1. Introduction
Computational chemistry is the use of computers to answer outstanding questions in chemistry. Various algorithms have been developed to calculate the properties of molecules and reactions. The predictions of these methods are used in many fields. For example, they are frequently used to aid development of synthetic processes [
1] and target searches in drug discovery [
2]. Similarly, they can be used to characterize molecular configurations which are difficult to study experimentally, such as transition states of chemical reactions.
The initial step of most computational approaches to chemistry involves some form of electronic structure theory calculation: the determination of molecular electronic wavefunctions and their corresponding energies [
3,
4]. Many methods for the solution of this problem have been established.
The most conceptually simple approach within this category is the full configuration interaction (FCI) approach. Here, a finite basis set of spin-orbitals is used to describe the Hilbert space of the electronic wavefunction. Typically, this is initially a localized basis of atomic orbitals. Molecular orbitals are found using an algorithm such as the Hartree–Fock method, with the Hamiltonian in a basis of Slater determinants formed from these molecular orbitals giving the configuration interaction (CI) matrix. The eigenstates and eigenvalues of the CI matrix then give electronic eigenstates and their corresponding energies. Such a technique is numerically exact, to within the limitations of the basis set and the assumption that relativistic effects are negligible. However, the computational expense of this technique scales factorially with the number of basis functions used [
3]. This limits the application to extremely small molecules [
5], and thus is typically used as a benchmark for other methods.
Approximate methods such as coupled cluster theory [
6] or Møller–Plesset perturbation theory [
7] are often used to obtain results with practical computational resources; however, exact methods are required for benchmarking these. Additionally, for any approximation applied, a system can be found wherein such an approximation breaks down. These facts reinforce the necessity for computationally feasible numerically exact methods.
It has been established that a scalable quantum computer would be capable of providing full configuration interaction level electronic structure results in polynomial time [
8,
9,
10]. As quantum chemistry is expected to be a key application of developing quantum devices [
11], there has been a great deal of theoretical development on the algorithms that would be used to perform quantum chemical calculations on a scalable quantum computer. Algorithms to describe various chemical processes have been developed, including energy spectra [
8], reaction rates [
12,
13,
14] and reaction dynamics [
15]. Experimental demonstrations have been shown on a variety of quantum computing architectures, including photonic [
16], nuclear magnetic resonance [
17], superconducting [
18,
19] and trapped-ion [
20,
21] systems.
The variational quantum eigensolver (VQE) algorithm [
22,
23] is a hybrid quantum-classical scheme, where a classical variational approach is taken with a quantum device used to determine accurate expectation values. This approach has obtained much attention in the recent literature, although other hybrid quantum-classical schemes for the simulation of quantum systems [
24,
25] and other purposes [
26,
27,
28] have been reported. Although repeated Ansatz preparation and the need for multiple variational steps increases the overall asymptotic cost of these algorithms, they do not require coherency to be maintained throughout the entire circuit, instead requiring many short coherent evolutions. As such, while not providing full configuration interaction level accuracy, these methods can efficiently provide results that are more accurate than classical equivalents. These methods allowed for the simulation of beryllium hydride in a minimal basis in 2017, albeit with low accuracy [
19].
Although recent experimental approaches have focused on the variational quantum eigensolver, open questions remain in the study of approaches based on a phase estimation algorithm [
8,
29,
30,
31]. This requires coherency to be maintained for a time that scales exponentially with the desired precision. While this is not asymptotically prohibitive due to the required precision being fixed, it is markedly less practical for implementation on noisy devices. However, this does result in eigenvalues which are numerically exact.
Trotterization is the use of Trotter–Suzuki formulae to simulate evolution under a given Hamiltonian which comprises a sum of many terms, by sequentially simulating the evolution under each term. In both phase estimation and VQE, Trotterization of the qubit Hamiltonian is a basic tool. It can be used for the time evolution required by phase estimation and for Ansatz preparation in VQE. In doing this, a degree of error—the
Trotter error—is introduced. This error can be made arbitrarily small by increasing the Trotter number, i.e., the number of times the terms are iterated through. However, this increases the quantum computational cost of the procedure. As it is likely that quantum computational resources will be highly limited in the foreseeable future, it is useful to find methods to reduce this overhead in order to enable the simulation of larger systems. This is particularly relevant when considering phase estimation approaches, as Trotter error in these translates to the only source of algorithmic error in the simulation, whereas the impact of this error in a variational scheme is minimized through optimization of Ansatz parameters [
32].
It has been shown [
33,
34] that the error incurred in the use of a Trotter–Suzuki approximation is dependent on the order in which individual terms are simulated. However, the use of a Trotter ordering scheme is not determined by the Trotter error effects alone. Differing Trotter ordering can have an effect on the length of the circuit required to simulate one Trotter step, as identical gates between terms can be canceled [
33], with the degree of cancellation being dependent on the ordering of terms. Several ordering schemes have been reported to this end [
33,
34,
35,
36]. Nonetheless, it is possible that this effect could be outweighed by the minimization of Trotter error, and the consequent reduction in the overall number of Trotter steps—especially where the Trotter number necessary for chemically accurate predictions is low, or the ordering impact on Trotter error is high. In this paper, we thus focus on attempts to reduce the single-Trotter-step Trotter error, instead of considering other effects that impact circuit length. To this end, we report and characterize two new ordering strategies.
It is possible to derive an analytic expression for the
Trotter error operator [
35], of which the expectation value in the ground state yields the Trotter error. As finding the exact ground state is exponentially hard, finding the exact Trotter error with this approach is similarly difficult. However, the norm of the Trotter error operator can be determined without diagonalizing the full Hamiltonian. This serves as an upper bound to the true Trotter error, although this bound can be extremely loose [
36]. It has been observed [
36] that, despite the looseness of this bound, it does replicate some qualitative trends of the true Trotter error. As such, it is possible that using this information to guide an ordering scheme could result in an effective strategy. In
Section 5, we report and assess an ordering scheme in this vein. While the Trotter error operator can be computed in polynomial time, it remains computationally intensive. We therefore derive a Trotter term insertion error operator, which yields the terms that are added to the Trotter error operator upon insertion of a new term into the Hamiltonian. This allows direct and efficient comparison of the impact upon the Trotter error operator, of inserting a term into the Hamiltonian in different positions. This is of use in the greedy ordering scheme discussed in
Section 5.
We begin by providing a brief overview of the theory underpinning the canonical methods of the quantum simulation of electronic structure theory, and particularly the theory of Trotterization [
8]. We then consider three approaches to the development of Trotter ordering schemes. Firstly, in
Section 3, we discuss the hydrogen molecule in a minimal basis as a simple case study. Although this system has been extensively studied, including the consideration of all possible Trotter orderings in an experimental context [
18], an examination of the distribution of Trotter errors across varying Trotter orderings is yet unreported in the literature. We consider this here, along with a discussion of the geometry dependence of the optimal Trotter ordering. Secondly, in
Section 4, we propose two ordering schemes based on subdividing the molecular Hamiltonian into mutually commuting subsets of terms, and report their performance across a dataset of 44 systems. Finally, in
Section 5, we propose and assess a final ordering scheme based on minimizing the norm of the Trotter error operator.
2. Trotterization—Theoretical Background
The electronic Hamiltonian in the second quantized formalism is given by:
where
and
are Coulombic overlap and exchange integrals determined by the basis set chosen [
3,
4]. The overall goal of the simulation process is to determine the eigenstates and corresponding eigenvalues of this Hamiltonian. Letting the number of spin-orbitals included in the basis set be
N, there are
terms in the Hamiltonian in Equation (
1). In practice, molecular symmetries and orbital localization result in many of these terms having a zero or negligible coefficient. Regardless, the determination of the
and
integrals is classically efficient, and thus these weighting constants can be considered as input data when performing the calculation on either a classical or quantum device.
Classically, the matrix elements of the electronic Hamiltonian in a basis of Slater determinants may be obtained. The eigenvalues of the full configuration interaction matrix can then be determined, for instance by direct diagonalization. However, the dimension of the Fock space which acts upon grows exponentially with N. This can be reduced by excluding the subspace with the incorrect number of electrons; however, this still results in a growth of , where n is the number of electrons. As such, it is intractable to perform this process for more than a handful of tens of spin-orbitals. Conversely, N qubits span the entire Fock space that acts upon—a quantum computer thus circumvents the exponential cost of the simulation procedure.
Performing a similar procedure on a quantum device differs from a classical full configuration interaction calculation. Having calculated the
and
integrals, a mapping scheme to transform the creation and annihilation operators of Equation (
1), along with the electronic states they act upon, to operations upon and states of qubits must be found. This is typically performed through the Jordan–Wigner transformation, the Bravyi–Kitaev transformation, or other constructions [
34,
37,
38,
39,
40,
41]. In this paper, we primarily utilize the Jordan–Wigner transformation, although we present some results using the Bravyi–Kitaev mapping in
Section 4. The result of performing this mapping procedure is the generation of a qubit Hamiltonian, which consists of a sum of weighted strings of qubit Pauli operators.
From here, two approaches to finding molecular eigenstates and eigenvalues are common. In quantum phase estimation [
29,
42], a circuit corresponding to the the evolution operator
of the qubit Hamiltonian is repeatedly applied, with a second register of qubits used to store a binary expansion of the true eigenvalue. In a variational quantum eigensolver, a parameterized Ansatz state which is classically hard to store is generated. The expectation value of the qubit Hamiltonian with this state is measured, and a classical optimizer used to vary the Ansatz parameters until the expectation value is variationally minimized [
22,
23]. Typically, the unitary coupled cluster Ansatz [
32]—or a form derived from it [
43]—is used. Here, an exponentiated form of the unitary cluster operator is applied to a reference state.
