Investigating the Configurations in Cross-Shareholding: A Joint Copula-Entropy Approach



Abstract
:1. Introduction
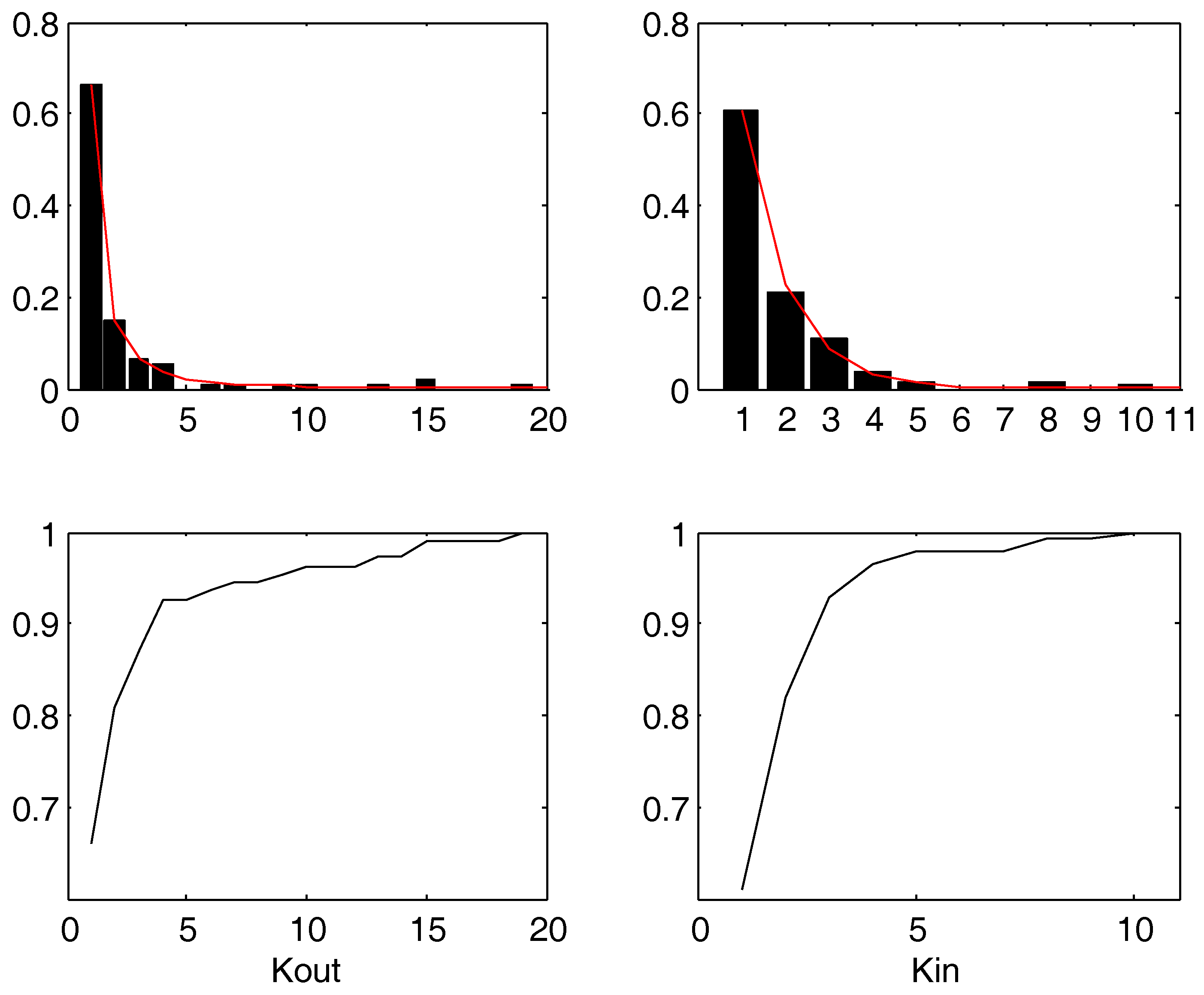
2. Distribution of the in- and out-Degrees: Empirical Evidences in Literature and a Case Study
2.1. The out-Degree
2.2. The in-Degree
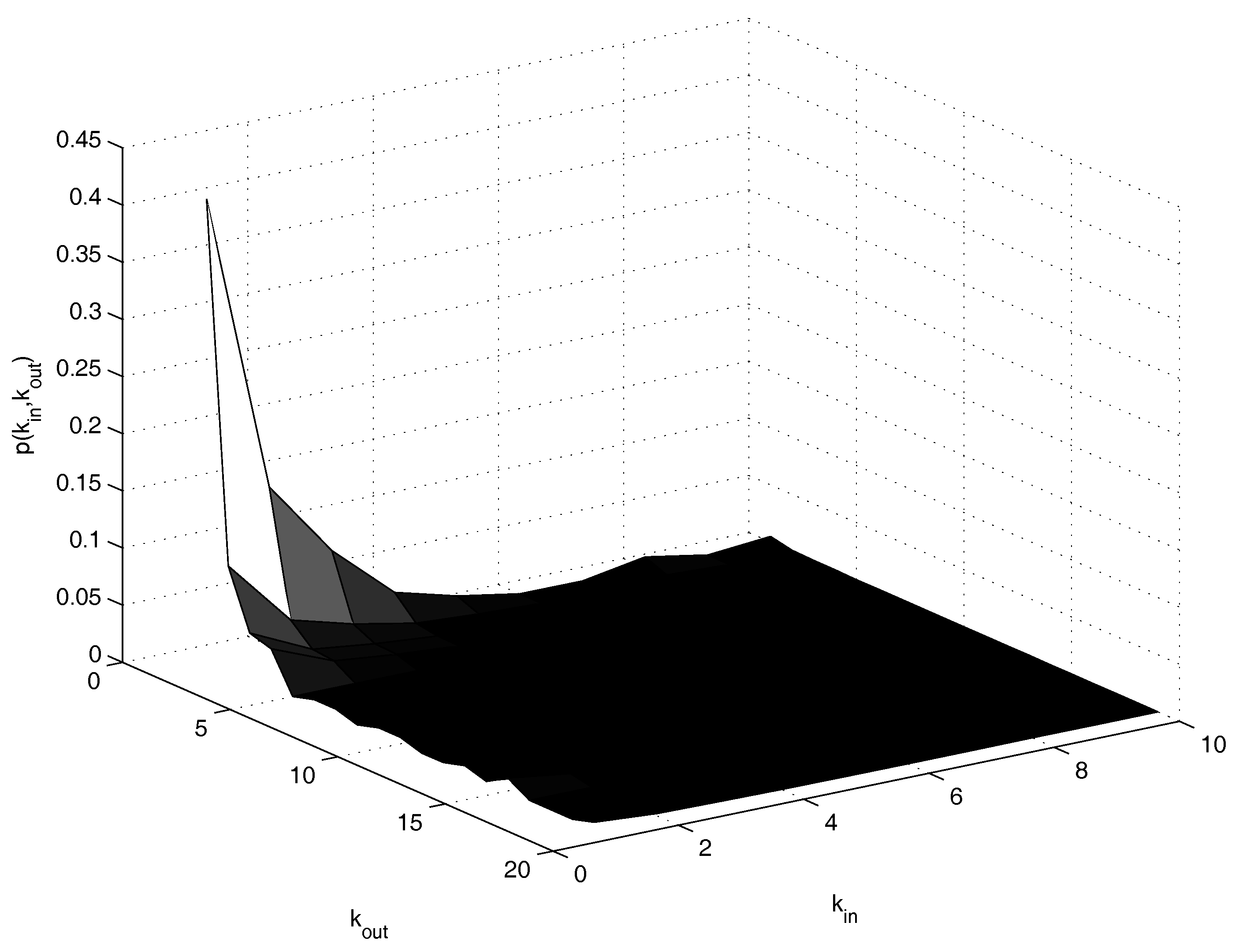
3. Data
4. Investigation Procedure
4.1. The Adopted Copulas
- if ;
- and , for each ;
- Given the 2-dimensional rectangle , thenwhere and .
- Product copulaThis is the case in which the random variables X and Y are independent.
- Lower Frechet boundThis copula represents the case of perfect negative correlation between X and Y.
- Upper Frechet boundThis copula, in an opposite way with respect to the previous one, captures perfect positive correlation between X and Y.
- Gumbel Archimedean copulaIn this case, one has an asymmetric tail dependence, with more mass on the right tail. Such a dependence is influenced by the value of the parameter .
- Clayton Archimedean copulaAnalogously to the previous case, here one has an asymmetric tail dependence. However, Clayton copula is associated to a predominance of the left tail.
- Frank Archimedean copulaThis copula is not associated to tail dependence, and is able to capture either positive or negative dependence on the basis of the value of .
