Learning Entropy as a Learning-Based Information Concept



Abstract
:1. Introduction
2. Concept of Learning Information Measure
- Supervised learning (as for given input–output patterns with supervised learning), or via
- unsupervised learning (such as learned by clustering methods, SOMs, or auto-encoders).
3. Shannon Entropy versus Learning Entropy
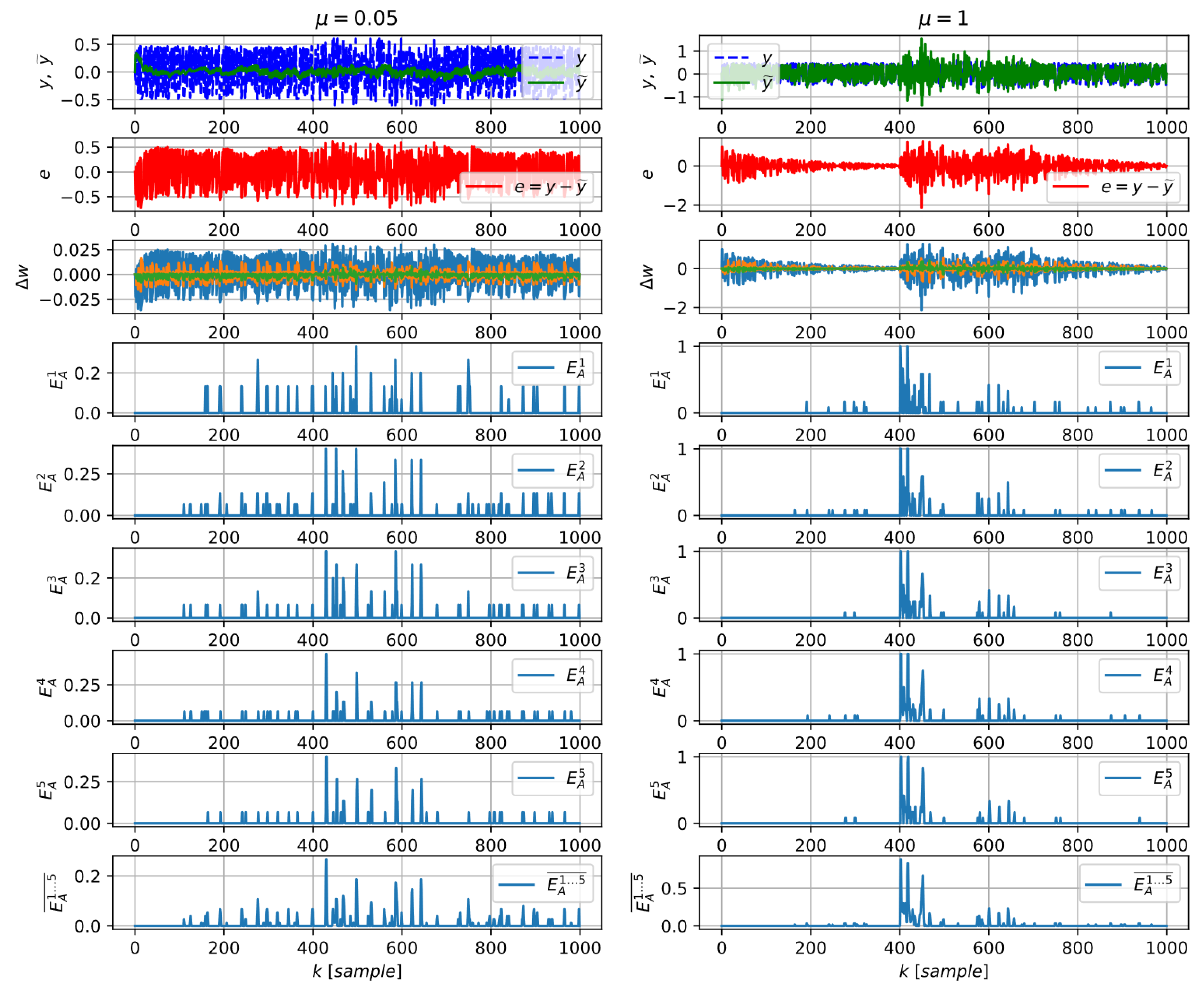
4. Algorithms for Learning Entropy Estimation
4.1. The Multiscale Approach
- is the relative detection sensitivity parameter that defines the crisp border between usual weight updates and unusually large ones (since the optimal α is never known in advance, the multi-scale evaluation has to be adopted).
