1. Introduction
In recent years, massive data has attracted much attention in various realistic scenarios. Actually, there exist many challenges for data processing such as distributed data acquisition, huge-scale data storage and transmission, as well as correlation or causality representation [
1,
2,
3,
4,
5]. Facing these obstacles, it is a promising way to make good use of information theory and statistics to deal with mass information. For example, a method based on Max Entropy in Metric Space (MEMS) is utilized for local features extraction and mechanical system analysis [
6]; as an information measure different from Shannon entropy, Voronoi entropy is discussed to characterize the random 2D patterns [
7]; Category theory, which can characterize the Kolmogorov–Sinai and Shannon entropy as the unique functors, is used in autonomous and networked dynamical systems [
8].
To some degree, probabilistic events attract different interests according to their probability. For example, considering that small probability events hidden in massive data contain more semantic importance [
9,
10,
11,
12,
13], people usually pay more attention to the rare events (rather than the common events) and design the corresponding strategies of their information representation and processing in many applications including outliers detection in the Internet of Things (IoT), smart cities and autonomous driving [
14,
15,
16,
17,
18,
19,
20,
21,
22]. Therefore, the probabilistic events processing has special values in the information technology based on semantics analysis of message importance.
In order to characterize the importance of probabilistic events, a new information measure named MIM is presented to generalize Shannon information theory [
23,
24,
25]. Here, we shall investigate the information processing including compression (or storage) and transmission based on MIM to bring some new viewpoints in the information theory. Now, we first give a short review on MIM.
1.1. Review of Message Importance Measure
Essentially, the message importance measure (MIM) is proposed to focus on the probabilistic events importance [
23]. In particular, the core idea of this information measure is that the weights of importance are allocated to different events according to the corresponding events’ probability. In this regard, as an information measure, MIM may provide an applicable criterion to characterize the message importance from the viewpoint of inherent property of events without the human subjective factors. For convenience of calculation, an exponential expression of MIM is defined as follows.
Definition 1. For a discrete distribution = , , …, , the exponential expression of message importance measure (MIM) is given bywhere the adjustable parameter ϖ is nonnegative and is viewed as the self-scoring value of event i to measure its message importance. Actually, from the perspective of generalized Fadeev’s postulates, the MIM is viewed as a rational information measure similar to Shannon entropy and Renyi entropy which are respectively defined by
where the condition of variable
X is the same as that described in Definition 1. In particular, a postulate for the MIM weaker than that for Shannon entropy and Renyi entropy is given by
while
is satisfied for Shannon entropy and Renyi entropy [
26], where
P and
Q are two independent random distributions and
denotes a kind of information measure.
Moreover, the crucial operator of MIM to handle probability elements is exponential function while the corresponding operators of Shannon and Renyi entropy are logarithmic function and polynomial function respectively. In this case, MIM can be viewed as a map for the assignments of events’ importance weights or the achievement for the self-scoring values of events different from conventional information measures.
As far as the application of MIM is concerned, it may be a better method by using this information measure to detect unbalanced events in signal processing. Ref. [
27] has investigated the minor probability event detection by combining MIM and Bayes detection. Moreover, it is worth noting that the physical meaning of the components of MIM corresponds to the normalized optimal data recommendation distribution, which makes a trade-off between the users’ preference and system revenue [
28]. In this respect, MIM plays a fundamental role in the recommendation system (a popular applications of big data) from the theoretic viewpoint. Therefore, MIM does not come from the imagination directly, whereas it is a meaningful information measure originated from the practical scenario.
1.2. The Importance Coefficient in MIM
In general, the parameter viewed as the importance coefficient has a great impact on the MIM. Actually, different parameter can lead to different properties and performances for this information measure. In particular, to measure a distribution , there are three kinds of work regions of MIM which can be classified by the parameters, whose details are discussed as follows.
- (i)
If the parameter satisfies , the convexity of MIM is similar to Shannon entropy and Renyi entropy. Actually, these three information measures all have maximum value properties and allocate weights for probability elements of the distribution . It is notable that the MIM in this work region focuses on the typical sets rather than atypical sets, which implies that the uniform distribution reaches the maximum value. In brief, the MIM in this work region can be regarded as the same class of message measure as Shannon entropy and Renyi entropy to deal with the problems of information theory.