4.2. Outline of the Analysis and Numerical Results
5. Results and Discussion
5.1. Case 1: Distance from the Empirical Joint Distribution
- Product copula (independence):
- Lower Frechet bound
- Upper Frechet bound
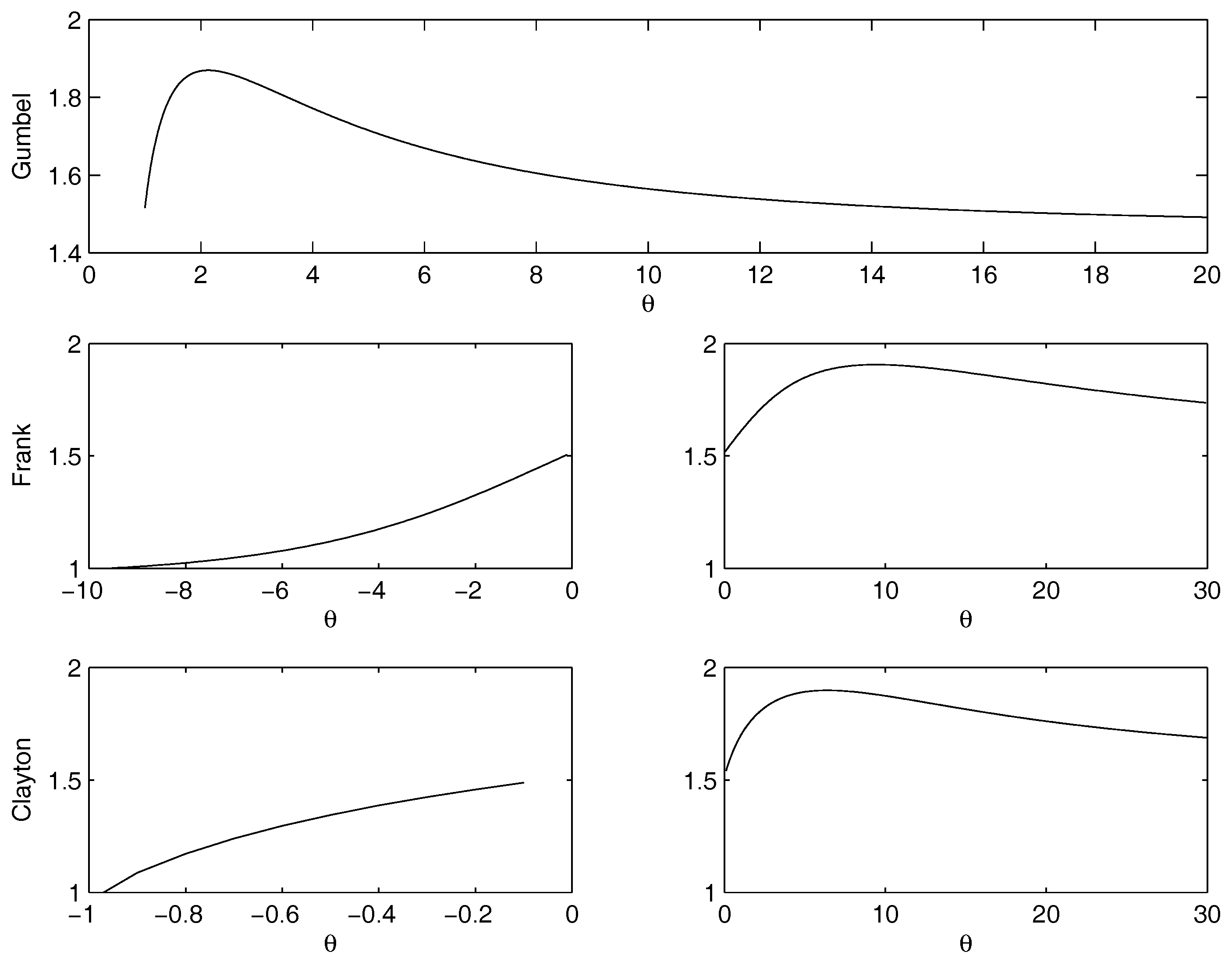
- Gumbel Archimedean copula. The best fit holds for , with practically 0 as value for the distance. This is coherent with the case of the product copula, because, in fact, when , then the Gumbel copula reduces to the product copula. Small differences on the distance are due to the numerical rounding of the algorithm. This outcome confirms what obtained for the independence case.
- Frank Archimedean copula. The distance from the empirical data is decreasing as approaches 0, but 0 does not belong to the definition set. Therefore, the calibrated parameter tends to zero. We do not have an optimal value of . From this, we infer that this copula is not suitable for the fit.
- Clayton Archimedean copula. For the negative values of , there is a minimum for , that belongs to the definition set and corresponds to the case of the lower Frechet bound. The value of the distance for is .
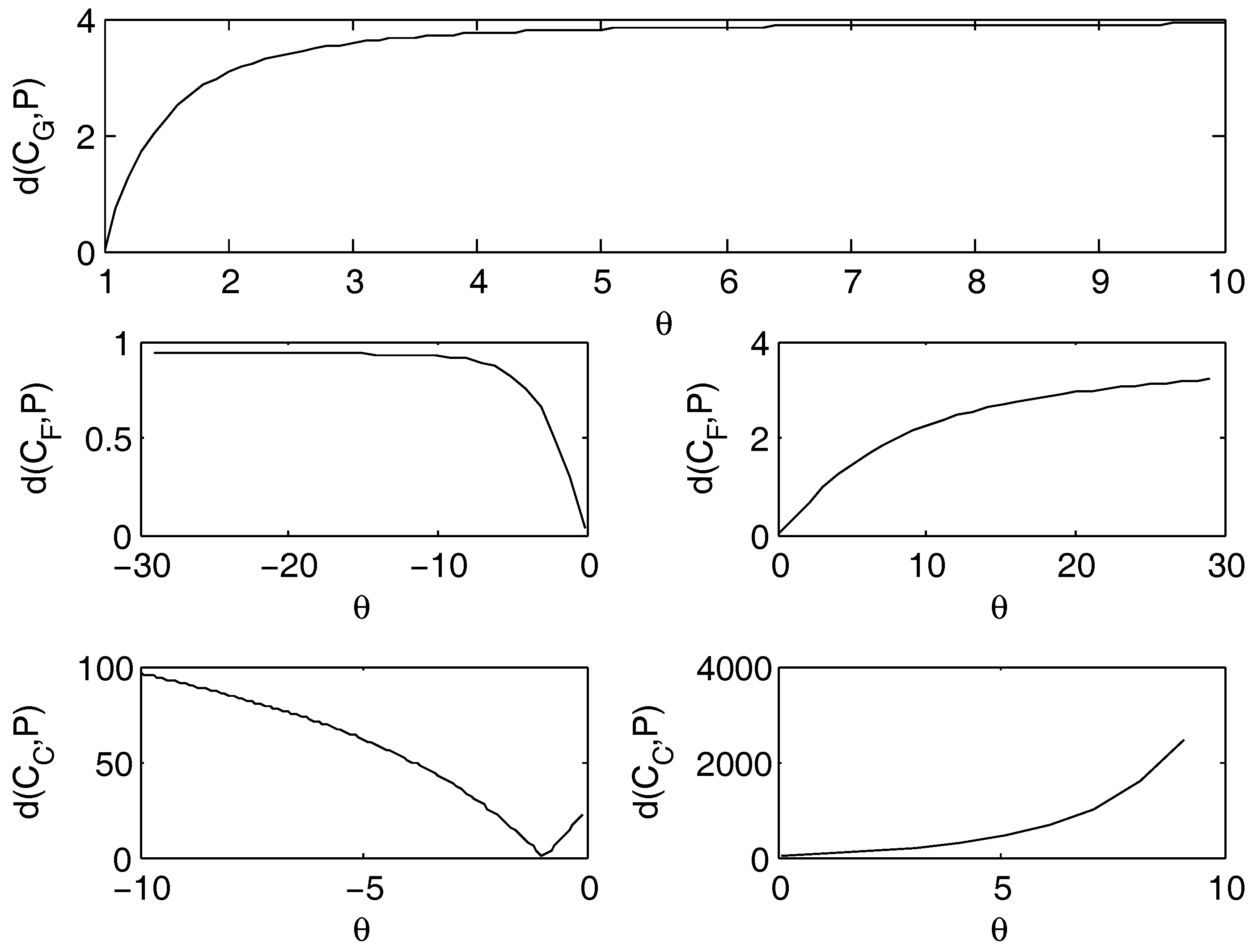
5.2. Case 2: Entropy
- Product: , the same value as for the empirical joint distribution. In fact, this copula well describes the joint distribution.
- Lower Frechet: .
- Upper Frechet: .
