A New Dictionary Construction Based Multimodal Medical Image Fusion Framework


Abstract
:1. Introduction
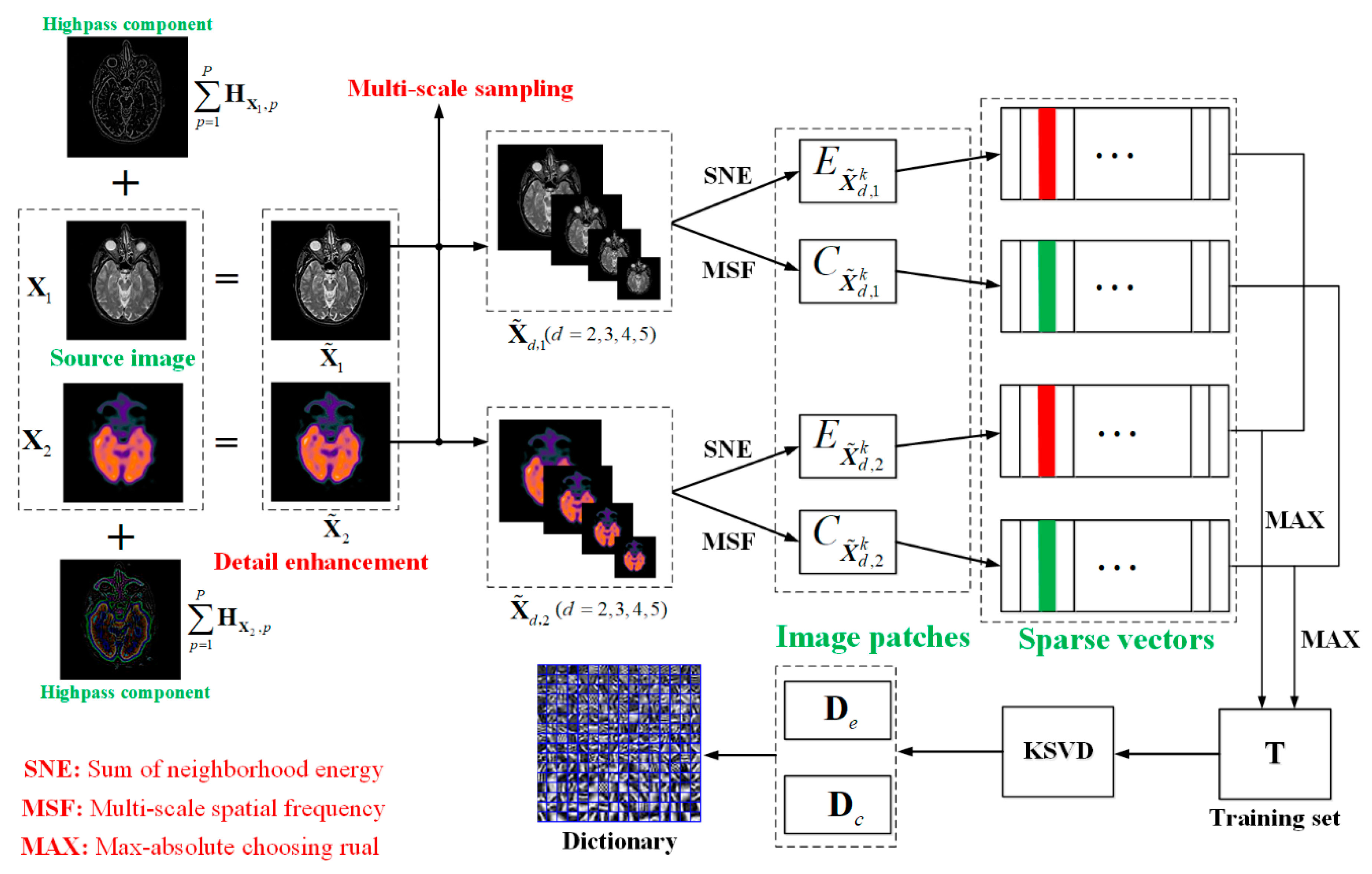
- We conduct multi-level neighbor distance filtering to enhance the information and take multi-scale sampling to realize the multi-scale expression of images, which can make image patches more informative and flexible, while not increasing the computational complexity in the training stage.
- Based on the characteristics of the human visual system processing medical images, we develop novel neighborhood energy and a multi-scale spatial frequency to cluster brightness and detail patches, and then train the brightness sub-dictionary and detail sub-dictionary, respectively.
- A feature discriminative dictionary is constructed by combing the two sub-dictionaries. The final dictionary contains important brightness and detail information, which can effectively describe the useful feature of medical images.
