Monitoring Volatility Change for Time Series Based on Support Vector Regression


Abstract
:1. Introduction
2. CUSUM Monitoring Procedure
3. Monitoring Procedure via SVR-GARCH Model
3.1. Support Vector Regression
3.2. Particle Swarm Optimization
| Algorithm 1 Standard PSO algorithm |
| 1: procedure PSO() |
| 2: |
| 3: |
| 4: while do |
| 5: ; |
| 6: |
| 7: for do |
| 8: update ; |
| 9: ; |
| 10: update |
| 11: end for |
| 12: update |
| 13: end while |
| 14: end procedure |
3.3. Monitoring Nonlinear Time Series via SVR
- 1.
- Estimate with from training sample ;
- 2.
- Estimate recursively with and some initial values and ;
- 3.
- Generate iid standard normal random variables , , , and construct a bootstrap sample ;
- 4.
- Based on , , estimate with , and calculate the bootstrapped residuals with obtained recursively by ;
- 5.
- Based on these residuals, construct the monitoring process , , , similarly to in (8) with analogously defined to ;
- 6.
- Finally, the critical value c is determined as the upper quantile of for .
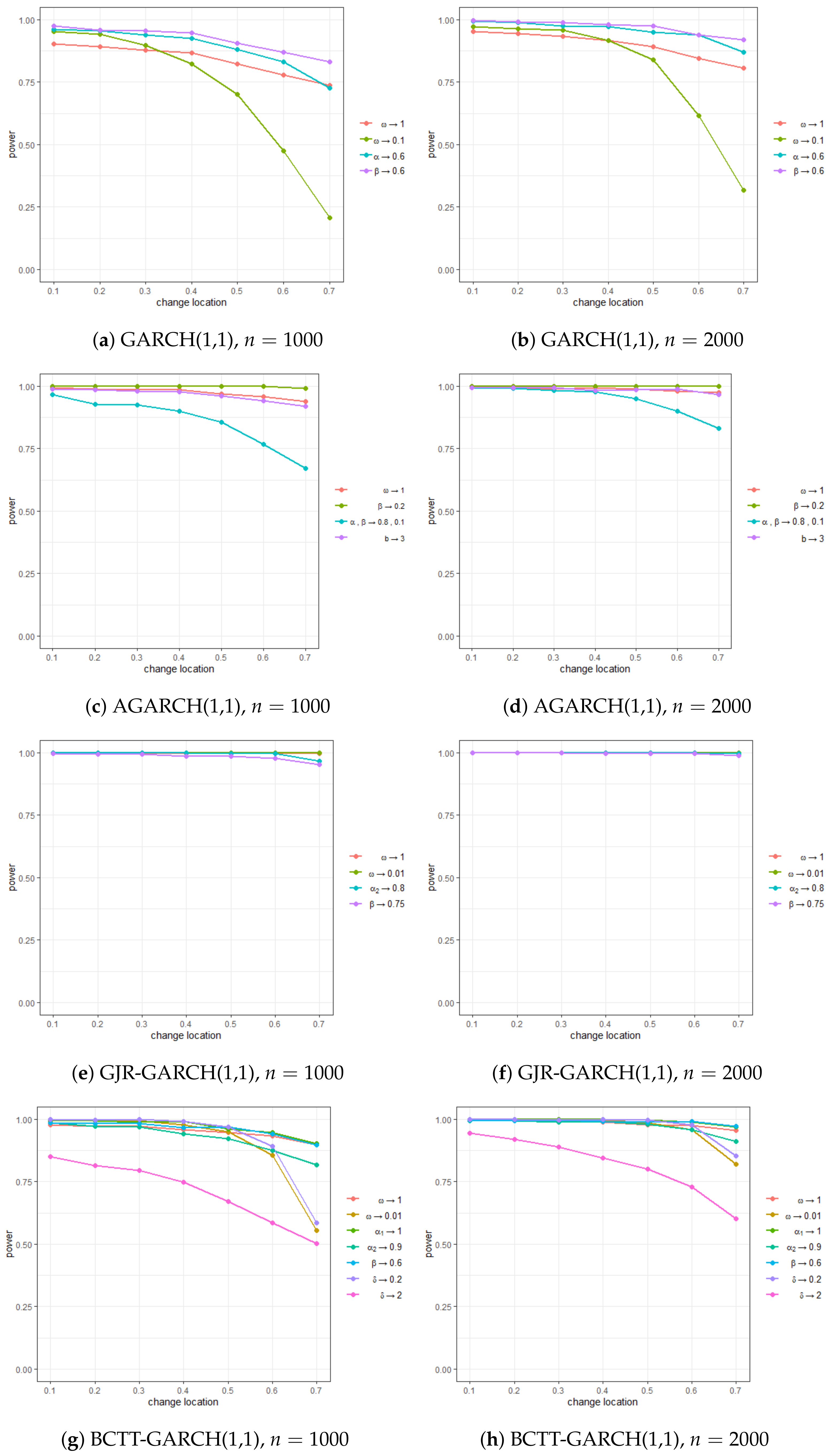
4. Simulation Experiments
- GARCH(1,1):
- AGARCH(1,1):
- GJR-GARCH(1,1):
- BCTT-GARCH(1,1): .
