Big Data Blind Separation


Department of Systems Engineering, King Fahd University of Petroleum & Minerals, Dhahran 31261, Saudi Arabia
Entropy 2018, 20(3), 150; https://doi.org/10.3390/e20030150
Submission received: 8 December 2017
/
Revised: 23 February 2018
/
Accepted: 23 February 2018
/
Published: 27 February 2018
(This article belongs to the Special Issue Entropy in Signal Analysis)
Abstract
:Data or signal separation is one of the critical areas of data analysis. In this work, the problem of non-negative data separation is considered. The problem can be briefly described as follows: given , find and such that . Specifically, the problem with sparse locally dominant sources is addressed in this work. Although the problem is well studied in the literature, a test to validate the locally dominant assumption is not yet available. In addition to that, the typical approaches available in the literature sequentially extract the elements of the mixing matrix. In this work, a mathematical modeling-based approach is presented that can simultaneously validate the assumption, and separate the given mixture data. In addition to that, a correntropy-based measure is proposed to reduce the model size. The approach presented in this paper is suitable for big data separation. Numerical experiments are conducted to illustrate the performance and validity of the proposed approach.
1. Introduction
Transforming data into information is a key research direction of the current scientific age. During the data collection phase, it is often the case that the data cannot be collected from the actual data generating locations (sources). Typically, a nearby physically connected location (station) that is accessible can be used for the data collection. If the station is influenced by more than one source, then the data collected at the station provides mixed information from the multiple sources (mixture data). This creates a challenging problem of identifying the source data from the given mixture data. Such a problem is typically known as a data (or signal) separation problem.
In this paper, a linear mixing type data separation problem is considered. The generative model of the problem in its standard form can be written as:
where denotes the given mixture matrix, is the unknown mixing matrix, and denotes the unknown source matrix. The problem can be further classified into overdetermined (m > n), undetermined (m < n), and square or determined (m = n) cases. The overdetermined case can be transformed into the square case by using the Principal Component Analysis (PCA) method [1,2]. The undetermined cases often result in loss of information or redundancy in the representation. Usually, approximate recovery is done based on the prior probability assumptions. Typically, Gaussian or Laplacian priors are used to estimate the mixing matrix. The idea is to identify the directions of maximum density via clustering. These directions correspond to the identification of the mixing matrix [3,4]. Once the mixing matrix is estimated, the source matrix is obtained by solving series of least square problems. In this paper, the data separation problem for cases will be considered.
In addition to that, the above problem given in Equation (1) can be solved under numerous assumptions based on the level of available information. In this work, both and are assumed to be unknown. In such a scenario, the above signal separation problem is known as the “Blind” Signal Separation (BSS) problem. Seminal ideas of the BSS problem can be found in [5], where the authors illustrated the idea of BSS via an example of two source signals (n = 2) and two mixture signals (m = 2). Their objective was to recover source signals from the mixture signals, without any further information. However, it has been known since then that the recovery of sources from a linear mixture is imperfect, and pragmatic recovery needs various identifiability conditions. In [6], various approaches and the identifiable conditions of the BSS problem are summarized.
One of the well known traditional solution approaches to the BSS problem is the Independent Component Analysis (ICA) [7]. The ICA-based approaches are built upon the key assumption of the statistical independence among the rows of . The basic objective of ICA is to separate the input data into statically independent components. During the last three decades, there have been a large amount of papers on signal analysis that are devoted to the usage of ICA. These approaches are designed not only for the linear but also for the nonlinear signal mixing scenarios. They have also been designed for the overdetermined, undetermined, as well as square cases of the BSS problem. Some of the well known approaches in ICA are based on mutual information [8]; negentropy [9]; projection pursuit [10]; infomax [11]. Recent applications of ICA include bio-medical data analysis [12,13,14,15,16,17]; power system analysis [18], and audio and speech [19]. It is out of the scope of this paper to summarize all the typical approaches of ICA. Therefore, interested readers are referred to [7,20] (and the references therein). One of the major critiques pertaining to ICA is the existence of independent sources. Some of the signal analysis areas (such as biomedical and hyperspectral image analysis) may not satisfy the independence criterion (see [21]). Thus, alternative approaches to ICA for BSS have also been a critical research direction in the area of signal analysis.
Other prominent approaches of BSS, apart from ICA, assume some sparsity or geometric structure in [22]. In this work, the focus is on the sparsity-based approaches of extracting non-negative sources. This area is widely known as Sparse Component Analysis (SCA) [23]. Specifically, following are the basic assumptions that are considered while solving the SCA problem.
Basic SCA assumptions:
- Every column of the source matrix is non-negative.
- Source matrix has a full row rank.
- Mixing matrix has a full column rank, and .
- The rows of the source matrix, and columns of the mixing matrix have unit norm.
- Source matrix is sparse.
The first assumption provides a mathematical advantage in designing the solution algorithms. Basically, the non-negativity assumption transforms the BSS problem into a convex programming problem [24,25,26]. In addition to that, non-negative source signals are very common in sound and image analysis. The next two assumptions ensure that the problem is recoverable (solvable). The fourth assumption is perhaps the limit of all BSS approaches, which is related to scalability and uniqueness (see [27]). The fifth assumption is the key sparsity assumption of the SCA-related approaches. Different scenarios of the SCA problem arise with different structures of the sparsity. The typical structures of sparsity discussed in the SCA literature can be classified as:
- Locally Dominant Case: In addition to the basic assumptions, for a given row r of , there exists at least one unique column c such that:
- Locally Latent Case: In addition to the basic assumptions, for a given row r of , there exists at least linearly independent and unique columns such that:
- General Sparse Case: This is the default case.
The first case is one of the widely known cases in the SCA literature (see [28,29] for recent literature reviews). The second case is new to the of SCA literature, and few recent papers address this case [30]. The first two cases have identifiability conditions, which assure identification and recovery of the source signals. If the conditions of the first two cases do not apply to the given data, then the SCA problem belongs to the last general case. Typically, the general case may not have perfect identification (apart from the scalability and uniqueness issues). For the general case, minimum volume-based approaches [26,31,32], and extreme direction-based approaches [33] have been proposed to approximately recover the source matrix. Some special cases of sparse structure, apart from the above cases, that can recover original source data have also been studied in the literature, for example see [34].
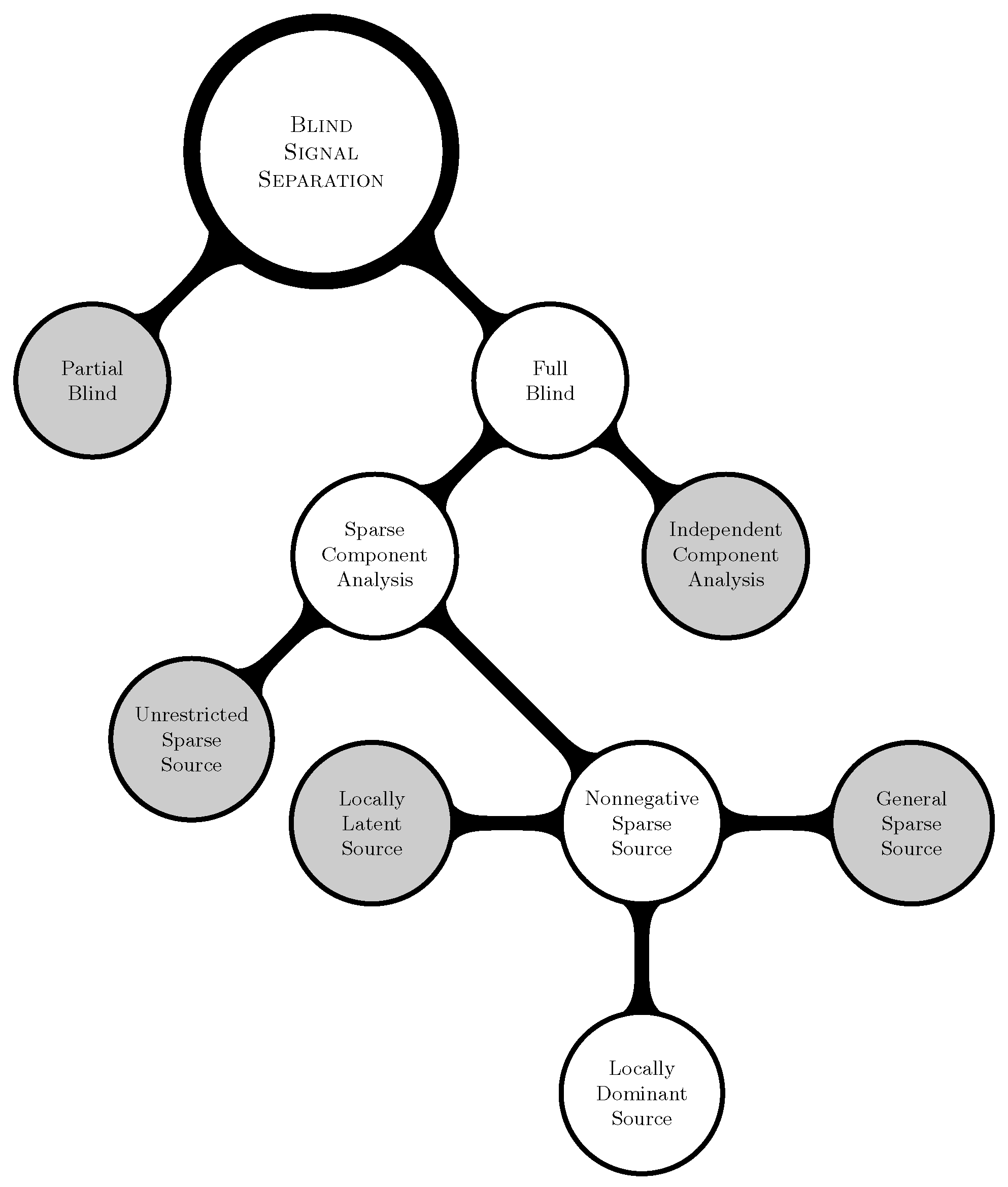
In addition to the above, the conditions on that improve the separability of sources are studied in the literature [35,36]. Methods that exploit spectral variability can be seen in [37]. Time series (frequency and transformation analysis) based methods to identify sparse sources have been presented in [4,38]. Further methods developed on the assumption of SCA can be found in [39,40]. The prominent application areas of SCA include, but are not limited to, the following: Blind Hyperspectral Unmixing (BHU) [41], chemical analysis [42], Nuclear Magnetic Resonance (NMR) spectroscopy [43], etc. Figure 1 portrays various linear BSS methods available in the literature. The grayed areas in the figure represent the research areas that will not be considered further in this paper. Thus, the branches unrelated to the paper that emerge from the grayed areas are ignored in the figure.
