3.1. Biggerstaff’s Analysis
We denote the likelihood ratio of a + prediction as
, estimated by:
(in words, the expression on the RHS is the true positive proportion divided by the false positive proportion or
sensitivity/(1–
specificity)). We denote the likelihood ratio of a − prediction as
, estimated by:
(in words, the expression on the RHS is the false negative proportion divided by the true negative proportion or (1–
sensitivity)/
specificity). Likelihood ratios are properties of a predictor (i.e., they are independent of prior probabilities) [
9]. Values
and
are the minimum requirements for a useful binary test; within these ranges, larger positive values of
and smaller positive values of
are desirable.
characterizes the extent to which a + prediction is more likely from
c crops than from
nc crops;
characterizes the extent to which a − prediction is less likely from
c crops than from
nc crops.
Now, working in terms of odds (
o) rather than probability (
p) (with
o =
p/(1−
p)), we can write versions of Bayes’ Rule, for example:
and:
Thus, a + prediction increases the posterior odds of
c status relative to the prior odds by a factor of
and a – prediction decreases the posterior odds of
c status relative to the prior odds by a factor of
. Biggerstaff [
10] used Equations (3) and (4) to make pairwise comparisons of binary tests (with both tests applied at the same prior odds), premised on the availability only of the sensitivities and specificities corresponding to the two tests’ operational classification rules (for example, when considering tests for application based on their published ROC curve summary statistics,
sensitivity and
specificity).
At this point, we refer to a previously published phytopathological data set [
11] in order to illustrate our analysis. Note, however, that the analysis we present is generic, and is not restricted to application in one particular pathosystem.
Table 2 summarizes data for five different scenarios, based in essence on five different normalized prediction-realization tables, derived from the original data set and discussed previously in [
6] in the context of decision making in epidemiology.
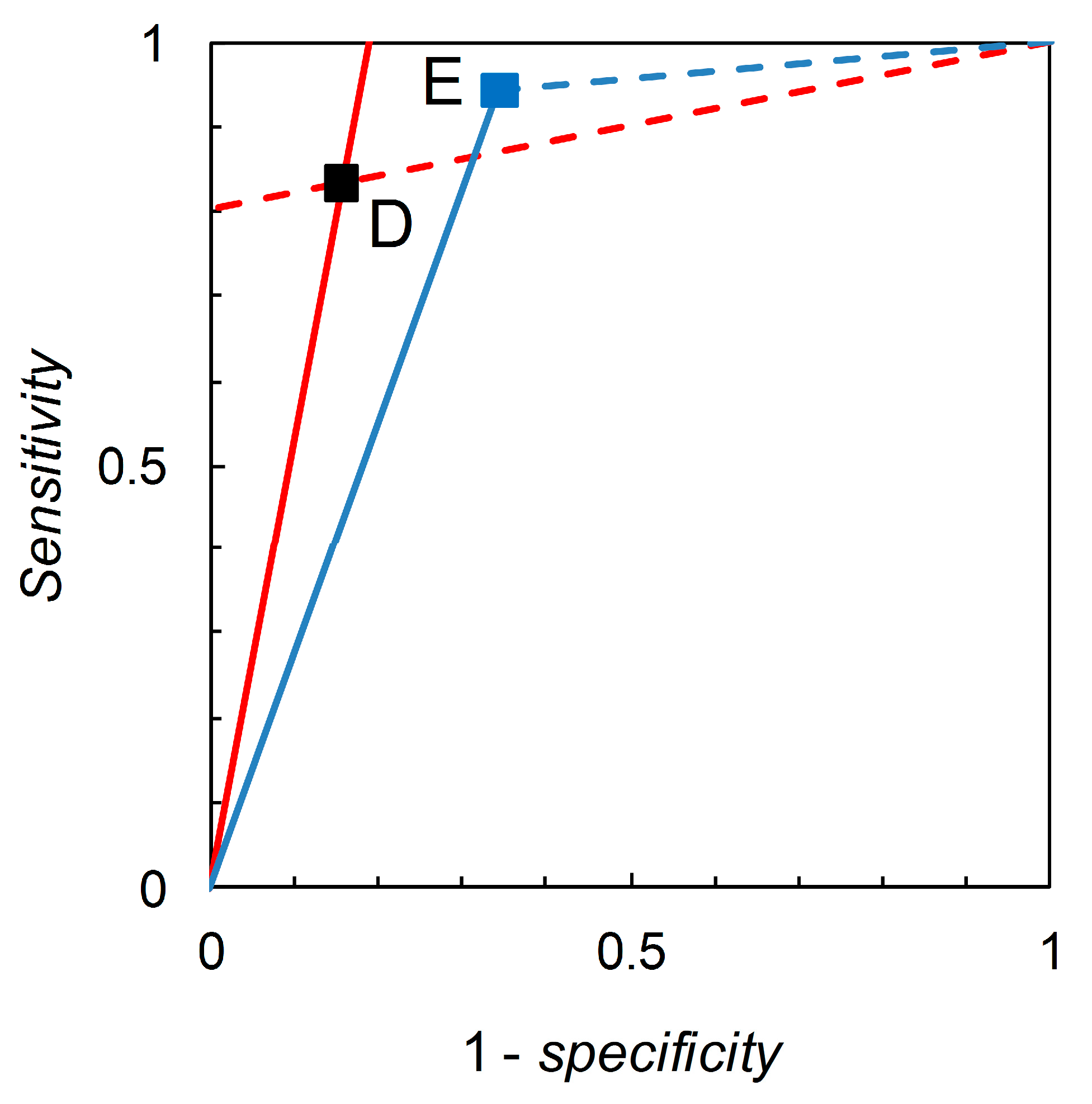
Recall that we are interested in probability (or odds) revision calculated on the basis of a forecast. For illustration, we first consider the pairwise comparison of the tests derived from Scenario B (reference) and Scenario C (comparison) made at
