The strong correlation between chromatic information and the various forms of vertex entropy derived graph entropies may at first seem paradoxical. The first quantity is combinatorial in nature and depends upon the precise arrangement of edges and vertices to produce the optimal coloring, which dictates its value. The summed vertex entropies, at least to first order, depend solely upon the individual node degrees and take little or no account of the global arrangement of the graph.
To begin our analysis, it must first be noted that the experimental data is generated by sampling a number of randomly generated graphs of varying size. The only relationship between the graphs is the manner of their construction, and, crucially the resultant degree distributions of the graphs. Let us consider an ensemble of graphs
, with degree distributions
and fixed order
. For this ensemble, as we do not know in advance the structure of the chromatic decomposition of a given graph, we can calculate the chromatic information for an “averaged” member
G of order
n, and chromatic number
, by using the average size of a chromatic class as follows:
where
is the average size of the chromatic class. This quantity, although not an actual expectation value, can be used to provide an upper bound on chromatic information (and conversely the minimum of entropy) as discussed below. In order to establish that this expression acts as an upper bound, it is sufficient to note that
, and Equation (
3) must be maximized subject to this constraint. It is a standard result that this is satisfied when
are identical for all chromatic classes. Equation (
18) simply sets them to be an identical partitioning of vertices by chromatic number.
In the case of the scale-free graphs, this yields analytically soluble integrals for inverse degree, fractional degree vertex entropies, and edge densities but for the clustering coefficient entropies, and for all
random graphs the integrals are not solvable directly. To simplify the analysis, we use the approximate continuum result for the scale-free degree distributions at
,
, where
m is the number of nodes a new nodes connects to during attachment. For the clustering coefficient, we can make a very rough approximation in the case of scale-free networks of
by arguing that, for an average node degree of
, each of the neighbors shares the average degree and has a probability if
of connecting to another neighbor of the vertex. The quantity is not exactly calculable, but in [
10], a closer approximation gives
, though for simplicity we will use our rough approximation. Where an exact solution is not available, we can roughly approximate the value of
, by replacing the exact degree of the node by the average degree and then asserting
