Inferring the Population Mean with Second-Order Information in Online Social Networks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
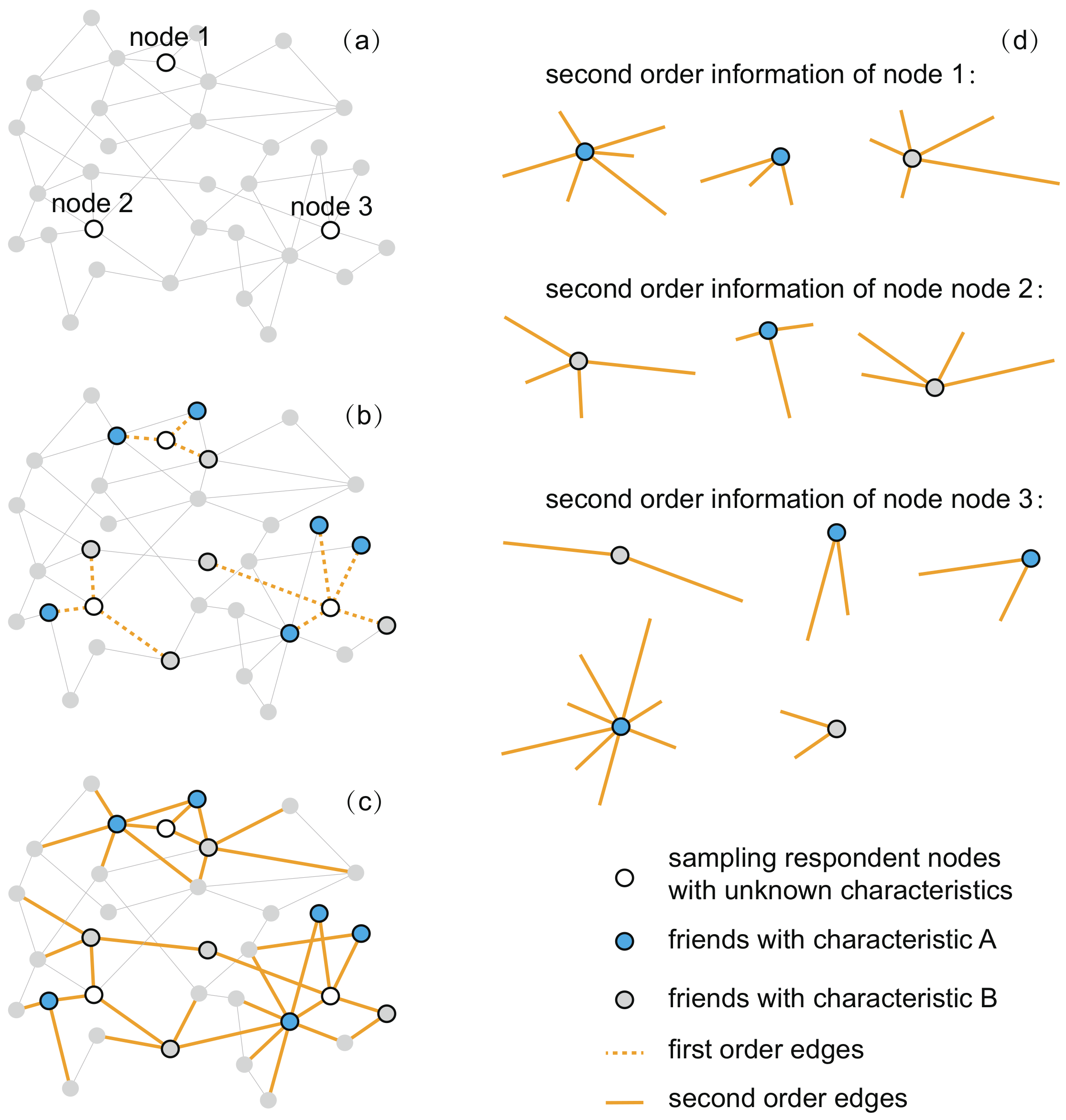
2.1. Sampling Strategies of Respondents
2.2. Inference with the Second-Order Information
- (1)
- Inference with respondents from simple random sampling:
- When the respondents are selected randomly, the inclusion probability of a respondent is , where N is the number of nodes in the network. When a respondent is selected, his/her friends are selected, as well. Therefore, the inclusion probability of a friend node i can be calculated by the probability of selecting respondents that connect with this friend:where is the degree of friend node i. Then, the proportion of nodes with Characteristic A can be estimated by a Hansen-Hurwitz estimator [26]:where U is the set of all friend nodes and A is the set of friend nodes with Characteristic A. We call this estimator SED1.
- (2)
- Inference with respondents from random walk-based sampling:
- Similarly, we can also generate the population mean when respondents are selected from the random walk-based sampling. In random walk-based sampling, the inclusion probability of a respondent s is proportional to its degree:where is the average degree of the network. Then, the inclusion probability of a friend node i can be calculated by the probability of selecting respondents that connect with this friend node:where S is the set of respondents that connect with friend node i. The average degree among the friends of a node can be approximated [28,29]:
- Then, we can use Equation (5) to extrapolate the equation for the inclusion probability of a friend node i:
- Equation (6) indicates that the inclusion probability of a friend node i is approximately proportional to its degree. Thus, the proportion of nodes with Characteristic A can be obtained by a Hansen-Hurwitz estimator:where U is the set of all friend nodes and A is the set of friend nodes with Characteristic A. We name this estimator SED2.
2.3. Experimental Design
- (1)
- Networks:
- We evaluate the developed method on three types of artificial networks and a real-world network: the Erdos–Rényi (ER) network [30], the Barabási–Albert (BA) network [31], the KOSKK (Kumpula-Onnela-Saramäki-Kaski-Kertész) network [32] and the anonymized online MSM (men who have sex with men) social network [33,34]. The artificial networks are configured with N = 10,000 nodes and M = 100,000 edges. For each type of artificial networks, 10%, 20%, 30% and 40% of randomly selected nodes with Characteristic A is assigned so that the population value for those with Characteristic A, , is 0.1, 0.2, 0.3 and 0.4, respectively. The MSM network has 16,082 nodes and 446,170 edges. Four characteristics are included: age, county (ct), civil status (cs) and profession (pf). The proportions of users with these characteristics are 0.778, 0.388, 0.404 and 0.382, respectively.
