1. Introduction
In the last years digital systems became the standard in all experimental sciences. By using new programmable electronic devices such as DSP’s, ASIC’s or FPGA’s, experimenters are allowed to design and modify their own signal generators, measuring systems, simulation models, etc.
Nowdays, the chaotic systems are widely used in digital electronics in fields such as electromagnetic compatibility, encrypted secure communications, controlled noise generators, etc. [
1,
2,
3,
4,
5]. These systems are specially interesting due to their extreme sensibility to initial conditions, nevertheless this characteristic is the source of the main difficulties at the time to implement them. In these fields the motivation of using chaotic systems is to genetrate sequences that meet certain requirements, rather than reproducing an exact replica of the real systems.
When a chaotic system is implemented in computers or any digital device, the chaotic attractor become periodic by the effect of finite precision, then only pseudo chaotic attractors can be generated [
6,
7]. Discretization may even destroy the pseudo chaotic behavior and consequently is a non trivial process [
3,
8].
In these new devices, floating- and fixed-point are the most common arithmetics. Floating-point is the more accurately solution but is not always recommended when speed, low power and/or small circuit area are required. A fixed-point solution is better in these cases, nevertheless the feasibility of their implementation needs to be investigated.
The effect of numerical discretization over a chaotic map was recently addressed in [
3,
9,
10,
11]. In our previous work [
3] we have explored the statistical degradation of the phases’ space for a family of 2D quadratic maps. These maps present a multiatractor dynamic that makes them very attractive as random number generator in fields like criptography, encoding, etc. Nepomuceno et al. [
9] reported the existence of more than one pseudo-orbit of continuous chaotic systems when it is discretizated using different schemes. In [
10] and [
11], authors have proposed to use the value of the entropy to choose the number of bits in the fractional part, when maps are implemented in integer arithmetic.
Grebogi and coworkers [
12] saw that the period
T scales with roundoff
as
where
d is the correlation dimension of the chaotic attractor. This issue was also addressed in [
13], in this paper authors explore the evolution on the period
T as consequence of roundoff induced by 2-based numerical representation. To have a large period
T is an important property of chaotic maps, in [
14] Nagaraj et al. studied the effect of switching over the average period lengths of chaotic maps in finite precision. They saw that the period
T of the compound map obtained by switching between two chaotic maps is higher than the period of each map. Liu et al. [
15] studied different switching rules applied to linear systems to generate chaos. Switching issue was also addressed in [
16], the author considered some mathematical, physical and engineering aspects related to singular, mainly switching systems. Switching systems naturally arise in power electronics and many other areas in digital electronics. They have also interest in transport problems in deterministic ratchets [
17] and it is known that synchronization of the switching procedure affects the output of the controlled system. Chiou and Chen [
18] published an analysis of the stabilization and switching laws to design switched discrete-time systems. Recently, Borah et al. [
19] presented a family of new chaotic systems and a switching based synchronization strategy.
Stochasticity and mixing are relevant to characterize a chaotic behavior. To investigate these properties several quantifiers were studied [
20]. Entropy and complexity from information theory were applied to give a measure for causal and non causal entropy and causal complexity.
A fundamental issue is the criterium to select the probability distribution function (PDF) assigned to the time series, causal and non causal options are possible. Here we consider the non causal traditional PDF obtained by normalizing the histogram of the time series. Its statistical quantifier is the normalized entropy
that is a measure of equiprobability among all allowed values. We also considered a causal PDF that is obtained by assigning ordering patterns to segments of trajectory of length
D. This PDF was first proposed by Bandt & Pompe in a seminal paper [
21], the corresponding entropy
was also proposed as a quantifier by Bandt & Pompe. In [
22] authors applied the causal complexity
to detect chaos. Among them the use of an entropy-complexity representation (
plane) and causal-non causal entropy (
plane) deserves special consideration [
20,
22,
23,
24,
25,
26].
Recently, amplitude information was introduced in [
27] to add some immunity to weak noise in a causal PDF. The new scheme better tracks abrupt changes in the signal and assigns less complexity to segments that exhibit regularity or are subject to noise effects. Then, we define the causal entropy with amplitude contributions
and the causal complexity with amplitude contributions
. Also, we introduce the modified planes
and
.
Amigó and coworkers proposed the number of forbidden patterns as a quantifier of chaos [
28]. Essentially they reported the presence of forbidden patterns as an indicator of chaos. Recently it was shown that the name forbidden patterns is not convenient and it was replaced by missing patterns (MP) [
29], in this work authors showed that there are chaotic systems that present MP from a certain minimum length of patterns. Our main interest on MP is because it gives an upper bound for causal quantifiers.
Following [
14], in this paper we study the statistical characteristics of five maps, two well known maps: (1) the tent (TENT) and (2) logistic (LOG) maps, and three additional maps generated from them: (3) SWITCH, generated by switching between TENT and LOG; (4) EVEN, generated by skipping all the elements in odd positions of SWITCH time series and (5) ODD, generated by discarding all the elements in even positions of SWITCH time series. Binary floating- and fixed-point numbers are used, these specific numerical systems may be implemented in modern programmable logic devices.
The main contribution of this paper is the study of how different statistical quantifiers detect the evolution of stochasticity and mixing of the chaotic maps according as the numerical precision varies. To illustrate this sequences generated by well known maps were used, and also sequences obtained by randomization methods like skipping and switching.
Organization of the paper is as follows:
Section 2 describes the statistical quantifiers used in the paper and the relationship between their value and the characteristics of the causal and non causal PDF’s considered;
Section 3 shows and discusses the results obtained for all the numerical representations. Finally
Section 4 deals with final remarks and future work.
2. Information Theory Quantifiers
Systems that evolve over time are called dynamical systems. Generally, only measurements of scalar time series are accessible, these time series may be function of variables describing the underlying dynamics (i.e., ). The goal is to infer properties and reach conclusions of an unknown system from the analysis of measured record of observational data. The key question would be to know how much information about the dynamics of the underlying processes can be revealed by the analysed data. A probability distribution function (PDF) P is typically used to quantify the apportionment of a time series . Information Theory quantifiers can be defined as measures that characterize properties of the PDF associated with these time series, they allow to extract information about the studied system. We can see these quantifiers as metrics in the PDFs space, they enable to compare and classify different sets of data according to their PDFs where stochastic and deterministic are the two extremes of processes.
Here, we are concerned in chaotic dynamics, which are fundamentally causal and statistical in nature. For this reason, we are forced to use a different approach since a purely statistical approach ignores the correlations between successive values from the time series; and a causal approach focuses on the PDFs of data sequences.
The selected quantifiers are based on symbolic counting and ordinal pattern statistics. They make it possible to distinguish between the two main features: the information content of data and their complexity. It is important to highlight that rather than referring to a physical space, here we talk about a space of probability density functions.
In this section, we will introduce Information Theory quantifiers defined over discrete PDFs since discrete time series is our scope. Nevertheless, in [
30] definitions for the continuous case can be found.
2.1. Shannon Entropy and Statistical Complexity
Entropy is a measure of the uncertainty associated with a physical process that is described by
P. The Shannon entropy is considered as the most natural one [
30] when dealing with information content.
Let define a discrete probability distribution
with
, were
N is the number of possible states of the system under study. Then, Shannon’s logarithmic information measure:
When
, the prediction of which outcome
i will occur is a complete certainty. In this case, it is maximal the knowledge of the underlying process described by the probability distribution. On the contrary, we have minimal knowledge in a case of a uniform distribution
since every outcome has the same probability of occurrence, and the uncertainty is maximal, i.e.,
. These two situations are extreme cases, therefore we focus on the ‘normalized’ Shannon entropy,
, given as
On the other hand, there is not a unique definition of the concept of complexity. In this paper, the aim is to describe the complexity of the time series rather than that of the underlying systems. As stated by Kantz [
31], complex data might be generated by “simple” systems, while “complicated” models can generate low complexity outputs. A quantitative complexity can be defined as a measure that assigns low values both to uncorrelated random data (maximal Shannon entropy) and also to perfectly ordered data (null Shannon entropy). Then, if we have an ordered sequence, such as a simple oscillation or trend, the statistical complexity would be low, and the same would happen with an unordered sequence, such as uncorrelated white noise. In the middle of this situation the characterization of data is more difficult hence the complexity would be higher.
We look forward a quantifier functional of a PDF,
, in order to measure the degree of complexity or of correlational structures. As depicted in [
32] the functional is relate to organization, correlational structure, memory, regularity, symmetry, patterns, and other properties.
Rosso and coworkers [
33] introduced a suitable
Statistical Complexity Measure (SCM)
C, that is based on the seminal notion advanced by López-Ruiz et al. [
34]. SCM is defined as the product of a measure of information and a measure of disequilibrium and it is able to detect the distance from the equiprobable distribution of the accessible states.
This statistical complexity measure [
33,
35] is defined as follows:
H is the normalized Shannon entropy, see Equation
2, and
is the disequilibrium defined in terms of the Jensen–Shannon divergence
, [
36]. That is,
is a normalization constant such that
:
This value is obtained in a totally deterministic situation, where only one components of P has a no null value equal to one.
Note that the above introduced SCM depends on two different probability distributions: one associated with the system under analysis,
P, and the other with the uniform distribution,
. Furthermore, it was shown that for a given value of
H, the range of possible
C values varies between a minimum
and a maximum
, restricting the possible values of the SCM [
37]. Thus, it is clear that important additional information related to the correlational structure between the components of the physical system is provided by evaluating the statistical complexity measure.
2.2. Determination of a Probability Distribution
The evaluation derived from the Information Theory quantifiers suppose some prior knowledge about the system; specifically for those previously introduced (Shannon entropy and statistical complexity), a probability distribution associated to the time series under analysis should be provided before. The determination of the most adequate PDF is a fundamental problem because the PDF P and the sample space are inextricably linked. Usual methodologies assign to each value of the series (or non-overlapped set of consecutive values) a symbol from a finite alphabet , thus creating a symbolic sequence that can be regarded to as a non causal coarse grained description of the time series under consideration. In this case, information on the dynamics of the system is lost, such as order relations and the time scales.
If we want to incorporate
Causal information we have to add information about the past dynamics of the system, this is done by the assignment of symbols of alphabet
A to a portion of the trajectory. The Bandt and Pompe (BP) [
21] method is a simple and robust methodology that compares neighboring values in a time series and, thus solves this issue. The causality property of the PDF allows quantifiers (based on this PDFs) to discriminate between deterministic and stochastic systems [
38]. The steps are, first it is needed to create symbolic data by ranking the values of the series; and second to define by reordering the embedded data in ascending order. This last step is the same to make a phase space reconstruction, using embedding dimension
D (pattern length) and time lag
. The goal of quantifying the diversity of the ordering symbols is achieved. There is no need to perform model-based assumptions, because the appropriate symbol sequence arises naturally from the time series.
The procedure is the following:
Given a series
, a sequence of vectors of length
D is generated.
Each vector turns out to be the “history” of the value . Clearly, the longer the length of the vectors D, the more information about the history would the vectors have but a higher value of N is required to have an adequate statistics.
The permutations
of
are called “order of patterns” of time
t, defined by:
In order to obtain an unique result it is considered
if
. In this way, all the
possible permutations
of order
D, and the PDF
is defined as:
In the last expression the ♯ symbol denotes cardinality.
From the time series an ordinal pattern probability distribution
is extracted. For this, a unique symbol
is obtained from the vector defined by Equation (
8). For uniqueness,
if
is defined. With the following stationary assumption: for
, the probability for
should not depend on
t need to be met for the applicability of the BP method. Regarding the selection of the parameters, Bandt and Pompe suggested working with
for typical time series lengths, and specifically considered a time lag
in their cornerstone paper.
Recently, the permutation entropy was extended to incorporate amplitude information. In order to avoid the loss of amplitude information, that would be a disadvantage of ordinal pattern statistics, weights are introduced to obtain a “weighted permutation entropy (WPE)” [
27]. Non-normalized weights are computed for each temporal window for the time series
X, such that
In the equation above denotes the arithmetic mean of the current embedding vector of length D and its variance is then used to weight the relative frequencies of each ordinal pattern . Originally, this technique was proposed to discriminate patterns immersed in low noise. We take advantage of the fact that the fixed points are not computed in the WPE.
We calculated the normalized permutation Shannon entropy H and the statistical complexity C from these PDFs, and the obtained values are denoted as:
, is the normalized Shannon entropy applied to non-causal PDF ;
, is the normalized Shannon entropy applied to causal PDF ;
, is the normalized Shannon entropy applied to causal PDF with amplitude contribution ;
, is the normalized statistical complexity applied to causal PDF ;
, is the normalized statistical complexity applied to causal PDF with amplitude contribution .
