Slope Entropy: A New Time Series Complexity Estimator Based on Both Symbolic Patterns and Amplitude Information


Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Entropy
2.2. Permutation Entropy
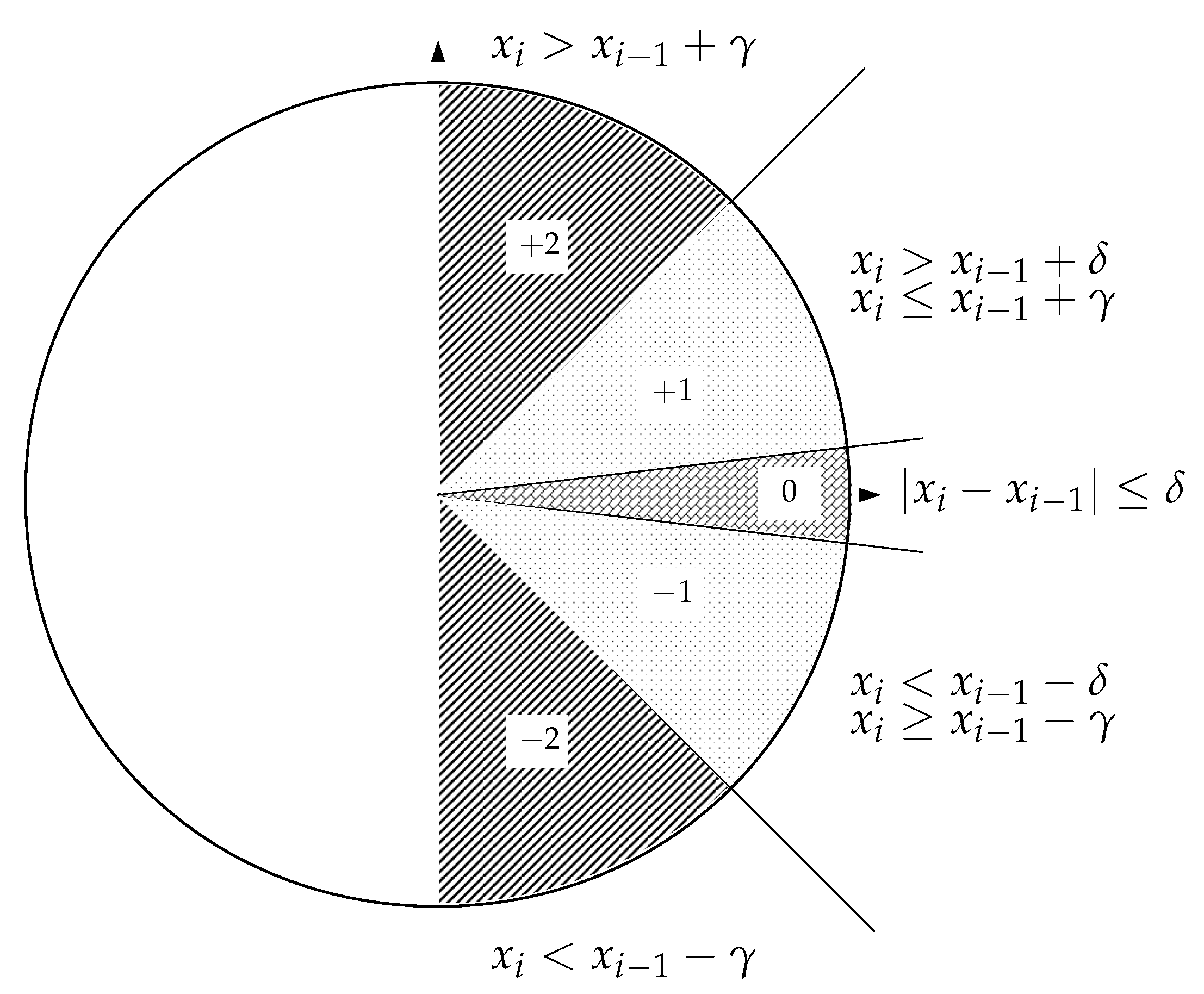
2.3. Slope Entropy
- If , the symbol is .
- If and , below the angle and above the 0 region when , the symbol is .
- In the vicinity of the 0 difference, when , the symbol assigned is 0.
- and , above the angle, and below the 0 region when , the symbol is .
- If , the symbol is .
| Algorithm 1 Slope Entropy (SlopEn) Algorithm | |
| Input: Time series , embedded dimension , length , , Initialisation: SlopEn , slope pattern counter vector , slope patterns relative frequency vector , list of slope patterns found | |
|
|
| Output: SlopEn ▹ Return result | |
2.4. Experimental Dataset
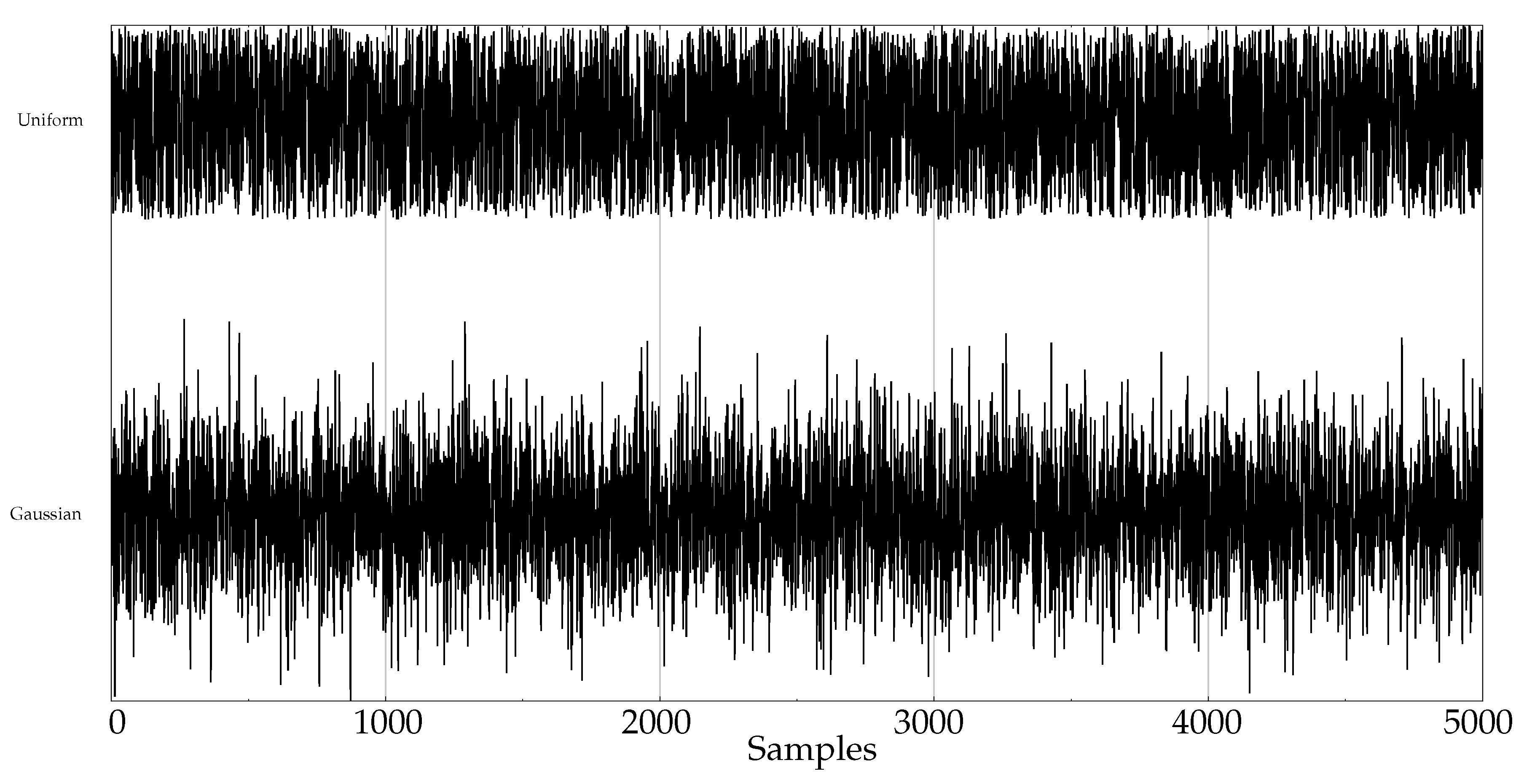
- Random records. There is a clear synthetic case where PE failed to find differences between two classes: random time series with Gaussian or uniform amplitude distributions. This is a representative example of what happens when classes under analysis have the same temporal correlations but differ in amplitude: PE discriminating power gets lost [42]. A dataset of this case was included in the experiments in order to find out if SlopEn was capable of overcoming this known weakness of PE. Two classes were generated using Gaussian or uniform amplitude distributions, with 100 records each, with a length of 5000 samples. An example of records from each class is shown in Figure 2. This dataset will be referred to in the paper as the RANDOM dataset.