- The KOSKK model is one of the best models to generate artificial networks which have similar structures to real-life social networks [35], including a skewed degree distribution, small average shortest path lengths, high average clustering coefficient, assortative mixing and community structures. In a KOSKK model, the network to be generated is initialed with N nodes and no links. Then, it evolves with three mechanisms: two mechanisms that create links and a mechanism that removes nodes [32].
- (i)
- Local attachment. A node i is randomly selected, and one of its neighbors j is chosen with probability , where is the weight on link . If j has other neighbors besides i, one of them (e.g., node k) is chosen with probability . If no links exist between i and k, the link is generated with probability and set . In both cases, the link weight, including , and , is increased by an amount . With larger , the generated network will have a stronger community structure.
- (ii)
- Global attachment. Node i is connected to a randomly-selected node l with probability (if no links exist, the probability is one), and the weight in link is set to .
- (iii)
- Node deletion. Any node and its adjacent links (i.e., all of its connections) can be removed with probability .
- When is fixed, the average degree is obtained by adjusting for each . In this paper, we set , , , , and the average degree . The process runs time steps to achieve the stationary state. Due to the node deletion mechanism, a few nodes may be isolated. In that case, we simply connect these nodes randomly to the giant connect component to make all nodes reachable through a path.
- (2)
- Simulation setup:
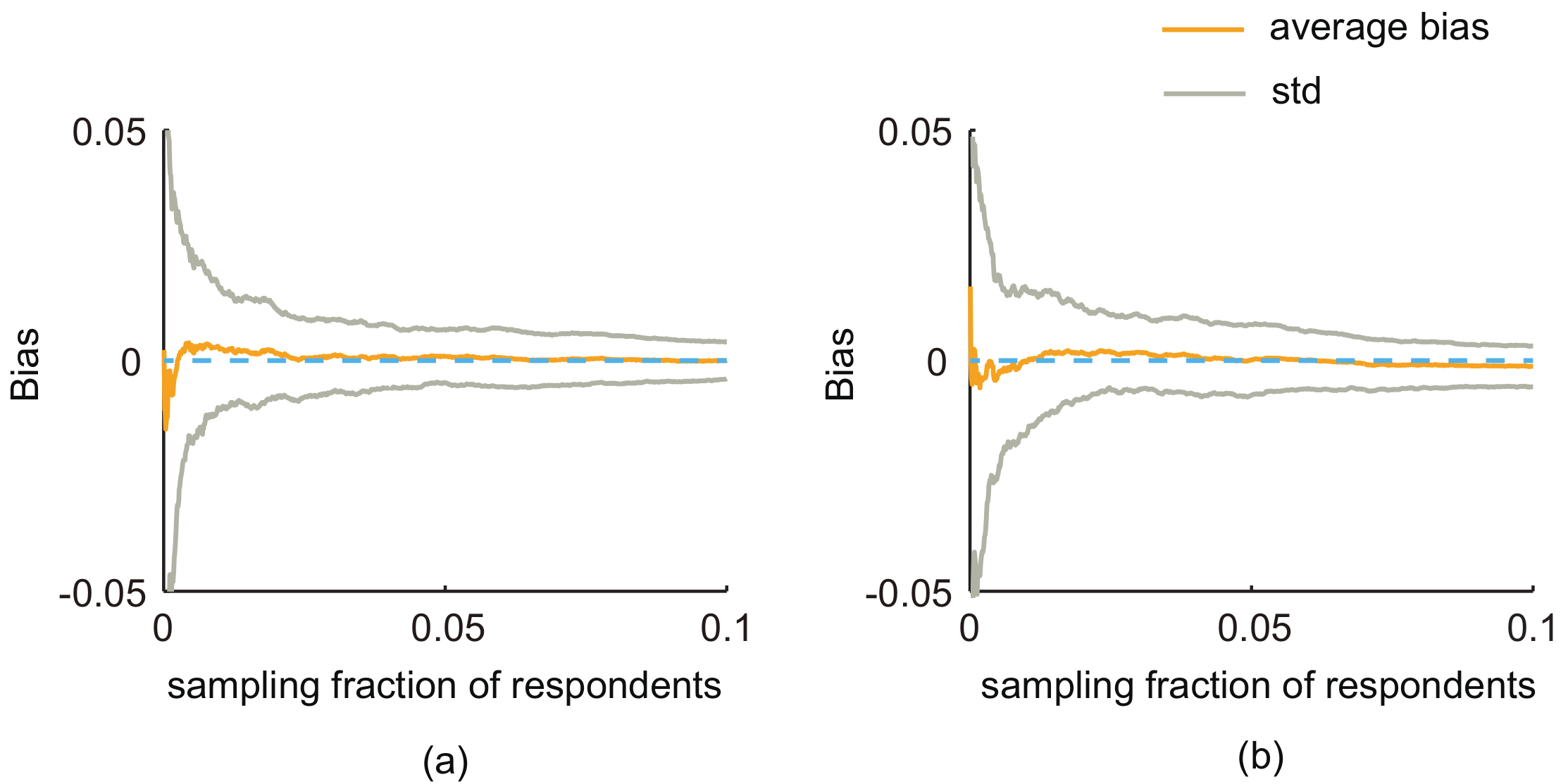
- In each simulation, we first select a number of respondents (10%) through a sampling strategy, i.e., simple random sampling or random walk-based sampling. Then, we collect the characteristics and degrees of the friend nodes of respondents. Finally, we use the collected second-order information to infer the population mean with the SED1 and SED2. For each characteristic, the simulation is repeated 100 times.
- In this paper, we use the average of the biases over simulations to measure the performance of the two proposed estimators:where is the estimate for the population proportion of nodes with Characteristic A from m time simulation, is the real population proportion and M is the number of simulations.
2.4. Generation of Networks with Varying Network Parameters
- (1)
- Degree correlation:
- In real-world social networks, the nodes do not randomly connect to each other as in the random network model. For example, nodes tend to connect preferentially to other nodes with either similar or opposite degree values [36,37]. In this paper, we use the Pearson correlation coefficient, r, to quantify the degree correlation [36]:where M is the number of edges in networks and and are the degree of nodes at the end of the i-th edge. The correlation coefficient r lies between −1 and one. When , the network shows assortative mixing patterns, i.e., nodes of the network tend to be connected with similar degree values. When , the network is disassortative, i.e., nodes of the network tend to be connected with opposite degree values.