= 0.05 (
Table 2). Madden [
6] gives a detailed comparison based on knowledge of the full ROC curve derived from field experimentation. Biggerstaff’s analysis essentially represents an attempt to reverse engineer a similar comparison based only on knowledge of the tests’ published sensitivities and specificities. Scenario B yields
sensitivity = 0.833 and
specificity = 0.844, so we have
= 5.333 and
= 0.198. Scenario C yields
sensitivity = 0.390 and
specificity = 0.990, so we have
= 39.000 and
= 0.616. Thus, Scenario C’s test is superior in terms of
values but inferior in terms of
values (even though its
sensitivity is lower and
specificity higher than that of the reference test). As long as we restrict ourselves to pairwise comparisons of binary tests at the same prior probability we have a simple analysis that leads, via calculation of likelihood ratios, to an evaluation of tests made on the basis of Bayesian posteriors (directly in terms of posterior odds, but these are easily converted to posterior probabilities if so desired). The diagrammatic version of this comparison is shown in
Figure 1. The likelihood ratios graph comprises two single-point ROC curves. A similar analysis for Scenario D (reference) and Scenario E (comparison) (
Figure 2) shows that Scenario E’s test is inferior in terms of
values but superior in terms of
values (even though its
sensitivity is higher and
specificity lower than that of the reference test).
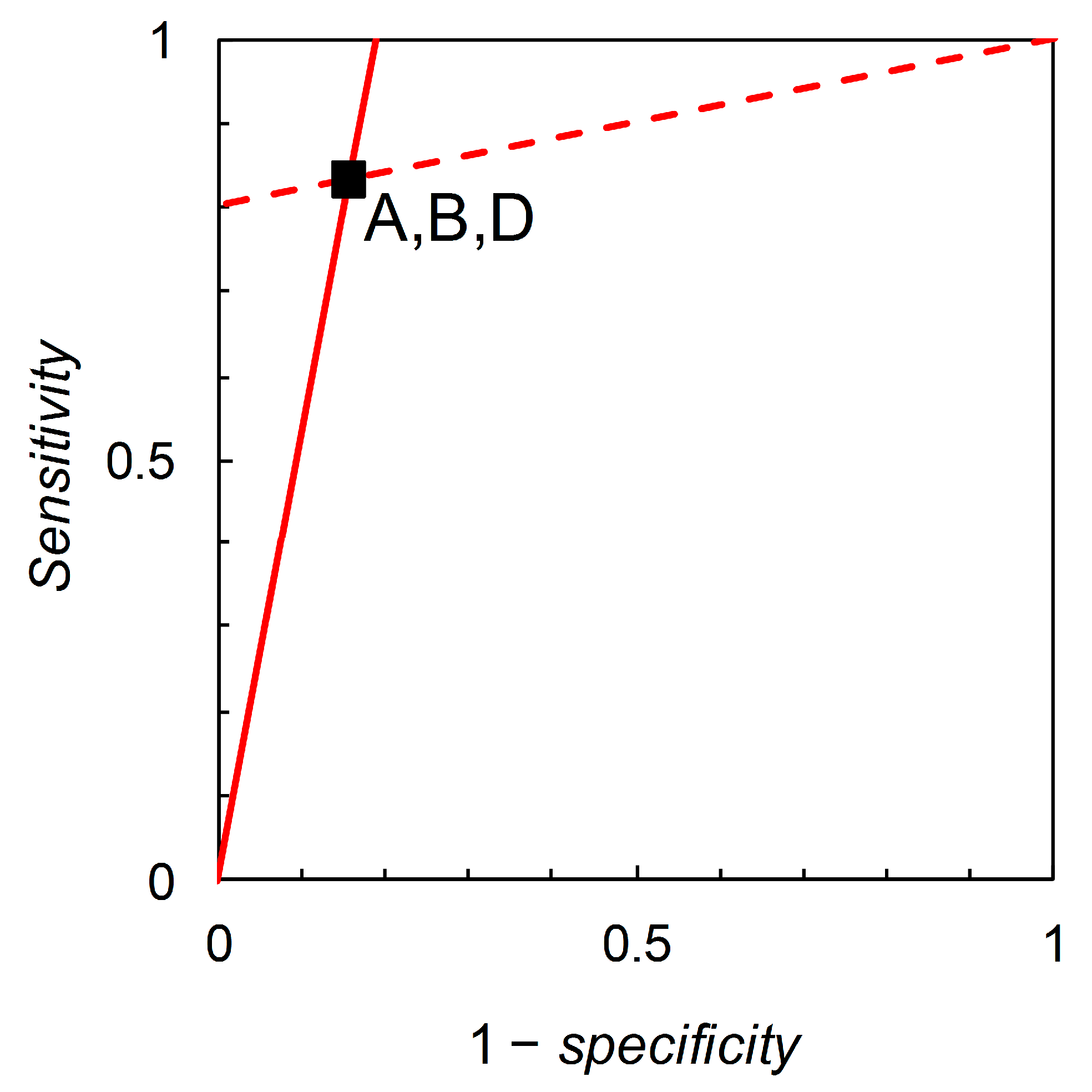
Referring back to
Table 2, the likelihood ratios, and corresponding graphs, for Scenarios A, B and D would be numerically identical. It is in this context that the information theoretic properties of likelihood ratios graphs (not pursued by Biggerstaff) are of interest. To elaborate further, we will require an estimate of the prior probability
. This is beyond what Biggerstaff’s analysis allowed, but it is not so unlikely that such an estimate might be available. For example, a
value is provided for any test for which a numerical version of the prediction-realization table (see
Table 1) is accessible.
For information quantities, the specified unit depends on the choice of logarithmic base; bits for log base 2, nats for log base
e, and hartleys (abbreviation: Hart) for log base 10 [
12]. Our preference is to use base
