Information Perspective to Probabilistic Modeling: Boltzmann Machines versus Born Machines


Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
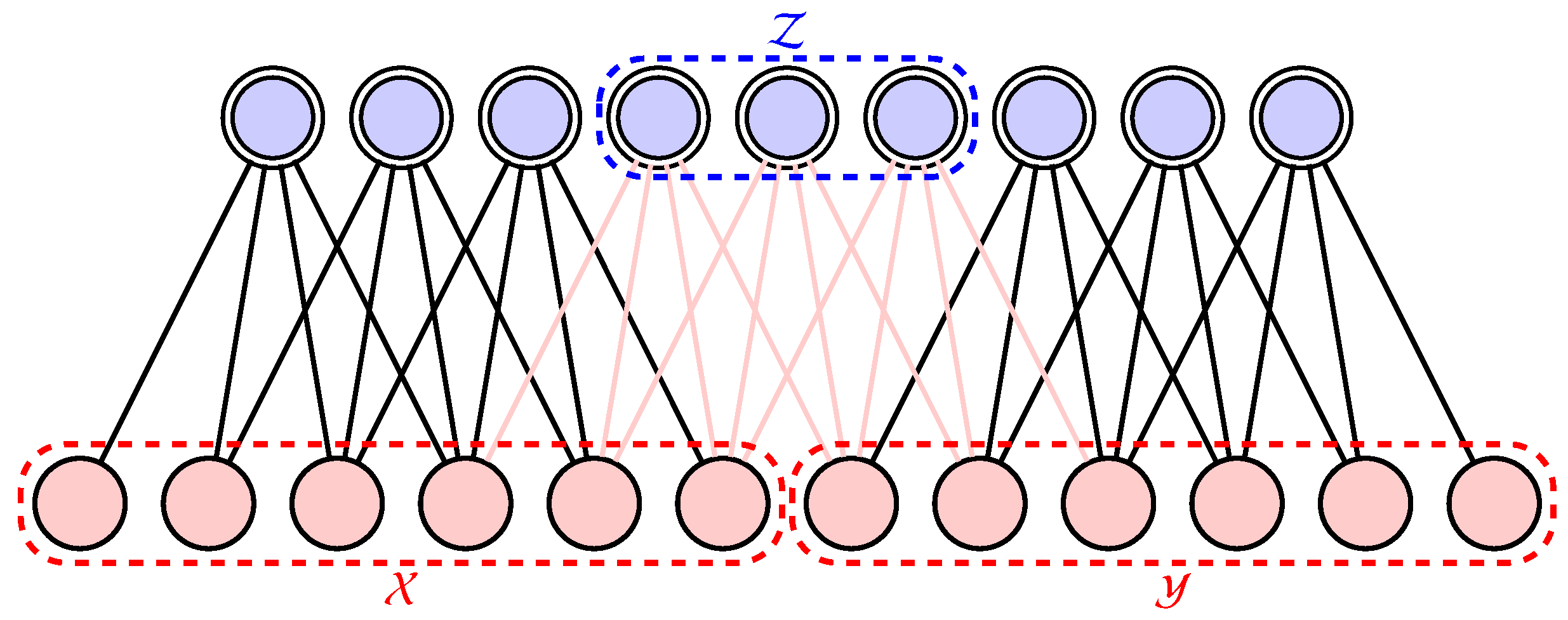
2. Complexity of Dataset: Classical Mutual Information and Quantum Entanglement Entropy
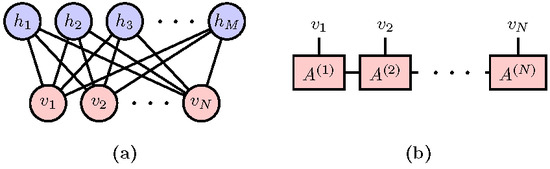
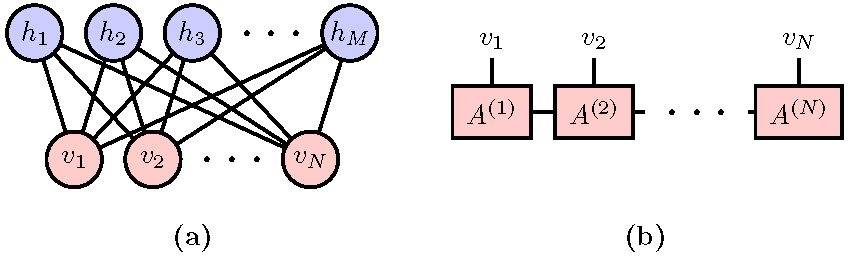
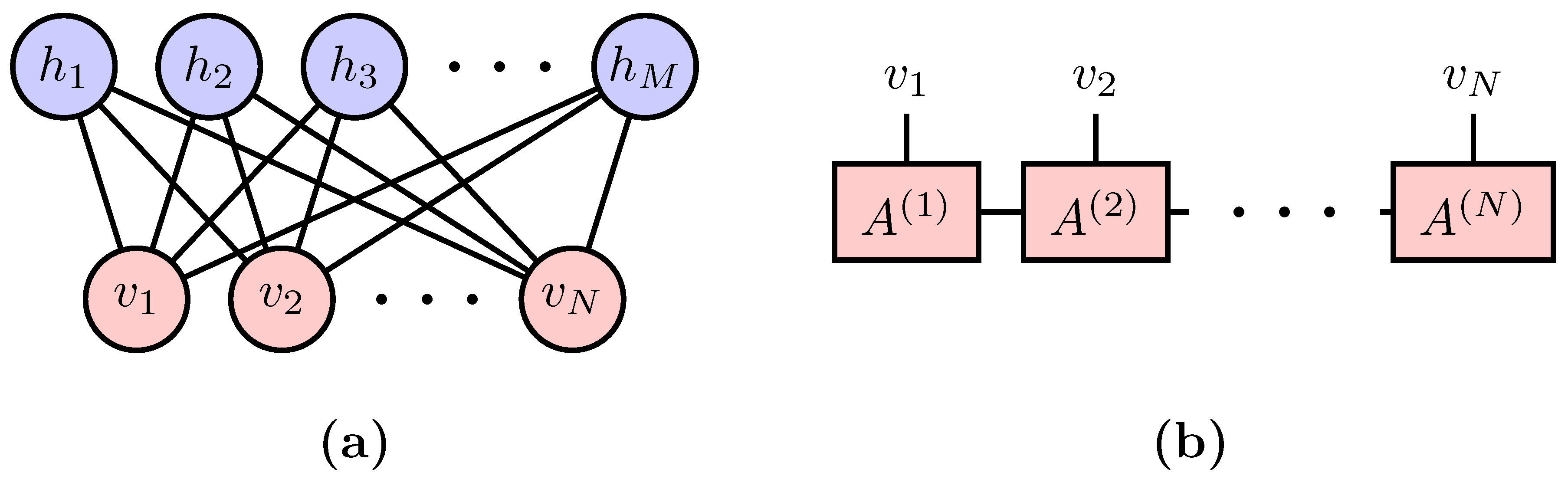
3. Probabilistic Modeling Using Restricted Boltzmann Machine
4. Information Pattern of MNIST Dataset and Its Implication to Generative Modeling
5. Summary
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [PubMed]
- Amit, D.J.; Gutfreund, H.; Sompolinsky, H. Spin-glass models of neural networks. Phys. Rev. A 1985, 32, 1007–1018. [Google Scholar] [CrossRef]
- Nguyen, H.C.; Zecchina, R.; Berg, J. Inverse statistical problems: From the inverse Ising problem to data science. Adv. Phys. 2017, 66, 197–261. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hinton, G.E.; Sejnowski, T.J. Learning and relearning in Boltzmann machines. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986; Volume 1, pp. 282–317. [Google Scholar]
- Hinton, G.E. A Practical Guide to Training Restricted Boltzmann Machines. In Neural Networks: Tricks of the Trade; Springer Berlin Heidelberg: Berlin, Germany, 2012; pp. 599–619. [Google Scholar]
- Barra, A.; Bernacchia, A.; Santucci, E.; Contucci, P. On the equivalence of hopfield networks and boltzmann machines. Neural Netw. 2012, 34, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Carleo, G.; Troyer, M. Solving the quantum many-body problem with artificial neural networks. Science 2017, 355, 602–606. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, D.L.; Li, X.; Das Sarma, S. Quantum entanglement in neural network states. Phys. Rev. X 2017, 7, 021021. [Google Scholar] [CrossRef]
- Gao, X.; Duan, L.M. Efficient representation of quantum many-body states with deep neural networks. Nat. Commun. 2017, 8, 662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, Y.; Moore, J.E. Neural network representation of tensor network and chiral states. arXiv, 2017; arXiv:1701.06246v1. [Google Scholar]
- Torlai, G.; Mazzola, G.; Carrasquilla, J.; Troyer, M.; Melko, R.; Carleo, G. Many-body quantum state tomography with neural networks. arXiv, 2017; arXiv:1703.05334. [Google Scholar]
- Cai, Z. Approximating quantum many-body wave-functions using artificial neural networks. arXiv, 2017; arXiv:1704.05148. [Google Scholar]
- Clark, S.R. Unifying neural-network quantum states and correlator product states via tensor networks. J. Phys. A Math. Theor. 2017, 51, 135301. [Google Scholar] [CrossRef]