- To investigate the effect of degree correlation on the proposed method, we adjust it by a degree-preserving random edge rewiring operation. Specifically, we first randomly pick a pair of edges from the network, and . Then, we sort these nodes, i.e., , , and , by their degree values. If , we rewire the two edges as and (as and ) if we want to increase (decrease) the degree correlation. If new edges do not exist and the recalculated is approaching the desired value, this rewiring operation is kept. Otherwise, the operation is rolled back. The above processes are repeated until reaches the desired value.
- (2)
- Homophily:
- Similar to the assortative mixing patterns on degrees, homophily measures the phenomenon that nodes with the same characteristics tend to connect with each other [38,39], which is often observed in real-world social networks. In this paper, we quantify homophily by the probability that nodes connect with neighbors who are similar to themselves with respect to the studied Characteristic A rather than that they connect randomly [34]:where is the proportion of links originating from nodes with Characteristic A and ending in the same characteristic nodes among all links originating from Characteristic A nodes. When = 1, all Characteristic A nodes only connect with Characteristic A nodes themselves, and there is no cross-group connection between Characteristic A nodes and Characteristic B nodes. When = 0, there exists no preference of link formation regarding Characteristic A.
- To generate the networks with varying homophily, a degree-preserving edge rewiring operation is used in this paper. Let be the homophily of the current network and be the desired value. When , two with-group edges, and , are randomly picked (i.e., , are with Characteristic A, and , are with Characteristic B). Then, we rewire the two edges as and to increase the cross-group edges and decrease the homophily. When , we pick two cross-group edges randomly and rewire them to form two within-group edges and increase the homophily. The above processes are repeated until reaches .
- (3)
- Activity ratio:
- In real-world networks, the personal networks of nodes are not independent of node characteristics. In this paper, we use the activity ratio (AR) [40] to quantify this characteristic of networks, i.e., the ratio of the mean degree for all nodes with Characteristic A to those with Characteristic B [40]:where and are the number of nodes with Characteristic A and B, respectively. When AR = 1, the formation of the personal networks is independent of the node characteristics; otherwise, it is affected by the node characteristics.
- In this paper, we generate networks with varying activity ratios by a characteristic exchange operation. Let w be the activity ratio of the current network and be the value we desire to set. When , we randomly pick two nodes, node i with Characteristic A and node j with Characteristic B. The degree of them is and , respectively. If , we exchange the characteristics of two nodes, i.e., i becomes a node with Characteristic B and j becomes a node with Characteristic A. If , we exchange the characteristics of nodes only if . The above processes are repeated until w reaches .
3. Results
3.1. Simulation of Artificial and Real-World Networks
- (1)
- Simulation with simple random sampling:
- We first implemented the developed methods on different networks with varying characteristics and studied the performance of the estimator developed for the simple random sampling, i.e., SEC1. The results are shown in Figure 2a. First, we can see that the biases of the estimates are all close to zero. The maximum biases of these characteristics are all below 0.04. Second, the average biases of estimates are all less than 0.005. Among them, the maximum average bias is 0.0045 when = 0.388 in the MSM network (i.e., characteristic ct). Third, the standard deviations of the biases for the characteristics of the real-world network are larger than those in the artificial networks.
