Deep Reinforcement Learning-Based Traffic Signal Control Using High-Resolution Event-Based Data

Abstract
:1. Introduction
1.1. Reinforcement Learning-Based Traffic Signal Control
1.2. Contribution and Organization of This Paper
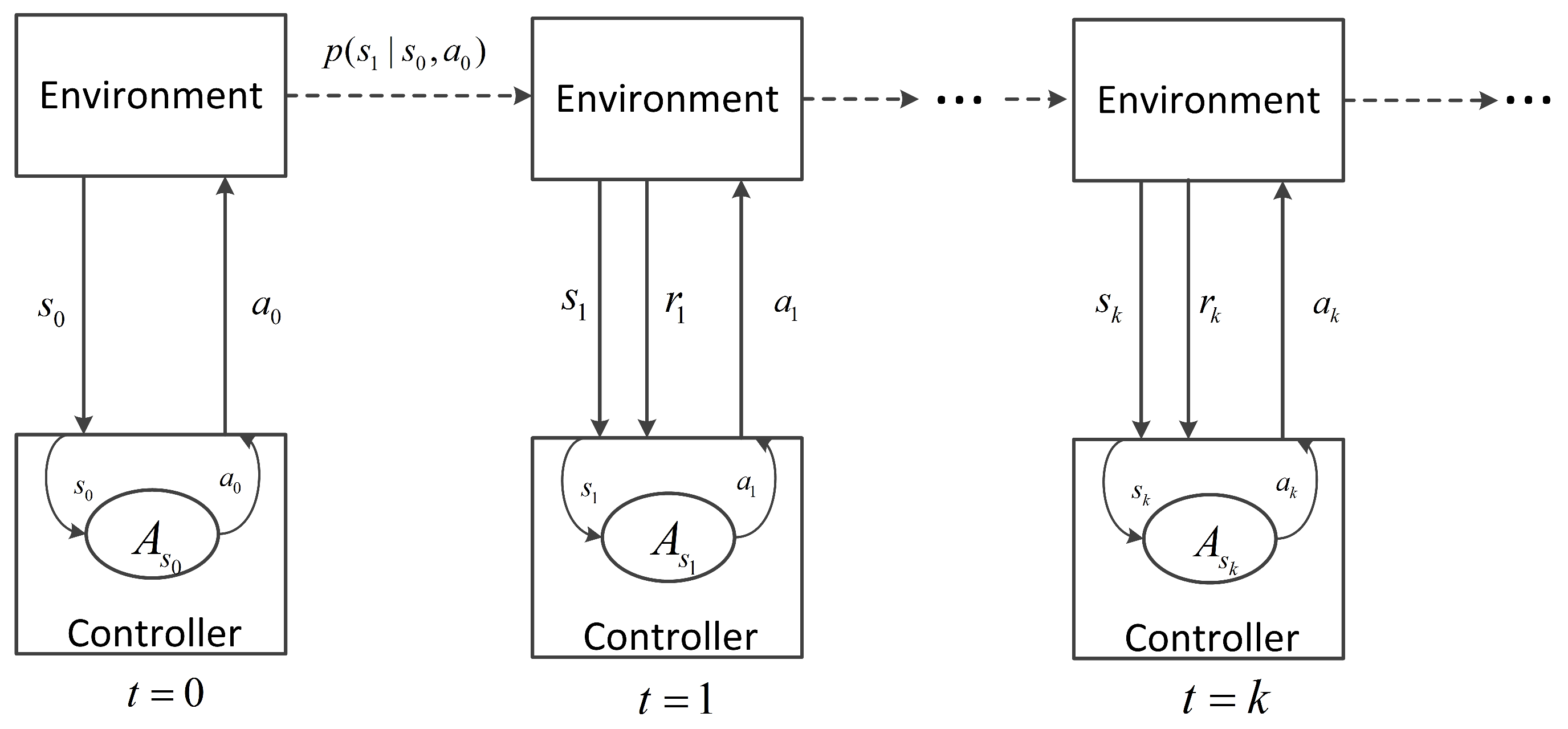
2. Traffic Signal Control as a Markov Decision Process
- S: the state space, which consists of all possible traffic states, ;
- A: the action space, ;
- : , the reward function;
- : , the transition probability function.