One of the critical gaps found in the SCA literature is the unavailability of a method to test the existence of a locally dominant assumption from the mixture data (). In this paper, a novel mathematical programming and correntropy-based approach is presented for testing the locally dominant source assumption. The proposed approach also provides a solution for the locally dominant SCA problem.
Throughout this paper, the following notation styles are used. A capital letter bold face character, like , indicates a matrix. A small letter bold face character with or without a subscript, like , indicates the rth column vector of matrix . A small letter bold face character with a special subscript, like , indicates the transpose of the pth row vector of matrix . A non-bold small letter character, like , represents the pth row rth column element of matrix .
The rest of the paper is organized as follows: Section 2 introduces the locally dominant case. Specifically, it displays the existing formulations from the literature, and presents the proposed novel formulation. A correntropy-based ranking method to eliminate the non-extreme data points is developed in Section 3. By incorporating the proposed model and the proposed ranking method, a tailored solution approach for the big data separation problem is developed in Section 4. A numerical study to assert the performance of the proposed approach is illustrated in Section 5. Finally, the paper is concluded with discussions in Section 6.
2. Locally Dominant Case
Consider the following determined or square version of the SCA model:
Each column for of the mixture matrix () can be represented as follows:
where is the jth column of the mixing matrix (), and is the jth row ith column element of the source matrix (). Equation (5) highlights that every column vector of is a linear combination of the column vectors of . Since the source matrix () is non-negative (i.e., for all i & j), the combination is a conic combination. Thus, the columns of are spanned by the columns of . In other words, the extreme column vectors of are the columns of . Therefore, the locally dominant case boils down to the identification of the extreme vectors of [24].
If all the columns of are non-negative, then normalizing every column of with respect to Norm-1 makes the columns of coplanar. That is, all the columns are contained in the following lower dimensional plane:
Now, the extreme points of on the lower dimensional plane correspond to the columns of . In addition to that, if some of the elements of are negative, then the columns of are projected onto a suitable lower dimensional plane. There are many approaches in the literature that are designed to work on this lower dimensional plane (affine hull) [25,44]. The advantage of working on this plane is that the extreme vector columns of will form the vertices of a lower dimensional simplex. Thus, identifying the extreme points will result in the identification of the mixing matrix. Next, a few well known mathematical formulations and solution approaches for SCA from the literature are presented.
2.1. Conventional Formulations
One of the earliest mathematical formulations that identifies the extreme vectors of is proposed in [24]. The idea is to pick one column of , say , and check the possibility of it being an extreme vector. The formulation corresponding to is given as follows:
where , is the variable that corresponds to the weight of for . The key idea that is exploited in the formulation is that the extreme vectors cannot be represented by a non-negative weighted combination of the other data vectors. The above formulation is a least square minimization problem. In the worse case, the formulation has to be executed N times for each , i.e., for . In the best case, the formulation has to be executed n times. A nonzero value of the objective function indicates that the vector is an extreme vector of .
Another approach, called Convex Analysis of Mixtures of Non-negative Sources (CAMNS), that works on the affine hull is presented in [25]. The solution approach of CAMNS involves two major steps. In the first step, the parameters and of the affine hull are estimated as follows:
where is the jth row of . In Equation (10), vector is subtracted from all the rows of , and in Equation (11), matrix contains the columns corresponding to the eigenvectors associated with the largest eigenvalues of . Basically, this first step is similar to the dimensionality reduction process executed in the PCA. In the second step, the following mathematical model is repeatedly solved:
where is a generated vector, is an ith row of , and is the unknown variable. The above formulation exploits the notion that the optimal solution of a linear program exists at the extreme points. For a given , the formulation is solved twice; one time as the maximization problem and the other time as the minimization problem. This is done in order to get one (or maybe two) new extreme point(s) in every iteration. The extreme points are identified by resolving the above formulation repeatedly with respect to different vectors. The crux of this method is hidden in the generation of and convergence of the approach, which are the main concepts presented in [25].
Notice that the above two ideologies extract the columns of sequentially. In addition to the above approaches, typical approaches in the literature identify the columns of sequentially [28,29,45]. Therefore, there is no mechanism to validate the locally dominant assumption from . One of the main objectives of this paper is to build such a mechanism using a mathematical formulation-based approach. In the following subsection, a novel formulation is presented that can provide the above mechanism.
2.2. Envelope Formulation
In this section, a mathematical model that can simultaneously identify all the extreme vectors of under the locally dominant assumption is proposed. To the best of our knowledge, an exact method that identifies all the extreme vectors in a single shot is unavailable.
Let be the data obtained after normalizing each column of with respect to Norm-2. Let be the ith column of . Let be a plane that is inclined in such a way that all the columns of are contained in one halfspace of the hyperplane, and the origin is in the other halfspace. Such a hyperplane is referred to as linear envelope in this work. The envelope can be written as:
where corresponds to the normal vector of the envelope, and is a constant. Out of infinite possible representations of the above envelope, an envelope with is selected for further analysis. Now, the distance between any vector and the envelope can be written as:
Equation (16) follows from Equation (14). Ignoring the denominator () in Equation (16) results in a proportional or scaled distance (). Among infinite possible linear envelopes, the aim is to find the tightest or supporting envelope. A formulation that can identify the tightest envelope is given as follows:
where is the unknown variable. The above formulation can be equivalently written as:
where is defined as . It is assumed that the duplicate and/or all zero columns of are removed before the execution of the above model. The aim of the above model is to find the envelope that has the minimum distance with respect to all the columns of . The above formulation is linear, and needs to be executed only once to identify all the extreme vectors. That is, at the optimal solution, the data points (’s) corresponding to the active constraints in Equation (19) will correspond to the extreme vectors of . It can be seen that the above formulation is always feasible. Furthermore, due to the design of the constraint given in Equation (19), the problem is linear. That is, the design allowed the usage of proportional distance (Equation (17)) instead of the nonlinear actual distance (Equation (15)).
In addition to that, from the LP theory, only m constraints will be active at the optimal solution. Let be the matrix containing the columns of corresponding to the m active constraints. Identifying the columns of requires the following additional steps: Calculate for . If for , then corresponds to . However, if any element of is strictly less than 0 for any , then it indicates that the locally dominant assumption is invalid for the given . Thus, this serves as a test for the existence of the locally dominant assumption.
The above test works for typical data mixing without noise. However, the image data is usually integer data. There is always rounding, taking place at the source or mixture level. Therefore, the rounding effect needs to be incorporated into the above condition. It is proposed in this paper to follow the heuristic method to incorporate the rounding effect. Let , where is a vector of all ones. The notion is that the rounding will create a maximum error of in each pixel element. Thus, the maximum error in any pixel element will be strictly less than . Therefore, the check for image data will be as follows: If for , then corresponds to .
Furthermore, the above idea can be extended for mixing scenarios containing noise. For instance, a level of tolerance can be used to analyze the noisy mixture data. Let , be a tolerance parameter selected by the user. Then, based on the earlier discussion, the check for noisy data will be as follows: If for , then corresponds to . The precise value of may not be available for a given scenario. Hence, the parameter will be empirically selected based on trial experiments. In Section 5, an experiment that highlights the usage of parameter for noisy data is illustrated.
3. Point Correntropy
Correntropy is a generalized correlation measure based on the concept of entropy. It is typically used in detecting local similarity between two random variables. Roughly speaking, it is a kernelized version of the conventional correlation measure. The measure first appeared in [46,47], and its usage as a cost function was illustrated in [48,49,50,51,52]. The optimization properties of the cost function are presented in [53]. The correntropy cost function (or the correntropic loss) for N errors is defined as:
where is a scaling parameter, is an array of errors, and is the transformation kernel function with parameter . In this work, a Gaussian kernel is selected, i.e., . Equation (23) is readily separable with respect to sample errors, and can be rewritten as:
where , and it will be referred to as point estimate of the correntropic loss.
Let be an error corresponding to the ith column vector of . For a given kernel parameter , the point estimate provides similarity information of the ith vector with respect to the other data vectors of . Based on the geometry of the vectors, the extreme vectors’ similarity with respect to the central vectors should be typically less than the other non-extreme vectors of . Thus, the point estimate of the correntropic loss function can be used as a measure to differentiate extreme and non-extreme vectors of .