e logarithms, symbolized ln, where we need derivatives, following Thiel [
7]. In this article, we will also make use of base 10 logarithms, symbolized log
10, where this serves to make our presentation straightforwardly compatible with previously published work, specifically that of Johnson [
13]. To convert from hartleys to nats, divide by log
10(
e); or to convert from nats to hartleys, divide by ln(10). When logarithms are symbolized just by log, as immediately following, this indicates use of a generic format such that specification of a particular logarithmic base is not required until the formula in question is used in calculation.
We start with disease prevalence as an estimate of the prior probability of need for a crop protection intervention, and seek to update this by application of a predictor. The information required for certainty (i.e., when the posterior probability of need for an intervention is equal to one) is then denominated in the appropriate information units. However, a predictor typically does not provide certainty, but instead updates to < 1. The information still required for certainty is then in the appropriate information units. We see from that the term represents the information content of prediction i in relation to actual status c in the appropriate information units. Provided the prediction is correct (i.e., in this case, i = +), the posterior probability is larger than the prior, and thus information content of the positive predictive value is > 0. In general, the information content of correct predictions is > 0. Predictions that result in a posterior unchanged from the prior have zero information content and incorrect predictions have information content < 0.
Here, we consider the information content of a particular forecast, averaged over the possible actual states. These quantities are
expected information contents, often referred to as relative entropies. For a binary test:
for the forecast
i = + and:
for the forecast
i = –. Relative entropies measure expected information consequent on probability revision from prior
to posterior
after obtaining a forecast. Relative entropies are ≥ 0, with equality only if the posterior probabilities are the same as the priors. Larger values of both
and
are preferable, as being indicative of forecasts that, on average, provide more diagnostic information.
