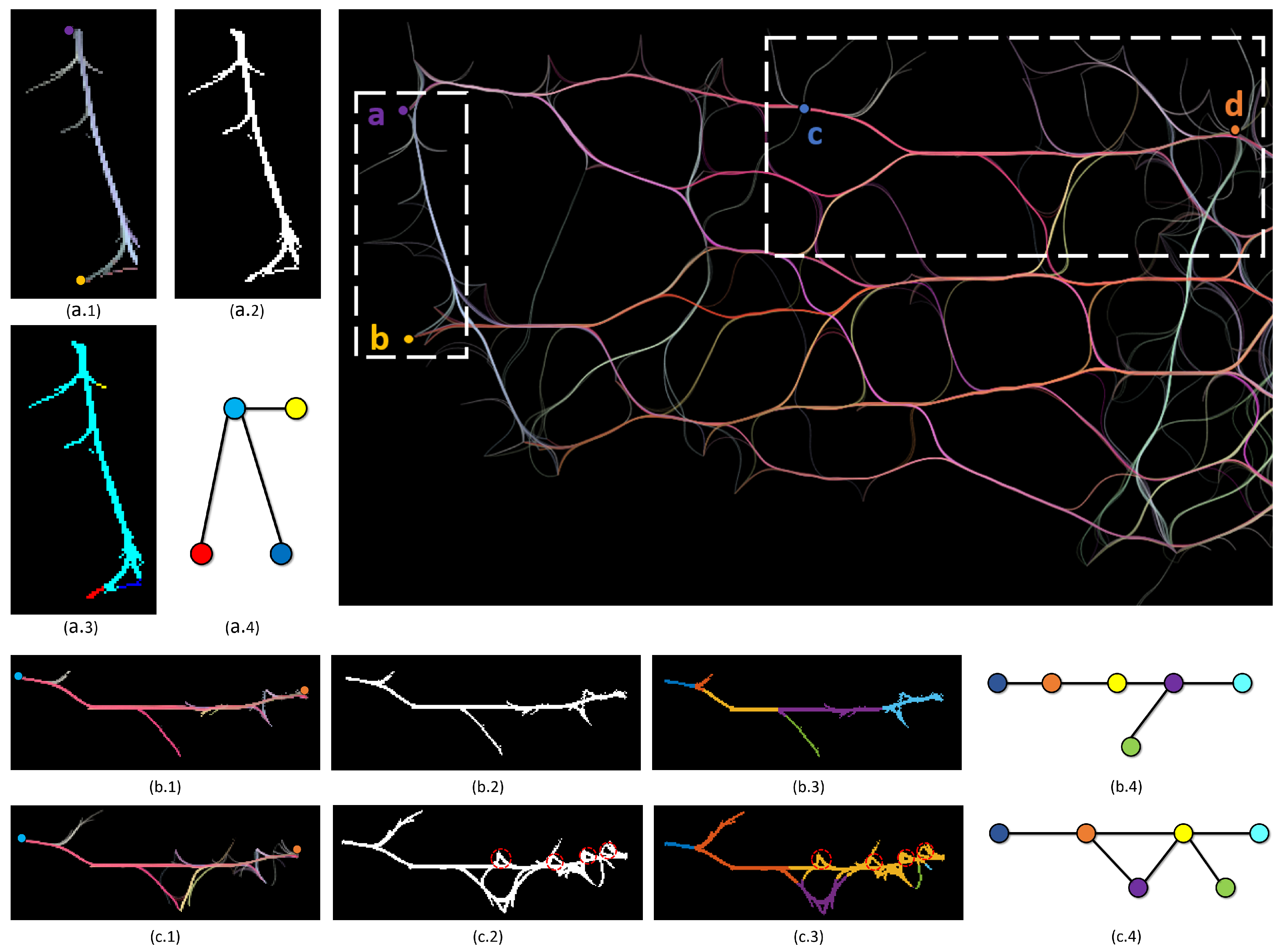
3.4. Algorithms and Implementation
| Algorithm 1FindAllPaths. | |
| 1: | // Initialization |
| 2: | Ps // The start pixel |
| 3: | Pt // The target pixel |
| 4: | W1 // The size of sliding window for Algorithm 2 |
| 5: | W2 // The size of sliding window for Algorithm 3 |
| 6: | C // The color threshold |
| 7: | I // The M × N image |
| 8: | R // The growing region |
| 9: | K // The clusters |
| 10: | P // The number of paths |
| 11: | N // The number of node in graph |
| 12: | VISITED[N] // The flag array that indicates if vertices are visited |
| 13: | Find the source pixel Ps and target pixel Pt. |
| 14: | // Given I, W1 and C, use region growing to find the region R connects Ps and Pt |
| 15: | R ← RegionGrowing(I, Ps, Pt, W1, C) |
| 16: | // Given the region R, use mean shift to calculate the clusters K |
| 17: | K ← MeanShift(R, W2) |
| 18: | Find the number of vertices N based on the separate components of K. |
| 19: | // Based on the clusters K, find the source region Rs and the target region Rt |
| 20 | P ← Depth-firstSearch(P, K, Rs, Rt, VISITED[Rs]) |
| Algorithm 2RegionGrowing(; ; ; ; ; ). | |
| 1: | Assign the color of Ps to Cm. |
| 2: | R // The growing region |
| 3: | Cm // The mean color of the growing region |
| 4: | Pc ← Ps // Assign the source pixel to be the current pixel |
| 5: | S ← ∅ // Initialize the candidates set |
| 6: | Push Pc into R. |
| 7: | whilePc! = Pt or S! = ∅ do |
| 8: | for each neighboring pixel Pn of Pc using the window size W1 do |
| 9: | if the angle θ1 between and <= L and the angle θ2 between and <= L and the color of Pc − Cm <= C then |
| 10: | Push Pn into S. |
| 11: | end if |
| 12: | end for |
| 13: | // Compute the next Pc |
| 14: | Compute the pixel in S whose color is closest to Cm, and assign the pixel to Pc. |
| 15: | Compute the mean color of S, and assign the mean color to Cm. |
| 16: | Pop Pc from S. |
| 17: | Push Pc into R. |
| 18: | end while |
| 19: | returnR. |
| Algorithm 3MeanShift(; ). | |
| 1: | K // the cluster result |
| 2: | Pc // The position of the current pixel |
| 3: | S // The temporal set |
| 4: | ITR // The iteration number |
| 5: | STOP // The flag that indicates all pixels do not move in the last iteration |
| 6: | STOP ← False |
| 7: | whileITR < 300 and STOP = False do |
| 8: | for each pixel Pc of R do |
| 9: | S ← ∅ |
| 10: | for each neighboring pixel Pn of Pc using the window size W2 do |
| 11: | if the color of Pc does not equal to the background color then |
| 12: | Push Pn into S. |
| 13: | end if |
| 14: | end for |
| 15: | Compute the new position for Pc based on S. |
| 16: | end for |
| 17: | // Check if some of the pixels have new positions |