- is the length of the floating window over which the average magnitudes of the recent weight updates are calculated (for periodical data, there is also the lag m between the actual time and the end of the window, see p. 4179 in [34]),
4.2. Practical Algorithm for Learning Entropy
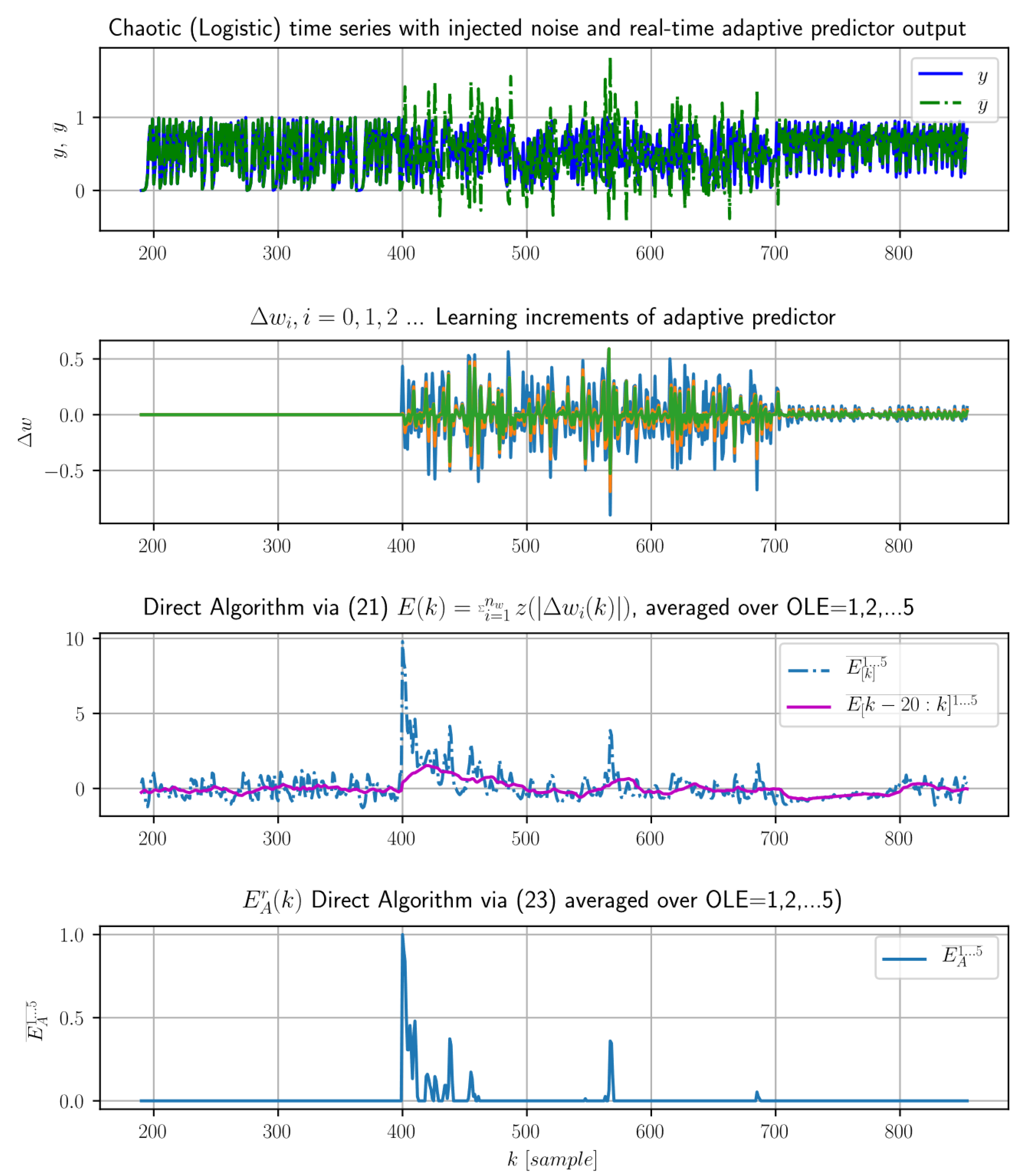
4.3. A Direct Algorithm
- detects only unusually large weight-update increments, larger than their recent mean plus standard deviation, and
- also directly computes their absolute significance (due to Z-scoring) for each weight while it was calculated in the previous concept of LE (18) and (19) via the multiscale evaluation over sensitivity setups (as recalled in Section 4.1 and (19)).