We can write the relative entropies
and
in terms of
sensitivity,
specificity and (constant) prior probability. Working here in natural logarithms, and recalling that
,
, and
we have:
in nats and:
again in nats. Now we can use these formulas to plot sets of iso-information contours for constant relative entropies
and
on the graph with axes
sensitivity and 1 –
specificity, for given prior probabilities. From Equation (7) we obtain:
the solution of which is the straight line
, which yields
. From Equation (8) we obtain:
the solution of which is the straight line
, which yields
. Thus, we find that iso-information contours for
and
are straight lines on the graph with axes
sensitivity and 1 –
specificity, i.e., Biggerstaff’s likelihood ratios graph (see
Figure 3).
Now consider Scenarios A, B and D; from the data in
Table 2, we calculate likelihood ratios
= 5.333 and
= 0.198 for all three scenarios (these are the slopes of the lines shown in
Figure 3). However, the three scenarios differ in their prior probabilities:
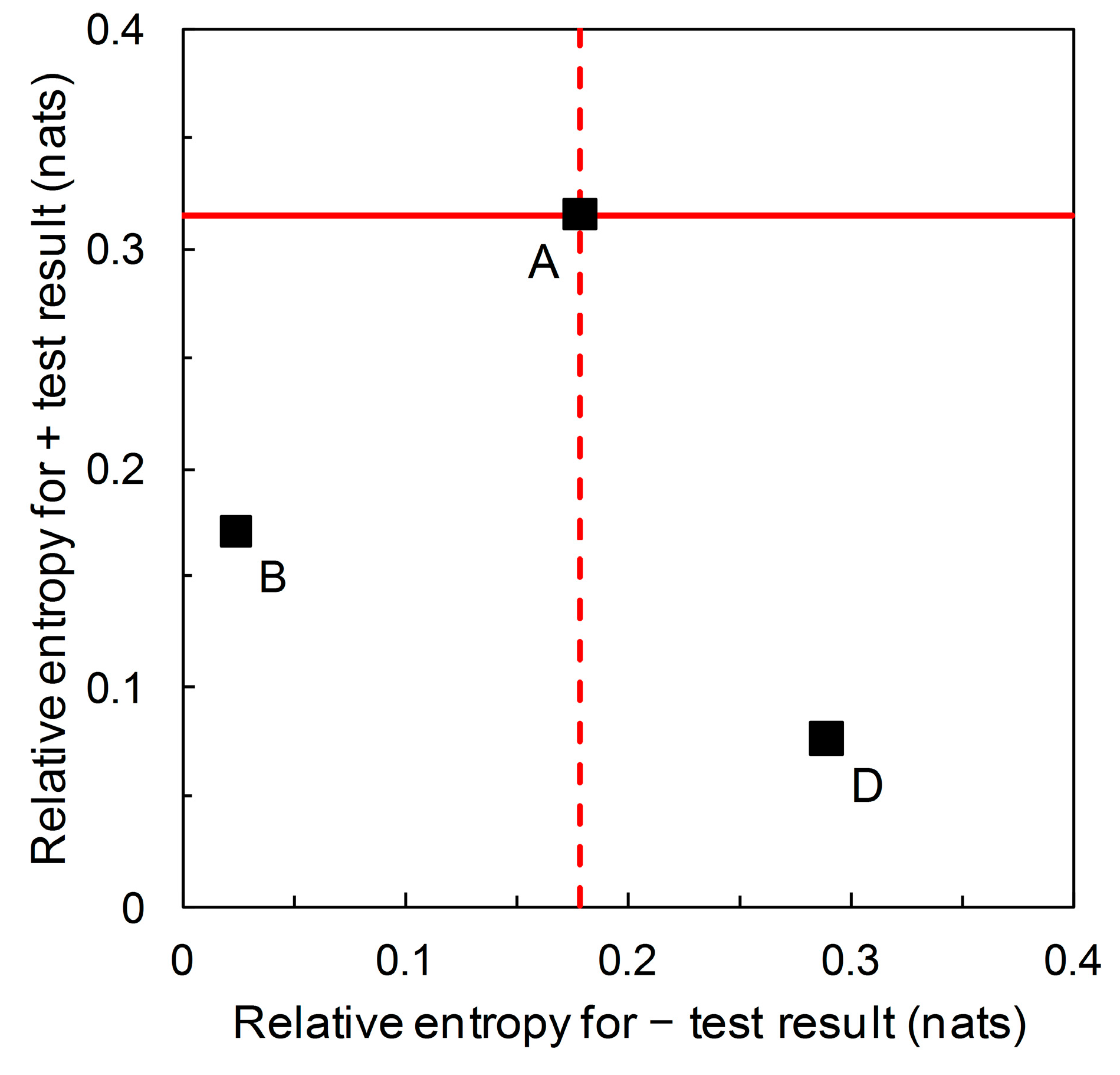
= 0.36, 0.05, 0.85 for A, B, and D respectively. This situation may arise in practice when a test is developed and used in one geographical location, and then subsequently evaluated with a view to application in other locations where the disease prevalence is different. The difference in test performance is reflected by the relative entropy calculations. For Scenario A, we calculate relative entropies
= 0.315 and
= 0.179 (both in nats, these characterize the lines shown in
