Methods and Challenges in Shot Boundary Detection: A Review

 , ,
, ,
Abstract
:1. Introduction
2. Fundamentals of SBD
2.1. Video Definition
2.2. Video Hierarchy
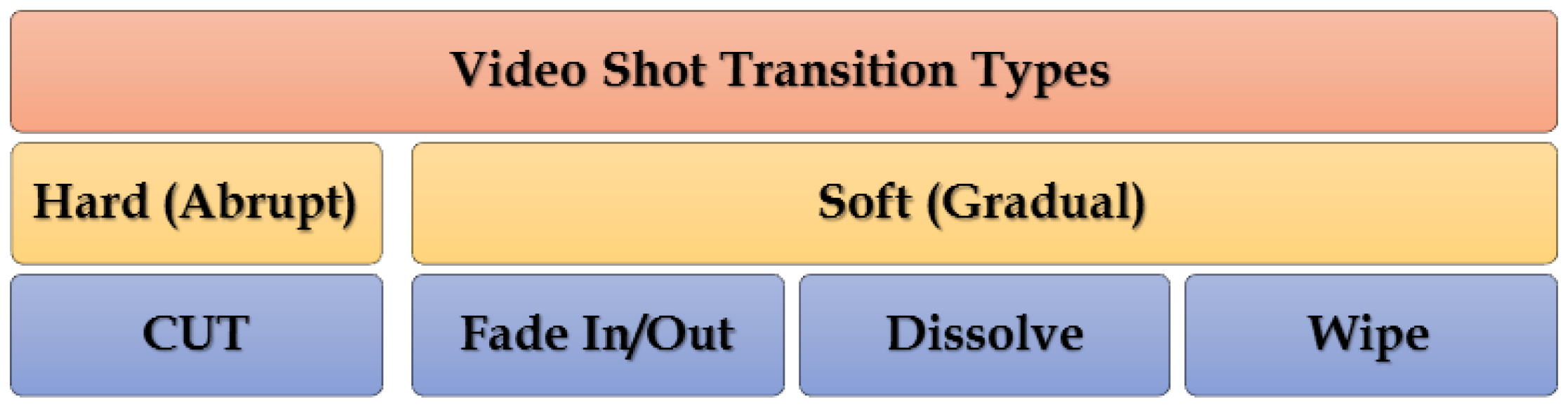
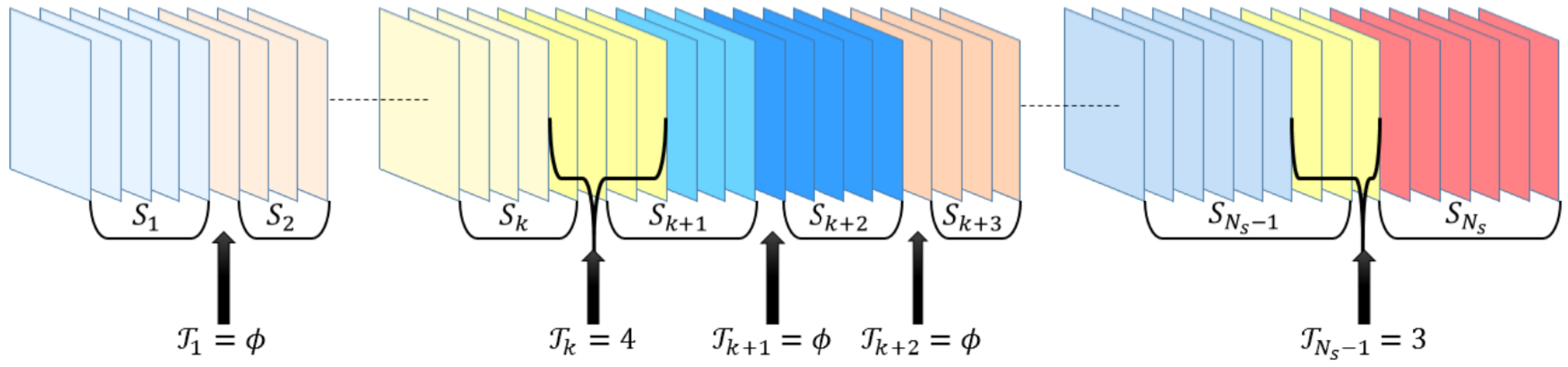
2.3. Video Transition Types
2.3.1. HT
2.3.2. ST
3. Compressed Doamin vs. Uncompressed Domain
4. SBD Modules
4.1. Representation of Visual Information (ROVI)
4.2. Construction of Dissimilarity/Similarity Signal (CDSS)
4.3. Classification of Dissimilarity/Similarity Signal (CLDS)
5. SBD approaches
5.1. Pixel-Based Approach
5.2. Histogram-Based Approaches
5.3. Edge-Based Approaches
5.4. Transform-Based Approaches
5.5. Motion-Based Approaches
5.6. Statistical-Based Approaches
5.7. Different Aspects of SBD Approaches
5.7.1. Video Rhythm Based Algorithms
5.7.2. Linear Algebra Based Algorithms
5.7.3. Information Based Algorithms
5.7.4. Deep Learning Based Algorithms
5.7.5. Frame Skipping Technique Based Algorithms
5.7.6. Mixed Method Approaches
6. SBD Evaluation Metrics
6.1. SBD Accuracy Metrics
6.2. SBD Computation Cost
6.3. Dataset
7. Open Challenges
7.1. Sudden Illuminance Change
7.2. Dim Lighting Frames
7.3. Comparable Background Frames
7.4. Object and Camera Motion
7.5. Changes in Small Regions (CSRs)
8. Unrevealed Issues and Future Direction
9. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Birinci, M.; Kiranyaz, S. A perceptual scheme for fully automatic video shot boundary detection. Signal Process. Image Commun. 2014, 29, 410–423. [Google Scholar] [CrossRef]
- Gonzalez-Diaz, I.; Martinez-Cortes, T.; Gallardo-Antolin, A.; Diaz-de Maria, F. Temporal segmentation and keyframe selection methods for user-generated video search-based annotation. Expert Syst. Appl. 2015, 42, 488–502. [Google Scholar] [CrossRef] [Green Version]
- Priya, R.; Shanmugam, T.N. A comprehensive review of significant researches on content based indexing and retrieval of visual information. Front. Comput. Sci. 2013, 7, 782–799. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, H.; Xiao, L.; Zheng, W.; Li, J.; Lin, F.; Zhang, B. A formal study of shot boundary detection. IEEE Trans. Circ. Syst. Video Technol. 2007, 17, 168–186. [Google Scholar] [CrossRef]
- Palmer, S.E. Vision Science: Photons to Phenomenology; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Del Fabro, M.; Böszörmenyi, L. State-of-the-art and future challenges in video scene detection: A survey. Multimedia Syst. 2013, 19, 427–454. [Google Scholar] [CrossRef]
- Fayk, M.B.; El Nemr, H.A.; Moussa, M.M. Particle swarm optimisation based video abstraction. J. Adv. Res. 2010, 1, 163–167. [Google Scholar] [CrossRef]
- Parmar, M.; Angelides, M.C. MAC-REALM: A Video Content Feature Extraction and Modelling Framework. Comput. J. 2015, 58, 2135–2170. [Google Scholar] [CrossRef]
- Hu, W.; Xie, N.; Li, L.; Zeng, X.; Maybank, S. A Survey on Visual Content-Based Video Indexing and Retrieval. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2011, 41, 797–819. [Google Scholar]
- Choroś, K. Improved Video Scene Detection Using Player Detection Methods in Temporally Aggregated TV Sports News. In Proceedings of the 6th International Conference on Computational Collective Intelligence. Technologies and Applications, ICCCI 2014, Seoul, Korea, 24–26 September 2014; Hwang, D., Jung, J.J., Nguyen, N.T., Eds.; Springer International Publishing: Cham, Switzerland, 2014. Chapter Improved V. pp. 633–643. [Google Scholar]
- Bhaumik, H.; Bhattacharyya, S.; Nath, M.D.; Chakraborty, S. Hybrid soft computing approaches to content based video retrieval: A brief review. Appl. Soft Comput. 2016, 46, 1008–1029. [Google Scholar] [CrossRef]
- Midya, A.; Sengupta, S. Switchable video error concealment using encoder driven scene transition detection and edge preserving SEC. Multimedia Tools Appl. 2015, 74, 2033–2054. [Google Scholar] [CrossRef]
- Liu, T.; Kender, J.R. Computational approaches to temporal sampling of video sequences. ACM Trans. Multimedia Comput. Commun. Appl. (TOMM) 2007, 3, 7. [Google Scholar] [CrossRef]
- Trichet, R.; Nevatia, R.; Burns, B. Video event classification with temporal partitioning. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar]
- Lu, Z.M.; Shi, Y. Fast video shot boundary detection based on SVD and pattern matching. IEEE Trans. Image Process. 2013, 22, 5136–5145. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Wang, D.; Zhu, J.; Zhang, B. Learning a Contextual Multi-Thread Model for Movie/TV Scene Segmentation. IEEE Trans Multimedia 2013, 15, 884–897. [Google Scholar]