2.3. Information Planes
A particularly useful visualization of the quantifiers from Information Theory is their juxtaposition in two-dimensional graphs. These diagnostic tools were shown to be particularly efficient to distinguish between the deterministic chaotic and stochastic nature of a time series since the permutation quantifiers have distinct behaviors for different types of processes. Four information planes are defined:
Causal entropy vs. non-causal entropy, ;
Causal entropy with amplitude contributions vs. non-causal entropy, ;
Causal causal complexity vs. causal entropy, ;
Causal causal complexity with amplitude contributions vs. causal entropy with amplitude contributions, .
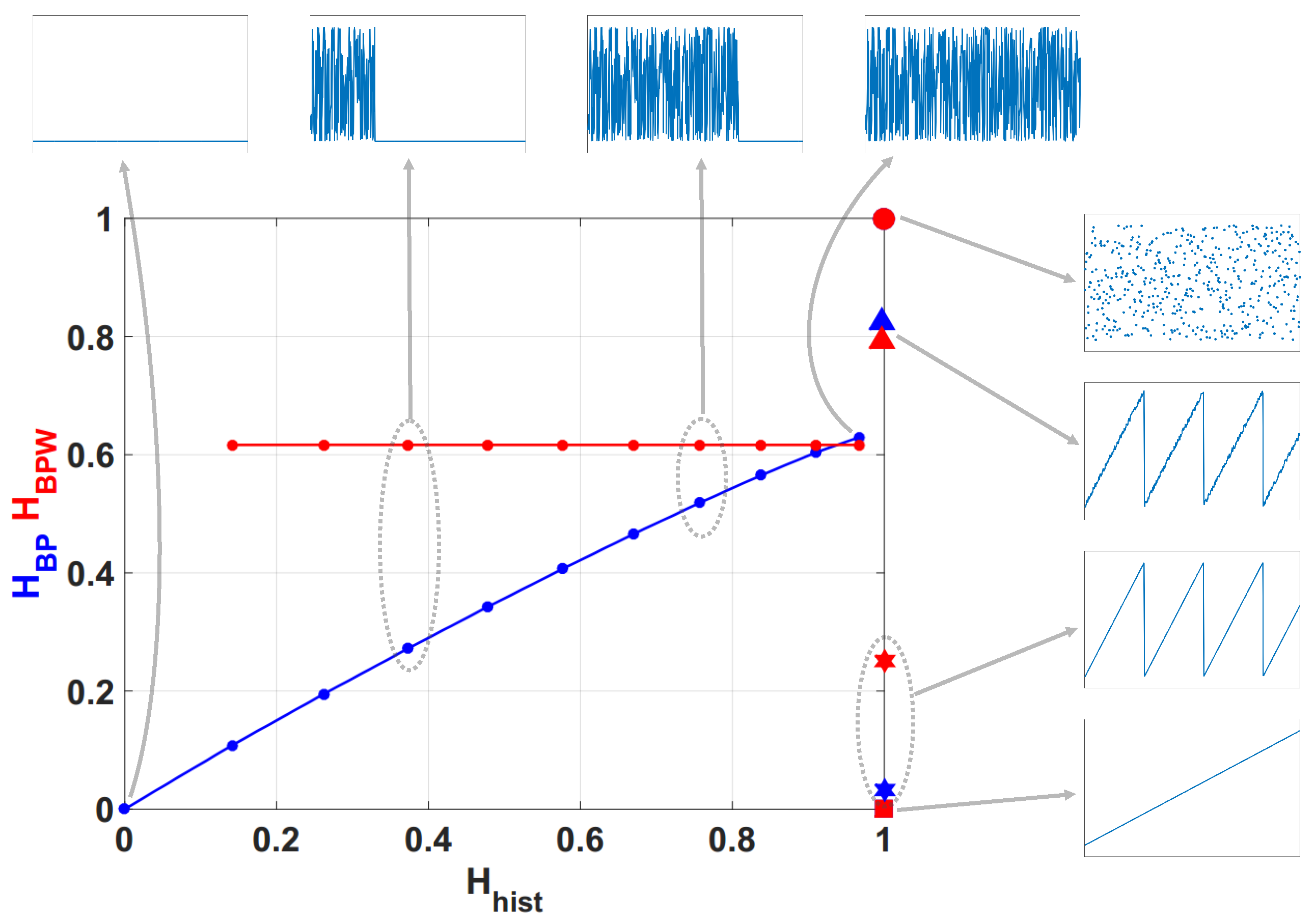
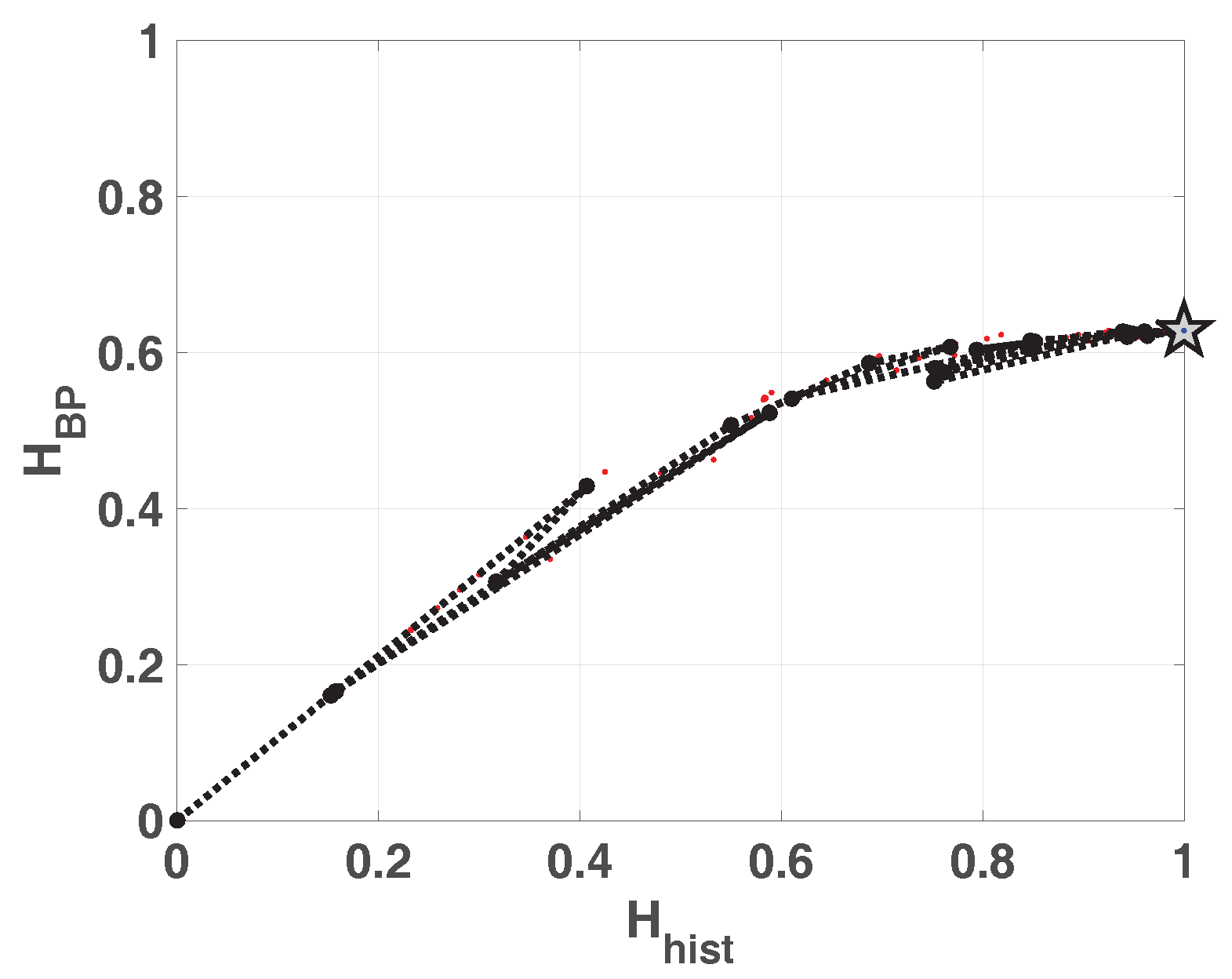
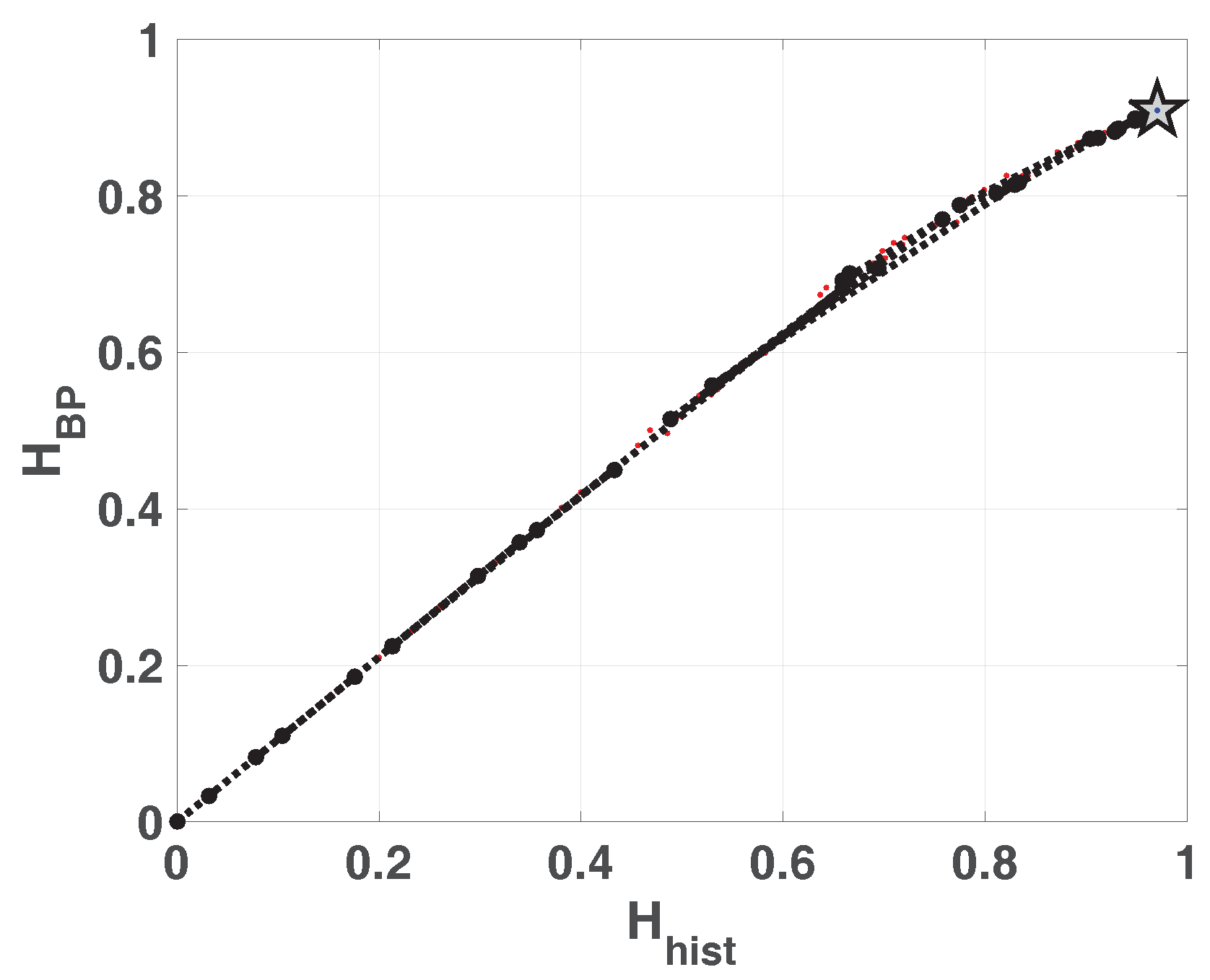
In
Figure 1 we show the planes
and
overlapped. In the resulting plane a higher value in any of the entropies,
,
or
, implies a more uniformity in the involved PDF. The point
represents the ideal case with uniform histogram and uniform distribution of ordering patterns. We show some relevant points as example. Ideal white random sequences with uniform distribution gives a point at
represented by a blue circle, a red circle in the same position shows the results when amplitude contributions are included
. If we sort the vector generated by ideal white random generator in an ascendant way, resulting points are shown by a blue square
and a red square
, in both cases the squares are overlapped at point
this example illustrates the complementarity of the information provided by
and
.