Figure 3 interpreted as iso-information contours for the expected information contents of + and – forecasts respectively). For Scenario B, we calculate
= 0.171 and
= 0.024 nats. For Scenario D,
= 0.076 and
= 0.289 nats. Thus we may view Biggerstaff’s likelihood ratios graph from an information theoretic perspective. While likelihood ratios are independent of prior probability, relative entropies are functions of prior probability. There is further discussion of relative entropies, including calculations for Scenarios C and E, in
Section 3.3.
3.2. Johnson’s Analysis
Johnson [
13] suggested transformation of the likelihood ratios graph (e.g.,
Figure 1,
Figure 2 and
Figure 3), such that the axes of the graph are denominated in log likelihood ratios. At the outset, note that Johnson works in base 10 logarithms and that this choice is duplicated here, for the sake of compatibility. Thus, although Johnson’s analysis is not explicitly information theoretic, where we use it as a basis for characterizing information theoretic quantities, these quantities will have units of hartleys. Note also that Johnson calculates
and
but here we take account of the signs of the log likelihood ratios. Fosgate’s [
14] correction of Johnson’s terminology is noted, although this does not affect our analysis at all.
From Equation (3), we write:
and from Equation (4):
with
> 0 (larger positive values are better) and
< 0 (larger negative values are better) for any useful test. As previously, the objective is to make pairwise comparisons of binary tests (with both tests applied at the same prior odds), premised on the availability only of the sensitivities and specificities corresponding to the two tests’ operational classification rules.