- (ii)
If we have
, the small probability elements will be the dominant factor for MIM to measure a distribution. That is, the small probability events can be highlighted more in this work region of MIM than those in the first one. Moreover, in this work region, MIM can pay more attention to atypical sets, which can be viewed as a magnifier for rare events. In fact, this property corresponds to some common scenarios where anomalies catch more eyes such as anomalous detection and alarm. In this case, some problems (including communication and probabilistic events processing) can be rehandled from the perspective of rare events importance. Particularly, the compression encoding and maximum entropy rate transmission are proposed based on the non-parametric MIM (namely NMIM) [
24]; in addition, the distribution goodness-of-fit approach is also presented by use of the differential MIM (namely DMIM) [
29].
- (iii)
If the MIM has the parameter , the large probability elements will be the main part contributing to the value of this information measure. In other words, the normal events attract more attention in this work region of MIM than rare events. In practice, this can be used in many applications where regular events are popular such as filter systems and data cleaning.
As a matter of fact, by selecting the parameter properly, we can exploit the MIM to solve several problems in different scenarios. The importance coefficient facilitates more flexibility of MIM in applications beyond Shannon entropy and Renyi entropy.
To focus on a concrete object, in this paper, we mainly investigate the first work region of MIM (namely ) and intend to dig out some novelties related to this metric for information processing.
1.3. Similarities and Differences between Shannon Entropy and MIM
In fact, when the parameter satisfies , MIM is similar to Shannon entropy in regard to the expression and properties. The exponential operator of MIM is a substitute for the logarithm operator of Shannon entropy. As a kind of tool based on probability distributions, the MIM with parameter has the same concavity and monotonicity as Shannon entropy, which can characterize the information otherness for different variables.
By resorting to the exponential operator of MIM, the weights for small probability elements are amplified more in some degree than those for large probability ones, which is considered as message importance allocation based on the self-scoring values. In this regard, the MIM may add fresh factors to the information processing, which takes into account the effects of probabilistic events’ importance from an objective viewpoint.
In the conventional Shannon information theory, data transmission and compression both can be viewed as the information transfer process from the variable
X to
Y. The capacity of information transmission is achieved by maximizing the mutual information between the
X and
Y. Actually, there exists distortion for probabilistic events during an information transfer process, which denotes the difference between the source and its corresponding reconstruction. Due to this fact, it is possible to compress data based on the allowable information loss in a certain extent [
30,
31,
32]. In Shannon information theory, rate-distortion theory is investigated for lossy data compression, whose essence is mutual information minimization under the constraint of a certain distortion. However, in some cases involved with distortion, small probability events containing more message importance require higher reliability than those with large probability. In this sense, another aspect of information distortion may be essential, in which message importance is considered as a reasonable metric. Particularly, information transfer process is characterized by the MIM (rather than the entropy) with controlling the distortion, which can be viewed as a new kind of information compression, compared to the conventional scheme compressing redundancy to save resources. In fact, some information measures with respect to message importance have been investigated to extend the range of Shannon information theory [
33,
34,
35,
36,
37]. In this regard, it is worthwhile exploring the information processing in the sense of MIM. Furthermore, it is also promising to investigate the Shannon mutual information constrained by the MIM in an information transfer process which may become a novel system invariant.
In addition, similar to Shannon conditional entropy, a conditional message importance measure for two distributions is proposed to process conditional probability.
Definition 2. For the two discrete probability = , , …, and = , , …, , the conditional message importance measure (CMIM) is given bywhere denotes the conditional probability between and . The component is similar to self-scoring value. Therefore, the CMIM can be considered as a system invariant which indicates the average total self-scoring value for an information transfer process. Actually, the MIM is a metric with different mathematical and physical meaning from Shannon entropy and Renyi entropy, which provides its own perspective to process probabilistic events. However, due to the similarity between the MIM and Shannon entropy, they may have analogous performance in some aspects. To this end, the information processing based on the MIM is discussed in this paper.