- if , the weight-update magnitudes larger than their recent mean are summed in (22) or counted in (23), i.e., the detection of unusual learning effort is the most sensitive one,
- if , only the weight-update magnitudes larger than their recent mean plus one standard deviation are summed in (22) or counted in (23), i.e., the detection of unusual learning effort is less sensitive,
- if , only the weight-update magnitudes larger than their recent mean plus two standard deviations are summed in (22) or counted in (23), i.e., the detection of unusual learning effort is even less sensitive, and, similarly, the detection of unusually large learning effort is less sensitive with the increasing parameter while the vector of detection sensitivities must not necessarily be a vector of integers.
5. Limitations and Further Challenges
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Markou, M.; Singh, S. Novelty detection: A review—Part 1: Statistical approaches. Signal Process. 2003, 83, 2481–2497. [Google Scholar] [CrossRef]
- Markou, M.; Singh, S. Novelty detection: A review—Part 2: Neural network based approaches. Signal Process. 2003, 83, 2499–2521. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [PubMed]
- Kinsner, W. Towards cognitive machines: Multiscale measures and analysis. Int. J. Cogn. Inf. Nat. Intel. (IJCINI) 2007, 1, 28–38. [Google Scholar] [CrossRef]
- Kinsner, W. A Unified Approach To Fractal Dimensions. Int. J. Cogn. Inf. Nat. Intel. (IJCINI) 2007, 1, 26–46. [Google Scholar] [CrossRef]
- Kinsner, W. Is Entropy Suitable to Characterize Data and Signals for Cognitive Informatics? Int. J. Cognit. Inform. Nat. Int. (IJCINI) 2007, 1, 34–57. [Google Scholar] [CrossRef]
- Zurek, S.; Guzik, P.; Pawlak, S.; Kosmider, M.; Piskorski, J. On the relation between correlation dimension, approximate entropy and sample entropy parameters, and a fast algorithm for their calculation. Phys. A Stat. Mech. Appl. 2012, 391, 6601–6610. [Google Scholar] [CrossRef]
- Schroeder, M.R. Fractals, Chaos, Power Laws: Minutes from an Infinite Paradise; W. H. Freeman: New York, NY, USA, 1991; ISBN 0-7167-2136-8. [Google Scholar]
- Costa, M.; Goldberger, A.L.; Peng, C.-K. Multiscale Entropy Analysis of Complex Physiologic Time Series. Phys. Rev. Lett. 2002, 89, 068102. [Google Scholar] [CrossRef]
- Costa, M.; Goldberger, A.L.; Peng, C.-K. Multiscale entropy analysis of biological signals. Phys. Rev. E 2005, 71, 021906. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.-D.; Wu, C.-W.; Lin, S.-G.; Wang, C.-C.; Lee, K.-Y. Time series analysis using composite multiscale entropy. Entropy 2013, 15, 1069–1084. [Google Scholar] [CrossRef]
- Faes, L.; Nollo, G.; Porta, A. Compensated transfer entropy as a tool for reliably estimating information transfer in physiological time series. Entropy 2013, 15, 198–219. [Google Scholar] [CrossRef]
- Yin, L.; Zhou, L. Function based fault detection for uncertain multivariate nonlinear non-gaussian stochastic systems using entropy optimization principle. Entropy 2013, 15, 32–52. [Google Scholar] [CrossRef]
- Vorburger, P.; Bernstein, A. Entropy-based Concept Shift Detection. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; pp. 1113–1118. [Google Scholar]