- These results indicate that although the performance of the SEC1 for different characteristics is different, the biases and variances are all small. That is to say, the method with the simple random sampling is feasible in both artificial and real-world networks.
- (2)
- Inference with respondents from random walk-based sampling:
- Then, we implemented the developed methods on these characteristics and study the performance of the SEC2, which was developed for the random walk-based sampling. Results are shown in Figure 2b. As we can see, these results are similar to those obtained by SEC1. The average biases for the characteristics of artificial networks are all close to zero. The estimates for the characteristics of the real-world networks show slightly larger biases. The biases of these variables deviate from zero: the estimates of age and ct are larger than the real population value (average biases of estimates are 0.003 for age and 0.030 for ct), and the estimates of cs are slightly lower than the real population value (the average bias of estimates is 0.014).
- The above results illustrate the effectiveness of the SEC2. Although variation of the performance was observed for different characteristics, the biases of estimates are all small and within acceptable limits (the maximum bias is 0.046 for ct).
3.2. Simulation with Varying Network Parameters
- (1)
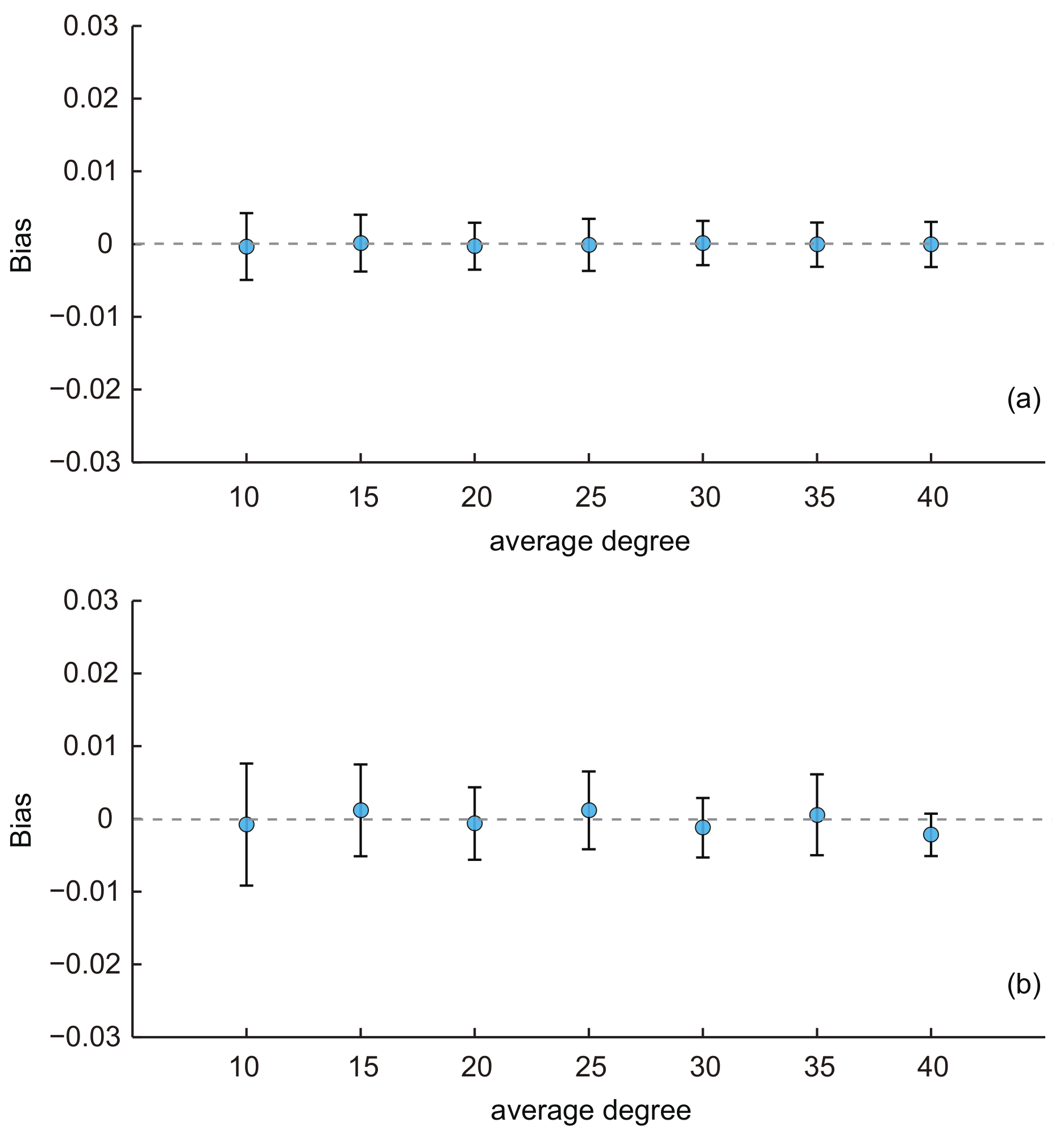
- Effect of average degree:
- First, we investigated the effect of the average network degree on the performance of the two estimators. Besides the baseline network (the average degree was 10), six additional KOSKK networks were generated with the same parameter configurations except that the average degrees were 15, 20, 25, 30, 35 and 40, respectively. Figure 3a shows the results of the SEC1, i.e., when respondents were selected by the simple random sampling. We can see that the average biases are all small and close to zero for varying average degrees. With the increasing of the average degree, the average biases of estimates were almost constant, and their standard deviations slightly decreased. An analysis of variance (ANOVA) test [41] indicated that there was no significant difference of the average biases among estimates with different average degree (p-value = 0.94). These results illustrate that the average degree has a limited effect on the performance of SEC1.
- Figure 3b shows the results of SEC2, i.e., when respondents are selected by the random walk-based sampling. These results are similar to those in Figure 3a. The average biases of estimates were almost constant, and their standard deviations slightly decreased with the increasing of the average degree. However, an ANOVA test indicated that there existed a significant difference of the average biases among estimates with different average degrees (p-value = ). These results reveal that, although the standard deviation of SEC2 was affected by the average degree, this estimator was also effective when the average degree varied due to the fact that the biases were all close to zero.
- (2)
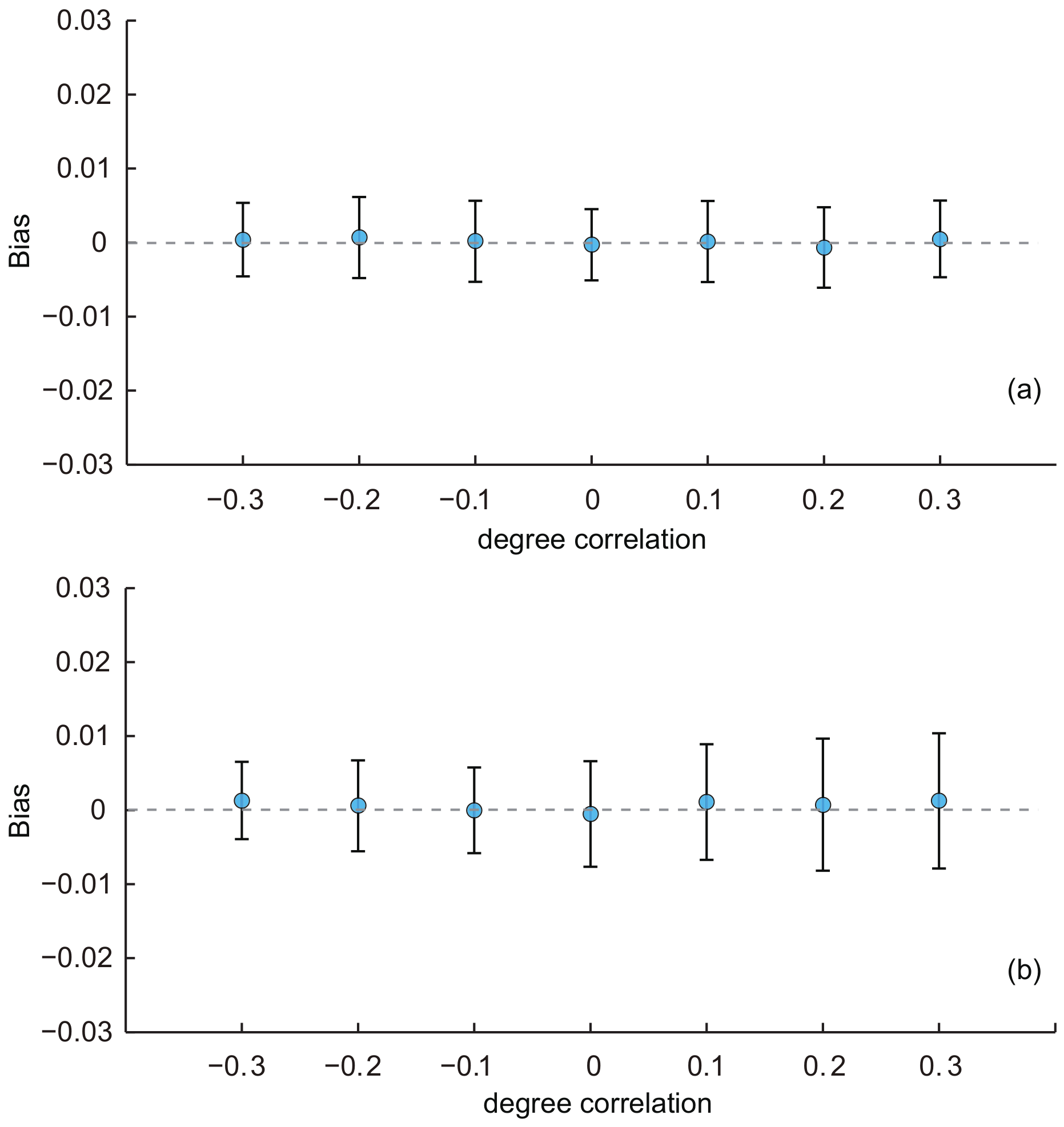
- Effect of degree correlation:
- In this part, we used the baseline KOSKK network and adjusted its degree correlation by the rewiring operation to generate seven networks with degree correlations of −0.3, −0.2, 0.1, 0, 0.1, 0.2 and 0.3, respectively. Then, we ran simulations on these networks with the two sampling strategies and compared the biases of estimates to investigate the effect of the degree correlation. Results are shown in Figure 4.