- Tavassolipour, M.; Karimian, M.; Kasaei, S. Event Detection and Summarization in Soccer Videos Using Bayesian Network and Copula. IEEE Trans. Circ. Syst. Video Technol. 2014, 24, 291–304. [Google Scholar] [CrossRef]
- Gao, G.; Ma, H. To accelerate shot boundary detection by reducing detection region and scope. Multimedia Tools Appl. 2014, 71, 1749–1770. [Google Scholar] [CrossRef]
- Pal, G.; Rudrapaul, D.; Acharjee, S.; Ray, R.; Chakraborty, S.; Dey, N. Video Shot Boundary Detection: A Review. In Emerging ICT for Bridging the Future—Proceedings of the 49th Annual Convention of the Computer Society of India CSI Volume 2; Satapathy, C.S., Govardhan, A., Raju, S.K., Mandal, K.J., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Chapter Video Shot; pp. 119–127. [Google Scholar]
- Choroś, K. False and miss detections in temporal segmentation of TV sports news videos–causes and remedies. In New Research in Multimedia and Internet Systems; Zgrzywa, A., Choroś, K., Siemiński, A., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Chapter 4; pp. 35–46. [Google Scholar]
- Iwan, L.H.; Thom, J.A. Temporal video segmentation: detecting the end-of-act in circus performance videos. Multimedia Tools Appl. 2017, 76, 1379–1401. [Google Scholar] [CrossRef]
- Mondal, J.; Kundu, M.K.; Das, S.; Chowdhury, M. Video shot boundary detection using multiscale geometric analysis of nsct and least squares support vector machine. Multimedia Tools Appl. 2017, 1–23. [Google Scholar] [CrossRef]
- Dutta, D.; Saha, S.K.; Chanda, B. A shot detection technique using linear regression of shot transition pattern. Multimedia Tools Appl. 2016, 75, 93–113. [Google Scholar] [CrossRef]
- Shahraray, B. Scene change detection and content-based sampling of video sequences. In IS&T/SPIE’s Symposium on Electronic Imaging: Science & Technology; International Society for Optics and Photonics: San Jose, CA, USA, 1995; pp. 2–13. [Google Scholar]
- Kar, T.; Kanungo, P. A motion and illumination resilient framework for automatic shot boundary detection. Signal Image Video Process 2017, 11, 1237–1244. [Google Scholar] [CrossRef]
- Duan, L.Y.; Xu, M.; Tian, Q.; Xu, C.S.; Jin, J.S. A unified framework for semantic shot classification in sports video. IEEE Trans. Multimedia 2005, 7, 1066–1083. [Google Scholar] [CrossRef]
- Amiri, A.; Fathy, M. Video shot boundary detection using QR-decomposition and gaussian transition detection. EURASIP J. Adv. Signal Process. 2010, 2009, 1–12. [Google Scholar] [CrossRef]
- Ren, W.; Sharma, M. Automated video segmentation. In Proceedings of the 3rd International Conference on Information, Communication, and Signal Processing, Singapore, Singapore, 15–18 October 2001; pp. 1–11. [Google Scholar]
- Xiong, W.; Lee, C.M.; Ma, R.H. Automatic video data structuring through shot partitioning and key-frame computing. Mach. Vis. Appl. 1997, 10, 51–65. [Google Scholar] [CrossRef]
- Janwe, N.J.; Bhoyar, K.K. Video shot boundary detection based on JND color histogram. In Proceedings of the 2013 IEEE Second International Conference on Image Information Processing (ICIIP), Shimla, India, 9–11 December 2013; pp. 476–480. [Google Scholar]
- Gargi, U.; Kasturi, R.; Strayer, S.H. Performance Characterization of Video-Shot-Change Detection Methods. IEEE Trans. Circ. Syst. 2000, 8, 4761–4766. [Google Scholar] [CrossRef]
- Chen, Y.; Deng, Y.; Guo, Y.; Wang, W.; Zou, Y.; Wang, K. A Temporal Video Segmentation and Summary Generation Method Based on Shots’ Abrupt and Gradual Transition Boundary Detecting. In Proceedings of the 2010 ICCSN’10 Second International Conference on Communication Software and Networks, Singapore, Singapore, 26–28 February 2010; pp. 271–275. [Google Scholar]
- Tong, W.; Song, L.; Yang, X.; Qu, H.; Xie, R. CNN-Based Shot Boundary Detection and Video Annotation. In Proceedings of the 2015 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting, Ghent, Belgium, 17–19 June 2015. [Google Scholar]
- Asghar, M.N.; Hussain, F.; Manton, R. Video indexing: A survey. Int. J. Comput. Inf. Technol. 2014, 3, 148–169. [Google Scholar]
- Kowdle, A.; Chen, T. Learning to Segment a Video to Clips Based on Scene and Camera Motion. In Proceedings of the Computer Vision—ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012. Part III. pp. 272–286. [Google Scholar]