In both cases, a circuit that implements an exponentiated sum of Pauli operators must be found. In general, such a circuit is difficult to find. However, standard circuits exist to simulate individual Pauli strings—. As such, we invoke a Trotter–Suzuki approximation to break the overall evolution operator into a product of individual terms.
A first-order Trotter–Suzuki approximation is given by [
44]:
where the Hamiltonian
is a sum of
m terms
. Intuitively, this states that the Hamiltonian can be approximated by rapidly switching between each term, across the desired evolution time. The exponential of a single Hamiltonian term can be described easily. Increasing
, the
Trotter number—the number of Trotter steps—deterministically reduces the error incurred by this approximation, but with commensurate increase in circuit length.
A second-order Trotter–Suzuki approximant
can be obtained by symmetrizing the first-order approximant. Higher-order approximants can be obtained recursively [
45]. Increasing the approximation order will yield reductions in error. However, the overall length of the quantum circuit required to simulate higher-order Trotter approximants increases exponentially with the order used. Choosing an appropriate strategy for simulation is then a three-way trade-off among the order of Trotter–Suzuki approximant, the number of time steps, and the need to minimize the overall circuit length. For consistency with other work, we mostly restrict ourselves here to use of a second-order Trotter approximant (Equation (
3)), although we additionally use a first-order Trotter approximant in
Section 3.
To bound the error incurred in the use of this approximation, Poulin et al. [
35] introduced the Trotter
error operator, which gives the Trotter error for a given Trotterized Hamiltonian. For a second-order Trotter–Suzuki approximant, the expectation value of this with an eigenstate is given by [
36]:
where
is the expected error (ignoring higher-order terms),
is the Trotter step size,
is the ground state,
is the Kronecker delta function and
are Hamiltonian terms [
36].
Examining this, it is evident that two factors primarily affect the degree of error introduced by the use of the Trotter–Suzuki approximation. Firstly, the error will decrease with the number of time steps used. Additionally, as the sums in Equation (
4) are ordered—being sums over conditional indices, rather than the whole range—the order in which terms are applied will impact the error incurred. Indeed, previous work has suggested that the Trotter ordering can dramatically impact the number of Trotter steps required for constant precision [
33,
39]. It is thus desirable to find an ordering strategy which minimizes this error, motivating this paper.
In this section, we have discussed the underlying theory of Trotterization and the impact of Trotter ordering schemes. For most molecular systems, the space of possible orderings is sufficiently vast as to inhibit direct statistical analysis. We proceed to consider a small test case—molecular hydrogen in a minimal basis—both to justify the generalized ordering schemes presented in
Section 4 and to study the role of molecular geometry in a small example.
3. Molecular Hydrogen
Molecular hydrogen in an STO-3G basis is the smallest and simplest chemically interesting electronic structure problem—barring its cationic form, which lacks two-electron interactions. Due to its simplicity, this example has been widely used both experimentally and theoretically [
8,
16,
17,
18,
20,
39,
41]. It was recently shown that this example is in a sense not quantum mechanical, as it lacks measurement contextuality [
46]; however, the simplicity of the system makes it a good candidate for initial studies.
The qubit Hamiltonian for the hydrogen molecule in an STO-3G basis, using a Jordan–Wigner transformation, with a bond length of
Å, is given by:
where the lower index of each Pauli operator corresponds to the index of the qubit it is applied to. This consists of 15 terms. Unfortunately, even a Hamiltonian of this small size provides on the order of
possible orderings. It is thus infeasible to consider all orderings for the full Hamiltonian, even for the hydrogen molecule in a minimal basis. The second-order Trotter error operator (Equation (
4)) consists of a sum of many triple commutators between Hamiltonian terms. As such, it is prudent to consider the commutativity of the terms in the Hamiltonian. Inspecting Equation (
5) shows that the terms with only two Pauli Z operators commute with all terms in the Hamiltonian. Along with the identity term, these form a
totally commuting set. Because they commute with all terms, their exponentials commute with the exponentials of all other terms, and consequentially they can be freely moved around a Trotterized evolution operator. As such, all terms in this set can be moved to the front of the operator, combined, and simulated as an entirely independent operator
where
is the sum of all totally commuting terms, and
is a Trotterization of the other terms. In other words, we only need to Trotterize the terms that do not commute with all terms.
This analysis has two principal advantages. Firstly, as the totally commuting set does not require a Trotter–Suzuki approximation, these terms can be simulated in one time step. This dramatically cuts down on the number of gates required for implementation on a quantum device. It should be noted here that for larger systems the size of the totally commuting set rapidly drops to one term (the identity operator). As such, this advantage is not scalable, and therefore this technique cannot be used directly in the analysis of larger systems.
More importantly for the purposes of this discussion, as we do not need to Trotterize the terms in the totally commuting set, the space of possible orderings is dramatically reduced to . As the simulation of each ordering takes less than 1 s on an average laptop computer, it is thus feasible to simply brute force search the entire space of orderings in order to study the distribution of errors.
In our simulations, integral data were generated using the Psi4 [
47] quantum chemistry package and OpenFermion [
48], with a standard Hartree–Fock basis used to express the molecular Hamiltonian. Our Python code was used to generate both Jordan–Wigner and Bravyi–Kitaev Hamiltonians. The exact ground state and its corresponding energy were then determined. Similarly, the Trotter error for every possible ordering was determined, with the overall evolution time and the number of Trotter steps set to unity.
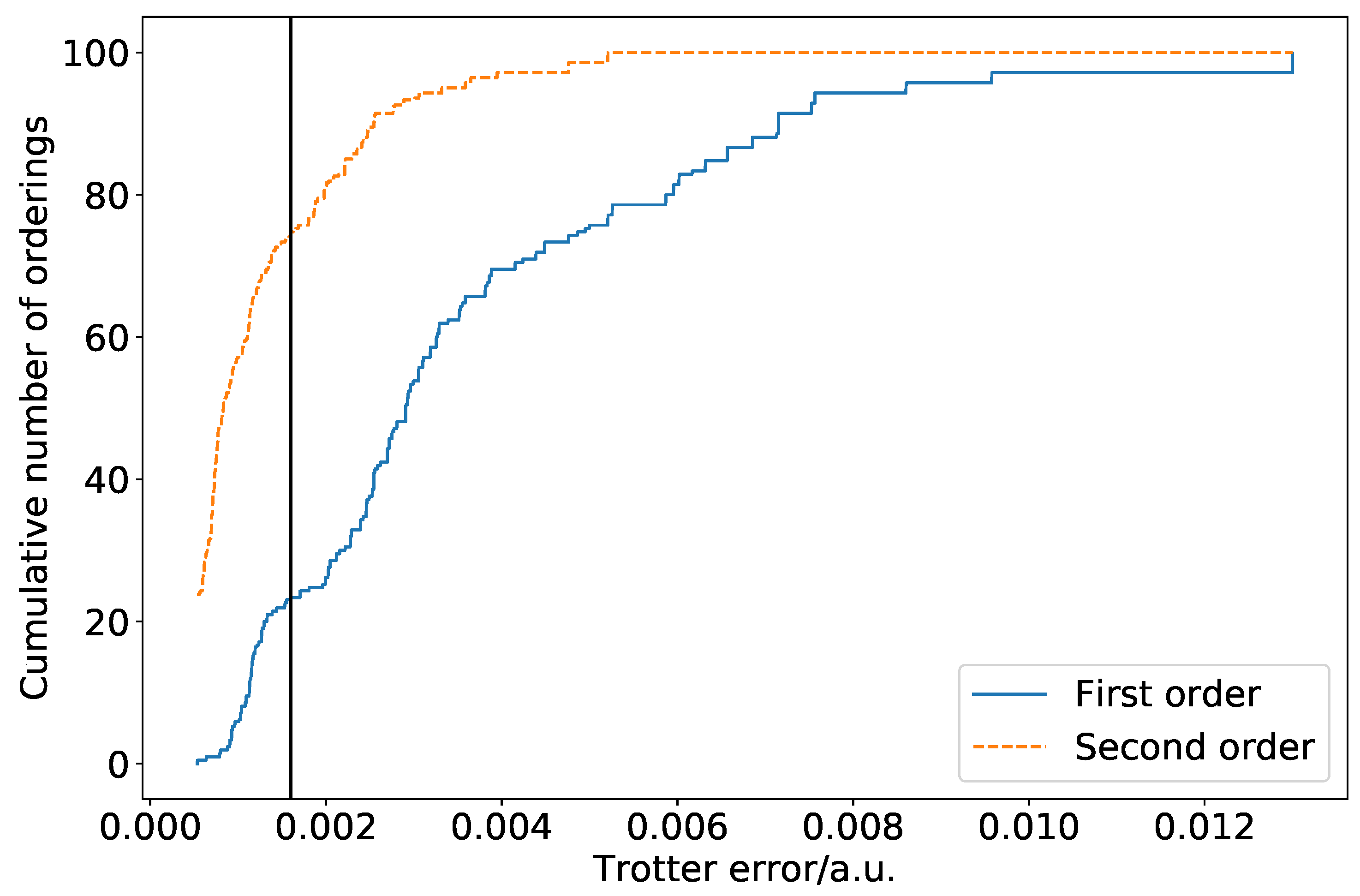
Figure 1 is a cumulative density plot showing the distribution of Trotterization errors which are obtained as a result of ordering variations. Errors are given relative to the true eigenvalue of the Hamiltonian with totally commuting terms removed. The same distribution is obtained regardless of whether the Jordan–Wigner or Bravyi–Kitaev Hamiltonian is simulated. The distribution is heavily weighted towards the low error region. This is promising, as it implies that a random choice of ordering is likely to introduce a small amount of ordering-dependent error. There is, however, over an order of magnitude difference between the optimal and poorest orderings. In this case, the difference is such that only three Trotter steps are required to reach an accuracy of
a.u. for the optimal ordering, whereas seven Trotter steps are required for the worst ordering. This implies that—if we extrapolate solely from the hydrogen molecule in a minimal basis—picking a bad ordering could result in a dramatically increased gate count in actual quantum simulations. This is important despite the high likelihood of random orderings being accurate, as if a systematic approach to ordering is taken, it must be ensured that this does not result in bad orderings being selected. It should be noted here, however, that the results of
Section 4 show that this difference is lessened in systems involving heavier atoms.