1.4. Motivation and Contributions
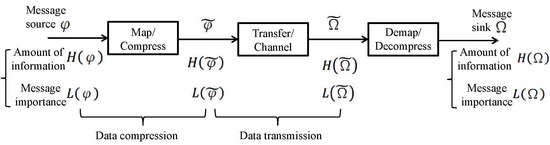
The purpose of this paper is to characterize the probabilistic events processing including compression and transmission by means of MIM. Particularly, in terms of the information processing system model shown in
Figure 1, the message source
(regarded as a random variable whose support set corresponds to the set of events’ types) can be measured by the amount of information
and the message importance
according to the probability distribution. Then, the information transfer process whose details are presented in
Section 2 can be characterized based on these two metrics. Different from the mathematically probabilistic characterization of traditional telecommunication system, this paper mainly discusses the information processing from the perspectives of message importance. In this regard, the information importance harvest in a transmission is characterized by the proposed message importance loss capacity. Moreover, the upper bound of information compression based on the MIM is described by the message importance distortion function. In addition, we also investigate the trade-off between bitrate transmission and message importance loss to bring some inspiration to the conventional information theory.
1.5. Organization
The rest of this paper is discussed as follows. In
Section 2, a system model involved with message importance is constructed to help analyze the data compression and transmission in big data. In
Section 3, we propose a kind of message transfer capacity to investigate the message importance loss in the transmission. In
Section 4, message importance distortion function is introduced and its properties are also presented to give some details. In
Section 5, we discuss the bitrate transmission constrained by message importance to widen the horizon for the Shannon theory. In
Section 6, some numerical results are presented to validate propositions and the analysis in theory. Finally, we conclude this paper in
Section 7. Additionally, the fundamental notations in this paper are summarized in
Table 1.
2. System Model with Message Importance
Considering an information processing system model shown in
Figure 1, the information transfer process is discussed as follows. At first, a message source
follows a distribution
whose support set is
corresponding to the events types. Then, the message
is encoded or compressed into the variable
following the distribution
whose alphabet is
. After the information transfer process denoted by matrix
, the received message
originating from
is observed as a random variable, where the distribution of
is
whose alphabet is
. Finally, the receiver recovers the original message
by decoding
where
denotes the decoding function and
is the recovered message with the alphabet
.
From the viewpoint of generalized information theory, a two-layer framework is considered to understand this model, where the first layer is based on the amount of information characterized by Shannon entropy denoted by , while the second layer reposes on message importance measure of events denoted by . Due to the fact that the former is discussed pretty entirely, we mainly investigate the latter in the paper.
Considering the source-channel separation theorem [
38], the above information processing model consists of two problems, namely data compression and data transmission. On one hand, the
data compression of the system can be achieved by using classical source coding strategies to reduce more redundancy, in which the information loss is described by
under the information transfer matrix
. Similarly, from the perspective of message importance, the data can be further compressed by discarding worthless messages, where the message importance loss can be characterized by
. On the other hand, the
data transmission is discussed to obtain the upper bound of the mutual information
, namely the information capacity. In a similar way,
means the income of message importance in the transmission.
In essence, it is apparent that the data compression and transmission are both considered as an information transfer processes , and they can be characterized by the difference between and . In order to facilitate the analysis of the above model, the message importance loss is introduced as follows.
Definition 3. For two discrete probability = , , …, and = , , …, , the message importance loss based on MIM and CMIM is given bywhere and are given by the Definitions 1 and 2. In fact, according to the intrinsic relationship between
and
, it is readily seen that
where
.
Proof. Considering a function ( and ), it is easy to have , which implies if , the function is concave.
In the light of Jensen’s inequality, if
is satisfied, it is not difficult to see
□
3. Message Importance Loss in Transmission
In this section, we will introduce the CMIM to characterize the information transfer processing. To do so, we define a kind of message transfer capacity measured by the CMIM as follows.
Definition 4. Assume that there exists an information transfer process aswhere the denotes a probability distribution matrix describing the information transfer from the variable X to Y. We define the message importance loss capacity (MILC) aswhere , , , is defined by Equation (4), and . In order to have an insight into the applications of MILC, some specific information transfer scenarios are discussed as follows.
3.1. Binary Symmetric Matrix
Consider the binary symmetric information transfer matrix, where the original variables are complemented with the transfer probability which can be seen in the following proposition.
Proposition 1. Assume that there exists an information transfer process , where the information transfer matrix iswhich indicates that X and Y both follow binary distributions. In that case, we havewhere () and . Proof of Proposition 1. Assume that the distribution of variable
X is a binary distribution
. According to Equation (
10) and Bayes’ theorem (namely,
), it is not difficult to see that
Furthermore, in accordance with Equations (
4) and (
9), we have
where
(
). Then, it is readily seen that
In the light of the positivity for in and the negativity in (if ), it is apparent that is the only solution for . That is, if , the extreme value is indeed the maximum value of when . Similarly, if , the solution also results in the same conclusion. □
Remark 1. According to Proposition 1, on one hand, when , that is, the information transfer process is just random, we will gain the lower bound of the MILC namely . On the other hand, when , namely there is a certain information transfer process, we will have the maximum MILC. As for the distribution selection for the variable X, the uniform distribution is preferred to gain the capacity.
