1. Introduction
In the realm of computational modeling today, scientists, mathematicians, and engineers investigate, design, optimize, and make predictions and decisions about an incredible multitude of real-world systems. In general, a computational model implements a mathematical model; the mathematical model represents the actual system in question using abstraction and simplification. In this paper, we investigate what happens when common simplifications go too far—resulting in an overly reduced or partial model—and how to account for the discrepancy between this model and the true system of interest. At the same time, these partial models still contain significant deterministic information, and they should not be thrown out entirely. Instead, we augment the partial models with a data-driven correction: we use what we know, and learn the rest.
Partial models are especially common in the context of the generalized Lotka–Volterra (GLV) equations. These equations describe the interactive behavior of any number
S of different species. The concentration of each species is represented by a variable
; there is one differential equation for each
whose right-hand side (RHS) includes a linear growth rate term and nonlinear interaction terms. This framework, also called the quasipolynomial form, is canonical in dynamical systems [
1] and is used to describe many types of physical systems, including reaction models for chemical kinetics [
2], ecological models [
3], and epidemiological models [
4]. In these applied fields, modelers commonly build a partial model with only
species. For example, there are over 50 chemical species thought to be involved in methane combustion [
5]; in practice, often merely five to ten species are included [
6]. Surprisingly, Kourdis and Belan found that the removal of 90–99% of chemical species can still lead to reliable output [
7,
8]. SEIR-type epidemiology models include subpopulations of Susceptible, Exposed, Infected, and Recovered (hence the name) humans and the disease carriers (e.g., mosquitoes), while omitting many others such as asymptomatic or hospitalized humans [
9], or even cattle or nonhuman primates [
10].
Validation is the process by which we check that the mathematical model faithfully represents the system in question. While all models should undergo validation, this is especially important when we know our models are incomplete. (
Verification is the process by which we check that any computation correctly solves the mathematical problems. For example, proper verification procedures include code documentation, unit and regression testing, and solution comparisons against a posteriori error estimates, to name a few. While critical to the success of computational modeling, verification is not a concern of this paper; we assume all computational implementations are correctly documented, implemented, and executed. For more information about verification, see, e.g., [
11,
12,
13].) In its most basic form, validation checks that the model output is consistent with all relevant observations. Statistical techniques that do not require knowledge of the model include, for example, goodness of fit (computing
values), analysis of residuals between model output and data, and
k-fold cross-validation [
14]. However, a validation process may require a more nuanced procedure, depending on what one plans to do with the model. In [
15], Oliver et al. described a sophisticated approach to model validation for predictions of unobservable quantities. Their framework relies on knowledge of the model and system under study, and it takes the behavior of the model over different scenarios into account. In [
16], Bayarri et al. described a comprehensive framework for the validation of computer experiments. Their framework includes detailed processes such as determining appropriate domains of model inputs, guarding against overfitting, and accounting for bias in the simulation output. In [
17], Farrell-Maupin and Oden described an adaptive method for model calibration and validation using increasingly complex models. In that method, additional richness is only introduced to the model after the simpler version is shown to be invalid. Finally, Jiang et al. implemented a sequential approach to model calibration, validation, and experimental design with the goal of reducing model bias by misspecified and reduced models [
18].
Note that all validation procedures rely on access to observations, which should (hopefully) include a description of the associated measurement error. If there is some mismatch between the model and the observations, the source of the discrepancy could either be the model or the observations, or both. Reliable experimental practices and proper data reduction techniques ensure that all observations are reported correctly with quantified measurement uncertainty. In this paper, we assume that any discrepancy between the model and observations is not caused by faulty experimental procedures or reporting. In this way, we may focus on what to do when the model itself causes the discrepancy.
