1. Introduction
Networks (graphs) with nodes (vertices) and edges (links) are a considerable simplification of complex patterns observed in real life, thus permitting studies of complex systems. For instance, the study of social interactions between individuals can be represented in the form of social networks [
1]. Researchers who published together can be related in a collaboration network [
2]. Movies and their respective critics can be presented as a bipartite graph with the edge-weight indicating a user-movie rating [
3] which further allow applications like recommender systems [
4]. The flexibility of networks and its vast literature on graph theory makes network science [
5,
6] extremely appealing to researchers.
An area of interest with significant importance is community detection, also known as graph clustering [
7], i.e., identifying groups of densely connected nodes. Traditionally, researchers have measured communities in terms of partition quality, known as modularity [
8]. A recovered community structure with high modularity implies good partitioning. To this date, community detection algorithms have evolved from traditional algorithms to the usage of complex learning algorithms like graph representation learning [
9,
10]. In graph representation learning, one can enforce nodes within the same community to share similar representations. These representations are learned by aggregating features from neighboring nodes. In addition, graph representation learning is extremely appealing because it provides a generalized application for downstream tasks such as link prediction [
11], classification [
12] and clustering [
13]. By exploiting existing literature on representation learning, these tasks can be solved simply by reusing existing machine learning techniques.
Among many types of graph representation learning algorithms, Graph Neural Network (GNN) has recently gained significant popularity. Inspired by Deep Learning methodologies, GNN is designed to follow a similar learning approach, but with graphs as its primary application. For instance, in graphs, convolutional layers are replaced with graph convolutional layers [
14]. The outcome is a translation of Deep Learning techniques from computer vision readily applied to graph data. Likewise, GNN inherits similar disadvantages from deep learning algorithms, which is widely known to be a black-box learning algorithm. To overcome this problem, machine learning researchers have explored explainable artificial intelligence (XAI) algorithms. Causal inference [
15] and Bayesian Deep Learning [
16,
17] are some examples of attempts to unravel the mysteries behind machine learning algorithms by presenting uncertainties and causal reasons.
From a different paradigm, generative models are equally appealing for introducing explainability. Stochastic Blockmodel (SBM) [
18,
19] is a popular approach to model networks. By proposing an assortative configuration on the stochastic matrix, one can generate networks that exhibit community structures. Leveraging on the reparameterization trick, Variational Autoencoder (VAE) [
20] improves explainability by introducing uncertainty to an autoencoder. Recently, Kipf and Welling [
21] proposed Variational Graph Autoencoder (VGAE), which results in research variants such as VGAECD [
22] and ARVGA [
23].
Albeit powerful, VGAE-based algorithm suffers from an optimization problem. When trained, it has tendencies to deviate from its primary objective in favor of the reconstruction of the input network and eventually lead to a posterior collapse [
24]. In this work, we focus our attention on a variant of VGAE, namely Variational Graph Autoencoder for Community Detection (VGAECD) [
22]. We found that optimizing the loss using stochastic gradient descent often leads to sub-optimal community structure when the model is initialized poorly.
Figure 1 demonstrates an example of the quality of detected communities (measured by NMI) with respect to the loss during training in a synthetic network generated by the LFR benchmark with
. We can observe that the training loss is consistently decreasing as expected. However, the NMI suddenly drops approximately after 80 epochs and gradually begins its re-ascent. This tendency has also been observed in other unsupervised deep learning algorithms [
25,
26,
27]. To circumvent this problem, one can train the unsupervised algorithm with a meta-learner [
25,
26]. More specifically, one can introduce a guide that prevents the algorithm from going astray. This new formulation comes with an advantage and disadvantage. Specifically, the weakness comes at the cost of more computation complexity.
Additionally, generalization becomes difficult because of the high coupling between the learner and the task of interest (task-dependent). Instead, in our work, we chose to leverage a variational solution. More specifically, we maximize the lower bound introduced in the Variational Autoencoder such that no additional modification is required on the original loss function. Instead, the optimization procedure follows a Neural Expectation-Maximization (NEM) algorithm [
28], which guarantees that communities do not collapse. This is possible because NEM can be formulated in terms of maximizing a variational lower bound [
29]. Maximizing this lower bound ensures that every new update is an improvement over the previous step. Furthermore, it has a theoretical guarantee for convergence up to local optima. We term our improved version, Variational Graph Autoencoder for Community Detection - Optimized (VGAECD-OPT).