| 18: | if none of the pixels in R moves then STOP ← True |
| 19: | end if |
| 20: | end while |
| 21: | Give every separate component a distinct number, and assign the result to K. |
| 22 | returnK. |
| Algorithm 4Depth-firstSearch(; ; ; ), . | |
| 1: | P // The number of path between Rs and Rt |
| 2: | VISITED[Rc] ← True |
| 3: | ifRc = Rt then |
| 4: | P ← P + 1 |
| 5: | else |
| 6: | for each adjacent region Rn of Rc do |
| 7: | if VISITED[Rn] = False then Depth-firstSearch(P, K, Rn, Rt, VISITED[Rn]) |
| 8: | end if |
| 9: | end for |
| 10: | end if |
| 11: | VISITED[Rc] ← False |
4. Application Examples
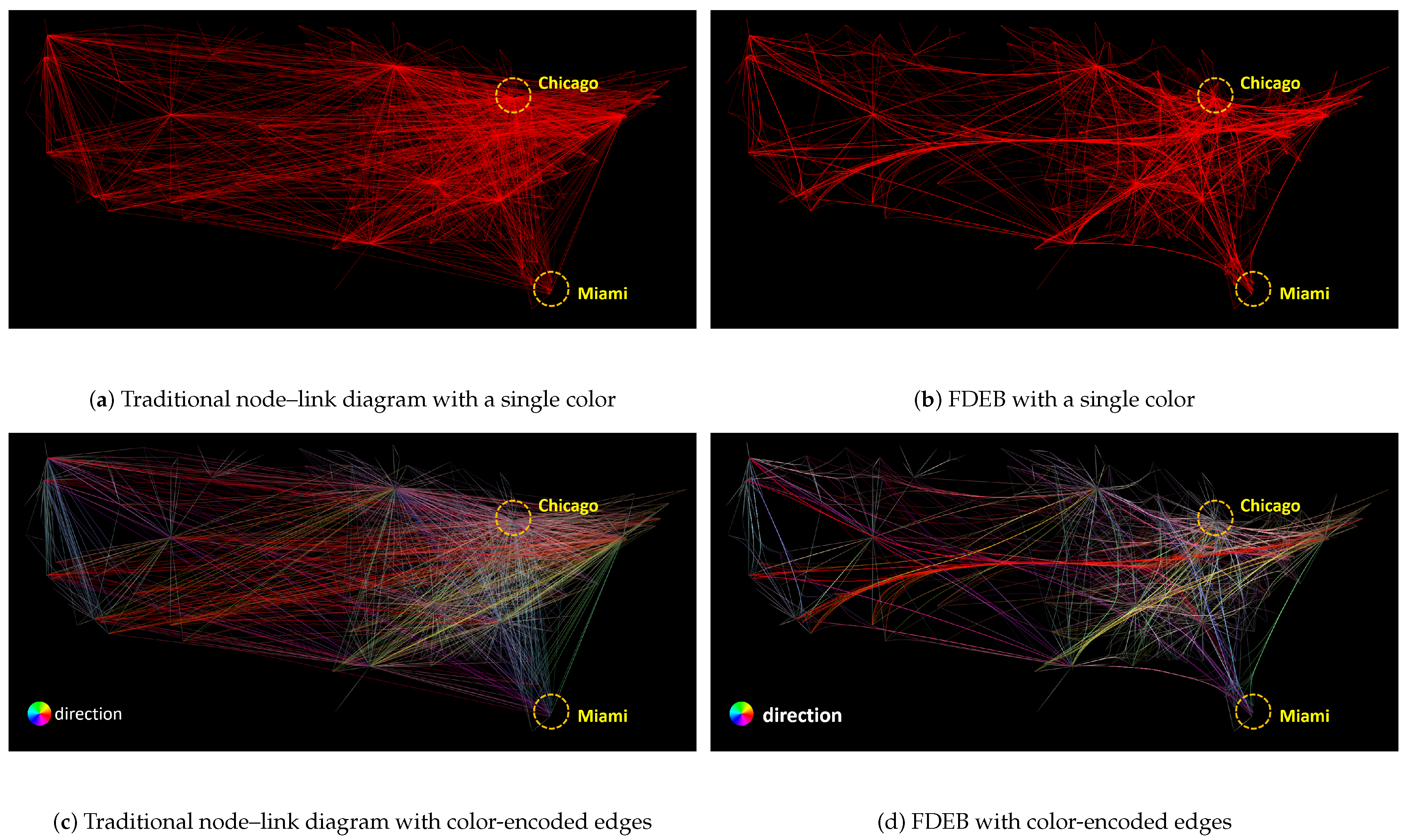
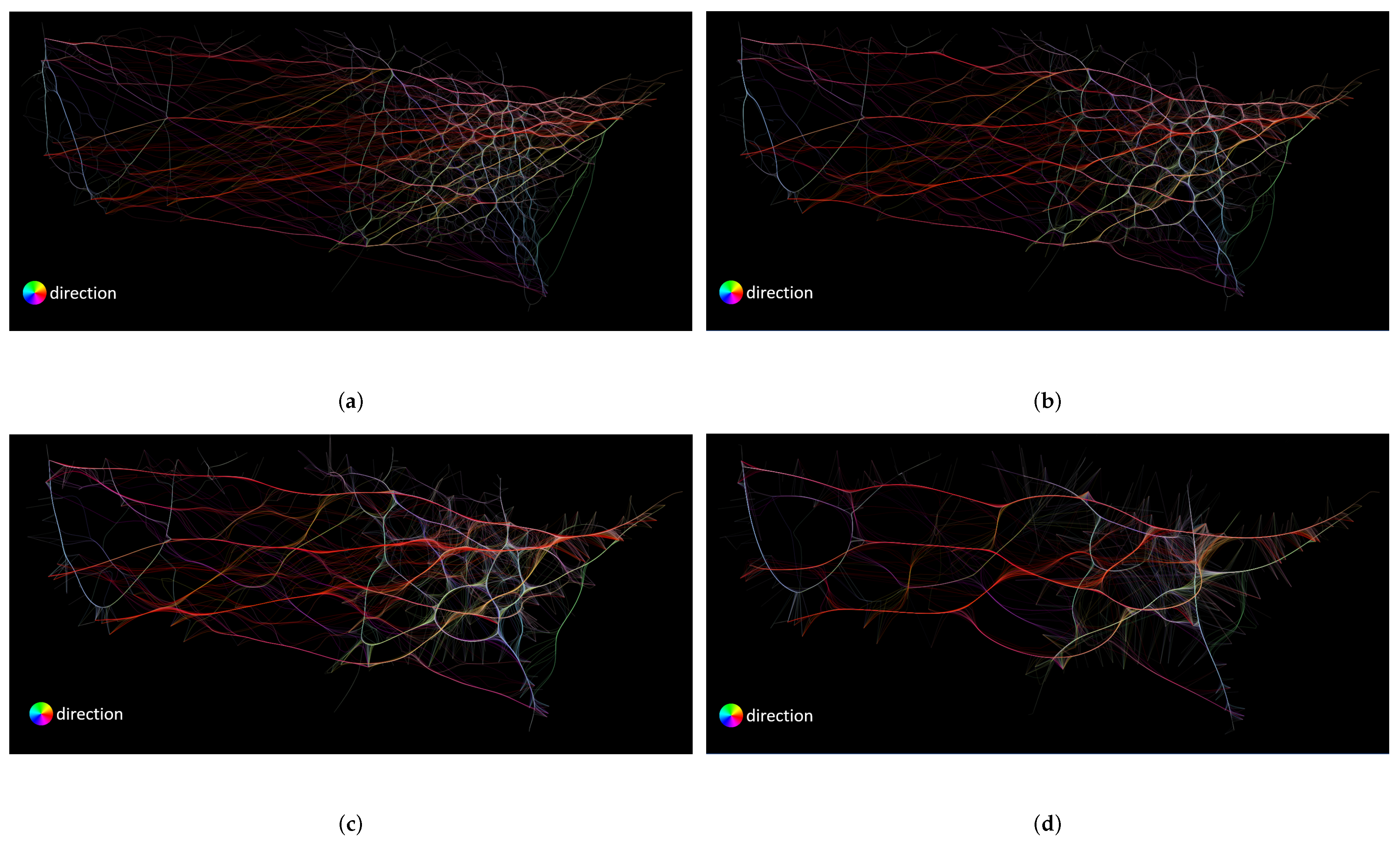
4.1. Revisit FDEB, FFTEB, and MLSEB
4.1.1. FDEB
4.1.2. FFTEB
4.1.3. MLSEB
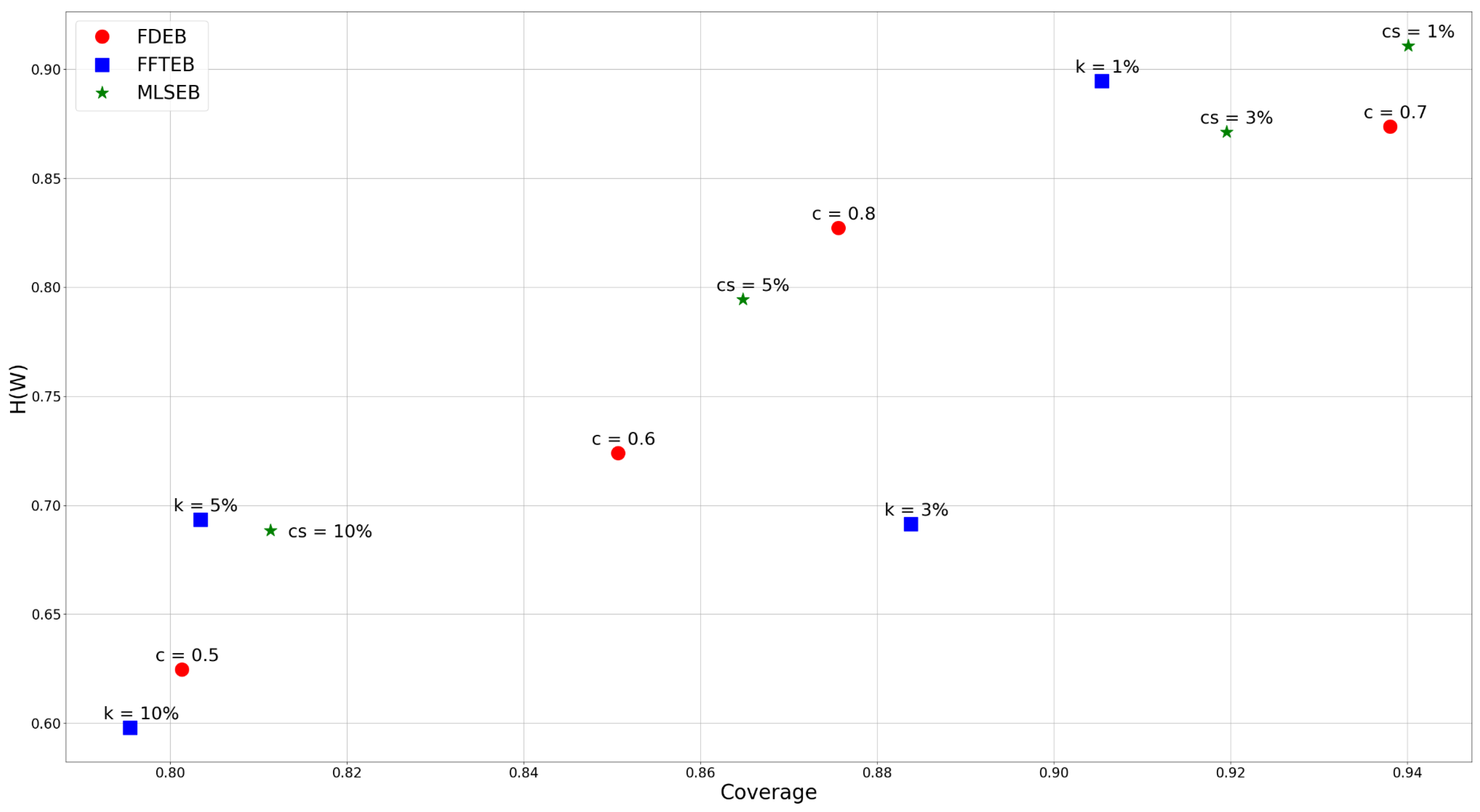
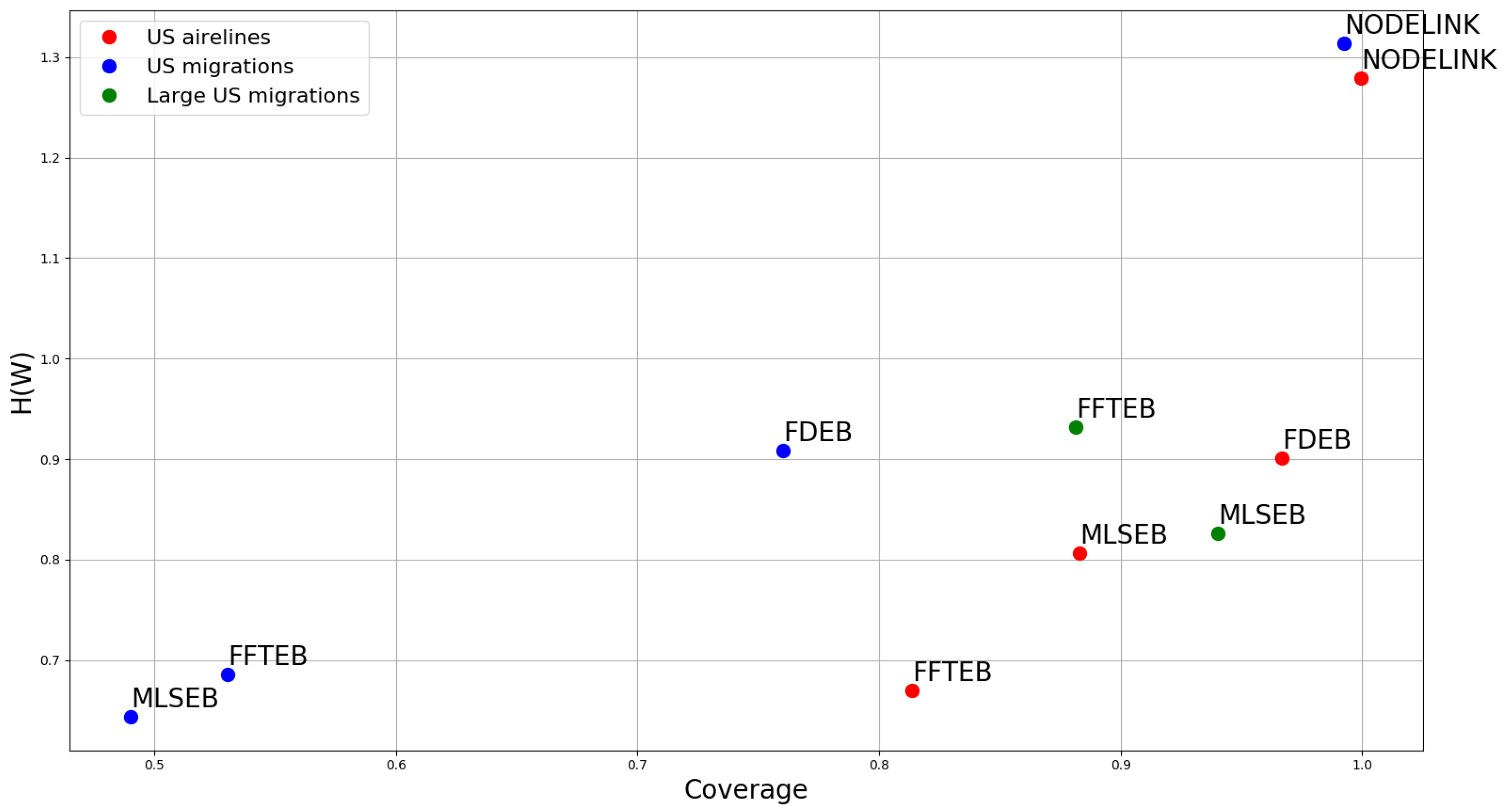
4.2. Heuristic Study
4.3. Comparison I
4.4. Comparison II
5. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| FDEB | force-directed edge bundling |
| FFTEB | fast fourier transform edge bundling |
| MLSEB | moving least squares edge bundling |
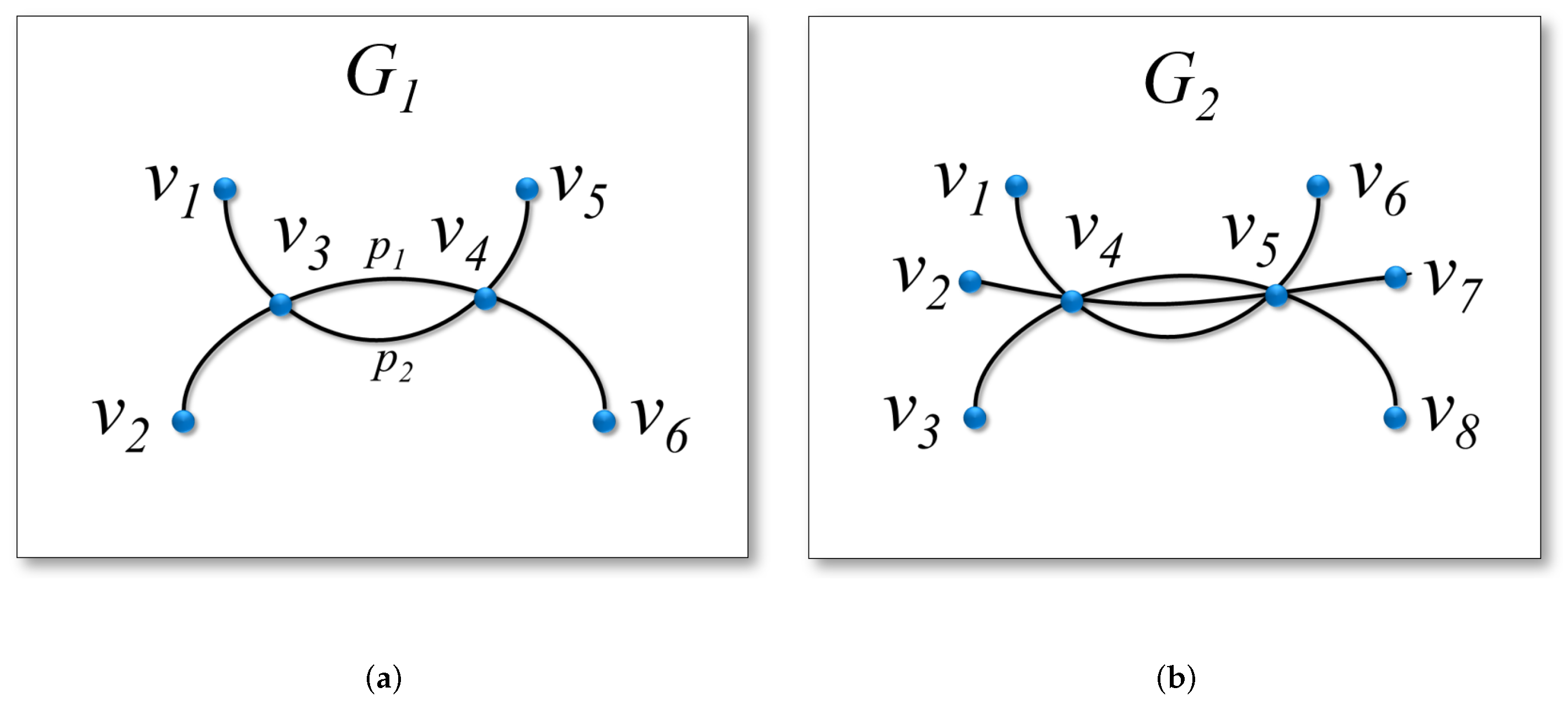
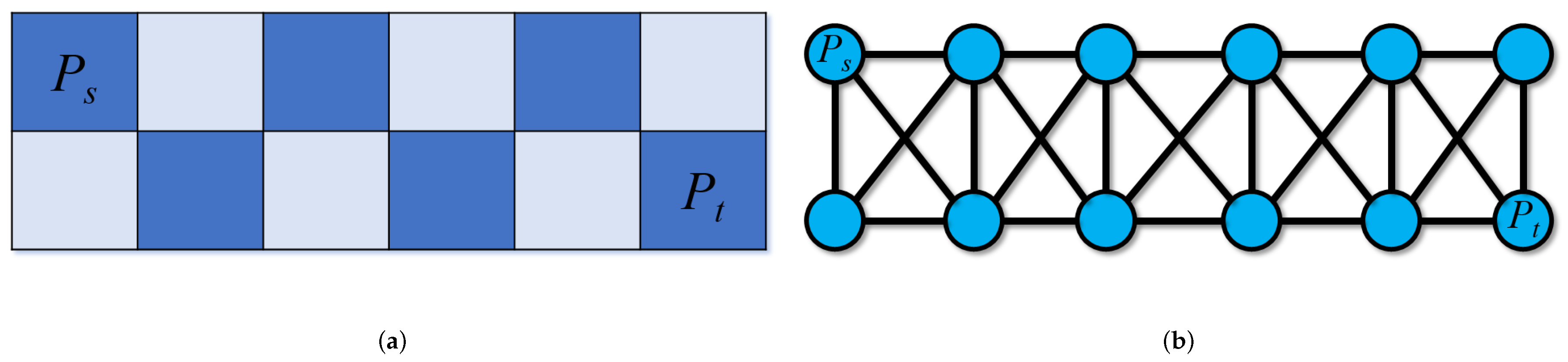
Appendix A Estimating the Number of Source–Target Paths

References
- Purchase, H.C.; Cohen, R.F.; James, M. Validating graph drawing aesthetics. In International Symposium on Graph Drawing; Springer: Berlin, Germany, 1995; pp. 435–446. [Google Scholar]
- Purchase, H. Which aesthetic has the greatest effect on human understanding? In International Symposium on Graph Drawing; Springer: Berlin, Germany, 1997; pp. 248–261. [Google Scholar]
- Ware, C.; Purchase, H.; Colpoys, L.; McGill, M. Cognitive measurements of graph aesthetics. Inform. Vis. 2002, 1, 103–110. [Google Scholar] [CrossRef]
- Purchase, H.C. Metrics for graph drawing aesthetics. J. Vis. Lang. Comput. 2002, 13, 501–516. [Google Scholar] [CrossRef]
- Di Giacomo, E.; Didimo, W.; Liotta, G.; Meijer, H. Area, curve complexity, and crossing resolution of non-planar graph drawings. In International Symposium on Graph Drawing; Springer: Berlin, Germany, 2009; pp. 15–20. [Google Scholar]
- Nguyen, Q.; Eades, P.; Hong, S.H. On the faithfulness of graph visualizations. In Proceedings of the 2013 IEEE Pacific Visualization Symposium (PacificVis), Sydney, NSW, Australia, 27 February–1 March 2013; pp. 209–216. [Google Scholar]
- Lhuillier, A.; Hurter, C.; Telea, A. State of the art in edge and trail bundling techniques. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2017; Volume 36, pp. 619–645. [Google Scholar]
