1. Introduction
Short fiber reinforced composite is being used in a wide range of sectors in our society. The composite is manufactured from processes such as, among many others, injection molding, compression molding and extrusion. The mechanical performances of the manufactured composite, such as stiffness and strength, is determined by the final state of fiber orientation. The final fiber state results from the flow induced orientation evolution that in the case of semi-concentrated or concentrated flow regimes involves strong fiber–fiber interactions whose modeling is crucial for determining the final part properties and performance.
Predicting flow induced anisotropy in reinforced polymer forming processes is of major interest. However, most of the existing models, as the ones described below, have important limitations associated with the numerous hypotheses introduced during their analytical derivation. When proceeding out of the domain of validity of those models, a pragmatic approach consists of assuming the existing models are still valid and calibrating them from experimental tests.
When these calibrated nominal models are unable to reproduce experimental findings, some ad hoc terms are usually added, being then calibrated accordingly (e.g., diffusion term reflecting fiber interactions).
Thus, data was traditionally employed for calibrating models derived from physical considerations. However, many times those models failed to address experimental findings even when they were finely calibrated. It is the case of models describing intense fiber interactions in semi-concentrated and concentrated fiber suspensions. This issue motivated numerous works referred to later, and remains even today not totally solved.
Recent advances in artificial intelligence, and more particularly in machine learning, are opening new routes. Thus, data can be used not only for calibrating pre-assumed models, i.e., assimilating data into existing models to identify the most adequate values of their parameters. Data can be also used for inferring the model itself, or eventually the correction of a nominal pre-existing model to enhance its predictability capacity.
The present paper aims at addressing this important and timely topic of data-driven model enrichment, here addressed from a methodological viewpoint. Future works will focus on (i) the use of data-driven models for improving computational efficiency in the simulation of complex flows as the ones encountered in processing; (ii) the derivation of more accurate rheological models for describing complex fluids; and (iii) the use of these more accurate rheological models in processing simulations for circumventing, or at least alleviating, the limitation of current models and procedures and their associated predictions.
Revisiting Standard Flow-Induced Orientation Models
The orientation description and its flow induced evolution can be addressed at three different scales [
1]:
At the microscopic scale the orientation state is described from the orientation of each fiber. Thus, in the case of a population consisting of fibers of length with an almost infinite aspect ratio (length to diameter), all of them are located into a representative volume element –RVE– , the orientation state in at time t reduces to the knowledge of the unit vectors , centered at the i-fiber centre of gravity and aligned along its axis.
If we assume that population immersed in a fluid flow characterized by the velocity gradient
, assumed unperturbed by the fibers’ presence and orientation, when neglecting the fiber–fiber interactions, the fiber rotary velocity is expressed by the Jeffery equation [
2], which reads
The mesoscopic description makes use of the probability distribution function , giving the fraction of fibers that at position and time t are oriented along .
Again, when neglecting fiber interaction, the evolution of that distribution function is given by the Fokker–Planck equation
where
represents the material derivative and
the gradient operator involving the conformational coordinates
.
The main difficulty of the previous descriptions is their complexity, the microscopic one due to the fact of needing to track all the fibers immersed in the flow and the mesoscopic due to the fact that the distribution function is defined in a high-dimensional space involving the physical space
, the time
t and the orientation
, the last defined on the unit sphere. Macroscopic descriptions circumvent both difficulties by operating with the probability distribution function moments [
3]. Thus, the second moment of the probability distribution function, also known as second order orientation tensor
, reads
where the integral applies on the unit sphere surface and “⊗” denotes the tensor product.
As described in [
1], the second order moment time evolution, again ignoring fiber interaction, reads
where
is the fourth order moment and “:” represents the tensor product twice contracted. In what follows the orientation rate in Equation (
4) will be referred to as
for indicating that it is associated to the Jeffery model that ignores fiber–fiber interactions.
The macroscopic description is retained in most of works and commercial software because of its relative simplicity. However, for employing it, one must consider closure relations [
4] for expressing the fourth order orientation tensor as a function of the second one, whose validity remains nowadays an open issue. In the numerical tests performed in the present paper the IBOF closure [
5] (invariant-based orthotropic fitted) is considered. Moreover, by restricting the orientation description to the second moment, only some probability distribution functions can be accurately described, others cannot be expressed from the solely use of the second order orientation tensor. On the other hand, size effects were neglected when deriving the models at different scales, limiting the model validity when addressing confined flows.
