Coupled Node Similarity Learning for Community Detection in Attributed Networks

Abstract
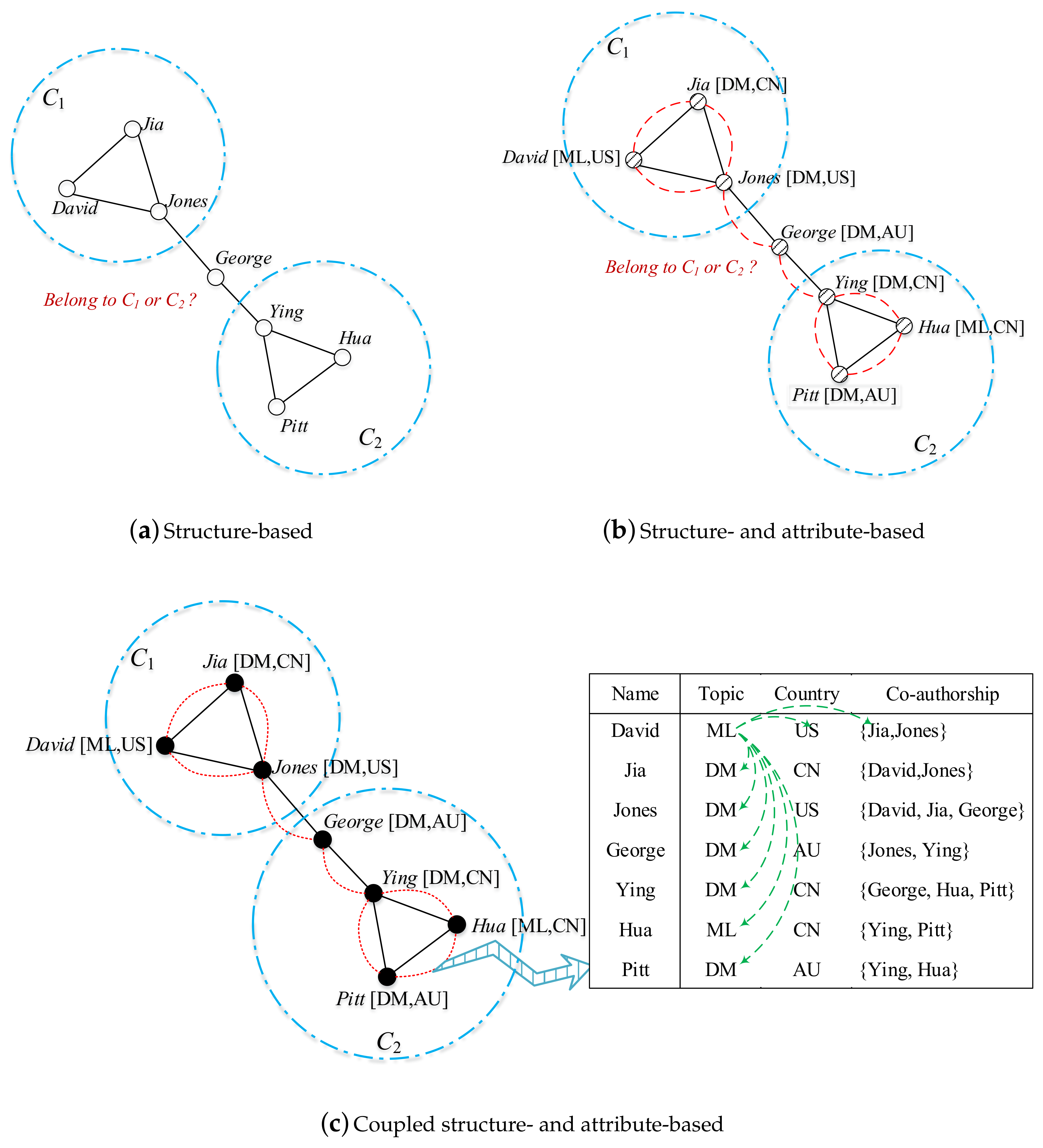
:1. Introduction
- CNS captures different levels of coupling relationships in an attributed graph, including value-to-value, value-to-node, and attribute-to-structure relationships. To the best of our knowledge, this is the first work that systematically represents the hierarchical interactions in terms of both structural and attribute aspects.