Blue and red stars show and respectively, applied to a sawtooth signal. Values are perfectly distributed in all interval but only a few ordering patterns appear, this explains the high and low . The frequency of occurrence of low amplitude patterns is higher than the one of high amplitude patterns, then the PDF with amplitude contributions is more uniform and is a little higher than . When sawtooth signal is contaminated with white noise and are increased as shown with blue and red triangles. Clearly, new ordering patterns appear and both and show higher values than non-contaminated case. However the growth of is smaller than showing that the technique of recording amplitude contributions adds some immunity to noise.
Finally, we evaluated the quantifiers for a sequence of a logistic map that converges to a fixed point, in all cases the length of data vector remains constant and the length of transitory is variable. Results obtained without amplitude contributions are depicted in blue dots, they converge to as the length of transitory is shorter, however (in red points) remains constant for all the cases. The last point in corresponds to a vector of zeros, in this case the histogram of ordering patterns with amplitude contributions is also a zero vector and can not be calculated. Through this last example, we show that the convergence to a fixed point can be detected by the join information of and .
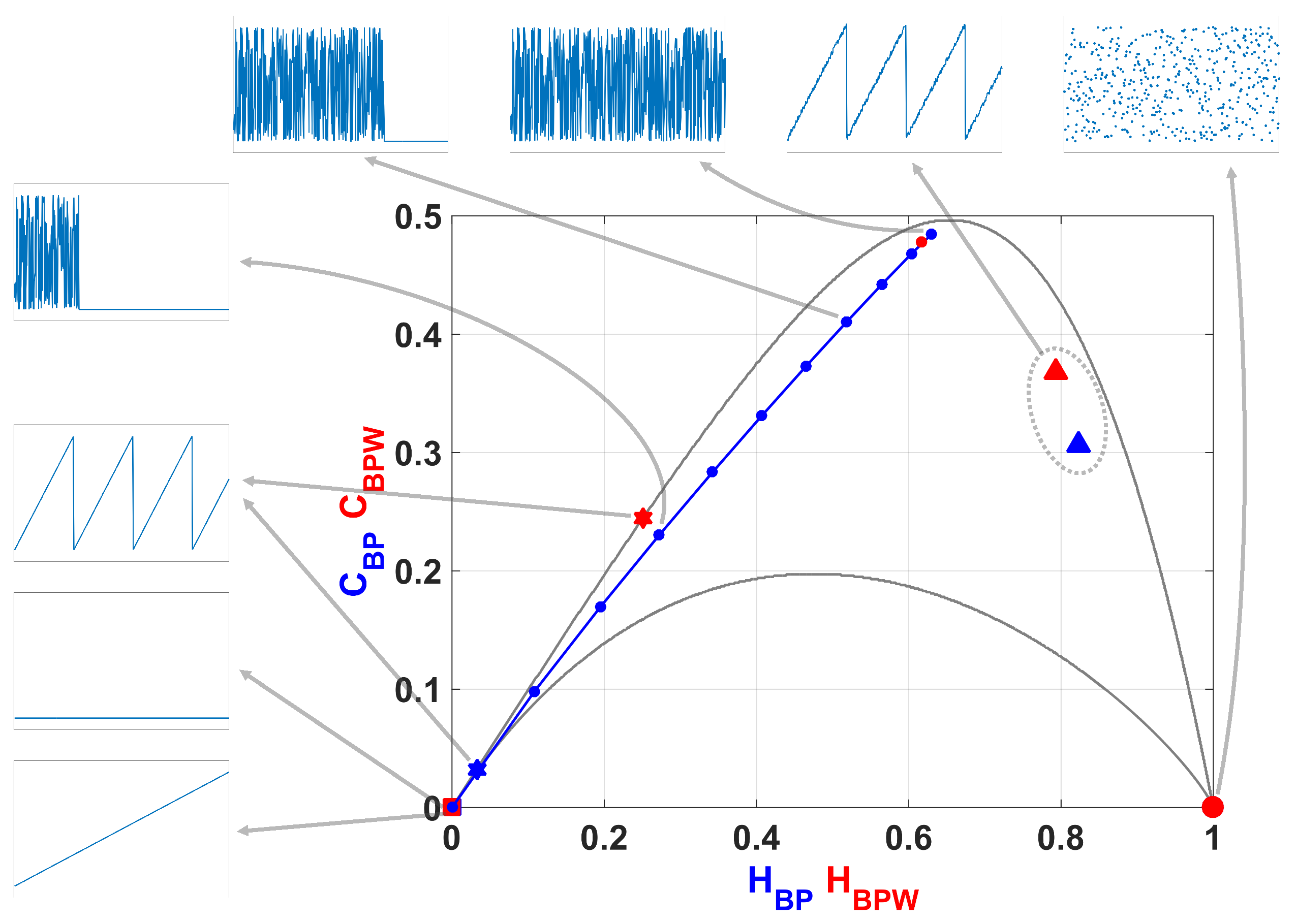
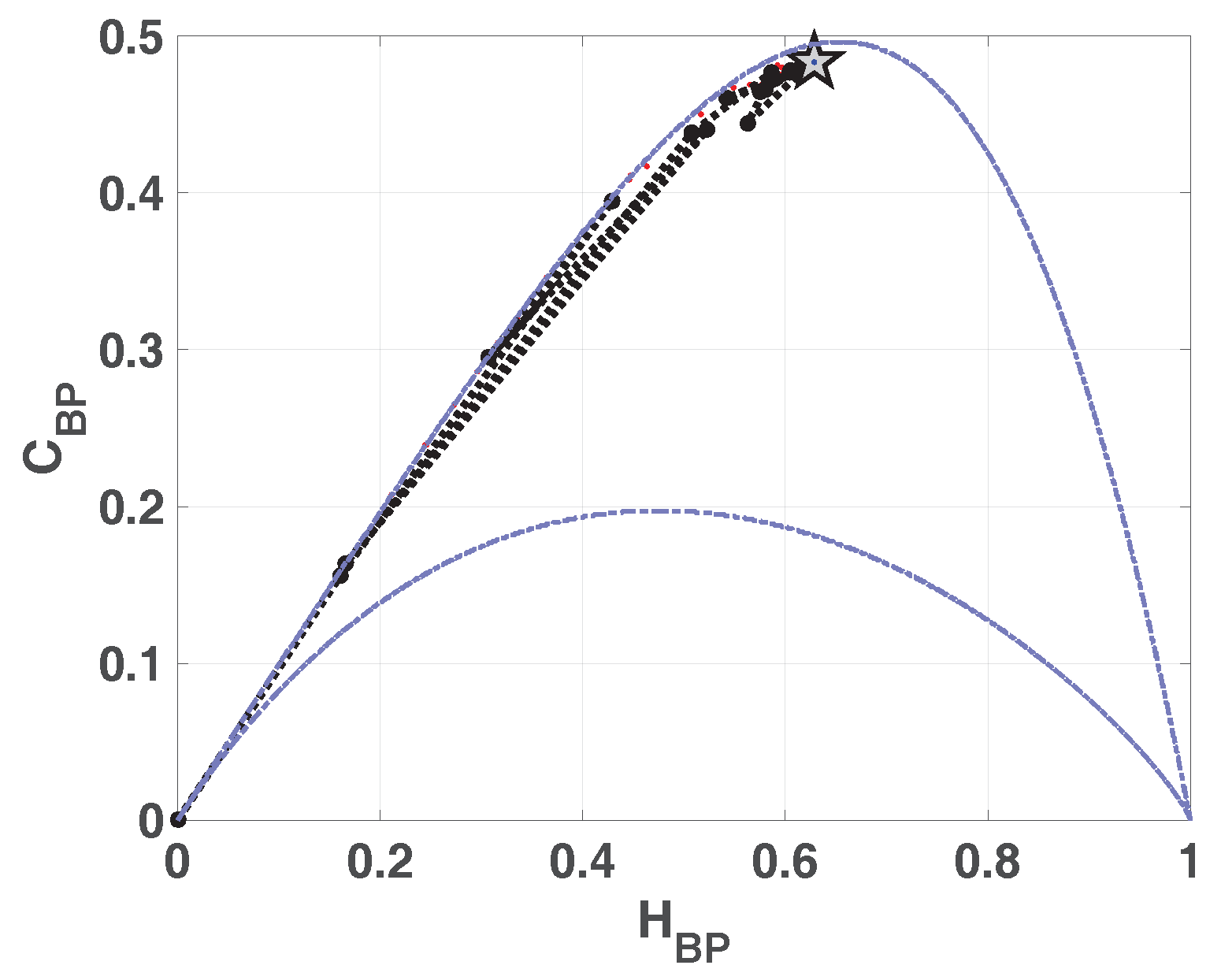
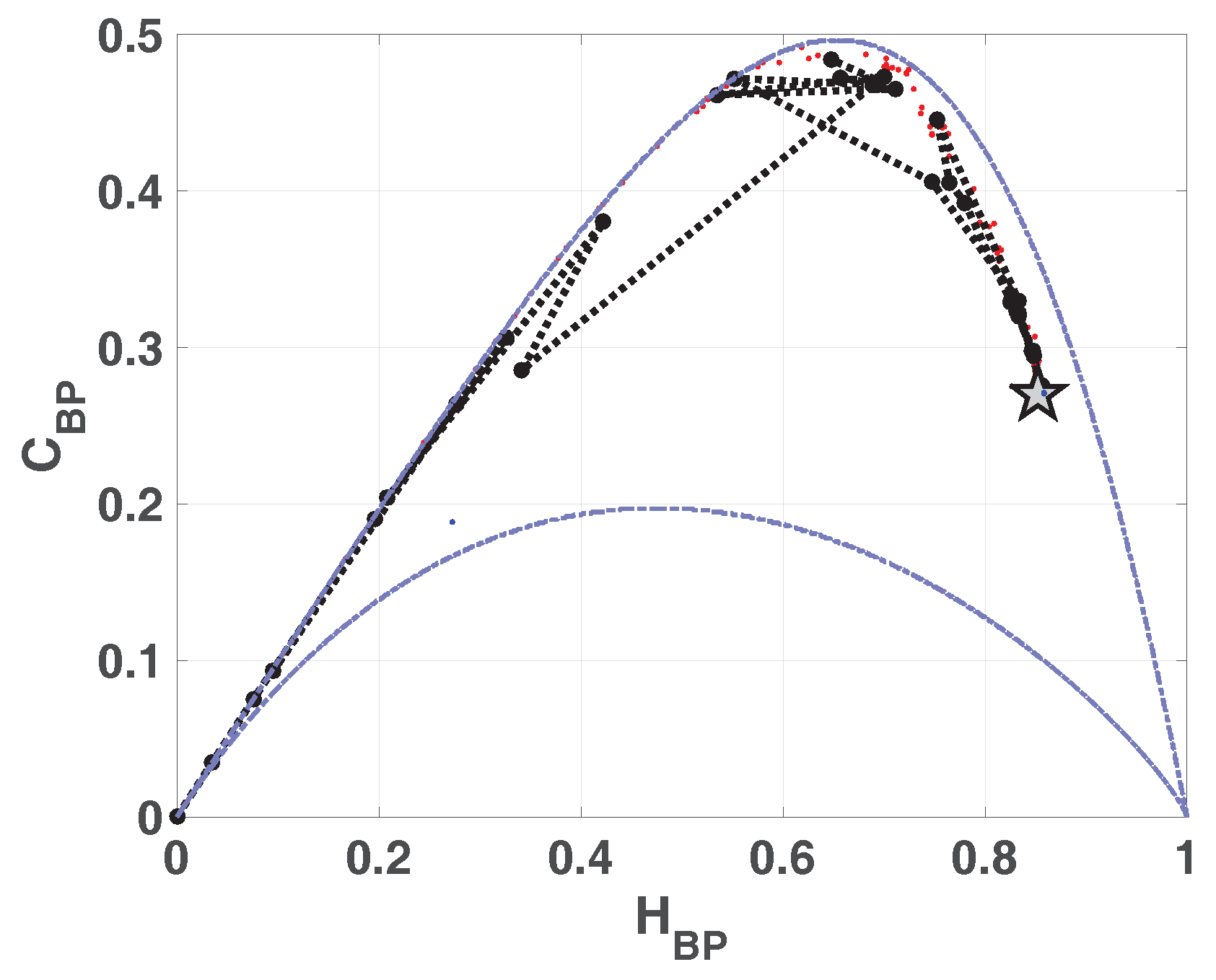
In
Figure 2 we show the causality plane
with and without amplitude contributions. The same sample points are showed to illustrate the planar positions for different data vectors. We can see that not the entire region
,
is achievable, in fact, for any PDF the pairs
of possible values fall between two extreme curves in the plane
[
39].