- Glasser, I.; Pancotti, N.; August, M.; Rodriguez, I.D.; Cirac, J.I. Neural-networks quantum states, string-bond states and chiral topological states. Phys. Rev. X 2017, 8, 1–15. [Google Scholar] [CrossRef]
- Kaubruegger, R.; Pastori, L.; Budich, J.C. Chiral topological phases from artificial neural networks. Phys. Rev. B 2017, 97, 195163. [Google Scholar] [CrossRef]
- Miles Stoudenmire, E.; Schwab, D.J. Supervised learning with quantum-inspired tensor networks. arXiv, 2016; arXiv:1605.05775. [Google Scholar]
- Chen, J.; Cheng, S.; Xie, H.; Wang, L.; Xiang, T. On the equivalence of restricted boltzmann machines and tensor network states. arXiv, 2017; arXiv:1701.04831. [Google Scholar] [CrossRef]
- Levine, Y.; Yakira, D.; Cohen, N.; Shashua, A. Deep learning and quantum entanglement: fundamental connections with implications to network design. arXiv, 2017; arXiv:1704.01552. [Google Scholar]
- Han, Z.Y.; Wang, J.; Fan, H.; Wang, L.; Zhang, P. Unsupervised generative modeling using matrix product states. arXiv, 2017; arXiv:1709.01662. [Google Scholar] [CrossRef]
- Liu, D.; Ran, S.J.; Wittek, P.; Peng, C.; García, R.B.; Su, G.; Lewenstein, M. Machine learning by two-dimensional hierarchical tensor networks: A quantum information theoretic perspective on deep architectures. arXiv, 2017; arXiv:1710.04833. [Google Scholar]
- Zhang, Y.H. Entanglement entropy of target functions for image classification and convolutional neural network. arXiv, 2017; arXiv:1710.05520. [Google Scholar]
- Pestun, V.; Vlassopoulos, Y. Tensor network language model. arXiv, 2017; arXiv:1710.10248. [Google Scholar]
- Gao, X.; Zhang, Z.; Duan, L. An efficient quantum algorithm for generative machine learning. arXiv, 2017; arXiv:1711.02038. [Google Scholar]
- Huang, Y. Provably efficient neural network representation for image classification. arXiv, 2017; arXiv:1711.04606. [Google Scholar]
- Bailly, R. Quadratic weighted automata: Spectral algorithm and likelihood maximization. In Proceedings of the Asian Conference on Machine Learning, Taoyuan, Taiwain, 13–15 December 2011; Volume 20, pp. 147–163. [Google Scholar]
- Zhao, M.J.; Jaeger, H. Norm-observable operator models. Neural Comput. 2010, 22, 1927–1959. [Google Scholar] [CrossRef] [PubMed]
- Born, M. Zur Quantenmechanik der Stoßvorgänge. Z. Phys. 1926, 37, 863–867. [Google Scholar] [CrossRef]
- Benedetti, M.; Garcia-Pintos, D.; Nam, Y.; Perdomo-Ortiz, A. A generative modeling approach for benchmarking and training shallow quantum circuits. arXiv, 2018; arXiv:1801.07686. [Google Scholar]