- CNS learns the above respective relationships in terms of calculating and integrating the intra-attribute coupled similarity, the inter-attribute coupled similarity, and the coupled attribute-to-structure similarity. Hence, CNS captures not only the attribute value interactions within and between attributes, but also the interactions between node attributes and structure. This provides a comprehensive means of understanding the intrinsic driving forces and complexity in community formation.
- We incorporate CNS into attributed graphs to generate weighted graphs, combining the topological structure and node attributes in a unified manner to detect communities in attributed networks.
- We also empirically evaluate the effectiveness of CNS similarity in terms of whether node attributes are involved, what types of node interactions are learned, and different levels of network structure complexity.
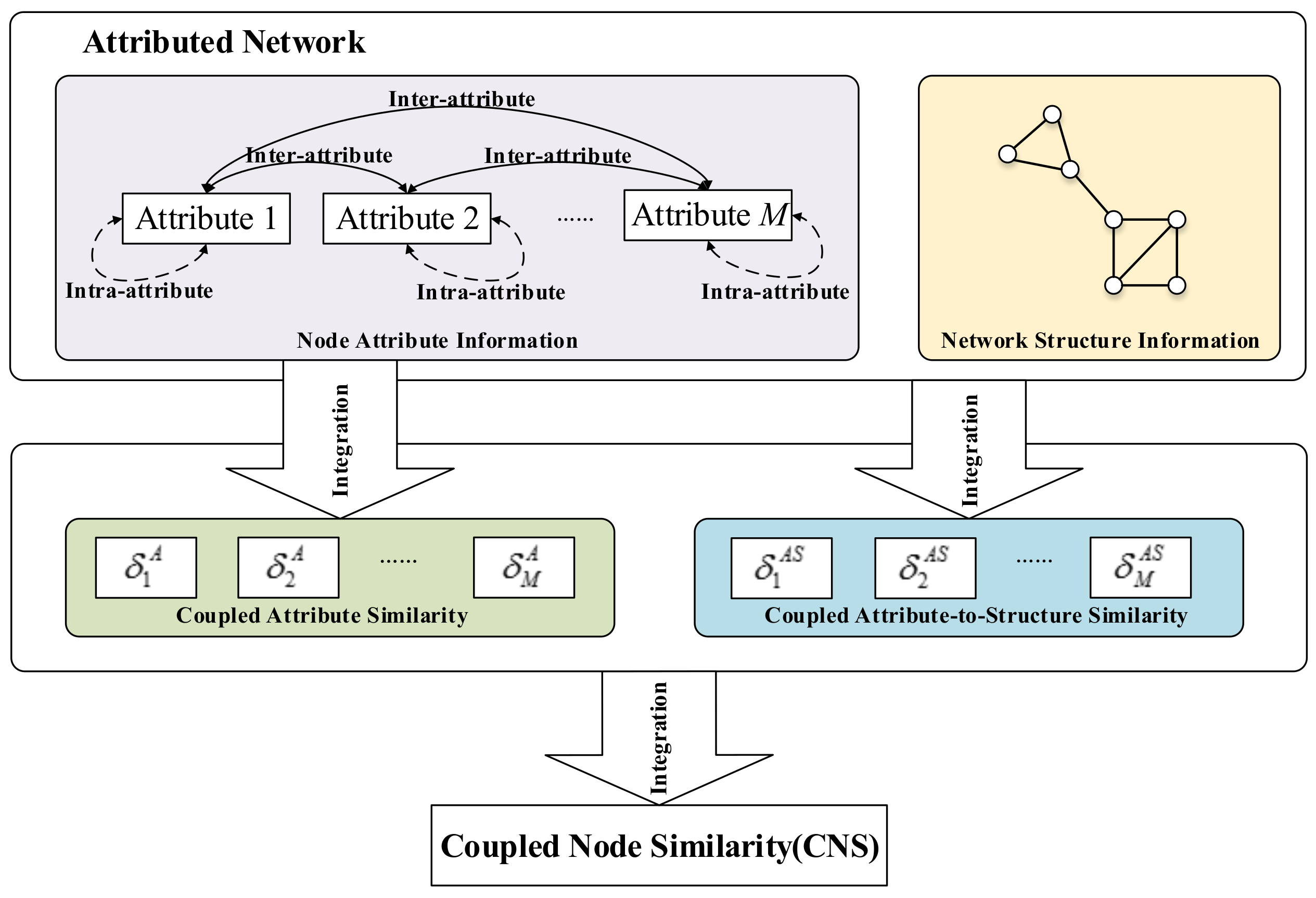
2. Learning Coupled Node Similarity
2.1. The CNS Framework
2.2. Coupled Attribute Similarity
2.3. Coupled Attribute-to-Structure Similarity
2.4. Coupled Node Similarity
2.5. The Algorithm for Learning CNS
| Algorithm 1 Learning Coupled Node Similarity |
| Input: Output:
|
2.6. Complexity Analysis
3. Similarity-Based Community Detection
4. Experiments and Analysis
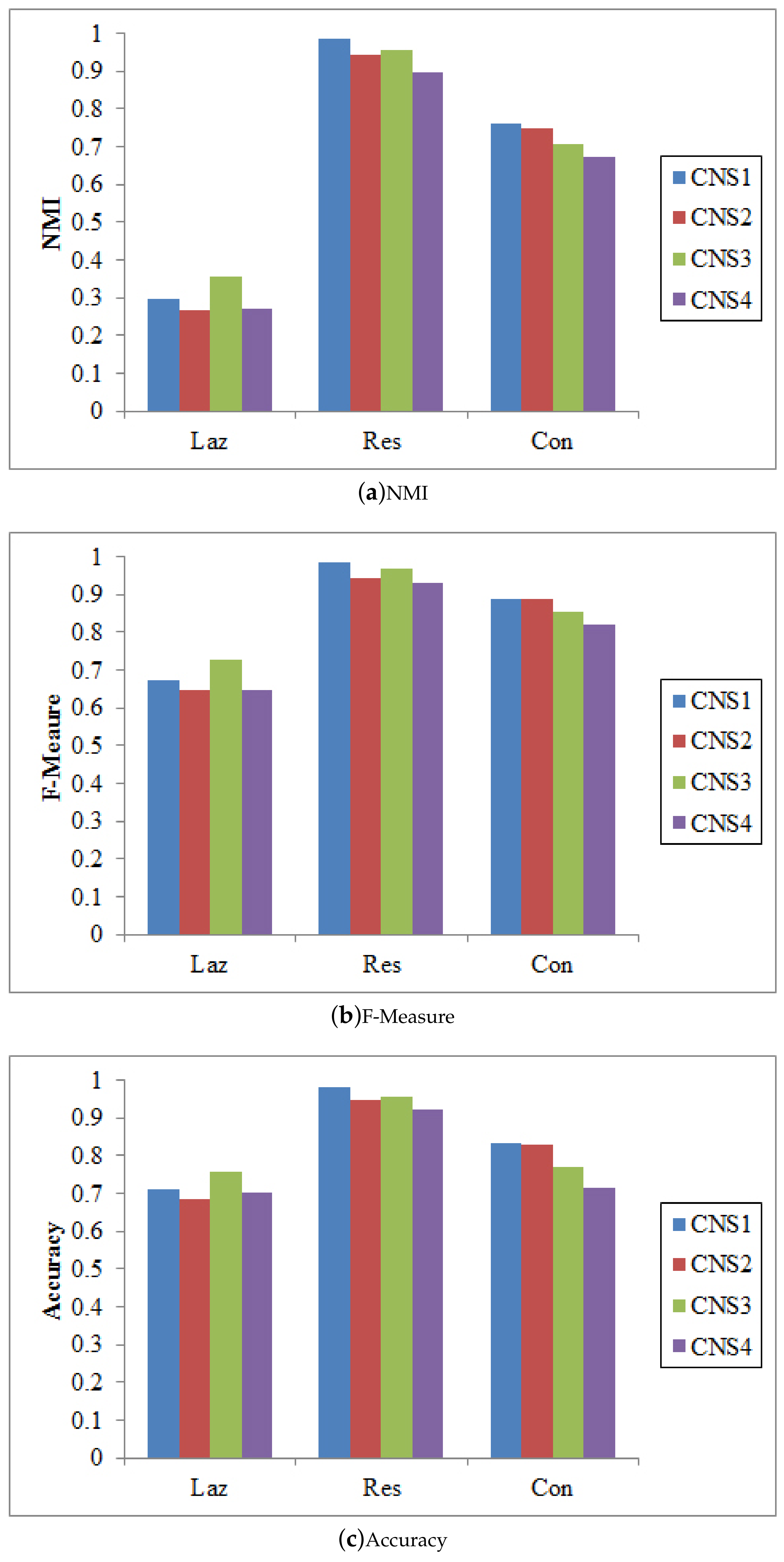
4.1. Detection Performance with vs. without Node Attribute Information
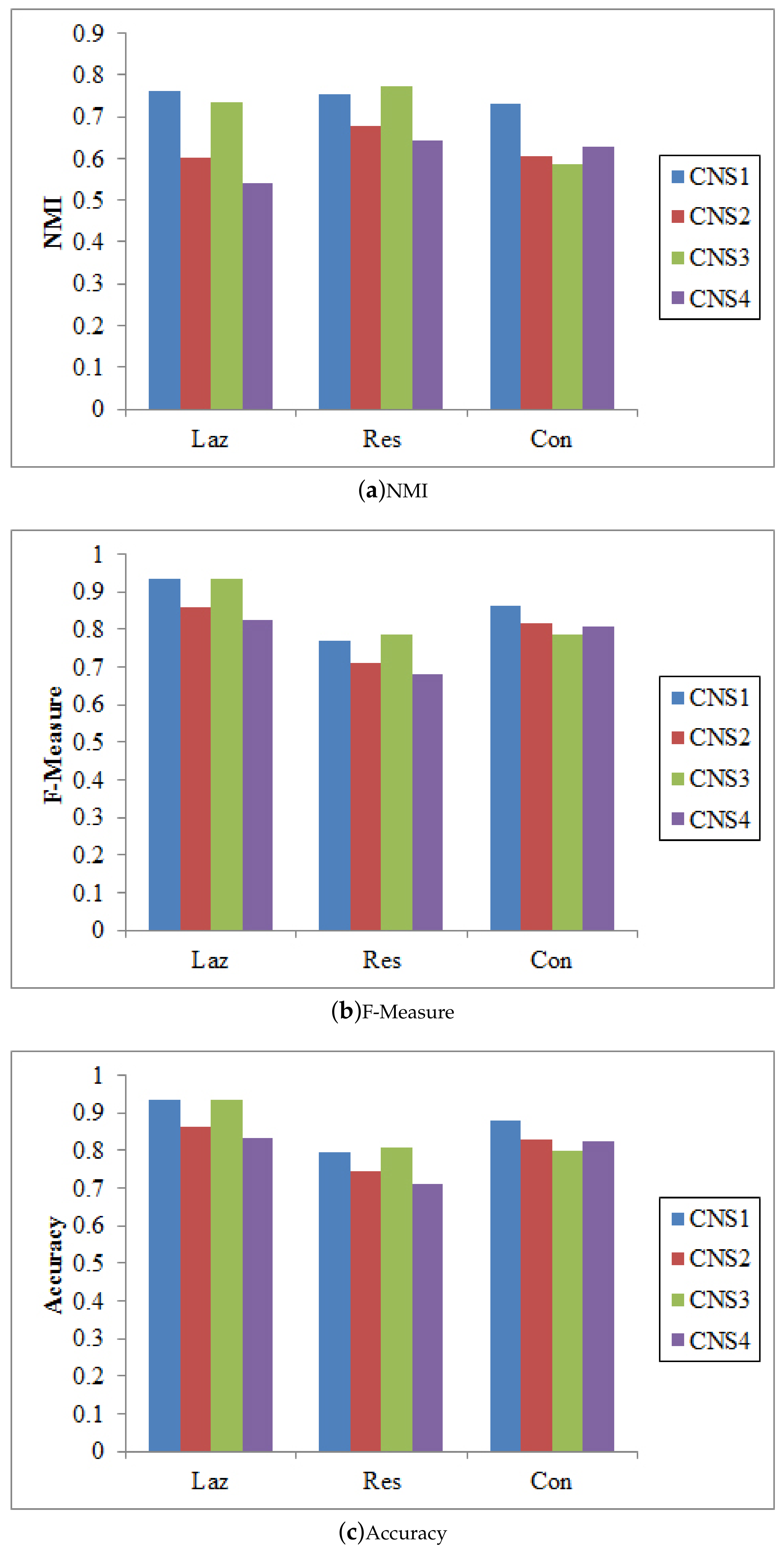
4.2. Effect of Differently Integrating Node Similarities
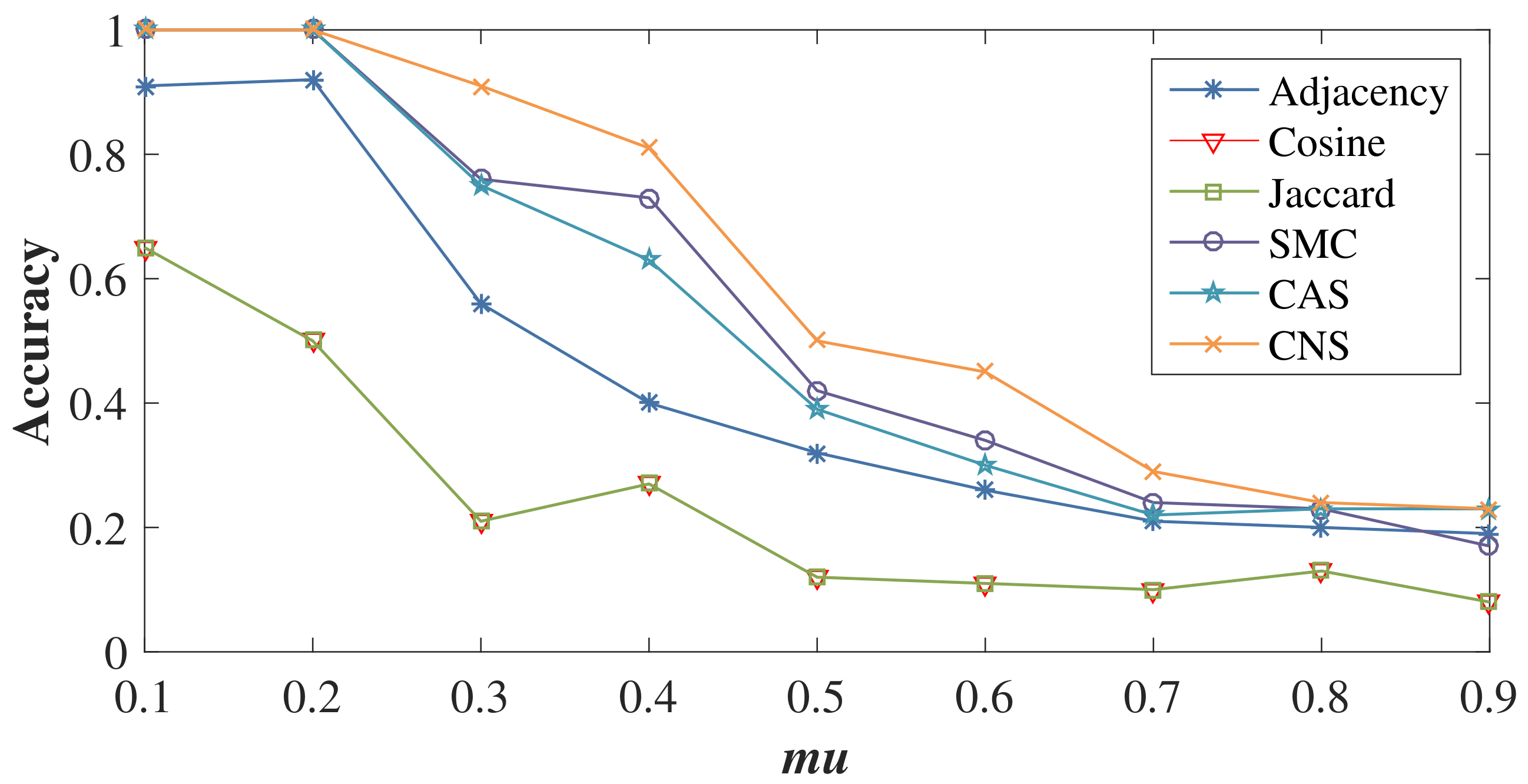
4.3. Impact of Varying Network Structure Complexity
4.4. Comparison Against Other Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chai, B.F.; Yu, J.; Jia, C.Y.; Yang, T.B.; Jiang, Y.W. Combining a popularity-productivity stochastic block model with a discriminative-content model for general structure detection. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2013, 88, 012807. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Ke, Y.; Wang, Y.; Cheng, H.; Cheng, J. GBAGC: A General Bayesian Framework for Attributed Graph Clustering. ACM Trans. Knowl. Discov. Data 2014, 9, 1–43. [Google Scholar] [CrossRef]