3. Definitions of Key RL Elements for Traffic Signal Control
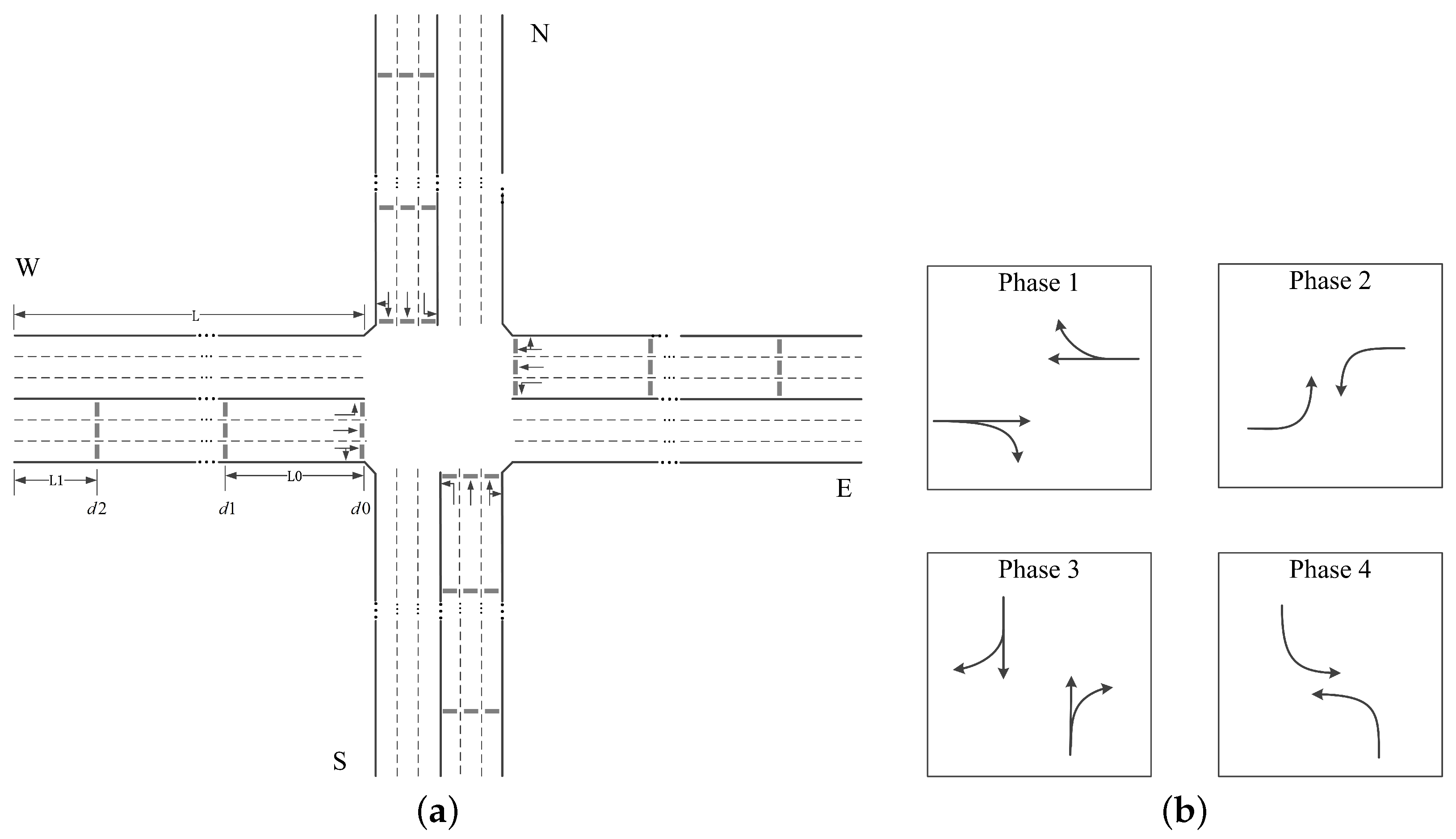
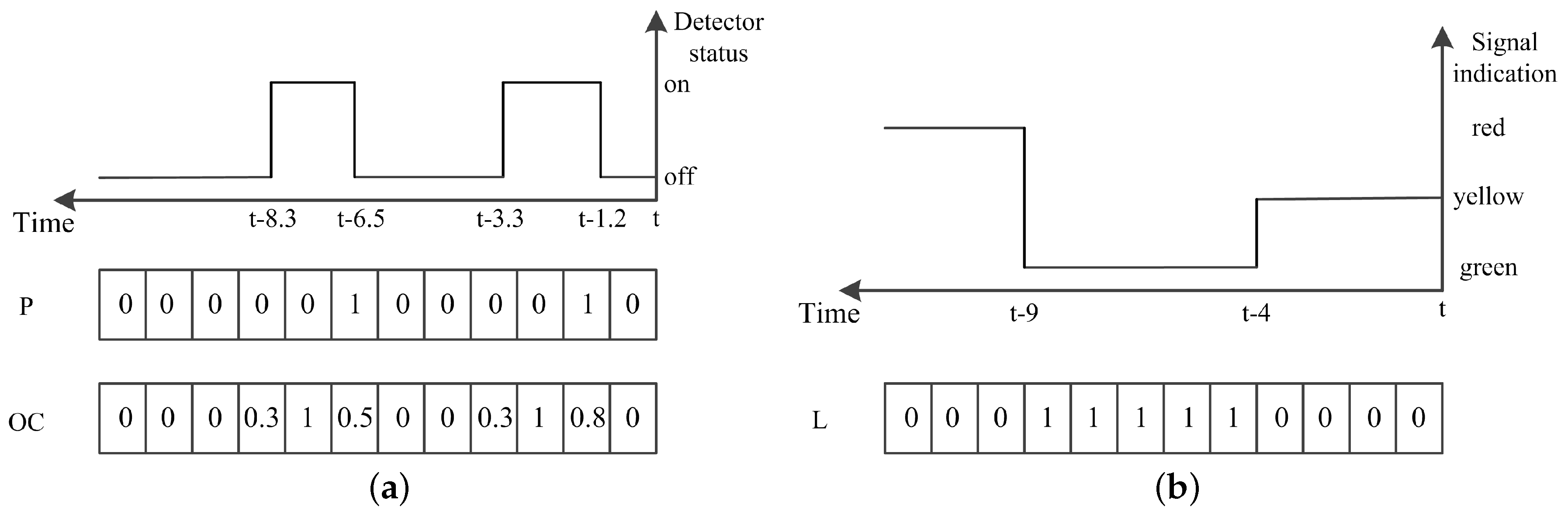
3.1. Configuration of Detection System
3.2. State Definition
3.3. Action Definition
3.4. Reward Definition
4. Traffic Signal Control through Double Dueling Deep Q Network
4.1. Double Deep Q Network Algorithm
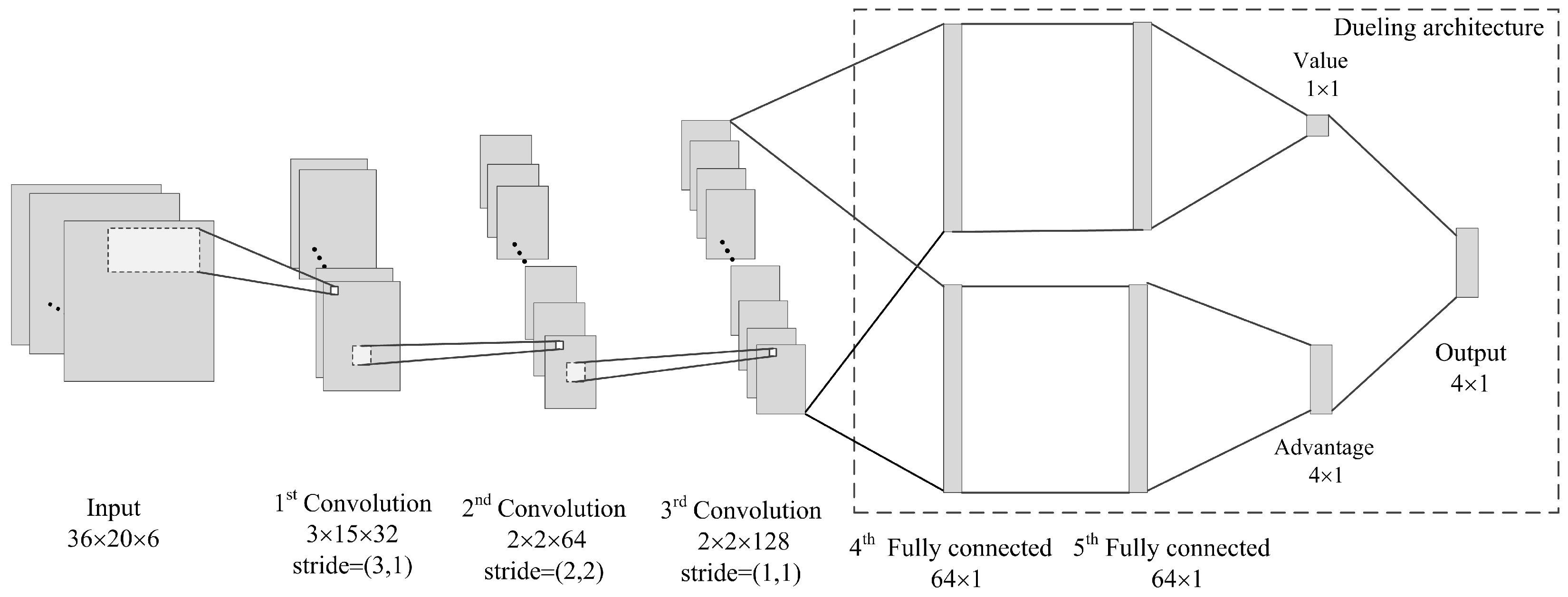
4.2. The Deep Convolutional Neural Network
4.3. Training Algorithm of Adaptive Traffic Signal
| Algorithm 1: Double Dueling Deep Q Network for Traffic Signal Control |
 |
- Action selection: the -greedy method is adopted to select the action, i.e., under the probability of the action is selected randomly, otherwise, the action with the greatest action-value is chosen (line 7), and is decayed linearly from the initial value to the final value over the given steps (line 27–29);
- Action execution: if the action is to keep the current signal phase, prolonging this phase for seconds. Otherwise, following an intermediate phase of seconds which indicates yellow signals for the running vehicles, the action (signal phase) is executed for seconds (line 8–13);
- Observation: After executing the action, the agent observes and obtains the reward and new intersection state (line 14);
- Experience storage: adding the interaction experience produced at this step into the replay memory, which has a limited capacity (line 15–18);
- Network training: when the cumulative experience reaches the requirement of minibatches update, the agent adjusts the weights of action-value network via three sub-steps. (1) randomly drawing experiences from the replay memory to form the minibatches of samples (line 20); (2) calculating the target value for each sample in the minibatches based on double networks, where the action-value network is applied for evaluating actions and the target network is used to estimate the target value (line 21–23); (3) performing a back propagation using Adam algorithm with the aim of minimizing the mean squared error (MSE) of minibatches, thus updating and (line 24–26).