- Lin, H.W.; Tegmark, M. Why does deep and cheap learning work so well? arXiv, 2016; arXiv:1608.08225. [Google Scholar]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koch-Janusz, M.; Ringel, Z. Mutual information, neural networks and the renormalization group. Nat. Phys. 2018, 14, 578–582. [Google Scholar] [CrossRef] [Green Version]
- Koller, D.; Friedman, N. Probabilistic Graphical Models, Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- MacKay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Mezard, M.; Montanari, A. Information, Physics, and Computation; Oxford University Press: Cambridge, UK, 2009. [Google Scholar]
- Zeng, B.; Chen, X.; Zhou, D.L.; Wen, X.G. Quantum information meets quantum matter–from quantum entanglement to topological phase in many-body systems. arXiv, 2015; arXiv:1508.02595. [Google Scholar]
- Eisert, J.; Cramer, M.; Plenio, M.B. Colloquium: Area laws for the entanglement entropy. Rev. Mod. Phys. 2010, 82, 277–306. [Google Scholar] [CrossRef]
- Linsker, R. Self-organization in a perceptual network. Computer 1988, 21, 105–117. [Google Scholar] [CrossRef]
- Bell, A.J.; Sejnowski, T.J. An information-maximization approach to blind separation and blind deconvolution. Neural Comput. 1995, 7, 1129–1159. [Google Scholar] [CrossRef] [PubMed]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep variational information bottleneck. arXiv, 2016; arXiv:1612.00410. [Google Scholar]
- Hastings, M.B.; González, I.; Kallin, A.B.; Melko, R.G. Measuring renyi entanglement entropy in quantum monte carlo simulations. Phys. Rev. Lett. 2010, 104, 157201. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Grover, T.; Vishwanath, A. Entanglement Entropy of critical spin liquids. Phys. Rev. Lett. 2011, 107, 067202. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.W.; Tegmark, M.; Rolnick, D. Why does deep and cheap learning work so well? J. Statis. Phys. 2017. [Google Scholar] [CrossRef]
- Hsieh, T.H.; Fu, L. Bulk entanglement spectrum reveals quantum criticality within a topological state. Phys. Rev. Lett. 2014, 113, 106801. [Google Scholar] [CrossRef] [PubMed]
- Rao, W.J.; Wan, X.; Zhang, G.M. Critical-entanglement spectrum of one-dimensional symmetry-protected topological phases. Phys. Rev. B 2014, 90, 075151. [Google Scholar] [CrossRef]
- Iaconis, J.; Inglis, S.; Kallin, A.B.; Melko, R.G. Detecting classical phase transitions with Renyi mutual information. Phys. Rev. B 2013, 87, 195134. [Google Scholar] [CrossRef]
- Smolensky, P. Information Processing in Dynamical Systems: Foundations of Harmony Theory. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986; Volume 1, pp. 194–281. [Google Scholar]