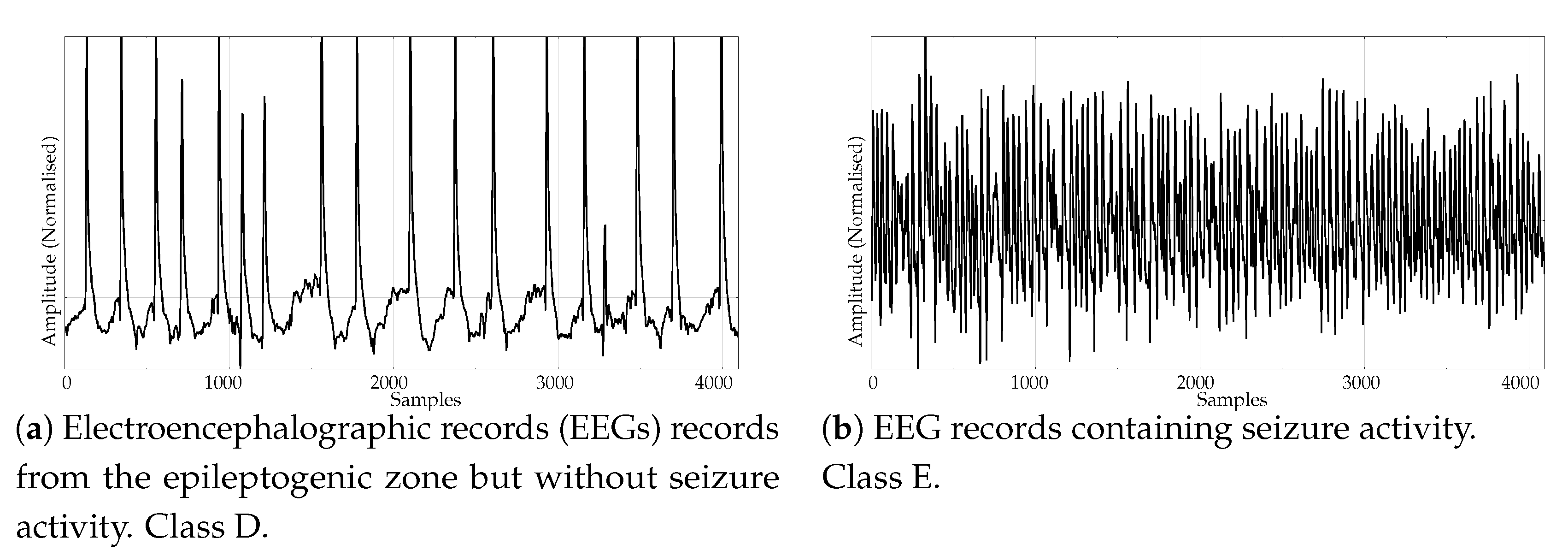
- Electroencephalographic records (EEGs) are the focus of many studies using entropy measures [43,44,45]. They have been used for a variety of purposes, such as to assess the mental status of a subject, driver’s fatigue, depth of anaesthesia, to detect a neurological disorder, or to predict the onset of epileptic seizures. There is also a great public availability of EEG records. For its good results using PE and SampEn in previous works, and due to the fact that it is probably the most widely known and analysed EEG database, we chose the University of Bonn EEG database [46]. There are five record classes in this database, but we only used the seizure–free and seizure–included records of classes D and E, respectively (100 records each one, uniform length of 4096 samples), easily separable, in principle. An example of class D record is plotted in Figure 3a, and in Figure 3b for class E.
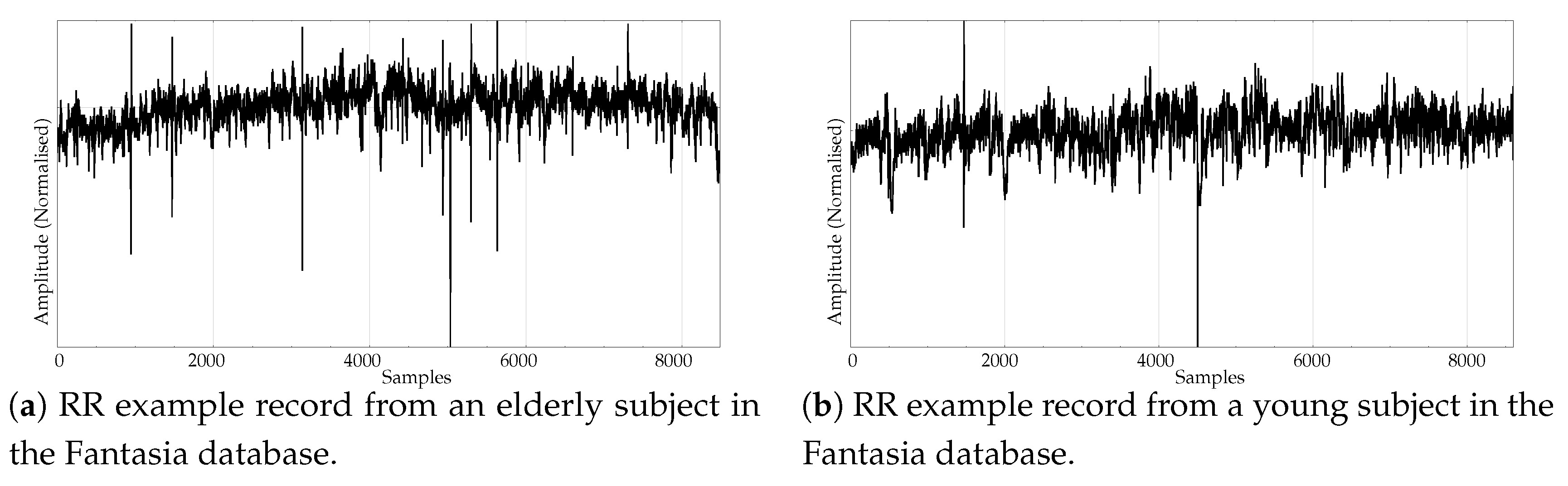
- Another type of biomedical records extensively analysed using non–linear methods are series of time durations between consecutive R–waves in the electrocardiogram (ECG), or RR intervals [47,48,49]. We chose a publicly available RR database from the PhysioBank [50], the well known Fantasia database [51]. This database contains 20 young (21–34 years old) and 20 elderly (68–85 years old) healthy subjects data whose ECG signal was recorded during 120 min while in continuous supine resting. Examples of records from the elderly and young population are shown in Figure 4a,b, respectively.