In
Section 2, we presented the analysis of samples of randomly generated graphs created using three schemes. Each of these showed a surprisingly strong correlation between the vertex entropy measures, summed across the whole graph, and the chromatic information obtained using the greedy algorithm. The greedy algorithm is well known to obtain a coloring of an arbitrary graph which is close, but not optimal. Indeed, the chromatic number of the graph obtained from the greedy algorithm
is an upper bound of the true chromatic number
. For a full description, see [
9,
16].
3.1. Gilbert Random Graphs
Let us first consider the case of the Gilbert random graphs. We follow the same treatment and notation as in [
9,
23]. We construct the graph starting with
n vertices, and each of the
possible links are connected with a probability
p. The two parameters
n and
p completely describe the parameters of the generated graph graph, and we denote this family of graphs as
. It is well known that Equation (
18) is maximized when each of the chromatic classes of the graph
are uniform. That is, if the cardinality of a chromatic class is denoted by
, and
is the chromatic number of the graph, we have
This chromatic decomposition is only obtained from the perfect graph on
n vertices,
, and proof of this upper bound is outlined in [
4]. For a given random graph
, we denote the coloring obtained in this way, the homogenized coloring
of
, and we assert that
. It is easy to verify that this yields the following as an expression for the chromatic information:
To build upon the analysis, we consider a randomly selected chromatic class
, which has
nodes. For brevity of notation, we write
as
c and ask the reader to remember that
c is a function of the chromatic number of the graph. We denote the probability that
c randomly selected nodes do not possess a link between them as
, and the probability that
at least one link exists between these nodes as
. We consider a large ensemble of random graphs, generated with the same Gilbert graph parameters
, which we write as
. For a randomly chosen member of this ensemble, the criterion for the graph
to possess a chromatic number
is simply that it is more likely for
c randomly selected nodes in
to be disconnected. That is,
To estimate the first term, we note that for
c randomly chosen nodes to have no connecting edges is given by
We can also estimate the second term, by factoring the probability of a link from any of the nodes
, connecting to another node in
. The total probability is accordingly the product of
Feeding in the standard parameters from the Gilbert graphs, we obtain
If we substitute back in the dependence of
c upon the chromatic number, we obtain the following inequality, as the criteria for a given chromatic number