- Yang, J.; Mcauley, J.; Leskovec, J. Community Detection in Networks with Node Attributes. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 1151–1156. [Google Scholar]
- Xin, Y.; Yang, J.; Xie, Z. A Semantic Overlapping Community Detection Algorithm in Social Networks Based on Random Walk. J. Comput. Res. Dev. 2015, 52, 499–511. [Google Scholar]
- Cruz, J.D.; Bothorel, C.; Poulet, F. Entropy based community detection in augmented social networks. In Proceedings of the International Conference on Computational Aspects of Social Networks, Salamanca, Spain, 19–21 October 2011; pp. 163–168. [Google Scholar]
- Ruan, Y.; Fuhry, D.; Parthasarathy, S. Efficient community detection in large networks using content and links. In Proceedings of the International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1089–1098. [Google Scholar]
- Zhou, Y.; Cheng, H.; Yu, J.X. Graph Clustering based on Structural/Attribute Similarities. Proc. VLDB Endow. 2009, 2, 718–729. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, H.; Yu, J.X. Clustering large attributed graphs: An efficient incremental approach. In Proceedings of the International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 689–698. [Google Scholar]
- Cheng, H.; Zhou, Y.; Yu, J.X. Clustering large attributed graphs: A balance between structural and attribute similarities. ACM Trans. Knowl. Discov. Data 2011, 5, 12. [Google Scholar] [CrossRef]
- Steinhaeuser, K.; Chawla, N.V. Community Detection in a Large Real-World Social Network. In Social Computing, Behavioral Modeling, and Prediction; Springer: Boston, MA, USA, 2008; pp. 168–175. [Google Scholar]
- Chanwimalueang, T.; Mandic, D. Cosine Similarity Entropy: Self-Correlation-Based Complexity Analysis of Dynamical Systems. Entropy 2017, 19, 652. [Google Scholar] [CrossRef]