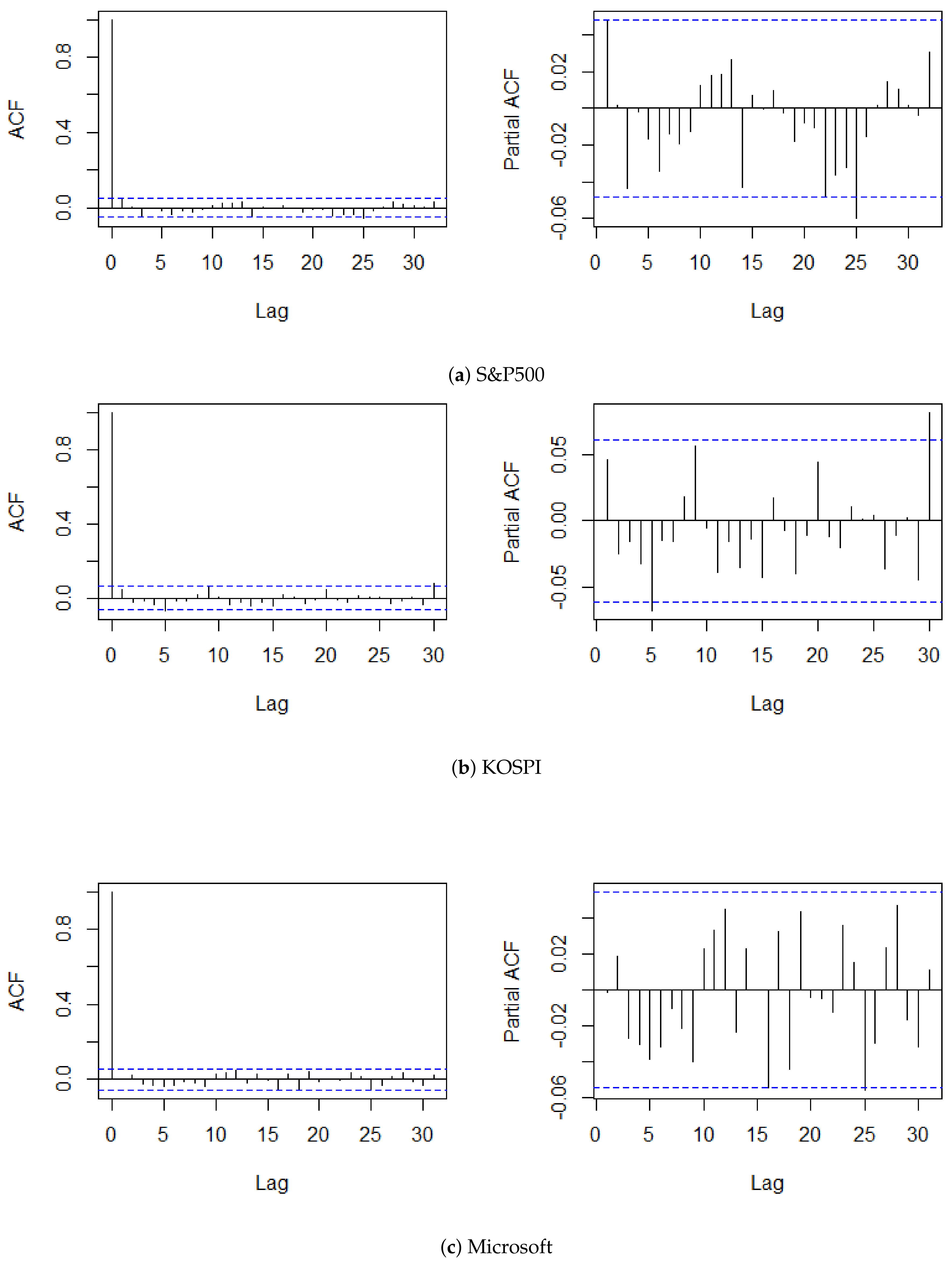
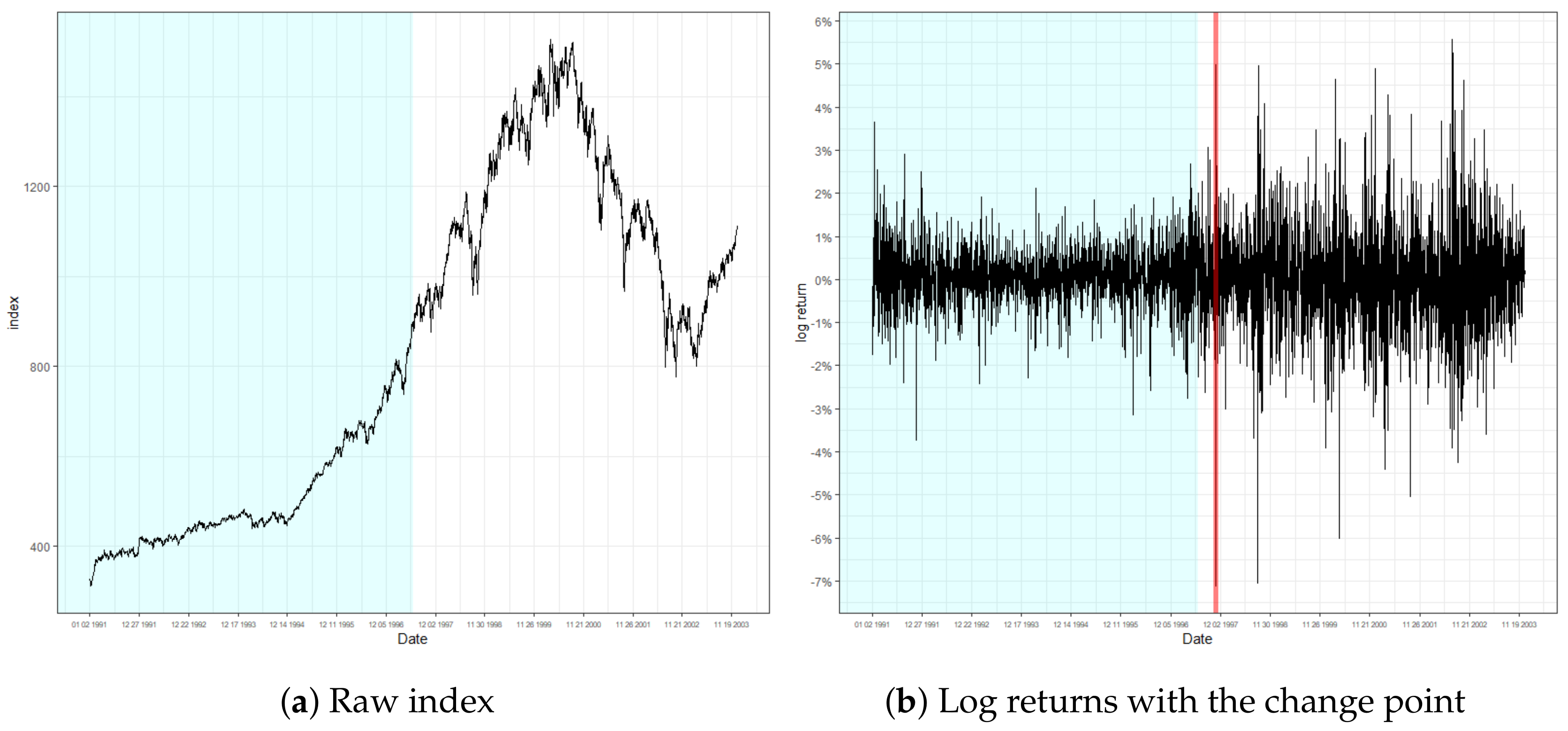
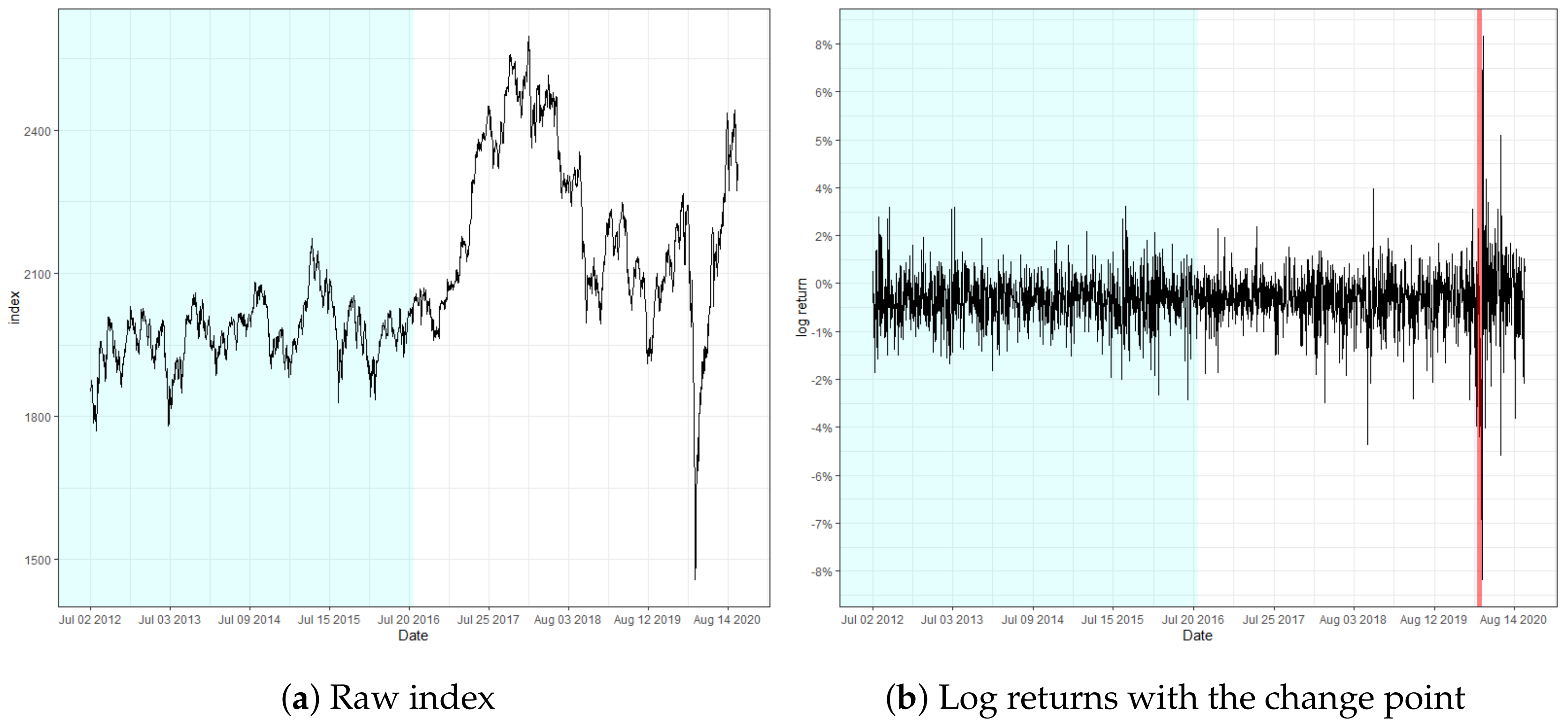
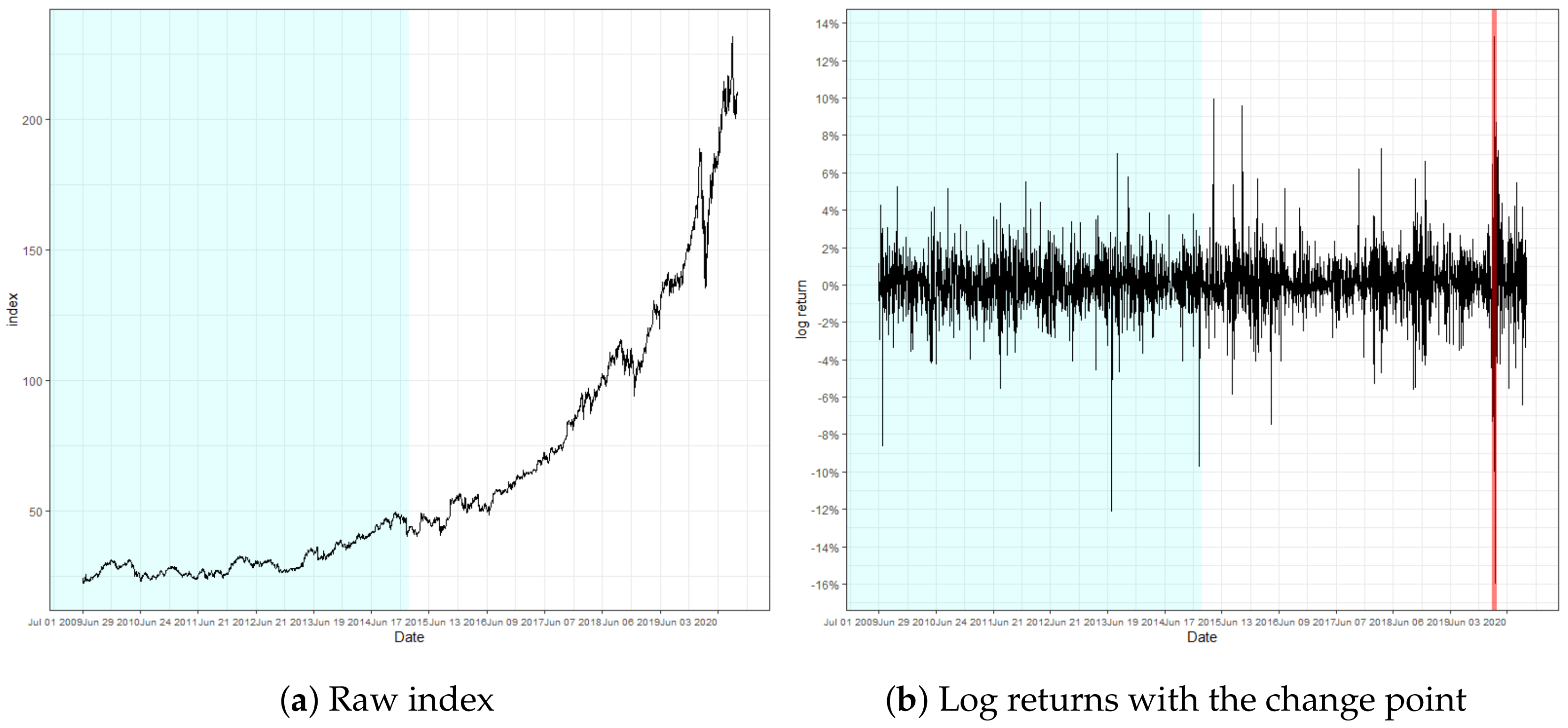
5. Real Data Analysis
6. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CUSUM | cumulative sum |
| SPC | statistical process control |
| ARL | average run length |
| ARMA | autoregressive and moving average |
| ARCH | autoregressive conditionally heteroskedasticity |
| GARCH | generalized autoregressive conditionally heteroskedasticity |
| SVR | support vector regression |
| SVM | support vector machine |
| PSO | particle swarm optimization |
| iid | independent and identically distributed |
| MAE | mean absolute error |
| EWMA | exponentially weighted moving average |
| AGARCH | asymmetric GARCH |
| GJR-GARCH | Glosten, Jagannathan and Runkle-GARCH |
| BCTT-GARCH | Box-Cox transformed threshold GARCH |
| ARMA | autoregressive and moving average |
| QMLE | quasi-maximum likelihood estimator |
| KOSPI | Korea Composite Stock Price Index |
| ACF | autocorrelation function |
| PACF | partial ACF |
References
- Page, E.S. Continuous inspection schemes. Biometrika 1954, 41, 100–115. [Google Scholar] [CrossRef]
- Page, E.S. A test for a change in a parameter occurring at an unknown point. Biometrika 1955, 42, 523–527. [Google Scholar] [CrossRef]
- Wu, Z.; Jiao, J.; Yang, M.; Liu, Y.; Wang, Z. An enhanced adaptive CUSUM control chart. IIE Trans. 2009, 41, 642–653. [Google Scholar] [CrossRef]