to support an effective random coloring of the graph, that can be used to estimate
:
It is easy to verify that equality is only ever reached when
, which yields the perfect graph in which
, as every node is adjacent to every other node. The left hand side of Equation (
25) is an increasing function of
, whereas the right hand side is a decreasing function, so as
increases we arrive at a minimum value such that the inequality is satisfied. We take this to be our estimate of the value of
. The obtained value is not a strict upper bound, as we see in
Section 2, but it is a reasonable estimate of the value. Although Equation (
25) as a transcendental equation is not directly soluble, we can numerically solve to determine the value of
for a fixed link probability
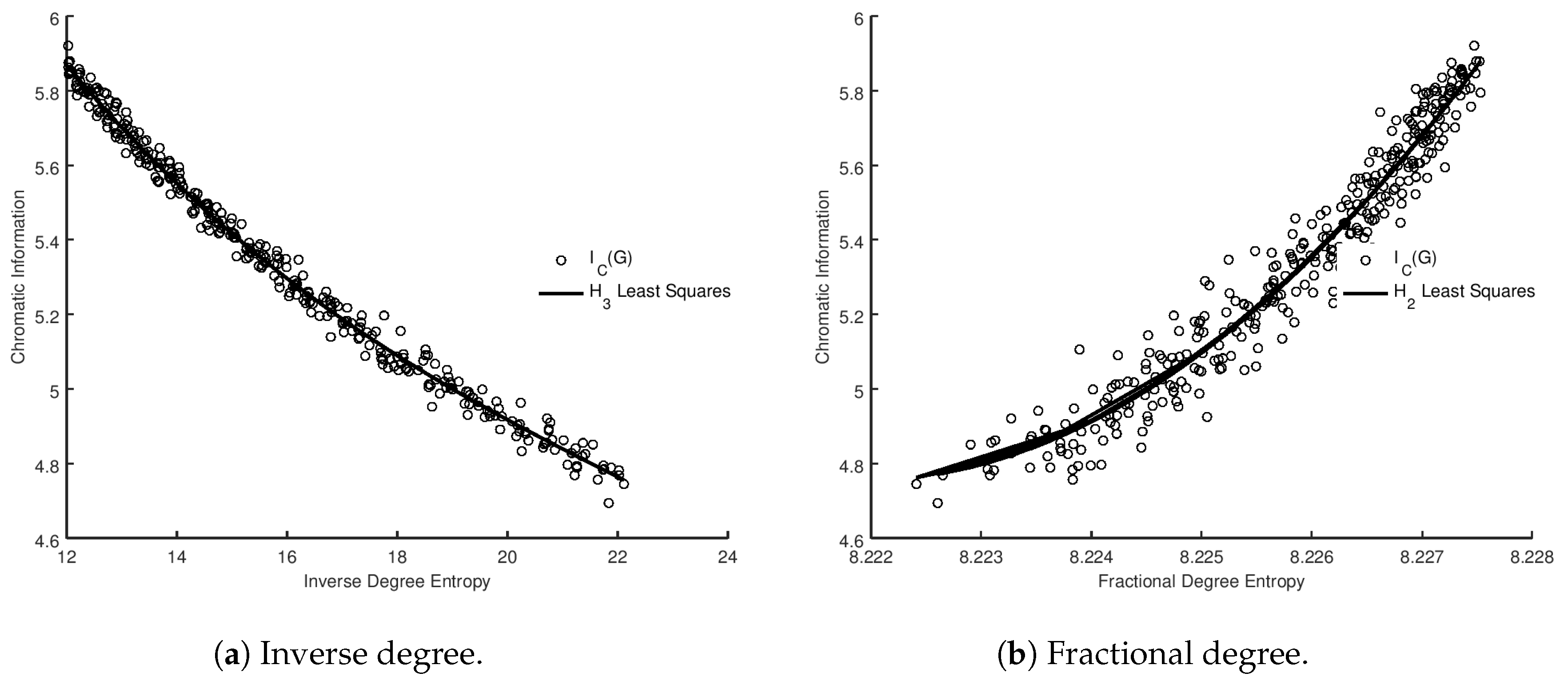
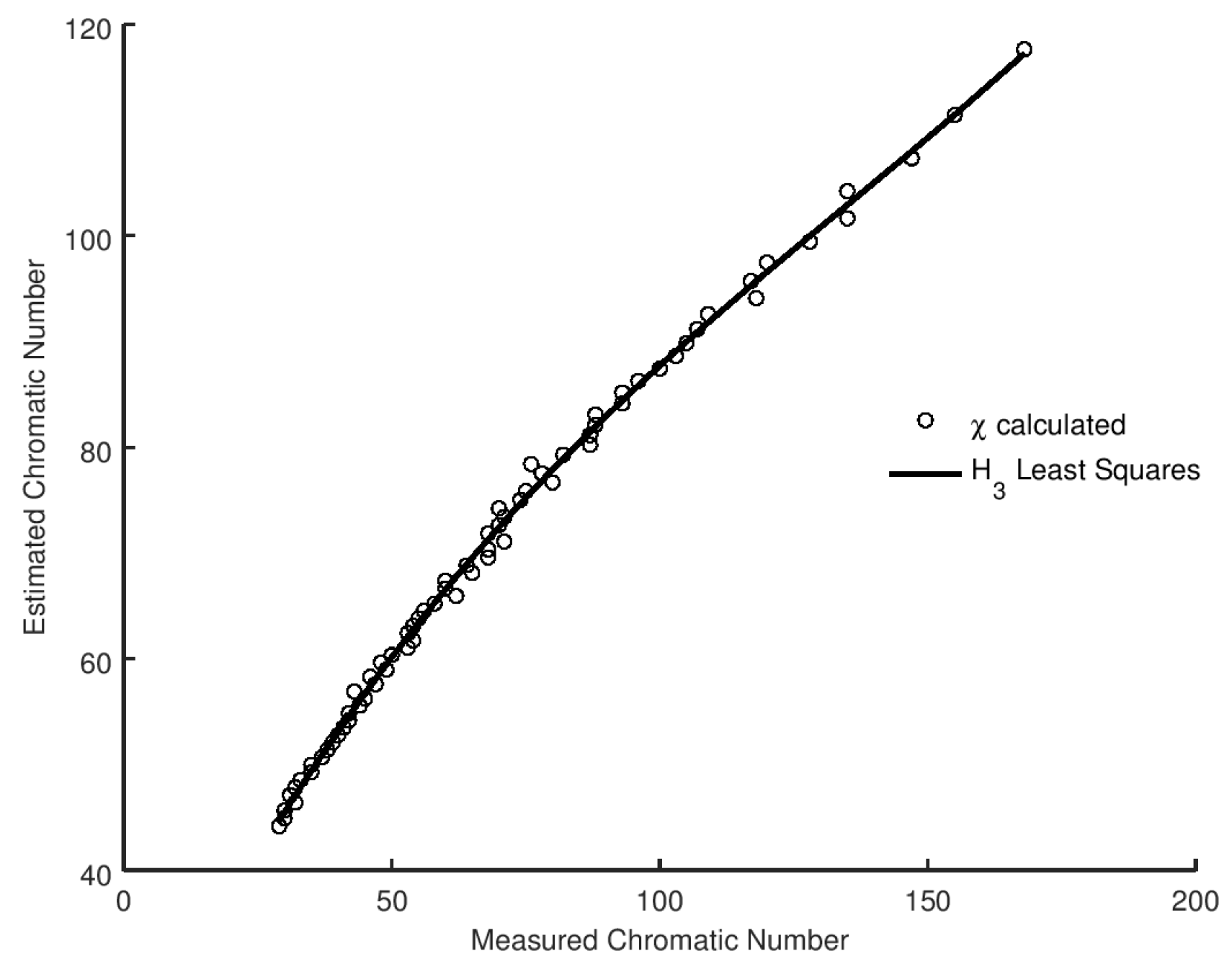
p at which equality is reached. We present the results of the analysis in
Figure 4, together with the optimal least squares fit of the relationship. We can also evaluate the best model for the correlation between our estimate and the measured values using BIC and AIC in the same manner as with the metrics. We present the results in
Table 14. It is evident that a cubic relationship offers the best choice of model, and that fit is overlaid on the experimental data in
Figure 4.
Having established that we can use Equation (
25) to generate a good estimate of the chromatic number of a Gilbert graph, we can now attempt to explain how the chromatic information obtained from the greedy algorithm correlates with the vertex entropy measures. We begin by simplifying Equation (
25) to determine the minimum value of
at which equality is reached, by assuming the limit of
, and
to obtain
Taking the logarithm of both sides of this equation and manipulating we arrive at the following expression:
Equation (
27) represents an approximation for the chromatic information of a random graph. Numerical experimentation indicates that the first term dominates for small values of
p, and as
the second terms becomes numerically larger. Inspection of
Table 13 shows that Equation (
27) contains terms that reflect a number of the expressions for the vertex entropy quantities we have considered. Indeed, as the experiments were conducted at a fixed value of
, for small
p, by elementary manipulation, one can see that
, or alternatively
. Although this is a far from rigorous analytical derivation of the dependence of the chromatic information on the vertex entropy terms, the analysis does perhaps go some way to making the strong correlation experimentally make sense in the context of this theoretical analysis. Deriving an exact relationship between the two quantities is beyond the scope of this work.