Chaotic maps present high values of complexity
(close to the upper complexity limit),and intermediate entropy
[
22,
40]. In the case of regular processes the values of entropy and complexity are close to zero. Stochastic processes that are uncorrelated present
near one and
near zero. Ideal random systems having uniform Bandt & Pompe PDF, are represented by the point
[
41] and a delta-like PDF corresponds to the point
. In both information planes
in
Figure 1 and
in
Figure 2, stochastic, chaotic and deterministic data are clearly localized at different planar positions.
We also used the number of missing patterns MP as a quantifier [
29]. As shown recently by Amigó et al. [
42,
43,
44,
45], in the case of deterministic maps, not all the possible ordinal patterns can be effectively materialized into orbits. Thus, for a fixed pattern-length (embedding dimension
D) the number of missing patterns of a time series (unobserved patterns) is independent of the series length
N. Remark that this independence does not characterize other properties of the series such as proximity and correlation, which die out with time [
43,
45]. In this paper, we use the MP to calculate an upper bound to the
and
.
A complete description and discussion about these quantifiers is out of scope of this manuscript. However, it can be found in [
23,
25,
29,
34,
37,
46,
47,
48].
3. Results
Five pseudo-chaotic maps were studied, two simple maps and three combination of them. For each one we have used numbers represented by floating-point (double presicion 754-IEEE standard) and fixed-point numbers with , where B is the number of bits that represents the fractional part. Time series were generated using 100 randomly chosen initial conditions within their attraction domain (interval ), for each one of these 54 number precisions. The studied maps are logistic (LOG), tent (TENT), sequential switching between TENT and LOG (SWITCH) and skipping discarding the values in the odd positions (EVEN) or the values in the even positions (ODD) respectively. In the following, all the results will be obtained from the pseudo-chaotic version of the LOG, TENT, SWITCH, EVEN and ODD maps.
Logistic map is interesting because it is representative of the very large family of quadratic maps. Its expression is:
with
.
Note that to effectively work in a given representation it is necessary to change the expression of the map in order to make all the operations in the chosen representation numbers. For example, in the case of LOG the expression in binary fixed-point numbers is:
with
where
B is the number of bits that represents the fractional part.
This rounding technique is the same as that used in [
4,
12,
14] and has some advantages, such as, it is algorithmically easy to implement and is independent of the platform where it is used, as long as
B is lower than the mantissa of the arithmetic of the local machine. In our case, the results were obtained with an Intel I7 PC, which has an ALU with IEEE-754 floating point standard with double precision, which limits the method to
bits.
Floating point representation does not constitute a field, wherein the basic maths properties, such as distributive, associative, are preserved. However, in fixed point arithmetics the exponent does not shift the point position and some properties as distributive remains. Also, we adopt the floor rounding mode because it arises naturally in a FPGA implementation.
The TENT map has been extensively studied in the literature because theoretically it has nice statistical properties that can be analytically obtained. For example it is easy to proof that it has a uniform histogram and consequently an ideal
. The Perron-Frobenius operator and its corresponding eigenvalues and eigenfunctions may be analytically obtained for this map [
49].
Tent map is represented with the equation:
with
u
.
In base-2 fractional numbers rounding, Equation (
12) becomes:
with
,
,
and
.
In [
11], the authors showed the evolution of the entropy of values
with respect to the binary precision. They characterized the evolution of the TENT map as a function of binary precision in a fixed-point arithmethics. In their scheme of generation of random numbers they used two postprocessing stages, first they binarized the data by detecting the crossing by a threshold, and then these data were processed by a XOR gate. In our case we use the output of the chaotic maps without any randomization process, however their results are very interesting to take a criterion about which parameters are useful to implement. In our case, we adopted two values of
u for two different reasons. Following [
11], an interesting value is
, or its closest value within the arithmetic used. On the other hand, the value of
is very attractive due to its extremely low implementation cost.
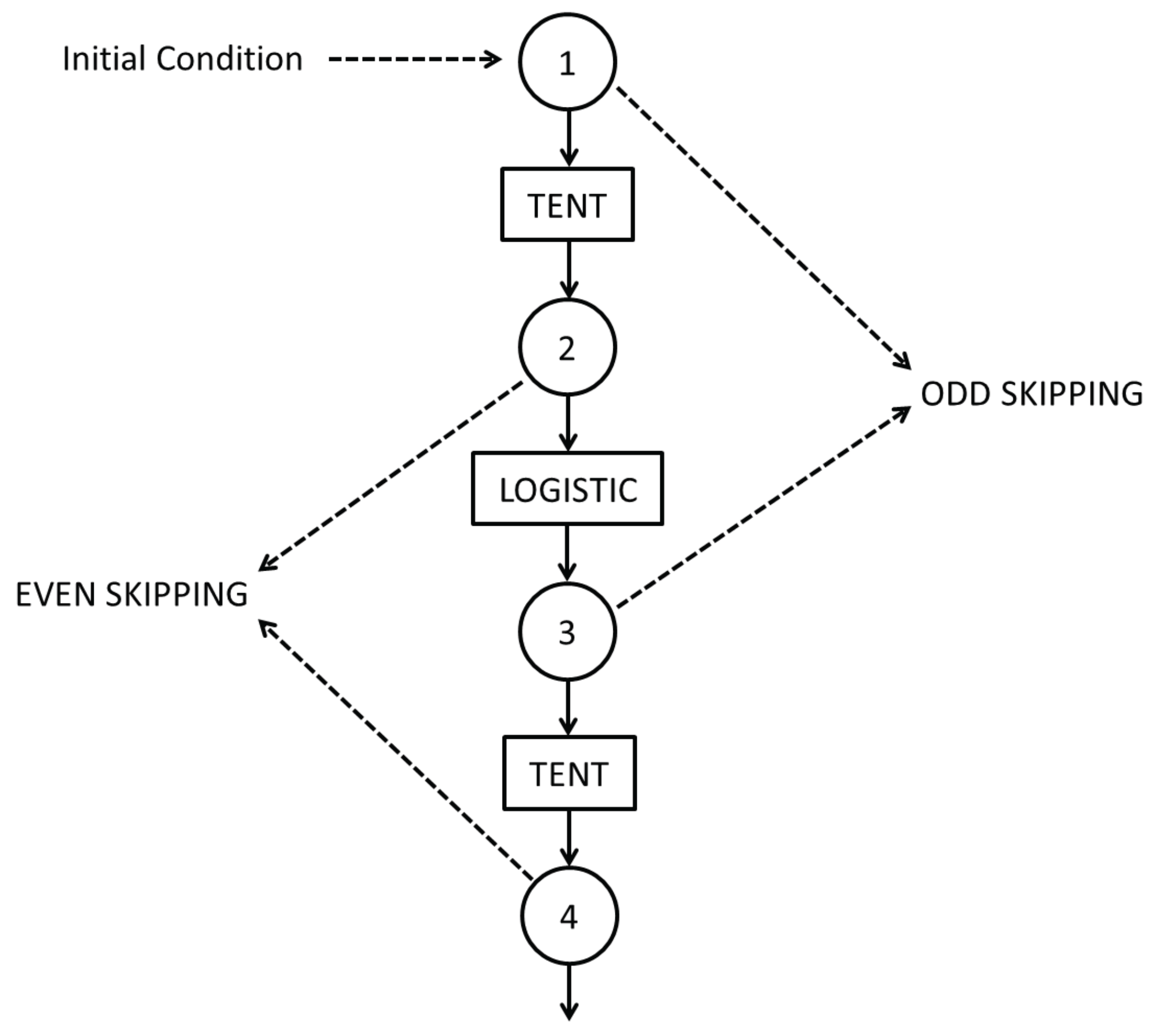
Switching, even and odd skipping procedures are shown in
Figure 3.
SWITCH map is expressed as:
with
and
n an even number.
However, as in the previous cases, we work with its pseudo-chaotic counterpart that can be expressed as:
Skipping is a usual randomizing technique that increases the mixing quality of a single map and correspondingly increases the value of
and decreases
of the time series. Skipping does not change the values of
for ergodic maps because it are evaluated using the non causal PDF (normalized histogram of values) [
23].
In the case under consideration we study even and odd skipping of the sequential switching of TENT and LOG maps:
Even skipping may be expressed as the composition function TENT∘LOG while odd skipping may be expressed as LOG∘TENT. The evolution of period as function of precision was reported in [
14] for these resulting maps. In this paper we use the same simulation algorithm and switching scheme as in [
14] and we add the analysis from the statistical point of view.
3.1. Period as a Function of Binary Precision
Grebogi and coworkers [
12] have studied how the period
T is related with the precision. There they saw that the period
T scales with roundoff
as
where
d is the correlation dimension of the chaotic attractor.
Nagaraj et al. [
14] studied the case of switching between two maps. They saw that the period
T of the compound map obtained by switching between two chaotic maps is higher than the period of each map and they found that a random switching improves the results. Here we have considered sequential switching to avoid the use of another random variable, because it can include its own statistical properties in the time series.
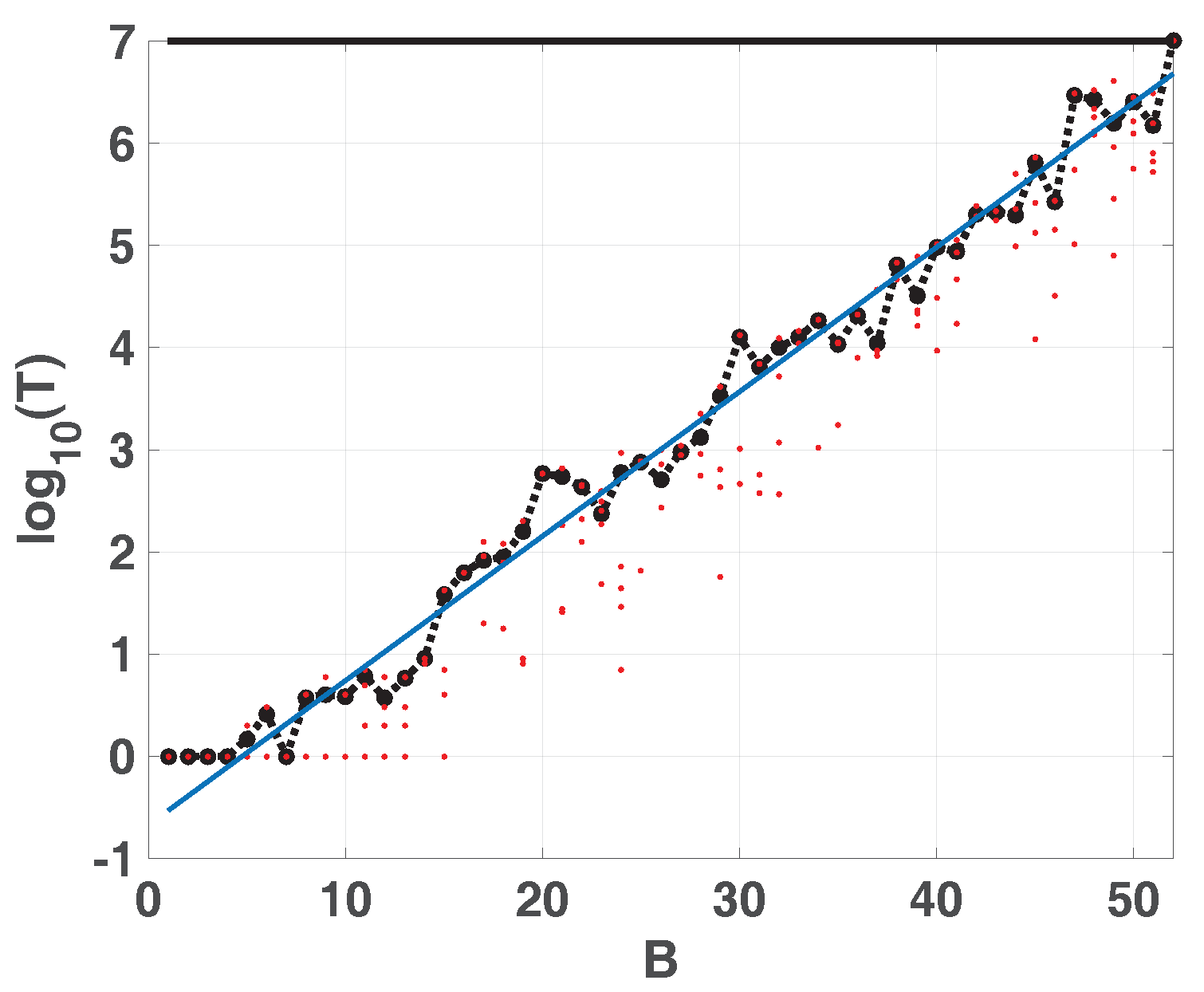
Figure 4 shows
T vs.