- Hinton, G.; Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Osindero, S. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 2006. [Google Scholar] [CrossRef] [PubMed]
- Nomura, Y.; Darmawan, A.; Yamaji, Y.; Imada, M. Restricted-boltzmann-machine learning for solving strongly correlated quantum systems. arXiv, 2017; arXiv:1709.06475. [Google Scholar]
- Torlai, G.; Melko, R.G. Learning thermodynamics with Boltzmann machines. Phys. Rev. B 2016, 94, 165134–165137. [Google Scholar] [CrossRef]
- Huang, L.; Wang, L. Accelerated Monte Carlo simulations with restricted Boltzmann machines. Phys. Rev. B 2017, 95, 035105. [Google Scholar] [CrossRef]
- Torlai, G.; Melko, R.G. Neural decoder for topological codes. Phys. Rev. Lett. 2017, 119, 030501. [Google Scholar] [CrossRef] [PubMed]
- Wang, L. Exploring cluster Monte Carlo updates with Boltzmann machines. Phys. Rev. E 2017, 96, 051301. [Google Scholar] [CrossRef] [PubMed]
- Morningstar, A.; Melko, R.G. Deep learning the ising model near criticality. arXiv, 2017; arXiv:1708.04622. [Google Scholar]
- Rao, W.J.; Li, Z.; Zhu, Q.; Luo, M.; Wan, X. Identifying product order with restricted boltzmann machines. arXiv, 2017; arXiv:1709.02597. [Google Scholar]
- Freund, Y.; Haussler, D. Unsupervised Learning of Distributions of Binary Vectors Using Two Layer Networks. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers: San Francisco, CA, USA, 1994; pp. 912–919. [Google Scholar]
- Le Roux, N.; Bengio, Y. Representational power of restricted Boltzmann machines and deep belief networks. Neural Comput. 2008, 20, 1631–1649. [Google Scholar] [CrossRef] [PubMed]
- Montufar, G.; Ay, N. Refinements of universal approximation results for deep belief networks and restricted Boltzmann machines. Neural Comput. 2011, 23, 1306–1319. [Google Scholar] [CrossRef] [PubMed]
- Montúfar, G.; Rauh, J. Hierarchical models as marginals of hierarchical models. Int. J. Approx. Reason. 2016. [Google Scholar] [CrossRef]
- Montufar, G.F.; Rauh, J.; Ay, N. Expressive Power and Approximation Errors of Restricted Boltzmann Machines. In Advances in Neural Information Processing Systems 24; Shawe-Taylor, J., Zemel, R.S., Bartlett, P.L., Pereira, F., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2011; pp. 415–423. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Preskill, J. Quantum Shannon theory. arXiv, 2016; arXiv:1604.07450. [Google Scholar]
- Wolf, M.M.; Verstraete, F.; Hastings, M.B.; Cirac, J.I. Area laws in quantum systems: Mutual information and correlations. Phys. Rev. Lett. 2008, 100, 070502. [Google Scholar] [CrossRef] [PubMed]
- Chow, C.; Liu, C. Approximating discrete probability distributions with dependence trees. IEEE Trans. Inform. Theory 1968, 14, 462–467. [Google Scholar] [CrossRef] [Green Version]