3.2. Binary Erasure Matrix
The binary erasure information transfer matrix is similar to the binary symmetric one; however, in the former, a part of information is lost rather than corrupted. The MILC of this kind of information transfer matrix is discussed as follows.
Proposition 2. Consider an information transfer process , in which the information transfer matrix is described aswhich indicates that X follows the binary distribution and Y follows the 3-ary distribution. Then, we havewhere and . Proof of Proposition 2. Assume the distribution of variable
X is
. Furthermore, according to the binary erasure matrix and Bayes theorem, we have that the transmission matrix conditioned by the variable
Y as follows:
Then, it is not difficult to have
Furthermore, it is readily seen that
where
. Moreover, we have the solution
leads to
and the corresponding second derivative is
which results from the condition
.
Therefore, it is readily seen that, in the case , the capacity reaches the maximum value. □
Remark 2. Proposition 2 indicates that, in the case , the lower bound of the capacity is obtained, that is . However, if a certain information transfer process is satisfied (namely ), we will have the maximum MILC. Similar to Proposition 1, the uniform distribution is selected to reach the capacity in practice.
3.3. Strongly Symmetric Backward Matrix
As for a strongly symmetric backward matrix, it is viewed as a special example of information transmission. The discussion for the message transfer capacity in this case is similar to that in the symmetric matrix, whose details are given as follows.
Proposition 3. For an information transmission from the source X to the sink Y, assume that there exists a strongly symmetric backward matrix as follows:which indicates that X and Y both obey K-ary distribution. We havewhere , and . Proof of Proposition 3. For given
K-ary variables
X and
Y whose distribution are
and
respectively, we can use the strongly symmetric backward matrix to obtain the relationship between the two variables as follows:
which implies
is a one-to-one onto function for
.
In accordance with Definition 2, it is easy to see that
Moreover, by virtue of the definition of MILC in Equation (
9), it is readily seen that
where
.
Then, by using Lagrange multiplier method, we have
By setting and , it can be readily verified that the extreme value of is achieved by the uniform distribution as a solution, that is . In the case that , we have with respect to , which implies that the extreme value of is the maximum value.
In addition, according to the Equation (
23), the uniform distribution of variable
X is resulted from the uniform distribution for variable
Y.
Therefore, by substituting the uniform distribution for
into Equation (
25), we will obtain the capacity
. □
Furthermore, in light of Equation (
22), we have
By setting
, it is apparent that
reaches the extreme value in the case that
. Additionally, when the parameter
satisfies
, we also have the second derivative of the
as follows:
which indicates that the convex
reaches the minimum value 0 in the case
.
Remark 3. According to Proposition 3, when , namely, the channel is just random, we gain the lower bound of the capacity namely . On the contrary, when (that is, there is a certain channel), we will have the maximum capacity.
4. Distortion of Message Importance Transfer
In this section, we will focus on the information transfer distortion, a common problem of information processing. In a real information system, there exists inevitable information distortion caused by noises or other disturbances, though the devices and hardware of telecommunication systems are updating and developing. Fortunately, there are still some bonuses from allowable distortion in some scenarios. For example, in conventional information theory, rate distortion is exploited to obtain source compression such as predictive encoding and hybrid encoding, which can save a lot of hardware resources and communication traffic [
39].
Similar to the rate distortion theory for Shannon entropy [
38], a kind of information distortion function based on MIM and CMIM is defined to characterize the effect of distortion on the message importance loss. In particular, there are some details of discussion as follows.
Definition 5. Assume that there exists an information transfer process from the variable X to Y, where the denotes a transfer matrix (distributions of X and Y are denoted by and respectively). For a given distortion function () and an allowable distortion D, the message importance distortion function is defined asin which , is defined by Equation (4), and denotes the allowable information transfer matrix set wherewhich is the average distortion. In this model, the information source X is given and our goal is to select an adaptive to achieve the minimum allowable message importance loss under the distortion constraint. This provides a new theoretical guidance for information source compression from the perspective of message importance.