Once validation reveals a discrepancy that cannot be reasonably explained by measurement error, we must improve the model. Consider that the discrepancy is revealed by comparing some set of model output to the corresponding set of observations. If a bias is perceived between the two, a natural first step would be to attach a discrepancy function or stochastic process to the model output, which can then be calibrated to correct the model. In fact, this type of discrepancy model, which we call a response discrepancy model, has been duly investigated, starting with the fundamental work of Kennedy and O’Hagan in 2001 [
19]. Since then, the response discrepancy model has been adapted into fields as diverse as climate modeling [
20], hydrology [
21], and cardiology [
22], among many others. Lewis et al. developed an information-theoretic approach to calibrate a low-fidelity model, including a response discrepancy function, from high-fidelity model outputs [
23]. This approach is based on Bayesian experimental design to both minimize uncertainty in the low-fidelity model parameters and reduce the number of needed high-fidelity model runs. A response discrepancy model can be useful and relatively quick to develop when one only needs to interpolate between data points.
Recall, however, our goals for computational modeling: to investigate, design, optimize, and make predictions and decisions. To achieve these goals, we must be able to trust the model output beyond a specific calibration scenario; otherwise, we could just rely on observations without need for a model. To this end, we aim to represent the model discrepancy with a discrepancy operator embedded within the model itself, i.e., an embedded discrepancy operator. There are several advantages of an embedded discrepancy operator. First, the operator can be constrained by physical information such as conservation laws, symmetries, fractional concentrations, nonnegativity constraints, and so on. Second, as a function of state variables or other existing model variables, the action of the discrepancy operator is physically interpretable. Third, the operator can be calibrated over many different scenarios, such as initial conditions, boundary conditions, or simulation geometries. Because of these qualities—physical consistency, interpretability, and robustness in different scenarios—an embedded discrepancy model could be valid for extrapolative predictions.
Embedded, or intrusive, approaches have been previously investigated. In [
24], Sargsyan et al. allowed for model error by endowing model parameters with random variable expansions. As an approach to model discrepancy, this does not break physical constraints, and the random parameters can be calibrated over many scenarios. However, not all model error can by captured in this way. With complex computational models, missing physics or misspecified physics sometimes causes the discrepancy. This is the situation considered in the current paper. Thus, the discrepancy model becomes part of the model itself, yielding an augmented or enriched model, in which case the specific form of the discrepancy model depends on the modeling context. In [
25], the authors investigated this type of inadequacy operator in the context of chemical kinetics for combustion. In this work, we propose and analyze a class of embedded discrepancy operators in the context of the generalized Lotka–Volterra equations, and we show that the error of highly reduced models can be captured by sparse linear operators. For example, a detailed model with 20 species includes 420 parameters where 400 correspond to nonlinear terms, a partial model of four species includes 20 of these, and our discrepancy operator introduces only eight new linear terms.
Although the context is different, the work here is perhaps most similar in philosophy and techniques to that which examines the closure problem of reduced-order fluid dynamics models such as RANS (Reynolds-averaged Navier–Stokes) and LES (large-eddy simulation). For example, Portone et al. developed an embedded operator in [
26] for porous media flow models of contaminant transport. Pan and Duraisamy constructed general data-driven closure models for both linear and chaotic systems, including canonical ordinary differential equations (ODEs) and the one-dimensional Burgers equation [
27]. Other works describe data-driven closure models using proper orthogonal decomposition [
28], Mori–Zwanzig techniques [
29], and linear approximations to closure models for the Kuramoto–Sivashinsky equation [
30]. In a sense, the current paper presents a type of data-driven “closure model” for partial Lotka–Volterra equations.
The paper is organized as follows. A brief review of the generalized Lotka–Volterra (GLV) equations along with a description of the detailed and partial models is given in
Section 2. In
Section 3, a class of embedded discrepancy operators and a method for enforcing physics-based constraints are proposed. The details of calibration and validation for the enriched models are given in
Section 4. Numerical results are listed in
Section 5, and the paper concludes with a discussion in
Section 6. Existing techniques to manipulate ordinary differential equations that motivate the proposed discrepancy operators are reviewed in
Appendix A.
2. Generalized Lotka–Volterra Equations
The generalized Lotka–Volterra equations are coupled ordinary differential equations, used to model the time dynamics of any number of interacting quantities. In particular, the Lotka–Volterra framework allows for linear (growth rate) and quadratic (interaction) terms.