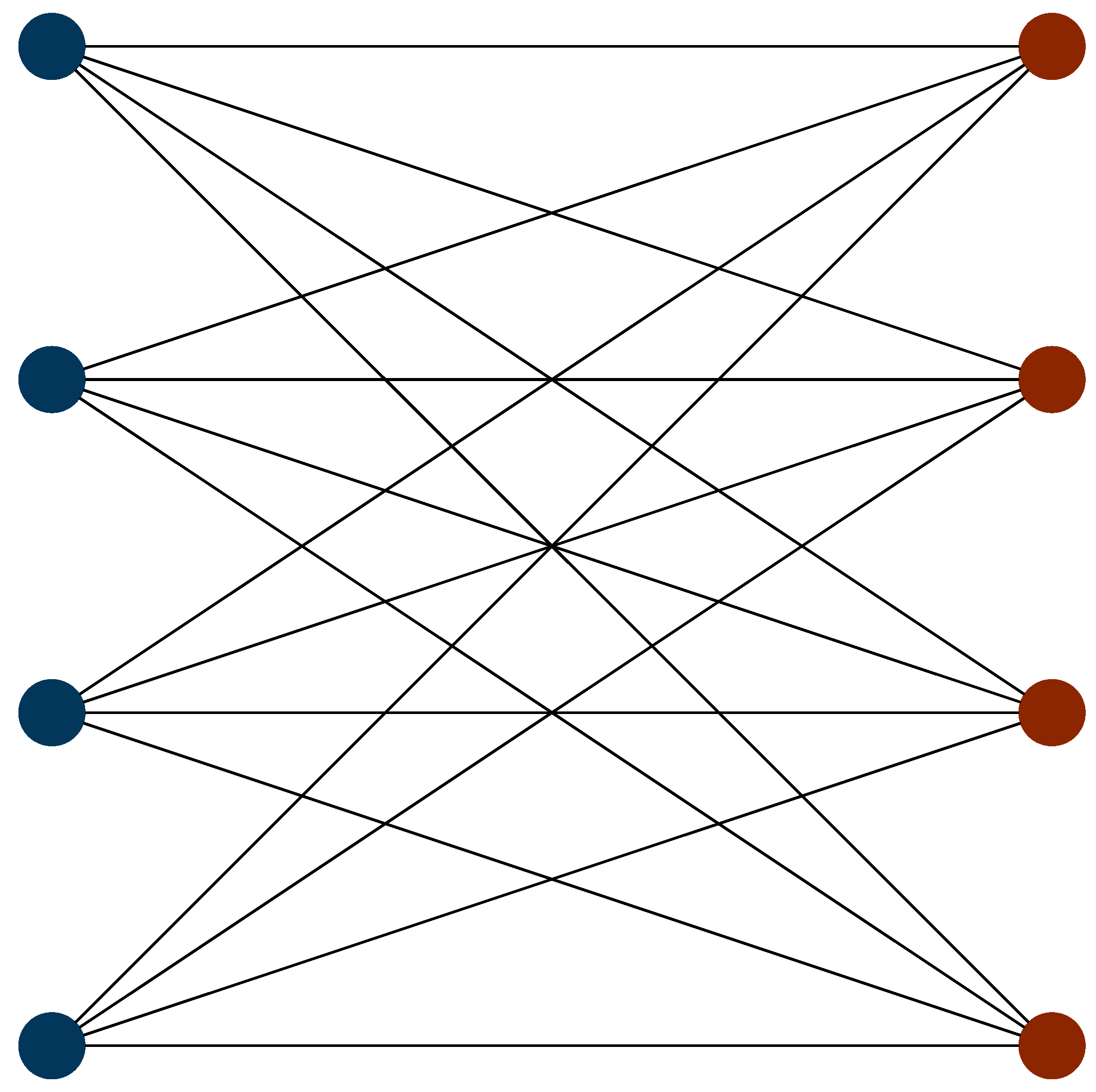
We now consider the optimal ordering strategy for the hydrogen molecule, by re-examining the commutativity structure graph (the incompatibility graph) discussed above.
Figure 2 shows this with totally commuting terms removed. Here, it is apparent that the incompatibility graph is bipartite. As such, the Hamiltonian can be subdivided into two sets of terms. Within each set, all terms mutually commute. No term in a given set commutes with any term in the other set. One set consists of all of the terms with Pauli Z operators, whereas the other set consists of terms with Pauli X and Y operators. We label the former of these sets the Z-set and the latter the XY-set. Using the Jordan–Wigner transformation, the optimal ordering using a first-order Trotter expansion is given by
where the leftmost term is simulated first, the second term is simulated second, and so on. Here, the first, third, fifth and seventh terms are members of the XY-set, while the remaining terms are members of the Z-set. Examining this, it is evident that the optimal ordering strategy is given by alternating between completely commuting sets in order of descending coefficient magnitude. This strategy is optimal for both Jordan–Wigner and Bravyi–Kitaev Hamiltonians. However, other systematic approaches to ordering strategies for this Hamiltonian produce differing results for the two mapping techniques. This emphasizes the need for a systematic ordering scheme which is mapping agnostic.
Geometry Dependence
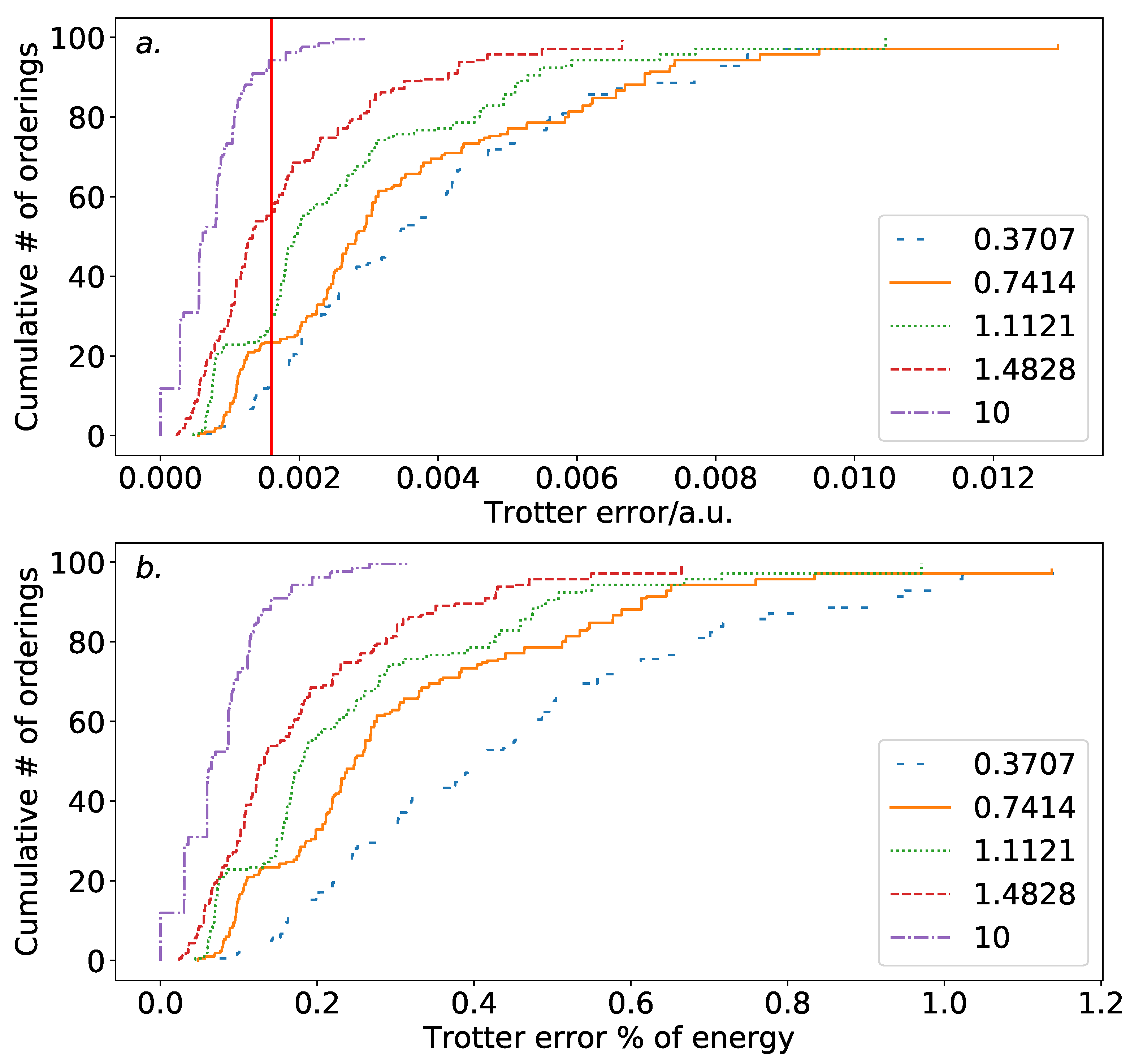
Molecular hydrogen allows for the specification of the entire molecular geometry with a single parameter; the bond length of the molecule. This allows for the consideration of how the Trotter error varies with the molecular geometry.