- Amigó, J.; Balogh, S.; Hernández, S. A Brief Review of Generalized Entropies. Entropy 2018, 20, 813. [Google Scholar] [CrossRef]
- Bereziński, P.; Jasiul, B.; Szpyrka, M. An Entropy-Based Network Anomaly Detection Method. Entropy 2015, 17, 2367–2408. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Orłowski, A.; Ząbkowski, T. Simulation Study on the Application of the Generalized Entropy Concept in Artificial Neural Networks. Entropy 2018, 20, 249. [Google Scholar] [CrossRef]
- Ghanbari, M.; Kinsner, W. Extracting Features from Both the Input and the Output of a Convolutional Neural Network to Detect Distributed Denial of Service Attacks. In Proceedings of the 2018 IEEE 17th International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Berkeley, CA, USA, 16–18 July 2018; pp. 138–144. [Google Scholar]
- Willsky, A.S. A survey of design methods for failure detection in dynamic systems. Automatica 1976, 12, 601–611. [Google Scholar] [CrossRef]
- Gertler, J.J. Survey of model-based failure detection and isolation in complex plants. IEEE Control Syst. Mag. 1988, 8, 3–11. [Google Scholar] [CrossRef]
- Isermann, R. Process fault detection based on modeling and estimation methods—A survey. Automatica 1984, 20, 387–404. [Google Scholar] [CrossRef]
- Frank, P.M. Fault diagnosis in dynamic systems using analytical and knowledge-based redundancy: A survey and some new results. Automatica 1990, 26, 459–474. [Google Scholar] [CrossRef]
- Widmer, G.; Kubat, M. Learning in the presence of concept drift and hidden contexts. Mach. Learn. 1996, 23, 69–101. [Google Scholar] [CrossRef]
- Polycarpou, M.M.; Helmicki, A.J. Automated fault detection and accommodation: A learning systems approach. IEEE Trans. Syst. Man Cybern. 1995, 25, 1447–1458. [Google Scholar] [CrossRef]
- Demetriou, M.A.; Polycarpou, M.M. Incipient fault diagnosis of dynamical systems using online approximators. IEEE Trans. Autom. Control 1998, 43, 1612–1617. [Google Scholar] [CrossRef]
- Trunov, A.B.; Polycarpou, M.M. Automated fault diagnosis in nonlinear multivariable systems using a learning methodology. IEEE Trans. Neural Netw. 2000, 11, 91–101. [Google Scholar] [CrossRef] [PubMed]
- Alippi, C.; Roveri, M. Just-in-Time Adaptive Classifiers—Part I: Detecting Nonstationary Changes. IEEE Trans. Neural Netw. 2008, 19, 1145–1153. [Google Scholar]
- Alippi, C.; Roveri, M. Just-in-Time Adaptive Classifiers—Part II: Designing the Classifier. IEEE Trans. Neural Netw. 2008, 19, 2053–2064. [Google Scholar]
- Alippi, C.; Boracchi, G.; Roveri, M. Just-In-Time Classifiers for Recurrent Concepts. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 620–634. [Google Scholar] [CrossRef]
- Alippi, C.; Ntalampiras, S.; Roveri, M. A Cognitive Fault Diagnosis System for Distributed Sensor Networks. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1213–1226. [Google Scholar] [CrossRef]
- Grossberg, S. Adaptive Resonance Theory: How a Brain Learns to Consciously Attend, Learn, and Recognize a Changing World. Neural Netw. 2013, 37, 1–47. [Google Scholar] [CrossRef]
- Bukovsky, I. Learning Entropy: Multiscale Measure for Incremental Learning. Entropy 2013, 15, 4159–4187. [Google Scholar] [CrossRef]