2.1. Detailed Models
The objects in the detailed models will be denoted with a
symbol. Let the vector
represent species concentrations. Here, the units of a particular
refer to the number of specimens per unit area, but specific units are omitted in this paper. The GLV equations of the detailed model
are written succinctly as:
where the vector
represents the intrinsic growth rates, and the matrix
collects the interaction rates—that is, the
th entry of
,
, indicates how species
j affects the concentration of species
i. The equilibrium solution is
.
Since this model is completely determined by the vector and the matrix (modulo initial conditions), we also say that . The species included in the detailed model are called the detailed set. The term intraspecific refers to interactive behavior within a particular species (the are intraspecific terms), while the term interspecific refers to the behavior between two different species (the , are interspecific terms).
2.2. Partial Models
The partial model is comprised of all terms involving the
s species of interest, i.e., by subsampling the detailed one. For example, suppose
and
. Then, the detailed model, written out, is
and the partial model is (now without the
)
Likewise, the partial model is referred to as
, so
and
. Here, the equilibrium solution is
.
In this example, the growth rate vectors and interaction matrices are
The species included in the partial model are called the partial set and sometimes also the remaining species—that is, remaining after a reduction process.
2.3. Defining the Scope
As the objective of this paper is to understand model discrepancy in the context of partial GLV models, we must define the scope of this context. There are a few considerations to keep in mind. First, note that, as explained above, the partial model considered here follows immediately from the detailed model. Thus, when determining the scope of models under investigation, it suffices to determine the detailed model(s). Then, given a detailed model, we investigate all possible partial models from to .
Second, the GLV equations encompass an infinite number of specific models, or model realizations, as S can be any integer , and the entries of and can be, in theory, any real numbers. Moreover, any two GLV models, determined by a specific and , may behave differently from one another. At the most specific extreme, all model parameters are fixed, yielding a single fixed pair of detailed and partial models, and we could then investigate the model discrepancy therein. At the most general extreme, many models are supplied via highly unconstrained realizations of the model parameters, and we could hope to thus discover highly general results about the model discrepancy. In this paper, by aiming somewhere in between these two extremes, we examine a moderately general random class of LV models. This class is determined by specifying appropriate distributions for the entries of and .
Third, since this is an initial exploration into representing model discrepancy in the GLV context, let us narrow the scope in order to examine well-behaved models, i.e., those with stable equilibria. We focus on symmetric interaction matrices
with negative entries. This constraint says that all interactions between and within species are competitive, not cooperative. Then, the matrix
can be stabilized by making its diagonal entries larger in magnitude than the sum of off-diagonal entries in the same row (or column), ensuring diagonal dominance and thus negative eigenvalues. Here, we consider models whose interaction matrices are symmetric, diagonally dominant, and have negative entries. These restrictions (or similar, e.g., that
be negative definite) are common assumptions in mathematical ecology studies; see, e.g., [
3,
31,
32]. The distributional form characterizing entries of
and
are given in the following subsection. Then, in
Section 5, specific models are sampled and analyzed through numerical examples.
2.4. Creating the GLV Detailed and Partial Models
In this subsection, the information above is summarized and refined algorithmically. Algorithm 1 generates a realization of a detailed model, and Algorithm 2 provides the corresponding partial model. Recall that we use
to differentiate between the two and denote a quantity of the detailed model.
| Algorithm 1 Generating a realization of the detailed model. |
- 1:
Initialize S - 2:
Sample - 3:
Set - 4:
Sample - 5:
Set interaction matrix - 6:
Set growth rate vector - 7:
return
|
| Algorithm 2 Subsampling the partial model. |
- 1:
Initialize , D - 2:
Set A as submatrix: - 3:
Set r as subvector: - 4:
return
|
Without loss of generality, we simply choose the first s species in Algorithm 2, as the detailed set follows no special or implicit ordering. Note that existence of a stable equilibrium of the partial model follows directly from that of the detailed model.