- Regier, P.; Briceño, H.; Boyer, J.N. Analyzing and comparing complex environmental time series using a cumulative sums approach. MethodsX 2019, 6, 779–787. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E.; Idrovo-Aguirre, B.J. Backcasting and forecasting time series using detrended cross-correlation analysis. Phys. A Stat. Mech. Appl. 2020, 560, 125109. [Google Scholar] [CrossRef]
- Montgomery, D.C. Statistical Quality Control; Wiley Global Education: Hoboken, NJ, USA, 2012. [Google Scholar]
- Gombay, E.; Serban, D. Monitoring parameter change in AR (p) time series models. J. Multivar. Anal. 2009, 100, 715–725. [Google Scholar] [CrossRef]
- Huh, J.; Oh, H.; Lee, S. Monitoring parameter change for time series models with conditional heteroscedasticity. Econ. Lett. 2017, 152, 66–70. [Google Scholar] [CrossRef]
- Na, O.; Lee, Y.; Lee, S. Monitoring parameter change in time series models. Stat. Methods Appl. 2011, 20, 171–199. [Google Scholar] [CrossRef]
- Vapnik, V. Statistical Learning Theory; John Wiley and Sons: New York, NY, USA, 1998. [Google Scholar]
- Fernandez-Rodriguez, F.; Gonzalez-Martel, C.; Sosvilla-Rivero, S. On the profitability of technical trading rules based on artificial neural networks: Evidence from the Madrid stock market. Econ. Lett. 2000, 69, 89–94. [Google Scholar] [CrossRef]
- Cao, L.; Tay, F. Financial forecasting using support vector machines. Neural Comput. Appl. 2001, 10, 184–192. [Google Scholar] [CrossRef]