To summarize, we improve VGAECD and propose a robust algorithm (VGAECD-OPT) for community detection. Our contributions are as follows,
The proposed algorithm, like VGAECD, inherits properties unique to generative models such as the possibility to generate a synthetic network with community structure. Such models can be useful to application areas such as high-performance computing [
32,
33]. On the other hand, the model itself can be used as a network anonymizer by inducing
artificial links or nodes on an existing social network [
34].
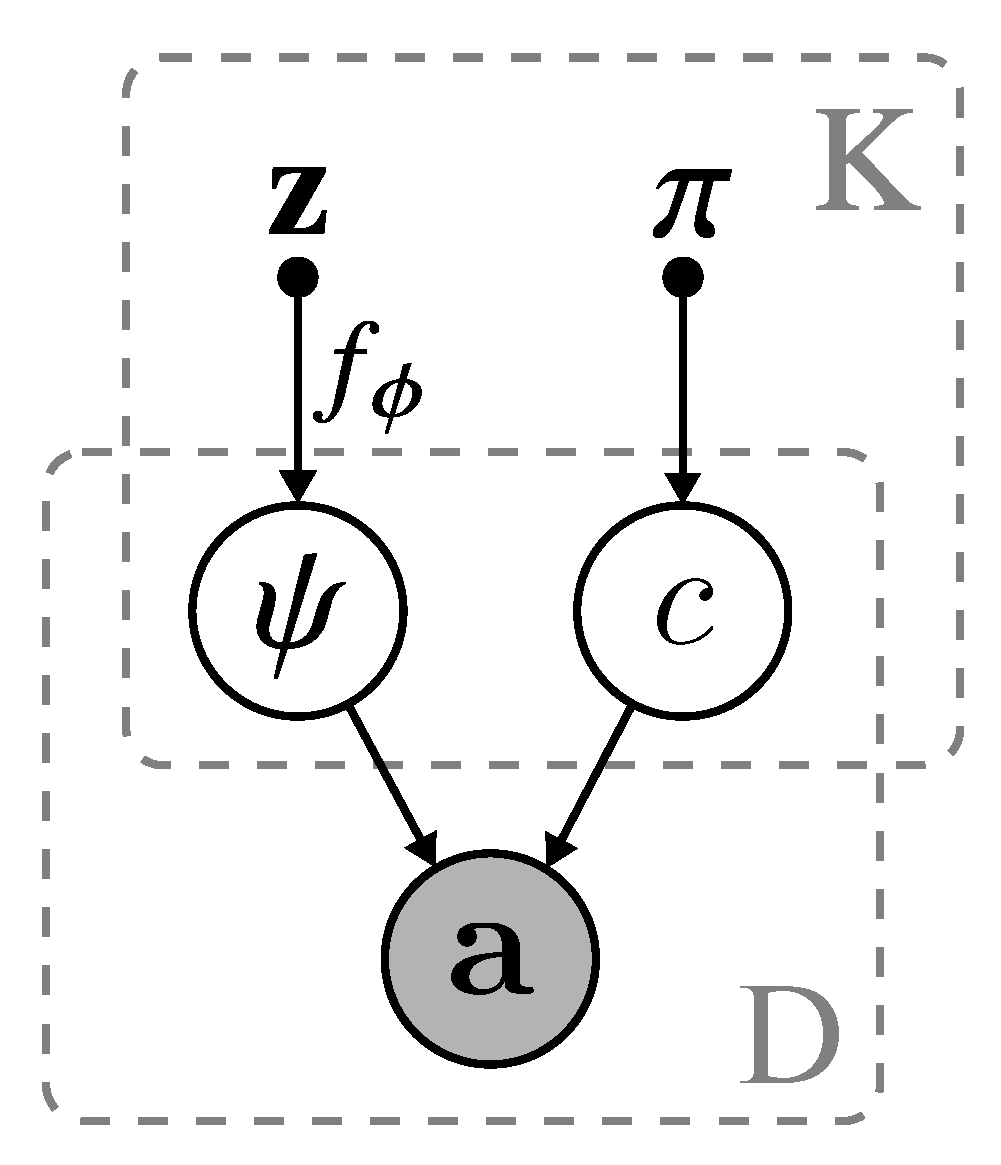
3. Problem Definition
Formally, a network with
N nodes can be defined as
, where
denotes the set of nodes and
is the set of edges. Incidentally, each node may be described by some features
where
defines a vector of real-values associated with node
with
D-dimension. Vectorizing the notations,
is the adjacency matrix of
. In this work, we consider the undirected and unweighted network
, such that
if
otherwise 0. Given the network
, we aim to partition the nodes in
into
K disjoint groups
such that nodes grouped within the same communities share a similar connectivity pattern. We define the connectivity pattern by the node’s edge probability
p. Specifically,
is the probability of connecting between nodes of the same community and
is the probability of connecting nodes between other communities. Consequently, the community structure is defined as,
We refer to this as the
modern view community structure definition as suggested in [
62]. This notion of community structure is a generalization to a probabilistic perspective.