3. Enriched GLV Model
Previous work shows how a set of
S coupled Lotka–Volterra equations can be converted to a set of
s equations,
, using algebraic substitutions and/or integration [
33]. The resulting equations will either need to depend on higher derivatives of the remaining species or on their complete time history—that is, the exact dynamics from the detailed model may be written only in terms of the partial set:
where
is the first derivative of
,
the second derivative, and so on, and
represents some memory kernel. Two such manipulations are reviewed in
Appendix A. This motivates an approximation of
with the available partial model
and a discrepancy model
that is a function of either the derivatives or memories of the remaining variables—that is, we seek a model for the partial set of variables as:
The above may be reminiscent of Takens’s theorem [
34], in which a dynamical system is reconstructed from (delayed) observations of the system. However, the two approaches differ fundamentally: here, the LHS derivatives are restricted to those of the partial set, i.e., a subset of the original variables, but that is not true in a delay embedding.
We now propose a particular form of .
3.1. Linear Embedded Discrepancy Operator
Recall that the detailed model is
and the partial model is
We initially propose an enriched model
, linear in
, of the form
where
and
. The subscripts on each
are chosen so that
i indicates that this coefficient appears in the RHS of the variable
, and
j indicates that this coefficient is multiplying the
jth derivative of
.
A major advantage of an embedded operator, as opposed to a response discrepancy model, is that the operator can be constrained by any available information about the physical system. In this simple example, we do have some information about the system that implies constraints on the introduced discrepancy parameters . First, we make the modeling ansatz that these discrepancy parameters should not depend explicitly on time. A result of this ansatz is then that the parameters be constrained independently. We also (assume that we) know that all interspecific interactions are competitive. In particular, note that because and . Thus, we enforce that . Thus, specific information about the high-fidelity physical system implies the following constraints:
Because of this final constraint, the discrepancy operator is no longer linear in
, but rather in
. We still refer to such a formulation as linear (precedence for this use of linear is found in [
35]). Thus, we amend the above enriched model in lines (
10a)–(10c) as
Finally, the introduced discrepancy parameters
are calibrated, using observations of species concentrations generated by the detailed model. Indeed, the strength of the embedded operator approach stems from two properties: (1) the ability to constrain the formulation by available physical information, and (2) the ability to leverage information from the detailed system by calibrating the model discrepancy parameters. Moreover, we calibrate over a range of initial conditions, denoted as
. Note that we also validate over a range of
initial conditions
so that
. Each
specifies the species initial concentrations:
By calibrating with observations from all scenarios, the goal is to build a more robust discrepancy model that is valid over several scenarios instead of only calibrated to a very specific dataset. This property of the model discrepancy construction further allows for the possibility, at least, that such an enriched model could be used in extrapolative conditions, such as a prediction in time, or in scenarios given by different initial conditions.
Note that the actual observations used to calibrate the parameters are specified in
Section 4, along with the particulars of the calibration itself. We have tried to separate what is essential to the formation of the discrepancy operator from the calibration details, which could reasonably change based on the example at hand.
3.2. Equilibrium and Stability of the Enriched Models
The equilibrium solution of the enriched model is
Thus, the parameters , which act linearly on the state , directly control the equilibrium solution. The stability of the enriched model is less obvious because of the absolute values; here, we conjecture that the models are indeed stable.
To see why, first consider an example enriched system of just one variable
x:
Depending on the sign of
, this becomes one of the following logistic equations
The logistic equations admit solutions of the qualitative nature shown in
Figure 1.
Importantly, the sign of
never changes over any solution curve. Given the initial condition, we could in fact solve the same system without the absolute value by choosing either (
16a) or (16b); both reach stable equilibrium. Thus, the presence of the absolute value in this example does not affect the stability of the system.
In general, the signs of the derivatives may change. However, we conjecture that the derivatives of all species do not change sign after a given point in time, say
(as seen in the numerical examples in
Section 5). In this case, the enriched differential equation for
is
where
The above does reach a stable equilibrium, as simply scales the overall dynamics and the interaction matrix A (still) determines the stability of the system.