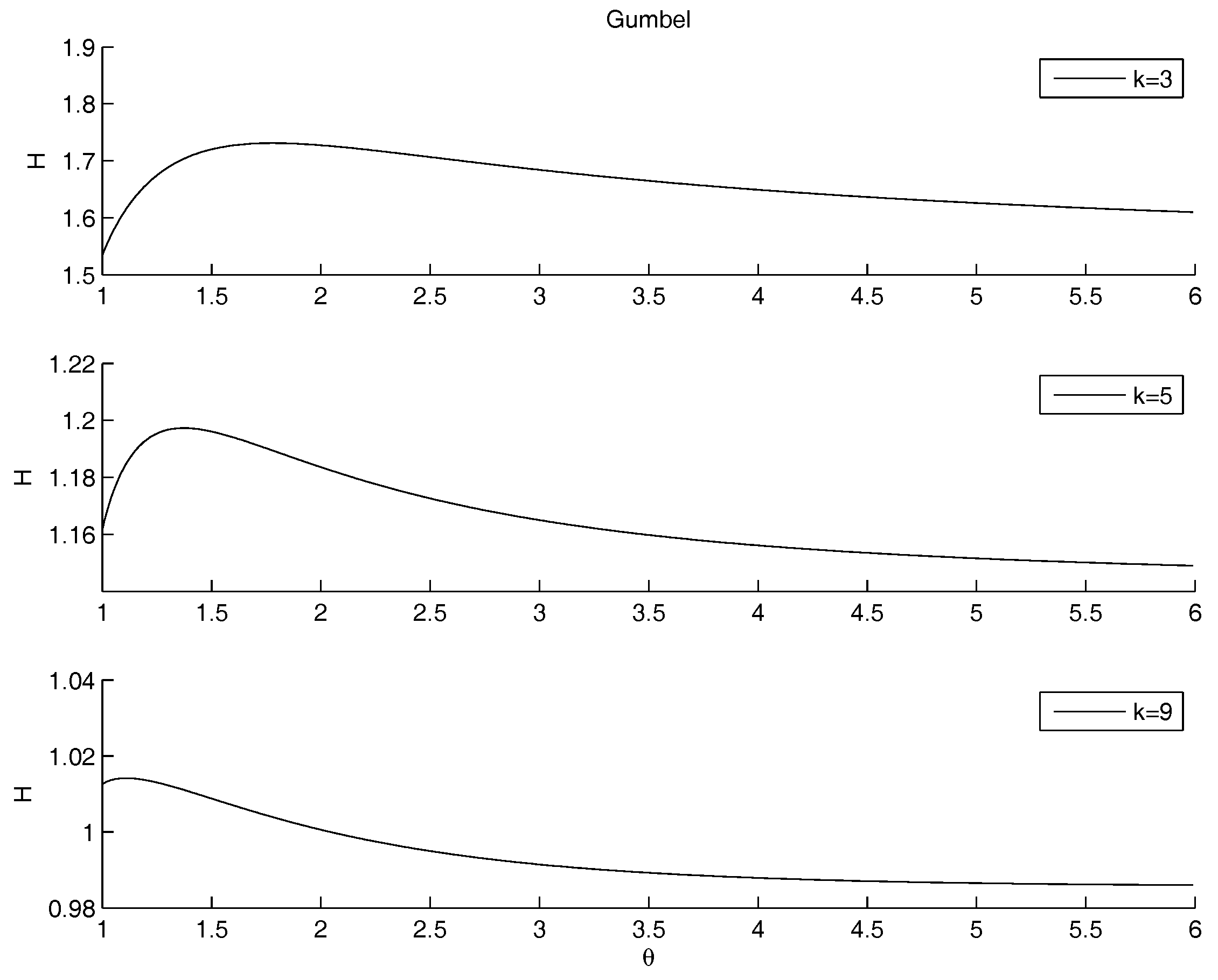
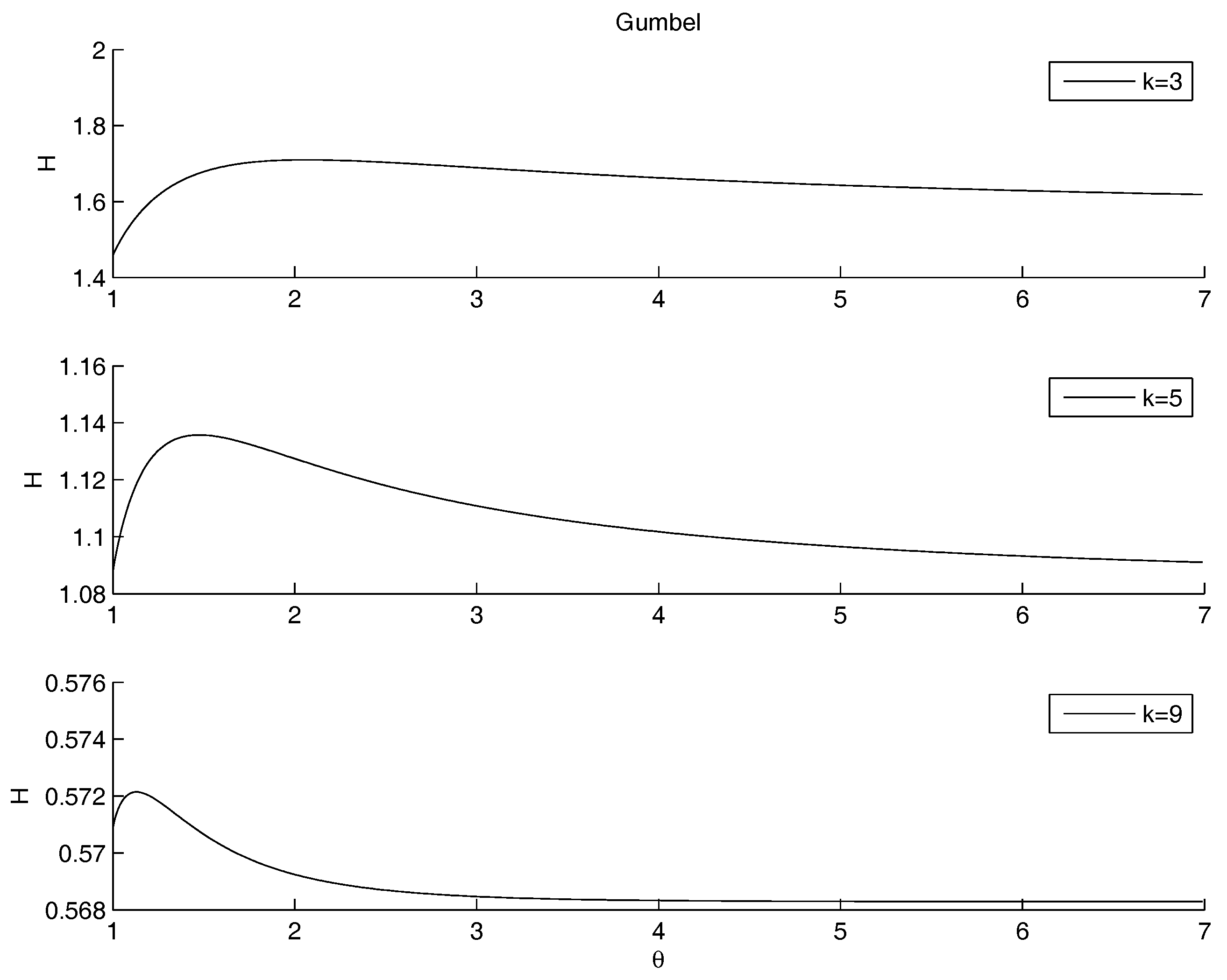
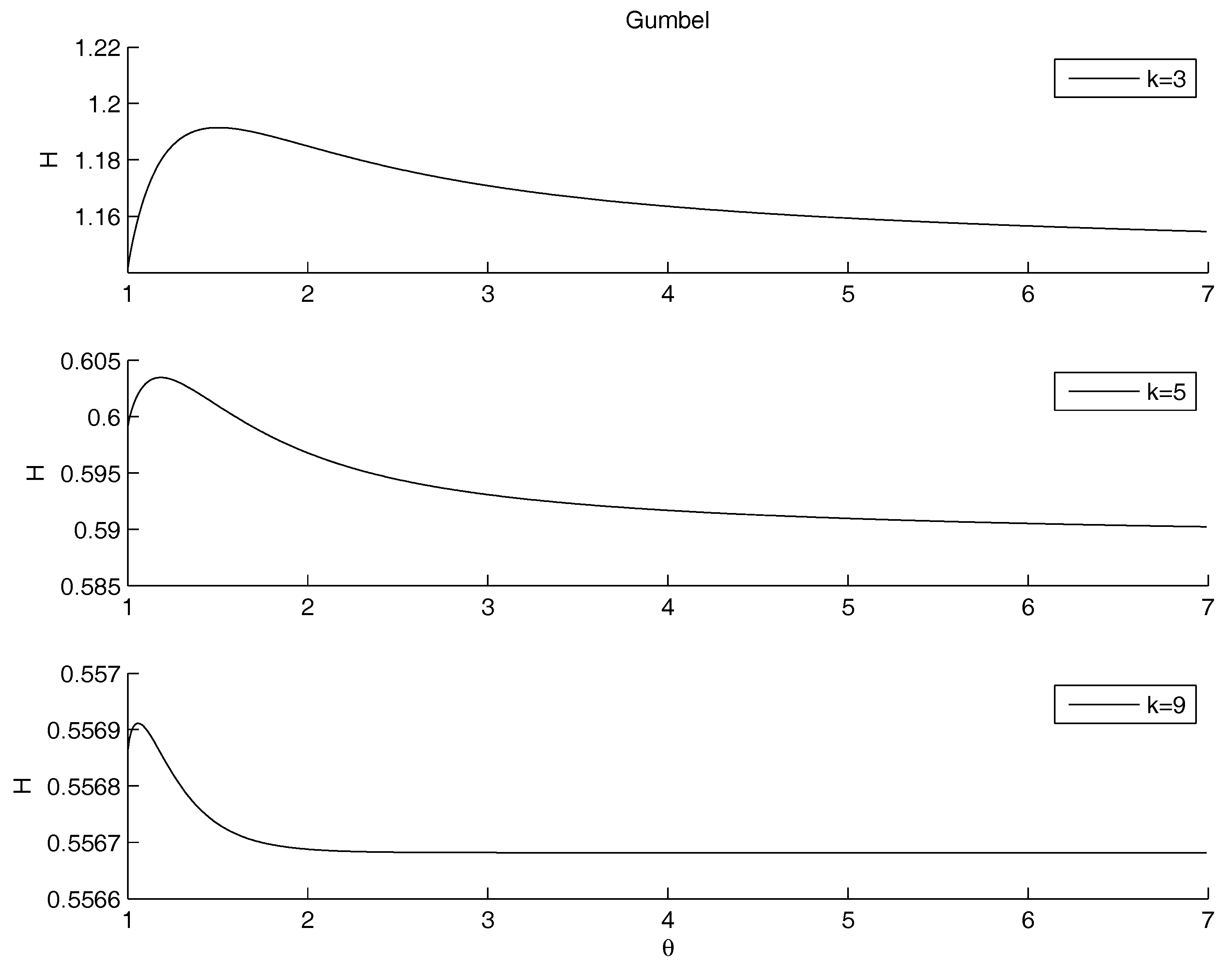
- Gumbel Archimedean copula. The numerical minimization procedure gives the best fit for , with a value of the entropy equal to . This is in line with the best fit of the product copula. From Figure 4 it is possible to note that there is an asymptotic behavior for going to infinity. The maximum is attained for with a value of the entropy equal to .