- Pérez-Cruz, F.; Afonso-Rodriguez, J.; Giner, J. Estimating GARCH models using SVM. Quant. Financ. 2003, 3, 163–172. [Google Scholar] [CrossRef]
- Chen, S.; Härdle, W.K.; Jeong, K. Forecasting volatility with support vector machine-based GARCH model. J. Forecast. 2010, 29, 406–433. [Google Scholar] [CrossRef]
- Bezerra, P.; Albuquerque, P. Volatility forecasting via SVR–GARCH with mixture of Gaussian kernels. Comput. Manag. Sci. 2017, 14, 179–196. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature Of Statistical Learning Theory; Springer: New York, NY, USA, 2000. [Google Scholar]
- Smola, A.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.; Lee, S.; Moon, M. Hybrid change point detection for time series via support vector regression and CUSUM method. Appl. Soft Comput. 2020, 89, 106101. [Google Scholar] [CrossRef]
- Lee, S.; Kim, C.; Lee, S. Hybrid CUSUM change point test for time series with time-varying volatilities based on support vector regression. Entropy 2020, 22, 578. [Google Scholar] [CrossRef]
- Lee, S.; Tokutsu, Y.; Maekawa, K. The cusum test for parameter change in regression models with ARCH errors. J. Jpn. Stat. Soc. 2004, 34, 173–188. [Google Scholar] [CrossRef] [Green Version]
- Oh, H.; Lee, S. Modified residual CUSUM test for location-scale time series models with heteroscedasticity. Ann. Inst. Stat. Math. 2019, 71, 1059–1091. [Google Scholar] [CrossRef]
- Lee, S. Location and scale-based CUSUM test with application to autoregressive models. J. Stat. Comput. Simul. 2020, 90, 2309–2328. [Google Scholar] [CrossRef]