- Chen, M.; Jaenicke, H. An information-theoretic framework for visualization. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1206–1215. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Feixas, M.; Viola, I.; Bardera, A.; Shen, H.W.; Sbert, M. Information Theory Tools for Visualization; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Von Landesberger, T.; Kuijper, A.; Schreck, T.; Kohlhammer, J.; van Wijk, J.J.; Fekete, J.D.; Fellner, D.W. Visual analysis of large graphs: State-of-the-art and future research challenges. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2011; Volume 30, pp. 1719–1749. [Google Scholar]
- Beck, F.; Burch, M.; Diehl, S.; Weiskopf, D. The state of the art in visualizing dynamic graphs. EuroVis STAR 2014, 2, 1–21. [Google Scholar]
- Herman, I.; Melançon, G.; Marshall, M.S. Graph visualization and navigation in information visualization: A survey. IEEE Trans. Vis. Comput. Graph. 2000, 6, 24–43. [Google Scholar] [CrossRef] [Green Version]
- Vehlow, C.; Beck, F.; Weiskopf, D. The state of the art in visualizing group structures in graphs. In Eurographics Conference on Visualization (EuroVis)-STARs; The Eurographics Association: Geneve, Switzerland, 2015; Volume 2. [Google Scholar]
- Wang, Y.; Shen, Q.; Archambault, D.; Zhou, Z.; Zhu, M.; Yang, S.; Qu, H. AmbiguityVis: Visualization of ambiguity in graph layouts. IEEE Trans. Vis. Comput. Graph. 2016, 22, 359–368. [Google Scholar] [CrossRef] [PubMed]
- Purchase, H.C.; Carrington, D.; Allder, J.A. Empirical evaluation of aesthetics-based graph layout. Empir. Softw. Eng. 2002, 7, 233–255. [Google Scholar] [CrossRef]
- Purchase, H.C. Evaluating graph drawing aesthetics: Defining and exploring. In Computer Graphics and Multimedia: Applications, Problems and Solutions; Idea Group Inc.: Calgary, AB, Canada, 2004; pp. 145–178. [Google Scholar]
- Fishwick, P.A. Aesthetic computing: A brief tutorial. In Visual Languages for Interactive Computing: Definitions and Formalizations; Idea Group Inc.: Calgary, AB, Canada, 2007. [Google Scholar]
- Purchase, H.C.; Pilcher, C.; Plimmer, B. Graph drawing aesthetics—created by users, not algorithms. IEEE Trans. Vis. Comput. Graph. 2012, 18, 81–92. [Google Scholar] [CrossRef] [PubMed]
- Kobourov, S.G.; Pupyrev, S.; Saket, B. Are crossings important for drawing large graphs? In International Symposium on Graph Drawing; Springer: Berlin, Germany, 2014; pp. 234–245. [Google Scholar]
- Eades, P.; Hong, S.H.; Klein, K.; Nguyen, A. Shape-based quality metrics for large graph visualization. In International Symposium on Graph Drawing and Network Visualization; Springer: Berlin, Germany, 2015; pp. 502–514. [Google Scholar]
- Battista, G.D.; Eades, P.; Tamassia, R.; Tollis, I.G. Graph Drawing: Algorithms for the Visualization of Graphs; Prentice Hall PTR: Upper Saddle River, UJ, USA, 1998. [Google Scholar]