- Bukovsky, I.; Oswald, C.; Cejnek, M.; Benes, P.M. Learning entropy for novelty detection a cognitive approach for adaptive filters. In Proceedings of the Sensor Signal Processing for Defence (SSPD), Edinburgh, UK, 8–9 September 2014; pp. 1–5. [Google Scholar]
- Bukovsky, I.; Homma, N.; Cejnek, M.; Ichiji, K. Study of Learning Entropy for Novelty Detection in lung tumor motion prediction for target tracking radiation therapy. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 3124–3129. [Google Scholar]
- Bukovsky, I.; Cejnek, M.; Vrba, J.; Homma, N. Study of Learning Entropy for Onset Detection of Epileptic Seizures in EEG Time Series. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016. [Google Scholar]
- Bukovsky, I.; Oswald, C. Case Study of Learning Entropy for Adaptive Novelty Detection in Solid-fuel Combustion Control. In Intelligent Systems in Cybernetics and Automation Theory (CSOC 2015); Advances in Intelligent Systems and Computing; Silhavy, R., Senkerik, R., Oplatkova, Z., Prokopova, Z., Silhavy, P., Eds.; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Cejnek, M.; Bukovsky, I. Concept drift robust adaptive novelty detection for data streams. Neurocomputing 2018, 309, 46–53. [Google Scholar] [CrossRef]
- Brissaud, J.-B. The meanings of entropy. Entropy 2005, 7, 68–96. [Google Scholar] [CrossRef]
- Bukovsky, I. Modeling of Complex Dynamic Systems by Nonconventional Artificial Neural Architectures and Adaptive Approach to Evaluation of Chaotic Time Series. PhD thesis (in English), CTU in Prague, Prague, Czech Republic. Available online: https://aleph.cvut.cz/F?func=direct&doc_number=000674522&local_base=DUPL&format=999 (accessed on 11 February 2019).
- Bukovsky, I.; Bila, J. Adaptive Evaluation of Complex Dynamical Systems Using Low-Dimensional Neural Architectures. In Advances in Cognitive Informatics and Cognitive Computing. Studies in Computational Intelligence; Wang, Y., Zhang, D., Kinsner, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 323, pp. 33–57. ISBN 978-3-642-16082-0. [Google Scholar]
- Bukovsky, I.; Kinsner, W.; Bila, J. Multiscale analysis approach for novelty detection in adaptation plot. In Proceedings of the Sensor Signal Processing for Defence (SSPD 2012), London, UK, 25–27 September 2012; pp. 1–6. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Detection Function Modifications for Varying Orders of LE | |
|---|---|
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bukovsky, I.; Kinsner, W.; Homma, N. Learning Entropy as a Learning-Based Information Concept. Entropy 2019, 21, 166. https://doi.org/10.3390/e21020166
Bukovsky I, Kinsner W, Homma N. Learning Entropy as a Learning-Based Information Concept. Entropy. 2019; 21(2):166. https://doi.org/10.3390/e21020166
Chicago/Turabian StyleBukovsky, Ivo, Witold Kinsner, and Noriyasu Homma. 2019. "Learning Entropy as a Learning-Based Information Concept" Entropy 21, no. 2: 166. https://doi.org/10.3390/e21020166
APA StyleBukovsky, I., Kinsner, W., & Homma, N. (2019). Learning Entropy as a Learning-Based Information Concept. Entropy, 21(2), 166. https://doi.org/10.3390/e21020166