A Review of Graph and Network Complexity from an Algorithmic Information Perspective




Abstract
:1. Introduction
1.1. Notation, Metrics, and Properties of Graphs and Networks
1.2. Classical Information Theory
2. Classical Information and Entropy of Graphs
Fragility of Computable Measures Such as Entropy
3. Moving Towards Algorithmic Complexity of Graphs
3.1. Lossless Compression in Network Complexity
3.2. Alternatives to Lossless Compression
3.3. Algorithmic Information Theory
3.4. Algorithmic Probability
3.5. Approximations to Graph Algorithmic Complexity
3.6. Reconstructing K of Graphs from Local Patterns
3.7. Group-Theoretic Robustness of Algorithmic Graph Complexity
3.8. Is Not a Graph Invariant But Highly Informative
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zenil, H.; Badillo, L.; Hernández-Orozco, S.; Hernandez-Quiroz, F. Coding-theorem like behaviour and emergence of the universal distribution from resource-bounded algorithmic probability. Int. J. Parallel Emergent Distrib. Syst. 2018. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef] [Green Version]
- Zenil, H. Small data matters, correlation versus causation and algorithmic data analytics. In Berechenbarkeit der Welt? Pietsch, W., Wernecke, J., Ott, M., Eds.; Springer: Wiesbaden, Germany, 2017. [Google Scholar]
- Zenil, H.; Soler-Toscano, F.; Dingle, K.; Louis, A. Graph automorphisms and topological characterization of complex networks by algorithmic information content. Phys. A Stat. Mech. Appl. 2014, 404, 341–358. [Google Scholar] [CrossRef]
- Babai, L.; Luks, E.M. Canonical labelling of graphs. In Proceedings of the 15th Annual ACM Symposium on Theory of Computing, Boston, MA, USA, 25–27 April 1983; ACM: New York, NY, USA; pp. 171–183. [Google Scholar]
- Erdős, P.; Rényi, A. On random graphs I. Publ. Math. Debrecen 1959, 6, 290–297. [Google Scholar]
- Gilbert, E.N. Random graphs. Ann. Math. Stat. 1959, 30, 1141–1144. [Google Scholar] [CrossRef]
- Boccaletti, S.; Bianconi, G.; Criado, R.; del Genio, C.I.; Gómez-Gardenes, J.; Romance, M.; Sendiña-Nadal, I.; Wang, Z.; Zanin, M. The structure and dynamics of multilayer networks. Phys. Rep. 2014, 544, 1–122. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Dehmer, M.; Emmert-Streib, F.; Shi, Y. Entropy bounds for dendrimers. Appl. Math. Comput. 2014, 242, 462–472. [Google Scholar] [CrossRef]