- Böttger, J.; Schäfer, A.; Lohmann, G.; Villringer, A.; Margulies, D.S. Three-dimensional mean-shift edge bundling for the visualization of functional connectivity in the brain. IEEE Trans. Vis. Comput. Graph. 2014, 20, 471–480. [Google Scholar] [CrossRef] [PubMed]
- Assaf, Y.; Pasternak, O. Diffusion tensor imaging (DTI)-based white matter mapping in brain research: A review. J. Mol. Neurosci. 2008, 34, 51–61. [Google Scholar] [CrossRef] [PubMed]
- Everts, M.H.; Begue, E.; Bekker, H.; Roerdink, J.B.; Isenberg, T. Exploration of the brain’s white matter structure through visual abstraction and multi-scale local fiber tract contraction. IEEE Trans. Vis. Comput. Graph. 2015, 21, 808–821. [Google Scholar] [CrossRef] [PubMed]
- Cornelissen, B.; Zaidman, A.; Holten, D.; Moonen, L.; van Deursen, A.; van Wijk, J.J. Execution trace analysis through massive sequence and circular bundle views. J. Syst. Softw. 2008, 81, 2252–2268. [Google Scholar] [CrossRef] [Green Version]
- Diehl, S.; Telea, A.C. Multivariate networks in software engineering. In Multivariate Network Visualization; Springer: Berlin, Germany, 2014; pp. 13–36. [Google Scholar]
- Reniers, D.; Voinea, L.; Ersoy, O.; Telea, A. The Solid* toolset for software visual analytics of program structure and metrics comprehension: From research prototype to product. Sci. Comput. Program. 2014, 79, 224–240. [Google Scholar] [CrossRef] [Green Version]
- Kienreich, W.; Seifert, C. An application of edge bundling techniques to the visualization of media analysis results. In Proceedings of the 2010 14th International Conference Information Visualisation, London, UK, 26–29 July 2010; pp. 375–380. [Google Scholar]
- Jia, Y.; Garland, M.; Hart, J.C. Social network clustering and visualization using hierarchical edge bundles. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2011; Volume 30, pp. 2314–2327. [Google Scholar]
- Holten, D. Hierarchical edge bundles: Visualization of adjacency relations in hierarchical data. IEEE Trans. Vis. Comput. Graph. 2006, 12, 741–748. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Wang, C.; Shene, C.K.; Chen, J.H. Hierarchical streamline bundles. IEEE Trans. Vis. Comput. Graph. 2012, 18, 1353–1367. [Google Scholar] [PubMed]
- Zhou, H.; Yuan, X.; Qu, H.; Cui, W.; Chen, B. Visual clustering in parallel coordinates. In Computer Graphics Forum; Wiley/Blackwell: Oxford, UK, 2008; Volume 27, pp. 1047–1054. [Google Scholar]
- Holten, D.; Van Wijk, J.J. Force-directed edge bundling for graph visualization. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2009; Volume 28, pp. 983–990. [Google Scholar]