- Lee, S.; Ha, J.; Na, O.; Na, S. The CUSUM test for parameter change in time series models. Scand. J. Stat. 2003, 30, 781–796. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; IEEE: Piscataway, NJ, USA, 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Ozcan, E.; Mohan, C.K. Analysis of a simple particle swarm optimization system. Intell. Eng. Syst. Through Artif. Neural Netw. 1998, 8, 253–258. [Google Scholar]
- Trelea, I.C. The particle swarm optimization algorithm: Convergence analysis and parameter selection. Inf. Process. Lett. 2003, 85, 317–325. [Google Scholar] [CrossRef]
- Yasuda, K.; Ide, A.; Iwasaki, N. Adaptive particle swarm optimization. In SMC’03 Conference Proceedings, Proceedings of the 2003 IEEE International Conference on Systems, Man and Cybernetics, Washington, DC, USA, 8 October 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 2, pp. 1554–1559. [Google Scholar]
- Zhang, Y.; Wang, S.; Ji, G. A comprehensive survey on particle swarm optimization algorithm and its applications. Math. Probl. Eng. 2015, 2015, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Tan, D.; Liu, L. Particle swarm optimization algorithm: An overview. Soft Comput. 2018, 22, 387–408. [Google Scholar] [CrossRef]
- Qian, W.; Li, M. Convergence analysis of standard particle swarm optimization algorithm and its improvement. Soft Comput. 2018, 22, 4047–4070. [Google Scholar] [CrossRef]