4. Solution Methodology
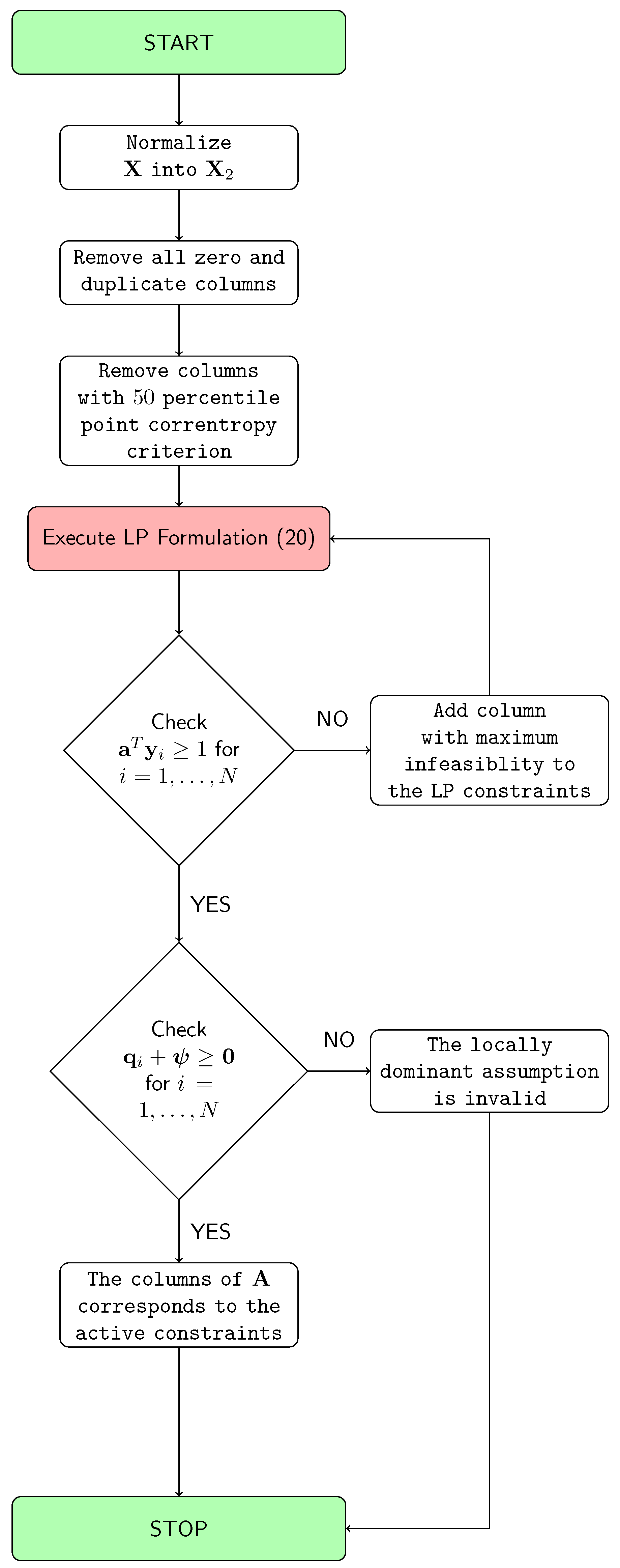
Our goal is to develop a geometric separation method for the non-negative data mixing problem, that can be applied to the “Big Data” scenarios. The concepts developed in Section 2 and Section 3 are tailored with respect to big data, and the following solution approach is proposed. The summary of the proposed approach is illustrated in Figure 2 and Algorithm 1.
| Algorithm 1: The Proposed Algorithm. |
| Data: Given Result: Find and such that = normalize(); Remove all zero columns and duplicate columns from , and say ; Estimate from ; Obtain by removing all columns with the 50 percentile point correntropy criterion from ; Let ; Let be the ith column of ; = Solution of LP Formulation (20) with respect to data ; while do  end Let be the matrix containing the columns of corresponding to the active constraints at the optimal solution of Formulation (20); Calculate for ; Set equal to 0 for non-noisy non-image data mixing, equal to for non-noisy image data mixing, or equal to the user-specified value for noisy mixing.; if then  else  end |
Data Ranking: As seen earlier, the extreme vectors of contain all the relevant information that is needed for separation (i.e., identifying and ). Other data vectors are redundant in identifying the mixing matrix. Thus, the point estimate of the correntropic loss can be evaluated at all the data points with respect to the central columns of . Those data points that have low value of the correntropic loss can be removed from the data set without losing any information. The major issues in implementing the above idea are as follows: how to select the right value for , and how to define corresponding to for .
The value of represents the kernel width, and should be large enough to contain the central vectors. However, it should be small enough to exclude the extreme vectors. In the following, we propose a practical method to estimate the value of . Let be a sample of columns randomly selected from . Let , where is the jth element of . Based on the trial experiments, we found that is a good choice for the kernel width. Furthermore, the value of should correspond to the center of the columns of . An approximate estimate for can be , where , for . Thus, simple (and practical for big data) estimate of error for will be for . Based on the trial experiments, it can be concluded that the larger the size of , the better the estimation. Furthermore, the strategy to eliminate the columns from the trial experiments is as follows. All the columns of that have the point estimate value lower than 50 percentile are removed from further consideration.
Handling a Large Number of Constraints: From Formulation (20), it can be seen that the big data corresponds to a large number of constraints. However, only m constraints are active, and the rest of the constraints are redundant (i.e., the rest of the constraints will never be active). The proposed data ranking method eliminates a good amount of the redundant constraints, depending upon the distribution of columns in the data set.
Let be the data matrix obtained after eliminating possible central vectors, and let be the eliminated central vectors. If the columns of are reorganized, then there exists a partition such that . Once the tightest envelope is obtained for by solving Formulation (20), the envelope is validated with respect to . If all the columns of fall in the same half space (i.e., Equation (14) is feasible with respect to ), then it can be guaranteed that none of the extreme vectors of were eliminated. However, if there is any infeasibility detected, then the column of with maximum infeasibility is added to the LP, and the LP is resolved.
Performance Index: In order to evaluate the performance of the proposed approach, distance-based metrics will be used. Specifically, two metrics (one for the mixing matrix, and the other for the source matrix) will be used in this work. The following error measure is for the mixing matrix:
where is the jth column of the original mixing matrix , and is the corresponding column to , obtained from the recovered mixing matrix . The corresponding columns are identified by the Hungarian algorithm [54]. The source matrix is obtained as follows:
The above approach can be replaced by , whenever exists. Similar to , the following error measure is for the source matrix:
where is the jth row of the original source matrix , and is the corresponding row to , obtained from the recovered source matrix .
5. Numerical Experiments
In order to illustrate the performance of the proposed approach, numerical experiments are presented. The experiments are divided into four groups. In the first group of experiments, simulated non-noisy data is used to test the performance and sensitivity of the proposed approach. In the second group of experiments, image data mixtures are used to test the applicability of the proposed approach on real image data. The third and fourth group of experiments compare the proposed approach with the well known SCA methods in the literature. In all the instances of this section, the following specifications were used: . All the random mixing matrices contain columns with unit norm. The LP resolving step is skipped in order to identify the number of instances in which the extreme vectors were eliminated. The LP was solved via the dual simplex method, using the state of the art Cplex 12.0 solver [55]. All the instances were solved on an Intel Xeon 2.4 GHz workstation, with 16 logical processors and 32 GB of RAM.
5.1. Simulated Data Separation
Setup: Given n and N, a random source matrix that satisfies the locally dominant assumption is generated. For the generated matrix, 100 random mixing matrices are generated. Then, using the equation, 100 random mixture matrices are generated. On each mixture matrix, the proposed approach is implemented. This study is executed for all the following combinations of n and 11, and N = 1000, 5000, 10,000, 50,000, 100,000, 500,000 and 1,000,000. In addition to that, this study is also executed for n and 100 when N = 1,000,000. The value of is set to zero in this experiment.