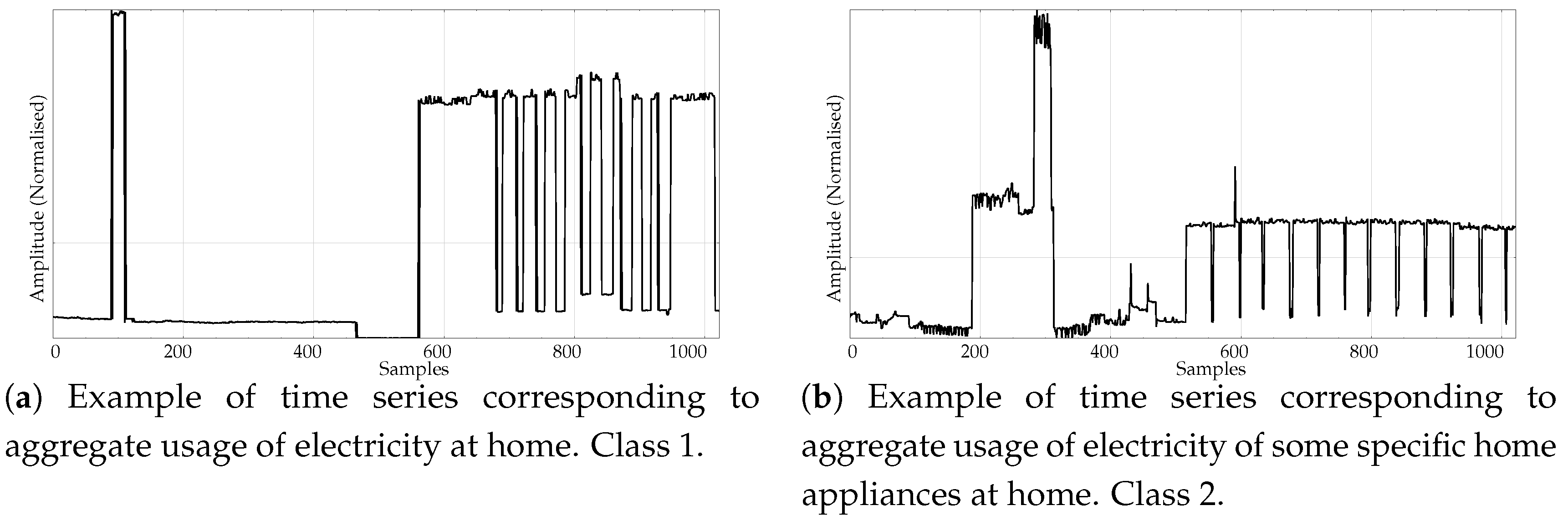
- Entropy measures are also very popular in other time series domains, beyond the very successful one of biomedical records. Along this line, we looked for other publicly available datasets featuring a complete different kind of time series, and we found the varied and diverse repository at www.timeseriesclassification.com [52]. Within this repository, we chose two classes of data from the Personalised Retrofit Decision Support Tools for UK Homes Using Smart Home Technology (REFIT) project [53]. The first class contains data related to aggregate usage of electricity (Figure 5a), and the second one to aggregate usage of electricity of some specific home appliances (Figure 5b). This dataset contains 20 records from each class, with a uniform length of 1022 samples. We used this dataset in a previous study [33] where PE was unable to find significant differences between the two classes. Therefore, this should be considered a difficult dataset for entropy measures based only on ordinal patterns. We will refer to this dataset across the paper as the ENERGY dataset.
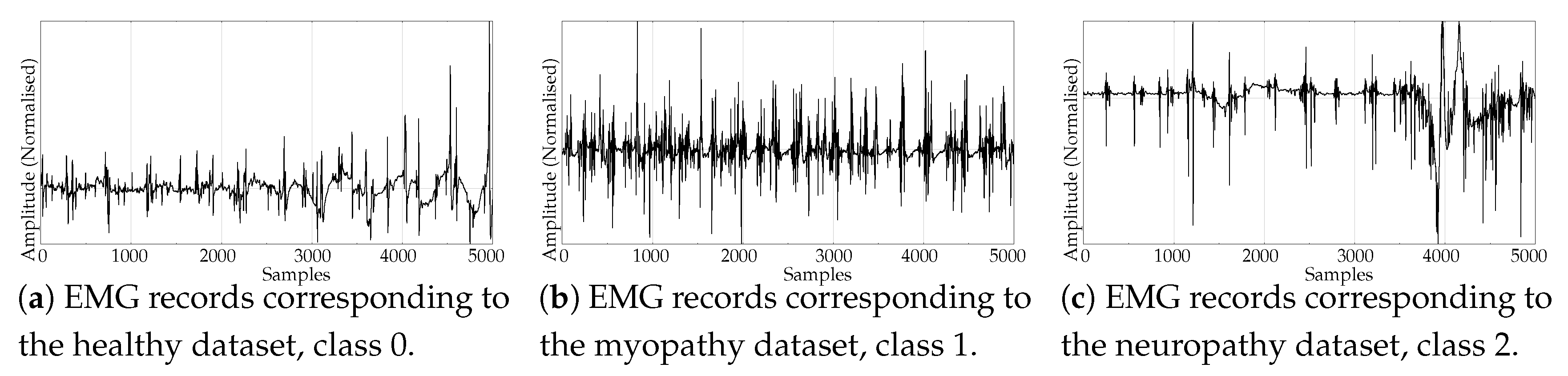
- The scientific and medical interest on Electromyograms (EMGs) and entropy measures is raising due to the recent availability of inexpensive continuous portable monitoring devices and the insight they provide into a number of important pathologies and motor disorders. They have been used to assess Parkinson’s disease [54], the neuromuscular impact of strokes [55], and muscular performance [56,57], to name just a few. The well–known site of Physionet [50] provides examples of EMGs, which we have used in previous classification studies, easily separable [22]. From three very long records of healthy, myopathy and neuropathy patients, we created three datasets by extracting non–overlapping epochs of 5000 samples. As a result, this dataset contains 10 healthy 5000 samples records (class 0), 22 myopathy 5000 samples records (class 1), and 29 neuropathy 5000 samples records (class 2). Examples of each class are shown in Figure 6a–c, respectively. This dataset will be referred to as the EMG dataset.