B in semi logarithmic scale. We run the attractor of the LOG from 100 randomly chosen initial conditions. The figure show: 100 red points for each fixed-point precision (
) and their average (dashed black line connecting black dots). The experimental averaged points can be fitted by a straight line (in blue) expressed as
where
m is the slope and
b is the
y-intercept.
Results for all the considered maps are summarized in
Table 1. We can detect that the average period was the same using both
and
when switching strategy is used. Then we report the results for SWITCH, EVEN and ODD using TENT with
to iterate.
Results are compatible for those obtained in [
14]. Switching between maps increases the period
T but skipping procedure decreases by almost half. Also, TENT with
exhibit the longest periods.
3.2. Quantifiers of Simple Maps
Here we report our results for both simple maps, LOG and TENT.
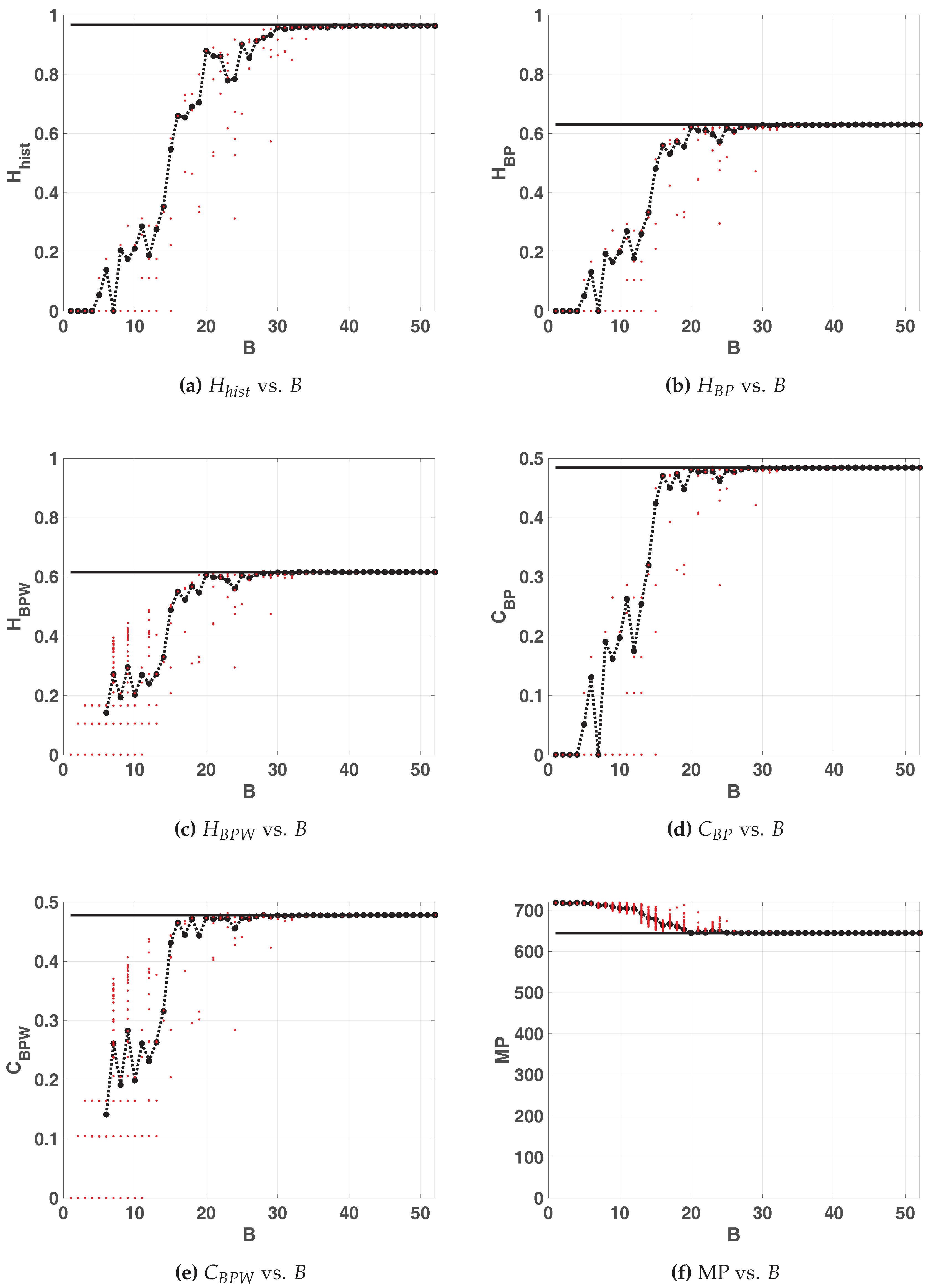
3.2.1. LOG
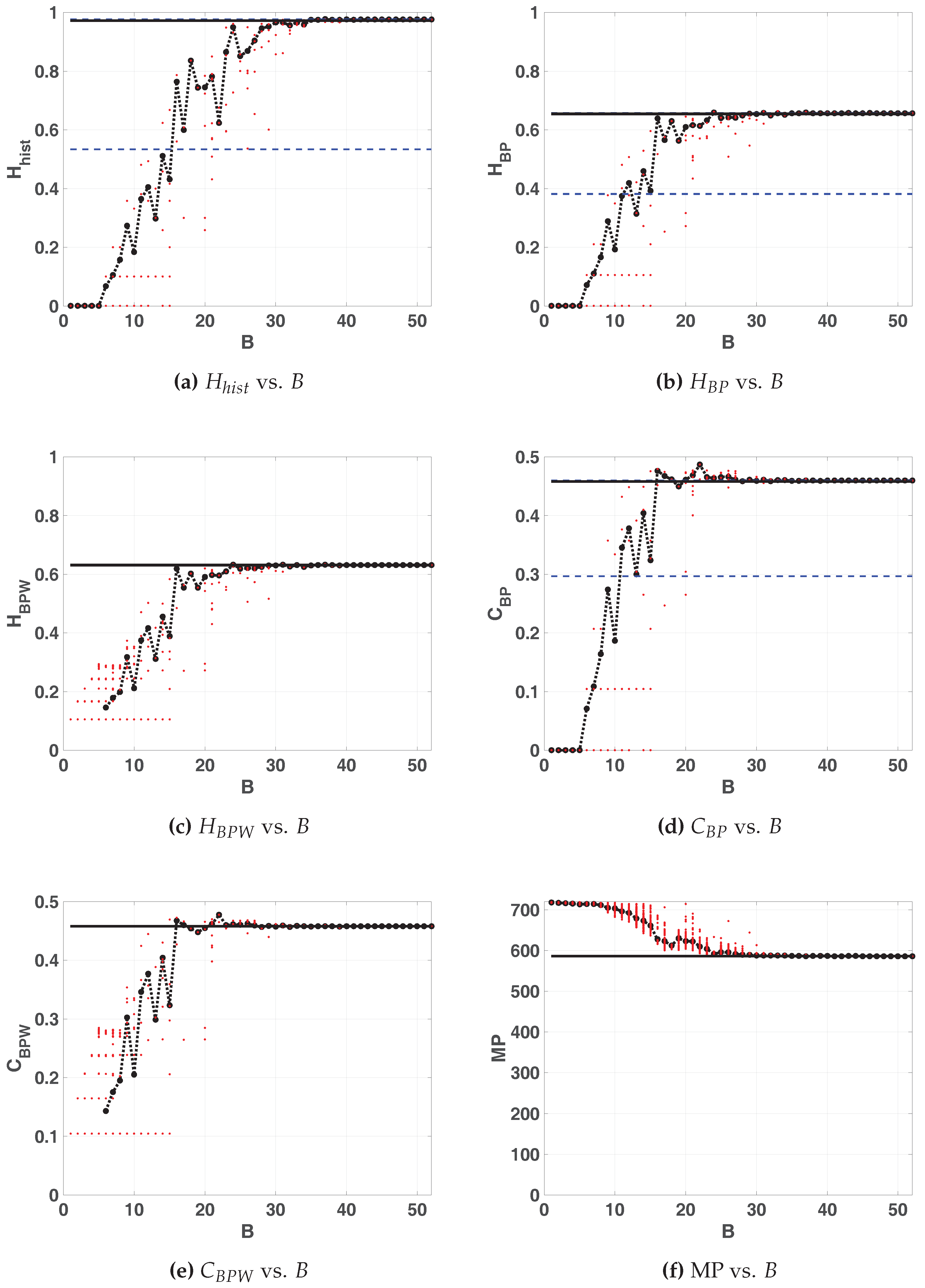
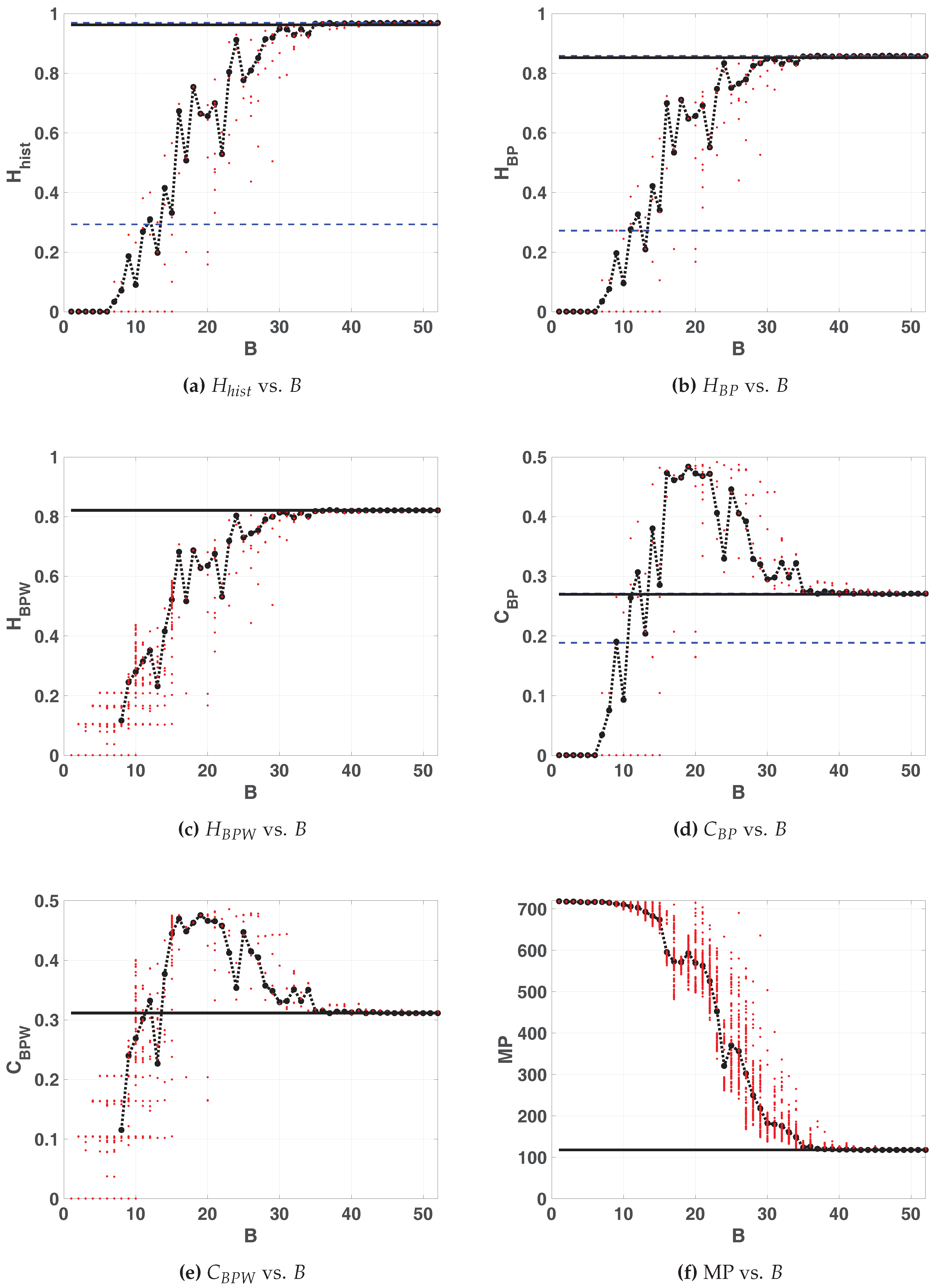
Figure 5 shows the statistical properties of LOG map in floating-point and fixed-point representation. All these figures show: 100 red points for each fixed-point precision (
) and in black their average (dashed black line connecting black dots), 100 horizontal dashed blue lines that are the results of each run in floating-point and a black solid line their average. Note that these lines are independent of
x-axis. In this case, all the lines of the floating-point are overlapped.