Figure 3 demonstrates this. To contrast the results above and for consistency with prior work, we here use a second-order Trotter expansion. Increasing the bond length results in a substantially reduced Trotter error. This is likely due to the increased locality of the electronic eigenstates, resulting in increased degeneracy, and thus in increased symmetry in the coefficients of the Z-set terms. At asymptotic separation, the Z-set terms have equal coefficient. This additional symmetry reduces the dependence of the Trotter error on ordering choice. It also allows for increased cancellation in the terms of the Trotter error operator, resulting in a reduction in Trotter error overall at higher bond lengths.
Table 1 shows how the Pauli Hamiltonian and optimal Trotter ordering varies with bond length. We first observe that the optimal ordering has changed at equilibrium bond length, due to the use of the second-order Trotter–Suzuki formula. The strategy of alternating between commuting sets remains. However, within each set, the terms are ordered in descending magnitude order, likely due to the symmetrization of the second-order approximant.
For small bond length, we observe substantially increased difference in the coefficients of the Z-set terms, due to the increased relative stability of the bonding orbitals. The strategy of alternating between Z-set and XY-set terms is optimal at all pre-asymptotic separations. However, the particular choice of Z-set terms differs at higher bond lengths, due to the increasing similarity of the coefficients of the Z-set terms. At asymptotic separation, a different ordering is preferable. Here, as the Z-set terms are equal, the Trotter error can be reduced to zero by placing all XY-set terms at the start of the expansion.
In this section, we discussed the small case study of molecular hydrogen, observing that the optimal ordering is described by alternating between fully commuting sets of terms. We proceed to present two generalized ordering schemes derived from this heuristic, and analyze their performance across a variety of molecular systems.
4. Generalized Ordering Strategies
While analysis of the hydrogen molecule yielded interesting results regarding the spread of ordering strategies, it would be desirable to find an ordering strategy that is effective in the general case. For this, we require an analysis of a variety of systems, and ideally those of a chemically interesting size. While the hydrogen study does not provide this, the optimal ordering at equilibrium bond length does provide us with a potential starting point for our investigation.
4.1. Methods
To contrast our ordering schemes against other possible alternatives, it is necessary to briefly review the conventions we use to describe other ordering schemes, previously discussed in Reference [
34].
Perhaps the most immediately obvious ordering scheme is the magnitude ordering. Here, terms are ordered according to the magnitude of their coefficient, from largest to smallest—the term with the largest magnitude coefficient is simulated first, followed by the second largest magnitude coefficient, and so on. This ordering scheme has the immediate appeal that high magnitude terms are simulated first. As a result, one could expect a reduction in the number of high magnitude terms in the error operator. Loosely, this is due to implementing high magnitude terms first, as opposed to later in the sequence where they may compound earlier errors. However, this approach does not take into consideration the structure of the error operator—high magnitude terms may not result in a meaningful increase in error if, for example, they commute with many other terms.
The
lexicographic ordering is an ordering scheme which attempts to maximize the similarity of the Pauli strings of adjacent terms. This is essentially a numerical ordering with respect to the Pauli strings. While this scheme may seem arbitrary, it is known to result in a maximum amount of gate cancellation, with commensurate reduction in overall quantum computational cost [
33]. However, there is little reason to suspect that this ordering would be beneficial for the purposes of Trotter error. Such an increase could lead to the requirement for a greater number of Trotter steps, undermining its advantages. It should be noted that our strategy for ordering terms lexicographically is a small modification from that used in other work [
33]. Whereas other approaches have grouped the qubit Hamiltonian terms by their fermionic operator, our approach does not maintain this structure, and instead stores the qubit Hamiltonian as a list of individual weighted Pauli string terms. As such, we do not treat any terms based on their fermionic role. Similarly, our ordering is based purely on the structure of the individual Pauli strings, rather than the fermionic terms they correspond to.
Testing on random Hamiltonians [
49] proved relatively optimistic for the prospects of some of the ordering schemes described in later sections of this paper. However, it has been established that testing on random Hamiltonians does not realistically capture the behavior of real molecular Hamiltonians when considering Trotter errors. A more rigorous analysis requires the use of real chemical Hamiltonians. We therefore used a set of 44 molecular Hamiltonians, largely using the same dataset as in Reference [
34].
Table 2 shows a breakdown of these systems. Equilibrium molecular geometries were gathered from the NIST CCCBDB database optimized at the Hartree–Fock level [
50]. Molecular orbital integrals in the Hartree–Fock basis were obtained from Psi4 [
47] and OpenFermion [
48]. As in Reference [
34], the procedure for determining the exact Trotter error was to directly calculate the expectation value of the Trotterized Hamiltonian with the exact ground state, using our Python code. The Trotter evolution time for each Hamiltonian was set
using the full configuration interaction energy for computational convenience. In a real simulation, the energy provided by a lower level of theory would be used.
4.2. Results—Magnitude Ordering
To provide some context for our discussion of Trotter ordering strategies, we first consider the Trotter error incurred for our systems using a magnitude ordering.
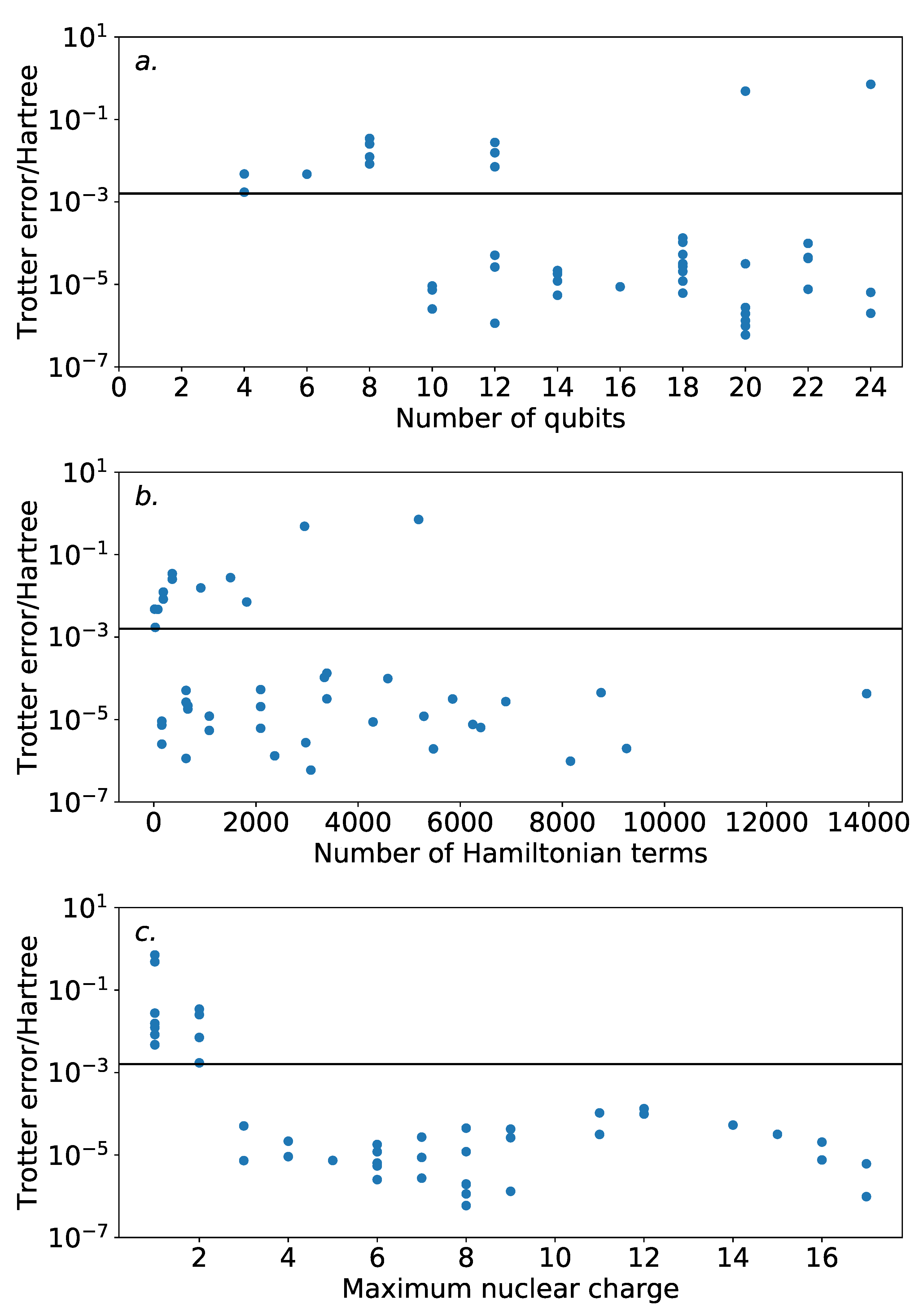
Figure 4 demonstrates this against a variety of properties. The majority of the systems demonstrated Trotter error below the threshold for chemical accuracy. While there is little indication of increasing Trotter error with the number of spin-orbitals, it should be noted that the systems studied are all within the regime that can be practically simulated on modern classical computers. It is unclear as to whether this trend will persist beyond this regime. Nonetheless, this is encouraging for experimental studies in the near future, where the number of available qubits will be highly constrained.