3. Experiments and Results
3.1. Classification Accuracy Tests
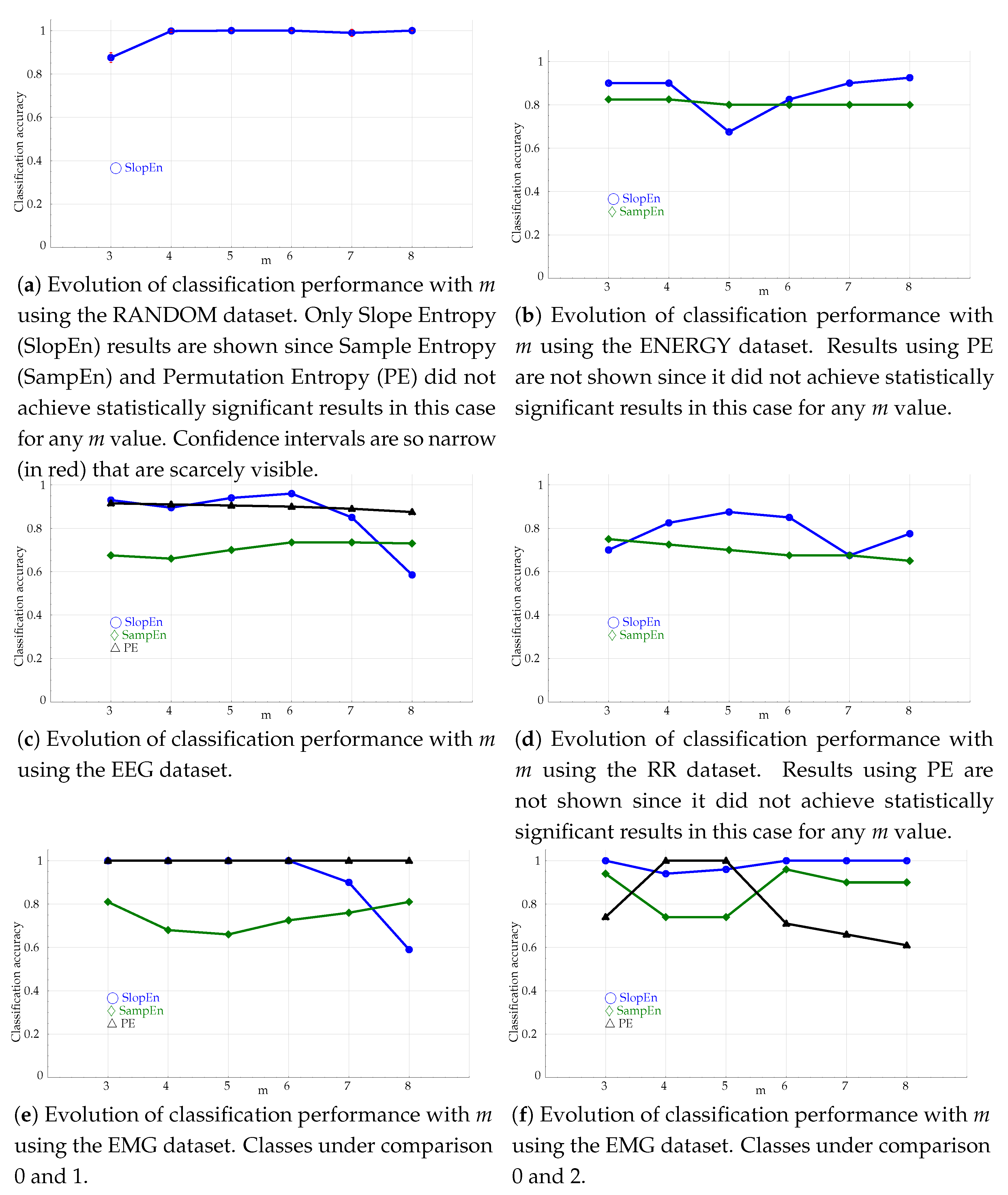
3.2. Embedded Dimension Influence Tests
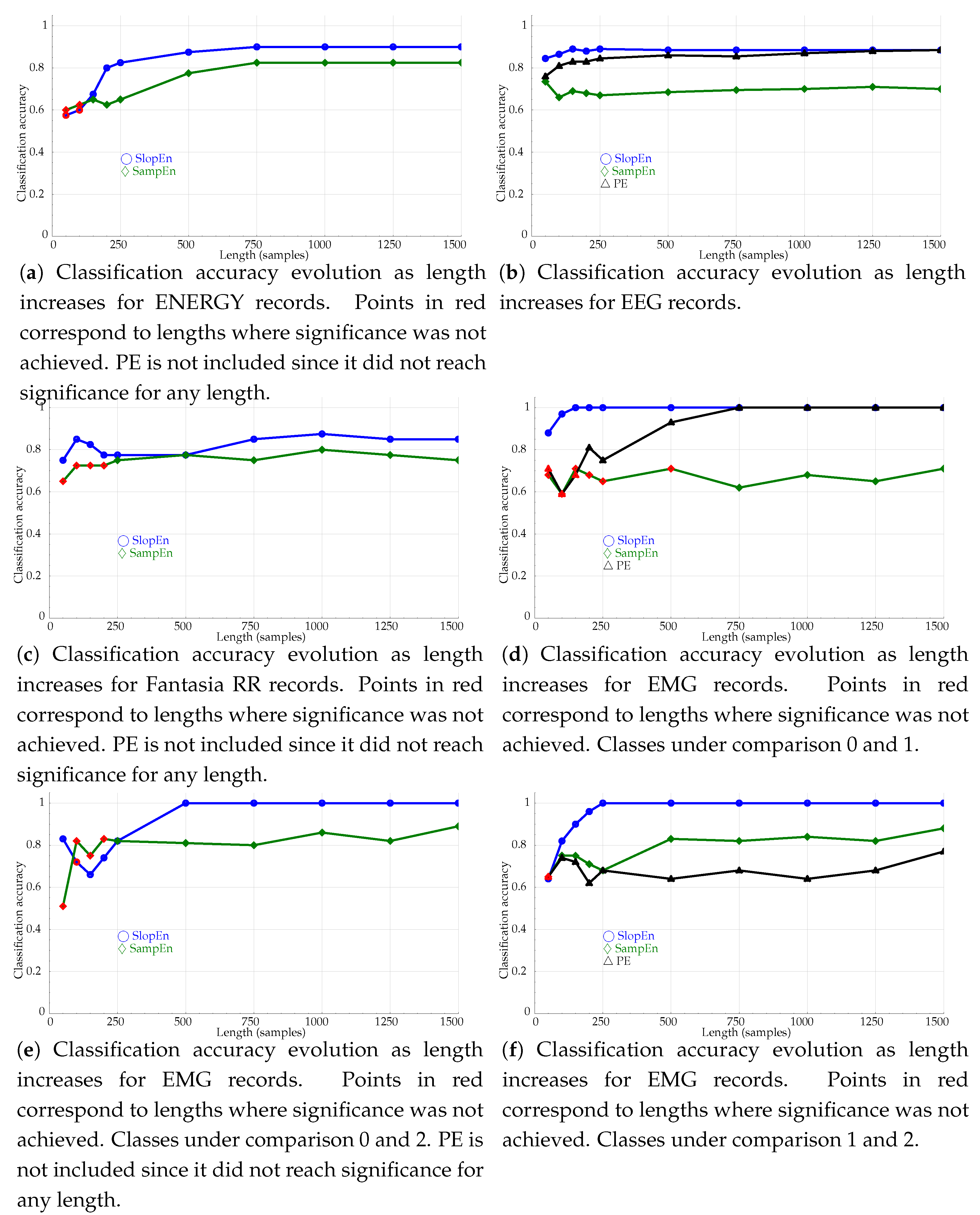
3.3. Length Influence Tests
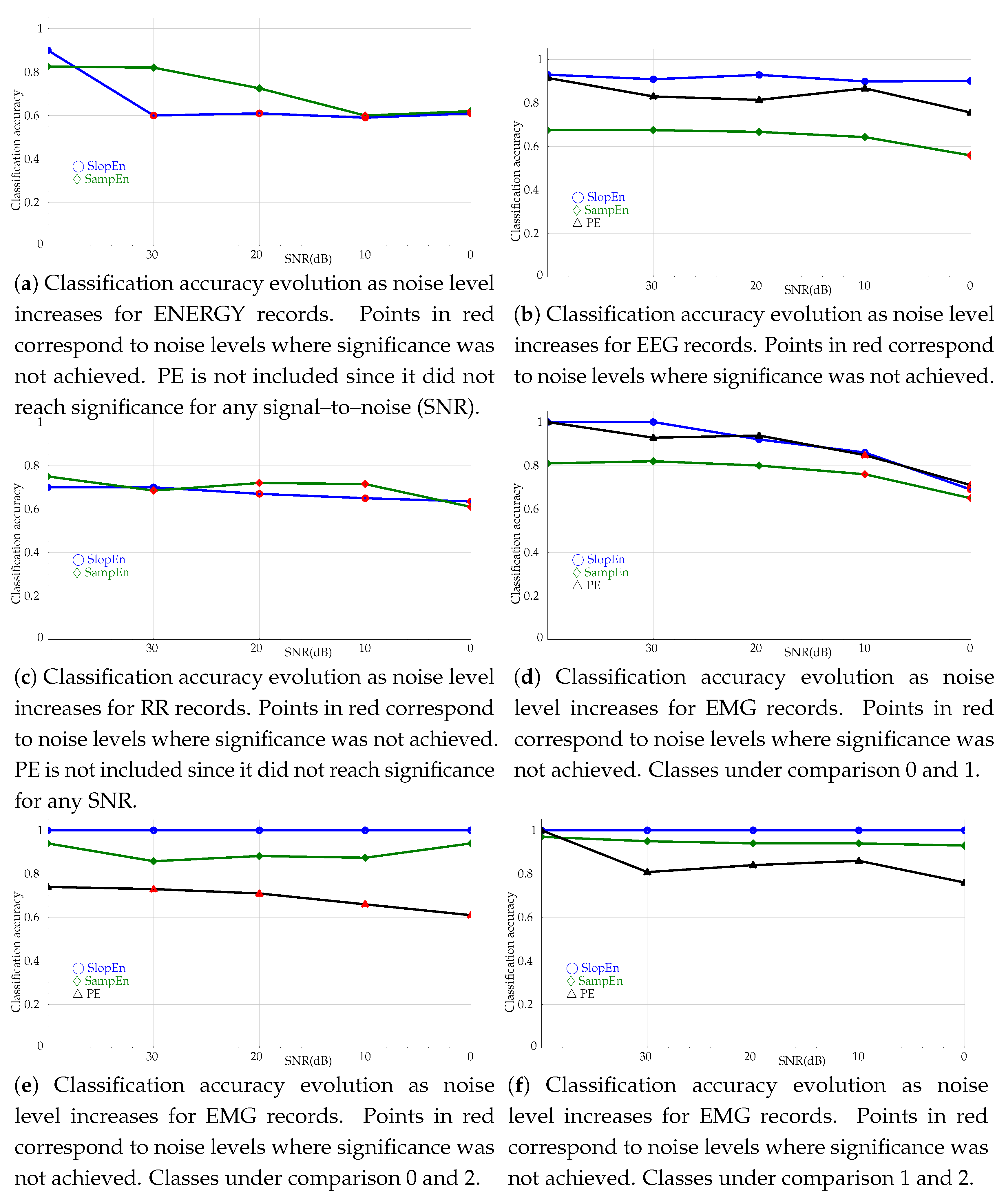
3.4. Noise Influence Tests
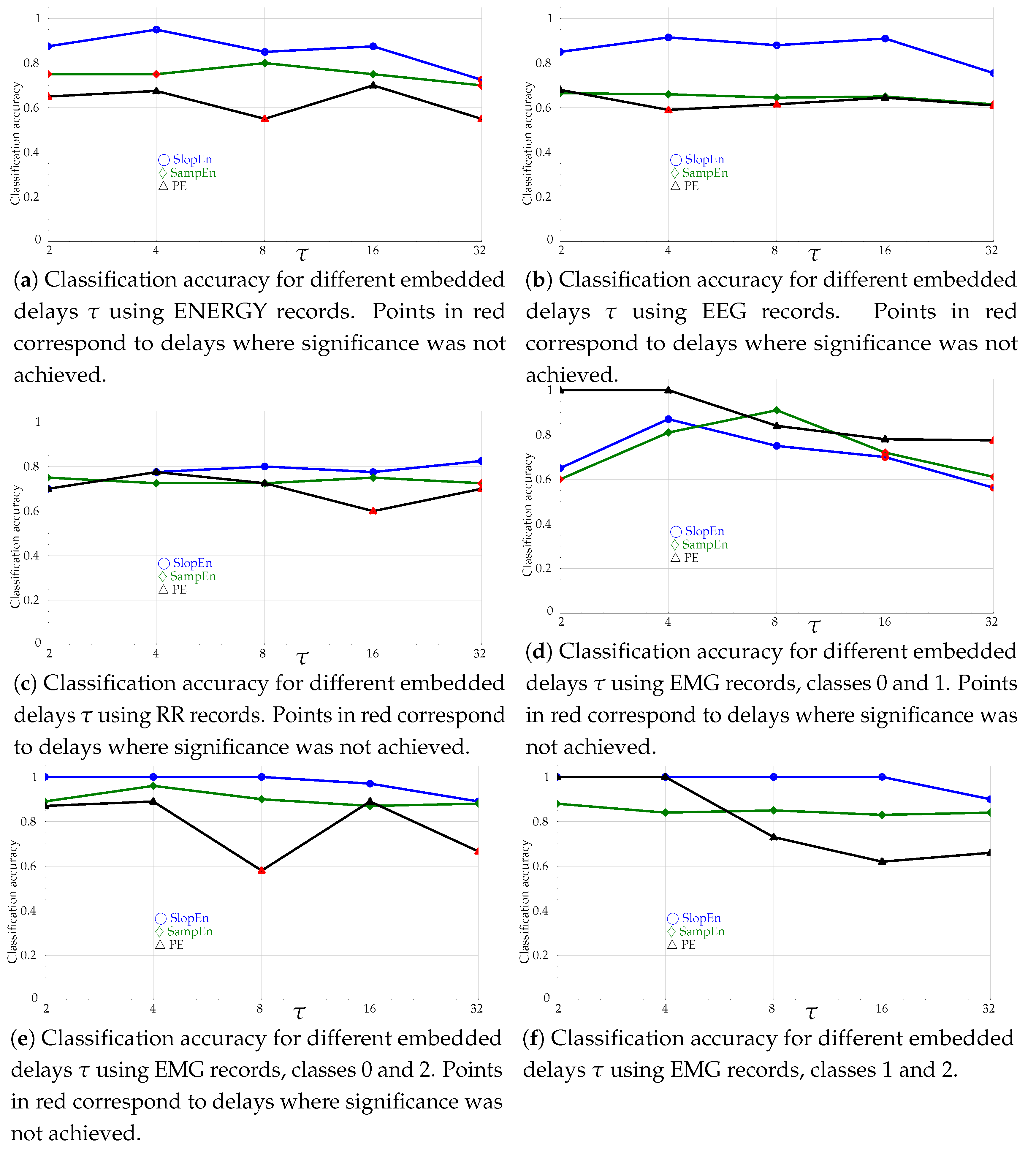
3.5. Embedded Delay Influence Tests
3.6. SlopEn Parameters Influence Tests
4. Discussion
- Accuracy is a kind of average between sensitivity and specificity, and a higher accuracy does not ensure significance because it can be the result of an unbalanced average. In this case, with a length of 100 samples, sensitivity was 0.51, and specificity 0.80, the average 0.72 was not significant because despite its high value, it came from a very low sensitivity. The same average for another test was achieved with a sensitivity of 0.80, and specificity of 0.68, but in this case, it was statistically significant. For length 150, the sensitivity was 1 and the specificity 0.57, significant for an accuracy of 0.66 but borderline.
- There are many methods for equal mean hypothesis testing, each one with its strengths and weaknesses [62]. We used the Bootstrap method, since no assumptions about the input data have to be made [63]. However, the size and distribution of the data may influence its results, mainly when significance is borderline. For example, in the previous 0.72 and 0.66 example, the test prioritised specificity over sensitivity due to the size differences of the input classes, 10 and 29, respectively.
- Rejecting the equal hypothesis is not a demonstration that it is completely false, or the other way round. Again, this is specially true in borderline cases where a minor random change can completely reverse the results.
- There are many factors than can influence the differences between time series. They are usually considered stationary, but in reality, they might exhibit some temporal changes. For example, border effects are quite common in biomedical records [14], and this impacts the results in a length influence analysis. Other well–known effects are the stochastic resonance [64,65], whereby more noise does not necessary imply less discriminating power, just the opposite. Regarding the temporal scale given by , a regular trend should not be expected in all cases because the classification performance depends on the information content of the temporal scale analysed. These scales could be completely independent in terms of this information content.
5. Conclusions
Funding
Conflicts of Interest
Appendix A. Example of SlopEn Computation
- Extract first subsequence from , . Compute the corresponding slope pattern, , since , and . Append pattern to the list of patterns found and initialise its counter to 1: .
- The next subsequence from is . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 2: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 2: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 2: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 2: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 2: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 2: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 2: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 3: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 3: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 4: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 4: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 2: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 5: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 5: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 6: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 2: .