- Lee, S. Improving Jaccard Index for Measuring Similarity in Collaborative Filtering. In Proceedings of the International Conference on Information Science and Applications, Macau, China, 20–23 March 2017; pp. 799–806. [Google Scholar]
- De Meo, P.; Ferrara, E.; Fiumara, G.; Provetti, A. Enhancing community detection using a network weighting strategy. Inf. Sci. Int. J. 2013, 222, 648–668. [Google Scholar] [Green Version]
- Zhang, H.; Zhou, C.; Liang, X.; Zhao, X.; Li, Y. A Novel Edge Weighting Method to Enhance Network Community Detection. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Kowloon, China, 9–12 October 2015; pp. 167–172. [Google Scholar]
- Khadivi, A.; Hasler, M. A weighting scheme for enhancing community detection in networks. In Proceedings of the 2010 IEEE International Conference on Communications (ICC), Cape Town, South Africa, 23–27 May 2010; pp. 1–4. [Google Scholar]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: an Introduction to Cluster Analysis; Wiley: Hoboken, NJ, USA, 1990. [Google Scholar]
- Wang, C.; Cao, L.; Wang, M.; Li, J.; Wei, W.; Ou, Y. Coupled Nominal Similarity in Unsupervised Learning. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; pp. 973–978. [Google Scholar]
- Wang, C.; Dong, X.; Zhou, F.; Cao, L.; Chi, C.H. Coupled Attribute Similarity Learning on Categorical Data. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 781–797. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; She, Z.; Cao, L. Coupled Clustering Ensemble: Incorporating Coupling Relationships both between Base Clusterings and Objects. In Proceedings of the IEEE 29th International Conference on Data Engineering, Brisbane, Australia, 8–12 April 2013; pp. 374–385. [Google Scholar]
- Liu, C.; Cao, L. A Coupled k-nearest Neighbor Algorithm for Multi-label Classification. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Ho Chi Minh City, Vietnam, 19–22 May 2015; pp. 176–187. [Google Scholar]