2. Proposed Framework
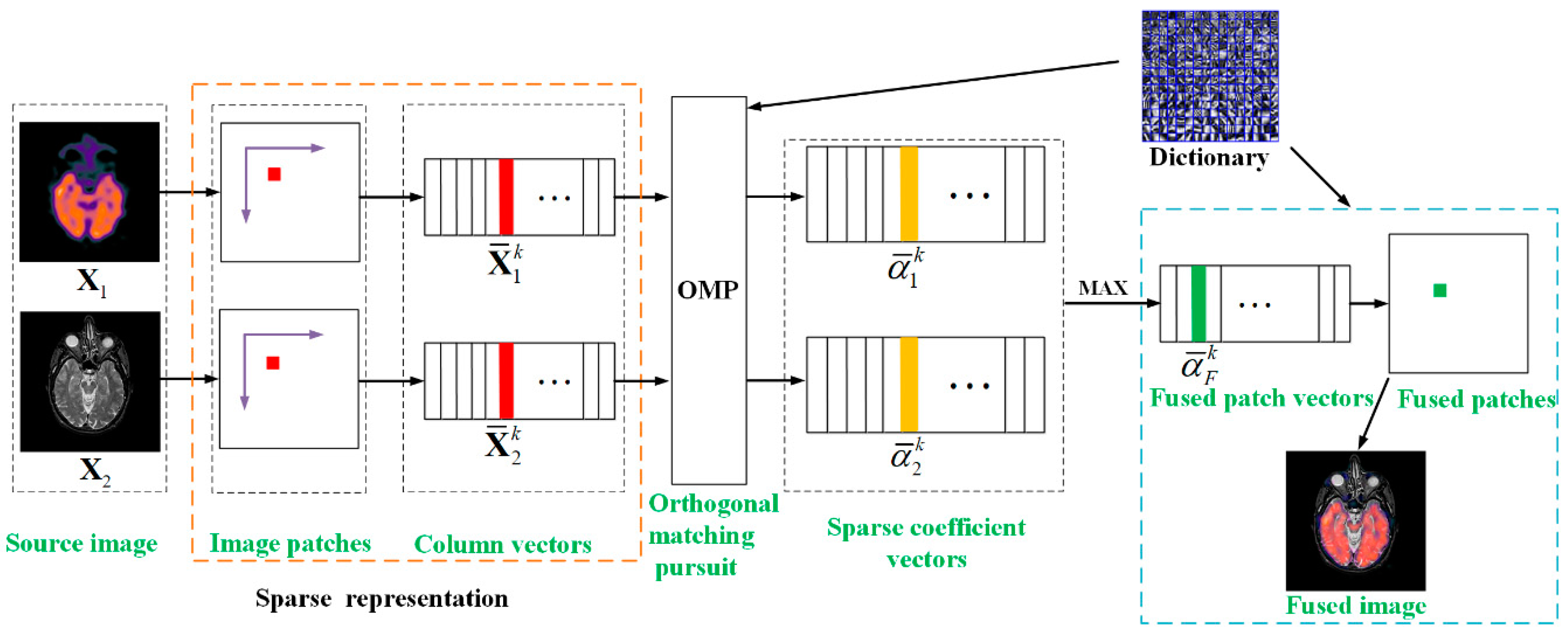
2.1. Sparse Representation
2.2. Proposed Dictionary Learning Approach
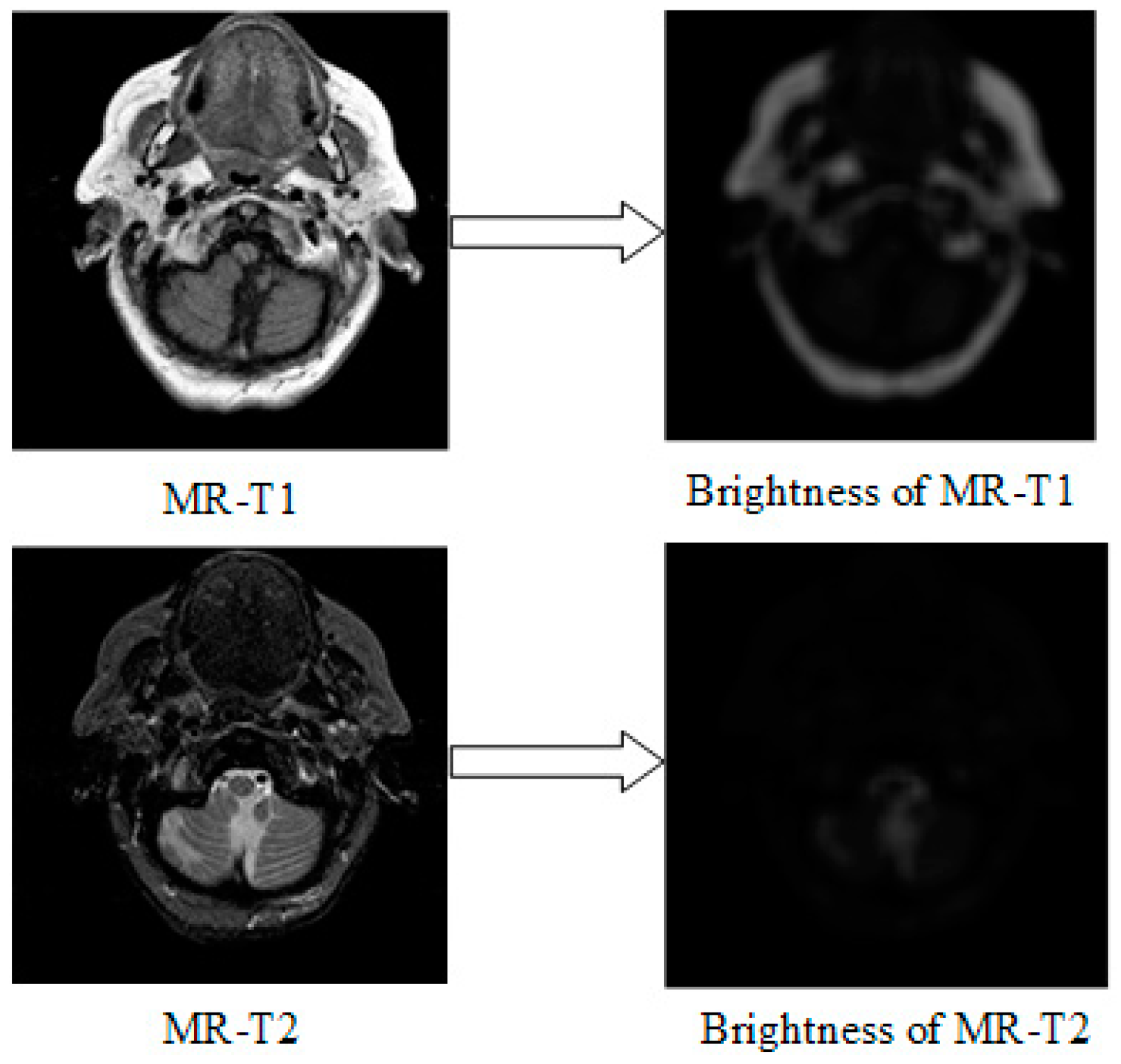
2.2.1. Detail Enhancement
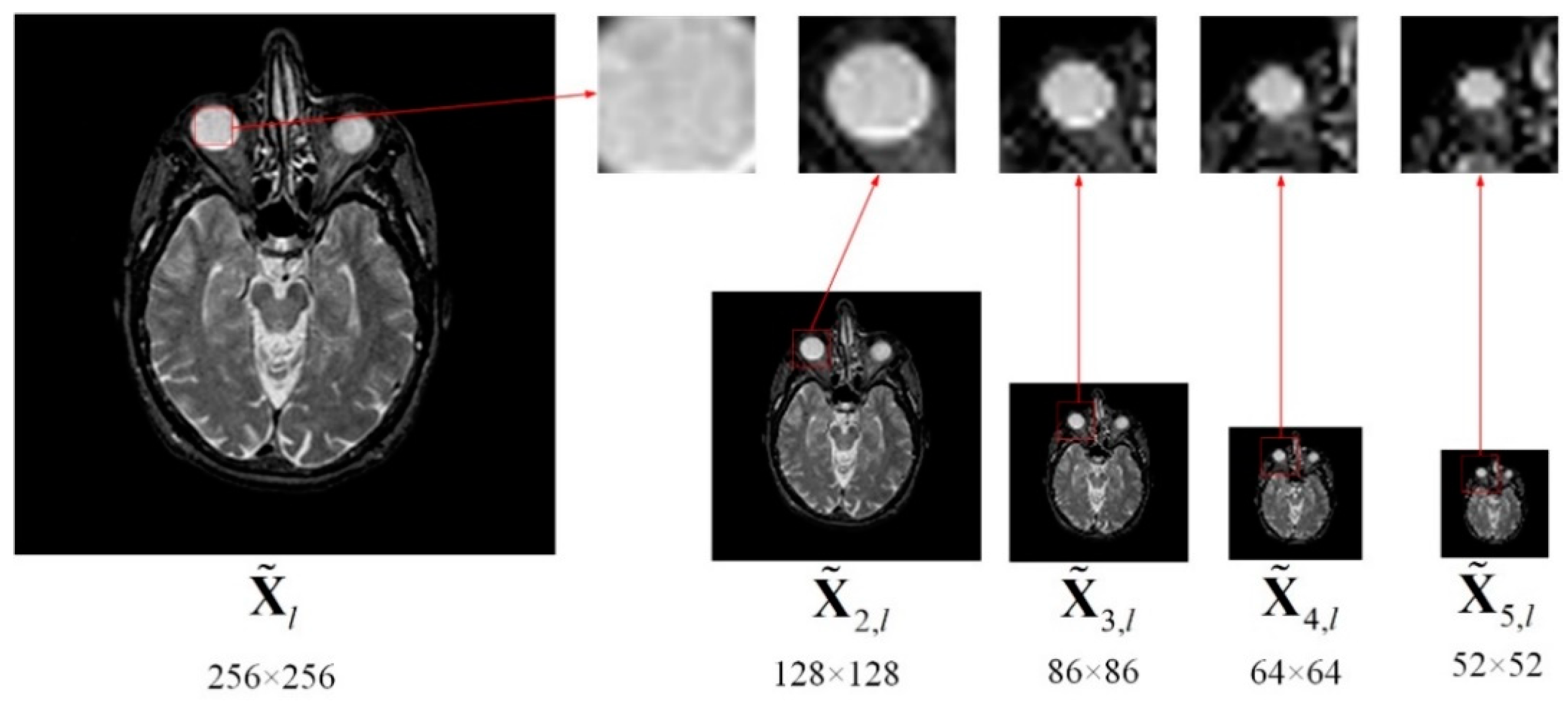
2.2.2. Multi-Scale Sampling (MSS)
2.2.3. Sum of Neighborhood Energy (SNE)
2.2.4. Multi-Scale Spatial Frequency (MSF)
2.2.5. Clustering and Dictionary Learning
| Algorithm 1 The proposed dictionary learning algorithm |
| Inputs: Two group of images () |
| (1) Extract patches of and from upper left to lower right. |