- Billingsley, P. Convergence of Probability Measure; Wiley: New York, NY, USA, 1968. [Google Scholar]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef] [Green Version]
- Francq, C.; Zakoian, J.M. GARCH Models: Structure, Statistical Inference and Financial Applications; John Wiley & Sons: New York, NY, USA, 2019. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Abe, S. Support Vector Machines for Pattern Classification; Springer: New York, NY, USA, 2005; Volume 2. [Google Scholar]
- Marini, F.; Walczak, B. Particle swarm optimization (PSO). A tutorial. Chemom. Intell. Lab. Syst. 2015, 149, 153–165. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 4-17 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Change location | ||||||||||||||||
| GARCH(1,1) | size | 0.038 | 0.045 | |||||||||||||
| power | 0.903 | 0.893 | 0.879 | 0.867 | 0.824 | 0.778 | 0.737 | 0.953 | 0.945 | 0.934 | 0.916 | 0.893 | 0.845 | 0.805 | ||
| 0.954 | 0.942 | 0.898 | 0.824 | 0.701 | 0.475 | 0.206 | 0.971 | 0.963 | 0.959 | 0.916 | 0.840 | 0.616 | 0.317 | |||
| 0.961 | 0.955 | 0.940 | 0.924 | 0.882 | 0.830 | 0.726 | 0.995 | 0.990 | 0.976 | 0.973 | 0.951 | 0.939 | 0.870 | |||
| 0.974 | 0.958 | 0.955 | 0.946 | 0.907 | 0.871 | 0.832 | 0.996 | 0.992 | 0.988 | 0.981 | 0.975 | 0.940 | 0.920 | |||
| AGARCH(1,1) | size | 0.039 | 0.037 | |||||||||||||
| power | 0.993 | 0.989 | 0.987 | 0.985 | 0.968 | 0.959 | 0.939 | 0.996 | 0.997 | 0.988 | 0.995 | 0.989 | 0.980 | 0.975 | ||
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.992 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||