- Berglund, M.; Raiko, T.; Cho, K. Measuring the usefulness of hidden units in boltzmann machines with mutual information. Neural Netw. 2015, 64, 12–18. [Google Scholar] [CrossRef] [PubMed]
- Peng, K.H.; Zhang, H. Mutual information-based RBM neural networks. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2458–2463. [Google Scholar]
- Koch-Janusz, M.; Ringel, Z. Mutual information, neural networks and the renormalization group. arXiv, 2017; arXiv:1704.06279. [Google Scholar]
- Salakhutdinov, R.; Hinton, G.E. Deep Boltzmann machines. In Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics (AISTATS’09), Clearwater Beach, FL, USA, 16–18 April 2009; Volume 5, p. 448. [Google Scholar]
- Perdomo-Ortiz, A.; Benedetti, M.; Realpe-Gómez, J.; Biswas, R. Opportunities and challenges for quantum-assisted machine learning in near-term quantum computers. Q. Sci. Technol. 2018, 3, 030502. [Google Scholar] [CrossRef] [Green Version]
- Vidal, G. Class of quantum many-body states that can be efficiently simulated. Phys. Rev. Lett. 2008, 101, 110501. [Google Scholar] [CrossRef] [PubMed]
- Wilms, J.; Troyer, M.; Verstraete, F. Mutual information in classical spin models. J. Statis. Mech. Theory Exp. 2011, 2011, P10011. [Google Scholar] [CrossRef]
- Lau, H.W.; Grassberger, P. Information theoretic aspects of the two-dimensional Ising model. Phys. Rev. E 2013, 87, 022128. [Google Scholar] [CrossRef] [PubMed]
- Alcaraz, F.C.; Rajabpour, M.A. Universal behavior of the Shannon mutual information of critical quantum chains. Phys. Rev. Lett. 2013, 111, 017201. [Google Scholar] [CrossRef] [PubMed]
- Stéphan, J.M. Shannon and Rényi mutual information in quantum critical spin chains. Phys. Rev. B 2014, 90, 045424. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Gao, S.; Steeg, G.V.; Galstyan, A. Efficient estimation of mutual information for strongly dependent variables. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), San Diego, CA, USA, 9–12 May 2015; Volume 38, p. 277. [Google Scholar]
- Depenbrock, S.; McCulloch, I.P.; Schollwöck, U. Nature of the Spin-Liquid Ground State of the S = 1/2 Heisenberg Model on the Kagome Lattice. Phys. Rev. Lett. 2012, 109, 067201. [Google Scholar] [CrossRef] [PubMed]
- Neal, R.M. Annealed importance sampling. Statis. Comput. 2001, 11, 125–139. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Murray, I. On the quantitative analysis of Deep Belief Networks. In Proceedings of the 25th Annual International Conference on Machine Learning (ICML 2008), Helsinki, Finland, 5–9 July 2008; McCallum, A., Roweis, S., Eds.; Omnipress: Madison, WI, USA; pp. 872–879. [Google Scholar]