- Orsini, C.; Dankulov, M.M.; Colomer-de-Simón, P.; Jamakovic, A.; Mahadevan, P.; Vahdat, A.; Bassler, K.E.; Toroczkai, Z.; Boguñá, M.; Caldarelli, G.; et al. Quantifying randomness in real networks. Nat. Commun. 2015, 6, 8627. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zenil, H.; Kiani, N.A.; Tegnér, J. An algorithmic refinement of maxent induces a thermodynamic-like behaviour in the reprogrammability of generative mechanisms. arXiv, 2018; arXiv:1805.07166. [Google Scholar]
- Bianconi, G. The entropy of randomized network ensembles. EPL 2007, 81, 28005. [Google Scholar] [CrossRef] [Green Version]
- Shang, Y. Bounding extremal degrees of edge-independent random graphs using relative entropy. Entropy 2016, 18, 53. [Google Scholar] [CrossRef]
- Estrada, E.; José, A.; Hatano, N. Walk entropies in graphs. Linear Algebra Appl. 2014, 443, 235–244. [Google Scholar] [CrossRef] [Green Version]
- Dehmer, M.; Mowshowitz, A. A history of graph entropy measures. Inf. Sci. 2011, 181, 57–78. [Google Scholar] [CrossRef]
- Sengupta, D.C.; Sengupta, J.D. Application of graph entropy in CRISPR and repeats detection in DNA sequences. Comput. Mol. Biosci. 2016, 6, 41–51. [Google Scholar] [CrossRef]
- Shang, Y. The Estrada index of evolving graphs. Appl. Math. Comput. 2015, 250, 415–423. [Google Scholar] [CrossRef]
- Korner, J.; Marton, K. Random access communication and graph entropy. IEEE Trans. Inf. Theory 1988, 34, 312–314. [Google Scholar] [CrossRef]
- Dehmer, M.; Borgert, S.; Emmert-Streib, F. Entropy bounds for hierarchical molecular networks. PLoS ONE 2008, 3, e3079. [Google Scholar] [CrossRef] [PubMed]
- Zenil, H.; Kiani, N.A.; Tegnér, J. Low algorithmic complexity entropy-deceiving graphs. Phy. Rev. E 2017, 96, 012308. [Google Scholar] [CrossRef] [PubMed]
- Morzy, M.; Kajdanowicz, T.; Kazienko, P. On measuring the complexity of networks: Kolmogorov complexity versus entropy. Complexity 2017, 2017, 3250301. [Google Scholar] [CrossRef]
- Zenil, H.; Soler-Toscano, F.; Kiani, N.A.; Hernández-Orozco, S.; Rueda-Toicen, A. A decomposition method for global evaluation of Shannon entropy and local estimations of algorithmic complexity. arXiv, 2016; arXiv:1609.00110v1. [Google Scholar]