- Nguyen, Q.H.; Hong, S.H.; Eades, P. TGI-EB: A new framework for edge bundling integrating topology, geometry and importance. In International Symposium on Graph Drawing; Springer: Berlin, Germany, 2011; pp. 123–135. [Google Scholar]
- Selassie, D.; Heller, B.; Heer, J. Divided edge bundling for directional network data. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2354–2363. [Google Scholar] [CrossRef] [PubMed]
- Zielasko, D.; Weyers, B.; Hentschel, B.; Kuhlen, T.W. Interactive 3D force-directed edge bundling. In Proceedings of the Eurographics/IEEE VGTC Conference on Visualization, Groningen, The Netherlands, 6–10 June 2016; Volume 35, pp. 51–60. [Google Scholar]
- Cui, W.; Zhou, H.; Qu, H.; Wong, P.C.; Li, X. Geometry-based edge clustering for graph visualization. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1277–1284. [Google Scholar] [CrossRef] [PubMed]
- Luo, S.J.; Liu, C.L.; Chen, B.Y.; Ma, K.L. Ambiguity-free edge-bundling for interactive graph visualization. IEEE Trans. Vis. Comput. Graph. 2012, 18, 810–821. [Google Scholar] [PubMed]
- Lambert, A.; Bourqui, R.; Auber, D. Winding roads: Routing edges into bundles. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2010; Volume 29, pp. 853–862. [Google Scholar]
- Lambert, A.; Bourqui, R.; Auber, D. 3D edge bundling for geographical data visualization. In Proceedings of the 2010 14th International Conference Information Visualisation, London, UK, 26–29 July 2010; pp. 329–335. [Google Scholar]
- Gansner, E.R.; Koren, Y. Improved circular layouts. In International Symposium on Graph Drawing; Springer: Berlin, Germany, 2006; pp. 386–398. [Google Scholar]
- Gansner, E.R.; Hu, Y.; North, S.; Scheidegger, C. Multilevel agglomerative edge bundling for visualizing large graphs. In Proceedings of the 2011 IEEE Pacific Visualization Symposium, Hong Kong, China, 1–4 March 2011; pp. 187–194. [Google Scholar]
- Ersoy, O.; Hurter, C.; Paulovich, F.; Cantareiro, G.; Telea, A. Skeleton-based edge bundling for graph visualization. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2364–2373. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hurter, C.; Ersoy, O.; Telea, A. Graph bundling by kernel density estimation. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2012; Volume 31, pp. 865–874. [Google Scholar]
- Peysakhovich, V.; Hurter, C.; Telea, A. Attribute-driven edge bundling for general graphs with applications in trail analysis. In Proceedings of the 2015 IEEE Pacific Visualization Symposium (PacificVis), Hangzhou, China, 14–17 April 2015; pp. 39–46. [Google Scholar]
- Van der Zwan, M.; Codreanu, V.; Telea, A. CUBu: Universal real-time bundling for large graphs. IEEE Trans. Vis. Comput. Graph. 2016, 22, 2550–2563. [Google Scholar] [CrossRef] [PubMed]