- Fu, B.; Xu, G.; Cao, L.; Wang, Z.; Wu, Z. Coupling Multiple Views of Relations for Recommendation. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Ho Chi Minh City, Vietnam, 19–22 May 2015; pp. 732–743. [Google Scholar]
- Cao, L. Coupling learning of complex interactions. Inf. Process. Manag. 2015, 51, 167–186. [Google Scholar] [CrossRef]
- Bothorel, C.; Cruz, J.D.; Magnani, M.; Micenkova, B. Clustering Attributed Graphs: Models, Measures and Methods. Netw. Sci. 2015, 3, 408–444. [Google Scholar] [CrossRef]
- Kim, K.; Altmann, J. Effect of homophily on network formation. Commun. Nonlinear Sci. Numer. Simul. 2017, 44, 482–494. [Google Scholar] [CrossRef]
- McPherson, M.; SmithLovin, L.; Cook, J.M. Birds of a Feather: Homophily in Social Networks. Ann. Rev. Sociol. 2001, 27, 415–444. [Google Scholar] [CrossRef]
- Xie, J.; Szymanski, B.K. Towards Linear Time Overlapping Community Detection in Social Networks. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Kuala Lumpur, Malaysia, 29 May–1 June 2012; pp. 25–36. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast Unfolding of Communities in Large Networks. J. Statist. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Yu, D.; Liu, G.; Guo, M.; Liu, X. An improved K-medoids algorithm based on step increasing and optimizing medoids. Expert Syst. Appl. 2018, 92, 464–473. [Google Scholar] [CrossRef]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near Linear Time Algorithm to Detect Community Structures in Large-Scale Networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.L.; Deng, C.H.; Ngo, C.W. k-means: A revisit. Neurocomputing 2018, 291, 195–206. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark Graphs for Testing Community Detection Algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef] [PubMed]
- Lazega, E. The Collegial Phenomenon: The Social Mechanisms of Cooperation Among Peers in a Corporate Law Partnership; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Cross, R.; Parker, A. The Hidden Power of Social Networks; Harvard Business School Press: Boston, MA, USA, 2004. [Google Scholar]