| (2) Patch classification based on SNE and MSF in Equations (6) and (8), respectively. |
| (3) Construct two training sets and by Equations (13) and (15), respectively. |
| (4) Obtain the two sub-dictionaries and by solve Equations (17) and (19), respectively. |
| (5) Generate the final dictionary by Equation (20) |
| Output: The overcomplete dictionary |
2.3. Image Fusion
3. Experiments and Analysis
3.1. Test methods and Parameters Setting
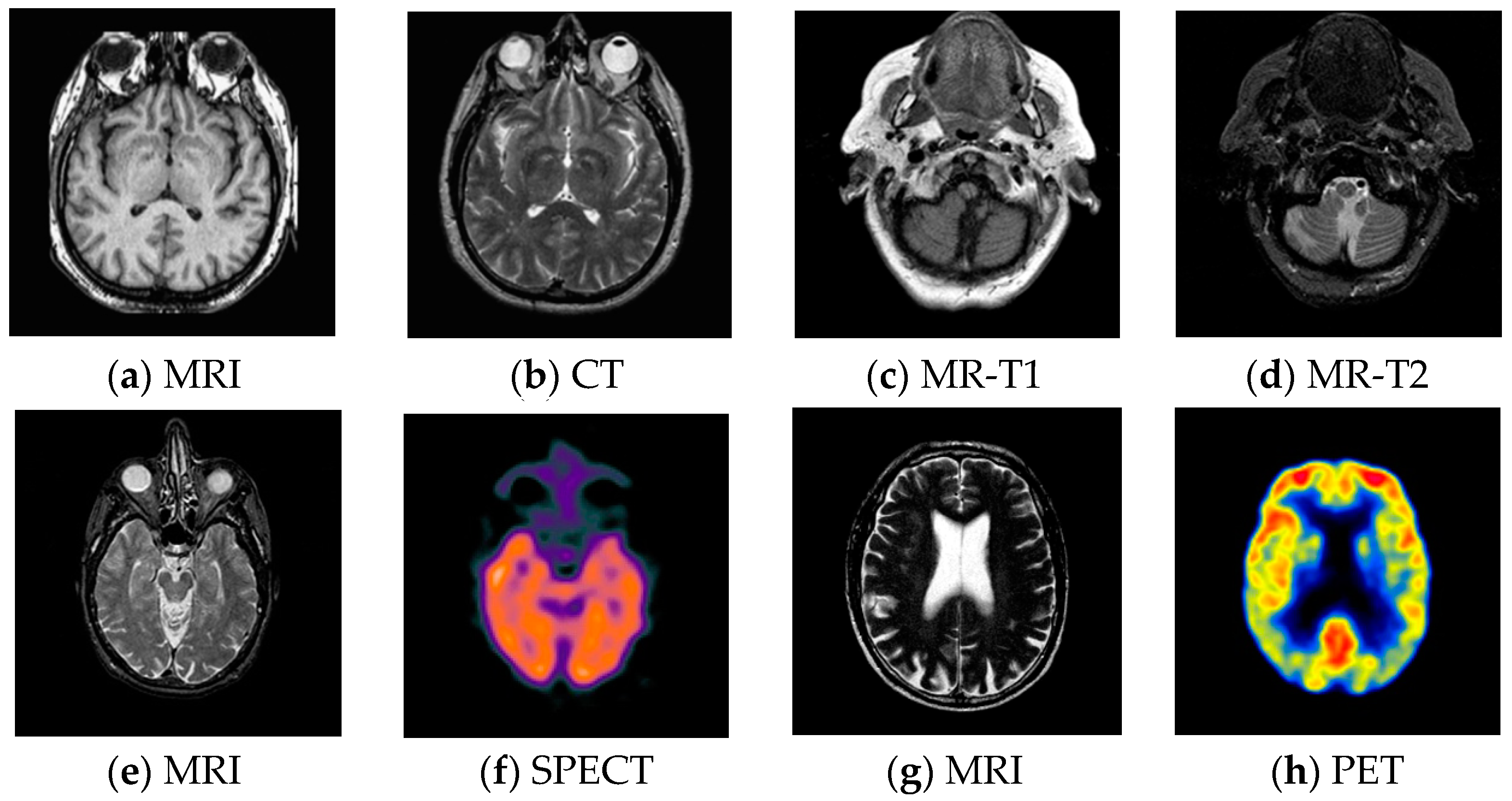
3.2. Test Images
- CT has a shorter imaging time and a higher spatial resolution, whereas it provides soft tissue information with low contrast.
- MRI can clearly display the soft tissue information of the human body, but it is hard to reflect the dynamic information of the metabolic activity in human body.
- MR-T1 image is sensitive to observe the anatomy, while the MR-T2 image can detect the tissue lesions.
- SPECT can show the biological activities of cells and molecules, but it is difficult to distinguish human organ tissues due to the low image quality of SPECT.
- PET can reflect the metabolic activity information of human tissues and organs at the molecular level, but the spatial resolution of PET is relatively low.