Additionally, we further constrain our problem definition to the view of a generative model. Given a generative model,
infers the model parameters
from the observed network
. Concretely, we are interested to maximize,
Under this optimization condition, a similar graph,
with adjacency matrix
can be generated from the same set of parameters such that
defines the reconstruction probability of the original adjacency matrix
. According to Bayesian principles, one can say that the model is a good model when
and satisfies the condition of having community structures as defined in Equation (
1).
6. Results and Discussion
In this section, we compare our proposed model (VGAECD-OPT) with several baseline methods. Among the generative models, SBM is an unsupervised model that does not use representation learning. For methods such as VGAE, DeepWalk, and node2vec, the latent representation is first learned then a clustering algorithm such as k-means is used. The * symbol denotes methods that were confined to structural information only.
We begin by discussing the stability performance of VGAECD-OPT in contrast to VGAECD in
Section 6.1. In
Section 6.2 we discuss the performance on several synthetic datasets.
Section 6.3 provides in-depth discussion on VGAECD-OPT’s performance and
Section 6.4 compares the runtime and time complexity of VGAECD-OPT against baseline methods. Finally, we end this section with a discussion on the limitations of the VGAE framework in
Section 6.5.
6.1. Stability Performance
As discussed in
Section 4.3 and illustrated in
Figure 1, we show that optimizing VGAECD with standard SGD will eventually result in a deviation. To show that VGAECD-OPT does not exhibit such property, we illustrate VGAECD-OPT’s performance curve in
Figure 4. Since VGAECD-OPT optimizes
and
loss in two different steps, VGAECD-OPT is more stable under the same training settings as VGAECD. On the contrary, our proposed algorithm achieves much higher NMI performance when initialized (epoch 0). At epoch 80, we achieve similar performance as VGAECD (
Figure 1). After epoch 80, our algorithm continues to ascend without any decline in performance. Although we note that the rate of convergence for our loss is much slower in comparison to VGAECD, it does not hinder our main objective of achieving better community structure recovery.
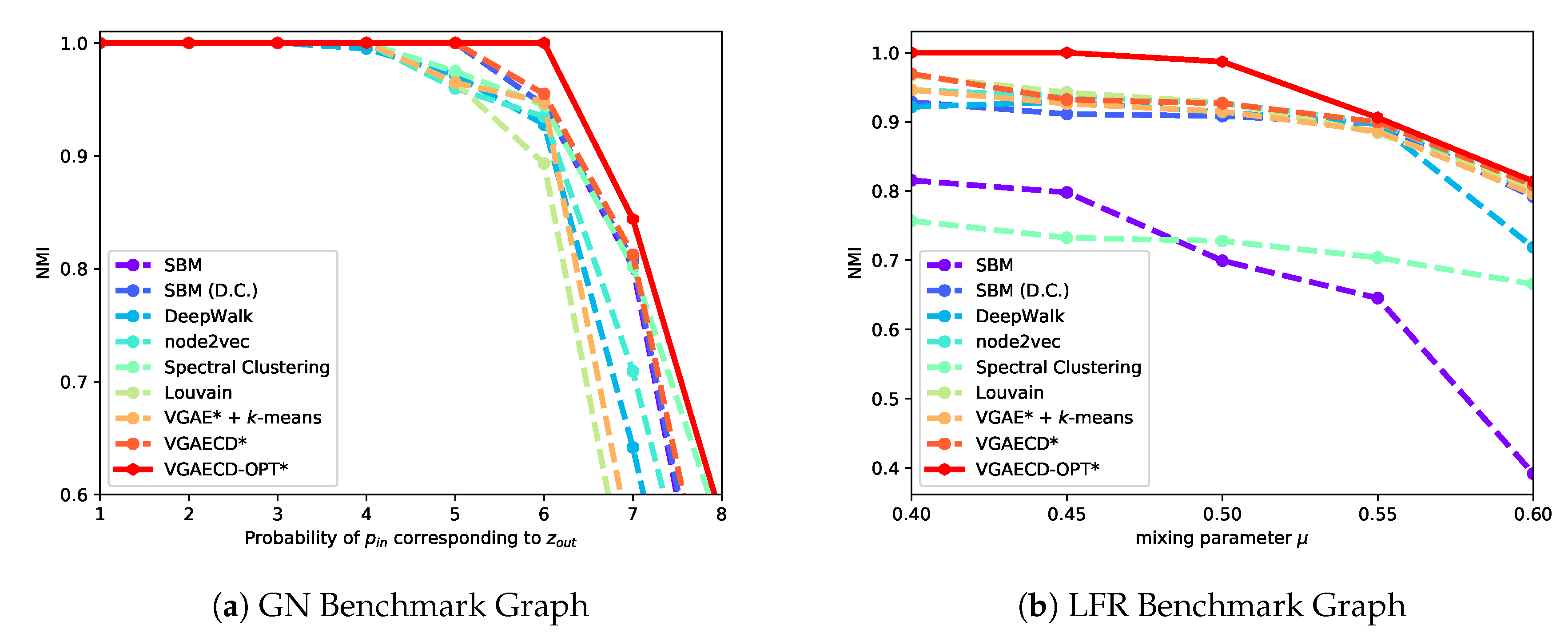
6.2. Performance on Synthetic Datasets
For starters, VGAECD-OPT is evaluated against existing discriminative and generative methods on two synthetic datasets. For methods that were confined to structural information only (i.e., absence of features), we denote them with an asterisk (*) sign. The results performed on synthetic datasets are shown in
Figure 5. As shown, VGAECD-OPT can recover community structures even in difficult settings (i.e.,
and
) meanwhile other algorithms exhibit difficulties. This proves that with linearization and dual optimization, VGAECD-OPT is much more stable than VGAECD. Its resiliency to posterior collapse has been mitigated, subsequently increasing the probability of community structure recovery.
6.3. Performance on Real-World Datasets
We now demonstrate the effectiveness of linearization and dual optimization approach towards real-world datasets.
Table 2 and