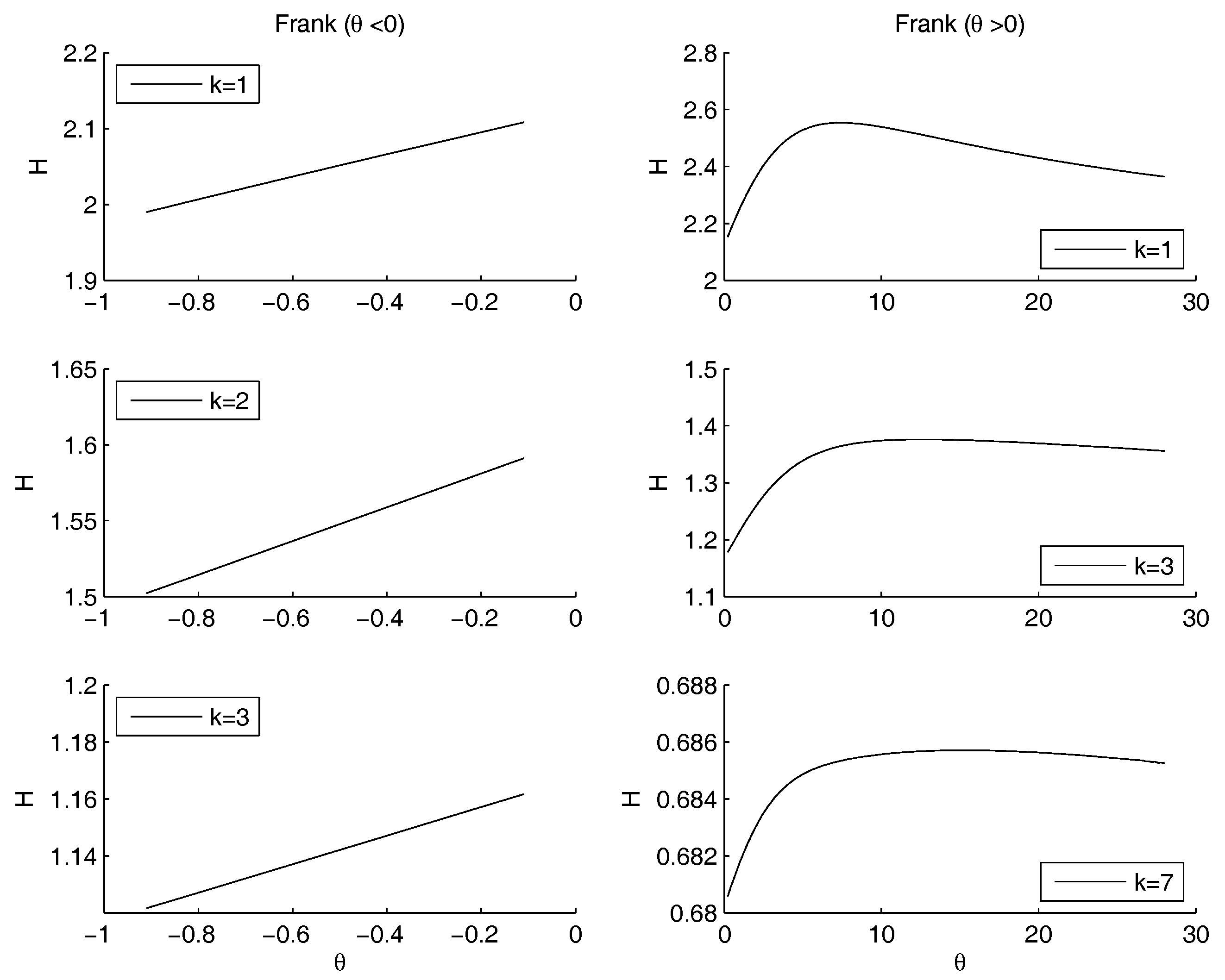
- Frank Archimedean copula. There is no minimum because 0 does not belong to the definition set of the functions. The maximum is attained for with a value of the entropy equal to .
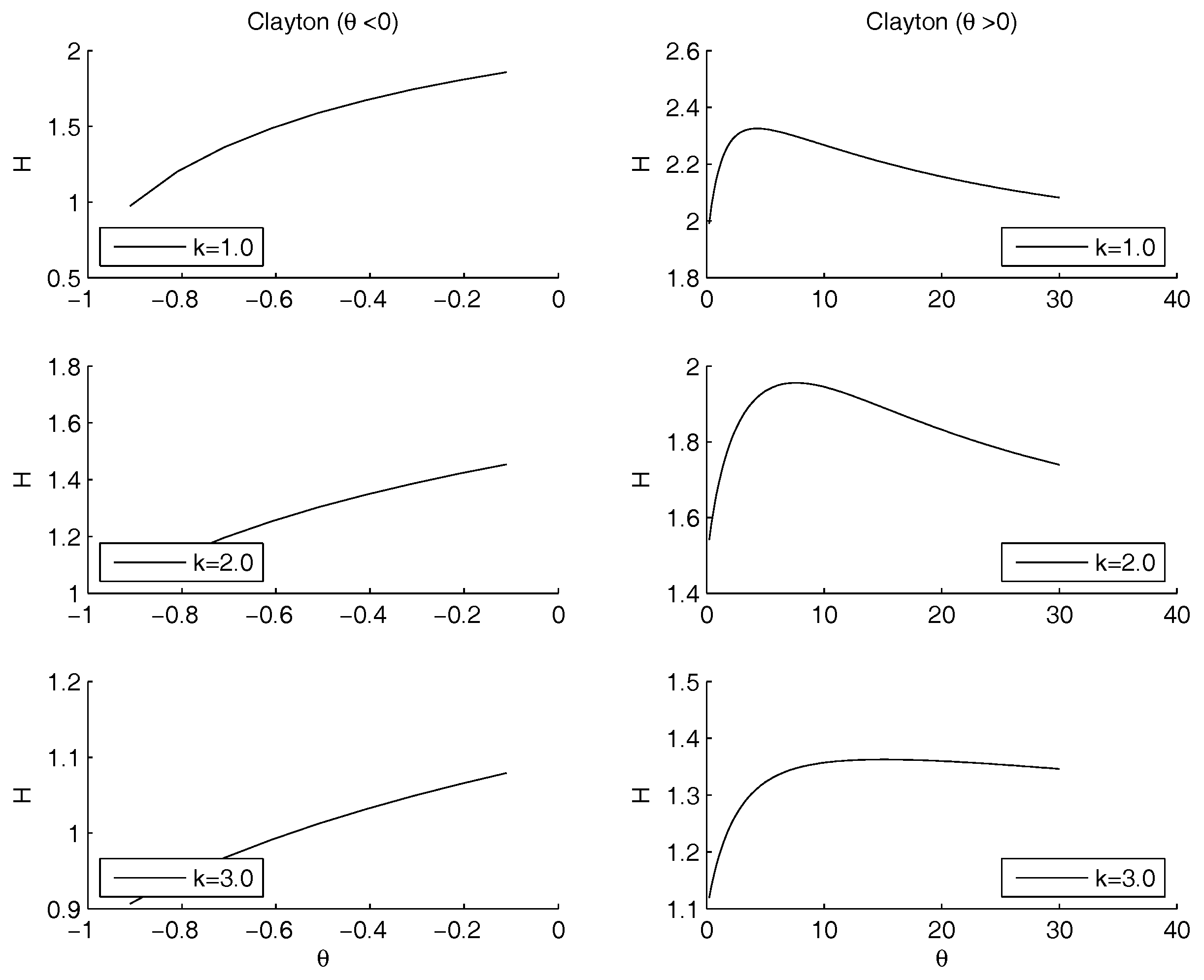
- Clayton Archimedean copula. There is no minimum internal to the definition set. From Figure 4 it is clearly visible that the function is decreasing for , so , that is the lower bound of the parameter variation interval, is a point of minimum. Regarding the maximum, the numerical maximization of the entropy gives the point of maximum in , with a value of the entropy equal to .
5.3. Case 3: Marginals Depending on Parameters
- step 1: power law for , and raw data for .
- step 2: raw data for , and power law for .
- step 3: raw data for , and exponential law for .
- step 4: power law for , and power law for .
- step 5: power law for , and exponential law for .