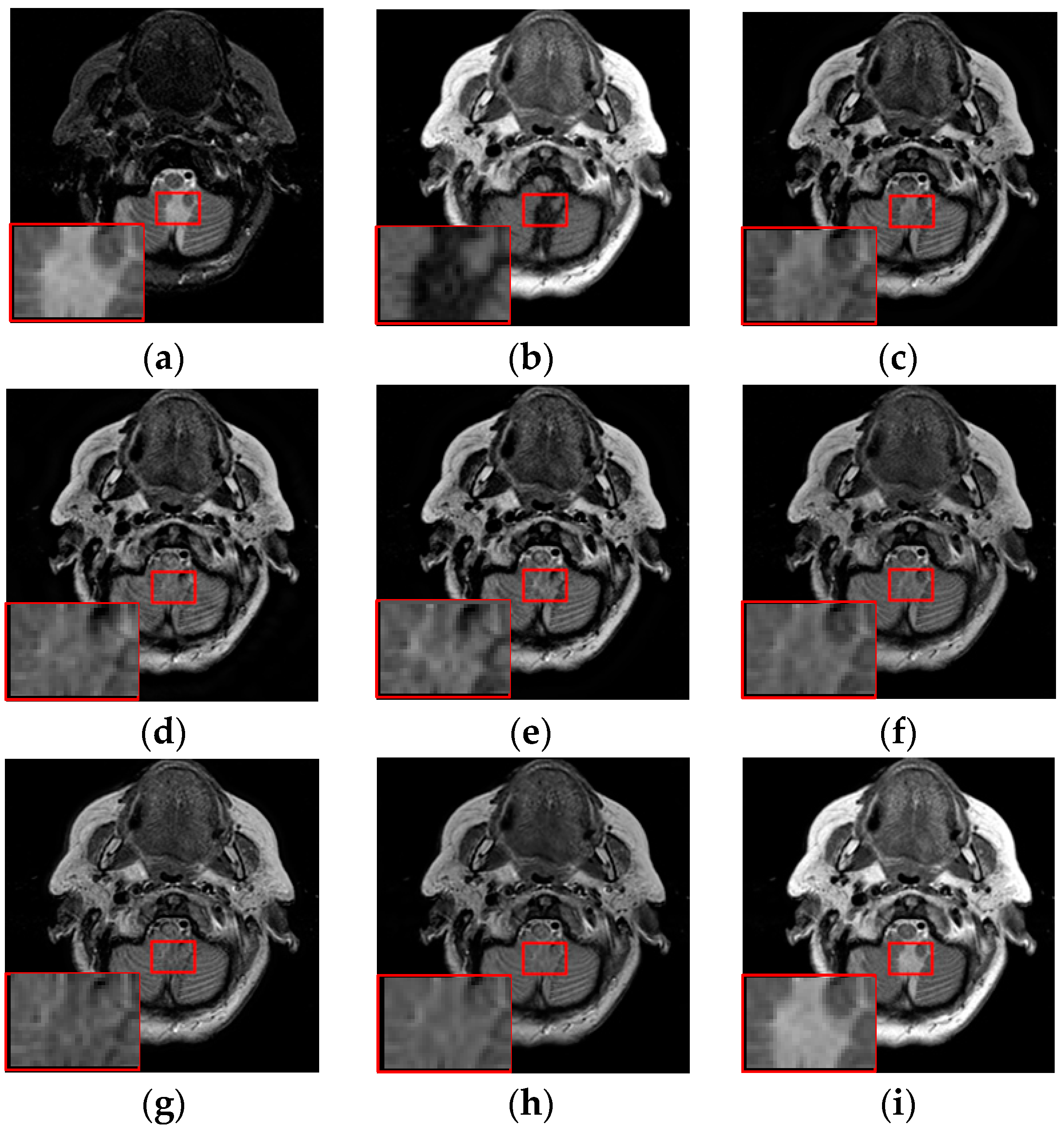
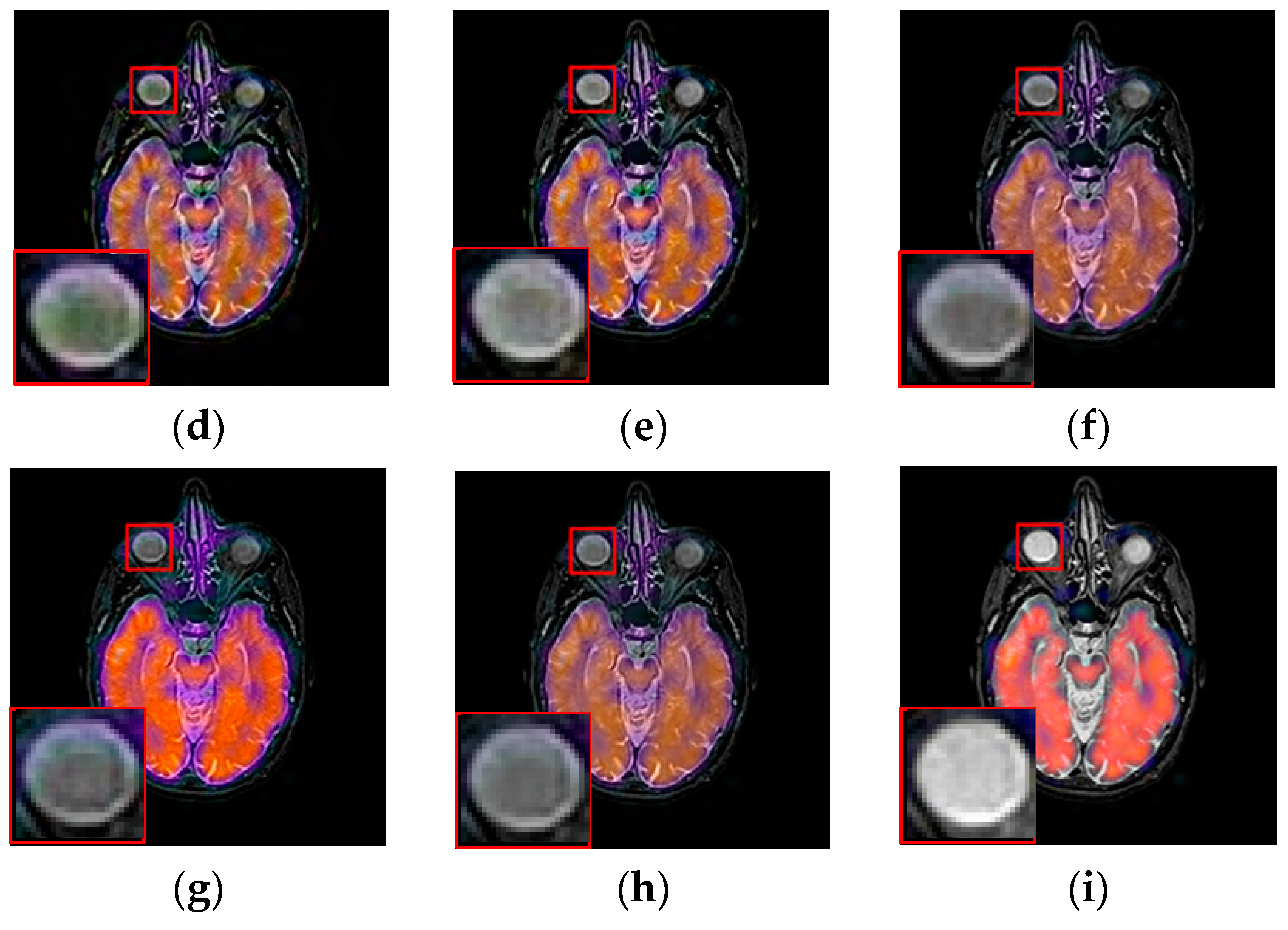
3.3. Fusion Results by Subjective Visual Effects Analysis
3.4. Fusion Results by Objective Evaluation
3.5. Computational Efficiency Analysis
3.6. Extension to Other Type Image Fusion Issues
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Du, J.; Li, W.; Lu, K.; Xiao, B. An overview of multi-modal medical image fusion. Neurocomputing 2016, 215, 3–20. [Google Scholar] [CrossRef]
- Li, H.; He, X.; Tao, D.; Tang, Y.; Wang, R. Joint medical image fusion, denoising and enhancement via discriminative low-rank sparse dictionaries learning. Pattern Recognit. 2018, 79, 130–146. [Google Scholar] [CrossRef]
- Li, S.; Yang, B.; Hu, J. Performance comparison of different multi-resolution transforms for image fusion. Inf. Fusion 2011, 12, 74–84. [Google Scholar] [CrossRef]
- Li, H.; Li, X.; Yu, Z.; Mao, C. Multifocus image fusion by combining with mixed-order structure tensors and multiscale neighborhood. Inf. Sci. 2016, 349, 25–49. [Google Scholar] [CrossRef]
- Goshtasby, A.; Nikolov, S. Image fusion: Advances in the state of the art. Inf. Fusion 2007, 8, 114–118. [Google Scholar] [CrossRef]
- Du, J.; Li, W.; Xiao, B.; Nawaz, Q. Medical image fusion by combining parallel features on multi-scale local extrema scheme. Knowl. Based Syst. 2016, 113, 4–12. [Google Scholar] [CrossRef]
- Jiang, Q.; Jin, X.; Lee, S.; Yao, S. A novel multi-focus image fusion method based on stationary wavelet transform and local features of fuzzy sets. IEEE Access 2017, 5, 20286–20302. [Google Scholar] [CrossRef]
- Lewis, J.; Callaghan, R.; Nikolov, S.; Bull, D.; Canagarajah, N. Pixel and region based image fusion with complex wavelets. Inf. Fusion 2007, 8, 119–130. [Google Scholar] [CrossRef]
- Nencini, F.; Garzelli, A.; Baronti, S.; Alparone, L. Remote sensing image fusion using the curvelet transform. Inf. Fusion 2007, 8, 143–156. [Google Scholar] [CrossRef]
- Do, M.N.; Vetterli, M. The Contourlet Transform: An Efficient Directional Multiresolution Image Representation. IEEE Trans. Image Process. 2005, 14, 2091–2106. [Google Scholar] [CrossRef]
- Li, X.; Li, H.; Yu, Z.; Kong, Y. Multifocus image fusion scheme based on the multiscale curvature in nonsubsampled contourlet transform domain. Opt. Eng. 2015, 54, 073115. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Palsson, F.; Sveinsson, J.R.; Ulfarsson, M.O. Multispectral and Hyperspectral Image Fusion Using a 3-D-Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 639–643. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- He, C.; Liu, Q.; Li, H.; Wang, H. Multimodal medical image fusion based on IHS and PCA. Procedia Eng. 2010, 7, 280–285. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Wang, M. Image fusion with morphological component analysis. Inf. Fusion 2014, 18, 107–118. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Blum, R.; Han, J.; Tao, D. Sparse representation based multi-sensor image fusion for multi-focus and multi-modality images: A review. Inf. Fusion 2018, 40, 57–75. [Google Scholar] [CrossRef]