5. Simulation Experiments
5.1. Experimental Settings
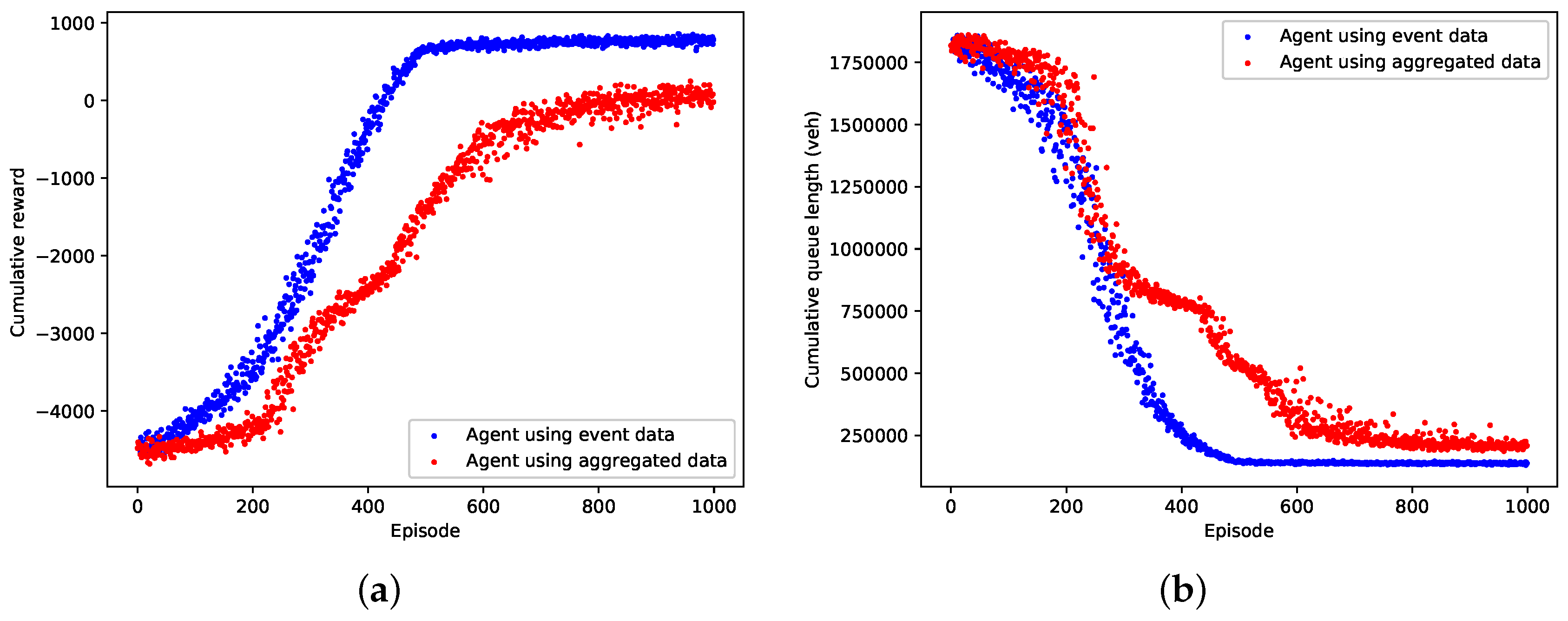
5.2. Training Results
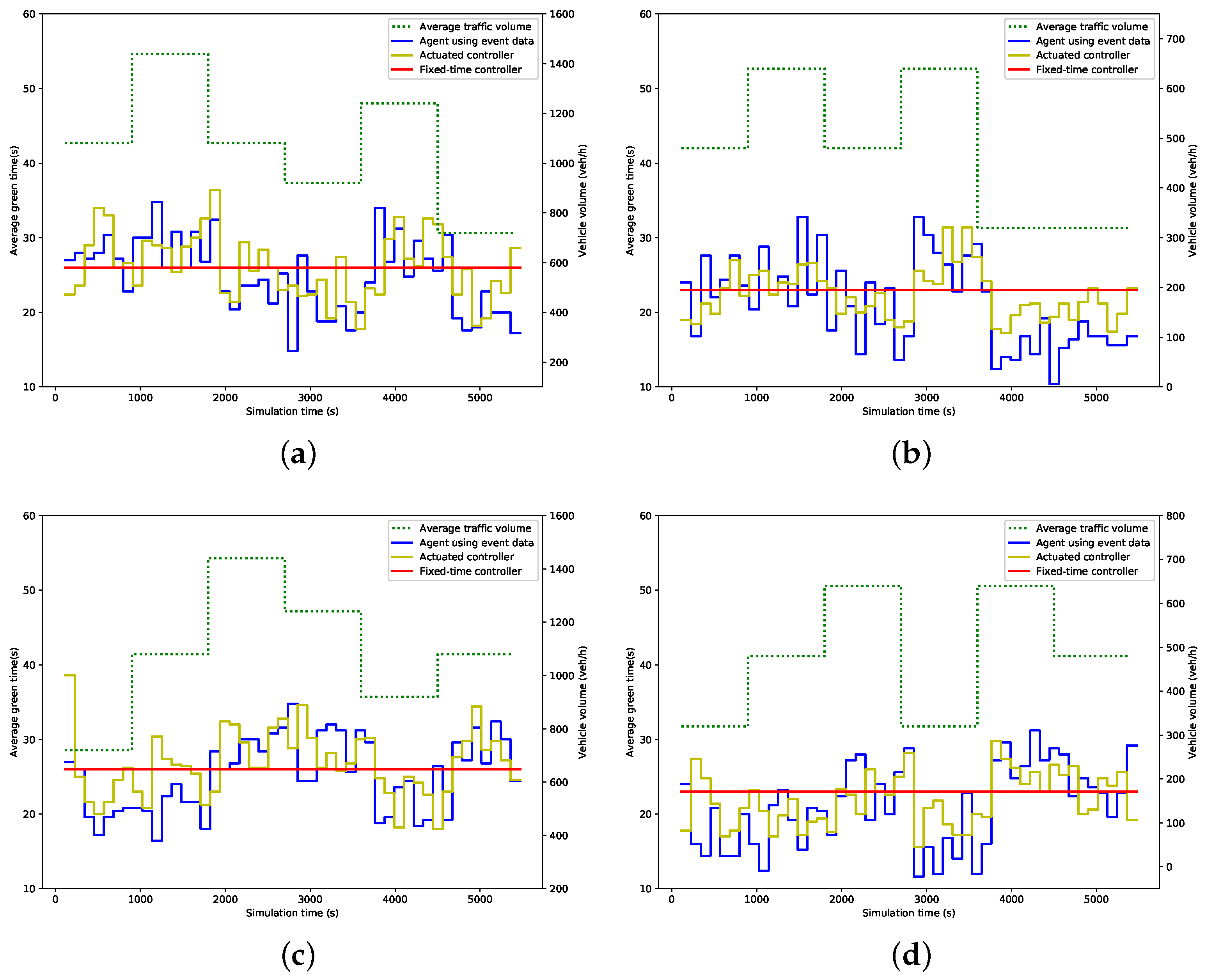
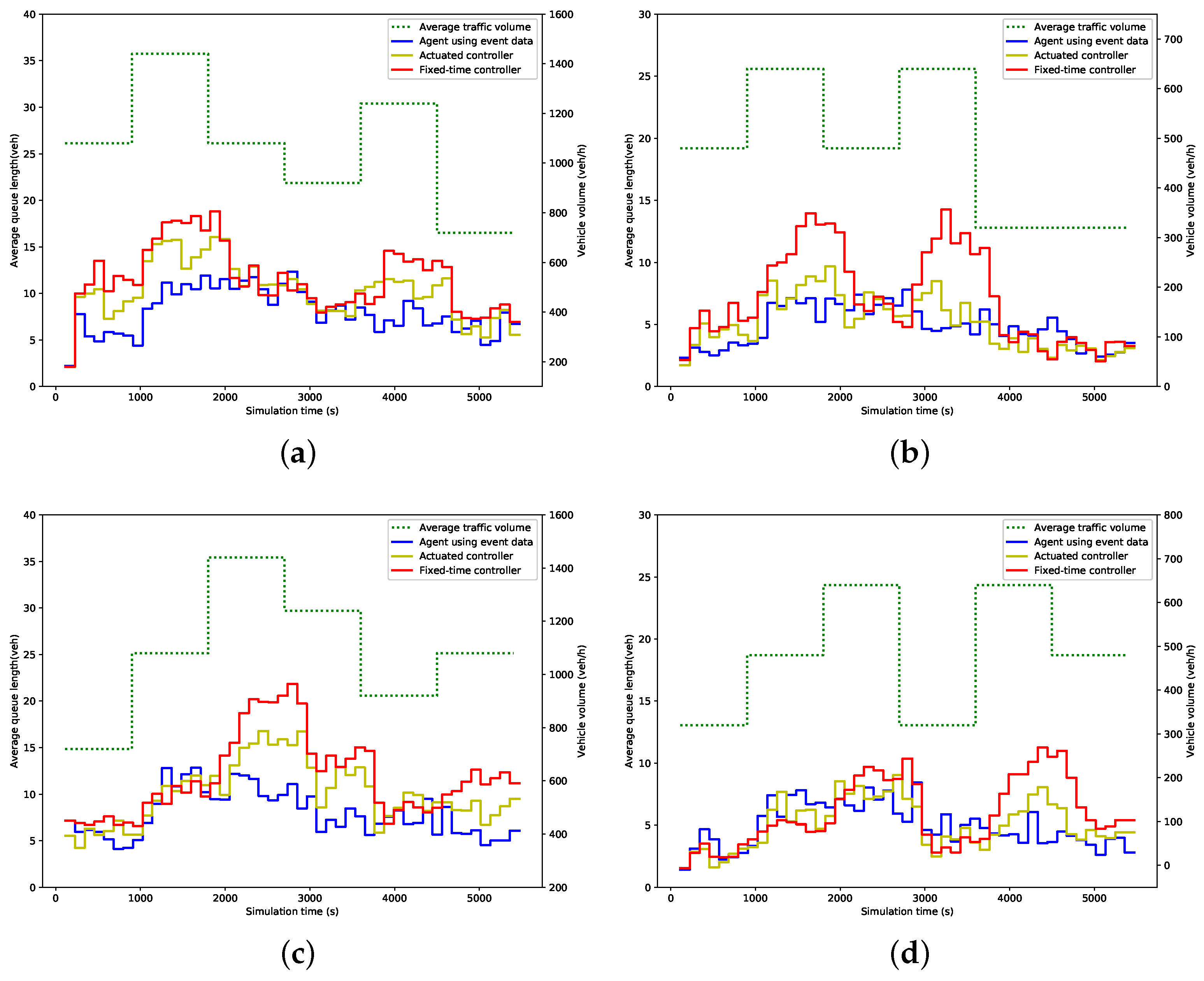
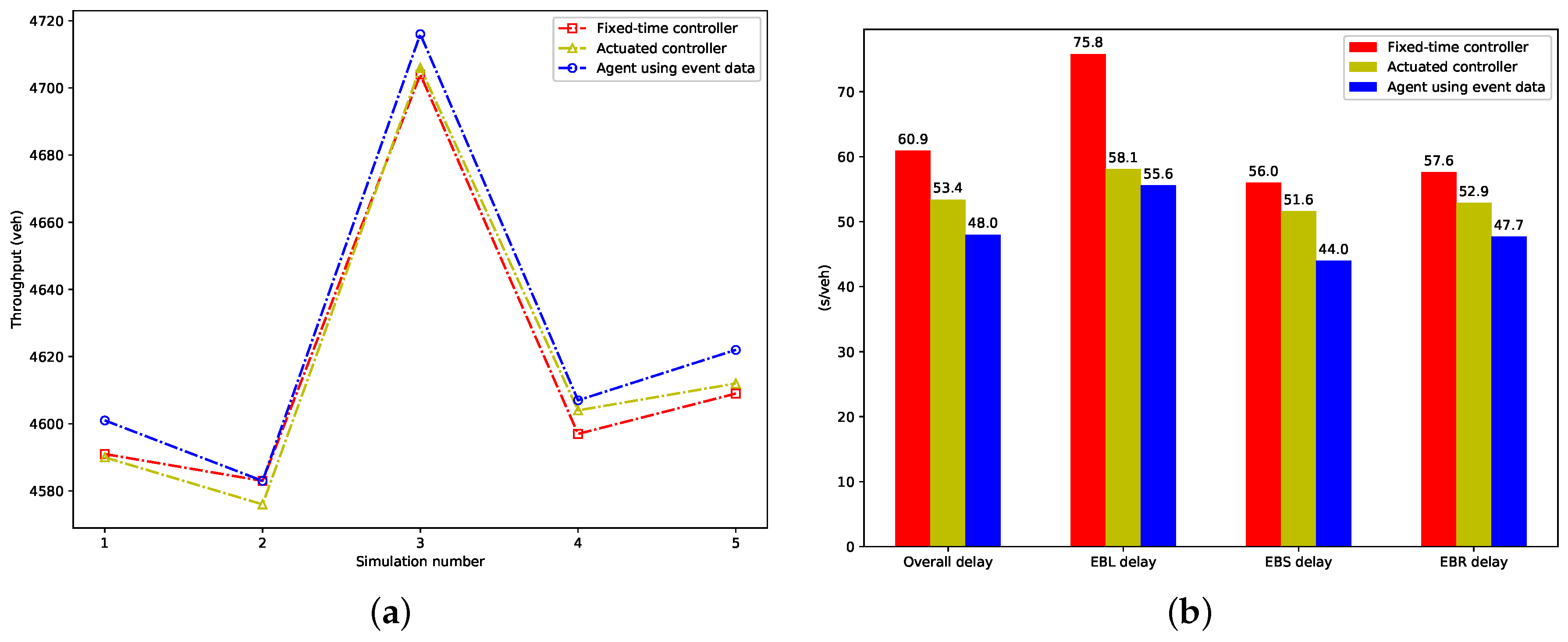
5.3. Evaluation Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Aziz, H.A.; Zhu, F.; Ukkusuri, S.V. Learning-based traffic signal control algorithms with neighborhood information sharing: An application for sustainable mobility. J. Intell. Transport. Syst. 2018, 22, 40–52. [Google Scholar] [CrossRef]
- Yau, K.L.A.; Qadir, J.; Khoo, H.L.; Ling, M.H.; Komisarczuk, P. A survey on reinforcement learning models and algorithms for traffic signal control. ACM Comput. Surv. 2017, 50, 34. [Google Scholar] [CrossRef]
- Araghi, S.; Khosravi, A.; Creighton, D. A review on computational intelligence methods for controlling traffic signal timing. Expert Syst. Appl. 2015, 42, 1538–1550. [Google Scholar] [CrossRef]