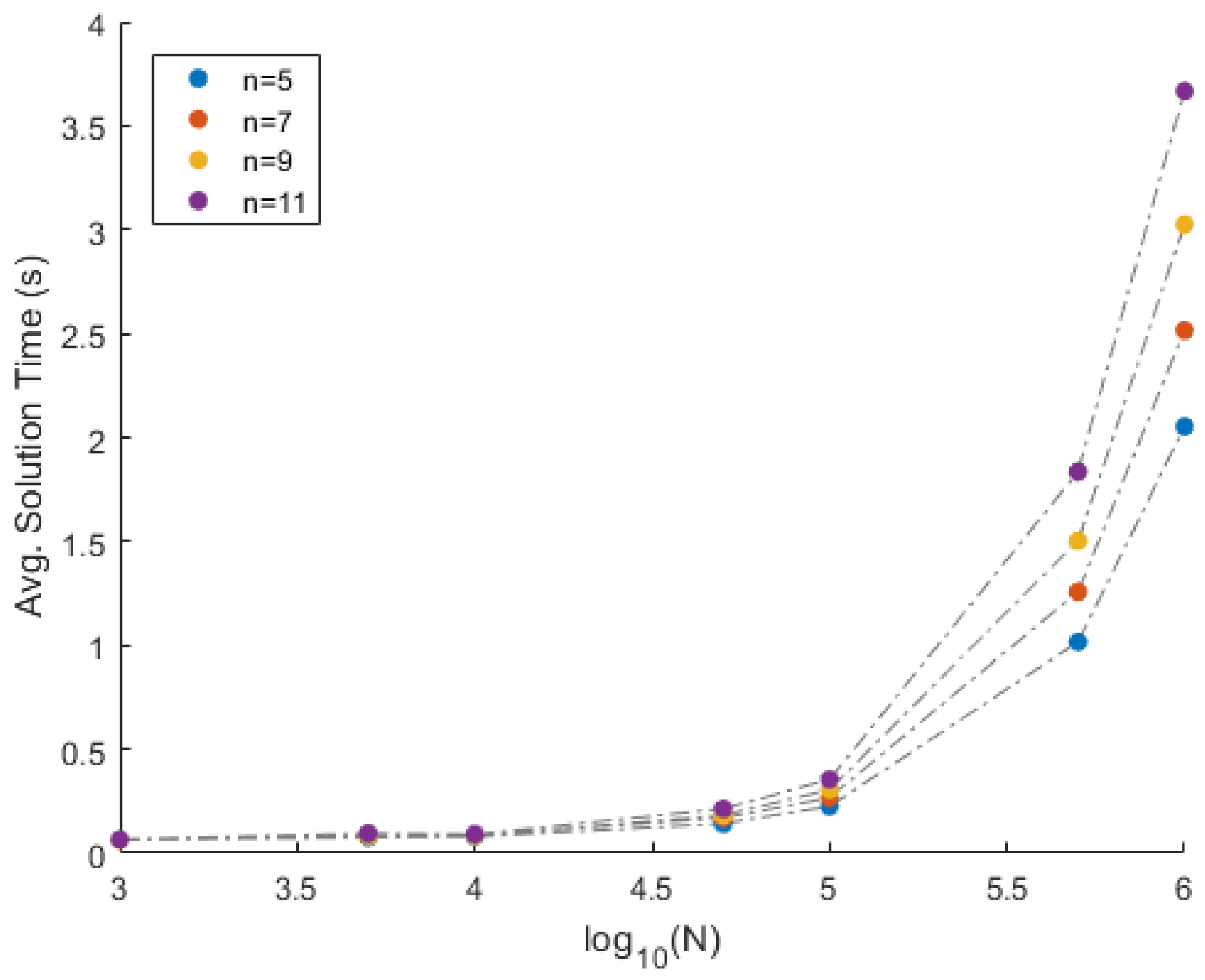
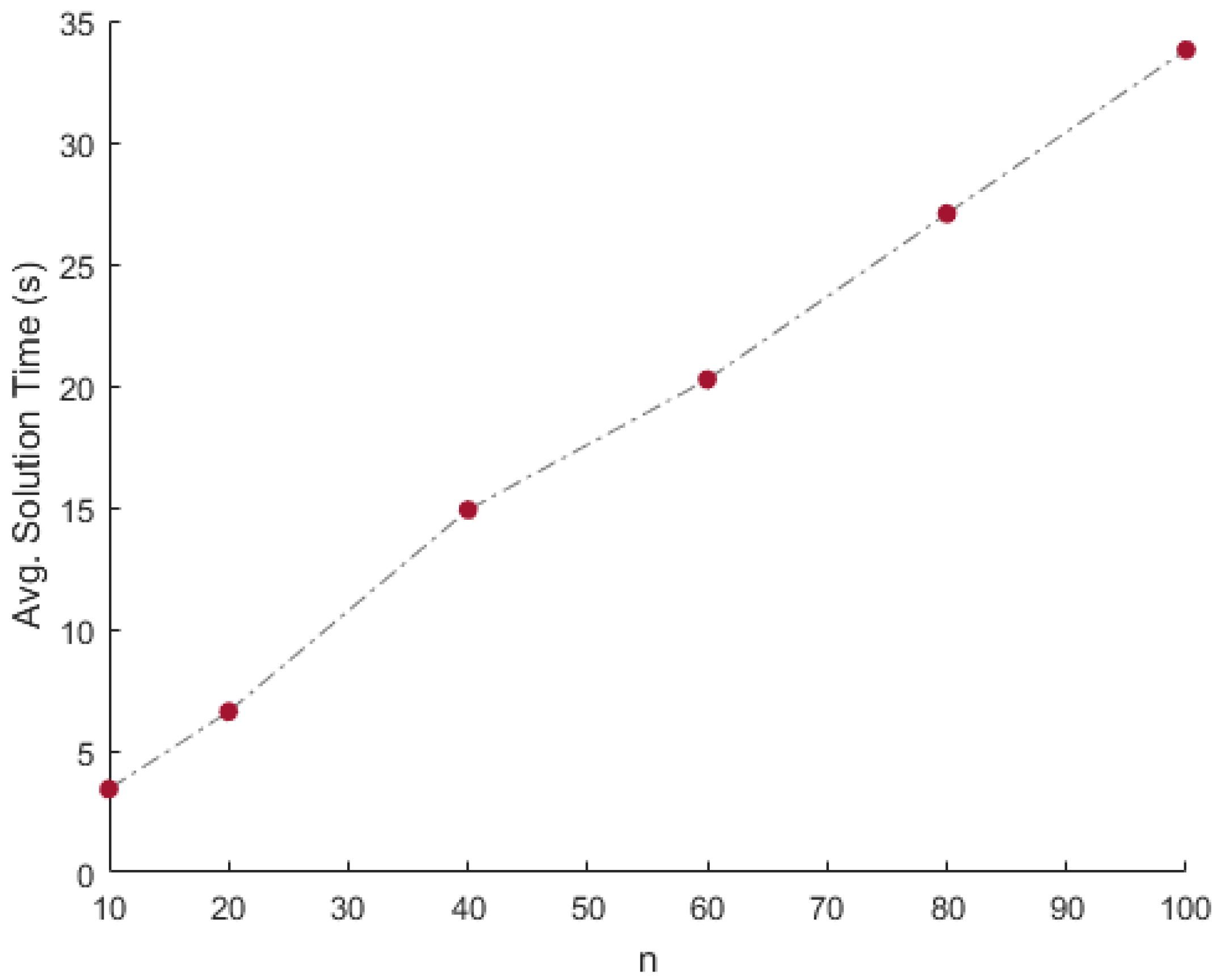
Results: Using one mixture matrix as input, and using the proposed approach, matrices and are recovered. This experiment is repeated 100 times for a given combination of n and N. The performance of the proposed approach is displayed in Table 1. The column corresponding to mErrA (vErrA) indicates the mean (variance) of error over the 100 instances. Similarly, columns mErrS and vErrS correspond to the mean and variance of error respectively. The column corresponding to mTime (vTime) indicates the mean (variance) of the solution time per instance in seconds (milliseconds) over the 100 instances. In addition to that, the column corresponding to mRed (vRed) indicates the mean (variance) of the percentage of columns eliminated over the 100 instances. Finally, the column corresponding to nMiss indicates the number of times the extreme vectors were eliminated based on the 50 percentile criterion. Since the mixtures are clean (i.e., no noise is added to the mixture data), the recovery is perfect. This can be seen from the very low average error (mErrA and mErrS) over the 100 iterations. Furthermore, the method is consistent in the recovery of the matrices, and it can be justified from the low variance in the error (vErrA and vErrS). The suitability and applicability of the proposed approach to big data can be seen from the solution time. For instance, Figure 3 and Figure 4 illustrate the average time in seconds required to solve one instance of the proposed approach for N data points and n data sources. The behavior of the solution time with respect to is exponential. In other words, the solution time increases linearly with respect to N. Furthermore, from Figure 4, it can be observed that the solution time is linear with respect to n. Thus, the algorithm is suitable for big data scenarios. Moreover, the 50 percentile criterion removes exactly 50% of the data points in all the cases, with zero variance. This is due to the fact that the source matrices are uniformly randomly generated. Due to the uniform generation of the source matrices, none of the extreme vectors were eliminated.
5.2. Image Mixture Separation
Setup: In the following experiments, image data available from the literature and online repositories are considered (see Table 2). Each source image of an image set is reshaped into one row vector. Then, the reshaped images are row-wise stacked together to generate the matrix. The source matrices are pre-processed in order to satisfy the locally dominant assumption. Next, for each source matrix , 100 random matrices are generated, and correspondingly 100 random matrices are analyzed using the proposed approach. Table 2 summarizes the details of the image sets that are considered in this subsection. The first column conveys the name of the image set that is being considered. The column corresponding to n indicates the total number of sources, and the column corresponding to N indicates the total data points (or column vectors) in . The value of is set to in this experiment.