A more rigorous analysis of stability for these systems will be addressed in future work. For now, we note that differential equations with absolute value terms have been treated in the literature. In particular, Khan and Barton showed that, for ODEs whose RHS are a composition of analytic and absolute value functions of the state variables, the arguments of the absolute values change sign finitely many times in any finite duration [
36], while Barton et al. provided a theoretical and computational framework for evaluating nonsmooth derivatives called lexicographic directional derivatives [
37]. Finally, Oakley demonstrated that certain second-order differential equations with absolute values admit solutions of sets of related linear differential equations [
35].
3.3. Proof of Concept: Linear Embedded Discrepancy Operator,
As an initial proof of concept, consider the
case. The detailed model is
and the partial model is simply
. In this case, the exact discrepancy is
, and we aim to approximate the effect of this term with
Calibration yields posterior mean values of
and
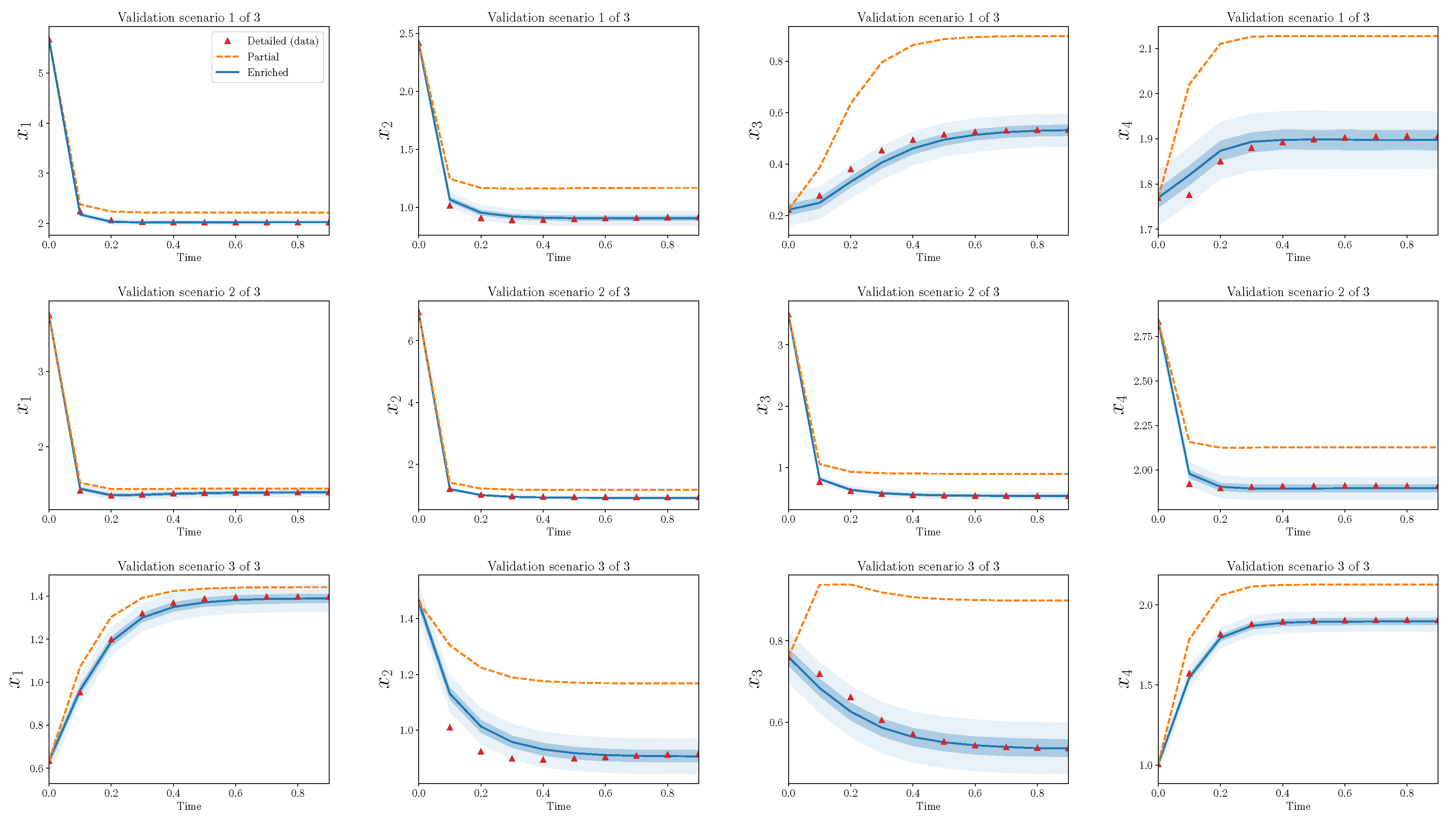
; further calibration details are deferred to the next section. The three models—detailed, partial, and enriched—are shown in
Figure 2a; excellent agreement between the detailed and enriched models is achieved.