In contrast to the rate distortion of Shannon information theory, this new information distortion function just depends on the message importance loss rather than entropy loss to choose an appropriate information compression matrix. In practice, there are some similarities and differences between the rate distortion theory and the message importance distortion in terms of the source compression. On one hand, both two information distortion encodings can be regarded as special information transfer processes just with different optimization objectives. On the other hand, the new distortion theory tries to keep the rare events as high as possible, while the conventional rate distortion focuses on the amount of information itself. To some degree, by reducing more redundant common information, the new source compression strategy based on rare events (viewed as message importance) may save more computing and storage resources in big data.
4.1. Properties of Message Importance Distortion Function
In this subsection, we shall discuss some fundamental properties of rate distortion function based on message importance in details.
4.1.1. Domain of Distortion
Here, we investigate the domain of allowable distortion, namely , and the corresponding message importance distortion function values as follows.
(i) The lower bound
: Due to the fact
, it is easy to obtain the non-negative average distortion, namely
. Considering
, we readily have the minimum allowable distortion, that is
which implies the distortionless case, namely
Y is the same as
X.
In addition, when the lower bound
(namely the distortionless case) is satisfied, it is readily seen that
and according to the Equation (
29) the message importance distortion function is
where
and
.
(ii) The upper bound
: When the allowable distortion satisfies
, it is apparent that the variables
X and
Y are independent, that is,
. Furthermore, it is not difficult to see that
which indicates that when the distribution of variable
Y follows
and
(
), we have the upper bound
Additionally, on account of the independent
X and
Y, namely
, it is readily seen that
4.1.2. The Convexity Property
For two allowable distortions
and
, whose optimal allowable information transfer matrixes are
and
respectively, we have
where
and
.
4.1.3. The Monotonically Decreasing Property
For two given allowable distortions and , if is satisfied, we have , where .
Proof. Considering that
, we have
where
. On account of the Equation (
36) and the convexity property mentioned in Equation (
37), it is not difficult to see that
where
. □
4.1.4. The Equivalent Expression
For an information transfer process
, if we have a given distortion function
, an allowable distortion
D and a average distortion
defined in Equation (
30), the message importance distortion function defined in Equation (
29) can be rewritten as
where
and
are defined by the Equations (1) and (
4), as well as
.
Proof. For a given allowable distortion D, if there exists an allowable distortion () and the corresponding optimal information transfer matrix leads to , we will have which contradicts the monotonically decreasing property. □
4.2. Analysis for Message Importance Distortion Function
In this subsection, we shall investigate the computation of message importance distortion function, which has a great impact on the probabilistic events analysis in practice. Actually, the definition of message importance distortion function in Equation (
29) can be regarded as a special function, which is the minimization of the message importance loss with the symbol error less than or equal to the allowable distortion
D. In particular, Definition 5 can also be expressed as the following optimization:
where
and
are MIM and CMIM defined in Equations (1) and (
4), as well as
.
To take a computable optimization problem as an example, we consider Hamming distortion as the distortion function
, namely
which means
and
(
). In order to reveal some intrinsic meanings of
, we investigate an information transfer of Bernoulli source as follows.
Proposition 4. For a Bernoulli(p) source denoted by a variable X and an information transfer process with Hamming distortion, the message importance distortion function is given byand the corresponding information transfer matrix iswhere and . 5. Bitrate Transmission Constrained by Message Importance
We investigate the information capacity in the case of a limited message importance loss in this section. The objective is to achieve the maximum transmission bitrate under the constraint of a certain message importance loss . The maximum transmission bitrate is one of system invariants in a transmission process, which provides a upper bound of amount of information obtained by the receiver.
In an information transmission process, the information capacity is the mutual information between the encoded signal and the received signal with the dimension bit/symbol. In a real transmission, there always exists an allowable distortion between the sending sequence X and the received sequence Y, while the maximum allowable message importance loss is required to avoid too much distortion of important events. From this perspective, message importance loss is considered to be another constraint for the information transmission capacity beyond the information distortion. Therefore, this might play a crucial role in the design of transmission in information processing systems.
In particular, we characterize the maximizing mutual information constrained by a controlled message importance loss as follows:
where
,
,
and
are MIM and CMIM defined in Equations (1) and (
4), as well as
.