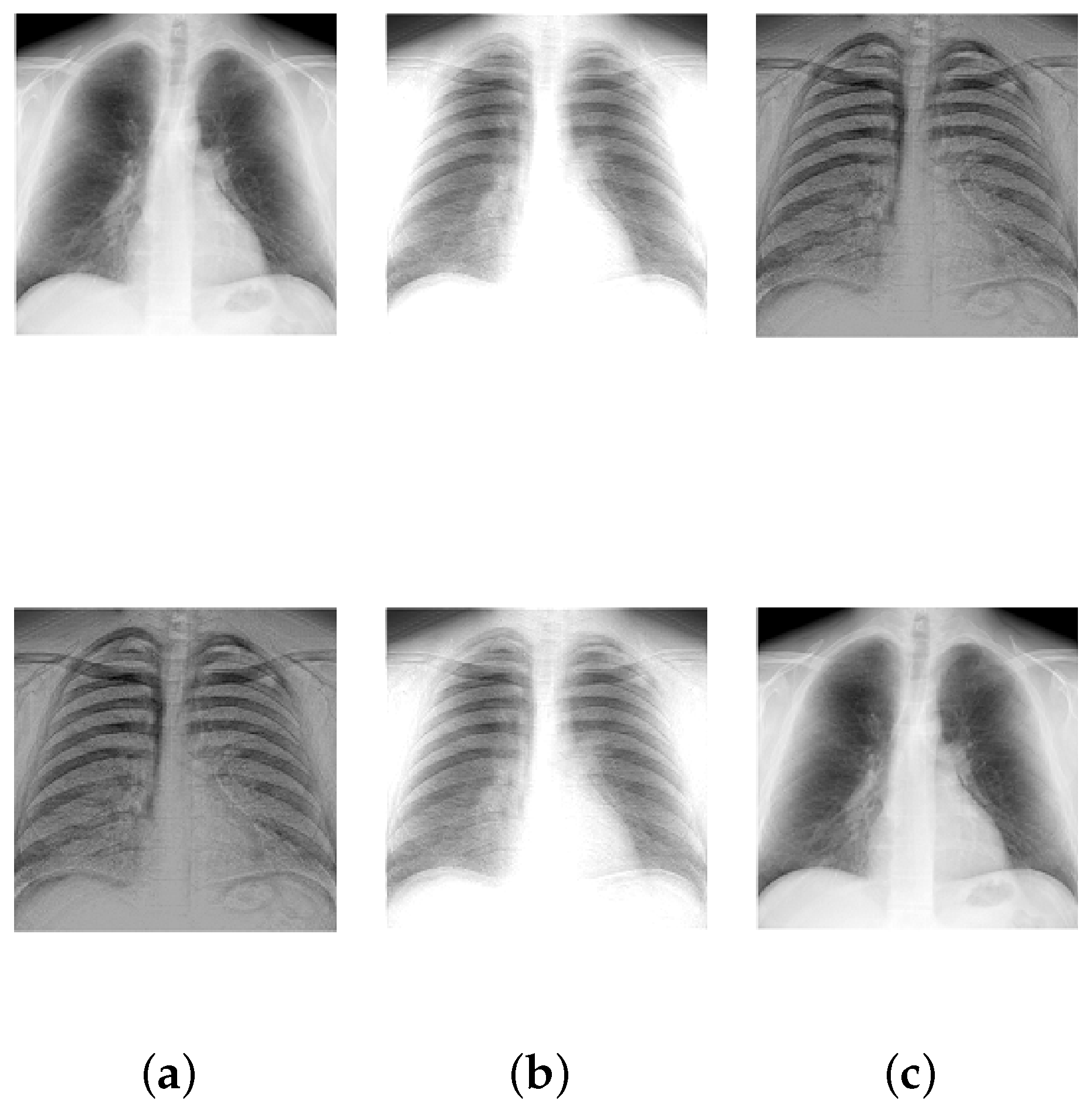
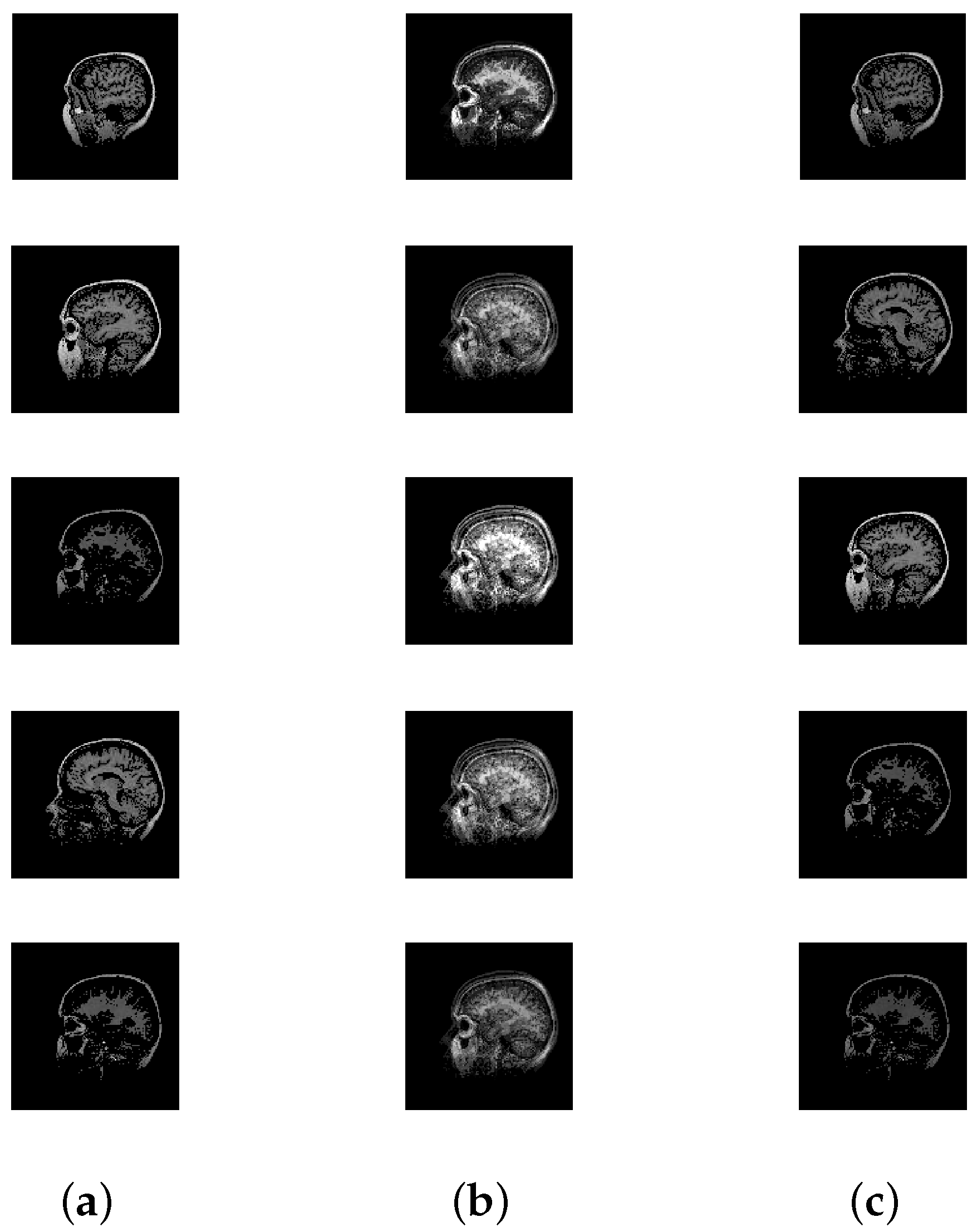
Results: Table 3 displays the results after executing the proposed approach on the 100 mixture instances of each image set. The columns have the notation similar to the earlier experiment, except that the vTime column units are in seconds. Moreover, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9 depict the results. Low mean errors ( and ) over the 100 runs are obtained for all the image sets. This shows that the method precisely recovers and matrices. A low value in the corresponding variance column indicates the high level of consistency of the proposed approach. The solution time, specifically for the finger print data set, indicates the applicability of the proposed approach for big data with complex image mixing scenarios. Based on the results, it can be seen that the 50 percentile criterion eliminates a good amount (more than 50%) of the redundant columns. However, in some instances (at most 7 percentage in one instance), the criterion eliminated some of the extreme vectors.
5.3. Comparative Experiment-I
Setup: Given n and N, a random source matrix that does not satisfy the locally dominant assumption is generated in this experiment. For the generated matrix, 100 random mixing matrices are generated. Then, using the equation, 100 random mixture matrices are generated. This study is executed for n and 15, and for N = 10,000. The value of is set to zero in this experiment. Well known methods from the SCA literature are compared with the proposed approach. The methods that are used for the comparison are N-FINDR ([44]), VCA ([45]), MVSA ([56]). The objective of this experiment is to highlight that the above three (like the other typical algorithms in the literature) do not have the capability to test the locally dominant assumption from the knowledge of . To the best of my knowledge, only an exhaustive search similar to the one presented in [24] can do such a test. However, the proposed approach does not require such an exhaustive search.
Results: Table 4 displays the results after executing the proposed and selected approaches on the 100 randomly generated mixture instances. The column corresponding to mErrA (vErrA) indicates the mean (variance) of error over the 100 instances for the three methods used from the literature. The lines in the column corresponding to ErrA indicate that the proposed approach was unable to identify any mixing matrix. The reason for the lines is the non-existence of the locally dominant assumption in the source data. This information is captured in the column corresponding to TnMiss. The numbers in the TnMiss column indicate the total number of times the proposed approach exited with the “no locally dominant sources” token. Based on the results, it can be seen that the other algorithms try to find the best match for the columns of . However, they are unable to validate the locally dominant assumption. This is due to the fact that no such test is available in the literature. However, in all the scenarios, the proposed approach was able to conclude that the input data is not a mixture of sources that contain the locally dominant signals.
5.4. Comparative Experiment-II
Setup: In this experiment, a random source matrix that satisfies the locally dominant assumption, is generated. For the generated matrix, 100 random mixing matrices are generated. Then, using the equation, 100 random mixture matrices are generated. In each mixture matrix, of the columns are randomly selected, and a uniform noise between 0 and is added to all the elements of the selected columns. This study is executed for n and 15, and for N = 10,000. Well known methods from the SCA literature are compared with the proposed approach. The methods that are used for the comparison are N-FINDR ([44]), VCA ([45]), MVSA ([56]). The objective of this experiment is to comparatively assess the performance of the proposed and selected methods in noisy data. In this experiment, the value of is defined as follows: , where is a vector of all ones, and takes the following values: .