- Aslani, M.; Mesgari, M.S.; Wiering, M. Adaptive traffic signal control with actor-critic methods in a real-world traffic network with different traffic disruption events. Transp. Res. Part C Emerg. Technol. 2017, 85, 732–752. [Google Scholar] [CrossRef] [Green Version]
- Mannion, P.; Duggan, J.; Howley, E. An experimental review of reinforcement learning algorithms for adaptive traffic signal control. In Autonomic Road Transport Support Systems; Birkhäuser: Basel, Switzerland, 2016; pp. 47–66. [Google Scholar]
- Aslani, M.; Seipel, S.; Mesgari, M.S.; Wiering, M. Traffic signal optimization through discrete and continuous reinforcement learning with robustness analysis in downtown Tehran. Adv. Eng. Inform. 2018, 38, 639–655. [Google Scholar] [CrossRef]
- El-Tantawy, S.; Abdulhai, B.; Abdelgawad, H. Design of reinforcement learning parameters for seamless application of adaptive traffic signal control. J. Intell. Transport. Syst. 2014, 18, 227–245. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Abdulhai, B.; Pringle, R.; Karakoulas, G.J. Reinforcement learning for true adaptive traffic signal control. J. Transp. Eng. 2003, 129, 278–285. [Google Scholar] [CrossRef]
