1. Introduction
High efficiency video coding (HEVC), also known as H.265, is the latest video coding standard. It was released in 2013 and achieves an average bitrate reduction of 50% for fixed video quality compared with the H.264/AVC which is a block-oriented motion-compensation-based video compression standard. As regards the limited channel bandwidth and storage capacity, its coding efficiency needs further improvement. A perceptual model based on the human visual system (HVS) can be integrated into the video coding framework to achieve a low bitrate with a high perceptual quality.
Saliency refers to the indication of the probability of human attention according to the visual stimulus, and the term saliency often appears indistinguishably in two types of studies with different approaches; the “different outputs” approach and the “different evaluations” approach [
1]. The first is a scientific study that aims to implement the psychophysical findings of human visual attention systems. This approach is referred to as a saliency map, and computes how much attention a pixel in a given image or video attracts, and then compares the output of the method with actual human gaze data. These outputs are often in the form of a two-dimensional map. The second type is a form of engineering studies, simply designed to extract meaningful objects. This approach is referred to as salient object detection, which aims to estimate regions in a given image that contain meaningful objects, and utilizes ground truth region labels for evaluation. Salient object detection is commonly interpreted in computer vision as a process that includes two stages: (a) detecting the most salient object and (b) segmenting the accurate regions of that object. These outputs are often in the form of a binary map.
Recently, perceptual video coding (PVC) has attracted lots of attention [
2,
3,
4]. The perceptual models in previous works have been divided into four categories: the visual attention (VA) model, the region-of-interest (ROI) model, the visual sensitivity (VS) model, and the cross-modal attention (CMA) model. A detailed description of these methods is as follows.
The main idea, according to the visual attention model, is to encode the importance of different regions with bottom-up or top-down attention. Itti presents a biologically-motivated algorithm to select visually-salient regions for video compression [
5]. Gou et al. propose a novel multiresolution spatiotemporal saliency detection model to calculate the spatiotemporal saliency map [
6]. This method can improve the coding efficiency significantly and works in real time. Wei et al. present an H.265/HEVC-compliant perceptual video coding scheme based on visual saliency [
7]. This method can reduce the bitrate significantly with negligible perceptual quality loss. However, in previous work, the video-based visual saliency model (VSM) has proved to be unsophisticated for use in video coding. The main idea of the ROI model is to encode an area around the predicted attention-grabbing regions with higher quality compared to other less visually important regions. Xu et al. present a region-of-interest based H.265/HEVC coding approach to improve the perceived visual quality [
8]. Grois et al. define a dynamic transition region between the region-of-interest and backgrounds [
9], then a complexity-aware adaptive spatial preprocessing scheme is presented for the efficient scalable video coding. However, the above methods do not make a distinction between the different parts of the non-moving region. The main idea, as regards the visual sensitivity model, is to improve the coding performance with kinds of visual signal distortion sensitivity differences in HVS [
10]. However, the computation complexity is higher when using these models. The main idea of the cross-modal attention model is to encode using multimodal interaction mechanisms [
11]. However, it is not applicable for no voice mixing of the video sequence. Recently, some innovative ideas have been developed to improve the performance of video coding. Ferroukhi et al. propose a method combining bandelets and the set partitioning in hierarchical trees (SPIHT) algorithm for medical video coding [
12], and this method has shown good high performances in terms of visual quality and peak signal-to-noise rate (PSNR) at low bitrates. Rouis et al. present a novel approach for perceptually guiding the rate-distortion optimization (RDO) process in H.265/HEVC [
13], and this proposed method demonstrates a superior rate-distortion (R-D) performance over a compared approach adopting a similar scheme. Moreover, the learning-based perceptual video coding methods are proposed to improve video quality [
14,
15]. However, the computation complexity of these methods is high.
In summary, the research related to PVC has made great progress in recent years, but there are deficiencies. For example, there is lack of effective saliency detection computing models for video coding applications. Image-based saliency detection has been extensively studied over the past decades. However, the research related to video-based saliency detection is much less explored. The existing saliency detection models only consider some of the characteristics of the image, and some of the temporal and context information is ignored. Moreover, most of the computation models are based on the pixel level. The computation complexity is too high, making it is unfavorable for real-time video applications.