- Shang, L.; Liu, S.; Zhou, Y.; Sun, Z. Modified sparse representation based image super-resolution reconstruction method. Neurocomputing 2017, 228, 37–52. [Google Scholar] [CrossRef]
- Gu, S.; Zuo, W.; Xie, Q.; Meng, D.; Feng, X.; Zhang, L. Convolutional Sparse Coding for Image Super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1823–1831. [Google Scholar]
- Liu, H.; Liu, Y.; Sun, F. Robust exemplar extraction using structured sparse coding. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1816–1821. [Google Scholar] [CrossRef]
- Xu, S.; Yang, X.; Jiang, S. A fast nonlocally centralized sparse representation algorithm for image denoising. Signal Process. 2017, 131, 99–112. [Google Scholar] [CrossRef]
- Mourabit, I.; Rhabi, M.; Hakim, A.; Laghrib, A.; Moreau, E. A new denoising model for multi-frame super-resolution image reconstruction. Signal Process. 2017, 132, 51–65. [Google Scholar] [CrossRef]
- Karanam, S.; Li, Y.; Radke, R. Person re-identification with discriminatively trained viewpoint invariant dictionaries. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4516–4524. [Google Scholar]
- An, L.; Chen, X.; Yang, S.; Bhanu, B. Sparse representation matching for person re-identification. Inf. Sci. 2016, 355, 74–89. [Google Scholar] [CrossRef] [Green Version]
- Bahrampour, S.; Nasrabadi, N.; Ray, A.; Jenkins, W. Multimodal task-driven dictionary learning for image classification. IEEE Trans. Image Process. 2015, 25, 24–38. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Yin, H.; Fang, L. Group-sparse representation with dictionary learning for medical image denoising and fusion. IEEE Trans. Biomed. Eng. 2012, 59, 3450–3459. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Sun, Y.; Huang, X.; Qi, G.; Zheng, M.; Zhu, Z. An Image Fusion Method Based on Sparse Representation and Sum Modified-Laplacian in NSCT Domain. Entropy 2018, 20, 522. [Google Scholar] [CrossRef]
- Wang, K.; Qi, G.; Zhu, Z.; Chai, Y. A Novel Geometric Dictionary Construction Approach for Sparse Representation Based Image Fusion. Entropy 2017, 19, 306. [Google Scholar] [CrossRef]
- Yang, B.; Li, S. Multifocus Image Fusion and Restoration with Sparse Representation. IEEE Trans. Instrum. Meas. 2010, 59, 884–892. [Google Scholar] [CrossRef]
- Yang, B.; Li, S. Pixel-level image fusion with simultaneous orthogonal matching pursuit. Inf. Fusion 2012, 13, 10–19. [Google Scholar] [CrossRef]
- Zhu, Z.; Chai, Y.; Yin, H.; Li, Y.; Liu, Z. A novel dictionary learning approach for multi-modality medical image fusion. Neurocomputing 2016, 214, 471–482. [Google Scholar] [CrossRef]
- Kim, M.; Han, D.K.; Ko, H. Joint patch clustering-based dictionary learning for multimodal image fusion. Inf. Fusion 2016, 27, 198–214. [Google Scholar] [CrossRef]
