Are Classification Deep Neural Networks Good for Blind Image Watermarking?


Abstract
:1. Introduction
1.1. Problem Formulation
- How to invert this highly non-linear extraction function? Once the feature vector is watermarked, how to map it back into the image space to create an image whose feature vector equals a given target vector?
- How to take into account a perceptual model ensuring the quality of the watermarked image?
- How to guarantee a required false positive level as there is no probabilistic modeling of these features?
- Which network architecture provides the best extraction function? Is it possible to robustify this extraction by fine-tuning the underlying network?
1.2. Prior Works
1.3. Structure of the Paper
2. Zero-Bit Watermarking
2.1. The Hypercone Detector
2.2. Linear and Invertible Extraction Function
3. Deep Learning Feature Extraction
3.1. Architecture
3.2. Adversarial Samples
3.3. Practical Solutions
4. Application to Zero-Bit Watermarking
4.1. Need of a Locality Transform
- Centering: ,
- PCA: ,
4.2. False Alarm Probability
4.3. The Objective Function and Imposed Constraints
4.4. Improving Robustness by Retraining
| Algorithm 1: Proposed watermarking algorithm. |
 |
5. Experiments
5.1. Experimental Protocol
5.2. Image Quality
5.3. From One Layer to Another
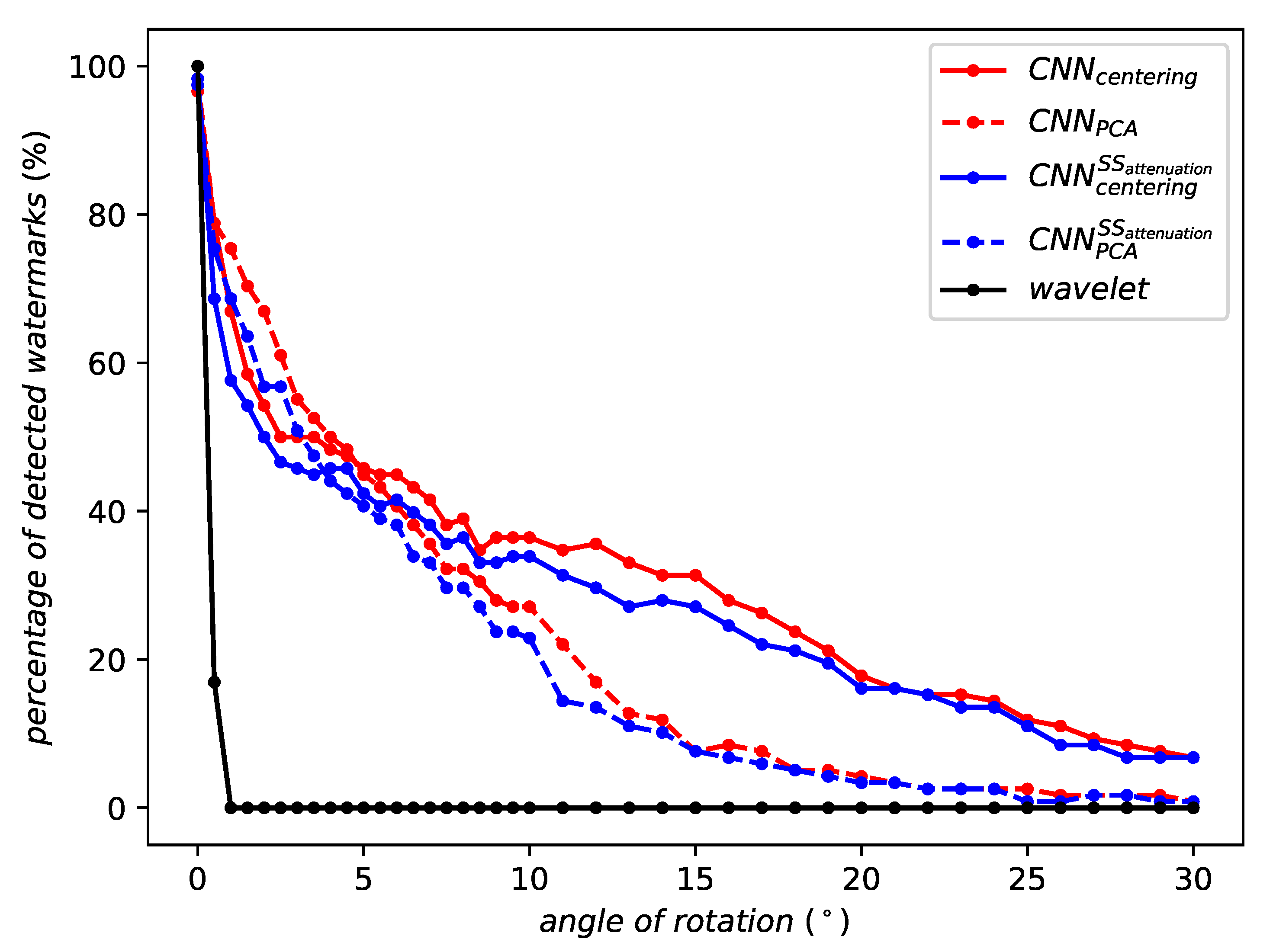
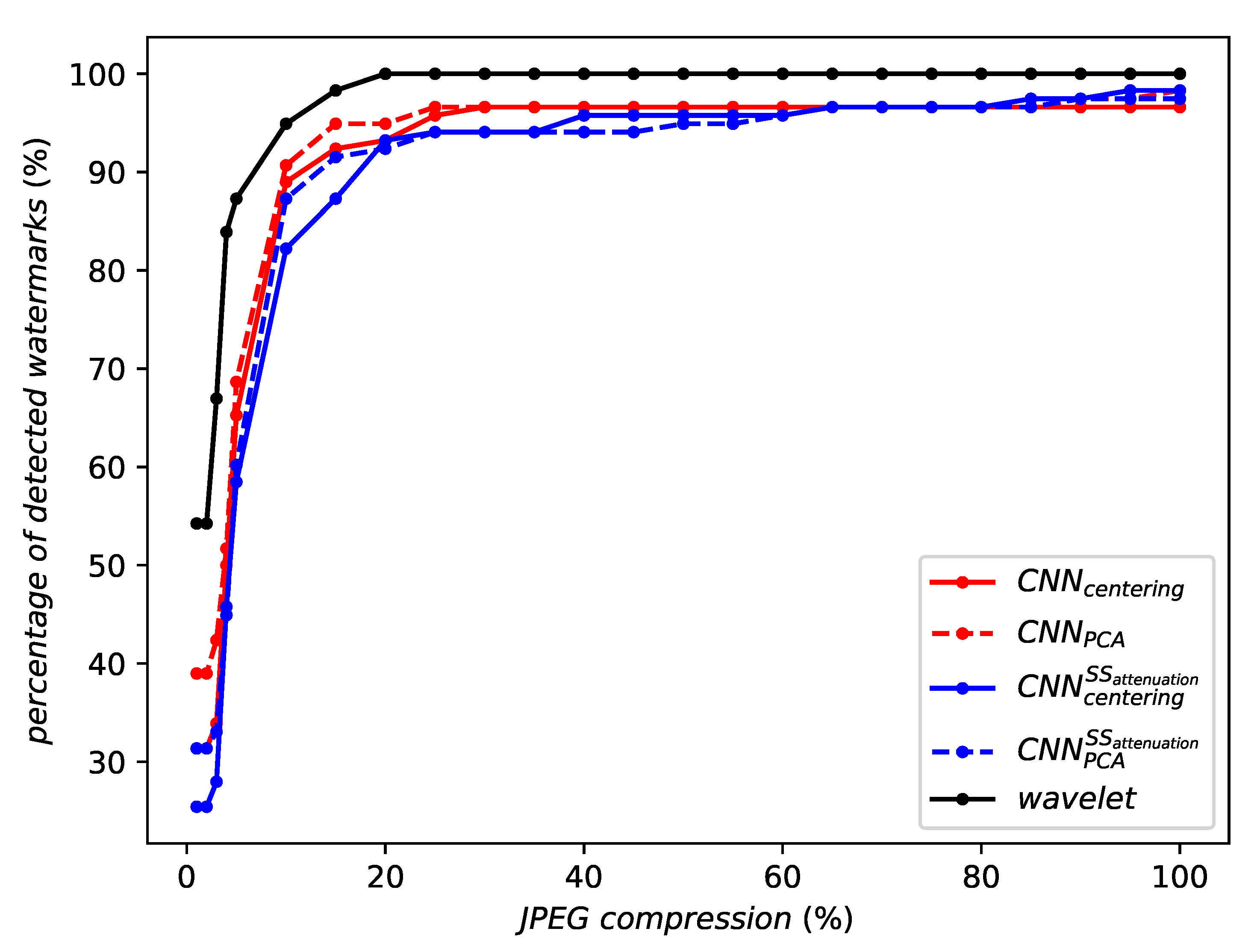
5.4. Robustness without Aggregation
5.5. Training Against Attacks
- Initially, no attacks. Images come from the ILSVRC2012 dataset.