| 0.967 | 0.927 | 0.924 | 0.900 | 0.856 | 0.767 | 0.672 | 0.995 | 0.992 | 0.983 | 0.978 | 0.950 | 0.899 | 0.832 | |||
| 0.989 | 0.986 | 0.981 | 0.978 | 0.962 | 0.943 | 0.920 | 0.994 | 0.995 | 0.994 | 0.984 | 0.987 | 0.988 | 0.966 | |||
| GJR-GARCH(1,1) | size | 0.042 | 0.033 | |||||||||||||
| power | 1.000 | 0.999 | 1.000 | 0.998 | 0.999 | 0.998 | 0.996 | 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | 1.000 | 0.999 | ||
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||
| 1.000 | 1.000 | 0.999 | 0.999 | 0.998 | 0.997 | 0.967 | 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | 1.000 | 0.998 | |||
| 0.996 | 0.993 | 0.994 | 0.986 | 0.986 | 0.977 | 0.954 | 1.000 | 1.000 | 1.000 | 0.998 | 0.998 | 0.997 | 0.989 | |||
| BCTT-GARCH(1,1) | size | 0.048 | 0.039 | |||||||||||||
| power | 0.978 | 0.973 | 0.973 | 0.957 | 0.948 | 0.934 | 0.897 | 0.997 | 0.996 | 0.993 | 0.989 | 0.979 | 0.975 | 0.955 | ||
| 0.995 | 0.995 | 0.993 | 0.978 | 0.951 | 0.855 | 0.556 | 0.999 | 0.997 | 0.997 | 0.997 | 0.987 | 0.958 | 0.819 | |||
| 0.997 | 0.995 | 0.988 | 0.992 | 0.962 | 0.947 | 0.903 | 1.000 | 0.999 | 1.000 | 1.000 | 0.996 | 0.989 | 0.968 | |||
| 0.987 | 0.971 | 0.968 | 0.941 | 0.921 | 0.875 | 0.817 | 0.995 | 0.993 | 0.988 | 0.992 | 0.980 | 0.958 | 0.911 | |||
| 0.986 | 0.983 | 0.984 | 0.967 | 0.970 | 0.941 | 0.897 | 0.998 | 0.994 | 0.997 | 0.992 | 0.990 | 0.992 | 0.972 | |||
| 0.999 | 0.998 | 0.999 | 0.992 | 0.969 | 0.891 | 0.585 | 0.999 | 0.999 | 0.998 | 0.999 | 0.996 | 0.978 | 0.854 | |||