- Richter, S.; Aberdeen, D.; Yu, J. Natural actor-critic for road traffic optimisation. In Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 1169–1176. [Google Scholar]
- Prashanth, L.; Bhatnagar, S. Reinforcement learning with function approximation for traffic signal control. IEEE Trans. Intell. Transp. Syst. 2011, 12, 412–421. [Google Scholar]
- Prabuchandran, K.; Hemanth Kumar, A.N.; Bhatnagar, S. Multi-agent reinforcement learning for traffic signal control. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 2529–2534. [Google Scholar]
- Jin, J.; Ma, X. A group-based traffic signal control with adaptive learning ability. Eng. Appl. Artif. Intell. 2017, 65, 282–293. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Lv, Y.; Wang, F.Y. Traffic signal timing via deep reinforcement learning. J. Autom. Sinica 2016, 3, 247–254. [Google Scholar]
- Genders, W.; Razavi, S. Using a deep reinforcement learning agent for traffic signal control. arXiv 2016, arXiv:1611.01142. [Google Scholar]
- Gao, J.; Shen, Y.; Liu, J.; Ito, M.; Shiratori, N. Adaptive traffic signal control: Deep reinforcement learning algorithm with experience replay and target network. arXiv 2017, arXiv:1705.02755. [Google Scholar]
- Liang, X.; Du, X.; Wang, G.; Han, Z. A Deep Reinforcement Learning Network for Traffic Light Cycle Control. Trans. Veh. Technol. 2019, 68, 1243–1253. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Liu, H.X. Using high-resolution event-based data for traffic modeling and control: An overview. Transp. Res. Part C Emerg. Technol. 2014, 42, 28–43. [Google Scholar] [CrossRef]
- Chen, P.; Yu, G.; Wu, X.; Ren, Y.; Li, Y. Estimation of red-light running frequency using high-resolution traffic and signal data. Accid. Anal. Prev. 2017, 102, 235–247. [Google Scholar] [CrossRef]
- Day, C.M.; Li, H.; Sturdevant, J.R.; Bullock, D.M. Data-Driven Ranking of Coordinated Traffic Signal Systems for Maintenance and Retiming. Transport. Res. Rec. 2018, 2672, 167–178. [Google Scholar] [CrossRef]
- Webster, F.V. Traffic Signal Settings; Road Research Technical Paper N0 39; Department of Scientific and Industrial Research: London, UK, 1957.