- Lhuillier, A.; Hurter, C.; Telea, A. FFTEB: Edge bundling of huge graphs by the fast fourier transform. In Proceedings of the 2017 IEEE Pacific Visualization Symposium (PacificVis), Seoul, Korea, 18–21 April 2017; pp. 190–199. [Google Scholar]
- Wu, J.; Zeng, J.; Zhu, F.; Yu, H. MLSEB: Edge bundling using moving least squares approximation. In International Symposium on Graph Drawing and Network Visualization; Springer: Berlin, Germany, 2017. [Google Scholar]
- Hurter, C.; Puechmorel, S.; Nicol, F.; Telea, A. Functional decomposition for bundled simplification of trail sets. IEEE Trans. Vis. Comput. Graph. 2018, 24, 500–510. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mobile Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Champaign, IL, USA, 1998. [Google Scholar]
- Purchase, H.; Andrienko, N.; Jankun-Kelly, T.; Ward, M. Theoretical foundations of information visualization. In Information Visualization; Springer: Berlin, Germany, 2008; pp. 46–64. [Google Scholar]
- Kerren, A.; Stasko, J.; Fekete, J.D.; North, C. Information Visualization: Human-Centered Issues and Perspectives; Springer: Berlin, Germany, 2008. [Google Scholar]
- Wang, C.; Shen, H.W. Information theory in scientific visualization. Entropy 2011, 13, 254–273. [Google Scholar] [CrossRef]
- Ji, G.; Shen, H.W. Dynamic view selection for time-varying volumes. IEEE Trans. Vis. Comput. Graph. 2006, 12, 1109–1116. [Google Scholar] [PubMed]
- Marchesin, S.; Chen, C.K.; Ho, C.; Ma, K.L. View-dependent streamlines for 3D vector fields. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1578–1586. [Google Scholar] [CrossRef] [PubMed]
- Takahashi, S.; Fujishiro, I.; Takeshima, Y.; Nishita, T. A Feature-driven approach to locating optimal viewpoints for volume visualization. In Proceedings of the (VIS 05). IEEE Visualization, 2005, Minneapolis, MN, USA, 23–28 October 2005; pp. 495–502. [Google Scholar]
- González, F.; Sbert, M.; Feixas, M. Viewpoint-based ambient occlusion. IEEE Comput. Graph. Appl. 2008, 28, 44–51. [Google Scholar] [CrossRef] [PubMed]
- Castelló, P.; Sbert, M.; Chover, M.; Feixas, M. Viewpoint-driven simplification using mutual information. Comput. Graph. 2008, 32, 451–463. [Google Scholar] [CrossRef]
- Feixas, M.; Del Acebo, E.; Bekaert, P.; Sbert, M. An information theory framework for the analysis of scene complexity. In Computer Graphics Forum; Blackwell Publishers Ltd.: Oxford, UK; Boston, MA, USA, 1999; Volume 18, pp. 95–106. [Google Scholar] [CrossRef]
- Rigau, J.; Feixas, M.; Sbert, M. New contrast measures for pixel supersampling. In Advances in Modelling, Animation and Rendering; Springer: Berlin, Germany, 2002; pp. 439–451. [Google Scholar]