In this paper, we proposed a new saliency detection model for video compression. Firstly, a novel saliency object detection model is proposed to generate a spatiotemporal saliency map. Secondly, the H.265/HEVC-compliant perceptual coding framework is developed based on the spatiotemporal saliency map. This paper has the following contributions: (1) a new superpixel-based salient object model is proposed which incorporates spatial and temporal features. (2) the proposed perceptual coding method achieves higher compression rates with a good balance between subjective and objective quality compared to the H.265/HEVC reference model.
2. Proposed Perceptual Video Coding Algorithm
2.1. System Overview
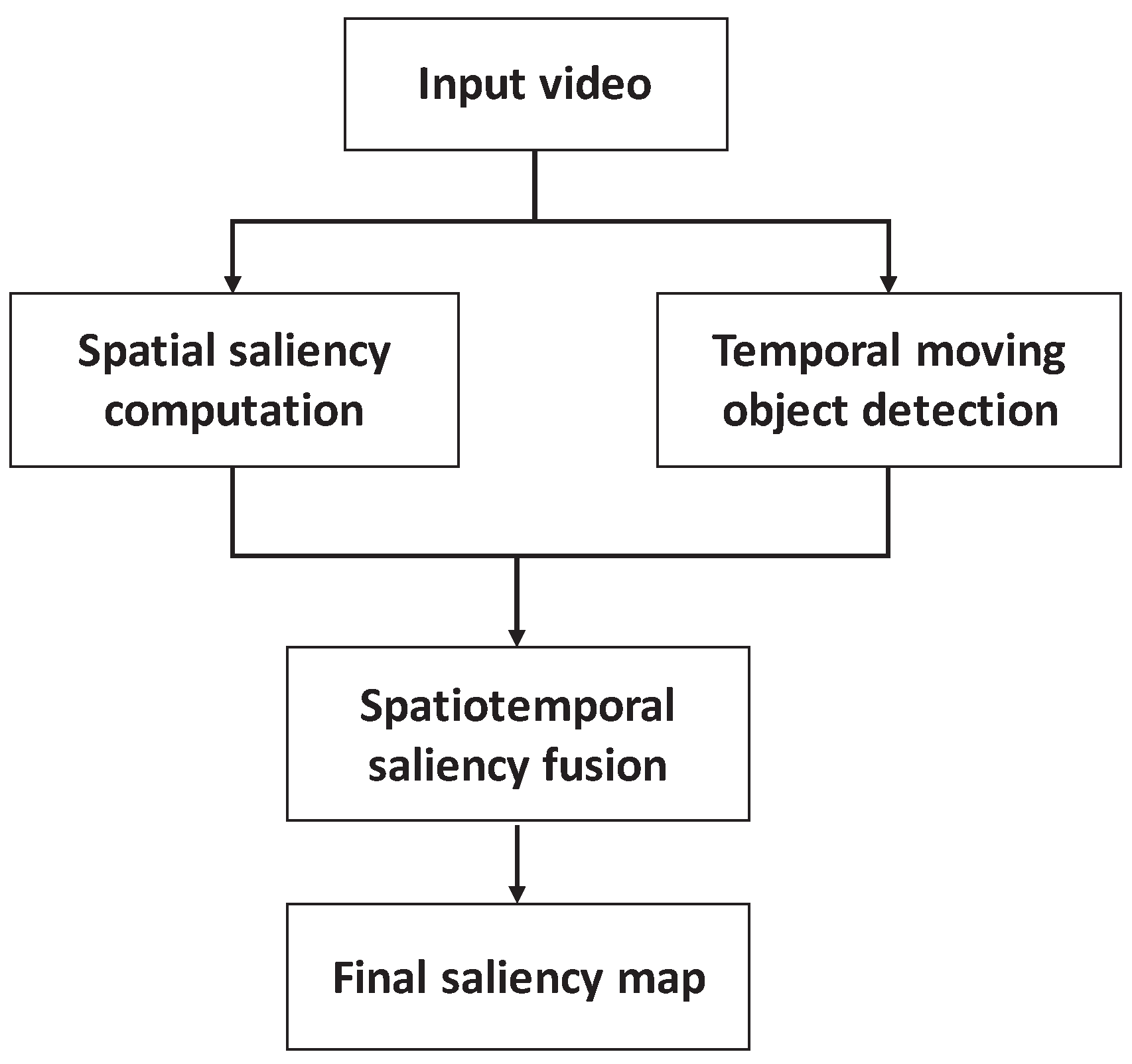
Figure 1 shows the framework of the saliency-based H.265/HEVC. This perceptual video coding framework includes two parts: the perceptual module and the encoder. The perceptual module is used to generate the saliency map using the spatiotemporal information. The saliency map is inputted so the encoder can determine the quantization parameters.