- Bescós, J.; Cisneros, G.; Martínez, J.M.; Menéndez, J.M.; Cabrera, J. A unified model for techniques on video-shot transition detection. IEEE Trans. Multimedia 2005, 7, 293–307. [Google Scholar] [CrossRef]
- Küçüktunç, O.; Güdükbay, U.; Ulusoy, Ö. Fuzzy color histogram-based video segmentation. Comput. Vis. Image Underst. 2010, 114, 125–134. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.N.; Lu, Z.M.; Niu, X.M. Fast video shot boundary detection framework employing pre-processing techniques. IET Image Process. 2009, 3, 121–134. [Google Scholar] [CrossRef]
- BABER, J.; Afzulpurkar, N.; Satoh, S. A framework for video segmentation using global and local features. Int. J. Pattern Recognit. Art. Intell. 2013, 27, 1355007. [Google Scholar] [CrossRef]
- Hanjalic, A. Shot-boundary detection: Unraveled and resolved? IEEE Trans. Circ. Syst. Video Technol. 2002, 12, 90–105. [Google Scholar] [CrossRef]
- Jiang, X.; Sun, T.; Liu, J.; Chao, J.; Zhang, W. An adaptive video shot segmentation scheme based on dual-detection model. Neurocomputing 2013, 116, 102–111. [Google Scholar] [CrossRef]
- Cao, J.; Cai, A. A robust shot transition detection method based on support vector machine in compressed domain. Pattern Recognit. Lett. 2007, 28, 1534–1540. [Google Scholar] [CrossRef]
- Hampapur, A.; Jain, R.; Weymouth, T.E. Production model based digital video segmentation. Multimedia Tools Appl. 1995, 1, 9–46. [Google Scholar] [CrossRef]
- Ling, X.; Yuanxin, O.; Huan, L.; Zhang, X. A Method for Fast Shot Boundary Detection Based on SVM. In Proceedings of the 2008 CISP’08 Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; Volume 2, pp. 445–449. [Google Scholar]
- Fang, H.; Jiang, J.; Feng, Y. A fuzzy logic approach for detection of video shot boundaries. Pattern Recognit. 2006, 39, 2092–2100. [Google Scholar] [CrossRef]
- Choroś, K.; Gonet, M. Effectiveness of video segmentation techniques for different categories of videos. New Trends Multimedia Netw. Inf. Syst. 2008, 181, 34. [Google Scholar]
- Choroś, K. Reduction of faulty detected shot cuts and cross dissolve effects in video segmentation process of different categories of digital videos. In Transactions on Computational Collective Intelligence V; Nguyen, N.T., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 124–139. [Google Scholar]
- Černeková, Z.; Kotropoulos, C.; Pitas, I. Video shot-boundary detection using singular-value decomposition and statistical tests. J. Electron. Imaging 2007, 16, 43012–43013. [Google Scholar] [CrossRef]
- Joyce, R.A.; Liu, B. Temporal segmentation of video using frame and histogram space. IEEE Trans. Multimedia 2006, 8, 130–140. [Google Scholar] [CrossRef]
- Černeková, Z.; Pitas, I.; Nikou, C. Information theory-based shot cut/fade detection and video summarization. IEEE Trans. Circ. Syst. Video Technol. 2006, 16, 82–91. [Google Scholar] [CrossRef]
- Porter, S.V. Video Segmentation and Indexing Using Motion Estimation. Ph.D. Thesis, University of Bristol, Bristol, UK, 2004. [Google Scholar]
- Barbu, T. Novel automatic video cut detection technique using Gabor filtering. Comput. Electr. Eng. 2009, 35, 712–721. [Google Scholar] [CrossRef]
- Zheng, W.; Yuan, J.; Wang, H.; Lin, F.; Zhang, B. A novel shot boundary detection framework. In Visual Communications and Image Processing 2005; International Society for Optics and Photonics: Beijing, China, 2005; p. 596018. [Google Scholar]
- Kawai, Y.; Sumiyoshi, H.; Yagi, N. Shot boundary detection at TRECVID 2007. In Proceedings of the TRECVID 2007 Workshop; NIST: Gaithersburg, MD, USA, 2007. [Google Scholar]
- Hameed, A. A novel framework of shot boundary detection for uncompressed videos. In Proceedings of the 2009 ICET 2009 International Conference on Emerging Technologies, Islamabad, Pakistan, 19–20 October 2009; pp. 274–279. [Google Scholar]
- Cotsaces, C.; Nikolaidis, N.; Pitas, I. Video shot boundary detection and condensed representation: A review. IEEE Signal Process. Mag. 2006, 23, 28–37. [Google Scholar] [CrossRef]
- Shekar, B.H.; Uma, K.P. Kirsch Directional Derivatives Based Shot Boundary Detection: An Efficient and Accurate Method. Procedia Comput. Sci. 2015, 58, 565–571. [Google Scholar] [CrossRef]
- Amiri, A.; Fathy, M. Video Shot Boundary Detection Using Generalized Eigenvalue Decomposition And Gaussian Transition Detection. Comput. Inform. 2011, 30, 595–619. [Google Scholar]
- Over, P.; Ianeva, T.; Kraaij, W.; Smeaton, A.F.; Val, U.D. TRECVID 2005—An Overview; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2005; pp. 1–27.