- Administration, F.H. Manual on Uniform Traffic Control Devices; Federal Highway Administration: Washington, DC, USA, 2009.
- Koonce, P.; Rodegerdts, L. Traffic Signal Timing Manual; FHWA-HOP-08-024; Federal Highway Administration: Washington, DC, USA, 2008.
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming, 1st ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1994. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling network architectures for deep reinforcement learning. arXiv 2015, arXiv:1511.06581. [Google Scholar]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Lin, L.J. Reinforcement Learning for Robots Using Neural Networks. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, 6 January 1993. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lopez, P.A.; Behrisch, M.; Bieker-Walz, L.; Erdmann, J.; Flötteröd, Y.P.; Hilbrich, R.; Lücken, L.; Rummel, J.; Wagner, P.; Wießner, E. Microscopic Traffic Simulation using SUMO. In Proceedings of the 21st IEEE International Conference on Intelligent Transportation Systems, Maui, HI, USA, 4–7 November 2018. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time (minute) | EW | NS | |||||
|---|---|---|---|---|---|---|---|
| Right Turn | Through | Left Turn | Right Turn | Through | Left Turn | ||
| 1~15 | 180 | 360 | 240 | 120 | 240 | 160 | |
| 15~30 | 240 | 480 | 320 | 180 | 360 | 240 | |
| 30~45 | 180 | 360 | 240 | 240 | 480 | 320 | |
| 45~60 | 180 | 280 | 320 | 180 | 440 | 160 | |
| 60~75 | 180 | 440 | 160 | 180 | 280 | 320 | |
| 75~90 | 120 | 240 | 160 | 180 | 360 | 240 | |
| Hyperparameter | Learning rate | Discount factor | Initial | Final |
| Value | 0.0002 | 0.75 | 1.0 | 0.01 |
| Hyperparameter | decay steps | Minibatchs size | Replay memory size | Target network update rate |
| Value | 450,000 | 32 | 100,000 | 0.001 |
| Phase 1 | Phase 2 | Phase 3 | Phase 4 | ||
|---|---|---|---|---|---|
| Fixed-time | Green time splits (s) | 26 | 23 | 26 | 23 |
| Cycle length (s) | 114 | ||||
| Fully actuated | Minimum green time (s) | 17 | 17 | 17 | 17 |
| Maximum green time (s) | 36 | 32 | 36 | 32 | |
| Unit extension (s) | 3.5 | ||||
| Passage time (s) | 3.4 | ||||
| Performance Metrics | EBA | ABA | |||
|---|---|---|---|---|---|
| Mean | Std | Mean | Std | ||
| Cumulative reward | 771.6 | 37.0 | 52.1 | 90.1 | |
| Cumulative queue length (veh) | 137,485.7 | 2849.4 | 209,773.87 | 14,168.4 | |
| Performance Metrics | Agent Using Event Data | Fixed-Time | Actuated | Improvement | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | vs. Fixed-Time | vs. Actuated | ||||
| Vehicular delay (s/veh) | 48.0 | 28.0 | 60.9 | 33.5 | 53.4 | 29.9 | 21.2% | 10.1% | |||
| Queue length (veh) | 26.0 | 7.8 | 31.0 | 8.3 | 36.9 | 10.0 | 29.7% | 16.4% | |||
| Vehicle speed (km/h) | 24.5 | 2.1 | 22.9 | 2.3 | 21.2 | 4.2 | 15.5% | 6.9% | |||
| Number of stops (#/veh) | 0.85 | 0.42 | 0.90 | 0.41 | 0.83 | 0.40 | 5.6% | −2.2% | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Xie, X.; Huang, K.; Zeng, J.; Cai, Z. Deep Reinforcement Learning-Based Traffic Signal Control Using High-Resolution Event-Based Data. Entropy 2019, 21, 744. https://doi.org/10.3390/e21080744
Wang S, Xie X, Huang K, Zeng J, Cai Z. Deep Reinforcement Learning-Based Traffic Signal Control Using High-Resolution Event-Based Data. Entropy. 2019; 21(8):744. https://doi.org/10.3390/e21080744
Chicago/Turabian StyleWang, Song, Xu Xie, Kedi Huang, Junjie Zeng, and Zimin Cai. 2019. "Deep Reinforcement Learning-Based Traffic Signal Control Using High-Resolution Event-Based Data" Entropy 21, no. 8: 744. https://doi.org/10.3390/e21080744
APA StyleWang, S., Xie, X., Huang, K., Zeng, J., & Cai, Z. (2019). Deep Reinforcement Learning-Based Traffic Signal Control Using High-Resolution Event-Based Data. Entropy, 21(8), 744. https://doi.org/10.3390/e21080744