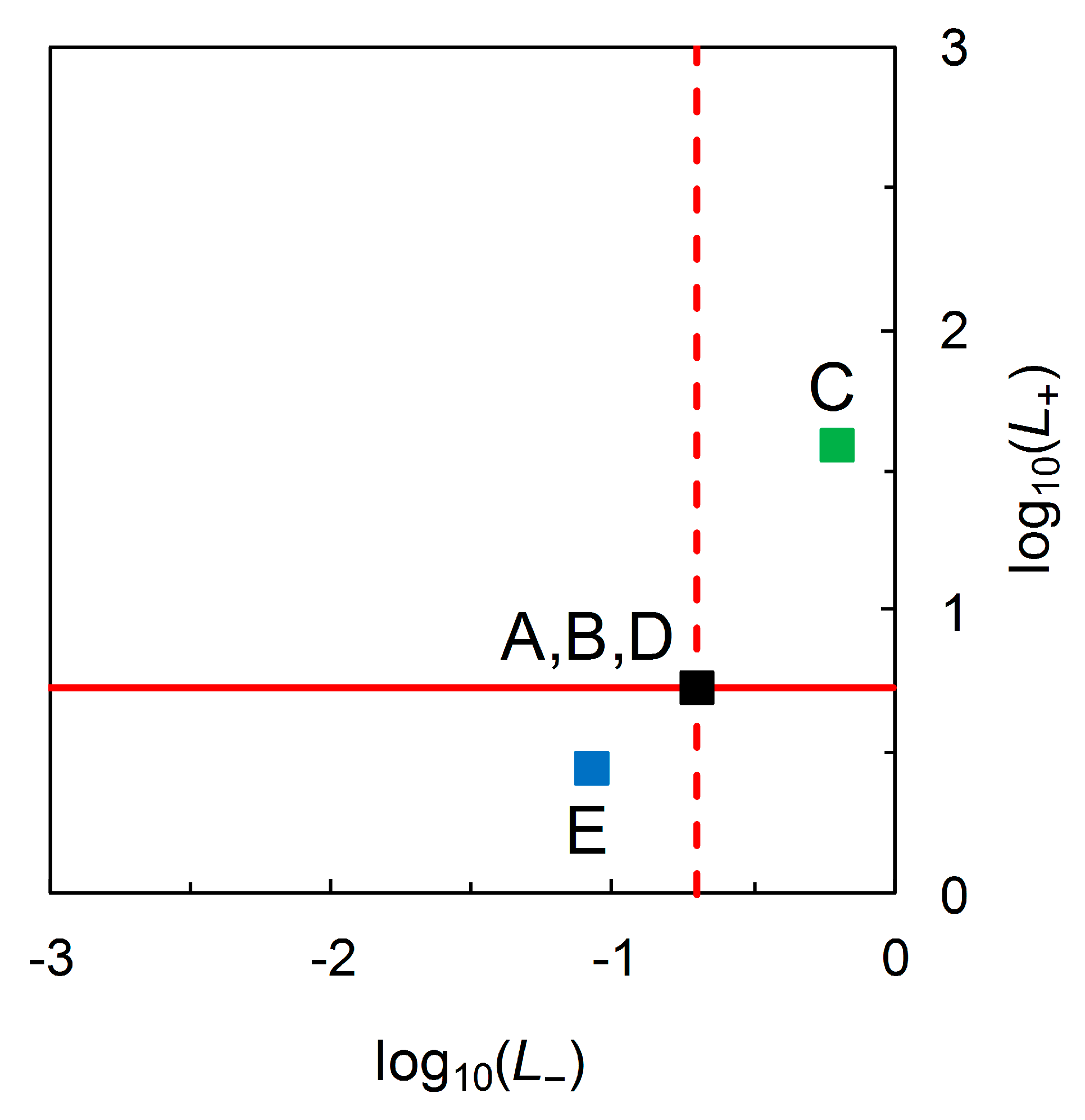
With Scenario B as the reference test and Scenario C as the comparison test, we find Scenario C’s test is superior in terms of
values but inferior in terms of
values (
Figure 4). With Scenario D as the reference test and Scenario E as the comparison test, we find Scenario E’s test is inferior in terms of
values, but superior in terms of
(
Figure 4). Moreover, we find that the transformed likelihood ratios graph still does not distinguish visually between Scenarios A, B and D (
Figure 4). Thus, the initial findings from the analysis of the scenarios in
Table 2 are the same as previously.
Now, as with Biggerstaff’s [
10] original analysis, we seek to view Johnson’s analysis from an information theoretic perspective. As before, we will require an estimate of the prior probability
. After some rearrangement, we obtain from Equation (11):
where
(> 0) and
(< 0) on the LHS are information contents (as outlined in
Section 3.1) with units of hartleys. From Equation (12):
where
(< 0) and
(> 0) on the LHS are information contents, again with units of hartleys. Thus, we recognize that log
10 likelihood ratios also have units of hartleys.
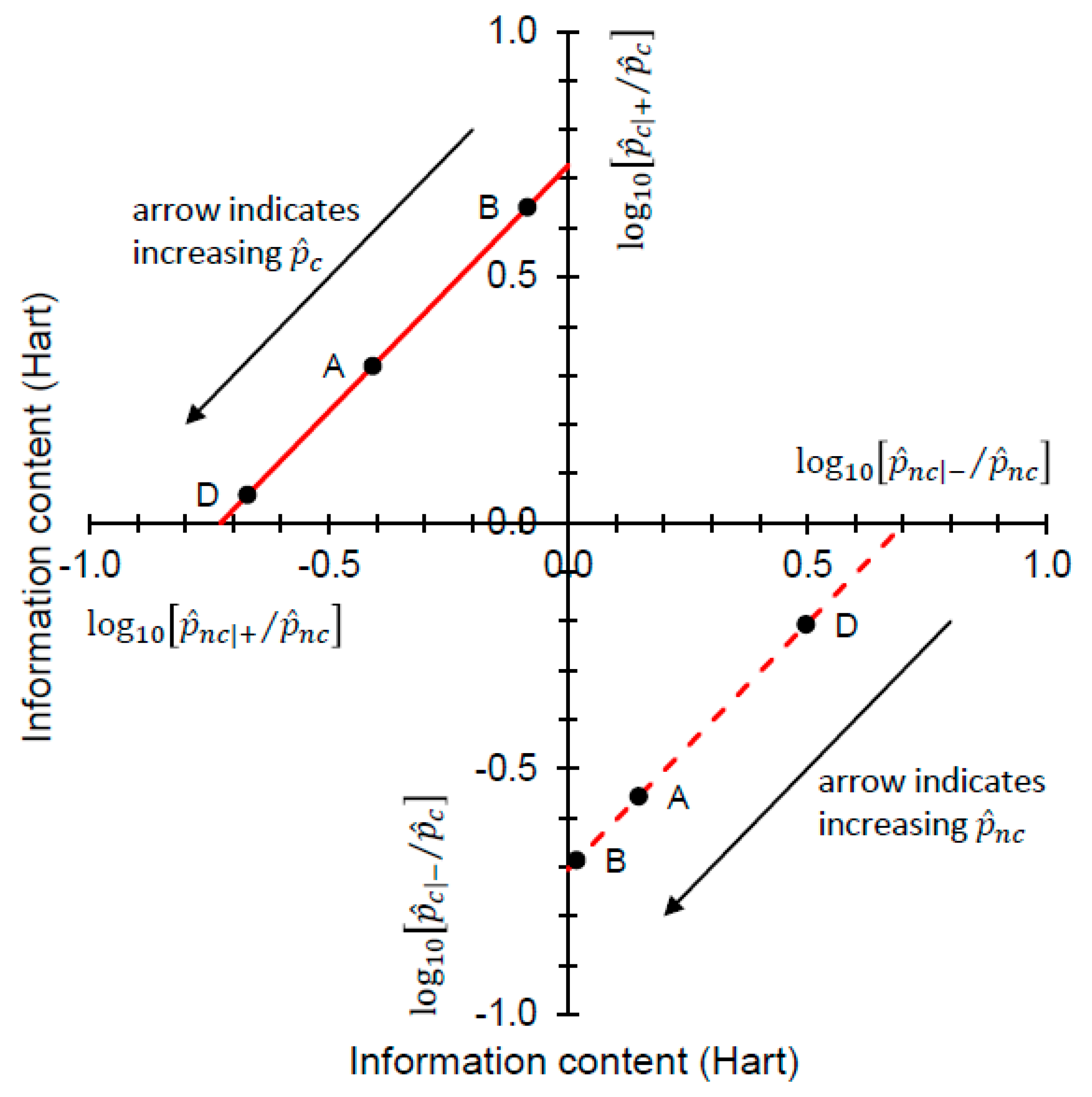
Figure 5 shows the information theoretic characteristics of Johnson’s analysis when data on priors are incorporated, by drawing log
10-likelihood contours on a graphical plot that has information contents on the axes.
In
Figure 5, both the
and