- Kolmogorov, A.N. Three approaches to the quantitative definition of information. Int. J. Comput. Math. 1968, 2, 157–168. [Google Scholar] [CrossRef]
- Martin-Löf, P. The definition of random sequences. Inform. Contr. 1966, 9, 602–619. [Google Scholar] [CrossRef]
- Chaitin, G.J. On the length of programs for computing finite binary sequences. J. ACM 1966, 13, 547–569. [Google Scholar] [CrossRef]
- Solomonoff, R.J. A formal theory of inductive inference: Parts 1 and 2. Inf. Comput. 1964, 13, 224–254. [Google Scholar]
- Levin, L.A. Laws of information conservation (non-growth) and aspects of the foundation of probability theory. Probl. Inform. Trans. 1974, 210, 30–35. [Google Scholar]
- Zenil, H.; Kiani, N.A.; Tegnér, J. Algorithmic complexity of motifs, clusters, superfamilies of networks. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine, Shanghai, China, 18–21 December 2013; pp. 74–76. [Google Scholar]
- Zenil, H.; Kiani, N.A.; Tegnér, N.A. Quantifying loss of information in network-based dimensionality reduction techniques. J. Complex Netw. 2015, 4, 342–362. [Google Scholar] [CrossRef] [Green Version]
- Calude, C.S. Information and Randomness: An Algorithmic Perspective, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Li, M.; Vitányi, P. An Introduction to Kolmogorov Complexity and Its Applications, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Turing, A.M. On computable numbers, with an application to the entscheidungsproblem. Proc. Lond. Math. Soc. 1937, 2, 230–265. [Google Scholar] [CrossRef]
- Kirchherr, W.W.; Li, M.; Vitányi, P.M.B. The miraculous universal distribution. Math. Intell. 1997, 19, 7–15. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Delahaye, J.P.; Zenil, H. Numerical evaluation of the complexity of short strings: A glance into the innermost structure of algorithmic randomness. Appl. Math. Comput. 2012, 219, 63–77. [Google Scholar] [CrossRef]
- Soler-Toscano, F.; Zenil, H.; Delahaye, J.P.; Gauvrit, N. Calculating kolmogorov complexity from the frequency output distributions of small turing machines. PLoS ONE 2014, 9, e96223. [Google Scholar] [CrossRef] [PubMed]