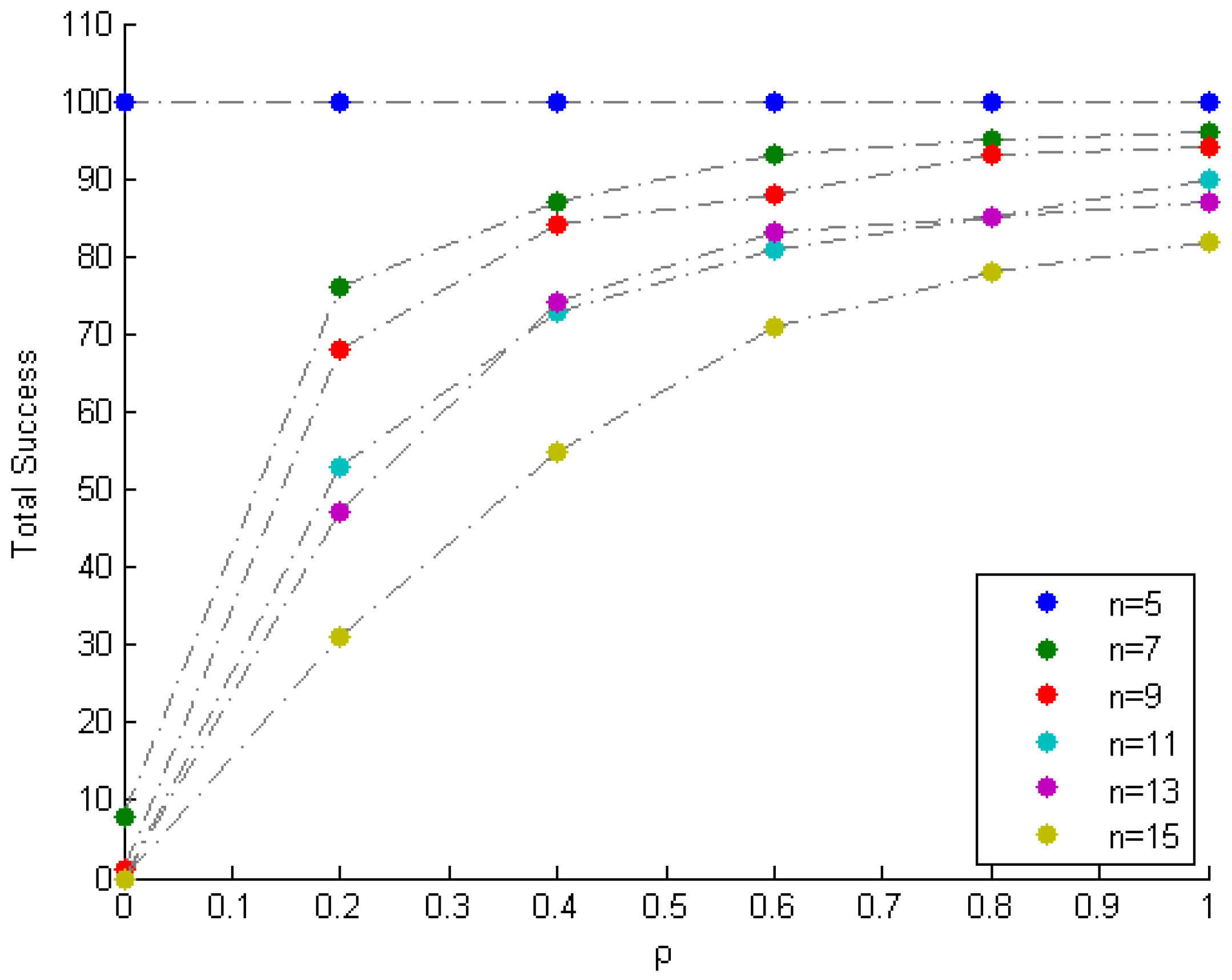
Results: Table 5 displays the results after executing the proposed and selected approaches on the 100 randomly generated noisy mixture instances. The columns corresponding to VCA, MVSA and N-FINDR present the average error over the 100 instances. The proposed approach is executed 100 times for each value of , and the average error for each value of is archived. The column corresponding to the proposed approach presents the best of the average errors over the values of . Table 6 (Figure 10) indicates the total number of times the method fails (succeeds) to identify the mixing matrix, for various values of . Based on the low value of error in the proposed column, and the trends depicted in Figure 10, it can be seen that the proposed approach recovers and in the majority of the noisy instances for higher values of . Moreover, as n increases, the complexity of mixing increases, and thus the proposed approach requires a higher value of for the recovery of and .
6. Discussion and Conclusions
The SCA approaches are relatively new to the BSS problem when compared to the ICA approaches. The main critique that often appears with respect to locally dominant SCA approaches is the validity of the locally dominant criterion. In this paper, a mathematical modeling-based approach is proposed that can validate the existence of the locally dominant criterion from the given mixture matrix. That is, the formulation can be used not only to identify the mixing matrix, but also to validate the assumption presented in Equation (2). Although the approach is proposed for the determined case, it can also be applied to the overdetermined cases. The columns of the matrix are proportional to the number of constraints in the proposed LP. Thus, big data often leads to LP with many redundant constraints. We propose the usage of interior point methods, when the total number of constraints is very high [57]. Moreover, LP decomposition-based approaches for SCA can also be developed to improve the solution time [58]. In addition to that, the LP presolve theory [59] can be designed to eliminate the redundant constraints in the proposed SCA approach. Roughly speaking, the point correntropic ranking method may be seen as a novel probabilistic approach for removing LP redundant constraints. The proposed method of estimating the point correntropy is computationally cheap, and can be applied to the big data scenarios. From the simulated data study, it can be seen that if the input data is uniformly distributed, then the 50 percentile criterion can be raised to a higher value. However, from the image data set, it is clear that the real world data is rarely uniformly distributed. Thus, the 50 percentile criterion is a good estimate to avoid the LP resolving. From the comparative experiments, it can be concluded that the proposed approach validates the locally dominant assumption in non-noisy and noisy mixing scenarios. To summarize, the proposed approach provides new insights into the BSS problem.
Acknowledgments
The author would like to acknowledge the support provided by Deanship of Research (DSR) at King Fahd University of Petroleum & Minerals (KFUPM) for funding this work through Junior Faculty Grant No. JF141010.
Conflicts of Interest
The author declares no conflict of interest.
References
- Joho, M.; Mathis, H.; Lambert, R.H. Overdetermined blind source separation: Using more sensors than source signals in a noisy mixture. In Proceedings of the Independent Component Analysis and Blind Signal Separation, Helsinki, Finlan, 19–22 June 2000; pp. 81–86. [Google Scholar]
- Winter, S.; Sawada, H.; Makino, S. Geometrical interpretation of the PCA subspace approach for overdetermined blind source separation. EURASIP J. Adv. Signal Process. 2006, 2006, 071632. [Google Scholar]
- Bofill, P.; Zibulevsky, M. Underdetermined blind source separation using sparse representations. Signal Process. 2001, 81, 2353–2362. [Google Scholar]
- Zhen, L.; Peng, D.; Yi, Z.; Xiang, Y.; Chen, P. Underdetermined blind source separation using sparse coding. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 3102–3108. [Google Scholar] [CrossRef] [PubMed]
- Herault, J.; Jutten, C.; Ans, B. Detection de Grandeurs Primitives dans un Message Composite par une Architecture de Calcul Neuromimetique en Apprentissage Non Supervise. In 1985—GRETSI—Actes de Colloques; Groupe d’Etudes du Traitement du Signal et des Images: Juan-les-Pins, France, 1985; pp. 1017–1022. [Google Scholar]
- Syed, M.; Georgiev, P.; Pardalos, P. A hierarchical approach for sparse source blind signal separation problem. Comput. Oper. Res. 2012, 41, 386–398. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Karhunen, J.; Oja, E. Independent Component Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 46. [Google Scholar]
- Amari, S.I.; Cichocki, A.; Yang, H.H. A new learning algorithm for blind signal separation. In Proceedings of the 8th International Conference on Neural Information Processing Systems, Denver, CO, USA, 27 November–2 December 1996; pp. 757–763. [Google Scholar]
- Comon, P. Independent component analysis, a new concept? Signal Process. 1994, 36, 287–314. [Google Scholar] [CrossRef] [Green Version]
- Hyvärinen, A. New approximations of differential entropy for independent component analysis and projection pursuit. In Proceedings of the 1997 Conference on Advances in Neural Information Processing Systems, Denver, CO, USA, 1–6 December 1998; pp. 273–279. [Google Scholar]
- Bell, A.J.; Sejnowski, T.J. An information-maximization approach to blind separation and blind deconvolution. Neural Comput. 1995, 7, 1129–1159. [Google Scholar] [CrossRef] [PubMed]
- Chai, R.; Naik, G.R.; Nguyen, T.N.; Ling, S.H.; Tran, Y.; Craig, A.; Nguyen, H.T. Driver fatigue classification with independent component by entropy rate bound minimization analysis in an EEG-based system. IEEE J. Biomed. Health Inform. 2017, 21, 715–724. [Google Scholar] [CrossRef] [PubMed]
- Naik, G.R.; Baker, K.G.; Nguyen, H.T. Dependence independence measure for posterior and anterior EMG sensors used in simple and complex finger flexion movements: Evaluation using SDICA. IEEE J. Biomed. Health Inform. 2015, 19, 1689–1696. [Google Scholar] [CrossRef] [PubMed]
- Naik, G.R.; Al-Timemy, A.H.; Nguyen, H.T. Transradial amputee gesture classification using an optimal number of sEMG sensors: An approach using ICA clustering. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 837–846. [Google Scholar]
- Deslauriers, J.; Ansado, J.; Marrelec, G.; Provost, J.S.; Joanette, Y. Increase of posterior connectivity in aging within the Ventral Attention Network: A functional connectivity analysis using independent component analysis. Brain Res. 2017, 1657, 288–296. [Google Scholar] [CrossRef] [PubMed]
- O’Muircheartaigh, J.; Jbabdi, S. Concurrent white matter bundles and grey matter networks using independent component analysis. NeuroImage 2017. [Google Scholar] [CrossRef] [PubMed]
- Hand, B.N.; Dennis, S.; Lane, A.E. Latent constructs underlying sensory subtypes in children with autism: A preliminary study. Autism Res. 2017, 10, 1364–1371. [Google Scholar] [CrossRef] [PubMed]
- Arya, Y. AGC performance enrichment of multi-source hydrothermal gas power systems using new optimized FOFPID controller and redox flow batteries. Energy 2017, 127, 704–715. [Google Scholar]
- Al-Ali, A.K.H.; Senadji, B.; Naik, G.R. Enhanced forensic speaker verification using multi-run ICA in the presence of environmental noise and reverberation conditions. In Proceedings of the 2017 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuching, Malaysia, 12–14 September 2017; pp. 174–179. [Google Scholar]
- Comon, P.; Jutten, C. Handbook of Blind Source Separation: Independent Component Analysis and Applications; Academic Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Nascimento, J.M.; Dias, J.M. Does independent component analysis play a role in unmixing hyperspectral data? IEEE Trans. Geosci. Remote Sens. 2005, 43, 175–187. [Google Scholar] [CrossRef]