Actually, the bitrate transmission with a message importance loss constraint has a special solution for a certain scenario. In order to give a specific example, we investigate the optimization problem in the Bernoulli(p) source with a symmetric or erasure transfer matrix as follows.
5.1. Binary Symmetric Matrix
Proposition 5. For a Bernoulli(p) source X whose distribution is () and an information transfer process with transfer matrixwe have the solution for defined in Equation (44) as follows:where is the solution of ( and mentioned in the optimization problem ), whose approximate value isin which the parameter Θ is given byand denotes the operator for Shannon entropy, that is , () and . Proof of Proposition 5. Considering the Bernoulli(
p) source
X following
and the binary symmetric matrix, it is not difficult to gain
where
,
and
.
Moreover, define the Lagrange function as
where
,
and
. It is not difficult to have the partial derivative of
as follows:
where
is given by the Equation (
14) and
By virtue of the monotonic increasing function for , it is easy to see the nonnegativity of is equal to in the case . Moreover, due to the nonnegative in which is mentioned in the proof of Proposition 1, it is readily seen that is satisfied under the condition .
Thus, the optimal solution
is the maximal available
p (
) as follows:
where
is the solution of
, and
is the MILC mentioned in Equation (
11).
By using Taylor series expansion, the equation
can be expressed approximately as follows:
whose solution is the approximate
as the Equation (
47).
Therefore, by substituting the
into Equation (
49), we have Equation (
46). □
Remark 4. Proposition 5 gives the maximum transmission bitrate under the constraint of message importance loss. Particularly, there are growth regions and smooth regions for the maximum transmission bitrate in the receiver with respect to message importance loss ϵ. When the message importance loss ϵ is constrained in a little range, the real bitrate is less than the Shannon information capacity, which is involved with the entropy of the symmetric matrix parameter .
5.2. Binary Erasure Matrix
Proposition 6. Assume that there is a Bernoulli(p) source X following distribution () and an information transfer process with the binary erasure matrixwhere . In this case, the solution for described in Equation (44) iswhere is the solution of , whose approximate value isand , and . Proof of Proposition 6. In the binary erasure matrix, considering the Bernoulli(
p) source
X whose distribution is
, it is readily seen that
where
denotes the Shannon entropy operator, namely
.
Moreover, according to the Definitions 1 and 2, it is easy to see that
where
.
Similar to the proof of the Proposition 5 and considering the monotonically increasing
and
in
, it is not difficult to see that the optimal solution
is the maximal available
p in the case
, which is given by
where
is the solution of
, and the upper bound
is gained in Equation (
16).
By resorting to Taylor series expansion, the approximate equation for
is given by
from which the approximate solution
in Equation (
56) is obtained.
Therefore, Equation (
55) is obtained by substituting the
into the Equation (
57). □
Remark 5. From Proposition 6, there are two regions for the maximum transmission bitrate with respect to message importance loss. The one depends on the message importance loss threshold ϵ. The other is just related to the erasure matrix parameter .
Note that single-letter models are discussed to show some theoretical results for information transfer under the constraint of massage importance loss, which may be used in some special potential applications such as maritime international signal or switch signal processing. As a matter of fact, in practice, it is preferred to operate multi-letters models which can be applied to more scenarios such as the multimedia communication, cooperative communications and multiple access, etc. As for these complicated cases which may be different from conventional Shannon information theory, we shall consider it in the near future.
6. Numerical Results
This section shall provide numerical results to validate the theoretical results in this paper.
6.1. The Message Importance Loss Capacity
First of all, we give some numerical simulation with respect to the MILC in different information transmission cases. In
Figure 2, it is apparent to see that if the Bernoulli source follows the uniform distribution, namely
, the message importance loss will reach the maximum in the cases of different matrix parameter
. That is, the numerical results of MILC are obtained as
in the case of parameter
and
, which corresponds to Proposition 1. Moreover, we also know that if
, namely the random transfer matrix is satisfied, the MILC reaches the lower bound that is
. In contrast, if the parameter
satisfies
, the upper bound of MILC will be gained such as
in the case
.
Figure 3 shows that, in the binary erasure matrix, the MILC is reached under the same condition as that in the binary symmetric matrix, namely
. For example the numerical results of MILC with
are
in the cases
. However, if
, the lower bound of MILC (
) is obtained in the erasure transfer matrix, different from the symmetric case.