- Sun, P. Weighting Links based on Edge Centrality for Community Detection. Phys. A Stat. Mech. Its Appl. 2014, 394, 346–357. [Google Scholar] [CrossRef]
- Hand, D.; Christen, P. A note on using the F-measure for evaluating record linkage algorithms. Stat. Comput. 2018, 28, 539–547. [Google Scholar] [CrossRef]
- Cao, L. Non-IIDness Learning in Behavioral and Social Data. Comput. J. 2014, 57, 1358–1370. [Google Scholar] [CrossRef]
 indicates the linkage between two nodes;
indicates the linkage between two nodes;  refers to simple attribute similarity between two nodes, and
refers to simple attribute similarity between two nodes, and  represents the complex coupling relationships between two nodes.)
indicates the linkage between two nodes; refers to simple attribute similarity between two nodes, and represents the complex coupling relationships between two nodes.)
represents the complex coupling relationships between two nodes.)
indicates the linkage between two nodes; refers to simple attribute similarity between two nodes, and represents the complex coupling relationships between two nodes.)







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| M | The number of node attributes |
| The set of all distinct values on the mth attribute | |
| The value of the mth attribute for node i | |
| K | The number of communities |
| C | The communities of the network, |
| The community to which node i belongs | |
| The neighbor set of node i | |
| The adjacency relationship between nodes i and j. if nodes i and j are connected; otherwise | |
| The weight between nodes i and j | |
| The similarity between nodes i and j | |
| The received label of node i | |
| The sum of all edge weights in the network, | |
| The sum of edge weights which are connected to node i, | |
| The node set whose mth attribute value is x | |
| The weight parameter for the nth attribute, , | |