According as B grows, statistical properties vary until they stabilize. For the value of remains almost identical to the value for the floating-point representation whereas and stabilizes at . Their values are: ; ; . Note that the stable value of missing patterns makes the optimum . Then, is the most convenient choice for hardware implementation because an increase in the number of fractional digits does not improve the statistical properties.
Some conclusions can be drawn regarding BP and BPW quantifiers. For
and 4, the averaged BP quantifiers are almost 0 while the averaged BPW quantifiers can not be calculated (see in
Figure 5c,e the missing black dashed line). This is because for those sequences were the initial condition were 0 all iterations result to be a sequence of zeros (the fixed point of the map), this is more likely to happen when using small precisions because of roundoff.
When
B increases the initial conditions are rounded to zero less frequently, this can be seen for
. In this, case the generated sequences starting from a non-null value fall to zero after a short transitory very often. An interesting issue in
Figure 5c,e, is that BPW quantifiers show a high dispersion unlike BP quantifiers. This is because BPW procedure takes into account the transient and discards fixed points, unlike BP procedure considers all the values of the sequence. We can see in
Figure 5c,e for
horizontal lines of red points that do not appear in
Figure 5b,d, this evidences that different initial conditions fall to the same orbits, even for adjacent precisions.
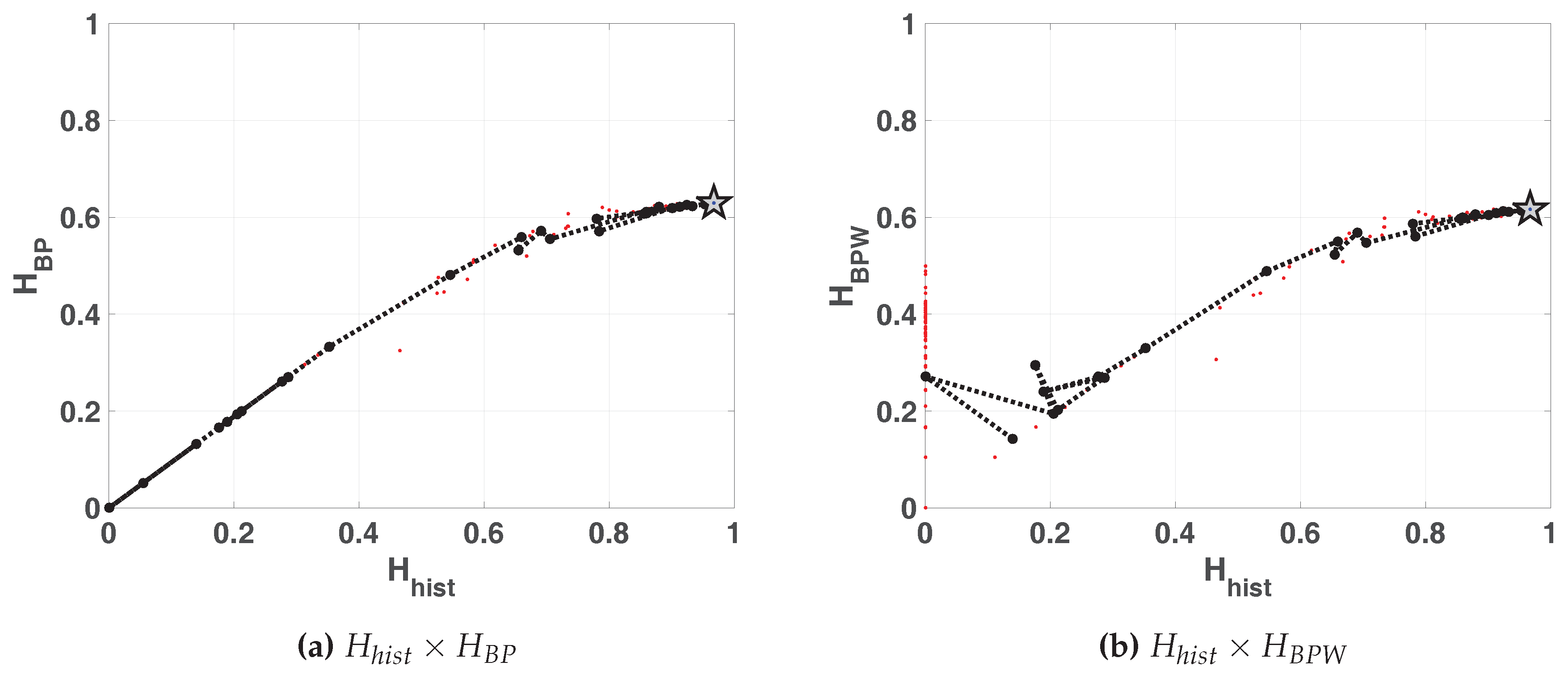
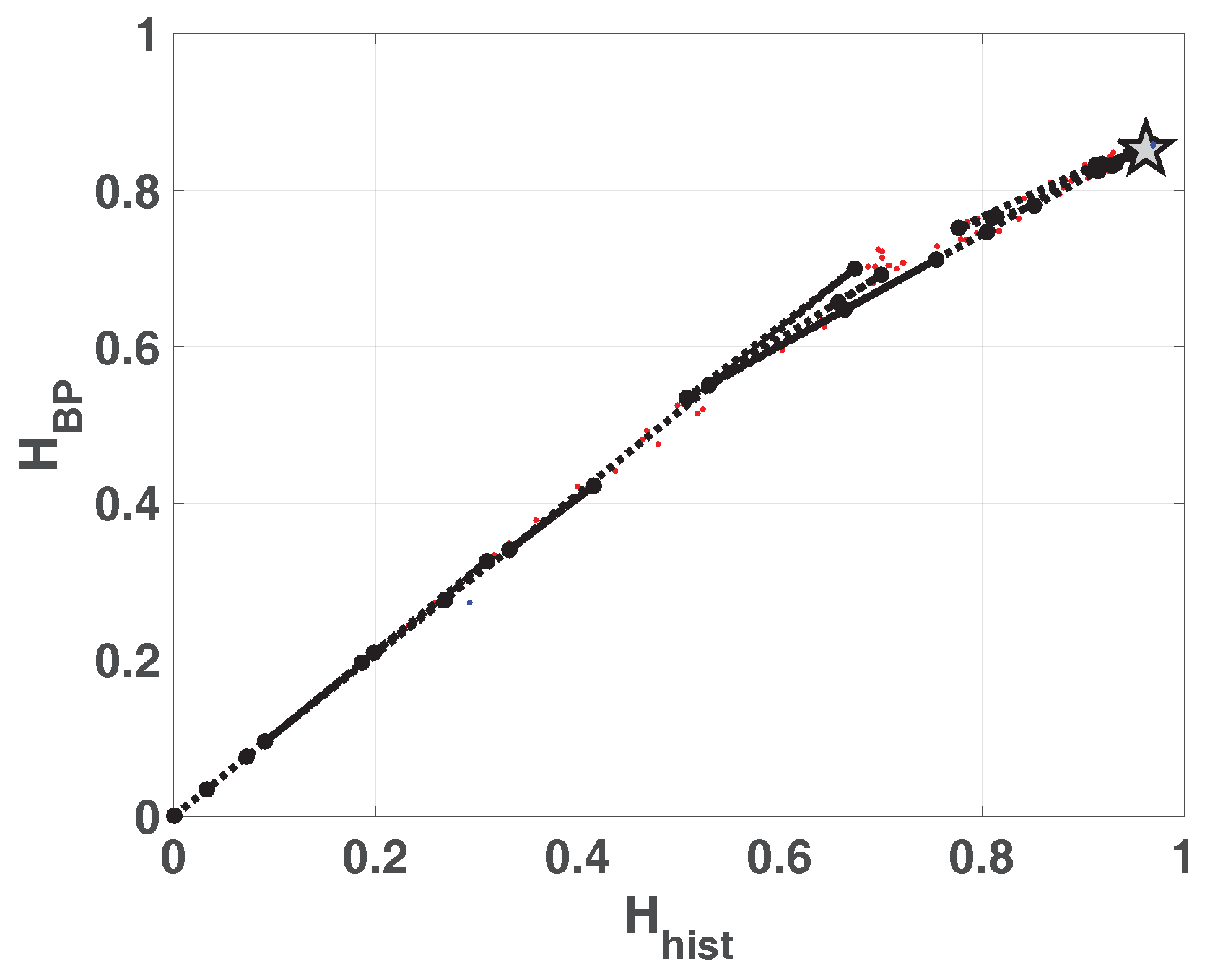
The same results are shown in double entropy planes with the precision as parameter (
Figure 6a without amplitude contributions and
Figure 6b with amplitude contributions). These figures show: 100 red points for each fixed-point precision (
B) and their average in black (dashed black line connecting black dots), 100 blue dots that are the results of each run in floating-point and the black star is their average. Here, the 100 blue points and their average are overlapped.
As expected, the fixed-point architecture implementation converges to the floating-point value as B increases. For both planes, and , from , increases but and remain constant. It can be seen that the distribution of values reaches high values () but their mixing is poor ().