- Tubiana, J.; Monasson, R. Emergence of compositional representations in restricted boltzmann machines. Phys. Rev. Lett. 2017, 118, 138301. [Google Scholar] [CrossRef] [PubMed]
- Agliari, E.; Barra, A.; Galluzzi, A.; Guerra, F.; Moauro, F. Multitasking associative networks. Phys. Rev. Lett. 2012, 109, 268101. [Google Scholar] [CrossRef] [PubMed]
- Sollich, P.; Tantari, D.; Annibale, A.; Barra, A. Extensive parallel processing on scale-free networks. Phys. Rev. Lett. 2014, 113, 238106. [Google Scholar] [CrossRef] [PubMed]
- Agliari, E.; Barra, A.; Galluzzi, A.; Guerra, F.; Tantari, D.; Tavani, F. Retrieval capabilities of hierarchical networks: From dyson to hopfield. Phys. Rev. Lett. 2015, 114, 028103. [Google Scholar] [CrossRef] [PubMed]
- Dumoulin, V.; Goodfellow, I.J.; Courville, A.; Bengio, Y. On the challenges of physical implementations of RBMs. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; pp. 1199–1205. [Google Scholar]
- Mocanu, D.C.; Mocanu, E.; Nguyen, P.H.; Gibescu, M.; Liotta, A. A topological insight into restricted Boltzmann machines. Mach. Learn. 2016, 104, 243–270. [Google Scholar] [CrossRef]
- Farhi, E.; Harrow, A.W. Quantum supremacy through the quantum approximate optimization algorithm. arXiv, 2016; arXiv:1602.07674. [Google Scholar]
- Amin, M.H.; Andriyash, E.; Rolfe, J.; Kulchytskyy, B.; Melko, R. Quantum Boltzmann machine. arXiv, 2016; arXiv:1601.02036. [Google Scholar]
- Kieferova, M.; Wiebe, N. Tomography and generative data modeling via quantum Boltzmann training. arXiv, 2016; arXiv:1612.05204. [Google Scholar]
- Benedetti, M.; Realpe-Gómez, J.; Biswas, R.; Perdomo-Ortiz, A. Quantum-assisted learning of graphical models with arbitrary pairwise connectivity. arXiv, 2016; arXiv:1609.02542. [Google Scholar]






© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, S.; Chen, J.; Wang, L. Information Perspective to Probabilistic Modeling: Boltzmann Machines versus Born Machines. Entropy 2018, 20, 583. https://doi.org/10.3390/e20080583
Cheng S, Chen J, Wang L. Information Perspective to Probabilistic Modeling: Boltzmann Machines versus Born Machines. Entropy. 2018; 20(8):583. https://doi.org/10.3390/e20080583
Chicago/Turabian StyleCheng, Song, Jing Chen, and Lei Wang. 2018. "Information Perspective to Probabilistic Modeling: Boltzmann Machines versus Born Machines" Entropy 20, no. 8: 583. https://doi.org/10.3390/e20080583
APA StyleCheng, S., Chen, J., & Wang, L. (2018). Information Perspective to Probabilistic Modeling: Boltzmann Machines versus Born Machines. Entropy, 20(8), 583. https://doi.org/10.3390/e20080583