In the discussion above, fiber–fiber interaction was ignored. Pioneering works assumed that interactions can be considered as randomizing events that tends to push the systems towards an isotropic orientation state, and then, they were modeled from a diffusion term into the Fokker-Planck equation by Folgar and Tucker [
6]. Thus, the probability distribution function time evolution is now expressed from
with
D the diffusion coefficient, assumed scaling the flow intensity from the second invariant of the velocity gradient.
By using this expression it results in an orientation evolution equation composed of two terms, the usual Jeffery-based orientation model complemented with a correction that can be easily derived as illustrated in [
1]. Thus the time evolution of the orientation can be written in its most general form as
where the first term corresponds to the Jeffery contribution given by Equation (
4) and the second contribution, the deviation with respect to the Jeffery model, comes from the interactions, modeled as a diffusion term within the Folgar and Tucker (F&T) model.
For addressing anomalous experimental orientation findings at odds with F&T predictions, in particular a delay in the orientation rates, other models of fiber–fiber interactions have been proposed [
7,
8,
9,
10,
11,
12]. In these studies, the observed delay was attributed to the intense fiber–fiber interactions and modeled either with a modified diffusion term, a microscopic description of interactions, or by introducing a sliding mechanism between fibers and fluid, with an anisotropic rotary diffusion.
At present neither, closure relations nor interaction models that are general and accurate enough, exist. A recent comparison of different approaches can be found in [
13]. The accuracy of the fiber orientation is tested usually by predicting the effect on mechanical properties due to the error in predicting of fiber orientation. This issue is beyond the scope of this work but references [
3,
4] have done that comparison. In [
14] authors noticed that for example, the incorrect prediction of fiber orientation as the suspension flows into a rib could seriously compromise the part performance.
Despite the fact that numerous works continue to introduce improved models, the present paper proposes an alternative methodology for improving existing models, based on the data-driven enriching of the model.
In our former works [
15] we addressed the fully data-driven modeling of suspensions, here we restrict to enriching the Jeffery model with a data-driven description of interactions, a methodology also considered in some of our former works [
16,
17].
As our main aim is not the derivation of a new interaction model for fiber suspensions, in what follows we will consider a molecular dynamics (MD) simulation, able to represent in absence of interactions Jeffery motion, and in presence of interactions describing them with a a standard Lennard–Jones potential. Here we are only interested in assimilating that data extracted from the data-driven interaction model that when added to the Jeffery contribution enables an accurate prediction of the orientation evolution in flow conditions that are different from the ones used to extract the model.
This fine-scale simulated data-generator does not pretend to infer an improved model for simulating processes, but only proving that a macroscopic orientation model can be learned from microscopic data in order to accurately describe that orientation state. By having access to more accurate data associated with the orientation evolution of a population of rods, from adequate measurements or generated from more accurate microscopic models (direct numerical simulations solving the fluid kinematics and induced fibers motion) more accurate macroscopic models could be derived.
The methodology described in this paper remains totally general, the only difference being the quality of the data that serves for learning the model, and consequently it can be applied to any flow regime, from dilute (without major interest being the Jeffery model valid) to the highly concentrated regime (where standard model fail).
The next section addresses the data-generator based on a MD fine-scale simulation. Then in
Section 3 we introduce the machine learning techniques that will be applied in
Section 4 to extract the interaction term. Finally in
Section 5 we proceed to verify the proposal by conducting some numerical experiments.
2. Data Generator Based on Molecular Dynamics (MD) Simulations
The fine scale simulation is performed by representing the fiber as connected beads where forces apply, the last derived from different potentials as well as the hydrodynamic drag.
We consider three different potentials: The Lennard–Jones potential to describe bead-bead interaction (both beads belonging to different fibers) and and that describe the elongation and bending interaction between neighbor beads of the same fiber.
As indicated at the end of the previous section, the MD simulation here addressed allows recovering Jeffery model predictions in absence of interaction. When interactions occur nothing was demonstrated on the ability of MD for representing fibers motion, but here as previously indicated, our main aim is proving that a macroscopic model can be extracted from individual microscopic data. The quality of the learned model only depends on the quality of the data that served to extract it. The MD strategy here considered must be viewed as a simply synthetic data generator.