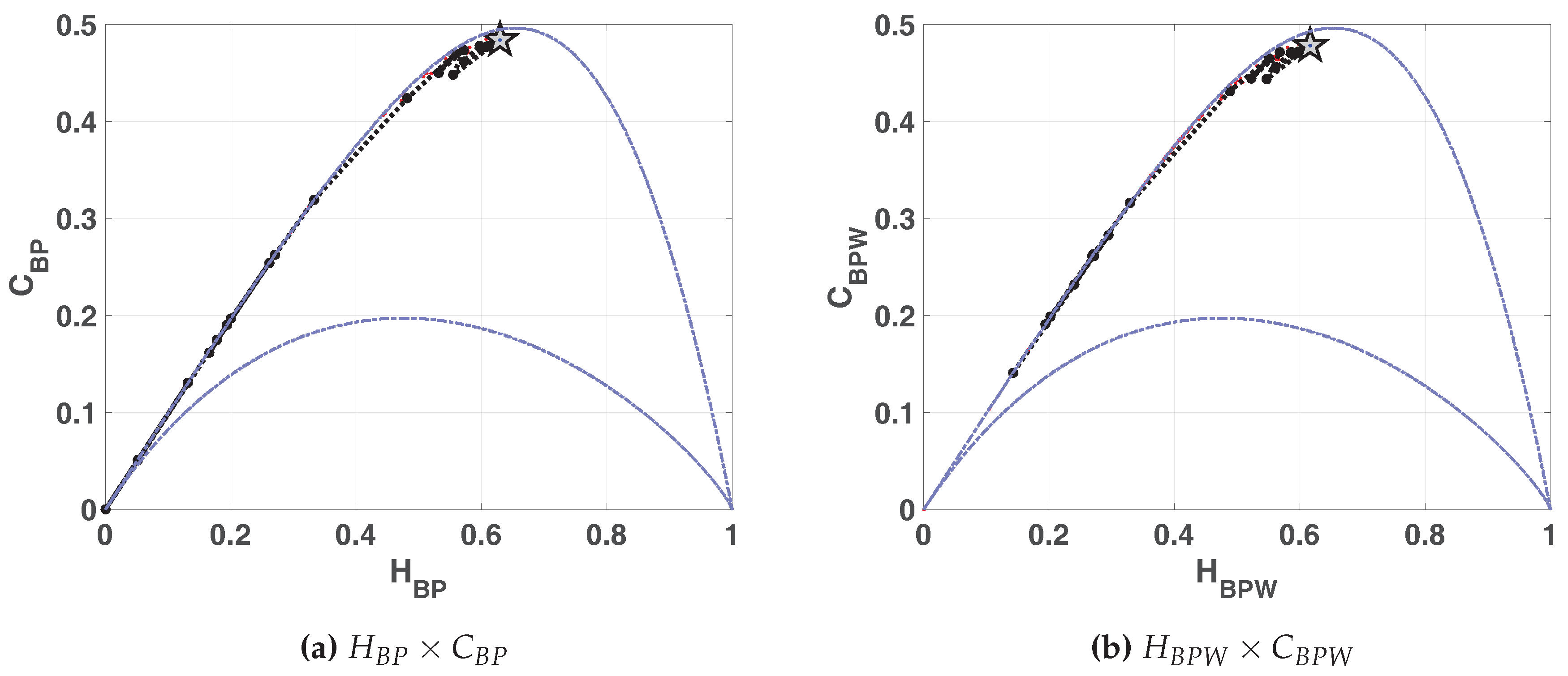
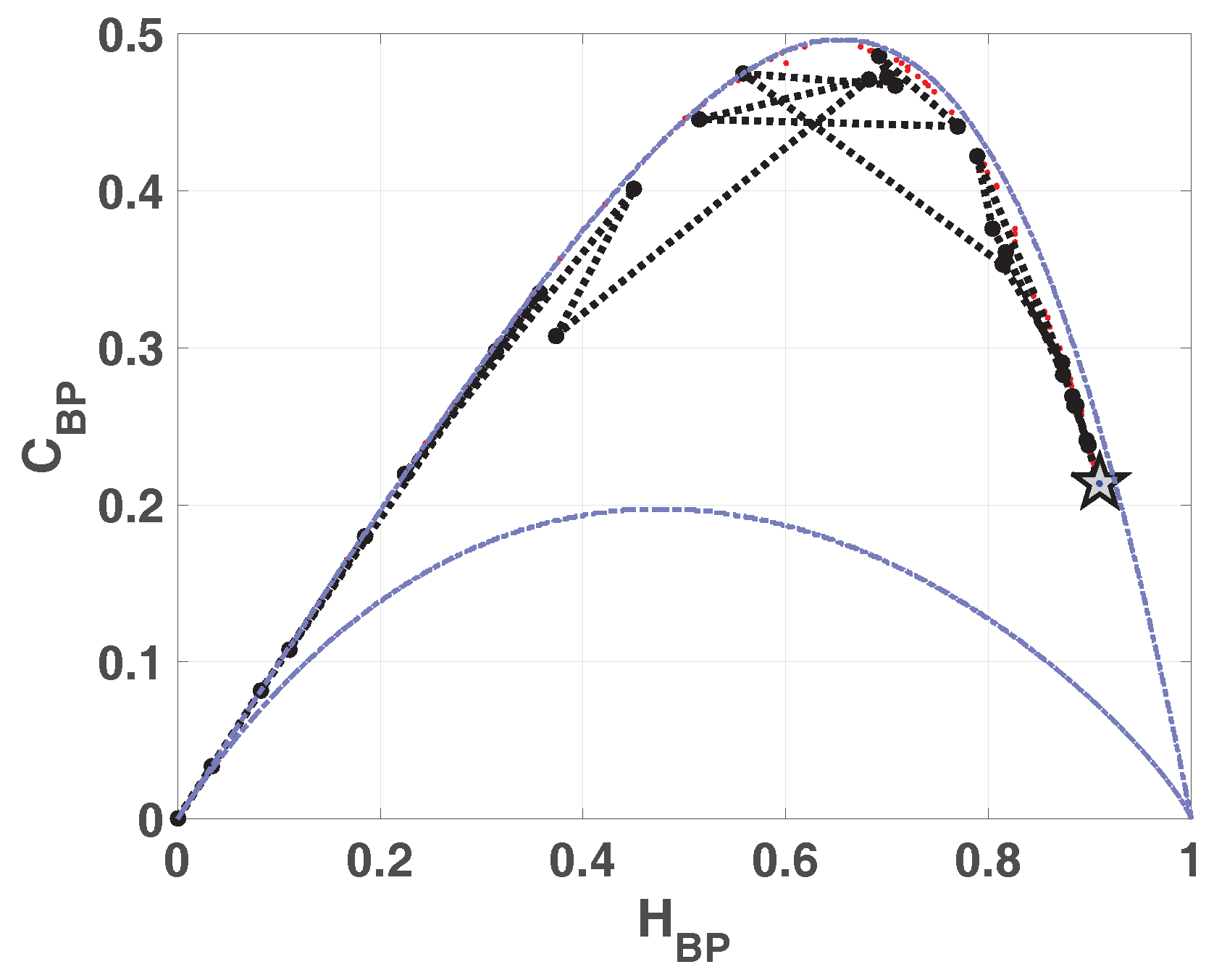
In
Figure 7a,b we show the entropy-complexity planes. Dotted grey lines are the upper and lower margins, it is expected that a chaotic system remains near the upper margin. These results characterize a chaotic behavior, in
plane we can see a low entropy and high complexity.
3.2.2. TENT
The equation that represents the implementation for
is:
Rounding is necessary only on the second multiplication because it is equivalent to a shift-to-left.
When this map is implemented with
in any computer using any numerical representation system (even floating-point!) truncation errors rapidly increase and make the unstable fixed point in
to become stable. The sequences within the attractor domain of this fixed point will have a short transitory of length between 0 and
B followed by an infinite number of 0’s [
50,
51]. This issue is easily explained in [
52], the problem appears because all iterations have a left-shift operation that carries the 0’s from the right side of the number to the most significant positions. As expected, the quantifiers
,
and
are equal to zero for all precisions. In the case of
and
quantifiers are different to zero because BPW procedure discards the elements once the fixed point is reached.
,
and MP present high dispersions related to the short length of serie’s transient. These transients have a maximum length of
B elements (iterations) for fixed-point arithmetic and 53 for floating-point (IEEE754 double precision).
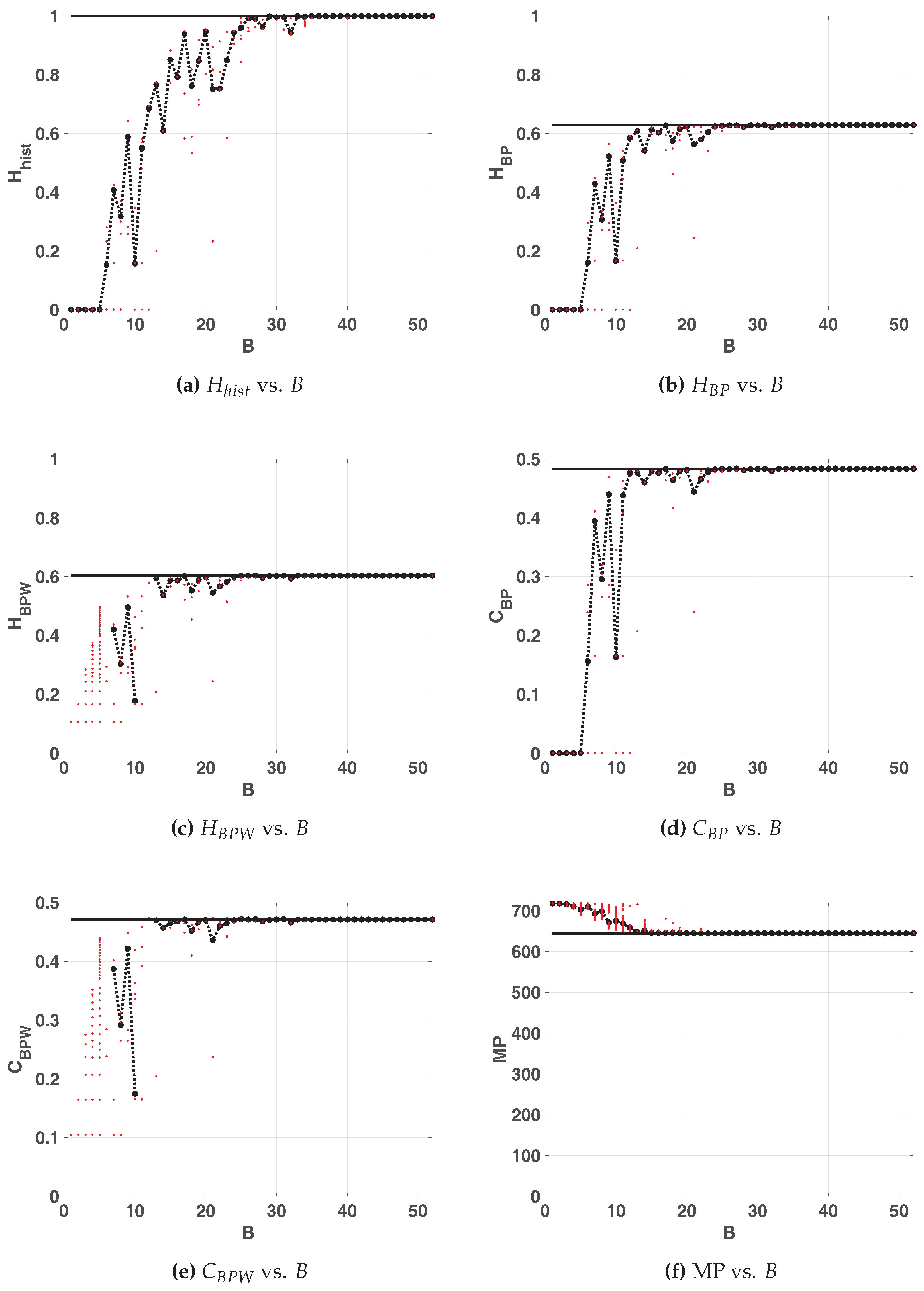
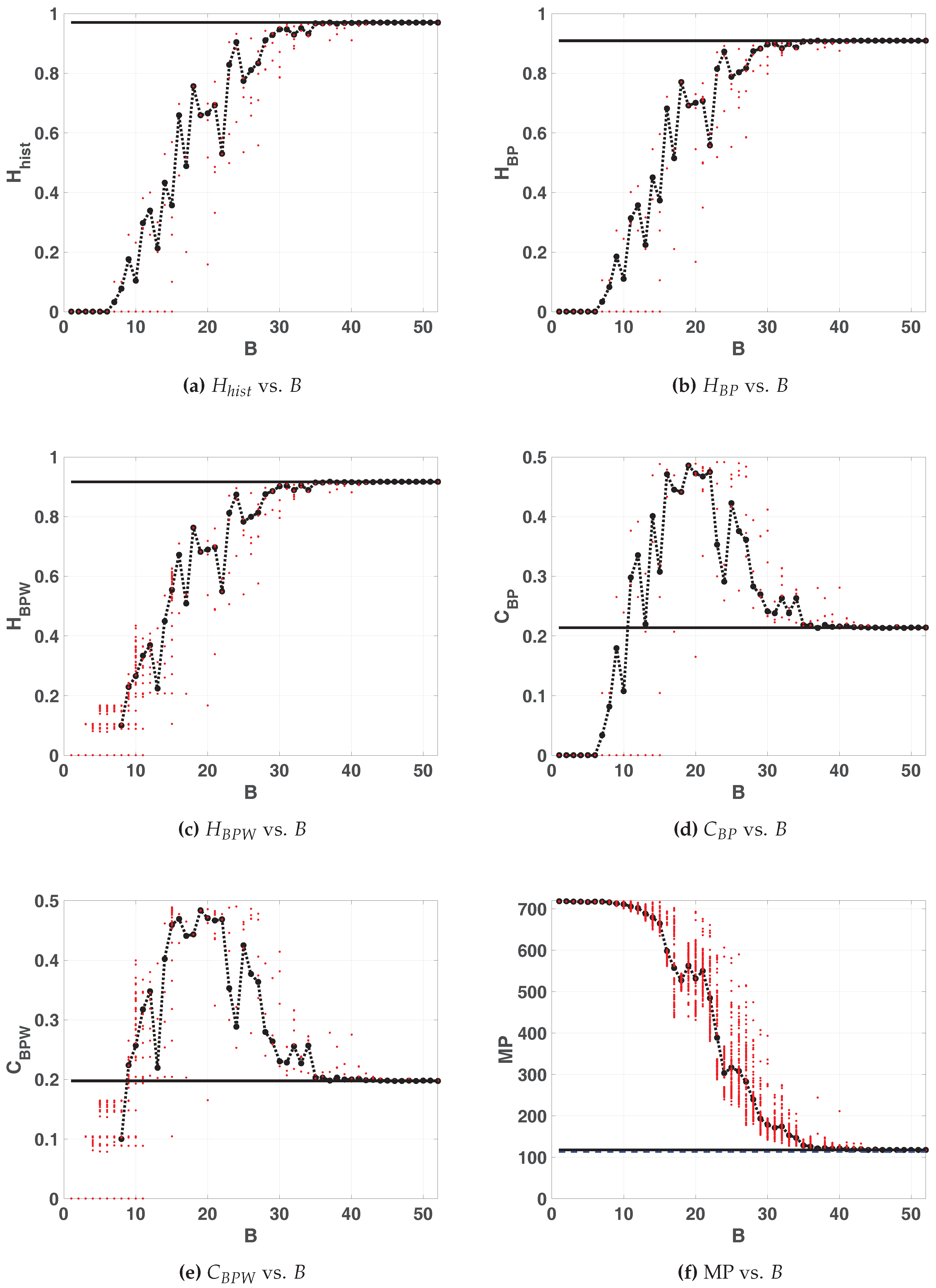
Figure 8 shows the quantifiers for floating- and fixed-point numerical representations for
. The results are similar to those of the LOG map, in that the averaged value of the quantifiers tends not monotonously to the floating point value and stabilizes from a certain value of
B. However, more bits of precision were necessary to achieve this, on the other hand it can be seen that the value of
improves and that of
remains similar to those of the LOG map. Using
and
we detect that below the 13 precision bits some initial conditions converge to fixed points or diverge, so it is not possible to use this map with
.