| the inter-relative attribute coupled similarities between values x and y of the mth attribute based on the nth attribute () | |
| , the complement set of B under the complete distinct value set of the nth attribute | |
| the node set whose attribute value in the nth attribute is in B | |
| The intra-attribute coupled similarity between the attribute values x and y of the mth attribute | |
| The inter-attribute coupled similarity between the attribute values x and y of the mth attribute based on other attributes | |
| The coupled attribute similarity between the attribute values x and y of the mth attribute | |
| The coupled attribute-to-structure similarity between the attribute values x and y of the mth attribute | |
| The coupled attribute similarity between nodes i and j | |
| The coupled node similarity between nodes i and j |
| ID | Name | Abbr. | K | M | ||
|---|---|---|---|---|---|---|
| R1 | Lazega | Laz | 71 | 575 | 2 | 7 |
| R2 | Research | Res | 77 | 2228 | 3 | 4 |
| R3 | Consult | Con | 46 | 879 | 4 | 2 |
| Similarity | SLPA | BGLL | K-Medoids | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Laz | Res | Con | Laz | Res | Con | Laz | Res | Con | |
| Adjacency | 14.04 | 65.68 | 58.15 | 31.47 | 70.92 | 66.42 | 11.25 | 29.02 | 20.15 |
| Cosine | 25.81 | 80.22 | 64.94 | 36.65 | 75.66 | 49.60 | 22.61 | 58.64 | 37.79 |
| Jaccard | 26.16 | 78.48 | 64.66 | 39.13 | 75.62 | 49.60 | 39.76 | 62.88 | 30.80 |
| SMC | 27.67 | 92.05 | 70.46 | 39.04 | 100 | 66.42 | 28.46 | 34.75 | 47.74 |
| CAS | 26.11 | 87.84 | 67.23 | 36.18 | 86.64 | 66.42 | 72.55 | 34.08 | 54.11 |
| CNS | 29.47 | 98.71 | 78.67 | 48.67 | 100 | 66.42 | 76.02 | 76.46 | 73.29 |
| 6.51 | 7.24 | 11.65 | 24.38 | 0.00 | 0.00 | 4.78 | 21.60 | 35.45 | |
| Similarity | SLPA | BGLL | K-Medoids | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Laz | Res | Con | Laz | Res | Con | Laz | Res | Con | |
| Adjacency | 52.32 | 68.25 | 80.00 | 71.96 | 62.98 | 80.87 | 53.54 | 40.36 | 63.36 |