Thus, without loss of generality, in what follows we consider the following potential for addressing the just mentioned mechanisms
where
is the number of fibers in the population and
represents the Lennard–Jones potential between bead
i of fiber
j and bead
k of fiber
l. The characteristic function
(with
the Kroenecker delta) ensures that the Lennard–Jones potential only acts between beads belonging to different fibers.
The Lennard–Jones potential reads
with
the distance between beads
of fiber
j and bead
of fiber
l, located at positions
and
respectively, and
and
are the two usual parameters involved in the Lennard–Jones potential. The elongation potential is given by
where
is the equilibrium distance between two successive beads, distance at which the potential reaches its minimum (and consequently the associated force vanishes). In the previous expression
reflects the potential intensity.
The bending potential between three successive beads
where
is the angle defined by vectors joining beads
and
with
the angle at equilibrium, that vanishes when considering straight fibers. In our study we consider parameters ensuring an almost rigid behavior of the fiber.
The hydrodynamic drag was enforced by adding at each bead the external force
where
denotes the velocity of bead
and
the friction coefficient.
The total force applied on each bead, inserted into the Newton equation, allows the acceleration calculation, and from it the velocity and position update, as performed in standard MD simulations.
The problem is expressed in a dimensionless form prior to proceed with its solution. It is important to emphasize that in absence of Lennard–Jones interactions and for almost rigid fibers, the previous modeling framework recovers the usual Jeffery kinematics.
3. Methods
Two dimensionality reduction methods, the principal component analysis (PCA) and the Code2Vect will be employed for constructing the interaction data-driven model, the former for reducing the dimensionality and the last for creating the nonlinear regression. For the sake of completeness both are summarized in the next sections.
3.1. Principal Component Analysis (PCA)
Let us consider a vector
containing some data. If some correlations exists in that data, one could find a linear transformation
to transform
into
, with
, with
. This mapping reads
The transformation matrix , , satisfies the orthogonality condition , where represents the -identity matrix ( is not necessarily ).
Assume that there exist M different snapshots , which we store in the columns of a matrix . The associated reduced matrix contains the associated vectors , . We assume without loss of generality centered variables.
PCA proceeds by guaranteeing maximal preserved variance and enforcing the latent variables in
being uncorrelated. In other words, the covariance
will be diagonal. PCA extracts the
d uncorrelated latent variables from
Pre- and post-multiplying by
and
, respectively, and making use of the fact that
, gives us
The covariance matrix
can then be factorized by applying the singular value decomposition (SVD), i.e.,
with
containing the orthonormal eigenvectors and
the diagonal matrix containing the eigenvalues, sorted in descending order.
Substituting Equation (
16) into Equation (
15), we arrive at
with
diagonal as soon as the
d columns of
are taken collinear with
d columns of
.
In the data-driven modeling approach proposed later, PCA will be used for expressing a time history in a time reduced basis. Thus, instead of describing a time function from its value at different time steps, it will be described by the weight of few functions defined in the whole time interval involved in the time reduced basis.
3.2. Code2Vect
In [
18] the authors proposed a supervised classification and nonlinear regression procedure that was called
Code2Vect because of its ability to map data from a representation (non-metric) space into a vector space equipped of a metric.
We assume that points in the origin space consists of
M arrays composed on D entries, noted by
. Theirs images in the vector space are noted by
, with in general
. The mapping is described by the
matrix
ensuring
where both, the components of
and the images
,
, must be calculated. Each point
keeps the label (value of the quantity of interest (QoI)) associated with is origin point
, denoted by
.
We would like placing points
, such that the Euclidian distance with each other point
scales with their outputs difference, i.e.,
where the coordinates of one of the points
can be arbitrarily chosen. Linear mappings are limited and do not allows proceeding in nonlinear settings. Thus, a better choice consists of the nonlinear mapping
, expressible from the general polynomial form
where
are
matrices and
a polynomial basis.
Equation (
19) ensures clustering due to the fact that data with similar output will be placed closer than when the outputs differ significantly. As well as the mapping has been determined, Equation (
18) (or its nonlinear counterpart) becomes an efficient nonlinear regression as described in [
18].