- After 5 epochs, horizontal flips and scaling within and are introduced.
- After 20 epochs, vertical flips and rotation of up to (both clockwise and anticlockwise) are introduced. Scaling is extended to the range from to .
- After 35 epochs, rotation is extended up to .
- After 50 epochs, horizontal and vertical stretching up to are introduced. Rotation is extended to , scaling to the ranges from to .
- From epoch 150 on, attacks are performed with the following parameters: rotation up to , scaling from to , horizontal and vertical stretching up to and with horizontal and vertical flipping.
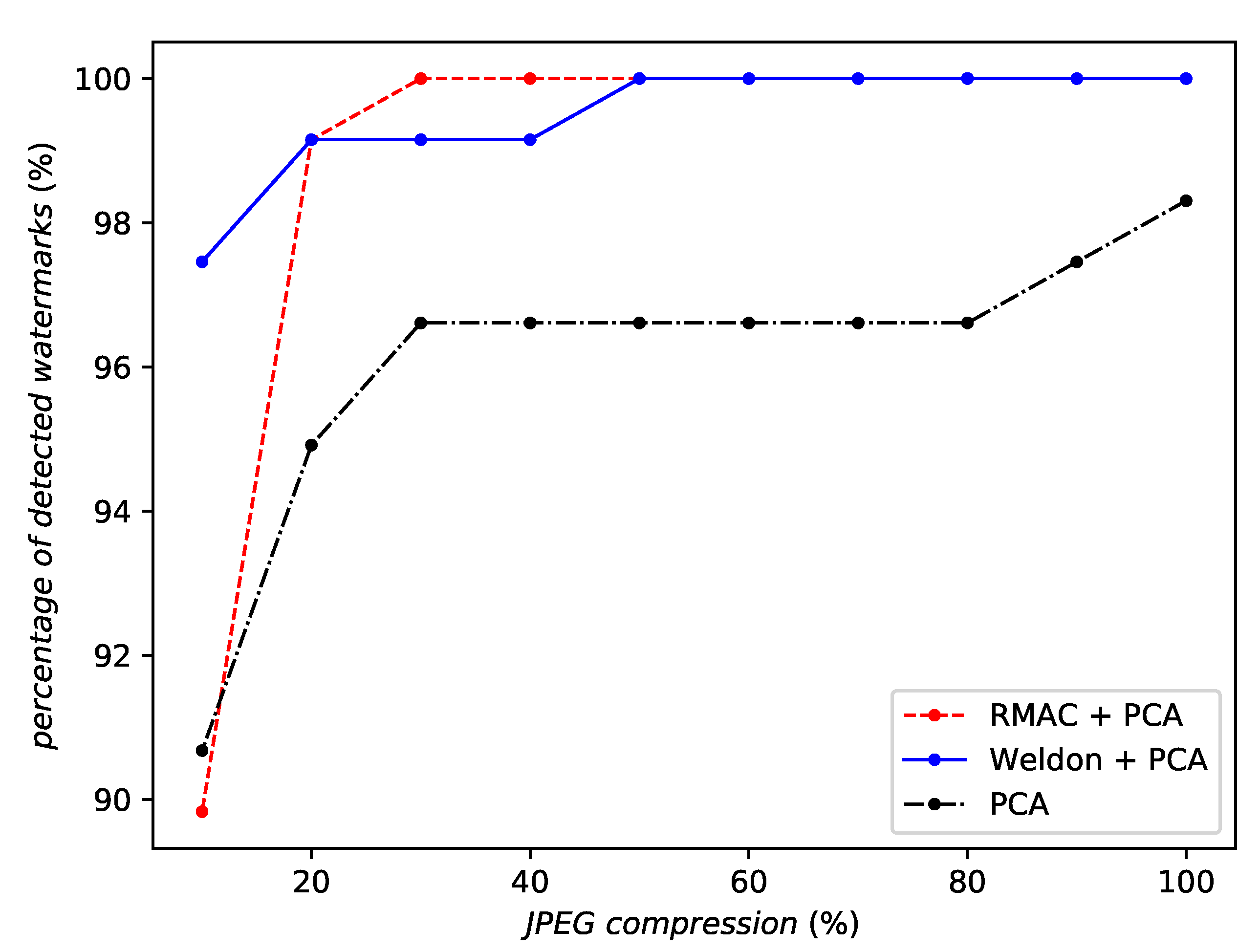
5.6. Robustness with Aggregation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A




References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2012, 60. [Google Scholar] [CrossRef]
- Siméoni, O.; Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Unsupervised object discovery for instance recognition. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV 2018), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Wu, J.; Yu, Y.; Huang, C.; Yu, K. Deep multiple instance learning for image classification and auto-annotation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3460–3469. [Google Scholar]
- Iscen, A.; Tolias, G.; Avrithis, Y.; Furon, T.; Chum, O. Panorama to Panorama Matching for Location Recognition. In Proceedings of the ACM International Conference on Multimedia Retrieval (ICMR 2017), Bucharest, Romania, 6–9 June 2017; ACM: New York, NY, USA, 2017. [Google Scholar]
- Radenović, F.; Tolias, G.; Chum, O. CNN Image Retrieval Learns from BoW: Unsupervised Fine-Tuning with Hard Examples. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 3–20. [Google Scholar]
- Gordo, A.; Almazán, J.; Revaud, J.; Larlus, D. Deep image retrieval: Learning global representations for image search. In Computer Vision – ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 241–257. [Google Scholar]
- Kanbak, C.; Moosavi-Dezfooli, S.M.; Frossard, P. Geometric robustness of deep networks: Analysis and improvement. arXiv 2017, arXiv:1711.09115. [Google Scholar]