- Subsequence . Pattern . This pattern is not in . Append it, and initialise its counter to 1: .
- Subsequence . Pattern . This pattern is already in . Update its counter to 3: .
Appendix B. SlopEn Source Code Implementation

References
- Kannathal, N.; Choo, M.L.; Acharya, U.R.; Sadasivan, P. Entropies for detection of epilepsy in {EEG}. Comput. Methods Programs Biomed. 2005, 80, 187–194. [Google Scholar] [CrossRef] [PubMed]
- Abásolo, D.; Hornero, R.; Espino, P.; Álvarez, D.; Poza, J. Entropy analysis of the EEG background activity in Alzheimer’s disease patients. Physiol. Meas. 2006, 27, 241. [Google Scholar] [CrossRef] [PubMed]
- Pincus, S.; Gladstone, I.; Ehrenkranz, R. A regularity statistic for medical data analysis. J. Clin. Monit. Comput. 1991, 7, 335–345. [Google Scholar] [CrossRef] [PubMed]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; The University of Illinois Press: Urbana, IL, USA, 1949. [Google Scholar]
- Rényi, A. Probability Theory; North-Holland Series in Applied Mathematics and Mechanics; Elsevier: Amsterdam, The Netherlands, 1970. [Google Scholar]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Sinai, Y.G. About A. N. Kolmogorov’s work on the entropy of dynamical systems. Ergod. Theory Dyn. Syst. 1988, 8, 501–502. [Google Scholar] [CrossRef]
- Richman, J.; Moorman, J.R. Physiological time-series analysis using Approximate Entropy and Sample Entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef]
- Chen, W.; Zhuang, J.; Yu, W.; Wang, Z. Measuring complexity using FuzzyEn, ApEn, and SampEn. Med. Eng. Phys. 2009, 31, 61–68. [Google Scholar] [CrossRef]
- Escudero, J.; Abásolo, D.; Simons, S. Classification of Alzheimer’s disease from quadratic sample entropy of electroencephalogram. Healthc. Technol. Lett. 2015, 2, 70–73. [Google Scholar]
- Simons, S.; Espino, P.; Abásolo, D. Fuzzy Entropy Analysis of the Electroencephalogram in Patients with Alzheimer’s Disease: Is the Method Superior to Sample Entropy? Entropy 2018, 20, 21. [Google Scholar] [CrossRef]
- Aboy, M.; Cuesta–Frau, D.; Austin, D.; Micó–Tormos, P. Characterization of Sample Entropy in the Context of Biomedical Signal Analysis. In Proceedings of the 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, France, 22–26 August 2007; pp. 5942–5945. [Google Scholar]
- Cuesta-Frau, D.; Novák, D.; Burda, V.; Molina-Picó, A.; Vargas, B.; Mraz, M.; Kavalkova, P.; Benes, M.; Haluzik, M. Characterization of Artifact Influence on the Classification of Glucose Time Series Using Sample Entropy Statistics. Entropy 2018, 20, 871. [Google Scholar] [CrossRef]
- Alcaraz, R.; Abásolo, D.; Hornero, R.; Rieta, J. Study of Sample Entropy ideal computational parameters in the estimation of atrial fibrillation organization from the ECG. In Proceedings of the 2010 Computing in Cardiology, Belfast, UK, 26–29 September 2010; pp. 1027–1030. [Google Scholar]
- Lu, S.; Chen, X.; Kanters, J.K.; Solomon, I.C.; Chon, K.H. Automatic Selection of the Threshold Value r for Approximate Entropy. IEEE Trans. Biomed. Eng. 2008, 55, 1966–1972. [Google Scholar] [PubMed]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale entropy analysis of biological signals. Phys. Rev. E 2005, 71, 021906. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.D.; Wu, C.W.; Lin, S.G.; Lee, K.Y.; Peng, C.K. Analysis of complex time series using refined composite multiscale entropy. Phys. Lett. A 2014, 378, 1369–1374. [Google Scholar] [CrossRef]
- Lempel, A.; Ziv, J. On the Complexity of Finite Sequences. IEEE Trans. Inf. Theory 1976, 22, 75–81. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef]