Step 1: Power Law for , and Raw Data for
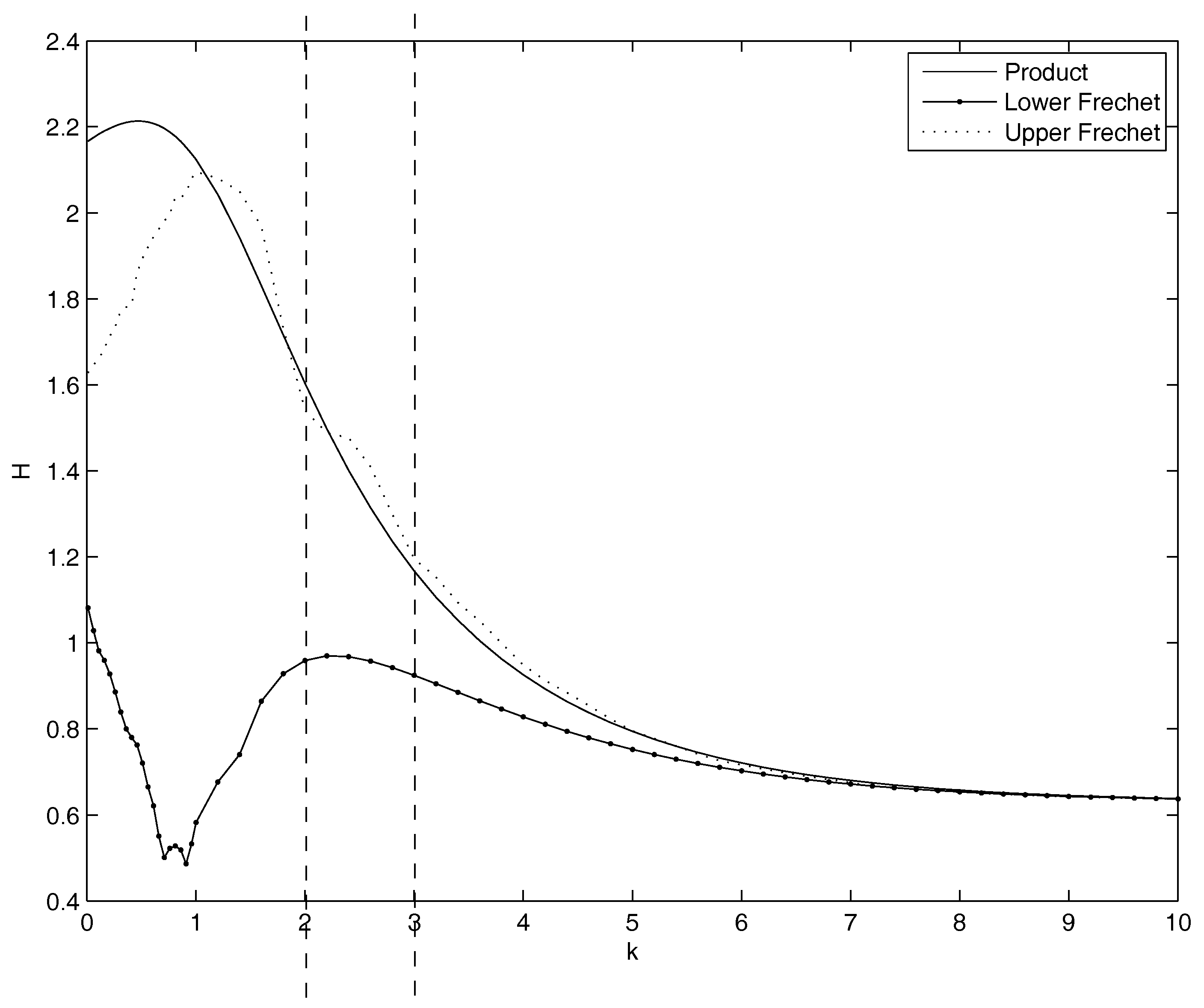
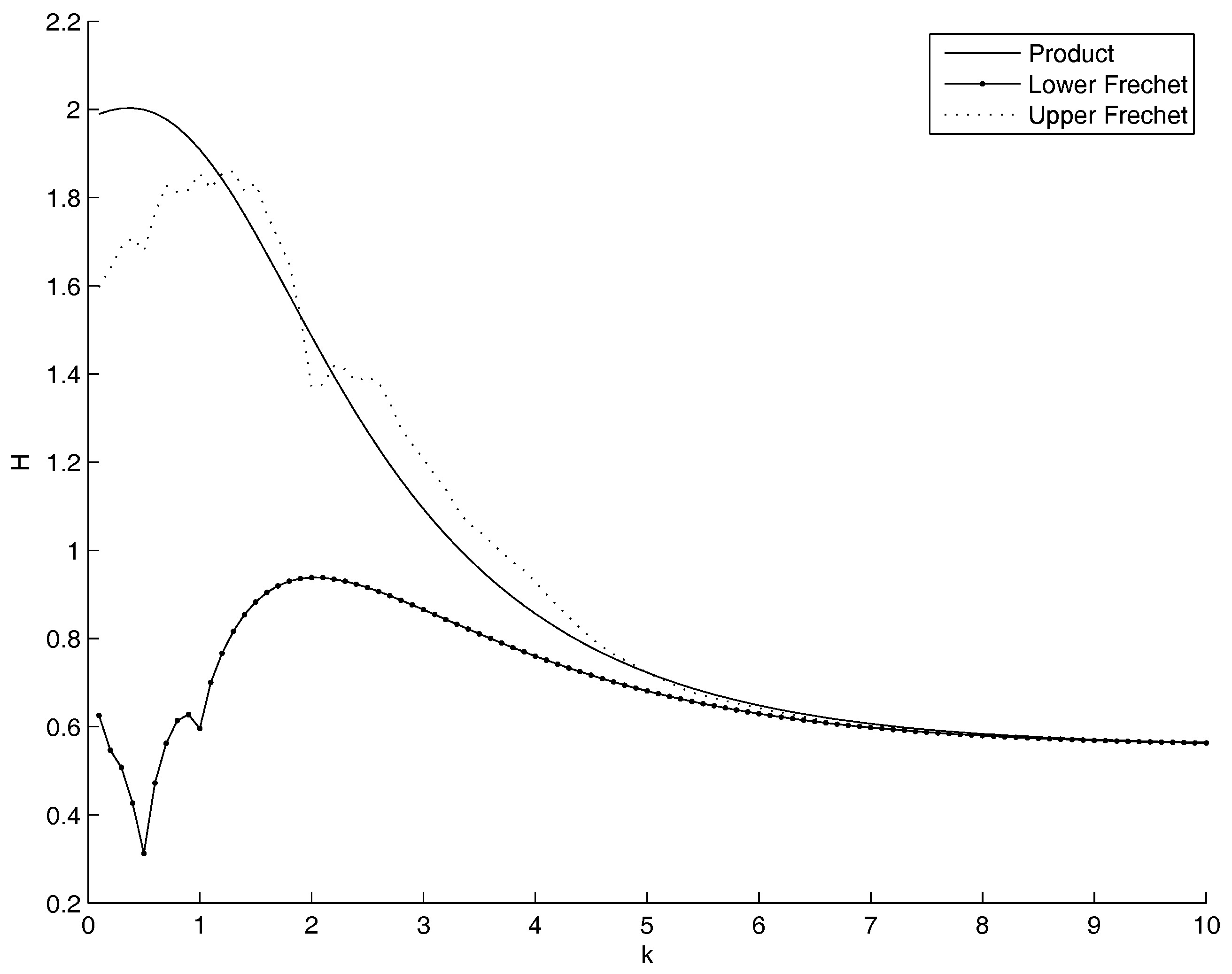
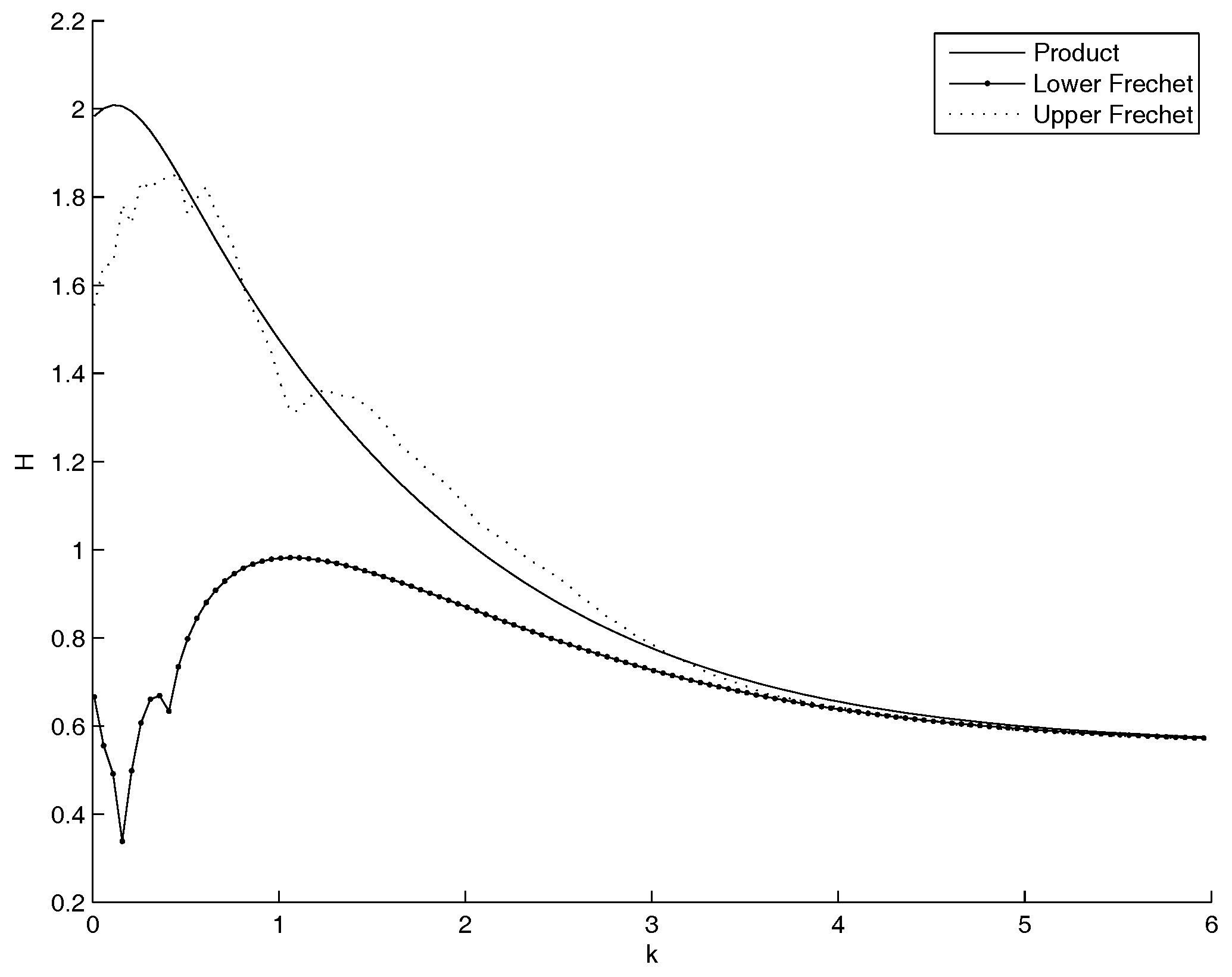
- Non parametric copulas: Figure 5 shows the behavior of the entropy as a function of k. The upper Frechet bound and the product copula are quite overlapped: the entropy increases as k increases. Practically, in the marginal of the entropy is minimal as the mass is pushed to the highest mass concentration of , that is at the left bound of the domain, although it should not become more sharp than the empirical distribution of . This is coherent with the Theorem in the Appendix A, as well as with the very well known fact that the entropy is minimal as the dispersion diminishes and the mass is concentrated. The lower Frechet copula has the opposite behavior. There is no minimum and no maximum internal to the range for k. All the three show a maximum: for and (Product), and (Lower Frechet), and (Upper Frechet). The only maximum in the most interesting range of is the Upper Frechet one. In the Frechet one there is also another local maximum in and and two local minima in and and in and . The other local fluctuations in the Upper Frechet do not lead to other local maxima or minima. All the entropies are decreasing for k increasing.