- Nagai, Y.; Uchida, Y.; Sakazawa, S.; Satoh, S. Digital watermarking for deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 3–16. [Google Scholar] [CrossRef] [Green Version]
- Darvish Rouhani, B.; Chen, H.; Koushanfar, F. DeepSigns: A Generic Watermarking Framework for IP Protection of Deep Learning Models. arXiv 2018, arXiv:1804.00750. [Google Scholar]
- Yu, P.T.; Tsai, H.H.; Lin, J.S. Digital watermarking based on neural networks for color images. Signal Process. 2001, 81, 663–671. [Google Scholar] [CrossRef]
- Khan, A.; Tahir, S.F.; Majid, A.; Choi, T.S. Machine learning based adaptive watermark decoding in view of anticipated attack. Pattern Recognit. 2008, 41, 2594–2610. [Google Scholar] [CrossRef]
- Stolarek, J.; Lipiński, P. Improving digital watermarking fidelity using fast neural network for adaptive wavelet synthesis. J. Appl. Comput. Sci. 2010, 18, 61–74. [Google Scholar]
- Mun, S.; Nam, S.; Jang, H.; Kim, D.; Lee, H. A Robust Blind Watermarking Using Convolutional Neural Network. arXiv 2017, arXiv:1704.03248. [Google Scholar]
- Zhu, J.; Kaplan, R.; Johnson, J.; Li, F.-F. HiDDeN: Hiding Data With Deep Networks. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 682–697. [Google Scholar]
- Quiring, E.; Arp, D.; Rieck, K. Forgotten siblings: Unifying attacks on machine learning and digital watermarking. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy, London, UK, 24–26 April 2018. [Google Scholar]
- Vukotić, V.; Chappelier, V.; Furon, T. Are Deep Neural Networks good for blind image watermarking? In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Merhav, N.; Sabbag, E. Optimal watermark embedding and detection strategies under limited detection resources. IEEE Trans. Inf. Theory 2008, 54, 255–274. [Google Scholar] [CrossRef] [Green Version]
- Furon, T.; Bas, P. Broken Arrows. EURASIP J. Inf. Secur. 2008, 2008, 597040. [Google Scholar] [CrossRef] [Green Version]
- Comesana, P.; Merhav, N.; Barni, M. Asymptotically optimum universal watermark embedding and detection in the high-SNR regime. IEEE Trans. Inf. Theory 2010, 56, 2804–2815. [Google Scholar] [CrossRef]