2.2. Video-Based Spatiotemporal Saliency Detection Model
For monitoring video, the moving object is the most attractive point of attention for a human. Meanwhile, there are the static features in the video. Thus, the spatiotemporal saliency map generated by the visual attention model and moving object detection model can be explored to guide the bit allocation for video coding.
For the input video signal, the spatial saliency and temporal saliency are computed using the spatiotemporal information, respectively. Therefore, according to a certain weight coefficient, the spatial and temporal saliency are merged into the final saliency map.
A good deal of research effort has already been devoted to saliency models for images. The image saliency models can be used for spatial saliency detection in each video frame. In this paper, the spatial saliency computation is based on the Markov chain (MC) saliency detection model developed by Lu et al. [
16], which is both effective and efficient. The main details of the MC saliency algorithm are as follows:
A single layer graph
with superpixels is constructed, where
V and
E represent the nodes and edges of
G, respectively. On the
G, each node, including transient nodes and absorbing nodes, is connected to the transient nodes which neighbor it or share common boundaries with its neighboring nodes. Thus, the weight
of the edge
between adjacent nodes
i and
j is defined as
where
and
represent the mean of the two nodes in the CIELAB color space, and
is a constant.
The nodes are renumbered so that the first t nodes are transient nodes and the last r nodes are absorbing nodes, and the affinity matrix A and degree matrix D can be expressed with . Then, the transition matrix P on the sparsely connected graph can be calculated from matrix A and D. After that, using the Markov chain theory, the absorbed time for each transient state can be calculated based on the transition matrix P. Finally, the saliency map S can be generated by normalizing the absorbed time.
The basic idea of the MC method is to detect the saliency using the time property in an absorbing Markov chain. The virtual boundary nodes are identified as absorbing nodes based on the prior boundary. The saliency is computed as the absorbed time to the absorbing nodes. On the basis of the MC saliency model, the spatial saliency value is represented as for each pixel i.
Particularly for videos, the temporal information is a significant hint, and more context exists in the field of video saliency detection. In video saliency detection, the optical flow technique can detect motion accurately.
and
are represented as the horizontal and vertical motion vector by using the Lucas–Kanade (LK) algorithm [
17]. Thus, the motion vector amplitude (MVA)
is calculated as
Furthermore, the MVA is enhanced as
where
and
are parameters, in this work,
and
. Finally, the
value is clipped to the [0, 255] range:
Then, the
can be assigned the temporal saliency value
for pixel
:
The temporal saliency reflects the dynamic characteristics of the video, while the spatial saliency reflects the static characteristics of the video. When the spatial and temporal saliency maps are constructed, we use them to get the final video saliency map.
Figure 2 shows the block diagram of the spatiotemporal saliency fusion framework. For the input video signal, the spatial saliency and temporal saliency are computed by using the spatiotemporal information, respectively. Thus, according to a certain weight coefficient, the spatial and temporal saliency are merged into the final saliency map.