From
Figure 4, it is not difficult to see that the certain transfer matrix (namely
) leads to upper bound of MILC. For example, when the number of source symbols satisfies
, the numerical results of MILC with
are
. In addition, the lower bound of MILC is reached in the case that
.
6.2. Message Importance Distortion
We focus on the distortion of message importance transfer and give some simulations in this subsection. From
Figure 5, it is illustrated that the message importance distortion function
is monotonically non-increasing with respect to the distortion
D, which can validate some properties mentioned in
Section 4.1. Moreover, the maximum
is obtained in the case
. Taking the Bernoulli(
p) source as an example, the numerical results of
with
are
and the corresponding probability satisfies
. Note that the turning point of
is gained when the probability
p equals to the distortion
D, which conforms to Proposition 4.
6.3. Bitrate Transmission with Message Importance Loss
Figure 6 shows the allowable maximum bitrate (characterized by mutual information) constrained by a message importance loss
in a Bernoulli(
p) source case. It is worth noting that there are two regions for the mutual information in the both transfer matrixes. In the first region, the mutual information is monotonically increasing with respect to the
; however, in the second region, the mutual information is stable, namely the information transmission capacity is obtained. As for the numerical results, the turning points are obtained at
and the maximum mutual information values are
in the binary symmetric matrix with the corresponding parameter
, while the turning points of erasure matrix are at
in the case that
with the maximum mutual information values
. Consequently, Propositions 5 and 6 are validated from the numerical results.
6.4. Experimental Simulations
In this subsection, we take the binary stochastic process (in which the random variable follows Bernoulli distribution) as an example to validate theoretical results. In particular, the Bernoulli(
p) source
X (whose distribution is denoted by
where
) with the symmetric or erasure matrix (described by Equations (
10) and (
15)) is considered to reveal some properties of message importance loss capacity (in
Section 3), message importance distortion function (in
Section 4) as well as bitrate transmission constrained by message importance (in
Section 5).
From
Figure 7, it is seen that the uniform information source
X (that is
) leads to the maximum message importance loss (namely MILC) in both cases of symmetric matrix and erasure matrix, which implies Propositions 1 and 2. Moreover, with the increase of number of samples, the performance of massage importance loss tends to smooth. In addition, the MILC in symmetric transfer matrix is larger than that in the erasure one when the matrix parameters
and
are the same.
As for the distortion of message importance transfer, we investigate the message importance loss based on different transfer matrices, which is shown in
Figure 8 where
is described as Equation (
43),
,
,
,
,
,
D is the allowable distortion and
p is the probability element of Bernoulli(
p) source. From
Figure 8, it is illustrated that, when the
is selected as the transfer matrix, the massage importance loss reaches the minimum, which corresponds to Proposition 4. In addition, if the transfer matrix is not certain (existing distortion), message importance loss is decreasing with the increase of allowable distortion.
Considering the transmission with a message importance loss constraint,
Figure 9 shows that, when the
(given by Equation (
52)) and
(given by Equation (
59)) are selected as the probability elements for the Bernoulli(
p) source in the symmetric matrix and erasure matrix respectively, the corresponding mutual information values are larger than those based on other probability (such as
and
). In addition, it is not difficult to see that, when the parameter
is equal to
, the mutual information (constrained by a message importance loss) in symmetric transfer matrix is larger than that in the erasure one.
7. Conclusions
In this paper, we investigated the information processing from the perspective of an information measure i.e., MIM. Actually, with the help of parameter , the MIM has more flexibility and can be used widely. Here, we just focused on the MIM with which not only has properties of self-scoring values for probabilistic events but also has similarities with Shannon entropy in information compression and transmission. In particular, based on a system model with message importance processing, a message importance loss was presented. This measure can characterize the information distinction before and after a message transfer process. Furthermore, we have proposed the message importance loss capacity which can provide an upper bound for the message importance harvest in the information transmission. Moreover, the message importance distortion function, which is to select an information transfer matrix to minimize the message importance loss, was discussed to characterize the performance of information lossy compression from the viewpoint of message importance of events. In addition, we exploited the message importance loss to constrain the bitrate transmission so that the combined factors of message importance and amount of information are considered to guide an information transmission. To give the validation for theoretical analyses, some numerical results and experimental simulations were also presented in details. As the next step research, we are looking forward to exploiting real data to design some applicable strategies for information processing based on the MIM, as well as investigating the performance of multivariate systems in the sense of MIM.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}