contours always have slope = 1. As the decompositions characterized in Equations (13) and (14) show, any (constant) log
10 likelihood ratio is the sum of two information contents. Looking at the “north-west” corner of
Figure 5 and taking Scenarios A, B, and D from
Table 2 as examples, we have
= 0.642, 0.319, 0.056 Hart and
= −0.085, −0.408, −0.671 Hart for
= 0.05 (B), 0.36 (A), 0.85 (D), respectively. In each case, Equation (13) yields
= 0.727 Hart. Looking at the “south-east” corner of
Figure 5, again taking Scenarios A, B, and D from
Table 2 as examples, we have
= 0.498, 0.148, 0.018 Hart and
= −0.207, −0.556, −0.687 Hart for
= 0.15 (D), 0.64 (A), 0.95 (B), respectively. In each case, Equation (14) yields
= −0.704 Hart. Thus we have an information theoretic perspective on Johnson’s analysis when data on priors are available, and this time one that separates Scenarios A, B and D visually (
Figure 5).
3.3. A New Diagrammatic Format
Biggerstaff’s [
10] diagrammatic format for binary predictors allows an information theoretic interpretation once the data on prior probabilities have been incorporated. This distinguishes predictors with the same likelihood ratios analytically, but not visually. Johnson’s [
13] transformed version of Biggerstaff’s diagrammatic format also allows an information theoretic interpretation once data on prior probabilities are incorporated. This approach distinguishes predictors with the same likelihood ratios both analytically and visually, but does not contribute to the comparison and evaluation of predictive values of disease forecasters.