- Fleishman, S.; Cohen-Or, D.; Lischinski, D. Automatic camera placement for image-based modeling. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2000; Volume 19, pp. 101–110. [Google Scholar]
- Gumhold, S. Maximum entropy light source placement. In Proceedings of the IEEE Visualization, (2002. VIS 2002), Boston, MA, USA, 27 October–1 November 2002; pp. 275–282. [Google Scholar]
- Vázquez, P.P.; Feixas, M.; Sbert, M.; Heidrich, W. Automatic view selection using viewpoint entropy and its application to image-based modelling. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2003; Volume 22, pp. 689–700. [Google Scholar]
- Sbert, M.; Feixas, M.; Rigau, J.; Chover, M.; Viola, I. Information theory tools for computer graphics. Synth. Lect. Comput. Graph. Anim. 2009, 4, 1–153. [Google Scholar] [CrossRef]
- Shannon, C.E. The bandwagon. IRE Trans. Inform. Theory 1956, 2, 3. [Google Scholar] [CrossRef]
- Guiaşu, S. Information Theory with New Applications; McGraw-Hill Companies: New York, NY, USA, 1977. [Google Scholar]
- Usher, M. Information Theory for Information Technologists; Scholium International, Inc.: Port Washington, NY, USA, 1984. [Google Scholar]
- Kullback, S. Information Theory and Statistics; Courier Corporation: North Chelmsford, MA, USA, 1997. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Bardera, A.; Bramon, R.; Ruiz, M.; Boada, I. Rate-distortion theory for clustering in the perceptual space. Entropy 2017, 19, 438. [Google Scholar] [CrossRef]
- Viola, P.; Wells, W.M., III. Alignment by maximization of mutual information. Int. J. Comput. Vis. 1997, 24, 137–154. [Google Scholar] [CrossRef]
- Maes, F.; Collignon, A.; Vandermeulen, D.; Marchal, G.; Suetens, P. Multimodality image registration by maximization of mutual information. IEEE Trans. Med. Imaging 1997, 16, 187–198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thévenaz, P.; Unser, M. Optimization of mutual information for multiresolution image registration. IEEE Trans. Image Process. 2000, 9, 2083–2099. [Google Scholar] [PubMed] [Green Version]
- Pluim, J.P.; Maintz, J.A.; Viergever, M.A. Mutual information based registration of medical images: A survey. IEEE Trans. Med. Imaging 2003, 22, 986–1004. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Fisher, J.W.; Yezzi, A.; Çetin, M.; Willsky, A.S. A nonparametric statistical method for image segmentation using information theory and curve evolution. IEEE Trans. Image Process. 2005, 14, 1486–1502. [Google Scholar] [PubMed]
- Bramon, R.; Ruiz, M.; Bardera, A.; Boada, I.; Feixas, M.; Sbert, M. An information-theoretic observation channel for volume visualization. In Proceedings of the EuroVis ‘13 Proceedings of the 15th Eurographics Conference on Visualization, Leipzig, Germany, 17–21 June 2013; Volume 32, pp. 411–420. [Google Scholar]