In the data-driven modeling approach proposed later, Code2Vect will be used for defining nonlinear regressions eventually involving heterogeneous data (e.g., the components of the orientation and velocity gradient tensors).
3.3. Model Training
In what follows the orientation based on the Jeffery model that ignores interaction will be denoted by the superscript , whereas the orientation evaluated from MD simulations will be denoted by .
The deviation
is expected to describe the fiber interactions because the proposed MD model in absence of interactions (with a vanishing Lennard–Jones potential) was able to reproduce very accurately fiber motion as described by Jeffery’s equation (Equation (
4)) . The associated rate equation can be written as
with components
It is expected that in absence of confinement, size effect, and for a given fiber concentration, will depend on the flow velocity gradient and the orientation state itself.
In what follows we consider two scenarios:
The first is related to the orientation process from a given initial orientation state for different flows characterized by their velocity gradient kept constant during all the flow process;
The second is more general and looks for expressing the deviation rate as a function of both the applied flow (defined by its changing velocity gradient) and the existing orientation state at a given time instant.
3.3.1. Orientation Evolution in Homogeneous Flows
In this case, the deviation rate at any time is assumed depending on the initial orientation state and the applied flow . Our main purpose is determining accurately . For the sake of simplicity and without loss of generality, we assume the same initial orientation, almost isotropic.
The procedure for learning the model consists of the following steps:
Consider an almost initial isotropic fiber distribution , , defining the initial orientation tensor .
Generate randomly or using a design of experiments (DoE) different flows characterized by the velocity gradients , .
The second invariant of tensors , , allows defining the maximum simulation time for each flow such that , with total strain large enough for reaching an almost steady orientation state.
Perform the MD integration for all the considered flows from the initial fiber distribution
, leading to
, from which the second order orientation tensor
can be computed at time
t from
that enables calculating its time derivative
.
Perform the integration of the Jeffery model from for the different flows, to obtain and its associate orientation rate .
The deviation results .
The interval is divided in D intervals, and the deviation rate at the associated deformation (the deformation is defined from ) extracted, i.e., , .
Thus, each component of , , can be expressed as a point in , , whose l—component results .
Now, the PCA is applied and the first
d modes retained. For facilitating visualization we will consider in fact the first three modes, i.e.,
, defining the matrix
. Thus, the image of
is given by
with
.
Now,
Code2Vec applies on vectors
(with
the vector form of the velocity gradient
), that are transformed into
from the nonlinear mapping
, i.e.,
where the mapping is constructed by enforcing
With orientation model constructed, as soon as a new orientation trajectory must be evaluated for a given velocity gradient it suffices to proceed as follows:
Map into the vector space according to ;
Identify the set containing the closest neighbors of ;
Compute the approximation weights , , depending on the distance between and , for example by using radial basis;
Interpolate the deviation reduced orientation trajectories according to
Push up to reconstruct the time evolution according to
It is important to note that the inverse mapping is not defined, and by this reason we perform the same interpolation that in the reduced space (previous item)
3.3.2. Instantaneous Orientation Behavior
The present case is even simpler. We consider different orientation states, that can be computed by taking some snapshots of the fibers orientation at different time during a complex flow simulation. Then, for each of them, we applied different flows to evaluate the instantaneous orientation rate of change.
The procedure reads:
Define at , initial orientation states , & , using for example a MD simulation in a complex flow.
Compute the associated orientation tensors
Define flows defined by their velocity gradient tensor , .
Update the orientation state at time from both the MD procedure and from the Jeffery equation, the former proceeding from , the last from , leading to (evaluated from ) and respectively, from which the associated rates can be obtained, respectively and , and from both the deviation .
Define the data-sets, , each one containing the vector representation of and , with as quantity of interest, QoI, .
Now, Code2Vect can apply to map each into , by constructing for each component the model (linear or in general nonlinear as previously dicussed)
Now, online, for any
and
, it results
that by applying the mapping leads to
. As in the previous section, the set of closest neighbors can be defined, and an interpolation performed to obtain
, that is used in the time-marching integration procedure according to
that adds to the standard Jeffery contribution the one extracted from the data related to the deviations.