- Aboy, M.; Hornero, R.; Abasolo, D.; Alvarez, D. Interpretation of the Lempel-Ziv Complexity Measure in the Context of Biomedical Signal Analysis. IEEE Trans. Biomed. Eng. 2006, 53, 2282–2288. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Murillo-Escobar, J.P.; Orrego, D.A.; Delgado-Trejos, E. Embedded Dimension and Time Series Length. Practical Influence on Permutation Entropy and Its Applications. Entropy 2019, 21, 385. [Google Scholar] [CrossRef]
- Li, D.; Liang, Z.; Wang, Y.; Hagihira, S.; Sleigh, J.W.; Li, X. Parameter selection in permutation entropy for an electroencephalographic measure of isoflurane anesthetic drug effect. J. Clin. Monit. Comput. 2013, 27, 113–123. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Varela-Entrecanales, M.; Molina-Picó, A.; Vargas, B. Patterns with Equal Values in Permutation Entropy: Do They Really Matter for Biosignal Classification? Complexity 2018, 2018, 1–15. [Google Scholar] [CrossRef]
- Riedl, M.; Müller, A.; Wessel, N. Practical considerations of permutation entropy. Eur. Phys. J. Spec. Top. 2013, 222, 249–262. [Google Scholar] [CrossRef]
- Zunino, L.; Olivares, F.; Scholkmann, F.; Rosso, O.A. Permutation entropy based time series analysis: Equalities in the input signal can lead to false conclusions. Phys. Lett. A 2017, 381, 1883–1892. [Google Scholar] [CrossRef]
- Liu, T.; Yao, W.; Wu, M.; Shi, Z.; Wang, J.; Ning, X. Multiscale permutation entropy analysis of electrocardiogram. Phys. A Stat. Mech. Its Appl. 2017, 471, 492–498. [Google Scholar] [CrossRef]
- Gao, Y.; Villecco, F.; Li, M.; Song, W. Multi-Scale Permutation Entropy Based on Improved LMD and HMM for Rolling Bearing Diagnosis. Entropy 2017, 19, 176. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J. Amplitude-aware permutation entropy: Illustration in spike detection and signal segmentation. Comput. Methods Programs Biomed. 2016, 128, 40–51. [Google Scholar] [CrossRef]
- Traversaro, F.; Risk, M.; Rosso, O.; Redelico, F. An empirical evaluation of alternative methods of estimation for Permutation Entropy in time series with tied values. arXiv 2017, arXiv:1707.01517. [Google Scholar]
- Fadlallah, B.; Chen, B.; Keil, A.; Príncipe, J. Weighted-permutation entropy: A complexity measure for time series incorporating amplitude information. Phys. Rev. E 2013, 87, 022911. [Google Scholar] [CrossRef]
- Liu, X.-F.; Wang, Y. Fine-grained permutation entropy as a measure of natural complexity for time series. Chin. Phys. B 2009, 18, 2690. [Google Scholar]
- Cuesta–Frau, D. Permutation entropy: Influence of amplitude information on time series classification performance. Math. Biosci. Eng. 2019, 16, 6842. [Google Scholar] [CrossRef]
- Koski, A.; Juhola, M.; Meriste, M. Syntactic recognition of ECG signals by attributed finite automata. Pattern Recognit. 1995, 28, 1927–1940. [Google Scholar] [CrossRef]
- Koski, A. Primitive coding of structural ECG features. Pattern Recognit. Lett. 1996, 17, 1215–1222. [Google Scholar] [CrossRef]
- Lake, D.E.; Richman, J.S.; Griffin, M.P.; Moorman, J.R. Sample entropy analysis of neonatal heart rate variability. Am. J. Physiol.-Regul. Integr. Comp. Physiol. 2002, 283, R789–R797. [Google Scholar] [CrossRef] [PubMed]
- Wessel, N.; Ziehmann, C.; Kurths, J.; Meyerfeldt, U.; Schirdewan, A.; Voss, A. Short-term forecasting of life-threatening cardiac arrhythmias based on symbolic dynamics and finite-time growth rates. Phys. Rev. E Stat. Phys. Plasmas Fluids Relat. Interdiscip. Top. 2000, 61, 733–739. [Google Scholar] [CrossRef] [PubMed]
- Cysarz, D.; Lange, S.; Matthiessen, P.; Van Leeuwen, P. Regular heartbeat dynamics are associated with cardiac health. Am. J. Physiol. Regul. Integr. Comp. Physiol. 2007, 292, R368–R372. [Google Scholar] [CrossRef]