| Cosine | 66.27 | 87.22 | 79.81 | 75.85 | 89.52 | 36.67 | 71.57 | 70.58 | 76.66 |
| Jaccard | 65.32 | 85.00 | 79.62 | 70.14 | 86.47 | 36.67 | 75.21 | 74.85 | 74.52 |
| SMC | 65.57 | 93.89 | 74.11 | 73.81 | 100 | 80.87 | 74.48 | 54.06 | 74.48 |
| CAS | 64.84 | 92.60 | 82.12 | 77.39 | 71.55 | 80.87 | 91.60 | 52.40 | 75.78 |
| CNS | 67.38 | 98.93 | 90.79 | 80.41 | 100 | 80.87 | 93.48 | 78.80 | 85.97 |
| 1.67 | 5.37 | 10.56 | 3.90 | 0.00 | 0.00 | 2.05 | 5.28 | 12.14 | |
| Similarity | SLPA | BGLL | K-Medoids | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Laz | Res | Con | Laz | Res | Con | Laz | Res | Con | |
| Adjacency | 61.32 | 73.95 | 72.60 | 60.87 | 66.22 | 70.00 | 60.14 | 46.31 | 67.10 |
| Cosine | 63.16 | 93.47 | 68.35 | 63.77 | 86.49 | 27.50 | 72.62 | 71.55 | 77.05 |
| Jaccard | 59.64 | 80.35 | 68.10 | 55.07 | 78.38 | 27.50 | 76.14 | 75.97 | 75.03 |
| SMC | 68.22 | 89.89 | 74.95 | 59.42 | 100 | 70.00 | 75.20 | 56.92 | 76.60 |
| CAS | 70.26 | 91.65 | 71.78 | 66.67 | 83.78 | 70.00 | 92.17 | 54.03 | 78.03 |
| CNS | 70.87 | 98.36 | 86.30 | 69.57 | 100 | 70.00 | 93.64 | 80.96 | 88.10 |
| 0.87 | 5.23 | 15.14 | 4.35 | 0.00 | 0.00 | 1.59 | 6.57 | 12.91 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, F.; Rui, X.; Wang, Z.; Xing, Y.; Cao, L. Coupled Node Similarity Learning for Community Detection in Attributed Networks. Entropy 2018, 20, 471. https://doi.org/10.3390/e20060471
Meng F, Rui X, Wang Z, Xing Y, Cao L. Coupled Node Similarity Learning for Community Detection in Attributed Networks. Entropy. 2018; 20(6):471. https://doi.org/10.3390/e20060471
Chicago/Turabian StyleMeng, Fanrong, Xiaobin Rui, Zhixiao Wang, Yan Xing, and Longbing Cao. 2018. "Coupled Node Similarity Learning for Community Detection in Attributed Networks" Entropy 20, no. 6: 471. https://doi.org/10.3390/e20060471
APA StyleMeng, F., Rui, X., Wang, Z., Xing, Y., & Cao, L. (2018). Coupled Node Similarity Learning for Community Detection in Attributed Networks. Entropy, 20(6), 471. https://doi.org/10.3390/e20060471