Table 3 demonstrates the performance of VGAECD-OPT on datasets without the presence of features. The arrows (↑ and ↓) indicate the direction towards better performance. For example, NMI (↑) indicates that the higher the value, the better the performance. Values marked in bold denote best-performing results. Additionally, we also note that the performance measure on ACC is subject to label oscillation. For instance, in a binary community detection task, communities are measured by an overlap between two covers (ground-truth and detected communities), but in classification tasks, exact label assignment assignments are accounted for (i.e., labeling a cat as a dog is a false positive).
As for competing baselines, we show that discriminative models such as Louvain’s algorithm, DeepWalk, and node2vec have competitive baseline performance. In general, Louvain’s method performs very well with modularity score. This is because Louvain’s method is by design an algorithm that maximizes modularity. However, this does not translate to true performance, as shown metrics with ground-truth measures (i.e., NMI, VI, and ACC). Node2vec and DeepWalk remain competitive in all datasets but performs poorly in Cora and PubMed datasets. These datasets contain features that determine the outcome of the algorithms’ performance. Among discriminative methods, Spectral Clustering has the highest variance in terms of performance. It performs extremely poor in PolBlogs like its generative model counterpart, the SBM. We reason that the algorithm is affected by hubs with high degrees like PolBlogs dataset [
19]. As a result, both algorithms pick these hubs as single node communities resulting in poorer performance.
On the other hand, generative models such as SBM performed poorly, mainly when datasets such as Cora and PubMed are used. Since SBM does not support features, it is difficult for SBM to thrive, especially when these datasets are feature-driven [
63]. Indeed, with VGAE-based approaches, the performance increases significantly. Most importantly, we note that VGAECD-OPT achieves the best performance among other variants.
In Karate dataset, it can be observed that VGAECD-SGC* and VGAECD-OPT* both performed poorer than VGAECD* in terms of NMI, VI, and ACC. Further analysis shows that the non-linearity of VGAECD was a contributing factor to its higher performance. However, as we demonstrate in
Table 3,
Table 4 and
Table 5, the presence of non-linearity was mostly negligible. Instead, the NMI performance improved when VGAECD adopts an SGC encoder. For baseline purposes, we introduced VGAECD-SGC, which comes with a linearized encoder but an absent dual optimizer. Coupled with dual optimization, VGAECD-OPT consistently shows improvements in contrast to VGAECD. We describe this with Equation (
13) such that
ensures each new community membership proposal follows proportionally to the loss.
6.4. Time Complexity Analysis
We now discuss the time complexity and runtime of the proposed algorithm. We divide our runtime analysis into four parts. In the first part, we will discuss the convergence rate of our proposed method. The second part analyzes the runtime performance of all methods on real-world datasets. The third part explores the scalability performance of our proposed method on synthetic networks. Finally, we present our analysis of the time complexity of all methods.