4. Results
In the considered suspension the fiber volume fraction () is kept at 0.01 (semi-dilute regime, 0.0025 < < 0.05 for a fiber aspect ratio of 20). These conditions apply to both procedures previously defined.
4.1. Orientation Evolution in Homogeneous Flows
Total 35 cases with different
are prepared for this case study (some of them related to pure shear and elongation flows). Out of 35 cases, its aimed to predict the
of the case number 10. The initial orientation state is almost isotropic, whereas the velocity gradient is
The prediction for the 10th flow is made according to the procedure described in
Section 3.3.1 and is shown in
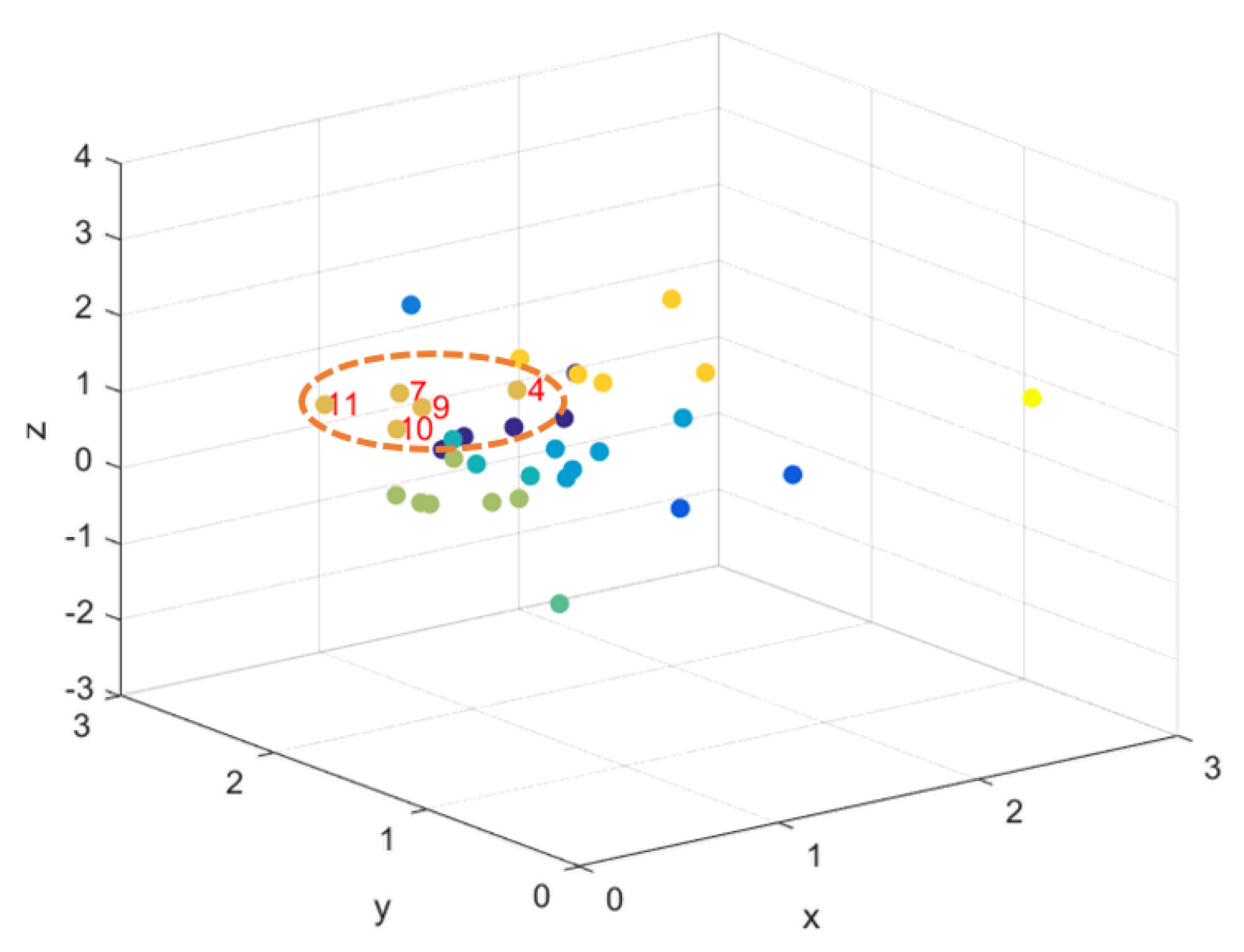
Figure 1. The mapped point representing the 10th flow has as closest neighbors flows 4, 7, 9 and 11.