- Parlitz, U.; Berg, S.; Luther, S.; Schirdewan, A.; Kurths, J.; Wessel, N. Classifying cardiac biosignals using ordinal pattern statistics and symbolic dynamics. Comput. Biol. Med. 2012, 42, 319–327. [Google Scholar] [CrossRef]
- Zunino, L.; Zanin, M.; Tabak, B.M.; Pérez, D.G.; Rosso, O.A. Forbidden patterns, permutation entropy and stock market inefficiency. Phys. A Stat. Mech. Its Appl. 2009, 388, 2854–2864. [Google Scholar] [CrossRef]
- Amigó, J. Permutation Complexity in Dynamical Systems; Springer Series in Synergetics: Heidelberg, Germany, 2010. [Google Scholar]
- Cuesta-Frau, D.; Molina-Picó, A.; Vargas, B.; González, P. Permutation Entropy: Enhancing Discriminating Power by Using Relative Frequencies Vector of Ordinal Patterns Instead of Their Shannon Entropy. Entropy 2019, 21, 1013. [Google Scholar] [CrossRef] [Green Version]
- Deng, B.; Cai, L.; Li, S.; Wang, R.; Yu, H.; Chen, Y.; Wang, J. Multivariate multi-scale weighted permutation entropy analysis of EEG complexity for Alzheimer’s disease. Cogn. Neurodynam. 2017, 11, 217–231. [Google Scholar] [CrossRef]
- Keller, K.; Unakafov, A.M.; Unakafova, V.A. Ordinal Patterns, Entropy, and EEG. Entropy 2014, 16, 6212–6239. [Google Scholar] [CrossRef]
- Li, P.; Karmakar, C.; Yan, C.; Palaniswami, M.; Liu, C. Classification of 5-S Epileptic EEG Recordings Using Distribution Entropy and Sample Entropy. Front. Physiol. 2016, 7, 136. [Google Scholar] [CrossRef] [Green Version]
- Andrzejak, R.G.; Lehnertz, K.; Mormann, F.; Rieke, C.; David, P.; Elger, C.E. Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Phys. Rev. E 2001, 64, 061907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baumert, M.; Czippelova, B.; Ganesan, A.; Schmidt, M.; Zaunseder, S.; Javorka, M. Entropy Analysis of RR and QT Interval Variability during Orthostatic and Mental Stress in Healthy Subjects. Entropy 2014, 16, 6384–6393. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Li, K.; Zhao, L.; Liu, F.; Zheng, D.; Liu, C.; Liu, S. Analysis of Heart Rate Variability Using Fuzzy Measure Entropy. Comput. Biol. Med. 2013, 43, 100–108. [Google Scholar] [CrossRef] [PubMed]
- Mayer, C.C.; Bachler, M.; Hörtenhuber, M.; Stocker, C.; Holzinger, A.; Wassertheurer, S. Selection of entropy-measure parameters for knowledge discovery in heart rate variability data. BMC Bioinform. 2014, 15, S2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goldberger, A.L.; Amaral, L.A.N.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation 2000, 101, 215–220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iyengar, N.; Peng, C.K.; Morin, R.; Goldberger, A.L.; Lipsitz, L.A. Age-related alterations in the fractal scaling of cardiac interbeat interval dynamics. Am. J.-Physiol.-Regul. Integr. Comp. Physiol. 1996, 271, R1078–R1084. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bagnall, A.; Lines, J.; Bostrom, A.; Large, J.; Keogh, E. The great time series classification bake off: A review and experimental evaluation of recent algorithmic advances. Data Min. Knowl. Discov. 2017, 31, 606–660. [Google Scholar] [CrossRef] [Green Version]
- Lines, J.; Bagnall, A.; Caiger-Smith, P.; Anderson, S. Classification of Household Devices by Electricity Usage Profiles. In Intelligent Data Engineering and Automated Learning—IDEAL 2011; Yin, H., Wang, W., Rayward-Smith, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 403–412. [Google Scholar]