| 0.850 | 0.814 | 0.795 | 0.749 | 0.671 | 0.585 | 0.502 | 0.945 | 0.919 | 0.890 | 0.846 | 0.800 | 0.728 | 0.602 | |||
| S&P500 | KOSPI | Microsoft | ||
|---|---|---|---|---|
| Summary statistics (training set) | Observations | 1640 | 1016 | 1417 |
| Mean | 0.0604 | 0.0096 | 0.0428 | |
| Standard deviation | 0.6931 | 0.7728 | 1.4408 | |
| Minimum | −3.7272 | −3.1429 | −12.1033 | |
| Median | 0.0352 | 0.0070 | 0.03145 | |
| Maximum | 3.6642 | 2.9124 | 7.0330 | |
| Skewness | −0.1064 | −0.0264 | −0.6141 | |
| Excess kurtosis | 2.2428 | 1.3848 | 6.8293 | |
| Retrospective test (training set) | Test statistic | 0.8069 | 1.2876 | 0.5897 |
| Monitoring test | Location | 97/10/28 | 20/03/11 | 20/03/13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Kim, C.K.; Kim, D. Monitoring Volatility Change for Time Series Based on Support Vector Regression. Entropy 2020, 22, 1312. https://doi.org/10.3390/e22111312
Lee S, Kim CK, Kim D. Monitoring Volatility Change for Time Series Based on Support Vector Regression. Entropy. 2020; 22(11):1312. https://doi.org/10.3390/e22111312
Chicago/Turabian StyleLee, Sangyeol, Chang Kyeom Kim, and Dongwuk Kim. 2020. "Monitoring Volatility Change for Time Series Based on Support Vector Regression" Entropy 22, no. 11: 1312. https://doi.org/10.3390/e22111312
APA StyleLee, S., Kim, C. K., & Kim, D. (2020). Monitoring Volatility Change for Time Series Based on Support Vector Regression. Entropy, 22(11), 1312. https://doi.org/10.3390/e22111312