- Lefèvre, S.; Vincent, N. Efficient and robust shot change detection. J. Real-Time Image Process. 2007, 2, 23–34. [Google Scholar] [CrossRef] [Green Version]
- Cooper, M.; Liu, T.; Rieffel, E. Video Segmentation via Temporal Pattern Classification. IEEE Trans. Multimedia 2007, 9, 610–618. [Google Scholar] [CrossRef]
- Grana, C.; Cucchiara, R. Linear transition detection as a unified shot detection approach. IEEE Trans. Circ. Syst. Video Technol. 2007, 17, 483–489. [Google Scholar] [CrossRef]
- Aryal, S.; Ting, K.M.; Washio, T.; Haffari, G. Data-dependent dissimilarity measure: An effective alternative to geometric distance measures. Knowl. Inf. Syst. 2017, 53, 479–506. [Google Scholar] [CrossRef]
- Le, D.D.; Satoh, S.; Ngo, T.D.; Duong, D.A. A text segmentation based approach to video shot boundary detection. In Proceedings of the 2008 IEEE 10th Workshop on Multimedia Signal Processing, Cairns, Australia, 8–10 October 2008; pp. 702–706. [Google Scholar]
- Camara-Chavez, G.; Precioso, F.; Cord, M.; Phillip-Foliguet, S.; de A. Araujo, A. Shot Boundary Detection by a Hierarchical Supervised Approach. In Proceedings of the 14th International Workshop on Systems, Signals and Image Processing and 6th EURASIP Conference focused on Speech and Image Processing, Multimedia Communications and Services, Maribor, Slovenia, 27–30 June 2007; pp. 197–200. [Google Scholar]
- Pacheco, F.; Cerrada, M.; Sánchez, R.V.; Cabrera, D.; Li, C.; de Oliveira, J.V. Attribute clustering using rough set theory for feature selection in fault severity classification of rotating machinery. Expert Syst. Appl. 2017, 71, 69–86. [Google Scholar] [CrossRef]
- Lee, M.S.; Yang, Y.M.; Lee, S.W. Automatic video parsing using shot boundary detection and camera operation analysis. Pattern Recognit. 2001, 34, 711–719. [Google Scholar] [CrossRef]
- Kikukawa, T.; Kawafuchi, S. Development of an automatic summary editing system for the audio-visual resources. Trans. Inst. Electron. Inf. Commun. Eng. 1992, 75, 204–212. [Google Scholar]
- Nagasaka, A.; Tanaka, Y. Automatic video indexing and full-video search for object appearances. In Visual Database Systems II; North-Holland Publishing Co.: Amsterdam, The Netherlands, 1992; pp. 113–127. [Google Scholar]
- Zhang, H.; Kankanhalli, A.; Smoliar, S.W. Automatic partitioning of full-motion video. Multimedia Syst. 1993, 1, 10–28. [Google Scholar] [CrossRef]
- Lian, S. Automatic video temporal segmentation based on multiple features. Soft Comput. 2011, 15, 469–482. [Google Scholar] [CrossRef]
- Yeo, B.L.; Liu, B. Rapid Scene Analysis on Compressed Video. IEEE Trans. Circ. Syst. Video Technol. 1995, 5, 533–544. [Google Scholar]
- Huan, Z.H.Z.; Xiuhuan, L.X.L.; Lilei, Y.L.Y. Shot Boundary Detection Based on Mutual Information and Canny Edge Detector. 2008 Int. Conf. Comput. Sci. Softw. Engineering 2008, 2, 1124–1128. [Google Scholar]
- Koprinska, I.; Carrato, S. Temporal video segmentation: A survey. Signal Process. Image Commun. 2001, 16, 477–500. [Google Scholar] [CrossRef]
- Tapu, R.; Zaharia, T. Video Segmentation and Structuring for Indexing Applications. Int. J. Multimedia Data Eng. Manag. 2011, 2, 38–58. [Google Scholar] [CrossRef]
- Ciocca, G.; Schettini, R. Dynamic storyboards for video content summarization. In Proceedings of the MIR’06 8th ACM International Workshop on Multimedia Information Retrieval, Santa Barbara, CA, USA, 26–27 October 2006; p. 259. [Google Scholar]
- Swanberg, D.; Shu, C.F.; Jain, R.C. Knowledge-guided parsing in video databases. In IS&T/SPIE’s Symposium on Electronic Imaging: Science and Technology; International Society for Optics and Photonics: San Jose, CA, USA, 1993; pp. 13–24. [Google Scholar]
- Solomon, C.; Breckon, T. Fundamentals of Digital Image Processing: A Practical Approach with Examples in Matlab; Wiley-Blackwell: Hoboken, NJ, USA, 2011; p. 344. [Google Scholar]
- Boreczky, J.S.; Rowe, L.a. Comparison of video shot boundary detection techniques. J. Electron. Imaging 1996, 5, 122–128. [Google Scholar] [CrossRef]
- Lienhart, R.W. Comparison of automatic shot boundary detection algorithms. In Proceedings of SPIE Storage and Retrieval for Image and Video Databases VII; International Society for Optics and Photonics: San Jose, CA, USA, 1998; Volume 3656, pp. 290–301. [Google Scholar]
- Ahmed, M.; Karmouch, A.; Abu-Hakima, S. Key Frame Extraction and Indexing for Multimedia Databases. In Proceedings of the Vision Interface’99, Trois-Rivieres, QC, Canada, 18–21 May 1999; Volume 99, pp. 506–511. [Google Scholar]
- Ahmed, M.; Karmouch, A. Video segmentation using an opportunistic approach. In Proceedings of the International Conference on Multimedia Modeling 1999, Ottawa, ON, Canada, 4–6 October 1999; pp. 389–405. [Google Scholar]
- Shih, T.Y. The reversibility of six geometric color spaces. Photogramm. Eng. Remote Sens. 1995, 61, 1223–1232. [Google Scholar]
- Tkalcic, M.; Tasic, J.F. Colour spaces: Perceptual, historical and applicational background. In Proceedings of the IEEE Region 8, EUROCON 2003, Computer as a Tool, Ljubljana, Slovenia, 22–24 September 2003; Volume 1, pp. 304–308. [Google Scholar]
- Thounaojam, D.M.; Khelchandra, T.; Singh, K.M.; Roy, S. A Genetic Algorithm and Fuzzy Logic Approach for Video Shot Boundary Detection. Comput. Intell. Neurosci. 2016, 2016, 14. [Google Scholar] [CrossRef] [PubMed]
- Mas, J.; Fernandez, G. Video shot boundary detection based on color histogram. In Notebook Papers TRECVID 2003; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2003. [Google Scholar]
- Qian, X.; Liu, G.; Su, R. Effective Fades and Flashlight Detection Based on Accumulating Histogram Difference. IEEE Trans. Circ. Syst. Video Technol. 2006, 16, 1245–1258. [Google Scholar] [CrossRef]
- Ji, Q.G.; Feng, J.W.; Zhao, J.; Lu, Z.M. Effective Dissolve Detection Based on Accumulating Histogram Difference and the Support Point. In Proceedings of the 2010 First International Conference on Pervasive Computing Signal Processing and Applications (PCSPA), Harbin, China, 17–19 September 2010; pp. 273–276. [Google Scholar]
- Bhoyar, K.; Kakde, O. Color image segmentation based on JND color histogram. Int. J. Image Process. (IJIP) 2010, 3, 283–292. [Google Scholar]