- Roberts, B.; Kroese, D.P. Estimating the number of st paths in a graph. J. Graph Algorithms Appl. 2007, 11, 195–214. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| U.S. Airlines | U.S. Migrations | U.S. Airlines | U.S. Migrations | U.S. Airlines | U.S. Migrations | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Configuration | ||||||||||||
| 0.661 | 0.795 | 0.791 | 0.669 | 0.225 | 0.437 | 0.457 | 0.268 | 0.486 | 0.584 | 0.349 | 0.258 | |
| 0.751 | 0.817 | 0.856 | 0.688 | 0.319 | 0.554 | 0.508 | 0.359 | 0.607 | 0.679 | 0.380 | 0.307 | |
| 0.793 | 0.830 | 0.870 | 0.699 | 0.343 | 0.575 | 0.518 | 0.389 | 0.646 | 0.681 | 0.391 | 0.339 | |
| 0.838 | 0.944 | 0.846 | 0.671 | 0.326 | 0.564 | 0.527 | 0.336 | 0.594 | 0.742 | 0.469 | 0.288 | |
| 0.907 | 0.972 | 0.888 | 0.705 | 0.450 | 0.689 | 0.577 | 0.397 | 0.710 | 0.810 | 0.513 | 0.346 | |
| 0.945 | 0.975 | 0.893 | 0.713 | 0.485 | 0.709 | 0.588 | 0.421 | 0.753 | 0.827 | 0.529 | 0.363 | |
| 0.893 | 0.988 | 0.873 | 0.763 | 0.642 | 0.770 | 0.681 | 0.459 | 0.815 | 0.947 | 0.680 | 0.398 | |
| 0.926 | 0.997 | 0.911 | 0.786 | 0.819 | 0.867 | 0.723 | 0.521 | 0.889 | 0.982 | 0.718 | 0.458 | |
| 0.961 | 0.997 | 0.928 | 0.792 | 0.864 | 0.877 | 0.740 | 0.558 | 0.925 | 0.985 | 0.726 | 0.467 | |
| 0.909 | 0.996 | 0.883 | 0.800 | 0.735 | 0.911 | 0.740 | 0.582 | 0.845 | 0.966 | 0.702 | 0.673 | |
| 0.934 | 0.998 | 0.940 | 0.822 | 0.848 | 0.973 | 0.782 | 0.691 | 0.902 | 0.988 | 0.746 | 0.702 | |
| 0.965 | 0.998 | 0.952 | 0.831 | 0.894 | 0.978 | 0.800 | 0.729 | 0.934 | 0.990 | 0.760 | 0.719 | |
| 0.922 | 0.999 | 0.938 | 0.809 | 0.759 | 0.937 | 0.857 | 0.692 | 0.858 | 0.977 | 0.726 | 0.682 | |
| 0.945 | 0.999 | 0.954 | 0.837 | 0.870 | 0.988 | 0.889 | 0.776 | 0.905 | 0.995 | 0.761 | 0.703 | |
| 0.976 | 0.999 | 0.967 | 0.849 | 0.920 | 0.995 | 0.901 | 0.792 | 0.936 | 0.995 | 0.789 | 0.718 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Zhu, F.; Liu, X.; Yu, H. An Information-Theoretic Framework for Evaluating Edge Bundling Visualization. Entropy 2018, 20, 625. https://doi.org/10.3390/e20090625
Wu J, Zhu F, Liu X, Yu H. An Information-Theoretic Framework for Evaluating Edge Bundling Visualization. Entropy. 2018; 20(9):625. https://doi.org/10.3390/e20090625
Chicago/Turabian StyleWu, Jieting, Feiyu Zhu, Xin Liu, and Hongfeng Yu. 2018. "An Information-Theoretic Framework for Evaluating Edge Bundling Visualization" Entropy 20, no. 9: 625. https://doi.org/10.3390/e20090625
APA StyleWu, J., Zhu, F., Liu, X., & Yu, H. (2018). An Information-Theoretic Framework for Evaluating Edge Bundling Visualization. Entropy, 20(9), 625. https://doi.org/10.3390/e20090625