- Figure 6 shows the entropy function when the exponent of the power law for is allowed to change. Therefore, the marginal distribution is allowd to change, still remaining a power law. The other marginal is given by the case study for . The marginal distributions are combined through the Gumbel copula. The minimum that was detected on the raw data for disappears, and an asymptotic behavior remains: the entropy is decreasing for , i.e., in the case of convergence towards the Frechet upper bound. Therefore, the minimum entropy is obtained either when the copula is the product or when the considered quantities are perfectly positively correlated.Once more, we may remark that the entropy decreases as the concentration of the distribution increases, possibly reaching a Dirac’s delta function. Since the marginal on is fixed, the minimum is obtained when the mass through the other marginal is concentrated on the highest peak of , that is at the left border. This effect is obtained by increasing the steepness of the marginal of . The higher k, the more the mass is concentrated on the left border. This effect is emphasized by the application of the copula. Since both marginals are left-skewed, the product gives the minimum, for quite a range of values of k. However, the entropy is decreasing as , reaching values lower than the minimum, when present. Therefore any concentration limit can be overrun, providing that the slope of the power law is large. We already noted that most systems show a power law with an exponent between 2 and 3. This prevents the rise of concentration.The analysis of the maximum is quite different. As k increases, the maximum is pushed to the left side of the range of , tending to 1 for high values of k, i.e., in the case of independence.
- Frank copula. Also for the Frank copula there are different configurations as the parameters of the power law changes. Figure 7 outlines the situation for (left hand side) and for (right hand side).The Frank copula when gives a result similar to the left part of the second row of the Figure 4: there is no minimum. Moreover, the value of the entropy is increasing as increases. However, for each fixed , the values of the entropy decreases as k increases. If the maximum moves to the right as k increases. There is no minimum, since 0 does not belong to the definition set.
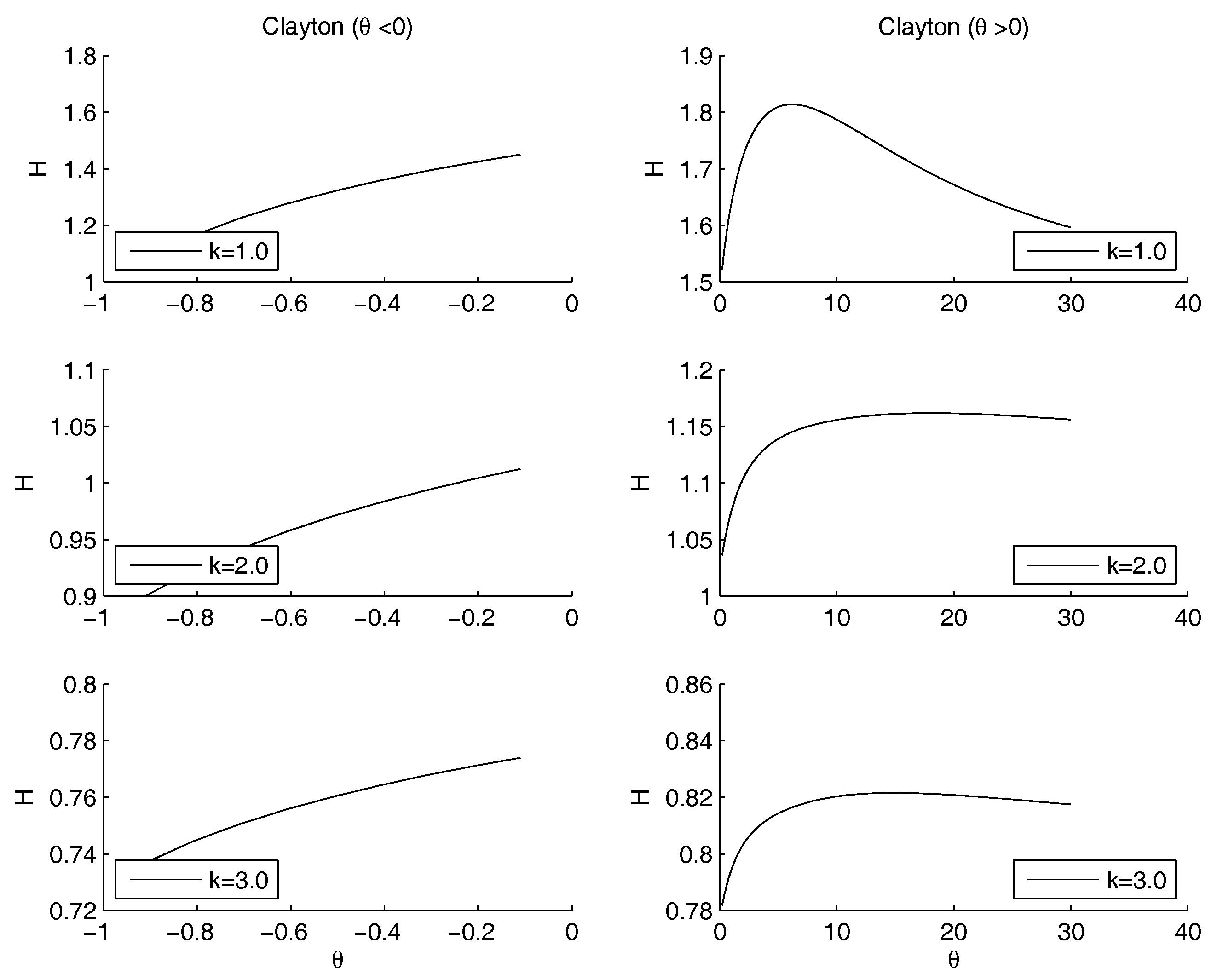
- Clayton copula. Figure 8 shows the situation depending on the parameters of the power law. For , the subplots show that the maximum moves to the right hand side as k increases. There is no minimum, since 0 does not belong to the definition set, there is no minimum. For , there is a minimum for , for any value of k.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Maximum of a Product and Minimum of the Shannon Entropy
Appendix B. Steps 2-5 of case 3
Appendix B.1. Step 2: Power Law for kin, and Raw Data for kout
- Non parametric copulas. The situation is quite similar to Figure 5. The product copula and the Upper Frechet are quite close each to the other. The same comments as for Figure 5 hold. The functions are decreasing as k increases. There are local maxima: in (Product), in (Lower Frechet), in (Upper Frechet). We remark that there are many more small fluctuations, that lead to local minima for the Upper Frechet - although the values of the entropy there is much higher than the value on the tail. In the lower Frechet we remark that the local minima have a different location: for and or . There is also a local maximum in




Appendix B.2. Step 3: Exponential Law for kin, Raw Data for kout
- Non parametric copulas. The situation is quite similar to Figure 5. The product copula and the Upper Frechet are quite close to each other. The same comments as for Figure 5 and Figure A1 hold. The functions are decreasing as k increases. Figure A5 shows the results. There are local maxima: in (Product), in (lower Frechet), in (upper Frechet). We remark that there are many more small fluctuations, that lead to local minima for the upper Frechet—although the values of the entropy there is much higher than the value on the tail. Compared to Figure 9, the local minimum in the upper Frechet at , is much deeper, and could be considered a true local minimum. In the lower Frechet case, we remark that the local minima have a different location: for and or .There is also a local maximum in

- Gumbel Archimedean copula. Figure A6 shows the case. The same comments as for Figures 6 and 10 hold.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
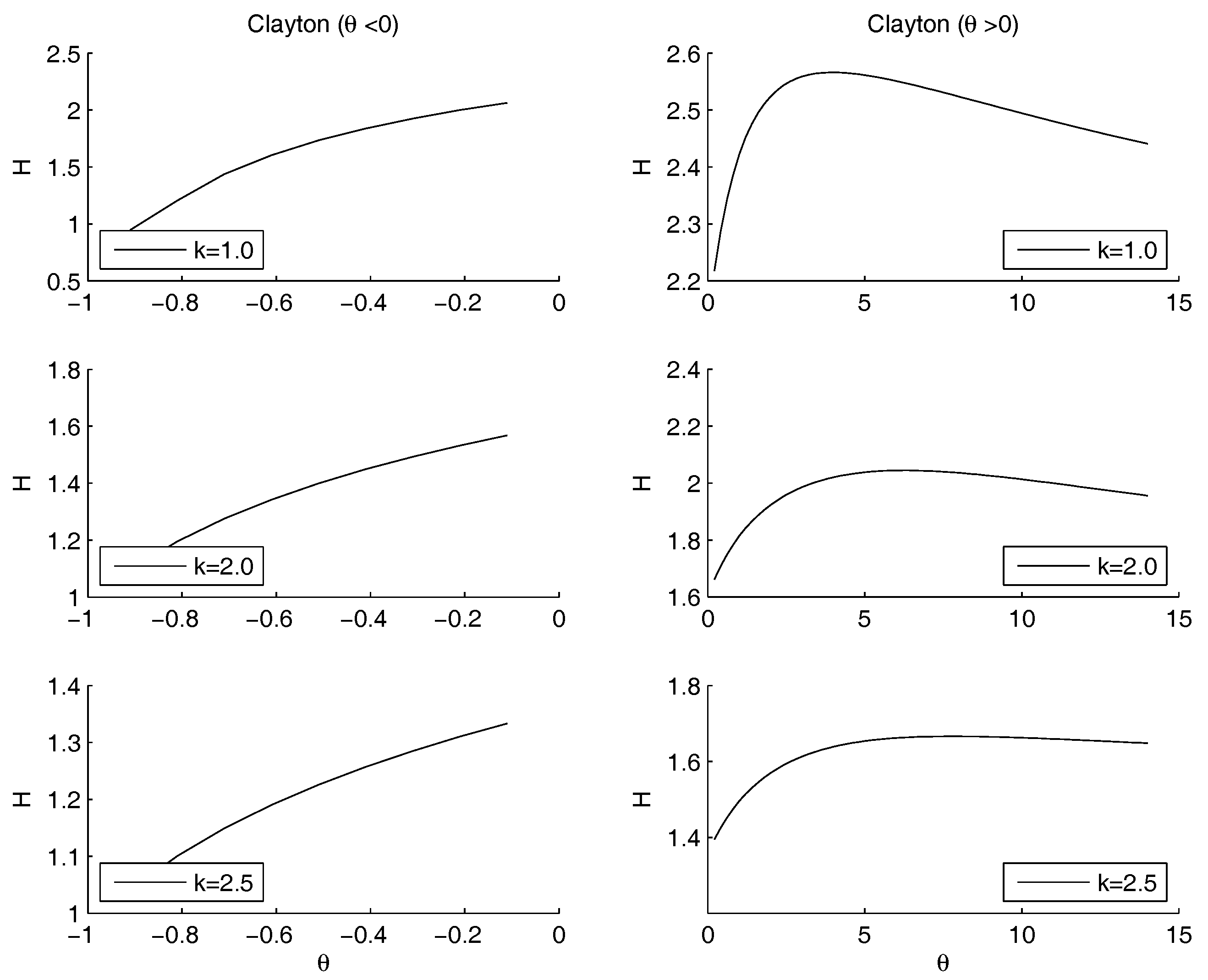{kind=link}
{kind=link}
{kind=link}
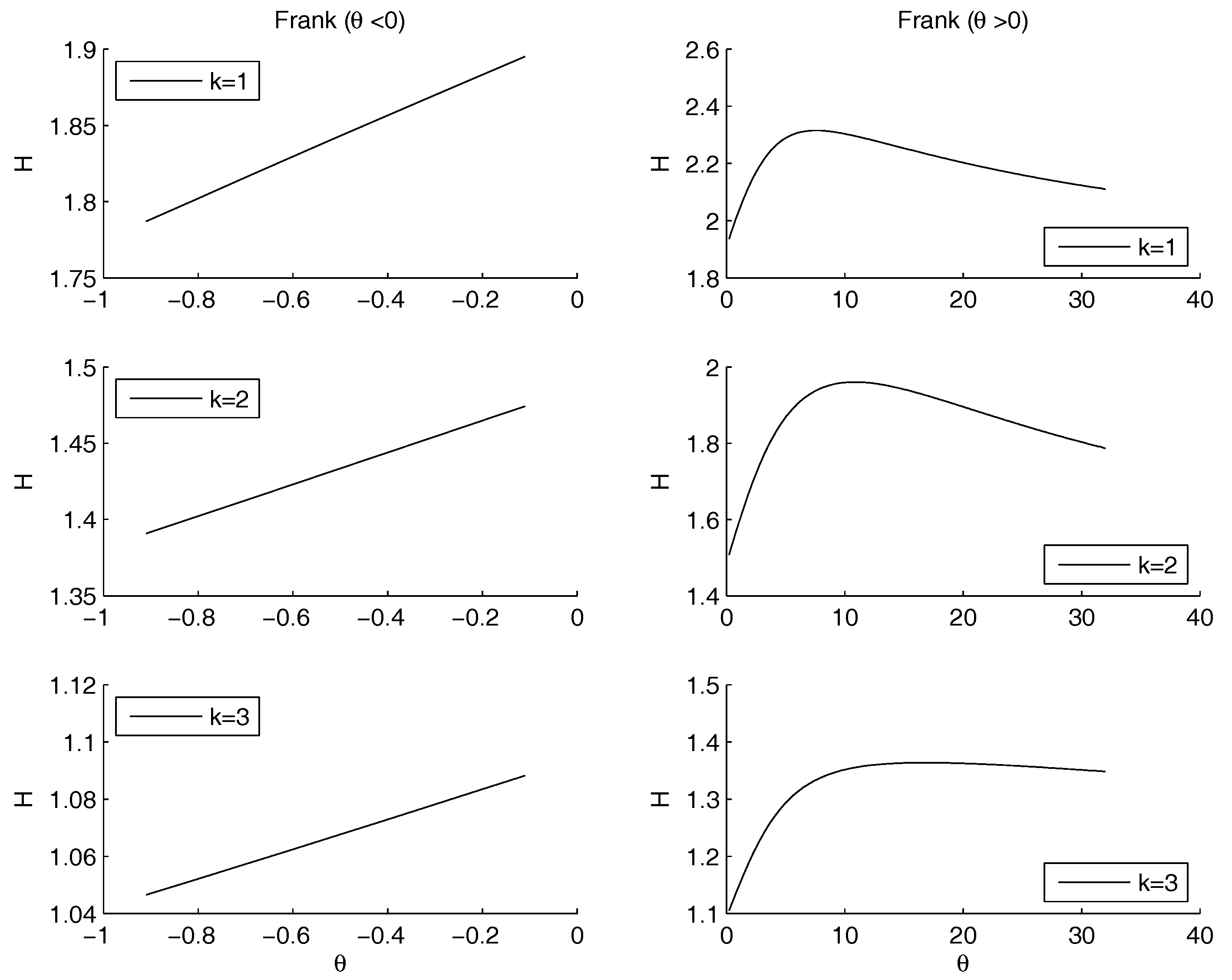{kind=link}
{kind=link}
{kind=link}
{kind=link}
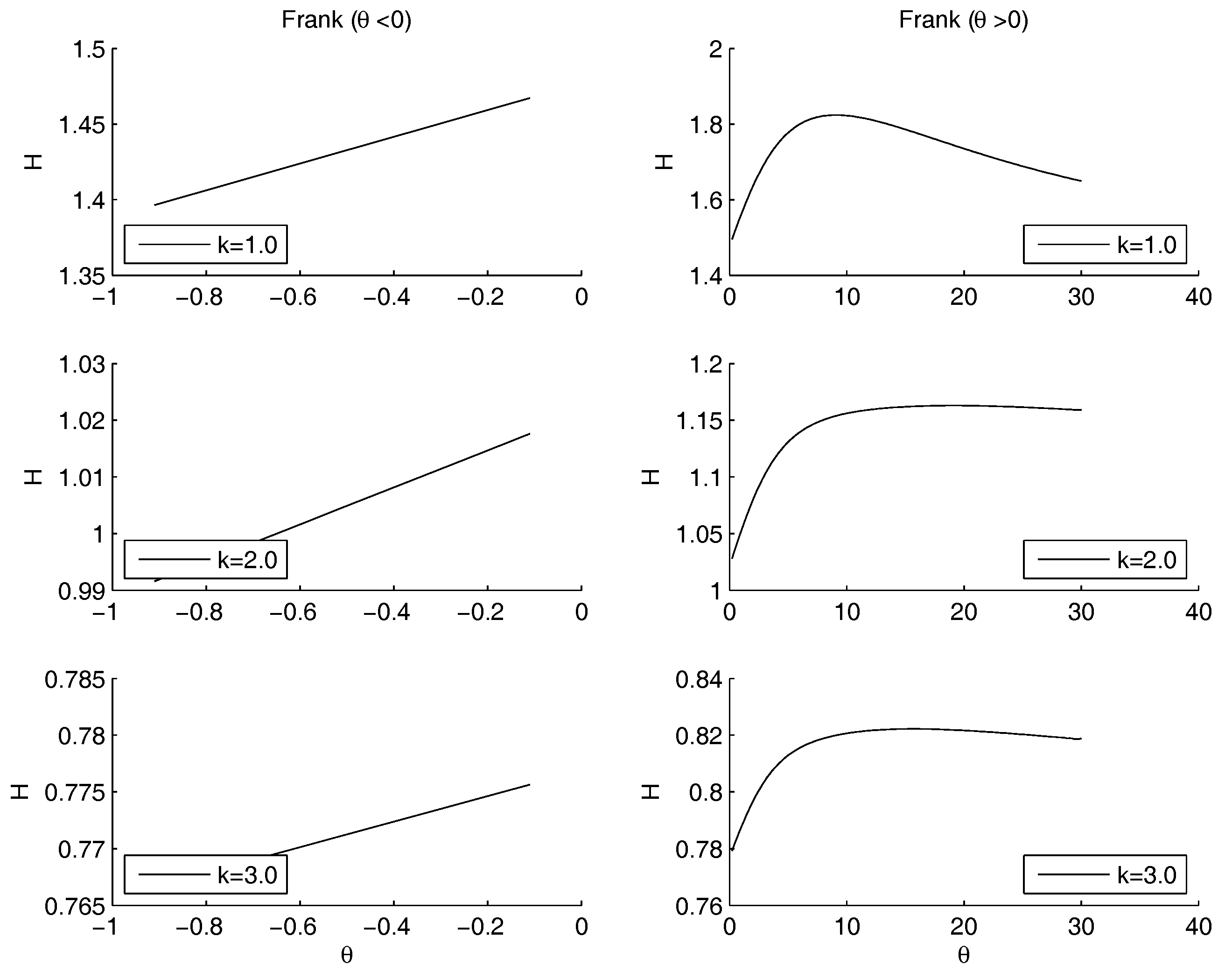{kind=link}
{kind=link}
Appendix B.3. Steps 4 and 5: either Power Law or Exponential Law for kin, and Power Law for kout
References