There is no obvious correlation between the Trotter error and either the number of spin-orbitals or the number of terms in the Hamiltonian. However, when plotted against the maximum nuclear charge (i.e., the nuclear charge of the heaviest atom in the system)—as suggested by the previous work of Babbush et al. [
36]—there is a notable, albeit loose, trend. All of the systems with single step magnitude ordering Trotter error insufficient for chemical accuracy involve only H and He nuclei. This could be affected by the special handling of the Trotter time for low energy systems in Equation (
7). The results here reinforce the need for benchmarks of quantum approaches to electronic structure theory problems to consider systems with heavy atoms.
Beyond these systems, there is a peak in Trotter error around a maximum nuclear charge of 11. This is in agreement with the results of Babbush et al. [
36], where it is observed that systems with mostly full spin-orbitals will incur low Trotter error. The peak in our data is due to the presence of Na or Mg, which in an STO-3G basis have many unfilled spin-orbitals.
4.3. Statistics of Commuting Hamiltonian Subsets
One approach to using commutativity structure to inform ordering strategy is to consider coloring of the incompatibility graph of the qubit Hamiltonian. As in
Figure 2, we can consider this structure by representing the commutativity of the terms in the Hamiltonian as a graph, with terms in the Hamiltonian corresponding to nodes and an edge representing the case where terms do not commute. Generating such a graph requires
time, as calculating the commutator of two arbitrary terms is classically efficient.
Following our example of the Hydrogen molecule, a strategy of dividing the Hamiltonian into sets of mutually commuting subsets—sets of terms where all members commute—can be followed. This is equivalent to finding a coloring of the incompatibility graph. Unfortunately, it is well known that finding a coloring with a minimal number of colors is NP-hard [
51]. However, heuristics—often using a greedy approach—have been developed [
52]. There is no immediately obvious reason to suspect that coloring the Hamiltonian using a heuristic is problematic for the purposes of our analysis. Indeed, these heuristics have seen frequent recent use for partitioning electronic structure Hamiltonians, for the purpose of measurement reduction in variational quantum algorithms [
53,
54,
55,
56]. Nonetheless, it does suggest that caution should be used when considering the generalizability of the results presented.
Graphs representing the Hamiltonians in our dataset were generated using the NetworkX Python package [
57]. Due to the relative computational ease of this procedure, our dataset here was extended by 16 additional systems, as indicated by
Appendix B. From here, colorings were generated using the greedy coloring method provided by the same package, using an independent set strategy [
52]. Coloring schemes for both Jordan–Wigner and Bravyi–Kitaev Hamiltonians were generated.
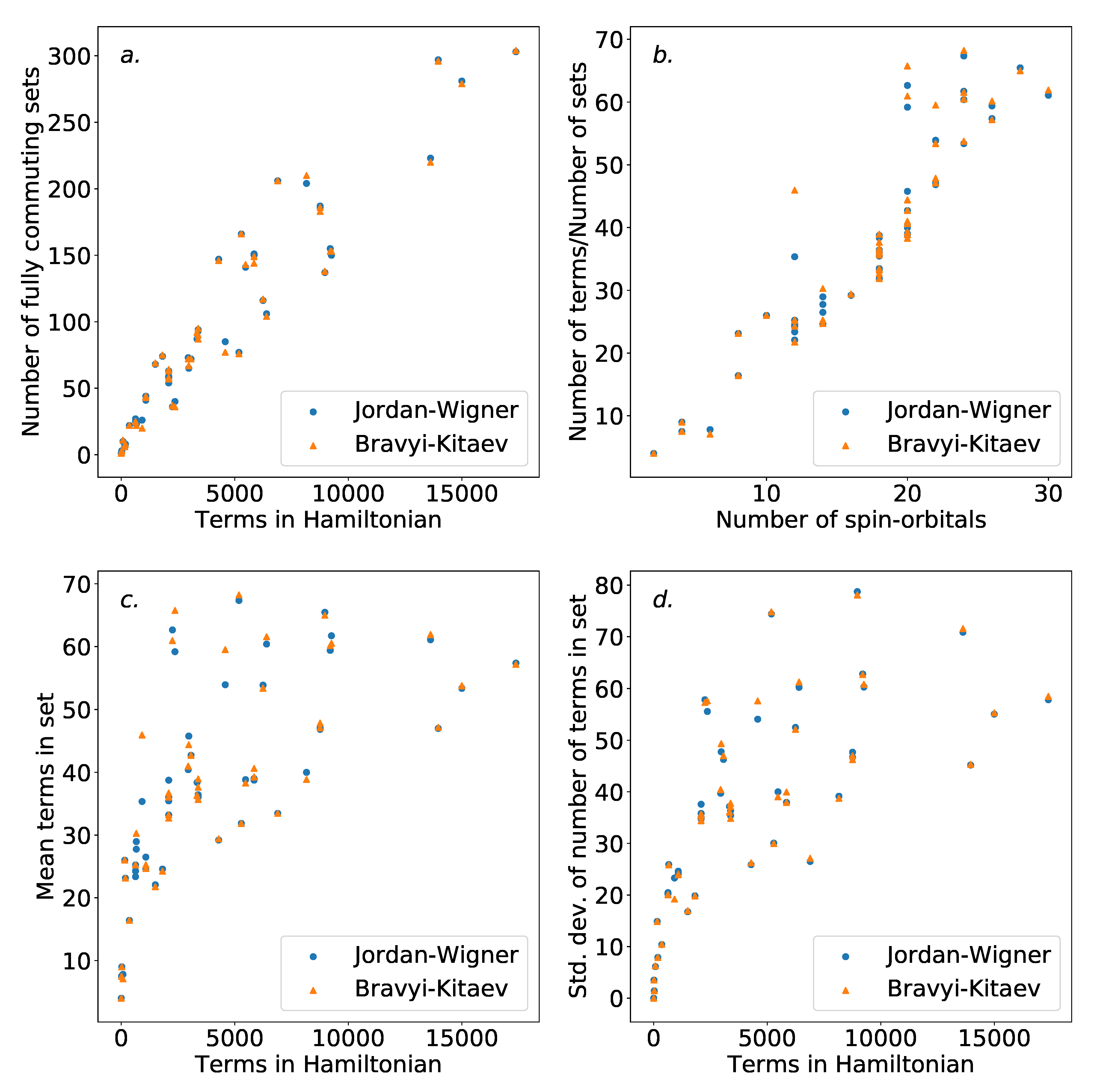
Figure 5 shows the number of independent sets found with regard to both the number of terms in the overall Hamiltonian, and the number of spin-orbitals describing the Hamiltonian. As is to be expected, the number of sets increases with the number of terms in the Hamiltonian.
There are
terms in the initial electronic Hamiltonian. Of these, terms that do not share any indices with each other will clearly commute, even in the absence of the use of the Jordan–Wigner or Bravyi–Kitaev transformations. As such, it is reasonable to expect the number of independent sets to be
. Therefore the ratio of the number of terms and independent sets found can be expected to scale roughly linearly with the number of spin-orbitals involved. This scaling is shown in
Figure 5, outside the smallest Hamiltonians. Notable outliers are present, likely due to molecular symmetries. Little difference is observed between the Jordan–Wigner and Bravyi–Kitaev Hamiltonians. This is to be expected, as the commutativity structure is defined by the physical electronic Hamiltonian; there is no obvious reason to expect that the mapping technique used would significantly affect this. Our results here are in agreement with those in Reference [
56], where the same scaling was observed for the dual problem (i.e., coloring the compatibility graph of the Hamiltonian).
Figure 5 also demonstrates the average and standard deviation of the size of the independent sets found for each Hamiltonian. The increased average size of the groups is unsurprising, as the number of terms increases faster than the number of sets. The increasing variance in the size of the sets may be undesirable. This is due to the fact that evenly-sized groups could be advantageous for ordering schemes, due to an increased ability to distribute the placement of terms. It is possible that the use of an alternative coloring strategy could circumvent this, and further work is required to assess whether this has an impact on the ordering schemes presented in
Section 4.3.
4.4. Subset-Based Ordering Schemes
The purpose here of dividing the Hamiltonian into mutually commuting subsets is to examine how a Trotter ordering which takes this into account will perform. The above analysis of the hydrogen molecule suggested that alternating between commuting sets may be an effective scheme for Trotter ordering. With Hamiltonians partitioned into commuting subsets as above, this scheme can be extended to larger systems. In this method, an ordered Hamiltonian is generated by sequentially picking terms from each subset until all subsets are depleted.
Two methodologies for this ordering algorithm were considered. In the first—the depleteGroups strategy—the sets were cycled through, picking the highest magnitude term from each and appending this to the ordered Hamiltonian. The second—the equaliseGroups strategy—at each stage picked the highest magnitude term in the largest subset, appending it to the ordered Hamiltonian. Where there were multiple “largest subsets", the highest magnitude term in the union of all largest subsets was used. Whereas the former strategy ensures that the sets are consistently cycled through until depletion, the latter ensures that the sets are evenly distributed throughout the Trotterized Hamiltonian.