- Syed, M.; Georgiev, P.; Pardalos, P. Robust Physiological Mappings: From Non-Invasive to Invasive. Cybern. Syst. Anal. 2015, 1, 96–104. [Google Scholar]
- Georgiev, P.; Theis, F.; Cichocki, A.; Bakardjian, H. Sparse component analysis: A new tool for data mining. In Data Mining Biomedicine; Springer: Boston, MA, USA, 2007; pp. 91–116. [Google Scholar]
- Naanaa, W.; Nuzillard, J. Blind source separation of positive and partially correlated data. Signal Process. 2005, 85, 1711–1722. [Google Scholar] [CrossRef]
- Chan, T.H.; Ma, W.K.; Chi, C.Y.; Wang, Y. A convex analysis framework for blind separation of non-negative sources. IEEE Trans. Signal Process. 2008, 56, 5120–5134. [Google Scholar] [CrossRef]
- Chan, T.H.; Chi, C.Y.; Huang, Y.M.; Ma, W.K. A convex analysis-based minimum-volume enclosing simplex algorithm for hyperspectral unmixing. IEEE Trans. Signal Process. 2009, 57, 4418–4432. [Google Scholar] [CrossRef]
- Syed, M.N.; Georgiev, P.G.; Pardalos, P.M. Blind Signal Separation Methods in Computational Neuroscience. In Modern Electroencephalographic Assessment Techniques: Theory and Applications; Humana Press: New York, NY, USA, 2015; pp. 291–322. [Google Scholar]
- Ma, W.K.; Bioucas-Dias, J.M.; Chan, T.H.; Gillis, N.; Gader, P.; Plaza, A.J.; Ambikapathi, A.; Chi, C.Y. A signal processing perspective on hyperspectral unmixing: Insights from remote sensing. IEEE Signal Process. Mag. 2014, 31, 67–81. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Yin, P.; Sun, Y.; Xin, J. A geometric blind source separation method based on facet component analysis. Signal Image Video Process. 2016, 10, 19–28. [Google Scholar] [CrossRef]
- Lin, C.H.; Chi, C.Y.; Wang, Y.H.; Chan, T.H. A Fast Hyperplane-Based Minimum-Volume Enclosing Simplex Algorithm for Blind Hyperspectral Unmixing. IEEE Trans. Signal Process. 2016, 64, 1946–1961. [Google Scholar] [CrossRef]
- Zhang, S.; Agathos, A.; Li, J. Robust Minimum Volume Simplex Analysis for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6431–6439. [Google Scholar] [CrossRef]
- Naanaa, W.; Nuzillard, J.M. Extreme direction analysis for blind separation of nonnegative signals. Signal Process. 2017, 130, 254–267. [Google Scholar]
- Sun, Y.; Ridge, C.; Del Rio, F.; Shaka, A.; Xin, J. Postprocessing and sparse blind source separation of positive and partially overlapped data. Signal Process. 2011, 91, 1838–1851. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. On the uniqueness of overcomplete dictionaries, and a practical way to retrieve them. Linear Algebra Appl. 2006, 416, 48–67. [Google Scholar] [CrossRef]
- Georgiev, P.; Theis, F.; Ralescu, A. Identifiability conditions and subspace clustering in sparse BSS. In Independent Component Analysis and Signal Separation; Springer: Berlin/Heidelberg, Germany, 2007; pp. 357–364. [Google Scholar]
- Drumetz, L.; Veganzones, M.A.; Henrot, S.; Phlypo, R.; Chanussot, J.; Jutten, C. Blind hyperspectral unmixing using an Extended Linear Mixing Model to address spectral variability. IEEE Trans. Image Process. 2016, 25, 3890–3905. [Google Scholar] [CrossRef] [PubMed]
- Amini, F.; Hedayati, Y. Underdetermined blind modal identification of structures by earthquake and ambient vibration measurements via sparse component analysis. J. Sound Vib. 2016, 366, 117–132. [Google Scholar] [CrossRef]
- Gribonval, R.; Schnass, K. Dictionary Identification—Sparse Matrix-Factorization via l1-Minimization. IEEE Trans. Inf. Theory 2010, 56, 3523–3539. [Google Scholar]
- Kreutz-Delgado, K.; Murray, J.; Rao, B.; Engan, K.; Lee, T.; Sejnowski, T. Dictionary learning algorithms for sparse representation. Neural Comput. 2003, 15, 349–396. [Google Scholar] [CrossRef] [PubMed]
- Nascimento, J.M.; Bioucas-Dias, J.M. Blind hyperspectral unmixing. In Proceedings of the SPIE Conference on Image and Signal Processing for Remote Sensing XIII, Florence, Italy, 18–20 September 2007. [Google Scholar]
- Duarte, L.T.; Moussaoui, S.; Jutten, C. Source separation in chemical analysis: Recent achievements and perspectives. IEEE Signal Process. Mag. 2014, 31, 135–146. [Google Scholar] [CrossRef]
- Sun, Y.; Xin, J. Nonnegative Sparse Blind Source Separation for NMR Spectroscopy by Data Clustering, Model Reduction, and ℓ1 Minimization. SIAM J. Imag. Sci. 2012, 5, 886–911. [Google Scholar] [CrossRef]
- Winter, M.E. N-FINDR: An algorithm for fast autonomous spectral end-member determination in hyperspectral data. In Proceedings of the Imaging Spectrometry V, Denver, CO, USA, 19–21 July 1999; pp. 266–275. [Google Scholar]
- Nascimento, J.M.; Dias, J.M. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef]
- Santamaria, I.; Pokharel, P.P.; Principe, J.C. Generalized correlation function: Definition, properties, and application to blind equalization. IEEE Trans. Signal Process. 2006, 54, 2187–2197. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.P.; Príncipe, J.C. Correntropy: Properties and applications in non-Gaussian signal processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Singh, A.; Principe, J.C. Using correntropy as a cost function in linear adaptive filters. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 2950–2955. [Google Scholar]
- Zhao, S.; Chen, B.; Principe, J.C. Kernel adaptive filtering with maximum correntropy criterion. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 2012–2017. [Google Scholar]
- Chen, B.; Xing, L.; Liang, J.; Zheng, N.; Principe, J.C. Steady-state mean-square error analysis for adaptive filtering under the maximum correntropy criterion. IEEE Signal Process. Lett. 2014, 21, 880–884. [Google Scholar]
- Chen, B.; Xing, L.; Zhao, H.; Zheng, N.; Principe, J.C. Generalized correntropy for robust adaptive filtering. IEEE Trans. Signal Process. 2016, 64, 3376–3387. [Google Scholar] [CrossRef]
- Chen, B.; Liu, X.; Zhao, H.; Principe, J.C. Maximum correntropy Kalman filter. Automatica 2017, 76, 70–77. [Google Scholar] [CrossRef]
- Syed, M.N.; Pardalos, P.M.; Principe, J.C. On the optimization properties of the correntropic loss function in data analysis. Optim. Lett. 2014, 8, 823–839. [Google Scholar] [CrossRef]
- Kuhn, H.W. The hungarian metRhod for the assignment problem. In 50 Years of Integer Programming 1958–2008; Springer: Berlin, Germany, 2010; pp. 29–47. [Google Scholar]
- Cplex, I. User-Manual CPLEX; IBM Software Group: New York, NY, USA, 2011; Volume 12. [Google Scholar]
- Li, J.; Bioucas-Dias, J.M. Minimum volume simplex analysis: A fast algorithm to unmix hyperspectral data. In Proceedings of the 2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; Volume 3. [Google Scholar] [CrossRef]
- Terlaky, T. Interior Point Methods of Mathematical Programming; Springer Science & Business Media: Berlin, Germany, 2013; Volume 5. [Google Scholar]
- Dantzig, G.B.; Thapa, M.N. Linear Programming 2: Theory and Extensions; Springer Science & Business Media: Berlin, Germany, 2006. [Google Scholar]
- Andersen, E.D.; Andersen, K.D. Presolving in linear programming. Math. Program. 1995, 71, 221–245. [Google Scholar] [CrossRef]
Figure 1.
Overview of the “Blind” Signal Separation (BSS) problem.

Figure 2.
The proposed approach.

Figure 3.
Time VS comparison on the simulated data.

Figure 4.
Time vs. n comparison on the simulated data.

Figure 5.
Mixing and unmixing of chest X-rays. (a) Original; (b) Mixture; (c) Recovered.

Figure 6.
Mixing and unmixing of scenery. (a) Original; (b) Mixture; (c) Recovered.

Figure 7.
Mixing and unmixing of a CT scan. (a) Original; (b) Mixture; (c) Recovered.

Figure 8.
Mixing and unmixing of zip codes. (a) Original; (b) Mixture; (c) Recovered.

Figure 9.
Mixing and unmixing of a finger print. (a) Original; (b) Mixture; (c) Recovered.

Figure 10.
Total success vs. (the tolerance parameter).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Performance of the proposed approach on the simulated data.