- Adnan, A.; Ali, M. Shot boundary detection using sorted color histogram polynomial curve. Life Sci. J. 2013, 10, 1965–1972. [Google Scholar]
- Li, Z.; Liu, X.; Zhang, S. Shot Boundary Detection based on Multilevel Difference of Colour Histograms. In Proceedings of the 2016 First International Conference on Multimedia and Image Processing (ICMIP), Bandar Seri Begawan, Brunei, 1–3 June 2016; pp. 15–22. [Google Scholar]
- Park, S.; Son, J.; Kim, S.J. Effect of adaptive thresholding on shot boundary detection performance. In Proceedings of the 2016 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Korea, 26–28 October 2016; pp. 1–2. [Google Scholar]
- Park, S.; Son, J.; Kim, S.J. Study on the effect of frame size and color histogram bins on the shot boundary detection performance. In Proceedings of the 2016 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Korea, 26–28 October 2016. [Google Scholar]
- Verma, M.; Raman, B. A Hierarchical Shot Boundary Detection Algorithm Using Global and Local Features. In Proceedings of International Conference on Computer Vision and Image Processing: CVIP 2016, Volume 2; Raman, B., Kumar, S., Roy, P.P., Sen, D., Eds.; Springer: Singapore, 2017; pp. 389–397. [Google Scholar]
- Pye, D.; Hollinghurst, N.J.; Mills, T.J.; Wood, K.R. Audio-visual segmentation for content-based retrieval. In Proceedings of the 5th International Conference on Spoken Language Processing (ICSLP’98), Sydney, Australia, 30 November–4 December 1998. [Google Scholar]
- Dailianas, A.; Allen, R.B.; England, P. Comparison of automatic video segmentation algorithms. In Proceedings of SPIE–The International Society for Optical Engineering; SPIE: Philadelphia, PA, USA, 1996; Volume 2615, pp. 2–16. [Google Scholar]
- Lienhart, R.W. Reliable transition detection in videos: A survey and practitioner’s guide. Int. J. Image Graph. 2001, 1, 469–486. [Google Scholar] [CrossRef]
- Heng, W.J.; Ngan, K.N. High accuracy flashlight scene determination for shot boundary detection. Signal Process. Image Commun. 2003, 18, 203–219. [Google Scholar] [CrossRef]
- Kim, S.H.; Park, R.H. Robust video indexing for video sequences with complex brightness variations. In Proceedings of the lnternational Conference on Signal and Image Processing, Kauai, HI, USA, 12–14 August 2002; pp. 410–414. [Google Scholar]
- Zabih, R.; Miller, J.; Mai, K. A Feature-Based Algorithm for Detecting and Classifying Scene Breaks. In Proceedings of the Third ACM International Conference on Multimedia Multimedia 95; San Francisco, CA, USA, 5–9 Novenber 1995; Volume 95, pp. 189–200. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Zabih, R.; Miller, J.; Mai, K. A feature-based algorithm for detecting and classifying production effects. Multimedia Syst. 1999, 7, 119–128. [Google Scholar] [CrossRef]
- Lupatini, G.; Saraceno, C.; Leonardi, R. Scene break detection: a comparison. In Proceedings of the Eighth IEEE International Workshop on Research Issues In Data Engineering, ‘Continuous-Media Databases and Applications’, Orlando, FL, USA, 23–24 February 1998; pp. 34–41. [Google Scholar] [Green Version]
- Nam, J.; Tewfik, A.H. Combined audio and visual streams analysis for video sequence segmentation. In Proceedings of the 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, (ICASSP-97), Munich, Germany, 21–24 April 1997; Volume 4, pp. 2665–2668. [Google Scholar]
- Lienhart, R.W. Reliable dissolve detection. In Photonics West 2001-Electronic Imaging; International Society for Optics and Photonics: San Jose, CA, USA, 2001; pp. 219–230. [Google Scholar]
- Heng, W.J.; Ngan, K.N. Integrated shot boundary detection using object-based technique. In Proceedings of the 1999 IEEE International Conference on Image Processing, 1999 ICIP 99, Kobe, Japan, 24–28 October 1999; Volume 3, pp. 289–293. [Google Scholar]
- Heng, W.J.; Ngan, K.N. An Object-Based Shot Boundary Detection Using Edge Tracing and Tracking. J. Vis. Commun. Image Represent. 2001, 12, 217–239. [Google Scholar] [CrossRef]
- Roberts, L.G. Machine Perception of Three-Dimensional Soups. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1963. [Google Scholar]
- Zheng, J.; Zou, F.; Shi, M. An efficient algorithm for video shot boundary detection. In Proceedings of the 2004 IEEE International Symposium on Intelligent Multimedia, Video and Speech Processing, Hong Kong, China, 20–22 October 2004; pp. 266–269. [Google Scholar]
- Mahmmod, B.M.; Ramli, A.R.; Abdulhussain, S.H.; Al-Haddad, S.A.R.; Jassim, W.A. Low-Distortion MMSE Speech Enhancement Estimator Based on Laplacian Prior. IEEE Access 2017, 5, 9866–9881. [Google Scholar] [CrossRef]
- ABDULHUSSAIN, S.H.; Ramli, A.R.; Mahmmod, B.M.; Al-Haddad, S.A.R.; Jassim, W.A. Image Edge Detection Operators based on Orthogonal Polynomials. Int. J. Image Data Fusion 2017, 8, 293–308. [Google Scholar] [CrossRef]
- Abdulhussain, S.H.; Ramli, A.R.; Al-Haddad, S.A.R.; Mahmmod, B.M.; Jassim, W.A. On Computational Aspects of Tchebichef Polynomials for Higher Polynomial Order. IEEE Access 2017, 5, 2470–2478. [Google Scholar] [CrossRef]
- Mahmmod, B.M.; Ramli, A.R.; Abdulhussain, S.H.; Al-Haddad, S.A.R.; Jassim, W.A. Signal Compression and Enhancement Using a New Orthogonal-Polynomial-Based Discrete Transform. IET Signal Process. 2018, 12, 129–142. [Google Scholar] [CrossRef]
- Abdulhussain, S.H.; Ramli, A.R.; Al-Haddad, S.A.R.; Mahmmod, B.M.; Jassim, W.A. Fast Recursive Computation of Krawtchouk Polynomials. J. Math. Imaging Vis. 2018, 60, 1–19. [Google Scholar] [CrossRef]
- Porter, S.V.; Mirmehdi, M.; Thomas, B.T. Video cut detection using frequency domain correlation. In Proceedings of the IEEE 15th International Conference on Pattern Recognition, Barcelona, Spain, 3–7 September 2000; Volume 3, pp. 409–412. [Google Scholar]
- Vlachos, T. Cut detection in video sequences using phase correlation. IEEE Signal Process. Lett. 2000, 7, 173–175. [Google Scholar] [CrossRef]
- Porter, S.; Mirmehdi, M.; Thomas, B. Temporal video segmentation and classification of edit effects. Image Vis. Comput. 2003, 21, 1097–1106. [Google Scholar] [CrossRef]
- Cooper, M.; Foote, J.; Adcock, J.; Casi, S. Shot boundary detection via similarity analysis. In Proceedings of the TRECVID Workshop; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2003. [Google Scholar]