Different fusion methods can be utilized, and the linear fusion is used in this paper. The final video saliency map
is generated by
where
is the weight of the temporal saliency, and
is the weight of the spatial saliency. The weight
is determined by the contribution of temporal characteristics in the spatiotemporal saliency. The best experimental combination that we obtained for Equation (
6) was achieved for
= 3/7 in this paper [
18].
In the video, the moving objects are regarded as the salient region. Finally, the superposition of spatiotemporal saliency is taken as the final saliency with linear fusion.
Figure 3d shows the spatiotemporal saliency for the third frame of the BasketballDrill sequence.
It is noted that this work is different from the existing method [
6]. Firstly, the Markov chain-based saliency detection model in this work is a spatial domain approach, while the phase spectrum of quaternion Fourier transform (PQFT) model in the existing method [
6] is a frequency domain one. However, the PQFT-based saliency model only highlights the boundaries of the salient object while the object interior still has a low saliency value. Secondly, the Markov chain-based saliency detection method in the proposed work can enhance the object interior significantly. Moreover, the proposed method is more effective in saliency detection.
Figure 4 shows an example of the saliency maps calculated by PQFT and the proposed methods, and it was discovered that the proposed method can predict eye fixations better than the PQFT method.
Moreover, for good saliency detection, a model should meet at least the following two criteria: (a) Good detection: the probability of missing real salient regions and falsely marking the background as a salient region should be low. (b) High saliency value: the boundaries of salient regions and region interiors have a high saliency value. The advantages of the proposed work are as follows: (1) In this work, the optical flow technique is used to detect temporal saliency, which can detect moving objects precisely. (2) The Markov chain-based saliency detection method in the proposed work can enhance the region’s interior significantly. Thus, the generated saliency map with the proposed method can increase the coding performance.
2.3. Saliency-Based Quantization Control Algorithm
In the video, the moving objects are regarded as the salient region. Finally, the superposition of spatiotemporal saliency is taken as the final saliency with linear fusion.
In H.265/HEVC standards, the coding unit (CU) is a square region and is a node of the quad-tree partitioning of the coding tree units (CTU) [
19]. The quad-tree partitioning structure allows recursive splitting into four equally sized nodes, and the minimum CU size is configured to be
,
, or
that of the luma samples. Coding unit tree is an algorithm for adaptive quantization parameters (QP). In order to control QP in the encoder, the saliency map can be partitioned into the block with a size of
. Then, the block-based saliency average value
is calculated as
where
N is CU size, and
is the saliency value of the pixel
within a CU.
In H.265/HEVC standards, a QP is used to determine the quantization step, the setting range of QP is from 0 to 51. In order to associate the block-based saliency value with QP, the saliency value can be normalized to the range [0, 3]. In this paper, the min–max normalization method is used to generate the saliency level for the block-based saliency average value
:
where
is the calculated saliency level, and
and
are the maximums and minimums of
, respectively.
When the value is high, the corresponding image can be encoded as a foreground. In contrast, when the value is low, the corresponding image can be encoded as a background. In the perceptual video coding process, the foreground needs to increase the allocated bitrate resources, while the background needs to reduce the allocated bitrate resources. In video coding, QP is used to adjust distortion. When the QP is larger, the image distortion is higher. Therefore, a high QP is used for the foreground coding, and a low QP is used for the background coding. On the basis of the saliency level , the setting quantized parameters () can be dynamically adjusted in the encoding process. When is the default quantized parameter, and the has four values (22, 27, 32, and 37) in H.265/HEVC reference software. Thus, the saliency-based quantization control algorithm is shown in Algorithm 1. By using the proposed method, more image distortion is introduced to CUs with a low saliency while less to CUs with a high saliency.
| Algorithm 1: Saliency-based quantization control algorithm |
![Entropy 21 00165 i001]() |
3. Experiment Results
The proposed algorithm is implemented and verified based on the H.265/HEVC reference model HM 16.0. The quantization parameters are set to 22, 27, 32, and 37, respectively. The configuration profile is low-delay (LD).