To measure convergence rate, we introduced an early stopping criterion (The early stopping criterion serves the purpose of measuring convergence rate only. In practice, algorithms run with a fixed number of epochs); when a specific NMI threshold is achieved, we terminate the algorithm. This allows fairer comparison since VGAECD-SGC and VGAECD-OPT converges faster than VGAECD. We present this result in
Table 6. We show a marginal improvement in speed when the encoder has been replaced with a linear encoder. Coupled with a dual optimization process, we can obtain a faster convergence rate, resulting in a fewer number of training iterations. For Karate dataset, VGAECD-OPT is ahead by 1 s, whereas in the Cora dataset, it achieved a speedup of almost
. In contrast to VGAECD-SGC, the proposed algorithm is faster on Karate and Cora datasets but is slower on PolBlogs on average run time. We find this to be insignificant since the standard deviation is more unstable.
For complete runtimes analysis, we allow all VGAE variants to complete 200 epochs without early stopping. We present these results in
Table 7. Overall, the fastest algorithm is Louvain’s method, which has been shown to run near-linear time in a very sparse network [
7]. In the worst case, it performs with time complexity of
as presented in
Table 8. On the other hand, our proposed algorithm performs better than state-of-the-art representation learning methods such as DeepWalk and node2vec on all real-world datasets (Karate, PolBlogs, Cora, and PubMed) despite being a generative model.
To demonstrate runtime scalability,
Figure 6 shows the algorithm’s expected runtime as the number of nodes and community increases. Each network is generated from an LFR benchmark with standard parameters (see
Section 5.3), but with a variable number of nodes and communities. The resulting network is summarized in
Table 9. Due to the nature of our proposed method being a generative model, the runtime performance approximately polynomial in runtime. Although SBM is a generative model, it employs different optimization strategies. For instance, the original implementation by Karrer and Newman [
19] struggles beyond 5000 number of nodes. To overcome this, we used a Markov Chain Monte Carlo sampling strategy to obtain reasonable runtime results. When nodes and communities are fewer than 10,000 and 10, respectively, the performance of our method is comparable to DeepWalk and node2vec. This is because both discriminative methods do not account for communities and
k-means is used instead, resulting in faster runtimes.
We now analyze the time complexity of VGAECD-OPT. From Algorithm 1, the encoder has a time complexity of where N is the number of nodes, D is the size of the trainable graph filter, l is the number of linear layers, and X is the dimension of each node features. Since the number of filters is constant with respect to the number of layers, we have . The constant 2 accounts for the computation of and . If we assume that the adjacency matrix is sparse, we can have an encoder with a complexity of . With NEM, we introduce two additional steps, which has a time complexity of for performing the Expectation-Maximization steps. Given many samples, we can further simplify this to . With an inner product decoder, it has a time complexity of . Overall, the final time complexity for one epoch is . In comparison, VGAECD has a time complexity of due to its two-layer GCN architecture. Thus, we can conclude that VGAECD-OPT is relatively competitive with VGAECD in terms of time complexity.
We list a summary of the competing method’s time complexity in
Table 8. Additionally, we note the following notations:
N—number of nodes,
—the number of random walks,
T—walk length,
W—window size,
D—the representation size and
K—number of communities.
6.5. Limitations of VGAE Framework
Overall, VGAE and its variants have proven to be an effective algorithm for learning networks with features. In this section, we highlight one shortcoming of VGAE that remains a challenge. In particular, VGAE has scaling difficulties. In VGAE, the inner product decoder uses a cross-entropy loss function. Unfortunately, this requires a dense by dense matrix multiplication, which requires a significant amount of memory for backpropagation purposes. In other literature, methods such as LINE [
50] and DeepWalk [
12] employs a negative sampling loss function for link prediction. In VGAE’s case, such implementation is not trivial as the task differs (reconstruction vs. link prediction). To explain this, let us consider an undirected unweighted graph
. One can observe that negative sampling considers the connectivity of each node by considering edges that are present and absent,
. Formally, negative sampling can be defined as
Here, we consider positive samples (edges) in the first term of Equation (
17) with
being the representation of node
and negative samples in the second term.
denotes the non-linear function and
K defines the number of negative samples which are drawn from some probability distribution
. The first term of Equation (
17) defines the likelihood of positive samples inducing an edge while the second term negates such probability. In other words, the loss function in Equation (
17) induces separation of the positive samples from the negative samples, in such a way that the representations of each positive edge would stay further apart from negative edges. In DeepWalk and LINE, the effectiveness of negative sampling is highly dependent on the context (random walker’s chain). Under the current VGAE framework, such a context does not exist. Implementing this in VGAE is non-trivial. Hence, to scale our model, we need more efficient decoders, which remains a challenging task.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}