- In Figure 4a, we can see that the performance of the SEC1 is almost unaffected by the degree correlation: the average biases and their standard deviations were almost constant with the varying degree correlation. Figure 4b shows the results of the SEC2. We can find that the average biases were almost constant, but the standard deviations of the biases slightly increased with the increasing of the degree correlation. The ANOVA test indicated that there was no significant difference of the average biases among estimates with different degree correlations for both two estimators (p-value = 0.58 for SEC1 and 0.51 for SEC2). These results reveal that the degree correlation had a limited effect on the performance of SEC1 and SEC2.
- (3)
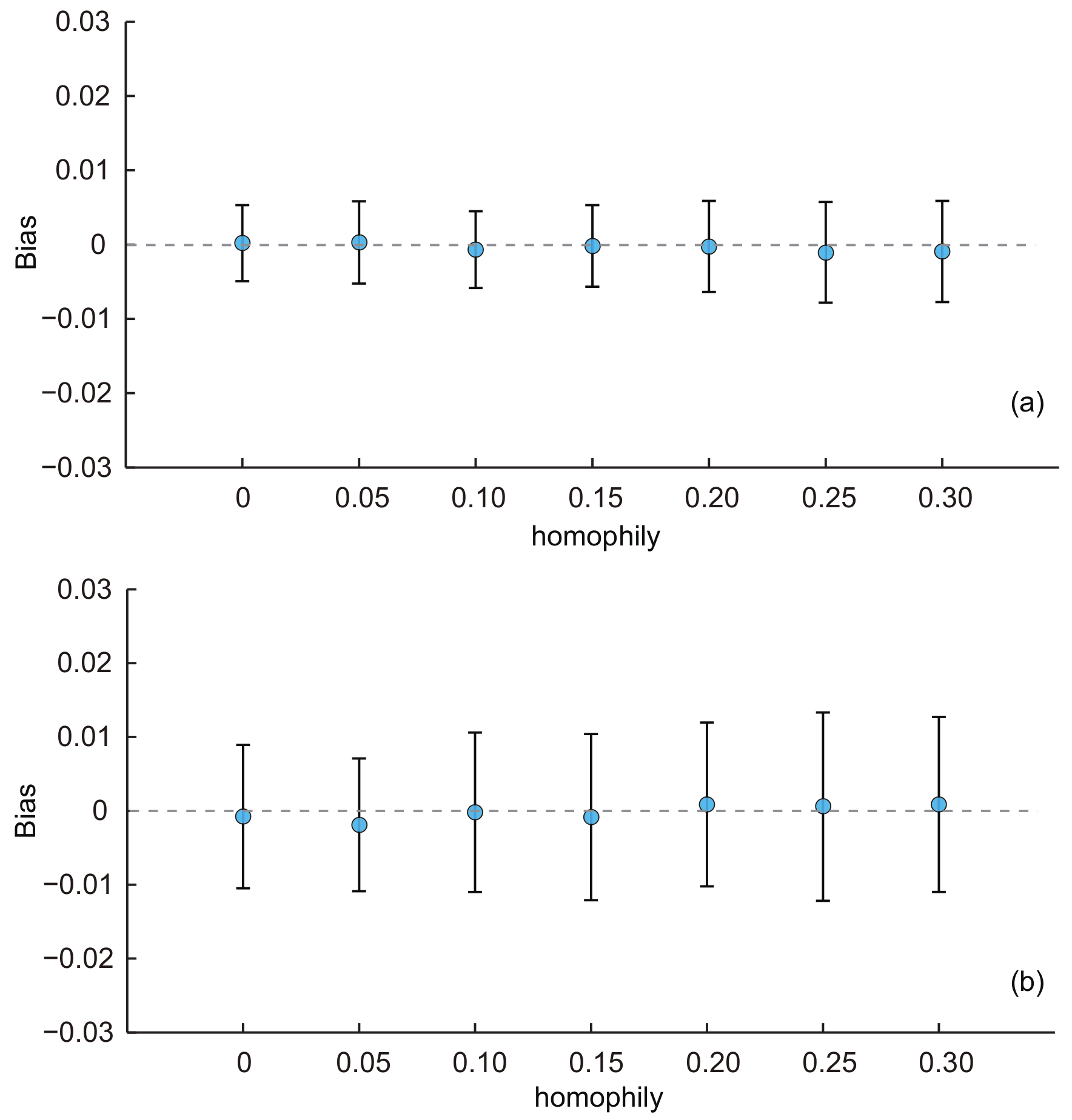
- Effect of homophily:
- Similarly, we used the baseline KOSKK network and adjusted the homophily to generate seven networks with of 0, 0.05, 0.10, 0.15, 0.20, 0.25 and 0.3, respectively. The results are shown in Figure 5. From the results, we can see that the average biases of estimates for two estimators were all constant with the increasing of the homophily. The ANOVA test indicated that there was no significant difference of the average biases among estimates with different homophily for both two estimators (p-value = 0.56 for SEC1 and 0.54 for SEC2). These results illustrate that the homophily had a limited effect on the performance of the estimators. It is worth noting that traditional estimates for random walk-based sampling are well known for their vulnerability on networks with large homophily. For example, in a study of hidden populations [40], the bias was more than 0.1 when population homophily was high. The unbiasedness of SEC2 implies that the use of second-order information increases the robustness of the population inference and is an indication of potential use for surveys to be implemented with undesirable settings.