- Delpini, D.; Battiston, S.; Riccaboni, M.; Gabbi, G.; Pammolli, F.; Caldarelli, G. Evolution of controllability in interbank networks. Sci. Rep. 2013, 3, 1626. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, J.; Barzel, B.; Barabasi, A.L. Universal resilience patterns in complex networks. Nature 2016, 530, 307–312. [Google Scholar] [CrossRef] [PubMed]
- Iori, G.; De Masi, G.; Precup, O.V.; Gabbi, G.; Caldarelli, G. A network analysis of the Italian overnight money market. J. Econ. Dyn. Control 2008, 32, 259–278. [Google Scholar] [CrossRef]
- Newman, M.; Barabasi, A.L.; Watts, D.J. The Structure and Dynamics of Networks; Princeton University Press: Princeton, NJ, USA, 2011. [Google Scholar]
- Soramaki, K.; Bech, M.L.; Arnold, J.; Glass, R.J.; Beyeler, W.E. The topology of interbank payment flows. Physica A 2007, 379, 317–333. [Google Scholar] [CrossRef]
- Aoyama, H.; Fujiwara, Y.; Ikeda, Y.; Iyetomi, H.; Souma, W. Econophysics and Companies: Statistical Life and Death in Complex Business Networks; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Elliott, M.; Golub, B.; Jackson, M.O. Financial networks and contagion. Am. Econ. Review 2014, 104, 3115–3153. [Google Scholar] [CrossRef]
- Bellenzier, L.; Grassi, R. Interlocking directorates in Italy: Persistent links in network dynamics. J. Econ. Interact. Coord. 2014, 9, 183–202. [Google Scholar] [CrossRef]
- Croci, E.; Grassi, R. The economic effect of interlocking directorates in Italy: New evidence using centrality measures. Comput. Math. Org. Theory 2014, 20, 89–112. [Google Scholar] [CrossRef]
- Rotundo, G.; D’Arcangelis, A.M. Network analysis of ownership and control structure in the Italian Stock market. Adv. Appl. Stat. Sci. 2010, 2, 255–273. [Google Scholar]
- Ferraro, G.; Iovanella, A. Technology transfer in innovation networks: An empirical study of the Enterprise Europe Network. Int. J. Eng. Bus. Manag. 2017, 9, 1–14. [Google Scholar] [CrossRef]
- Ceptureanu, S.I.; Ceptureanu, E.G.; Marin, I. Assessing role of strategic choice on organizational performance by Jacquemin–Berry entropy index. Entropy 2017, 19, 448. [Google Scholar] [CrossRef]
- Ferraro, G.; Iovanella, A. Organizing collaboration in inter-organizational innovation networks, from orchestration to choreography. Int. J. Eng. Bus. Manag. 2015, 7. [Google Scholar] [CrossRef]
- Gulati, R.; Westphal, J.D. Cooperative or controlling? The effects of CEO-board relations and the content of interlocks on the formation of joint ventures. Adm. Sci. Q. 1999, 44, 473–506. [Google Scholar] [CrossRef]
- Ceptureanu, E.G.; Ceptureanu, S.I.; Popescu, D. Relationship between Entropy, Corporate Entrepreneurship and Organizational Capabilities in Romanian Medium Sized Enterprises. Entropy 2017, 19, 412. [Google Scholar] [CrossRef]
- Weber, S.; Weske, K. The joint impact of bankruptcy costs, fire sales and cross-holdings on systemic risk in financial networks. Prob. Uncertain. Quant. Risk 2017, 2, 9. [Google Scholar] [CrossRef]
- Silva, T.C.; Alexandre, M.D.S.; Tabak, B.M. Bank lending and systemic risk: A financial-real sector network approach with feedback. J. Financ. Stab. 2017. [Google Scholar] [CrossRef]
- Souza, S.R.S.D.; Silva, T.C.; Tabak, B.M.; Guerra, S.M. Evaluating systemic risk using bank default probabilities in financial networks. J. Econ. Dyn. Control 2016, 66, 54–75. [Google Scholar] [CrossRef]
- Cinelli, M.; Ferraro, G.; Iovanella, A. Rich-club ordering and the dyadic effect: Two interrelated phenomena. Physica A: Statistical Mechanics and its Applications 2018, 490, 808–818. [Google Scholar] [CrossRef]
- Pastor-Satorras, R.; Vespignani, A. Epidemic dynamics and endemic states in complex networks. Phys. Review E 2001, 63, 066117. [Google Scholar] [CrossRef] [PubMed]
- Pastor-Satorras, R.; Vespignani, A. Epidemic spreading in scale-free networks. Phys. Review Lett. 2001, 86, 3200. [Google Scholar] [CrossRef] [PubMed]
- Cinelli, M.; Ferraro, G.; Iovanella, A. Structural bounds on the dyadic effect. J. Complex Netw. 2017, 5, 694–711. [Google Scholar]
- Rotundo, G.; D’Arcangelis, A.M. Ownership and control in shareholding networks. J. Econ. Int. Coord. 2010, 5, 191–219. [Google Scholar] [CrossRef]
- Rotundo, G.; D’Arcangelis, A.M. Network of companies: an analysis of market concentration in the Italian stock market. Qual. Quant. 2014, 48, 1893–1910. [Google Scholar] [CrossRef]
- Joe, H. Multivariate Models and Multivariate Dependence Concepts; CRC Press: Boca Raton, FL, USA, 1997. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas; Springer: Berlin, Germany, 1999. [Google Scholar]
- Sklar, M. Fonctions de repartition an dimensions et leurs marges. Publ. Inst. Statist. Univ. Paris 1959, 8, 229–231. (In French) [Google Scholar]
- US Mergers Guidelines. Available online: http://www.stanfordlawreview.org/online/obama-antitrust-enforcement (accessed on 18 February 2018).
- Frechet, M. Remarques au sujet de la note precedente. C.R. Acad. Sci. Paris 1958, 246, 2719–2720. [Google Scholar]