- Ohta, Y.I.; Kanade, T.; Sakai, T. Color information for region segmentation. Comput. Graph. Image Process. 1980, 13, 222–241. [Google Scholar] [CrossRef]
- Urhan, O.; Gullu, M.K.; Erturk, S. Modified phase-correlation based robust hard-cut detection with application to archive film. IEEE Trans. Circ. Syst. Video Technol. 2006, 16, 753–770. [Google Scholar] [CrossRef]
- Priya, G.L.; Domnic, S. Edge Strength Extraction using Orthogonal Vectors for Shot Boundary Detection. Procedia Technol. 2012, 6, 247–254. [Google Scholar] [CrossRef]
- Bouthemy, P.; Gelgon, M.; Ganansia, F. A unified approach to shot change detection and camera motion characterization. IEEE Trans. Circ. Syst. Video Technol. 1999, 9, 1030–1044. [Google Scholar] [CrossRef]
- Dufaux, F.; Konrad, J. Efficient, robust, and fast global motion estimation for video coding. IEEE Trans. Image Process. 2000, 9, 497–501. [Google Scholar] [CrossRef] [PubMed]
- Bruno, E.; Pellerin, D. Video shot detection based on linear prediction of motion. In Proceedings of the 2002 IEEE International Conference on Multimedia and Expo (ICME’02), Lausanne, Switzerland, 26–29 August 2002; Volume 1, pp. 289–292. [Google Scholar]
- Priya, L.G.G.; Domnic, S. Walsh—Hadamard Transform Kernel-Based Feature Vector for Shot Boundary Detection. IEEE Trans. Image Process. 2014, 23, 5187–5197. [Google Scholar]
- Barjatya, A. Block matching algorithms for motion estimation. IEEE Trans. Evol. Comput. 2004, 8, 225–239. [Google Scholar]
- Zedan, I.A.; Elsayed, K.M.; Emary, E. Abrupt Cut Detection in News Videos Using Dominant Colors Representation. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics 2016; Hassanien, A.E., Shaalan, K., Gaber, T., Azar, A.T., Tolba, M.F., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 320–331. [Google Scholar]
- Jain, R.; Kasturi, R. Dynamic vision. In Computer Vision: Principles; IEEE Computer Society Press: Washington, DC, USA, 1991; pp. 469–480. [Google Scholar]
- Alattar, A.M. Detecting And Compressing Dissolve Regions In Video Sequences With A DVI Multimedia Image Compression Algorithm. In Proceedings of the 1993 IEEE International Symposium on Circuits and Systems (ISCAS’93), Chicago, IL, USA, 3–6 May 1993; pp. 13–16. [Google Scholar]
- Truong, B.T.; Dorai, C.; Venkatesh, S. New Enhancements to Cut, Fade, and Dissolve Detection Processes in Video Segmentation. In Proceedings of the Eighth ACM International Conference on Multimedia, Marina del Rey, CA, USA, 30 October 2000; ACM: New York, NY, USA, 2000; pp. 219–227. [Google Scholar]
- Miadowicz, J.Z. Story Tracking in Video News Broadcasts. Ph.D. Thesis, University of Kansas, Lawrence, KS, USA, 2004. [Google Scholar]
- Ribnick, E.; Atev, S.; Masoud, O.; Papanikolopoulos, N.; Voyles, R. Real-time detection of camera tampering. In Proceedings of the IEEE International Conference on Video and Signal Based Surveillance (AVSS’06), Sydney, Australia, 22–24 November 2006; p. 10. [Google Scholar]
- Chung, M.G.; Kim, H.; Song, S.M.H. A scene boundary detection method. In Proceedings of the 2000 International Conference on Image Processing, Vancouver, BC, Canada, 10–13 September 2000; Volume 3, pp. 933–936. [Google Scholar]
- Ngo, C.W.; Pong, T.C.; Chin, R.T. Video partitioning by temporal slice coherency. IEEE Trans. Circ. Syst. Video Technol. 2001, 11, 941–953. [Google Scholar]
- Ferman, A.M.; Tekalp, A.M. Efficient filtering and clustering methods for temporal video segmentation and visual summarization. J. Vis. Commun. Image Represent. 1998, 9, 336–351. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Meng, J.; Juan, Y.; Chang, S.F. Scene Change Detection in a MPEG compressed Video Sequence. In Proceedings of the IS&T/SPIE International Symposium on Electronic Imaging, Science & Technology, San Jose, CA, USA, 5–10 February 1995; Volume 2419, pp. 14–25. [Google Scholar]
- Dadashi, R.; Kanan, H.R. AVCD-FRA: A novel solution to automatic video cut detection using fuzzy-rule-based approach. Comput. Vis. Image Underst. 2013, 117, 807–817. [Google Scholar] [CrossRef]
- Nishani, E.; Çiço, B. Computer vision approaches based on deep learning and neural networks: Deep neural networks for video analysis of human pose estimation. In Proceedings of the 2017 6th Mediterranean Conference on Embedded Computing (MECO), Bar, Montenegro, 11–15 June 2017; pp. 1–4. [Google Scholar]
- Xu, J.; Song, L.; Xie, R. Shot boundary detection using convolutional neural networks. In Proceedings of the 2016 Visual Communications and Image Processing (VCIP), Chengdu, China, 27–30 November 2016; pp. 1–4. [Google Scholar]
- Birinci, M.; Kiranyaz, S.; Gabbouj, M. Video shot boundary detection by structural analysis of local image features. In Proceedings of the WIAMIS 2011: 12th International Workshop on Image Analysis for Multimedia Interactive Services, Delft, The Netherlands, 13–15 April 2011. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up robust features. In European Conference on Computer Vision; Springer: Berlin, Germany, 2006; pp. 404–417. [Google Scholar]
- Bhaumik, H.; Chakraborty, M.; Bhattacharyya, S.; Chakraborty, S. Detection of Gradual Transition in Videos: Approaches and Applications. In Intelligent Analysis of Multimedia Information; IGI Global: Hershey, PA, USA, 2017; pp. 282–318. [Google Scholar]
- Chan, C.; Wong, A. Shot Boundary Detection Using Genetic Algorithm Optimization. In Proceedings of the 2011 IEEE International Symposium on Multimedia (ISM), Dana Point, CA, USA, 5–7 December 2011; pp. 327–332. [Google Scholar]
- Jaffré, G.; Joly, P.; Haidar, S. The Samova Shot Boundary Detection for TRECVID Evaluation 2004; TREC Video Retrieval Evaluation Workshop: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Mohanta, P.P.; Saha, S.K.; Chanda, B. A model-based shot boundary detection technique using frame transition parameters. IEEE Trans. Multimedia 2012, 14, 223–233. [Google Scholar] [CrossRef]
- Lankinen, J.; Kämäräinen, J.K. Video Shot Boundary Detection using Visual Bag-of-Words. In Proceedings of the VISAPP 2013—Proceedings of the International Conference on Computer Vision Theory and Applications, Barcelona, Spain, 21–24 February 2013; Volume 1, pp. 778–791. [Google Scholar]
- ImageNet. Available online: http://www.image-net.org/ (accessed on 13 March 2018).