The velocity gradient
for
are:
In what follows, and for the sake of representation clarity, only the component of the orientation tensor will be discussed.
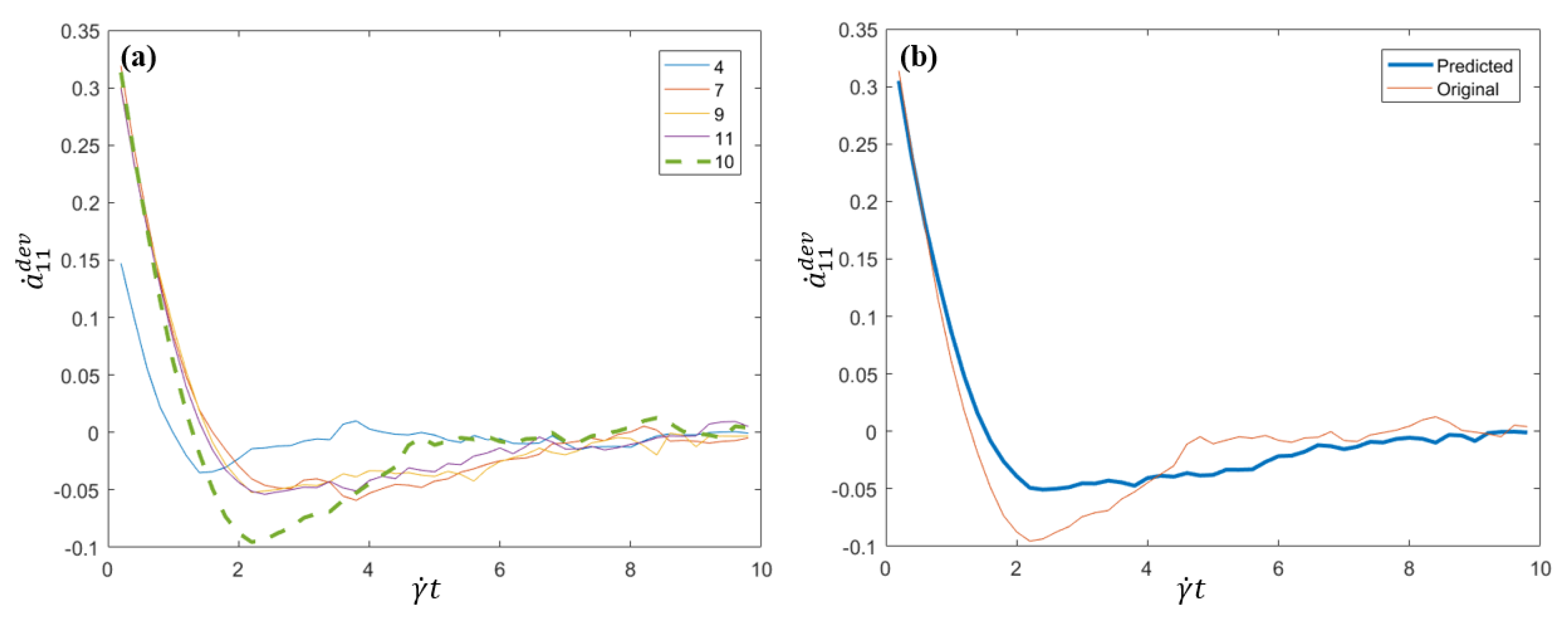
The corresponding
for the five flows
j = 4, 7, 9, 10, 11 are presented in
Figure 2a, whereas the prediction and reference solution (original data) for that flow,
, are presented in
Figure 2b. The proposed strategy perform quite reasonably by capturing the main behavior. Obviously the finer is the sampling, the more accurate is the prediction.
4.2. Instantaneous Orientation Behavior
In the present case we consider two numerical tests reported below.
In this first test, we perform a MD simulation for extracting different orientation states when considering an almost isotropic initial orientation state a the flow characterized by
The extracted
intermediate orientation states are defined in
Table 1.