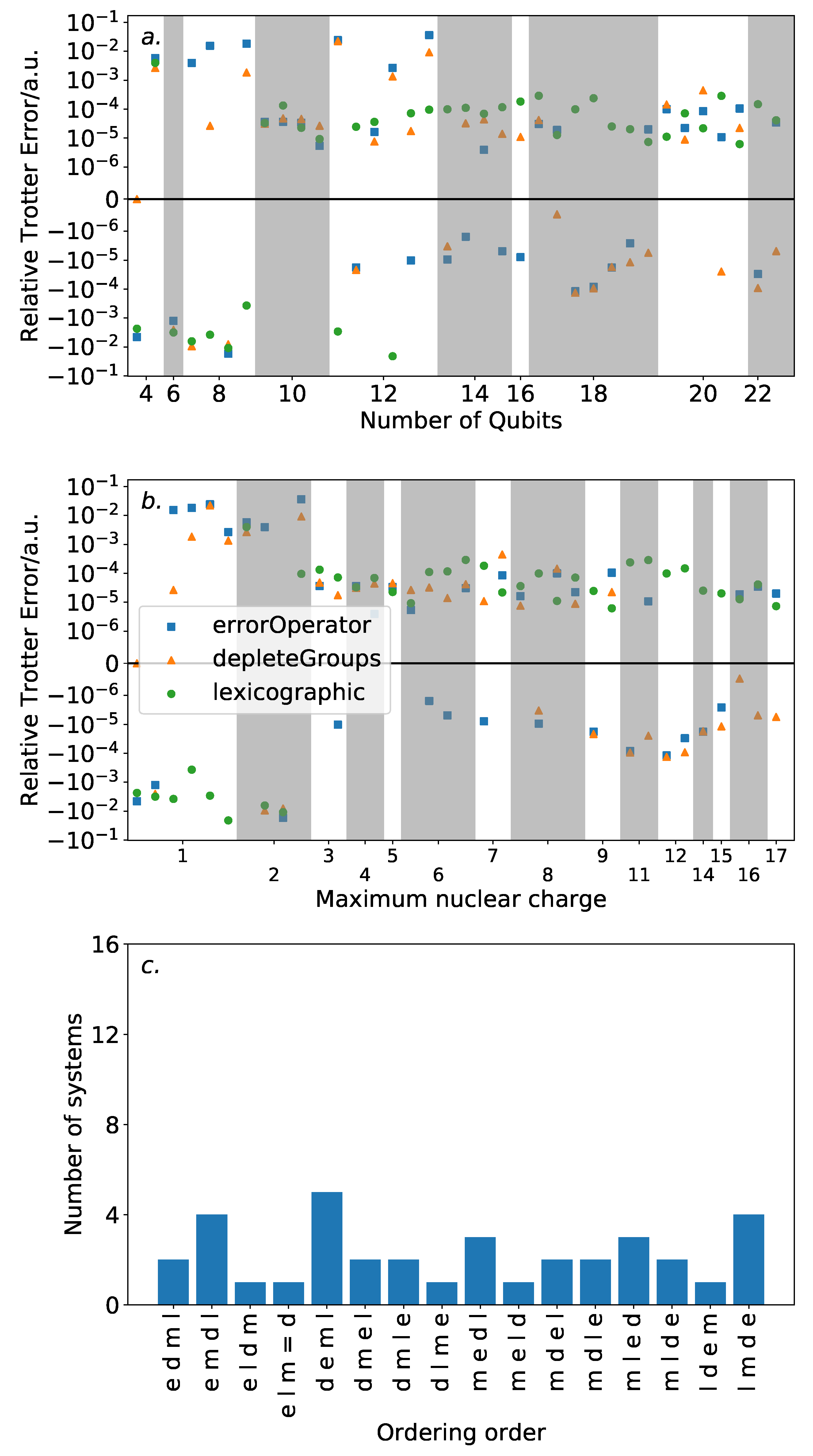
The Trotter error for one Trotter step (using a second-order Trotter approximation) was calculated for each Hamiltonian using both ordering strategies, using the approach discussed in
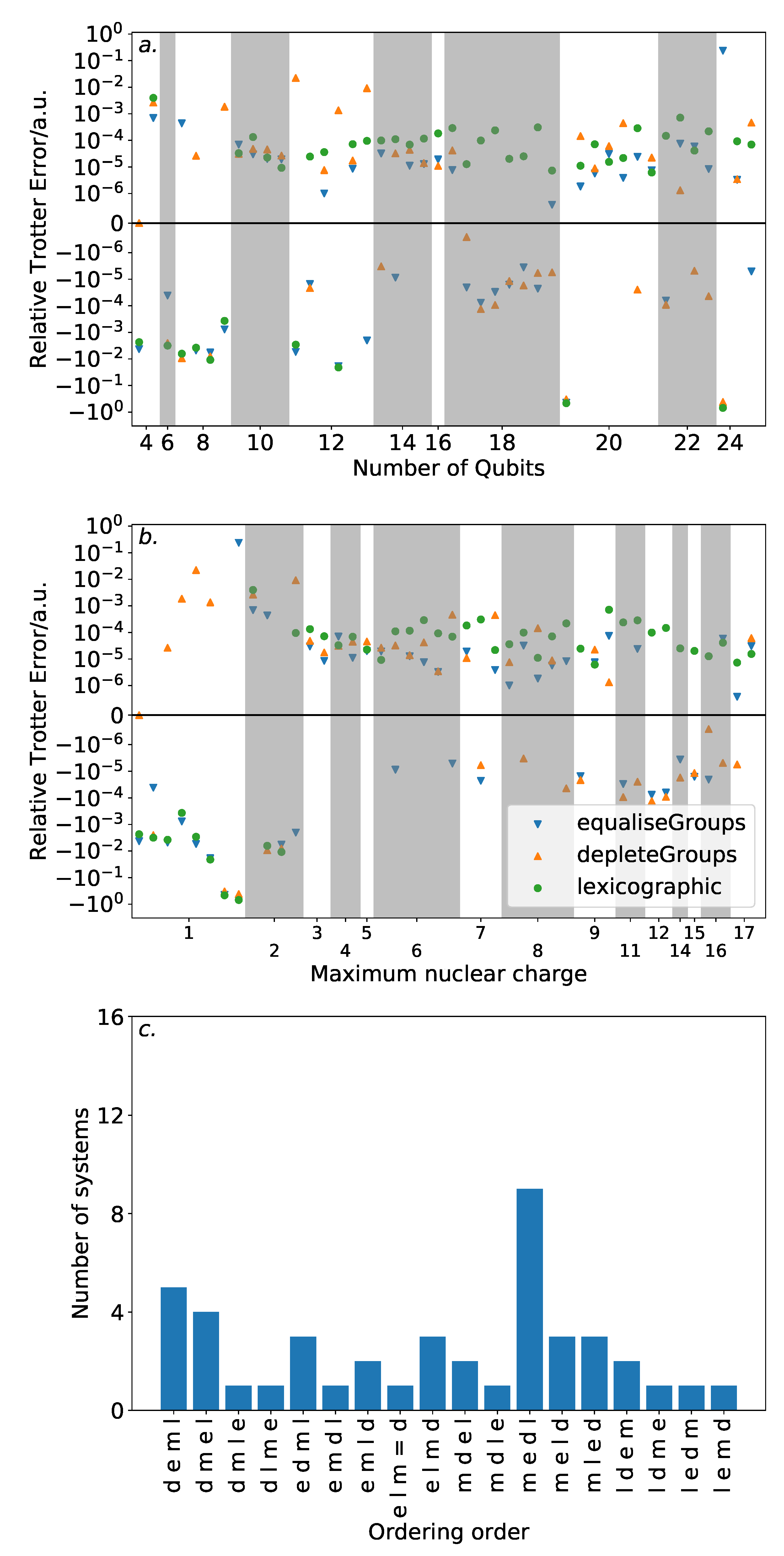
Section 4. Clearly, as this includes systems requiring more than 8 qubits, an exhaustive search of all possible orderings is not possible for all but the smallest of the systems included. Instead, we compare the depleteGroups and equaliseGroups orderings against other ordering schemes described above. We consider the performance of each ordering in terms of the number of spin-orbitals considered in the molecular system, and in the maximum nuclear charge.
Figure 6 shows the results of this analysis. High variance in ordering performance is associated with systems with only light atoms, but for most systems with heavier atoms, there is only a roughly
a.u. difference in Trotter error between the orderings. This is a large variance in comparison to the absolute Trotter error. However,
Figure 4 shows that using a magnitude ordering for these systems yielded an error that is sufficient for chemical accuracy. The observed difference between orderings is insufficient to increase the error above this threshold. As such, these results suggest that ordering choice when performing VQE can be determined by other factors, such as circuit length minimization. This is in sharp contrast to the results in
Section 3 on the hydrogen molecule in an STO-3G basis, where the Trotter error was dramatically impacted by the Trotter ordering, resulting in a differing amount of Trotter steps required for chemical accuracy. This reinforces the need to consider larger systems when benchmarking methods. Conversely, if phase estimation is to be performed, it is likely that this error would be compounded due to applications of higher powers of the Trotterized unitary. In this context, an optimal ordering scheme in terms of Trotter error would be more necessary.
The equaliseGroups and depleteGroups strategies appear reasonably promising. The depleteGroups scheme is superior to the equaliseGroups strategy in all bar one of the systems with more than 20 spin-orbitals, and performs roughly commensurately elsewhere. We conclude that of the depleteGroups and equaliseGroups strategies, the depleteGroups strategy should be favored, although it is possible that this is a result of the uneven group sizes shown by
Figure 5. An inspection of
Figure 6 shows that the depleteGroups strategy is better than the magnitude ordering in eighteen cases.
More consistency is observed with respect to the maximum nuclear charge. Highly variable performance is observed with light atoms; however beyond this, the difference in Trotter error is relatively minor. For several of the systems consisting of the most (22) spin-orbitals, the depleteGroups strategy begins to dramatically outperform all other orderings considered—including the magnitude ordering. For systems involving period three atoms, there is only one exception to this result. More data are required to assess whether this trend consistently extends to other, and larger, systems.