- (4)
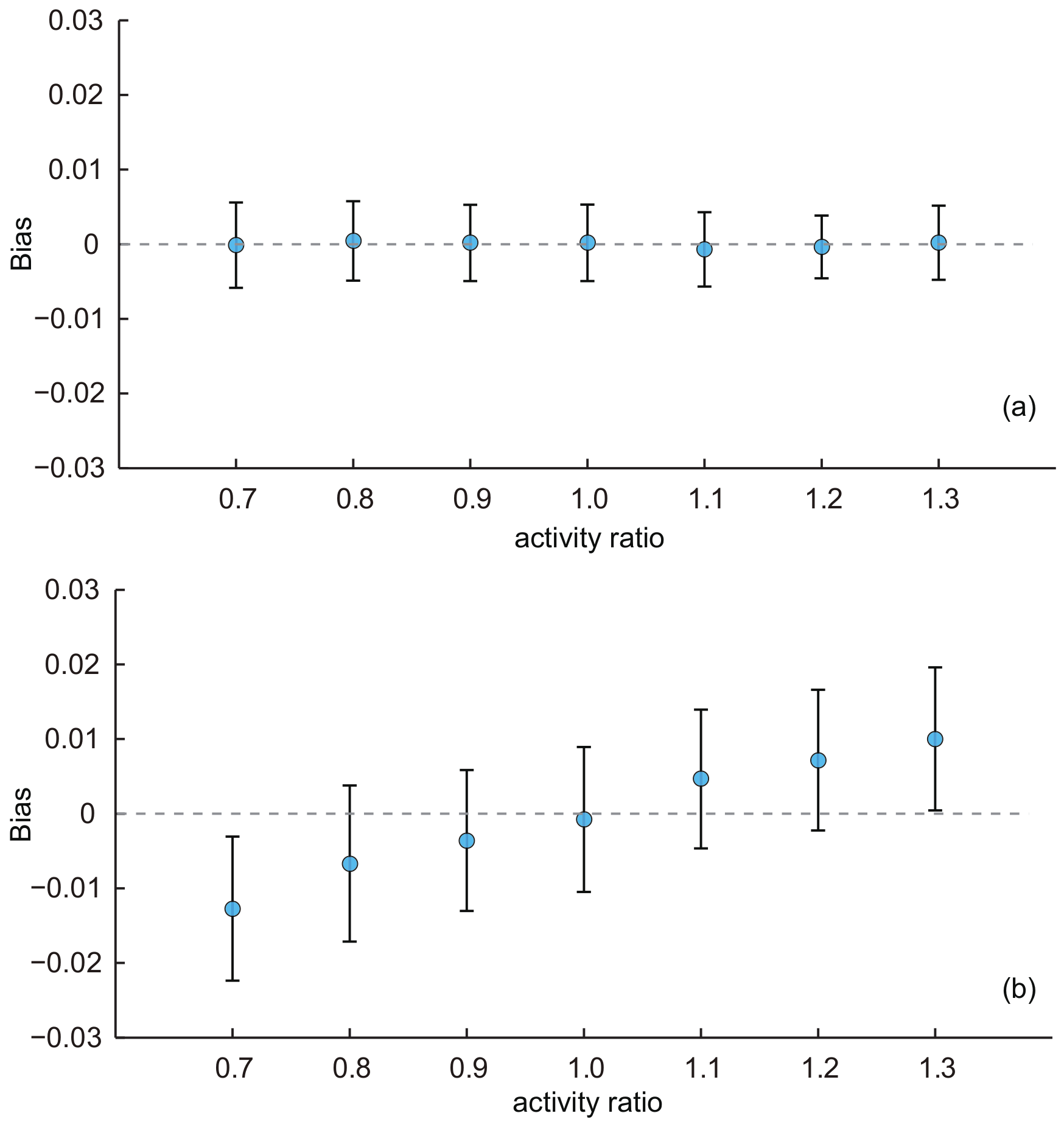
- Effect of activity ratio:
- Finally, we used the baseline KOSKK network to generate seven networks with the varying activity ratios of 0.7, 0.8, 0.9, 1.0, 1.1, 1.2 and 1.3 to investigate the effect of the activity ratio on the performance of two proposed estimators.
- For SEC1, the average biases were almost constant with varying activity ratios (shown in Figure 6a). The ANOVA test indicated that there was no significant difference of the average biases among estimates with different activity ratios for this estimator (p-value = 0.73). For SEC2, we find quite different results in Figure 6b. The performance of SEC2 was greatly affected by the activity ratio. When AR = 1, the average bias is almost zero. However, no matter whether AR is less than or large than one, the average biases deviated from zero: the bias increased with AR, and when AR < 1, the biases tended to be smaller than zero; when AR > 1, the biases tended to be larger than zero. Recalling the results on the MSM real-world network, we also find a similar effect of AR on the estimates: the average biases of characteristic age and ct were larger than zero because their ARs are larger than one (AR = 1.08 for characteristic age and 1.24 for characteristic ct). For characteristic cs (AR = 0.94), the average bias was slightly lower than zero. The most extreme AR existed for the characteristic ct (AR = 1.24) and the average bias of the estimates was the largest: 0.03. On the other hand, for pf (AR = 1.03), which had the AR closest to one, the average bias was the smallest and was almost zero. Note that even SEC2 was affected by the activity ratio, the bias introduced by AR was not large and within acceptable limits (from 0.7–1.3, the biases were all within 0.03).