3.2. Scale-Free Graphs
In the case of scale-free graphs we can follow a similar analysis to that of the Gilbert graph models. To derive the probability of a link, we can appeal to the preferential attachment model. For a randomly selected node, the average probability of acquiring a link p is computable as . The dependence upon the connection valence m drops out and the average probability of a link existing between two nodes becomes .
Following an identical argument to the random graph case, we arrive at the following relationship:
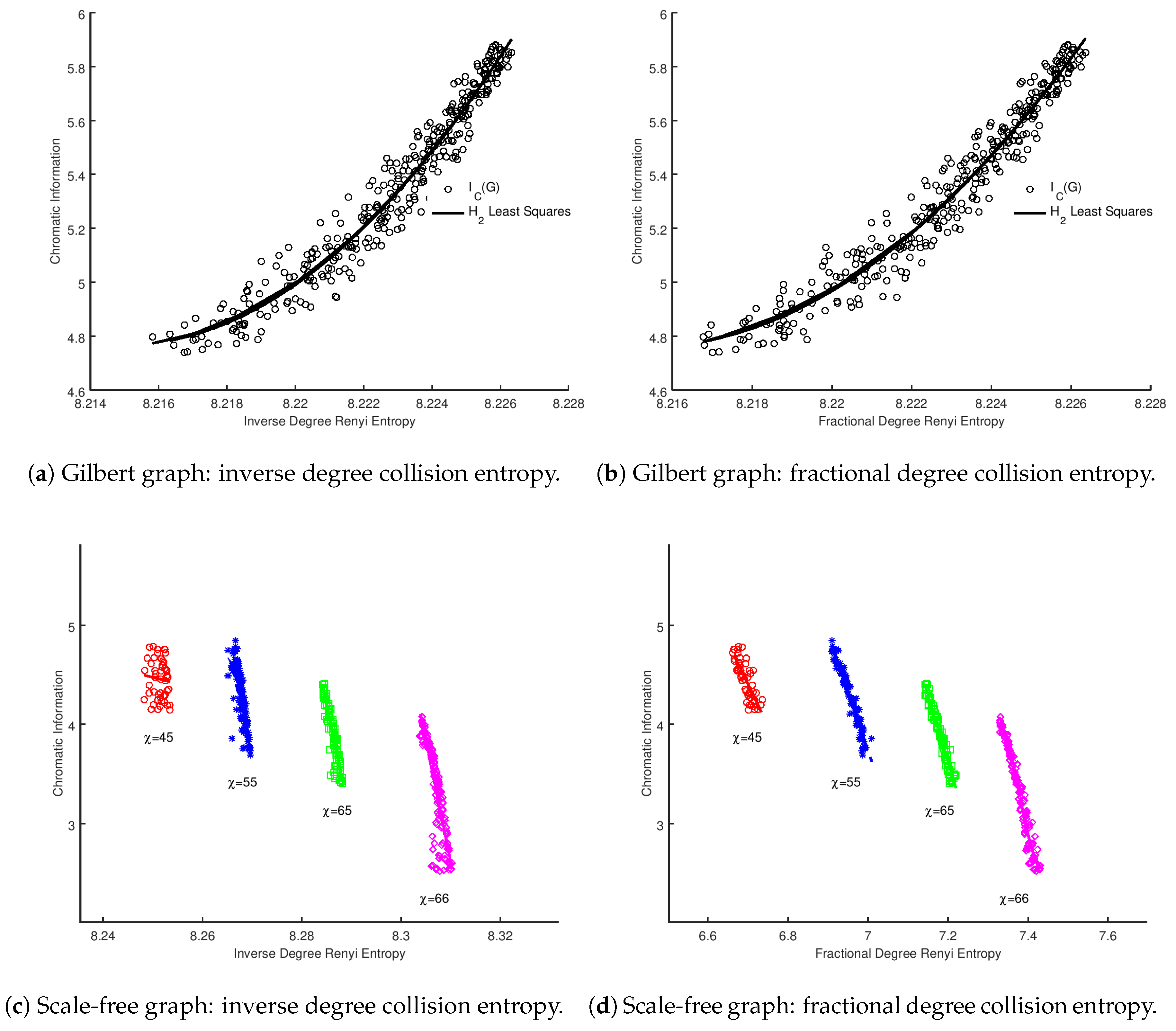
Again, it is important to stress that this is not a rigorous derivation of a relationship between chromatic information and vertex entropy, but it is possible to explain some of the correlations in the results presented in
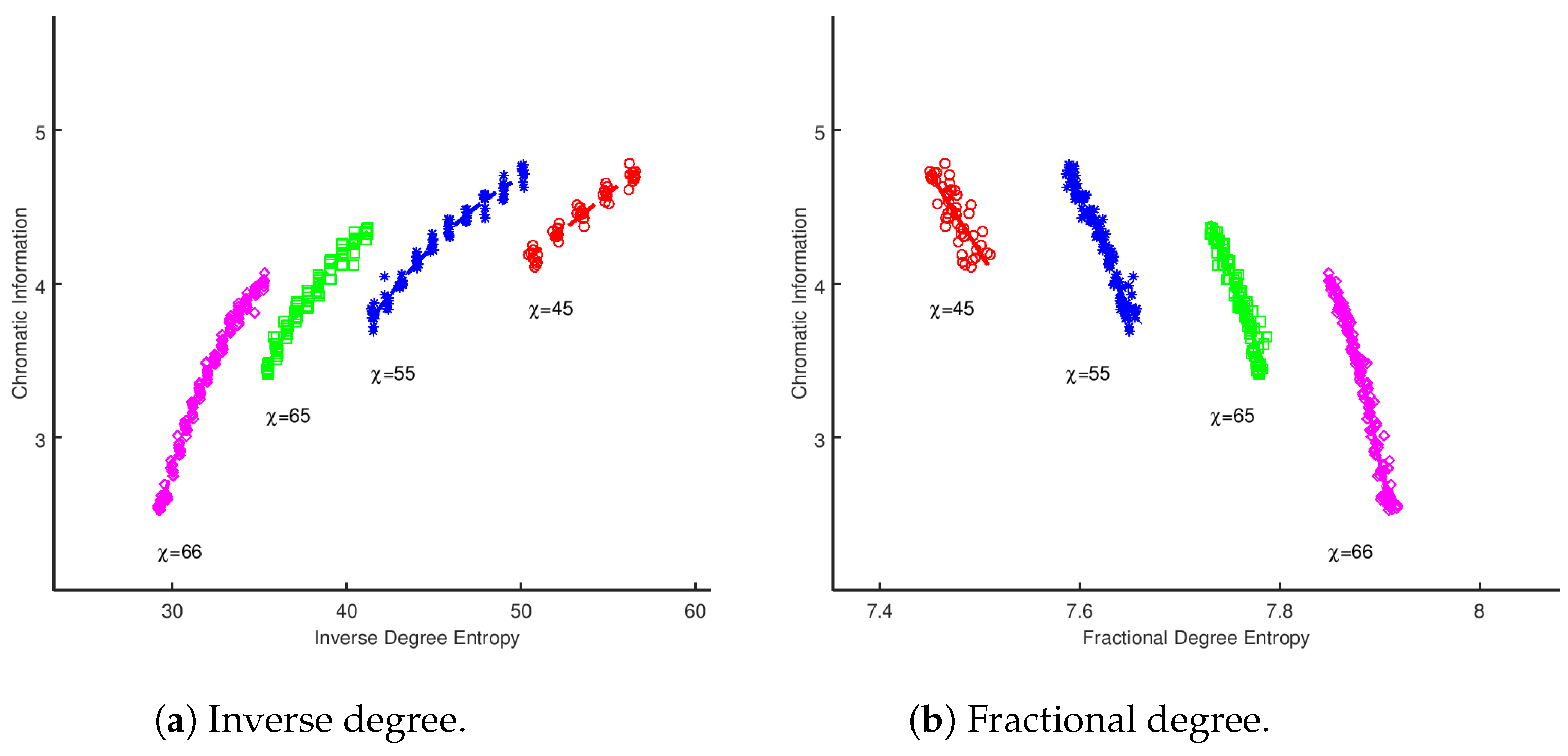
Figure 1. For a given fixed value of
, the experiments represent graphs produced with increasing edge densities. As edges are added to the graph that
do not increase the chromatic number, the size of the chromatic classes will evidently equalize (a discussion of this point can be found in [
4]). This will have the effect of increasing the chromatic information, until a point is reached where
. At this point, the denominator of Equation (
28) will increase, causing a drop in chromatic information. Therefore, as each vertex entropy measure is fundamentally dependent upon the number of edges in a fixed sized graph, we would expect to see a series of correlations for each value of chromatic information, which is indeed what is demonstrated in
Figure 1.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}