- Yin, H. Sparse representation with learned multiscale dictionary for image fusion. Neurocomputing 2015, 148, 600–610. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Z. Simultaneous image fusion and denoising with adaptive sparse representation. IET Image Process. 2015, 9, 347–357. [Google Scholar] [CrossRef]
- Qi, G.; Wang, J.; Zhang, Q.; Zeng, F.; Zhu, Z. An Integrated Dictionary-Learning Entropy-Based Medical Image Fusion Framework. Future Internet 2017, 9, 61. [Google Scholar] [CrossRef]
- Zhu, Z.; Yin, H.; Chai, Y.; Li, Y.; Qi, G. A novel multi-modality image fusion method based on image decomposition and sparse representation. Inf. Sci. 2018, 432, 516–529. [Google Scholar] [CrossRef]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the 27th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; pp. 40–44. [Google Scholar]
- Li, H.; Liu, X.; Yu, Z.; Zhang, Y. Performance improvement scheme of multifocus image fusion derived by difference images. Signal Process. 2016, 128, 474–493. [Google Scholar] [CrossRef]
- Zhao, H.; Shang, Z.; Tang, Y.; Fan, B. Multi-focus image fusion based on the neighbor distance. Pattern Recognit. 2013, 46, 1002–1011. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Li, H.; Manjunath, B.S.; Mitra, S.K. Multisensor image fusion using the wavelet transform. Graph. Models Image Process. 1995, 57, 235–345. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef]
- Xydeas, C.S.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Wang, Q.; Shen, Y.; Jin, J. Performance Evaluation of Image Fusion Techniques. In Image Fusion: Algorithms and Applications, 1st ed.; Stathaki, T., Ed.; Elsevier: London, UK, 2008; Volume 19, pp. 469–492. [Google Scholar]
- Zhao, J.; Laganiere, R.; Liu, Z. Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement. IJICIC 2007, 3, 1433–1447. [Google Scholar]
- Piella, G.; Heijmans, H. A New Quality Metric for Image Fusion. In Proceedings of the International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; pp. 173–176. [Google Scholar]
- Liu, Z.; Blasch, E.; Xue, Z.; Zhao, J.; Laganière, R.; Wu, W. Objective assessment of multiresolution image fusion algorithms for context enhancement in night vision: A comparative study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 94–108. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Qiu, H.; Yu, Z.; Zhang, Y. Infrared and visible image fusion scheme based on NSCT and low-level visual features. Infrared Phys. Technol. 2016, 76, 174–184. [Google Scholar] [CrossRef]
- Zhao, J.; Xia, J.; Maslov, K.I.; Nasiriavanaki, M.; Tsytsarev, V.; Demchenko, A.V.; Wang, L.V. Noninvasive photoacoustic computed tomography of mouse brain metabolism in vivo. NeuroImage 2013, 64, 257–266. [Google Scholar] [Green Version]
- Nasiriavanaki, M.; Xia, J.; Wan, H.; Bauer, A.Q.; Culver, J.P.; Wang, L.V. High-resolution photoacoustic tomography of resting-state functional connectivity in the mouse brain. Proc. Natl. Acad. Sci. USA 2013, 111, 21–26. [Google Scholar] [CrossRef] [PubMed] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Patches | 15625 | 3721 | 1600 | 841 | 529 |