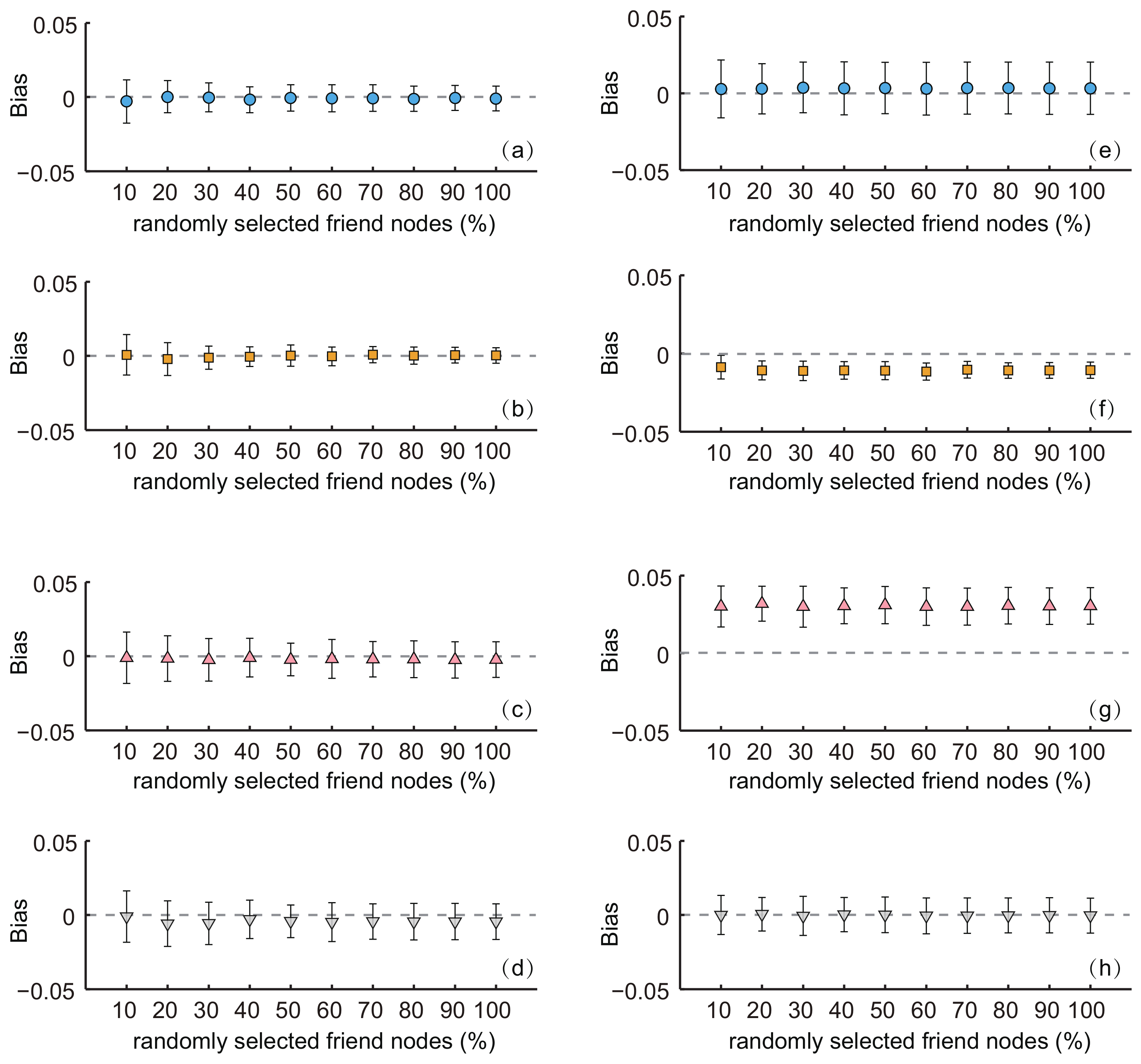
3.3. Simulation with Randomly-Selected Friend Nodes
4. Discussions
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mislove, A.; Marcon, M.; Gummadi, K.P.; Druschel, P.; Bhattacharjee, B. Measurement and analysis of online social networks. In Proceedings of the ACM SIGCOMM Conference on Internet Measurement 2007, San Diego, CA, USA, 24–26 October 2007; pp. 29–42. [Google Scholar]
- Zhang, Z.K.; Liu, C.; Zhan, X.X.; Xin, L.; Zhang, C.X.; Zhang, Y.C. Dynamics of information diffusion and its applications on complex networks. Phys. Rep. 2016, 651, 1–34. [Google Scholar] [CrossRef]
- Liu, C.; Lu, X. Analyzing hidden populations online: Topic, emotion, and social network of HIV-related users in the largest Chinese online community. BMC Med. Inform. Decis. Mak. 2018, 18, 2. [Google Scholar] [CrossRef] [PubMed]
- O’Connor, B.; Balasubramanyan, R.; Routledge, B.R.; Smith, N.A. From tweets to polls: Linking text sentiment to public opinion time series. In Proceedings of the International Conference on Weblogs and Social Media, Icwsm, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Diaz, F.; Gamon, M.; Hofman, J.M.; Kıcıman, E.; Rothschild, D. Online and social media data as an imperfect continuous panel survey. PLoS ONE 2016, 11, e0145406. [Google Scholar] [CrossRef] [PubMed]
- Wejnert, C.; Heckathorn, D.D. Web-based network sampling: Efficiency and efficacy of respondent-driven sampling for online research. Sociol. Methods Res. 2008, 37, 105–134. [Google Scholar] [CrossRef]
- Irena, J.; Barbara, S.; Grjibovski, A.M.; Elise, K.; Preben, A. Self-reported sexually transmitted infections and their correlates among men who have sex with men in norway: An internet-based cross-sectional survey. BMC Infect. Dis. 2010, 10, 1–11. [Google Scholar]
- Bartlett, Y.K.; Coulson, N.S. An investigation into the empowerment effects of using online support groups and how this affects health professional/patient communication. Patient Educ. Counsel. 2011, 83, 113–119. [Google Scholar] [CrossRef] [PubMed]
- Farvolden, P.; Denisoff, E.; Selby, P.; Bagby, R.M.; Rudy, L. Usage and longitudinal effectiveness of a Web-based self-help cognitive behavioral therapy program for panic disorder. J. Med. Intern. Res. 2005, 7, e7. [Google Scholar] [CrossRef] [PubMed]
- Selm, M.V.; Jankowski, N.W. Conducting online surveys. Qual. Quant. 2006, 40, 435–456. [Google Scholar] [CrossRef]
- Leskovec, J.; Faloutsos, C. Sampling from large graphs. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 631–636. [Google Scholar]
- Gjoka, M.; Butts, C.T.; Kurant, M.; Markopoulou, A. Multigraph sampling of online social networks. IEEE J. Sel. Areas Commun. 2010, 29, 1893–1905. [Google Scholar] [CrossRef]
- Leongarcia, A. Probability, Statistics, and Random Processes for Electrical Engineering, International Edition; Pearson Schweiz Ag: Zug, Switzerland, 2008. [Google Scholar]
- Rejaie, R.; Torkjazi, M.; Valafar, M.; Willinger, W. Sizing up online social networks. Netw. IEEE 2010, 24, 32–37. [Google Scholar] [CrossRef]
- Lu, X. Linked ego networks: Improving estimate reliability and validity with respondent-driven sampling. Soc. Netw. 2013, 35, 669–685. [Google Scholar] [CrossRef]
- Lovász, L.; Lov, L.; Erdos, O.P. Random walks on graphs: A survey. Combinatorics 1993, 8, 1–46. [Google Scholar]
- Gjoka, M.; Kurant, M.; Butts, C.T.; Markopoulou, A. A walk in facebook: Uniform sampling of users in online social networks. arXiv, 2009arXiv:0906.0060.