For these four orientation states a total of 38 samples at different are prepared.
As discussed in
Section 3.3.2 Code2Vect applies on the
M data
and
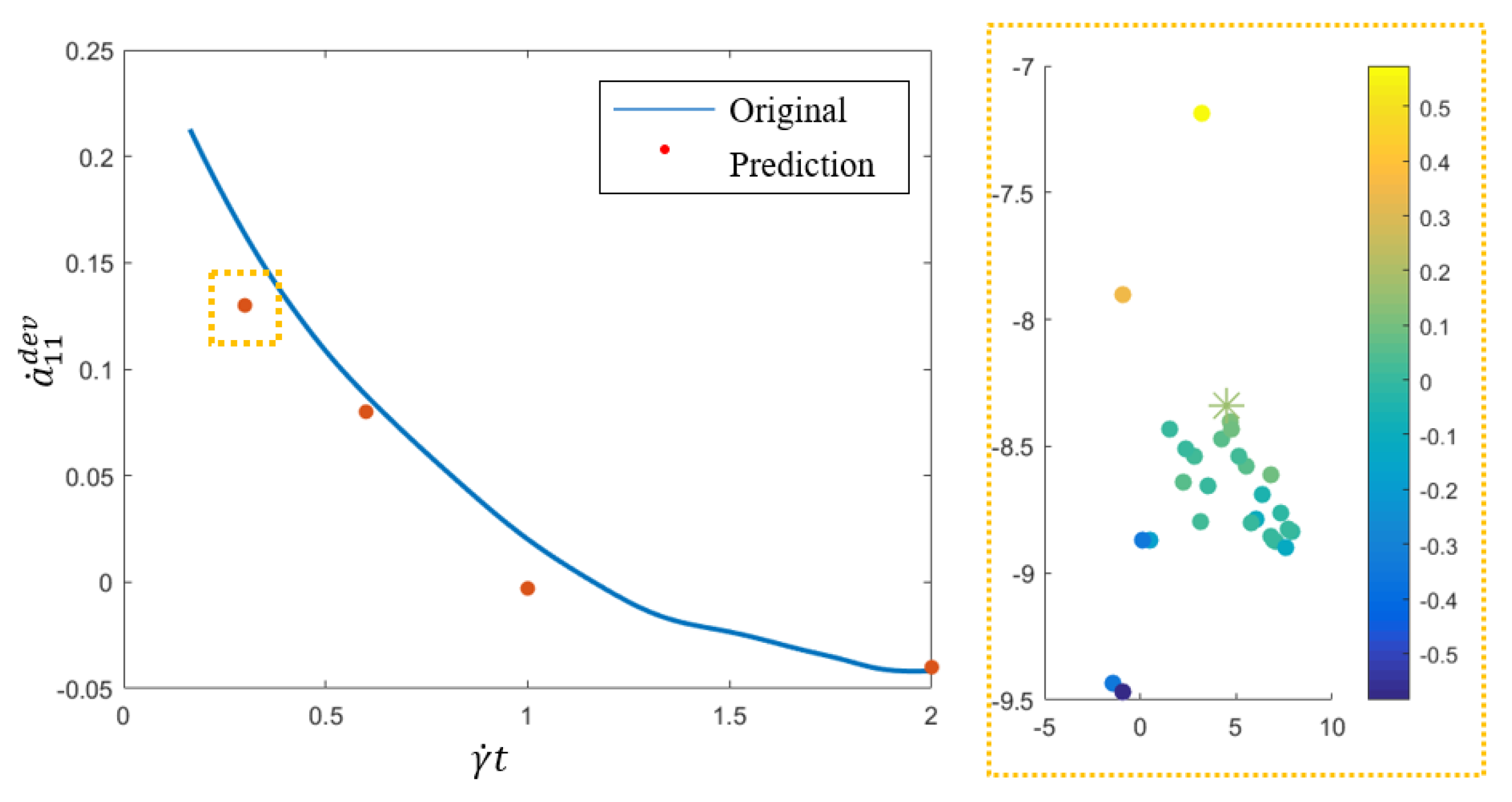
whose results are presented in
Figure 3, where original data and predictions of
up to
is depicted (left). Prediction at the evaluation point (star) along with 37 samples (filled circle) is depicted on the right image of that figure, where color scales with the value of
at
. The predicted data shows a good agreement with the raw data validating the proposed methodology.