- Bhalotra, P.S.A.; Patil, B.D. Shot boundary detection using radon projection method. Int. J. Signal Image Process. 2013, 4, 60. [Google Scholar]
- Miene, A.; Hermes, T.; Ioannidis, G.T.; Herzog, O. Automatic shot boundary detection using adaptive thresholds. In Proceedings of the TRECVID 2003 Workshop; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2003; pp. 159–165. [Google Scholar]
- Chen, J.; Ren, J.; Jiang, J. Modelling of content-aware indicators for effective determination of shot boundaries in compressed MPEG videos. Multimedia Tools Appl. 2011, 54, 219–239. [Google Scholar] [CrossRef] [Green Version]
- Guimaraes, S.J.F.; do Patrocinio, Z.K.G.; Souza, K.J.F.; de Paula, H.B. Gradual transition detection based on bipartite graph matching approach. In Proceedings of the IEEE International Workshop on Multimedia Signal Processing (MMSP’09), Rio De Janeiro, Brazil, 5–7 October 2009; pp. 1–6. [Google Scholar]
- Yoo, H.W.; Ryoo, H.J.; Jang, D.S. Gradual shot boundary detection using localized edge blocks. Multimedia Tools Appl. 2006, 28, 283–300. [Google Scholar] [CrossRef]
- Sobel, I.; Feldman, G. A 3 × 3 isotropic gradient operator for image processing. Presented at a Talk at the Stanford Artificial Project. In Pattern Classification and Scene Analysis; John Wiley and Sons: New York, NY, USA, 1968; pp. 271–272. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: an update. ACM SIGKDD Explor. Newslett. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Tippaya, S.; Sitjongsataporn, S.; Tan, T.; Khan, M.M.; Chamnongthai, K. Multi-Modal Visual Features-Based Video Shot Boundary Detection. IEEE Access 2017, 5, 12563–12575. [Google Scholar] [CrossRef]
- Ahmed, A. Video Representation and Processing for Multimedia Data Mining. In Semantic Mining Technologies for Multimedia Databases; IGI Global: Hershey, PA, USA, 2009; pp. 1–31. [Google Scholar]
- Van Rijsbergen, C.J. Information Retrieval; Butterworths: London, UK, 1979. [Google Scholar]
- Makhoul, J.; Kubala, F.; Schwartz, R.; Weischedel, R. Performance measures for information extraction. In Proceedings of the DARPA Broadcast News Workshop, Herndon, VA, USA, 28 February–3 March 1999; pp. 249–252. [Google Scholar]
- Lefevre, S.; Holler, J.; Vincent, N. A review of real-time segmentation of uncompressed video sequences for content-based search and retrieval. Real-Time Imaging 2003, 9, 73–98. [Google Scholar] [CrossRef] [Green Version]
- TRECVID. Available online: http://trecvid.nist.gov (accessed on 13 March 2018).
- Chen, L.H.; Hsu, B.C.; Su, C.W. A Supervised Learning Approach to Flashlight Detection. Cybern. Syst. 2017, 48, 1–12. [Google Scholar] [CrossRef]
- Parnami, N.M.N.S.A.; Chandran, S.L.S. Indian Institute of Technology, Bombay at TRECVID 2006. In Proceedings of the TRECVID Workshop; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2006. [Google Scholar]
- Mishra, R.; Singhai, S.K.; Sharma, M. Comparative Study of Block Matching Algorithm and Dual Tree Complex Wavelet Transform for Shot Detection in Videos. In Proceedings of the 2014 International Conference on Electronic Systems, Signal Processing and Computing Technologies (ICESC), Nagpur, India, 9–11 January 2014; pp. 450–455. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Color Space | Pre Processing | CDSS | CLDS Method | Post Processing | Transition Detection Ability | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Threshold | Adaptive Threshold | SML | HT | Dissolve | Fade | Wipe | |||||
| [68] | Gray&RGB | NA | City-Block | ✔ | - | - | NA | ✔ | - | - | - |
| [69] | Gray | Averaging Filter3x3 | City-Block | ✔ | - | - | NA | ✔ | - | - | - |
| [70] | RGB | -combine 2 MSB from each space -Avg. Filter | City-Block | ✔ | - | - | NA | ✔ | ✔ | - | - |
| [24] | Gray | -Block Proc. (12 Block) -Block matching | NA | ✔ | - | - | NA | ✔ | ✔ | ✔ | - |
| [72] | RGB | NA | City-Block | - | ✔ | - | Flash Detector | ✔ | - | ✔ | - |
| Ref | Color Space | Pre Processing | Histogram Size | CDSS | CLDS Method | Post Processing | Transition Detection Ability | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Threshold | Adaptive Threshold | SML | HT | Dissolve | Fade | Wipe | ||||||
| [69] | Gray | NA | NA | ✔ | - | - | NA | ✔ | - | - | - | |
| [70] | Gray | NA | 64 | City-Block | ✔ | - | - | NA | ✔ | ✔ | - | - |
| [77] | RGB | NA | 256 | Weighted Difference | ✔ | - | - | NA | ✔ | - | - | - |
| [79] | Gray (global) | NA | 64 | City-Block | ✔ | - | - | NA | ✔ | - | - | - |
| [79] | Gray (16 region) | NA | 64 | City-Block | ✔ | - | - | NA | ✔ | - | - | - |
| [80] | RGB | RGB discretization | 64 and 256 | City-Block | ✔ | - | - | NA | ✔ | - | - | - |
| [81] | RGB | 6-bit from each channel | 64 | Equation (15) | ✔ | - | - | NA | ✔ | - | - | - |
| [82] | RGB | 6-bit from each channel | 64 | Equation (16) | ✔ | - | - | Temporal Skip | ✔ | - | - | - |
| [31] | Multiple Spaces | NA | 256 | Distances Spaces | ✔ | - | - | NA | ✔ | ✔ | - | - |