- Tourangeau, R.; Yan, T. Sensitive questions in surveys. Psychol. Bull. 2007, 133, 859–883. [Google Scholar] [CrossRef] [PubMed]
- Nuno, A.; John, F.A.V.S. How to ask sensitive questions in conservation: A review of specialized questioning techniques. Biol. Conserv. 2015, 189, 5–15. [Google Scholar] [CrossRef] [Green Version]
- Coutts, E.; Jann, B. Sensitive questions in online surveys: Experimental results for the randomized response technique (RRT) and the unmatched count technique (UCT). Sociol. Work. Pap. 2008, 40, 169–193. [Google Scholar] [CrossRef]
- Warner, S.L. Randomized response: A survey technique for eliminating evasive answer bias. Publ. Am. Stat. Assoc. 1965, 60, 63–66. [Google Scholar] [CrossRef]
- Dalton, D.R.; Wimbush, J.C.; Daily, C.M. Using the unmatched count technique (UCT) to estimate base rates for sensitive behavior. Pers. Psychol. 1994, 47, 817–829. [Google Scholar] [CrossRef]
- Droitcour, J.A.; Larson, E.M. An innovative technique for asking sensitive questions: The three-card method. BMS Bull. Sociol. Methodol. 2002, 75, 5–23. [Google Scholar] [CrossRef]
- Fishburne, P.M. Survey Techniques for Studying Threatening Topics: A Case Study on the Use of Heroin. Ph.D. Thesis, New York University, New York, NY, USA, 1980. [Google Scholar]
- Rossier, C. Measuring abortion with the Anonymous Third Party Reporting Method. In Methodologies for Estimating Abortion Incidence and Abortion-Related Morbidity: A Review; Singh, S., Remez, L., Eds.; Guttmacher Institute: New York, NY, USA, 2010; Chapter 7; pp. 99–106. [Google Scholar]
- Hansen, M.H.; Hurwitz, W.N. On the theory of sampling from finite populations. Ann. Rheum. Dis. 1943, 14, 2111–2118. [Google Scholar] [CrossRef]
- Chen, S.; Lu, X. An immunization strategy for hidden populations. Sci. Rep. 2017, 7, 3268. [Google Scholar] [CrossRef] [PubMed]
- Catanzaro, M.; Boguná, M.; PastorSatorras, R. Generation of uncorrelated random scale-free networks. Phys. Rev. E 2004, 71, 027103. [Google Scholar] [CrossRef] [PubMed]
- Vázquez, A. Growing network with local rules: Preferential attachment, clustering hierarchy, and degree correlations. Phys. Rev. E 2003, 67, 056104. [Google Scholar] [CrossRef] [PubMed]
- Erdős, P.; Rényi, A. On random graphs. Publ. Math. 1959, 6, 290–297. [Google Scholar]
- Albert, R.; Barabási, A. Statistical mechanics of complex networks. Rev. Mod. Phys. 2002, 74, 47–91. [Google Scholar] [CrossRef]
- Kumpula, J.M.; Onnela, J.P.; Saramäki, J.; Kaski, K.; Kertész, J. Emergence of communities in weighted networks. Phys. Rev. Lett. 2007, 99, 228701. [Google Scholar] [CrossRef] [PubMed]
- Rybski, D.; Buldyrev, S.V.; Havlin, S.; Liljeros, F.; Makse, H.A. Scaling laws of human interaction activity. Proc. Natl. Acad. Sci. USA 2009, 106, 12640–12645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, X.; Bengtsson, L.; Britton, T.; Camitz, M.; Kim, B.J.; Thorson, A.; Liljeros, F. The sensitivity of respondent-driven sampling. J. R. Stat. Soc. Ser. A (Stat. Soc.) 2012, 175, 191–216. [Google Scholar] [CrossRef]
- Toivonen, R.; Kovanen, L.; Kivela, M.; Onnela, J.P.; Saramaki, J.; Kaski, K. A comparative study of social network models: Network evolution models and nodal attribute models. Soc. Netw. 2009, 31, 240–254. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E. Assortative mixing in networks. Phys. Rev. Lett. 2002, 89, 208701. [Google Scholar] [CrossRef] [PubMed]
- Hu, H.B.; Wang, X.F. Disassortative mixing in online social networks. EPL (Europhys. Lett.) 2009, 86, 18003. [Google Scholar] [CrossRef] [Green Version]
- McPherson, M.; SmithLovin, L.; Cook, J.M. Birds of a feather: Homophily in social networks. Annu. Rev. Sociol. 2001, 27, 415–444. [Google Scholar] [CrossRef]
- Morris, M.; Kretzschmar, M. Concurrent partnerships and transmission dynamics in networks. Soc. Netw. 1995, 17, 299–318. [Google Scholar] [CrossRef]
- Gile, K.J.; Handcock, M.S. Respondent-driven sampling: An assessment of current methodology. Sociol. Methodol. 2010, 40, 285–327. [Google Scholar] [CrossRef] [PubMed]
- Wishart, J. Statistical Tables for Biological, Agricultural and Medical Research; Oliver & Boyd: Edinburgh, UK, 1963; p. 533. [Google Scholar]








© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Lu, X.; Liu, Z.; Jia, Z. Inferring the Population Mean with Second-Order Information in Online Social Networks. Entropy 2018, 20, 480. https://doi.org/10.3390/e20060480
Chen S, Lu X, Liu Z, Jia Z. Inferring the Population Mean with Second-Order Information in Online Social Networks. Entropy. 2018; 20(6):480. https://doi.org/10.3390/e20060480
Chicago/Turabian StyleChen, Saran, Xin Lu, Zhong Liu, and Zhongwei Jia. 2018. "Inferring the Population Mean with Second-Order Information in Online Social Networks" Entropy 20, no. 6: 480. https://doi.org/10.3390/e20060480
APA StyleChen, S., Lu, X., Liu, Z., & Jia, Z. (2018). Inferring the Population Mean with Second-Order Information in Online Social Networks. Entropy, 20(6), 480. https://doi.org/10.3390/e20060480