It should be noted that the process reported here to color the Hamiltonian commutativity graph was relatively simple, examining only one possible ordering strategy using a standard library. Future work could investigate the impact of altering the details of this scheme. A variety of factors could be considered here. For example, it is not immediately obvious whether it would be preferable to split the graph into few large independent sets, or many smaller ones. As mentioned above, various schemes of Hamiltonian term partitioning have been developed to reduce the cost of variational quantum algorithms, by combining sets of commuting or anticommuting terms [
53,
54,
55,
56]. It remains an open question as to whether Trotter ordering schemes based on graph coloring heuristics can be applied to Hamiltonians with terms combined in such a fashion.
The results of the depleteGroups strategy are encouraging, although they do not achieve improvement over a magnitude ordering in all cases. Further work examining larger systems is required to test whether the observed improvement with the depleteGroups strategy is maintained at larger numbers of spin-orbitals, although this may prove computationally difficult.
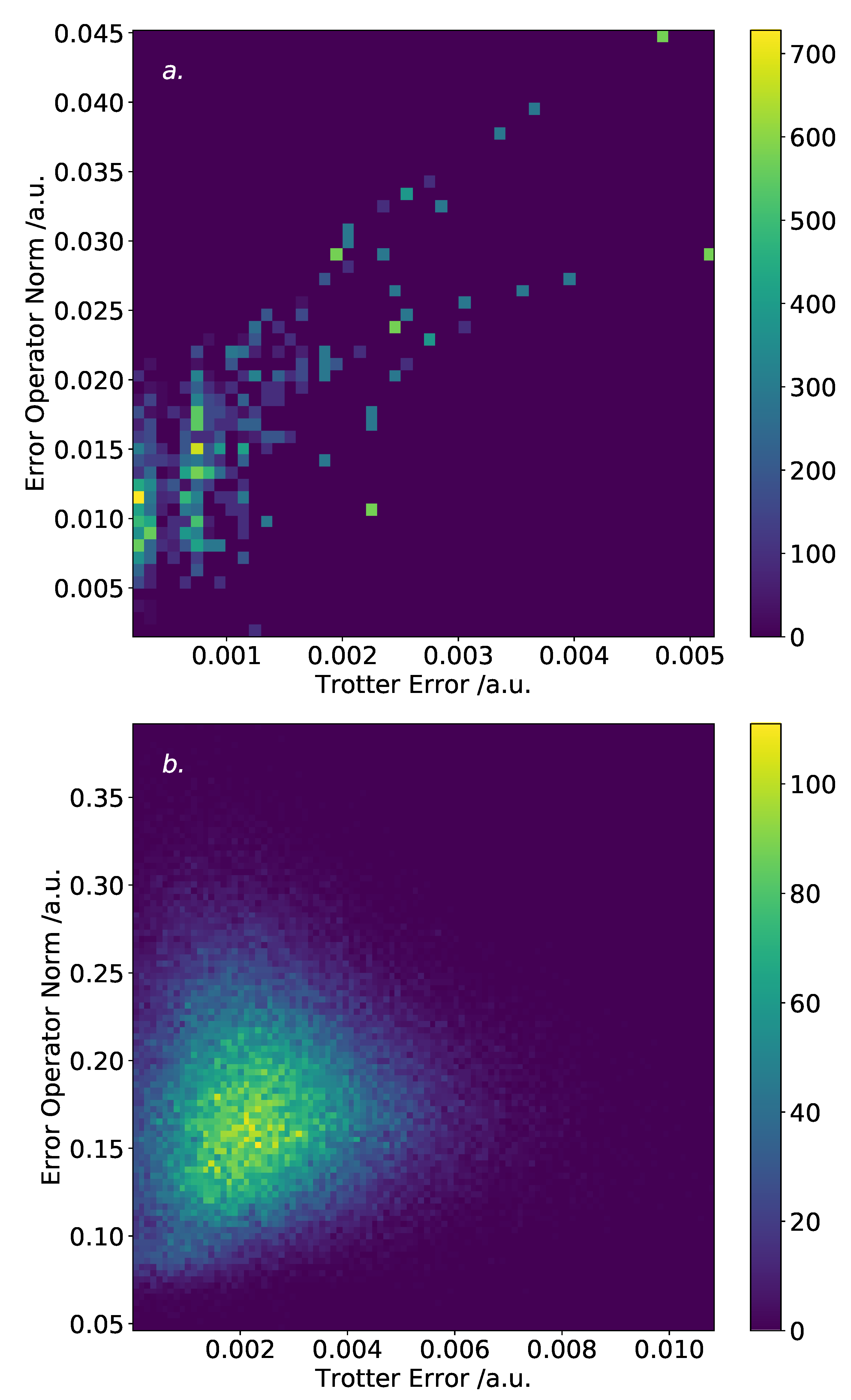
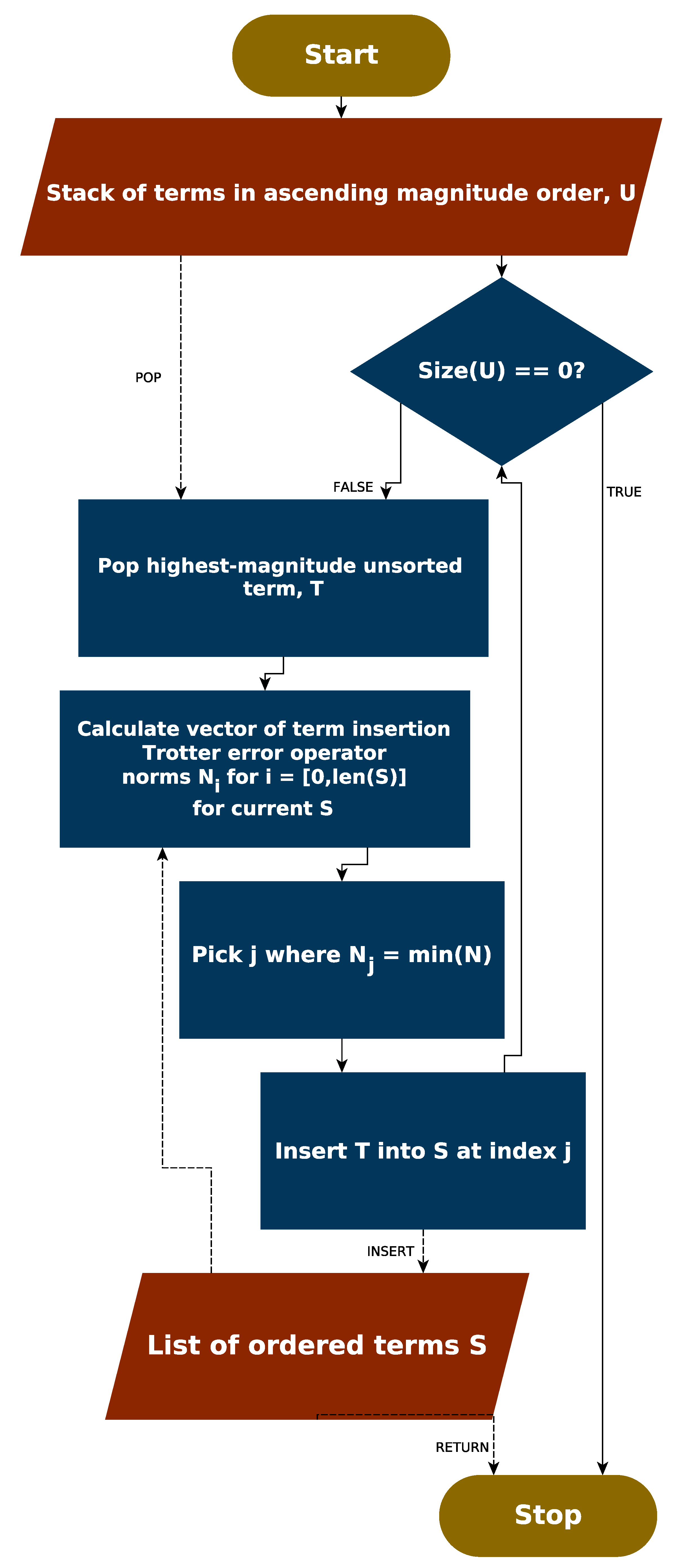
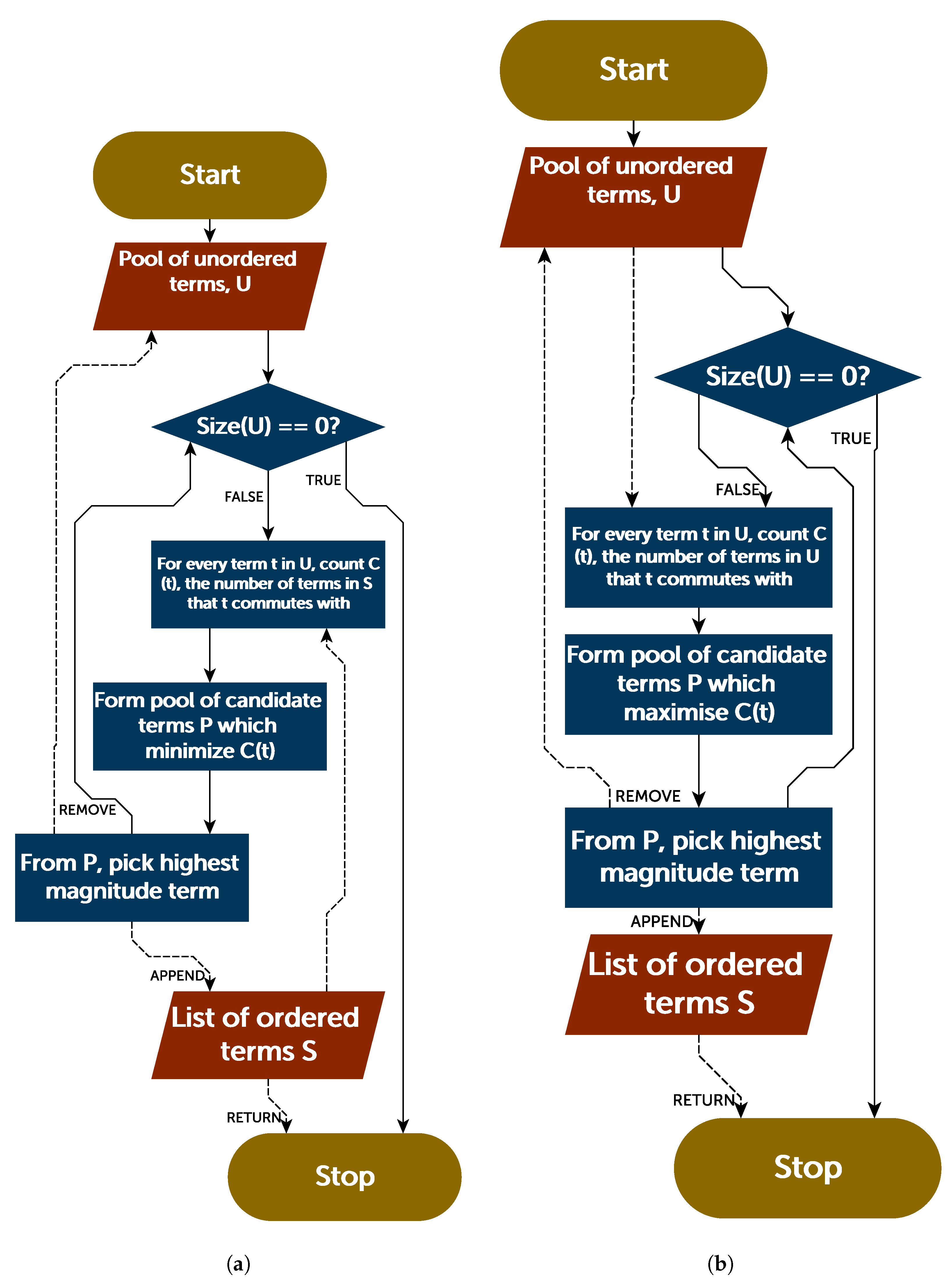
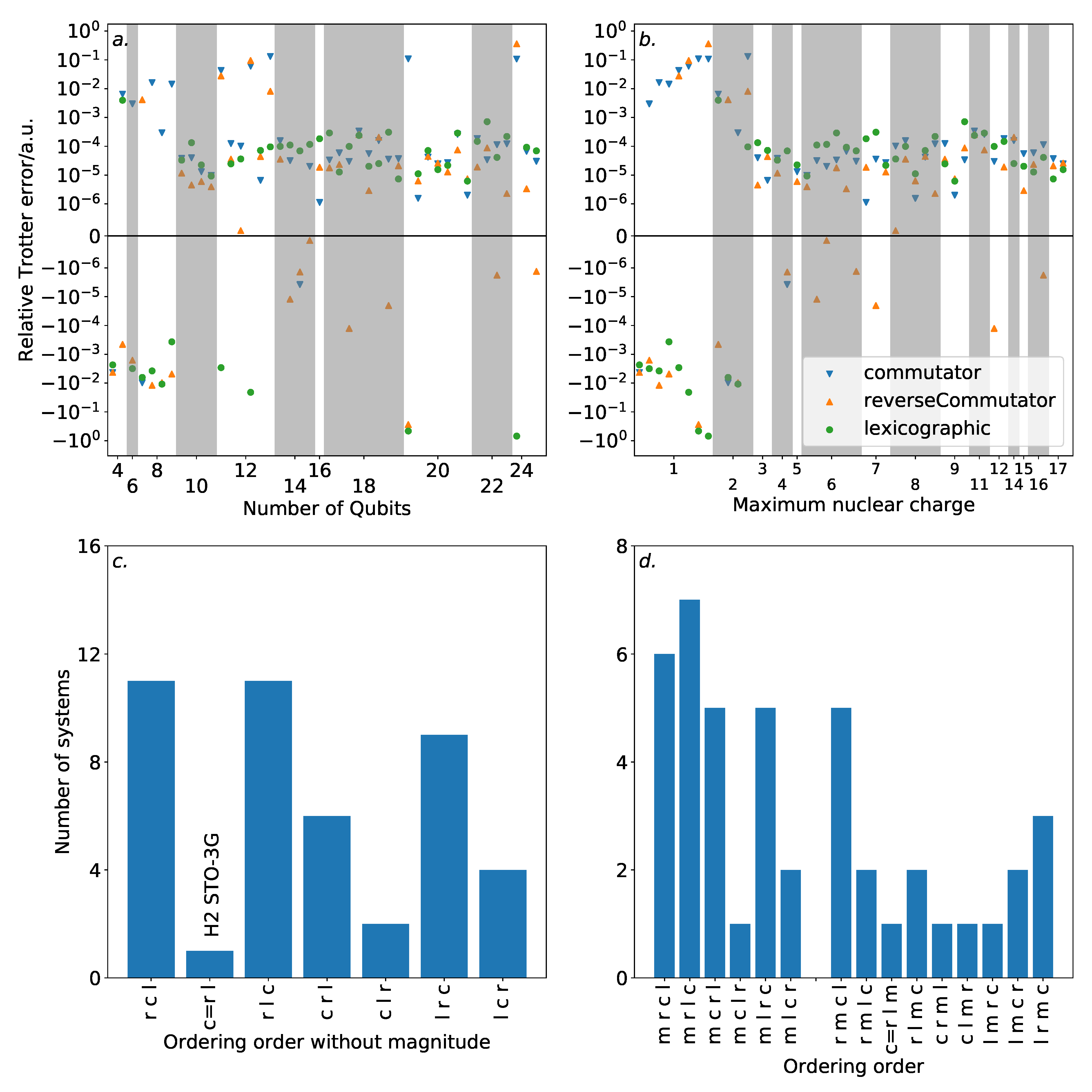
In complement to the above discussion, an entirely different approach to ordering could be considered, which relies upon the Trotter error operator. As the norm of this can be efficiently (albeit slowly) determined classically, it is possible that this information could be used to directly inform an ordering strategy—rather than indirectly through the commutation relations of terms. For completeness, we consider such an approach now.
6. Discussion and Conclusions
In this paper, we discussed ordering schemes for Trotterization from a variety of perspectives. Brute-force analysis on the STO-3G molecular hydrogen Hamiltonian and inspection of the Trotter error operator show that the commutativity structure of the Hamiltonian is of vital importance in determining the Trotter error incurred by a given ordering. The commutativity structure—represented by the incompatibility graph—can be efficiently found on a classical computer. Greedy coloring heuristics can be used to partition this graph into commuting or anticommuting sets, a technique which has been used recently in the context of term reduction in variational quantum algorithms [
53,
54,
55,
56]. It remains an open question as to how these term reduction techniques can be related to Trotter ordering strategies when implementing variational quantum algorithms.