The performance of the proposed algorithm is evaluated by the average bitrate saving (BS) and Bjontegarrd Delta PSNR (BD-PSNR) according to Reference [
20]. The BS is calculated as
where
and
are the bitrates using the H.265/HEVC reference software and the proposed method with different
.
The double stimulus continuous quality scale (DSCQS) method is used for subjective evaluation [
21]. The subjects are presented with pairs of video sequences, where the first sequence is the H.265/HEVC reference video and the second sequence is the video with the proposed method. Secondly, a total of 24 naive viewers take part in the test campaign, and all viewers are screened for the correct level of visual acuity and color vision. Thirdly, viewers are expected to mark their visual quality score on an answer sheet with a quality rating scale over a defined scale that is defined in
Table 1.
The subjective evaluation of video quality is evaluated by the difference mean opinion score (MOS) average values Delta MOS (D-MOS), which is calculated as
where
and
are the measured MOS values from the sequence encoded by the proposed method and the H.265/HEVC reference software HM 16.0 with different
, respectively.
In the ablation study, the results of spatial-only, temporal-only, and the proposed spatiotemporal saliency-based quantization control scenarios are shown in
Table 2. From the experimental results, it can be seen that the average bitrate saving and Bjontegarrd Delta PSNR loss are 6.51%, 0.059 dB, and 6.09%, 0.053 dB for the spatial-only, temporal-only scenarios, respectively. For the proposed spatiotemporal method, the bitrate can be reduced by 5.22% while the Bjontegarrd Delta PSNR loss is only 0.046 dB on average. Thus, the objective distortion of the proposed method is smaller compared with the spatial-only and temporal-only scenarios.
For our experiments, we selected four test sequences of different resolutions. The four test sequences were also selected by considering the diversity of spatial characteristics and temporal characteristics. The four test sequences were the ‘
’ sequence with a resolution of
, the ‘
’ sequence with a resolution of
, the ‘
’ sequence with a resolution of
, and the ‘
’ sequence with a resolution of
. The test results of the proposed method are shown in
Table 3, compared to H.265/HEVC reference software with four QP values of 22, 27, 32, and 37, It shows that the proposed PVC method can achieve 1.22%–8.84% bitrate reduction for the test sequences, where
. It is also observed in
Table 3 that the bitrate reduction values are usually decreased as the QP value increases for the proposed method. This is because the distortions introduced by quantization errors are high enough at high QP values. It is noted in
Table 3 that the average time saving is 0.16% for the test sequences (
), compared to the H.265/HEVC reference software. Thus, the proposed method is effective, and the computational cost of the proposed method is almost the same as the H.265/HEVC reference software.
When the Delta MOS values are smaller, the subjective qualities are closer to the original H.265/HEVC reference software. The fifth, eighth, and eleventh columns in
Table 2 show the visual quality for the spatial-only, temporal-only, and spatiotemporal scenarios. It can be seen from the table that the average absolute Delta MOS value of the proposed method is even smaller than 0.1.
Figure 5 shows the typical example of MOS curve for Vidyo1 and BasketballDrill sequences among the spatial-only, temporal-only, spatio-temporal methods, and the H.265/HEVC reference model. From these figures, it can be seen that the proposed method shows visual quality improvements over the H.265/HEVC reference model, spatiotemporal methods, and temporal-only scenarios. Furthermore, when QP is set to 37,
Figure 6 shows the difference between the image of pure-HEVC and the image of the proposed reconstructed video for RaceHorsesC sequence. As can be seen from the graphic, at the low bit-rate, the visual quality of the proposed method is better than the visual quality of pure-HEVC.
Furthermore, the comparative results with previous work are shown in
Table 4, with QP set to 32. For Bae’s work [
10], the average bitrate saving and Delta MOS are 1.4%, 0.3, respectively. In contrast, the average bitrate can be reduced by 3.9% and the Delta MOS is 0.2 for the proposed scheme. Thus, the performance of the proposed method is superior to Bae’s work.
In summary, from the objective and subjective test results, the proposed perceptual video coding scheme can achieve higher compression rates with the balance between subjective and objective quality compared to the H.265/HEVC reference model.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}