We also show the phase diagram of the three models in
Figure 2b including the 2D phase diagram from the detailed model projected onto the
-axis. The recovered derivatives of the enriched model approximately match this projection quite well. Analogous plots are difficult to visualize in higher dimensions, but in this low-dimensional case, this projection may provide some intuition about why the enriched model behaves like the detailed model.
3.4. Other Possible Formulations
There are a number of related possible formulations of the model discrepancy. Some options are the following:
An affine expression up to the
Nth derivative:
A quadratic expression up to the
Nth derivative. Let
A memory expression, such as:
for some
.
Each of the above formulations includes an affine term . Whether or not such a constant term would be advantageous when all the missing dynamics terms are state-dependent is not immediately clear.
Of course, one could also propose some combination of the above formulations as an embedded discrepancy operator. Investigating the numerical advantages and limitations of many such discrepancy operators is beyond the scope of the current paper. For now, numerical results are presented in
Section 5 about the proposed linear embedded discrepancy operator, as described in
Section 3.1.
6. Conclusions
This study is an initial step toward representing model discrepancy in nonlinear dynamical systems of interacting species. The proposed discrepancy model here is a linear operator embedded within the differential equations. The particular form is motivated by circumstances in which a set of differential equations can be converted to a set of fewer equations; in this decoupling process, more information must be introduced about the remaining set, such as memory or higher derivatives. In this work, the discrepancy model is similarly constructed by introducing more information about the partial set, namely as a linear operator which acts on the remaining variables and (the absolute values of) their first derivatives.
We can examine the performance of the enriched models over two regimes: equilibrium and transient dynamics. The introduced parameters act on the state variables, directly affect the equilibrium solution, and seem to be sufficient, as the enriched models typically recover equilibria of the detailed models. On the other hand, the parameters act on the derivatives of the state, provide a type of overall scaling of the dynamics, and give an improvement but not a total correction; the enriched models recover much of the transient dynamics, but certainly not all of the discrepancy for every combination of . While the performance in the transient regime could be improved, the linear embedded discrepancy operators show promise as discrepancy models, even in scenarios that extrapolate over initial conditions. The results also bring up many new questions.
For example, what is the effective dimension of the missing dynamics of the partial model? In other words, how many (and which) new random variables need to be introduced to effectively (i.e., within some tolerance) capture the error of the partial model? The initial results here suggest that the discrepancy between the partial and detailed models can, under some conditions, be adequately described with a relatively small number of discrepancy variables and parameters. An outstanding question is whether or not some estimate of this effective discrepancy dimension can be found a priori. Certainly, such an estimate would heavily rely on given knowledge of the detailed and partial models.
Another avenue to explore is the design and analysis of more elaborate discrepancy representations in the generalized Lotka–Volterra setting, including those with second (or higher) derivatives, memory, nonlinear terms, or some combination of these. Of course, a trade-off exists between the richness of the discrepancy representation and the computational expense of both the forward and inverse problems.
Finally, the detailed models (and thus also partial models) investigated here are quite simple; the interaction matrices are negative definite, diagonally dominant, and symmetric, with off-diagonal entries sampled from identical distributions. An immediate next step in this research is to examine the performance of linear embedded discrepancy operators after relaxing these restrictions on the random interaction matrices.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