| [85] | RGB Global | NA | 768 | Equation (17) | - | - | GA | NA | ✔ | ✔ | ✔ | - |
| [86] | RGB | 4-MSB from each space | 4096 | City-Block | ✔ | - | - | Refine Stage | ✔ | ✔ | ✔ | - |
| [87] | Gray | histogram quantized to 64-bins | 64 | Equation (18) | ✔ | - | - | - | - | ✔ | - | |
| [88] | Gray | NA | NA | Equation (18) | ✔ | - | - | - | ✔ | - | - | |
| [37] | L*a*b* | Video transformation detection | 15 | Fuzzy rules | ✔ | - | - | ✔ | ✔ | ✔ | - | |
| [30] | RGB | NA | 17,472 | Histogram intersection | - | ✔ | - | ✔ | ✔ | ✔ | - | |
| [90] | HSV + Gray | Resize frame | 1024 | City-Block | ✔ | - | - | ✔ | - | - | - | |
| [91] | HSV | NA | NA | Euclidean | - | ✔ | - | -Gaussian filter -Voting mechanism | ✔ | ✔ | ✔ | - |
| [92] | HSV | frame resize | 109 | correlation | - | ✔ | - | ✔ | - | - | - | |
| [94] | RGB | quantization to 8 levels | 24 | City-Block | ✔ | - | - | NA | ✔ | - | - | - |
| Ref | Color Space | Edge Operator | Pre Processing | CDSS | CLDS Method | Post Processing | Transition Detection Ability | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Threshold | Adaptive Threshold | SML | HT | Dissolve | Fade | Wipe | ||||||
| [100] | Gray | Canny | Frame Smoothing | ECR | ✔ | - | - | ✔ | ✔ | ✔ | ✔ | |
| [104] | Gray Ycbcr | wavelet | Temporal subsampling | Number of edge point | ✔ | - | - | refine stage | ✔ | ✔ | ✔ | - |
| [80] | Gray | Canny | NA | ECR | ✔ | - | - | ✔ | ✔ | ✔ | - | |
| [106,107] | Gray and RGB or YUV | Canny | NA | Euclidean | ✔ | - | - | Refine stage | ✔ | - | ✔ | ✔ |
| [109] | Gray | Robert | NA | Number of edge pixels | ✔ | - | - | - | - | ✔ | - | |
| Ref | Color Space | Transform | Pre Processing | CDSS | CLDS Method | Transition Detection Ability | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Threshold | Adaptive Threshold | SML | HT | Dissolve | Fade | Wipe | |||||
| [115] | Gray | DFT | Block 32 × 32 | mean and std of normalized correlation | ✔ | - | - | ✔ | - | - | - |
| [116] | Luminance | DFT | Block processing | phase correlation | ✔ | - | - | ✔ | - | - | - |
| [117] | Gray | DFT | Block Processing | normalized correlation and median | ✔ | - | - | ✔ | ✔ | ✔ | - |
| [118] | Ohta Color Space | DCT | cosine similarity | NA | ✔ | - | - | ✔ | ✔ | - | - |
| [120] | Gray | DFT | spatial subsampling | Correlation | - | ✔ | - | ✔ | - | - | - |
| [121] | Gray | Walsh Hadamard | Frame resize | City-block | ✔ | - | - | ✔ | - | - | - |
| Ref | Color Space | Statistics | Pre Processing | CDSS | CLDS Method | Post Processing | Transition Detection Ability | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Threshold | Adaptive Threshold | SML | HT | Dissolve | Fade | Wipe | ||||||
| [129] | Gray | Variance | NA | NA | ✔ | ✔ | - | NA | - | ✔ | - | - |
| [130] | Gray | mean and variance | NA | NA | - | ✔ | - | NA | - | ✔ | ✔ | - |
| [40] | DC images | likelihood function | NA | NA | ✔ | - | - | NA | ✔ | ✔ | - | - |
| [131] | RGB | mean standard deviation skew | NA | NA | ✔ | - | - | NA | ✔ | ✔ | ✔ | - |
| Ref | Features | Frame Skipping | Dataset | F1 | Computation Cost | ||
|---|---|---|---|---|---|---|---|
| [15] | Pixel Histogram | ✔ | 2001 other | 90.3 | 85.2 | 87.7 | Low |
| [85] | Histogram | - | 2001 | 88.7 | 93.1 | 90.7 | Moderate |
| [33] | PBA CNN | ✔ | 2001 | 91.2 | 84.2 | 87.5 | Moderate |
| [57] | Gradient | - | 2001 2007 | 90.5 87 | 87.6 89.9 | 89 88.4 | Moderate |
| [125] | Walsh-Hadamard Motion | - | 2001 2007 | 88.1 95.7 | 91.2 96.5 | 89.6 96.1 | High |
| [1] | SURF | ✔ | 2005 | - | - | 83 | Moderate |
| [18] | Histogram Mutual Info Harris | ✔ | 2001 | 93.5 | 94.5 | 93.99 | Moderate |
| [41] | Histogram SIFT | ✔ | Other | 96.6 | 93 | 94.7 | Moderate |
| [138] | Histogram Fuzzy Color Histogram | - | Other | 90.6 | 95.3 | 92.9 | Moderate |
| [156] | SURF Histrogram | ✔ | 2001 | 90.7 | 87.3 | 88.7 | Moderate |
| [22] | Contourlet Transform 3 level of decomposition | - | 2007 | 98 | 97 | 97.5 | High |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulhussain, S.H.; Ramli, A.R.; Saripan, M.I.; Mahmmod, B.M.; Al-Haddad, S.A.R.; Jassim, W.A. Methods and Challenges in Shot Boundary Detection: A Review. Entropy 2018, 20, 214. https://doi.org/10.3390/e20040214
Abdulhussain SH, Ramli AR, Saripan MI, Mahmmod BM, Al-Haddad SAR, Jassim WA. Methods and Challenges in Shot Boundary Detection: A Review. Entropy. 2018; 20(4):214. https://doi.org/10.3390/e20040214
Chicago/Turabian StyleAbdulhussain, Sadiq H., Abd Rahman Ramli, M. Iqbal Saripan, Basheera M. Mahmmod, Syed Abdul Rahman Al-Haddad, and Wissam A. Jassim. 2018. "Methods and Challenges in Shot Boundary Detection: A Review" Entropy 20, no. 4: 214. https://doi.org/10.3390/e20040214
APA StyleAbdulhussain, S. H., Ramli, A. R., Saripan, M. I., Mahmmod, B. M., Al-Haddad, S. A. R., & Jassim, W. A. (2018). Methods and Challenges in Shot Boundary Detection: A Review. Entropy, 20(4), 214. https://doi.org/10.3390/e20040214