- Clayton, D.G. A model for association in bivariate life tables and its application in epidemiological studies of familial tendency in chronic disease incidence. Biometrika 1978, 65, 141–151. [Google Scholar] [CrossRef]
- Frank, M.J. On the simultaneous associativity of F(x, y) and x + y − F(x, y). Aequ. Math. 1979, 19, 194–226. [Google Scholar] [CrossRef]
- Gumbel, E.J. Bivariate exponential distributions. J. Amer. Statist. Assoc. 1960, 55, 698–707. [Google Scholar] [CrossRef]
- Ling, C.H. Representation of associative functions. Publ. Math. Debrecen 1965, 12, 189–212. [Google Scholar]
- Caldarelli, G. Scale-Free Networks: Complex Webs in Nature and Technology; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Cimini, G.; Serri, M. Entangling credit and funding shocks in interbank markets. PloS ONE 2016, 11, e0161642. [Google Scholar] [CrossRef] [PubMed]
- Gandy, A.; Veraart, L.A.M. A Bayesian Methodology for Systemic Risk Assessment in Financial Networks. Manag. Sci. 2016, 63, 4428–4446. [Google Scholar] [CrossRef] [Green Version]
- Serri, M.; D’Arcangelis, A.M.; Rotundo, G. Systemic Risk of NPLs Market. The Italian case. Unpublished work.
- Feller, W. An Introduction to Probability Theory and its Applications II, 2nd ed.; Wiley: New York, NY, USA, 1971. [Google Scholar]
- Zambrano, E.; Hernando, A.; Fernández Bariviera, A.; Hernando, R.; Plastino, A. Thermodynamics of firms’ growth. J. R. Soc. Interface 2015, 12, 20150789. [Google Scholar] [CrossRef] [PubMed]
- Souma, W.; Fujiwara, Y.; Aoyama, H. Change of ownership networks in Japan. In Practical Fruits of Econophysics; Springer: Berlin, Germany, 2005; pp. 307–311. [Google Scholar]
- Souma, W.; Fujiwara, Y.; Aoyama, H. Shareholding Networks in Japan. Available online: http://aip.scitation.org/doi/abs/10.1063/1.1985396 (accessed on 18 February 2018).
- Garlaschelli, D.; Battiston, S.; Castri, M.; Servedio, V.; Caldarelli, G. The scale-free topology of market investments. Physica A 2005, 350, 491–499. [Google Scholar] [CrossRef]
- D’Errico, M.; Grassi, R.; Stefani, S.; Torriero, A. Shareholding Networks and Centrality: An Application to the Italian Financial Market. In Networks, Topology and Dynamics; Springer: Berlin, Germany, 2009; pp. 215–228. [Google Scholar]
- Chang, X.; Wang, H. Cross-Shareholdings Structural Characteristic and Evolution Analysis Based on Complex Network. Discret. Dyn. Nat. Soc. 2017, 5, 1–7. [Google Scholar]
- Li, H.; Fang, W.; An, H.; Yan, L. The shareholding similarity of the shareholders of the worldwide listed energy companies based on a two-mode primitive network and a one-mode derivative holding-based network. Physica A 2014, 415, 525–532. [Google Scholar] [CrossRef]
- Ma, Y.; Zhuang, X.; Li, L. Research on the relationships of the domestic mutual investment of China based on the cross-shareholding networks of the listed companies. Physica A 2011, 390, 749–759. [Google Scholar] [CrossRef]
- Li, H.; An, H.; Gao, X.; Huang, J.; Xu, Q. On the topological properties of the cross-shareholding networks of listed companies in China: Taking shareholders’ cross-shareholding relationships into account. Physica A 2014, 406, 80–88. [Google Scholar] [CrossRef]
- Vitali, S.; Glattfelder, J.B.; Battiston, S. The network of global corporate control. PLoS ONE 2011, 6, e25995. [Google Scholar] [CrossRef] [PubMed]
- Chapelle, A.; Szafarz, A. Controlling Firms Through the Majority Voting Rule. Physica A 2005, 355, 509–529. [Google Scholar] [CrossRef]
- Rachev, S.T. Probability Matrices and the Stability of Stochastic Models; Wiley: New York, NY, USA, 1991. [Google Scholar]
- Liese, F.; Vajda, I. Convex Statistical Distances; B.G. Teubner Verlagsgesellschaft: Leipzig, Germany, 1987. [Google Scholar]
- Schellhase, C. Density and Copula Estimation Using Penalized Spline Smoothing. Available online: https://d-nb.info/1026680123/34 (accessed on 18 February 2018).
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Champaign, IL, USA, 1949. [Google Scholar]
- Clementi, F.; Gallegati, M. Pareto’s law of income distribution: Evidence for Germany, the United Kingdom, and the United States. In Econophysics of wealth distributions; Springer: Berlin, Germany, 2005; pp. 3–14. [Google Scholar]








© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cerqueti, R.; Rotundo, G.; Ausloos, M. Investigating the Configurations in Cross-Shareholding: A Joint Copula-Entropy Approach. Entropy 2018, 20, 134. https://doi.org/10.3390/e20020134
Cerqueti R, Rotundo G, Ausloos M. Investigating the Configurations in Cross-Shareholding: A Joint Copula-Entropy Approach. Entropy. 2018; 20(2):134. https://doi.org/10.3390/e20020134
Chicago/Turabian StyleCerqueti, Roy, Giulia Rotundo, and Marcel Ausloos. 2018. "Investigating the Configurations in Cross-Shareholding: A Joint Copula-Entropy Approach" Entropy 20, no. 2: 134. https://doi.org/10.3390/e20020134
APA StyleCerqueti, R., Rotundo, G., & Ausloos, M. (2018). Investigating the Configurations in Cross-Shareholding: A Joint Copula-Entropy Approach. Entropy, 20(2), 134. https://doi.org/10.3390/e20020134