- Cox, I.; Miller, M.; Bloom, J. Digital Watermarking; Morgan Kaufmann: Burlington, MA, USA, 2002. [Google Scholar]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2015, arXiv:1511.05879. [Google Scholar]
- Durand, T.; Thome, N.; Cord, M. Weldon: Weakly supervised learning of deep convolutional neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4743–4752. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Challenge on Learned Image Compression. Available online: http://www.compression.cc/challenge/ (accessed on 10 June 2018).
- Alakuijala, J.; Obryk, R.; Stoliarchuk, O.; Szabadka, Z.; Vandevenne, L.; Wassenberg, J. Guetzli: Perceptually Guided JPEG Encoder. arXiv 2017, arXiv:1703.04421. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Emb. Dim. | Average Marked Image | Average Rotation 5° |
|---|---|---|---|
| Original dimensionality, centering | |||
| pool1 | 802 816 | −64.49 | −0.68 |
| pool2 | 401 408 | −58.32 | −1.13 |
| pool3 | 200 704 | −52.25 | −3.80 |
| pool4 | 100 352 | −21.31 | −3.81 |
| pool5 | 25 088 | −4.95 | −2.24 |
| fc1 | 4 096 | −5.27 | −4.41 |
| fc2 | 4 096 | −4.11 | −1.70 |
| PCA to 256 dimensions | |||
| pool1 | 802 816 | −3.65 | −0.93 |
| pool2 | 401 408 | −12.30 | −1.36 |
| pool3 | 200 704 | −8.13 | −3.20 |
| pool4 | 100 352 | −8.19 | −2.42 |
| pool5 | 25 088 | −4.61 | −2.41 |
| fc1 | 4 096 | −5.61 | −3.20 |
| fc2 | 4 096 | −5.22 | −1.69 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vukotić, V.; Chappelier, V.; Furon, T. Are Classification Deep Neural Networks Good for Blind Image Watermarking? Entropy 2020, 22, 198. https://doi.org/10.3390/e22020198
Vukotić V, Chappelier V, Furon T. Are Classification Deep Neural Networks Good for Blind Image Watermarking? Entropy. 2020; 22(2):198. https://doi.org/10.3390/e22020198
Chicago/Turabian StyleVukotić, Vedran, Vivien Chappelier, and Teddy Furon. 2020. "Are Classification Deep Neural Networks Good for Blind Image Watermarking?" Entropy 22, no. 2: 198. https://doi.org/10.3390/e22020198
APA StyleVukotić, V., Chappelier, V., & Furon, T. (2020). Are Classification Deep Neural Networks Good for Blind Image Watermarking? Entropy, 22(2), 198. https://doi.org/10.3390/e22020198