- Zenil, H.; Kiani, N.A.; Tegnér, J. Methods of information theory and algorithmic complexity for network biology. Semin. Cell. Dev. Biol. 2016, 51, 32–43. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zenil, H.; Soler-Toscano, F.; Delahaye, J.P.; Gauvrit, N. Two-dimensional kolmogorov complexity and validation of the coding theorem method by compressibility. PeerJ Comput. Sci. 2015, 1, e23. [Google Scholar] [CrossRef]
- Buhrman, H.; Li, M.; Tromp, J.; Vitányi, P. Kolmogorov random graphs and the incompressibility method. SIAM J. Comput. 1999, 29, 590–599. [Google Scholar] [CrossRef]
- Alon, U. Network motifs: Theory and experimental approaches. Nat. Rev. Genet. 2007, 450, 450–461. [Google Scholar] [CrossRef] [PubMed]
- Langton, C.G. Studying artificial life with cellular automata. Phys. D Nonlinear Phenom. 1986, 22, 120–149. [Google Scholar] [CrossRef]
- Milo, R.; Shen-Orr, S.; Itzkovitz, S.; Kashtan, N.; Chklovskii, D.; Alon, U. Network motifs: Simple building blocks of complex networks. Science 2002, 298, 824–827. [Google Scholar] [CrossRef] [PubMed]
- Zenil, H.; Kiani, N.A.; Marabita, F.; Deng, Y.; Elias, S.; Schmidt, A.; Ball, G.; Tegnér, J. An algorithmic information calculus for causal discovery and reprogramming systems. bioarXiv 2017. [Google Scholar] [CrossRef]



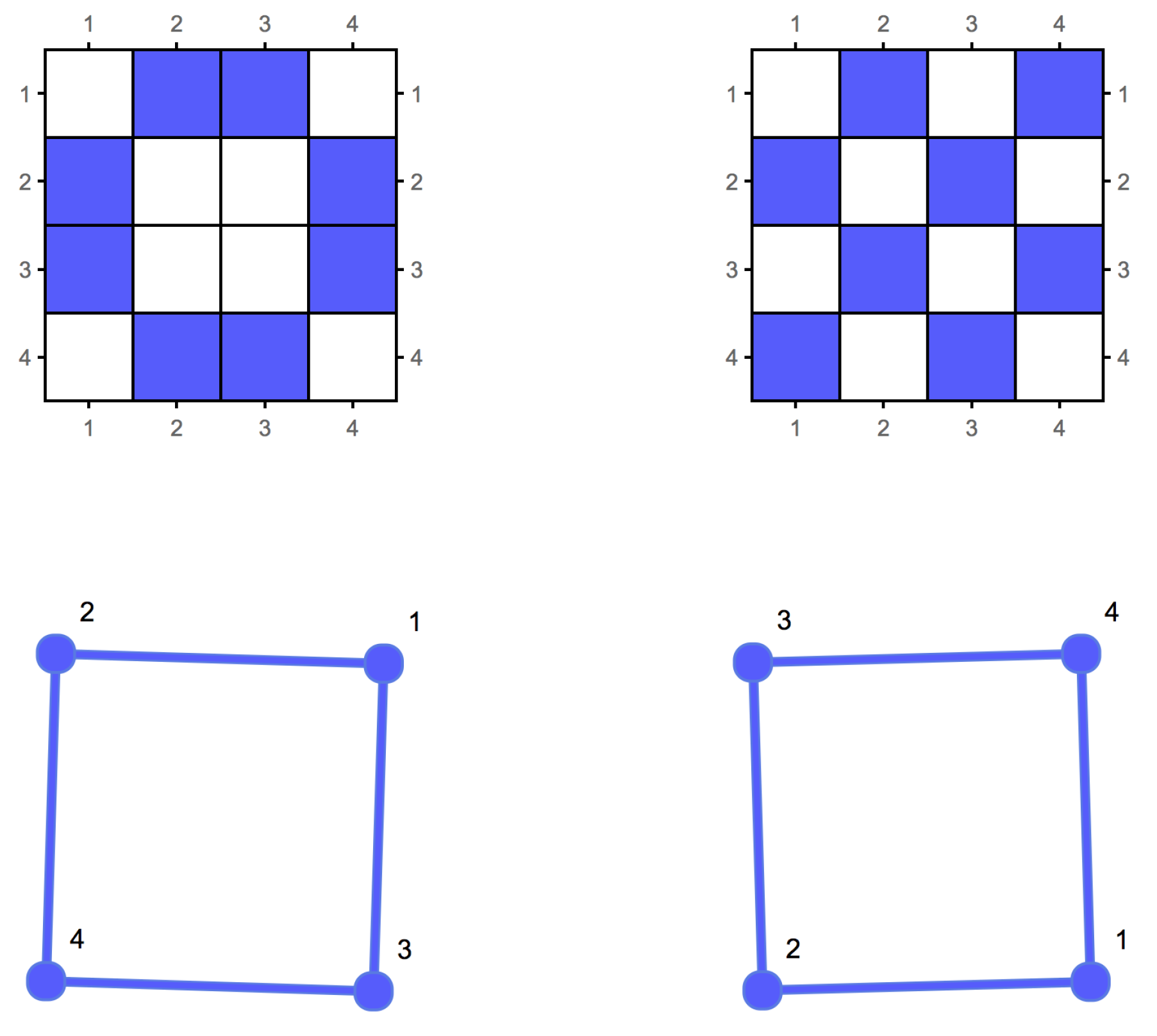{kind=link}
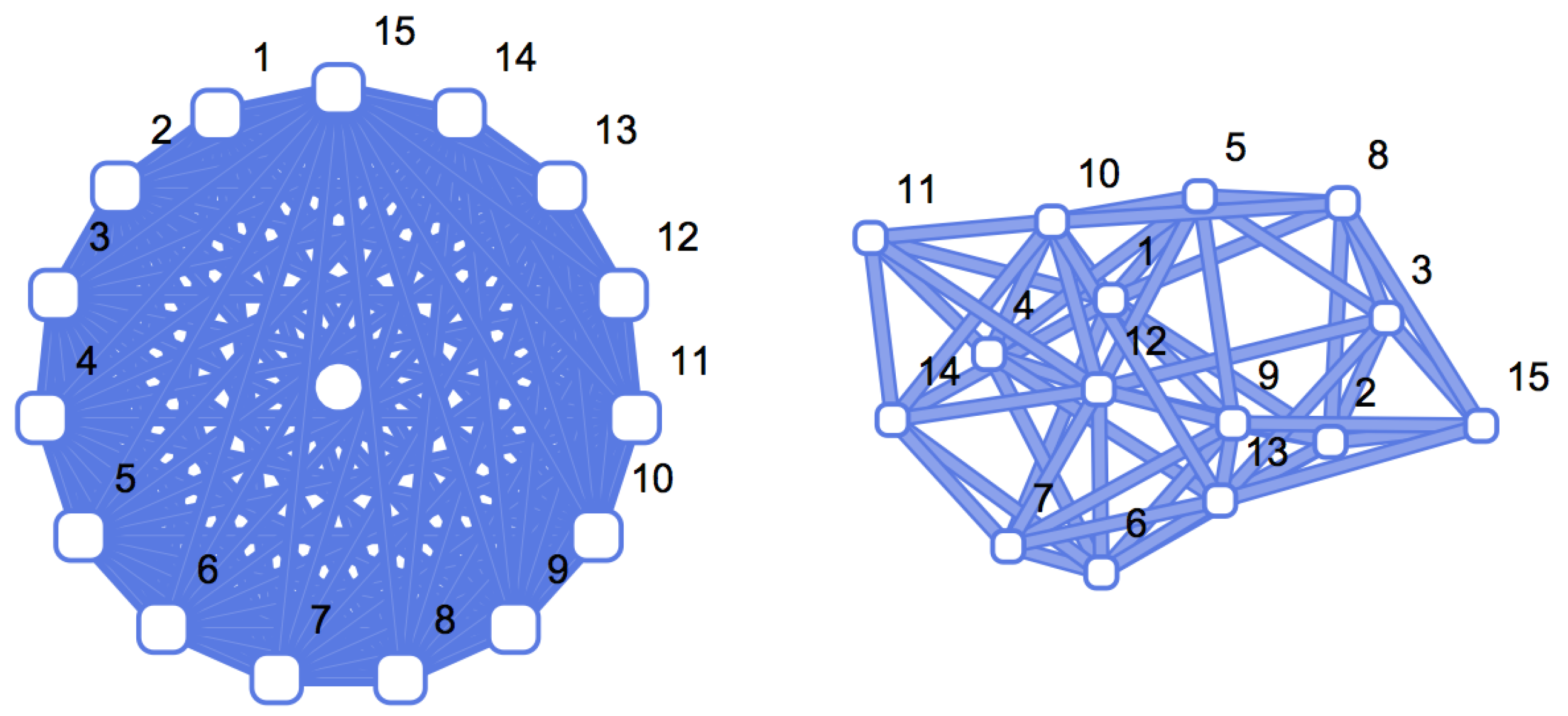{kind=link}
| Type of Graph/Network | Asymptotic Expected Behaviour |
|---|---|
| Empty/Complete | |
| Regular recursive (e.g., cycles, stars) | |
| Barabási-Albert | |
| Watts-Strogatz | |
| or | |
| Algorithmic random Erdős-Rényi | |
| Pseudo-random Erdős-Rényi |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zenil, H.; Kiani, N.A.; Tegnér, J. A Review of Graph and Network Complexity from an Algorithmic Information Perspective. Entropy 2018, 20, 551. https://doi.org/10.3390/e20080551
Zenil H, Kiani NA, Tegnér J. A Review of Graph and Network Complexity from an Algorithmic Information Perspective. Entropy. 2018; 20(8):551. https://doi.org/10.3390/e20080551
Chicago/Turabian StyleZenil, Hector, Narsis A. Kiani, and Jesper Tegnér. 2018. "A Review of Graph and Network Complexity from an Algorithmic Information Perspective" Entropy 20, no. 8: 551. https://doi.org/10.3390/e20080551
APA StyleZenil, H., Kiani, N. A., & Tegnér, J. (2018). A Review of Graph and Network Complexity from an Algorithmic Information Perspective. Entropy, 20(8), 551. https://doi.org/10.3390/e20080551