| Summation | 15625 | 6691 | |||
| Images | Metric | Dctwt | Curvelet | NSCT | Liu-ASR | Kim | Zhu | Proposed |
|---|---|---|---|---|---|---|---|---|
| MRI/CT | MI | 3.3878 | 3.1522 | 3.5582 | 3.7833 | 3.6642 | 3.6680 | 4.9366 |
| QAB/F | 0.5134 | 0.4581 | 0.5635 | 0.5404 | 0.4743 | 0.4620 | 0.6254 | |
| QNICE | 0.8093 | 0.8086 | 0.8098 | 0.8105 | 0.8102 | 0.8102 | 0.8161 | |
| QP | 0.3094 | 0.2460 | 0.3948 | 0.4353 | 0.3168 | 0.3469 | 0.5421 | |
| QS | 0.7273 | 0.6881 | 0.7533 | 0.7720 | 0.7654 | 0.7631 | 0.7996 | |
| MR-T1/MR-T2 | MI | 2.9706 | 2.8620 | 3.0517 | 3.2929 | 3.1832 | 3.2811 | 4.7856 |
| QAB/F | 0.5395 | 0.4976 | 0.5613 | 0.5269 | 0.5008 | 0.4955 | 0.6566 | |
| QNICE | 0.8074 | 0.8071 | 0.8076 | 0.8082 | 0.8079 | 0.8082 | 0.8158 | |
| QP | 0.4513 | 0.3709 | 0.4693 | 0.4896 | 0.4089 | 0.4614 | 0.6735 | |
| QS | 0.7290 | 0.6888 | 0.7659 | 0.8105 | 0.8042 | 0.8045 | 0.8532 |
| Images | Metric | Dctwt | Curvelet | NSCT | Liu-ASR | Kim | Zhu | Proposed |
|---|---|---|---|---|---|---|---|---|
| MRI/SPECT | MI | 2.7104 | 2.6430 | 2.7347 | 2.8251 | 2.7289 | 2.8235 | 3.4636 |
| QAB/F | 0.6646 | 0.6522 | 0.6635 | 0.6382 | 0.5712 | 0.6170 | 0.6829 | |
| QNICE | 0.8063 | 0.8062 | 0.8064 | 0.8066 | 0.8063 | 0.8066 | 0.8087 | |
| QP | 0.4283 | 0.3854 | 0.4540 | 0.5042 | 0.3123 | 0.4122 | 0.5317 | |
| QS | 0.8890 | 0.8513 | 0.9097 | 0.9143 | 0.8950 | 0.9053 | 0.9186 | |
| MRI/PET | MI | 2.4927 | 2.4660 | 2.5622 | 2.7089 | 2.5934 | 2.7501 | 3.3282 |
| QAB/F | 0.5208 | 0.5076 | 0.5585 | 0.5801 | 0.4746 | 0.5260 | 0.6038 | |
| QNICE | 0.8055 | 0.8054 | 0.8057 | 0.8060 | 0.8057 | 0.8061 | 0.8077 | |
| QP | 0.3198 | 0.2875 | 0.3366 | 0.4383 | 0.2661 | 0.3641 | 0.3519 | |
| QS | 0.7642 | 0.7158 | 0.8296 | 0.8242 | 0.8017 | 0.8258 | 0.8582 |
| Curvelet | DCTWT | NSCT | Liu-ASR | Kim | Zhu | Proposed | |
|---|---|---|---|---|---|---|---|
| MRI/CT | 16.15 | 7.89 | 25.42 | 86.66 | 61.67 | 55.54 | 35.24 |
| MR-T1/MR-2 | 15.86 | 7.71 | 25.48 | 80.53 | 61.38 | 40.75 | 33.99 |
| MRI/SPECT | 39.27 | 14.11 | 75.76 | 173.29 | 55.20 | 226.69 | 88.84 |
| MRI/PET | 39.44 | 14.38 | 79.85 | 178.66 | 59.08 | 227.67 | 82.10 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, F.; Li, X.; Zhou, M.; Chen, Y.; Tan, H. A New Dictionary Construction Based Multimodal Medical Image Fusion Framework. Entropy 2019, 21, 267. https://doi.org/10.3390/e21030267
Zhou F, Li X, Zhou M, Chen Y, Tan H. A New Dictionary Construction Based Multimodal Medical Image Fusion Framework. Entropy. 2019; 21(3):267. https://doi.org/10.3390/e21030267
Chicago/Turabian StyleZhou, Fuqiang, Xiaosong Li, Mingxuan Zhou, Yuanze Chen, and Haishu Tan. 2019. "A New Dictionary Construction Based Multimodal Medical Image Fusion Framework" Entropy 21, no. 3: 267. https://doi.org/10.3390/e21030267
APA StyleZhou, F., Li, X., Zhou, M., Chen, Y., & Tan, H. (2019). A New Dictionary Construction Based Multimodal Medical Image Fusion Framework. Entropy, 21(3), 267. https://doi.org/10.3390/e21030267