| n × N | mErrA | vErrA | mErrS | vErrS | mTime | vTime | mRed | vRed | nMiss |
|---|---|---|---|---|---|---|---|---|---|
| 5 × 1000 | 1.04 × 10 | 9.78 × 10 | 1.17 × 10 | 4.76 × 10 | 0.0647 | 0.07095 | 50 | 0 | 0 |
| 5 × 5000 | 1.08 × 10 | 1.16 × 10 | 2.03 × 10 | 5.24 × 10 | 0.0756 | 0.04114 | 50 | 0 | 0 |
| 5 × 10,000 | 1.07 × 10 | 1.26 × 10 | 9.50 × 10 | 1.88 × 10 | 0.08 | 0.16436 | 50 | 0 | 0 |
| 5 × 50,000 | 1.10 × 10 | 1.13 × 10 | 5.10 × 10 | 5.39 × 10 | 0.1427 | 0.09452 | 50 | 0 | 0 |
| 5 × 100,000 | 1.02 × 10 | 8.22 × 10 | 4.85 × 10 | 3.21 × 10 | 0.2254 | 0.12459 | 50 | 0 | 0 |
| 5 × 500,000 | 1.01 × 10 | 9.28 × 10 | 1.81 × 10 | 6.50 × 10 | 1.0166 | 2.2 | 50 | 0 | 0 |
| 5 × 1,000,000 | 1.03 × 10 | 1.11 × 10 | 1.19 × 10 | 8.55 × 10 | 2.0526 | 1.9 | 50 | 0 | 0 |
| 7 × 1000 | 7.28 × 10 | 3.47 × 10 | 1.30 × 10 | 3.41 × 10 | 0.0641 | 0.05835 | 50 | 0 | 0 |
| 7 × 5000 | 6.85 × 10 | 2.72 × 10 | 1.71 × 10 | 1.08 × 10 | 0.0816 | 0.06362 | 50 | 0 | 0 |
| 7 × 10,000 | 6.86 × 10 | 2.28 × 10 | 1.01 × 10 | 7.70 × 10 | 0.0891 | 0.11015 | 50 | 0 | 0 |
| 7 × 50,000 | 7.08 × 10 | 1.89 × 10 | 7.05 × 10 | 4.27 × 10 | 0.1689 | 0.14786 | 50 | 0 | 0 |
| 7 × 100,000 | 6.78 × 10 | 2.46 × 10 | 1.14 × 10 | 5.67 × 10 | 0.2675 | 0.14104 | 50 | 0 | 0 |
| 7 × 500,000 | 7.26 × 10 | 2.61 × 10 | 6.11 × 10 | 1.80 × 10 | 1.2584 | 1.3 | 50 | 0 | 0 |
| 7 × 1,000,000 | 6.85 × 10 | 2.62 × 10 | 9.93 × 10 | 1.77 × 10 | 2.5154 | 3.3 | 50 | 0 | 0 |
| 9 × 1000 | 5.50 × 10 | 1.05 × 10 | 1.59 × 10 | 2.94 × 10 | 0.067 | 0.10896 | 50 | 0 | 0 |
| 9 × 5000 | 5.82 × 10 | 1.42 × 10 | 2.44 × 10 | 1.96 × 10 | 0.0812 | 0.05954 | 50 | 0 | 0 |
| 9 × 10,000 | 5.62 × 10 | 1.30 × 10 | 8.13 × 10 | 4.63 × 10 | 0.0835 | 0.08635 | 50 | 0 | 0 |
| 9 × 50,000 | 5.52 × 10 | 1.38 × 10 | 2.62 × 10 | 5.69 × 10 | 0.1821 | 0.12421 | 50 | 0 | 0 |
| 9 × 100,000 | 5.57 × 10 | 1.31 × 10 | 3.79 × 10 | 1.68 × 10 | 0.3066 | 0.1855 | 50 | 0 | 0 |
| 9 × 500,000 | 5.40 × 10 | 1.36 × 10 | 9.78 × 10 | 1.84 × 10 | 1.5029 | 1 | 50 | 0 | 0 |
| 9 × 1,000,000 | 5.32 × 10 | 1.21 × 10 | 1.49 × 10 | 2.10 × 10 | 3.0258 | 3.1 | 50 | 0 | 0 |
| 11 × 1000 | 4.05 × 10 | 4.77 × 10 | 1.75 × 10 | 3.13 × 10 | 0.0672 | 0.02826 | 50 | 0 | 0 |
| 11 × 5000 | 4.16 × 10 | 5.04 × 10 | 2.03 × 10 | 9.47 × 10 | 0.096 | 0.10778 | 50 | 0 | 0 |
| 11 × 10,000 | 4.21 × 10 | 4.87 × 10 | 1.31 × 10 | 7.33 × 10 | 0.0916 | 0.00928 | 50 | 0 | 0 |
| 11 × 50,000 | 4.09 × 10 | 5.02 × 10 | 6.61 × 10 | 2.97 × 10 | 0.2137 | 0.05729 | 50 | 0 | 0 |
| 11 × 100,000 | 4.12 × 10 | 3.79 × 10 | 1.90 × 10 | 6.92 × 10 | 0.355 | 0.25758 | 50 | 0 | 0 |
| 11 × 500,000 | 4.14 × 10 | 3.96 × 10 | 1.18 × 10 | 1.66 × 10 | 1.8358 | 0.69888 | 50 | 0 | 0 |
| 11 × 1,000,000 | 4.21 × 10 | 4.37 × 10 | 8.91 × 10 | 8.11 × 10 | 3.667 | 5.4 | 50 | 0 | 0 |
| 10 × 1,000,000 | 4.71 × 10 | 7.54 × 10 | 8.46 × 10 | 8.89 × 10 | 3.4245 | 2.5 | 50 | 0 | 0 |
| 20 × 1,000,000 | 1.83 × 10 | 5.10 × 10 | 1.12 × 10 | 6.32 × 10 | 6.6053 | 9.3 | 50 | 0 | 0 |
| 40 × 1,000,000 | 7.84 × 10 | 5.33 × 10 | 4.22 × 10 | 9.61 × 10 | 14.8988 | 64.8 | 50 | 0 | 0 |
| 60 × 1,000,000 | 7.32 × 10 | 4.62 × 10 | 1.05 × 10 | 2.18 × 10 | 20.2509 | 628.9 | 50 | 0 | 0 |
| 80 × 1,000,000 | 6.51 × 10 | 6.39 × 10 | 7.51 × 10 | 1.40 × 10 | 27.0654 | 101.7 | 50 | 0 | 0 |
| 100 × 1,000,000 | 5.13 × 10 | 2.83 × 10 | 4.65 × 10 | 5.57 × 10 | 33.7978 | 136.6 | 50 | 0 | 0 |
Table 2.
Image Mixture Separation Data.
| Image Set | n | N |
|---|---|---|
| Chest X-rays | 2 | 26,896 |
| Scenery | 3 | 65,536 |
| CT Scans | 5 | 16,384 |
| Zip Codes | 7 | 12,672 |
| Finger Print | 9 | 90,000 |
Table 3.
Image mixture separation results.
| Image Set | mErrA | vErrA | mErrS | vErrS | mTime | vTime | mRed | vRed | nMiss |
|---|---|---|---|---|---|---|---|---|---|
| Chest X-rays | 2.45 × 10 | 2.81 × 10 | 1.33 × 10 | 2.02 × 10 | 0.0755 | 4.89 × 10 | 81.632 | 0.0101 | 0 |
| Scenery | 2.06 × 10 | 5.30 × 10 | 4.10 × 10 | 4.12 × 10 | 0.109 | 9.81 × 10 | 73.2417 | 0.0033 | 7 |
| CT Scan | 1.19 × 10 | 9.09 × 10 | 4.80 × 10 | 1.20 × 10 | 0.0679 | 1.34 × 10 | 89.7026 | 0.0012 | 4 |
| Zip Codes | 7.36 × 10 | 2.61 × 10 | 4.96 × 10 | 8.17 × 10 | 0.0787 | 3.74 × 10 | 74.0513 | 0.0047 | 6 |
| Finger Print | 5.72 × 10 | 1.19 × 10 | 1.67 × 10 | 2.23 × 10 | 0.2716 | 1.57 × 10 | 55.952 | 6.49 × 10 | 0 |
Table 4.
Comparative experiment-I separation results.
| n | N | VCA | MVSA | N-FINDR | Proposed | ||||
|---|---|---|---|---|---|---|---|---|---|
| mErrA | vErrA | mErrA | vErrA | mErrA | vErrA | ErrA | TnMiss | ||
| 5 | 10,000 | 0.0755 | 7.08 × 10 | 0.0813 | 6.65 × 10 | 0.0905 | 4.14 × 10 | — | 100 |
| 7 | 10,000 | 0.056 | 9.63 × 10 | 0.0567 | 2.6 × 10 | 0.0604 | 7.23 × 10 | — | 100 |
| 9 | 10,000 | 0.0422 | 2.96 × 10 | 0.0402 | 1.13 × 10 | 0.0441 | 1.34 × 10 | — | 100 |
| 11 | 10,000 | 0.0333 | 8.56 × 10 | 0.0314 | 4.16 × 10 | 0.0342 | 7.16 × 10 | — | 100 |
| 13 | 10,000 | 0.0269 | 3.28 × 10 | 0.0252 | 1.56 × 10 | 0.0274 | 3.6 × 10 | — | 100 |
| 15 | 10,000 | 0.0223 | 1.52 × 10 | 0.0212 | 7.53 × 10 | 0.0226 | 1.8 × 10 | — | 100 |
Table 5.
Comparative experiment-II separation results.
| n | N | VCA | MVSA | N-FINDR | Proposed |
|---|---|---|---|---|---|
| 5 | 10,000 | 0.0798 | 0.0872 | 0.0954 | 6.43 × |
| 7 | 10,000 | 0.0573 | 0.045 | 0.0658 | 4.73 × |
| 9 | 10,000 | 0.0407 | 0.0309 | 0.0467 | 3.77 × |
| 11 | 10,000 | 0.0321 | 0.0265 | 0.0357 | 0.0012 |
| 13 | 10,000 | 0.0255 | 0.0231 | 0.0284 | 0.0007 |
| 15 | 10,000 | 0.0212 | 0.0197 | 0.0235 | 0.0021 |
Table 6.
Effect of parameter on the total number of failures.
| n | N | = 0 | = 0.2 | = 0.4 | = 0.6 | = 0.8 | = 1 |
|---|---|---|---|---|---|---|---|
| 5 | 10,000 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 10,000 | 92 | 24 | 13 | 7 | 5 | 4 |
| 9 | 10,000 | 99 | 32 | 16 | 12 | 7 | 6 |
| 11 | 10,000 | 100 | 47 | 27 | 19 | 15 | 10 |
| 13 | 10,000 | 100 | 53 | 26 | 17 | 15 | 13 |
| 15 | 10,000 | 100 | 69 | 45 | 29 | 22 | 18 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Syed, M.N. Big Data Blind Separation. Entropy 2018, 20, 150. https://doi.org/10.3390/e20030150
AMA Style
Syed MN. Big Data Blind Separation. Entropy. 2018; 20(3):150. https://doi.org/10.3390/e20030150
Chicago/Turabian StyleSyed, Mujahid N. 2018. "Big Data Blind Separation" Entropy 20, no. 3: 150. https://doi.org/10.3390/e20030150
APA StyleSyed, M. N. (2018). Big Data Blind Separation. Entropy, 20(3), 150. https://doi.org/10.3390/e20030150
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.