The positions on the double entropy (
Figure 9) and entropy complexity (
Figure 10) planes are marginally better than those on the LOG map and are characteristic of a pseudo-chaotic system.
3.3. Quantifiers of Combined Maps
Here we report our results for the three combinations of the combined maps, SWITCH, EVEN and ODD.
3.3.1. SWITCH
Between the two parameters analyzed for the TENT map, we found that mixing and stochasticity converge to the same values either for or for . So, we chose to use given its simplicity to be used both in software simulations and in hardware implementation.
Results with sequential switching are shown in
Figure 11. The calculated entropy value for floating-point implementation is
, this value is slightly higher than the one obtained for the LOG map. For fixed-point arithmetic this value is reached in
, but it stabilizes from
. Regarding the ordering patterns the number of MP decreases to 586, this value is lower than the one obtained for LOG map. It means the entropy
may increase up to
. BP and BPW quantifiers reach their maximum of
and
at
, but they stabilize from
. Complexities are lower than for LOG,
and
, these values are reached for
but they stabilize for
. Compared with LOG, statistical properties are better with less amount of bits, for
this map reaches optimal characteristics in the sense of random source.
Furthermore, we encountered one initial condition in floating-point with an anomalous behavior.
Figure 11a,b,d show an horizontal blue dashed line that is far from the average value, unlike this is not detected by quantifiers based on
procedure in
Figure 11c,e. Nevertheless comparing both procedures (
and
) we were able to detect a falling to fixed point after a long transitory, the BPW procedure discards the constant values (corresponding with a fixed point) and works only over the transitory values.
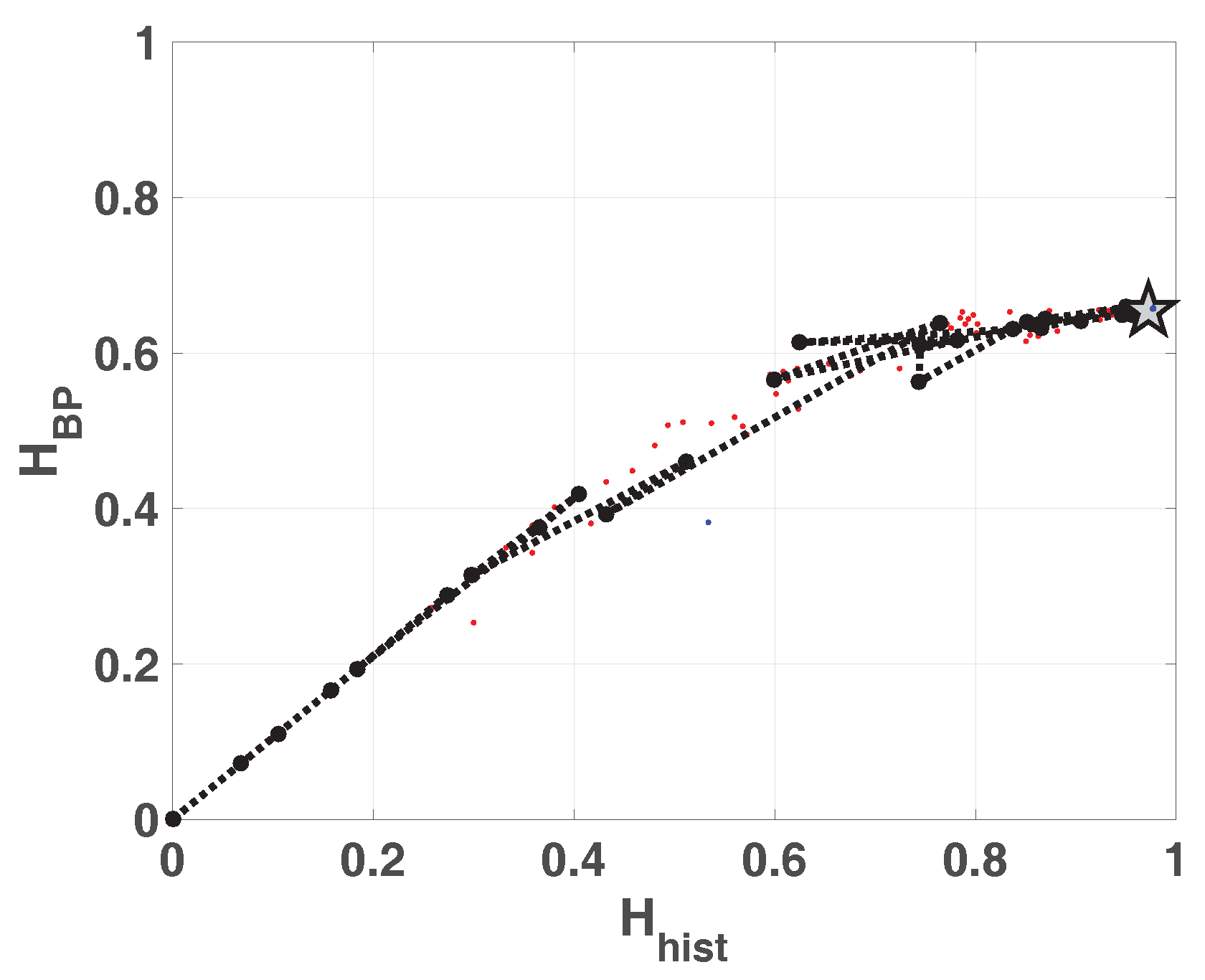
Double entropy plane
is showed in
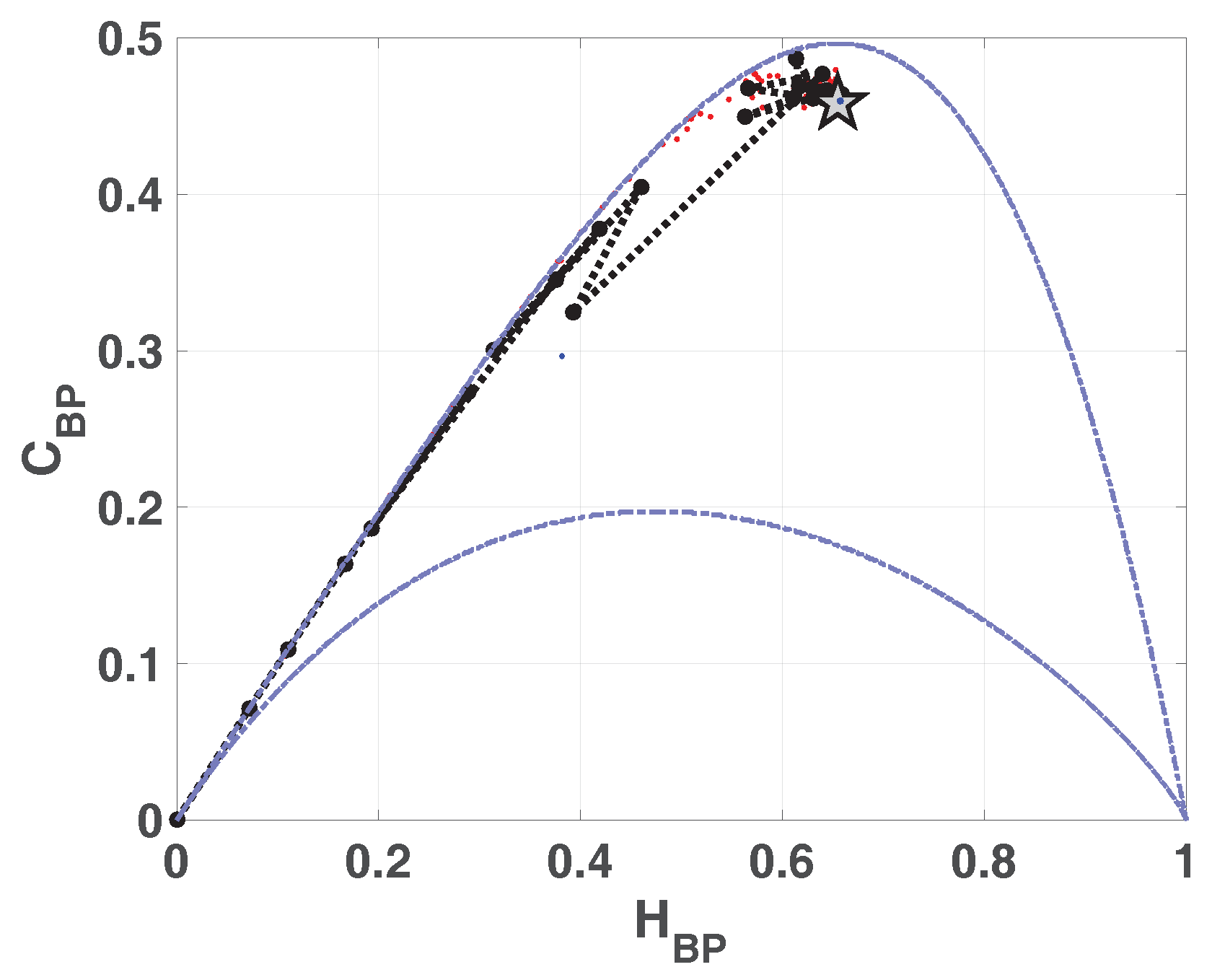
Figure 12. The reached point in this plane for SWITCH map is similar to that reached for LOG map, and it is denoted by a star in the figure. The mixing is slight better in this case.
Entropy-complexity plane
is showed in
Figure 13. If we compare with the same plane in the case of LOG (
Figure 7a),
is lower for SWITCH, this fact shows a more random behavior.
3.3.2. EVEN and ODD
In
Figure 14a and
Figure 15a we can see that quantifiers related to the normalized histogram of values slightly degrades with the skipping procedure. For example
reduces from
without skipping to
for EVEN and
for ODD. This difference between EVEN and ODD in floating point is because a high dispersion was obtained for
,
and
but not for
or
.
Figure 14b–f and
Figure 15b–f show the results of BP and BPW quantifiers for EVEN and ODD respectively. Higher accuracy is required to achieve lower complexity than without using skipping. From the MP point of view a great improvement is obtained using any of the skipping strategies but ODD is slightly better than EVEN. Missing patterns are reduced to
for EVEN and ODD, increasing the maximum allowed Bandt & Pompe entropy that reaches the mean value
for EVEN, and
. The complexity is reduced to
for EVEN and
for ODD. The minimum number of bits to converge to this value is
for both EVEN and ODD maps.
The enhancement showed in
Figure 14 and
Figure 15 is reflected in the position of asymptotic point in the planes
Figure 16 and
Figure 17. In both cases this position is closest to the ideal point
, because the resulting vectors present better mixing.
Compatible results are shown in
Figure 18 and
Figure 19, the position of asymptotic point is closest to the ideal point
. This result reflects that mixing is better because the complexity of resulting system is lower. This plane detects that the vector generated by ODD skipping is more mixed than EVEN.
4. Conclusions
In this paper we explored the statistical degradation of simple, switched and skipped chaotic maps due to the inherent error of a based-2 systems. We evaluated mixing and amplitude distributions from a statistical point of view.
Our work complements previous results given in [
14], where period lengths were investigated. In that sense, our results were compatible with these. We can see that the switching between two maps increases the dependence of period as function of precision, nevertheless the standard procedure of skipping reduce the period length in almost a half.
All statistics of the maps represented in fixed-point produces a non-monotonous evolution toward the floating-point results. This result is relevant because it shows that increasing the precision is not always recommended.
Our results show that SWITCH has a marginal improvement in the mixing with respect to LOG and TENT. However the greatest improvement comes when skipping is applied, we can see that BP and BPW entropies grow and BP and BPW complexities decrease, for the same numerical representation. This result is relevant because evidences that a long period is not synonymous of good statistics, switched maps EVEN and ODD have half period lengths but their mixing is better and their amplitude distributions remain almost equal. As counterpart, more precision is needed to reach the better asymptotes that offers the switching method.
It was especially interesting to note that the TENT maps with (which produces outputs that quickly converge to zero) and (with statistical properties better than LOG), produce outputs with the same results when they are included in the switched scheme.

 ,
, 




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}