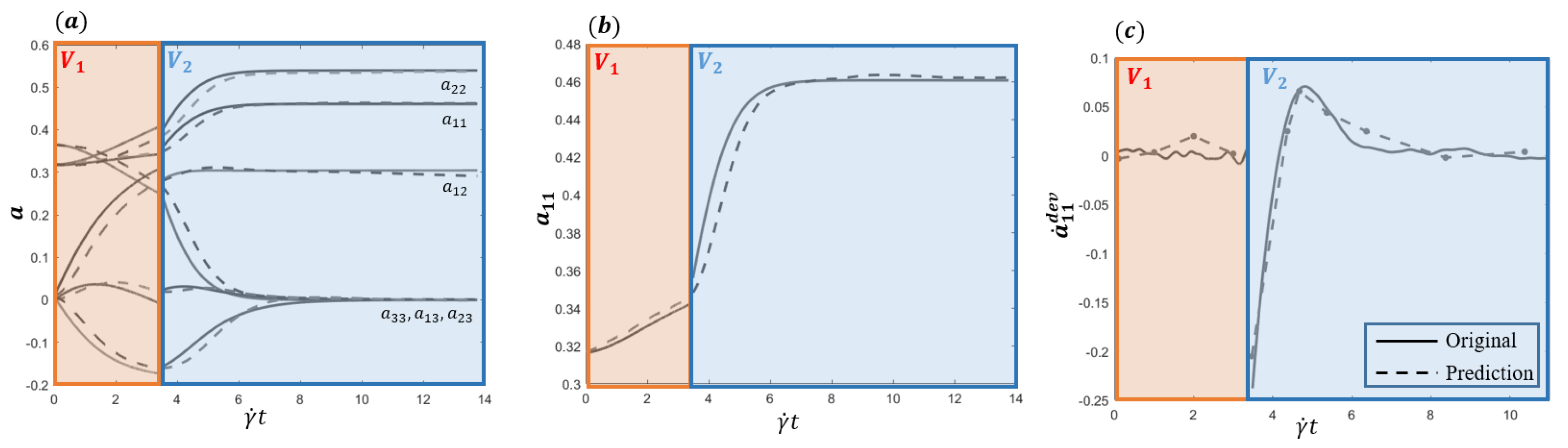
The last numerical test addresses a more complex scenario where the velocity gradient changes within the simulation-time window.
The prediction for is made when fibers (almost isotropically distributed at the initial time) are placed under two velocity gradient fields, (shear) and (elongation), consecutively, the former applying during the first s and the last the subsequent 10 s.
The velocity gradient
for these flow fields is
Data-driven enriched Jeffery solution and the one provided by MD simulation are compared over the entire time period in
Figure 4a,b, whereas
Figure 4c depicts the deviation prediction (following the procedure described in
Section 3.3.2) versus the reference one provided directly by the data. As it can be noticed, the numerical values of the prediction when compared with the reference data, both reported in
Table 2, exhibit an excellent accuracy.
5. Conclusions and Prospects
This work shows the opportunity of hybrid modeling methodologies, combining a model based on physics complemented with a data-driven enrichment to account for the gap between the model predictions and the collected data. In this work the synthetic data was used from a high-fidelity fine-scale simulation based on molecular dynamics, a simulation which took fiber–fiber interactions into account.
The data-driven model was constructed by using advanced machine learning techniques able to operate at the low-data limit, in particular the PCA and the so-called Code2Vect.
The proposed methodology was verified with numerical experiments that show the efficiency of our hybrid approach and the techniques employed for constructing the data-driven model.
Currently injection molding simulations use a constitutive model in which they have to provide an interaction parameter which is the same everywhere and is determined from experiments conducted under simple shear. It has been shown that the flow field is very different around corners, inserts, ribs and undercuts in complex injection molded parts. It is expected that the constitutive interaction parameter locally will be different but there is no model or methodology to determine this. Our approach should allow for more accurate fiber orientation prediction in such situations. The extension of the present work to efficient processing simulations constitute a work in progress.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}