- Flood, M.; Jensen, B.; Malling, A.S.; Lowery, M. Increased EMG Intermuscular Coherence and Reduced Signal Complexity in Parkinson’s Disease. Clin. Neurophysiol. 2019, 130, 259–269. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.; Zhang, X.; Gao, X.; Xiang, C.; Zhou, P. A Novel Interpretation of Sample Entropy in Surface Electromyographic Examination of Complex Neuromuscular Alternations in Subacute and Chronic Stroke. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 1878–1888. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, X.; Tang, X.; Gao, X.; Xiang, C. Re-Evaluating Electromyogram—Force Relation in Healthy Biceps Brachii Muscles Using Complexity Measures. Entropy 2017, 19, 624. [Google Scholar] [CrossRef] [Green Version]
- Bingham, A.; Arjunan, S.P.; Jelfs, B.; Kumar, D.K. Normalised Mutual Information of High-Density Surface Electromyography during Muscle Fatigue. Entropy 2017, 19, 697. [Google Scholar] [CrossRef] [Green Version]
- Montesinos, L.; Castaldo, R.; Pecchia, L. On the use of approximate entropy and sample entropy with centre of pressure time-series. J. Neuroeng. Rehabil. 2018, 15, 116. [Google Scholar] [CrossRef] [Green Version]
- Manis, G.; Aktaruzzaman, M.; Sassi, R. Bubble Entropy: An Entropy Almost Free of Parameters. IEEE Trans. Biomed. Eng. 2017, 64, 2711–2718. [Google Scholar] [PubMed]
- Li, D.; Li, X.; Liang, Z.; Voss, L.J.; Sleigh, J.W. Multiscale permutation entropy analysis of EEG recordings during sevoflurane anesthesia. J. Neural Eng. 2010, 7, 046010. [Google Scholar] [CrossRef] [PubMed]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale Entropy Analysis of Complex Physiologic Time Series. Phys. Rev. Lett. 2002, 89, 068102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kalpić, D.; Hlupić, N.; Lovrić, M. Students t–Tests. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1559–1563. [Google Scholar]
- Zoubir, A.M.; Iskander, D.R. Bootstrap Techniques for Signal Processing; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Hari, V.N.; Anand, G.V.; Premkumar, A.B.; Madhukumar, A.S. Design and Performance Analysis of a Signal Detector Based on Suprathreshold Stochastic Resonance. Signal Process. 2012, 92, 1745–1757. [Google Scholar] [CrossRef]
- Greenwood, P.E.; Müller, U.U.; Ward, L.M.; Wefelmeyer, W. Statistical Analysis of Stochastic Resonance in a Thresholded Detector. Austrian J. Stat. 2016, 32, 49–70. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Accuracy | ||
|---|---|---|---|
| PE | SampEn | SlopEn | |
| RANDOM | |||
| ENERGY | |||
| EEG | |||
| RR | |||
| EMG(0,1) | |||
| EMG(0,2) | |||
| EMG(1,2) | |||
| 1 | 3 | 6 | 5 | 5 | 1 | 2 | |
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| RR | 0.70 | 0.70 | 0.82 | 0.85 | 0.70 | 0.70 | 0.70 |
| EEG | 0.93 | 0.94 | 0.94 | 0.95 | 0.95 | 0.93 | 0.94 |
| ENERGY | 0.90 | 0.87 | 0.57 | 0.60 | 0.62 | 0.90 | 0.92 |
| EMG | 1,1,1 | 1,1,1 | 1,0.88,0.88 | 0.51,1,1 | 0.93,1,1 | 1,1,1 | 1,1,1 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cuesta-Frau, D. Slope Entropy: A New Time Series Complexity Estimator Based on Both Symbolic Patterns and Amplitude Information. Entropy 2019, 21, 1167. https://doi.org/10.3390/e21121167
Cuesta-Frau D. Slope Entropy: A New Time Series Complexity Estimator Based on Both Symbolic Patterns and Amplitude Information. Entropy. 2019; 21(12):1167. https://doi.org/10.3390/e21121167
Chicago/Turabian StyleCuesta-Frau, David. 2019. "Slope Entropy: A New Time Series Complexity Estimator Based on Both Symbolic Patterns and Amplitude Information" Entropy 21, no. 12: 1167. https://doi.org/10.3390/e21121167
APA StyleCuesta-Frau, D. (2019). Slope Entropy: A New Time Series Complexity Estimator Based on Both Symbolic Patterns and Amplitude Information. Entropy, 21(12), 1167. https://doi.org/10.3390/e21121167