We reported two ordering schemes dependent on the term commutativity structure, which operate by partitioning the Hamiltonian into totally commuting sets of terms. Applying a greedy coloring heuristic results in a number of sets that scales approximately as . By using these groups to inform placement of terms, this approach led to the best ordering scheme studied—the depleteGroups strategy. This strategy had the lowest Trotter error of all orderings in a plurality of Hamiltonians, although for systems involving heavy atoms, the difference when compared to a magnitude ordering was below the threshold for chemical accuracy.
Finally, we considered the use of the Trotter error operator norm to guide ordering strategies. A greedy algorithm aiming to minimize the norm of the Trotter error operator achieved performance consistent with magnitude ordering, though did not improve upon it in most cases. However, analysis of the Trotter error operator norm for very small molecules suggested that there is a high density of orderings which incur relatively low—if suboptimal—Trotter error.
Although the depleteGroups strategy showed promise, our analysis has indicated that finding an optimal Trotter ordering is a difficult task, due to the vast space of possible orderings. However, two results are of interest. Relative to the Trotter error, the difference between orderings can be substantial—in several cases, the difference in Trotter error incurred by the best and worst orderings was over two orders of magnitude. However, for the majority of systems studied, the overall Trotter error is extremely low. For all except four of the systems with more than 12 spin-orbitals, an ordering could be found that incurred a Trotter error below the threshold for chemical accuracy. Particularly for variational quantum algorithms—where Trotter decompositions are used to implement a variational Ansatz—this implies that Trotter error will not dominate the computational difficulty of simulations in the NISQ era.
Determining exact Trotter error on a classical computer is exponentially hard, due to the need to find an exact ground state. Therefore, there are two ways to scale examinations of Trotter error to systems involving larger numbers of spin-orbitals. The first is the use of efficient classical heuristics to compute
approximate estimates of the Trotter error which outperform the Trotter error operator norm. In particular, the development of classical approximations which reproduce the relative performance of differing Trotter ordering strategies would be a useful direction for future work. The second—similar to other techniques using a quantum device to improve the quantum algorithm [
58]—would be the use of NISQ devices themselves to directly evaluate ordering strategies through determination of exact Trotter errors in bulk. It is likely that a combination of each of these approaches will be necessary in order to determine ordering schemes that minimize Trotter error for large systems.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