We now return to the information theoretic interpretation of Biggerstaff’s likelihood ratios graph (and revert to working in natural logarithms for continuity with previous analysis based on
Figure 3). In
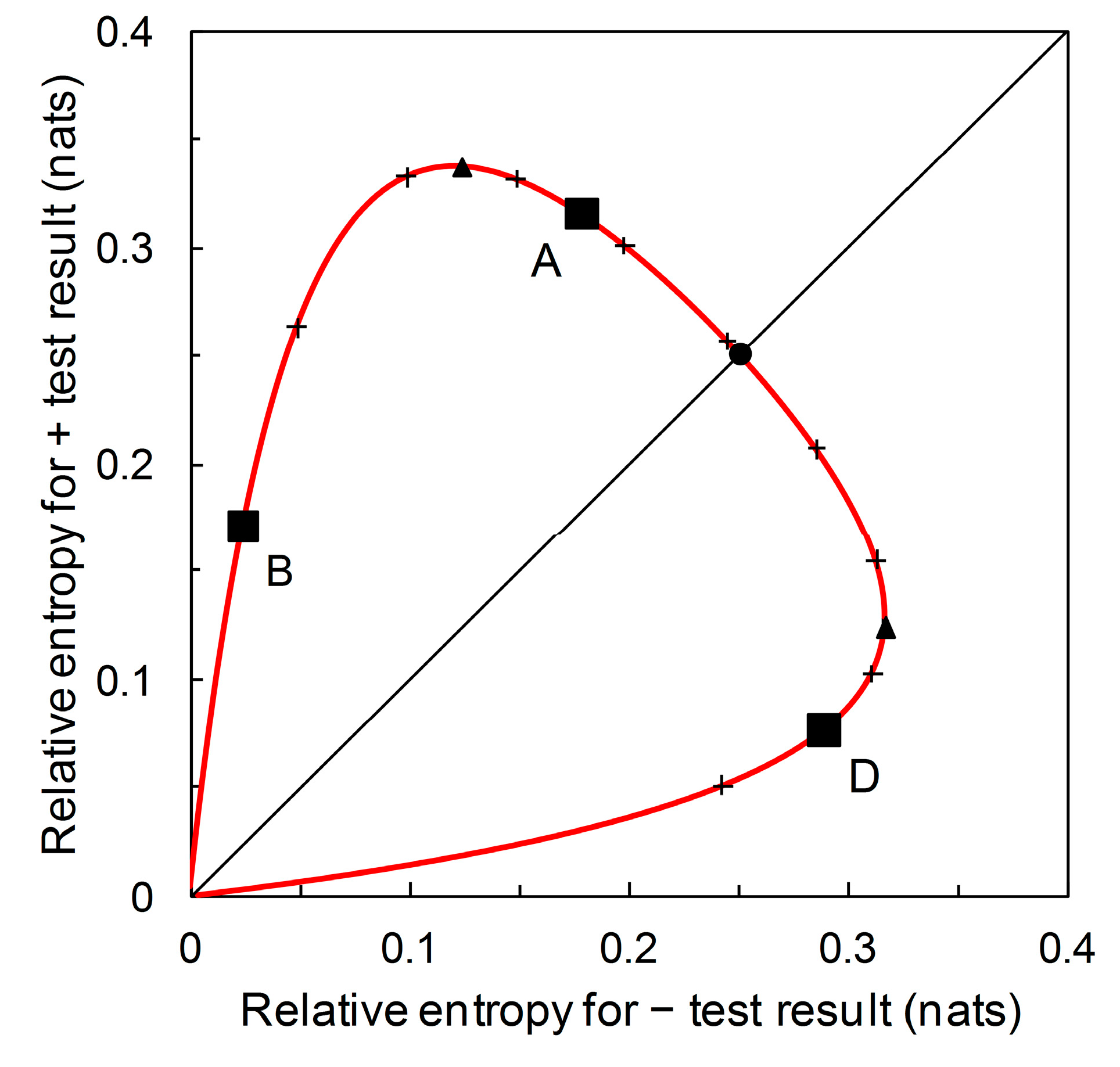
Figure 3, the likelihood ratios are the slopes of the lines on the graphical plot. The lines themselves are relative entropy contours, the value of which depends on prior probability. We can now visually separate scenarios that have the same likelihood ratios but different relative entropies (e.g., A, B, D in
Table 2) by calculating the graph with relative entropies
and
on the axes of the plot (
Figure 6). If we consider the predictor based on Scenario A as the reference, then the predictor based on Scenario B falls in the region of
Figure 6 indicating comparatively less information is provided by both + and – predictions, while the predictor based on Scenario D falls in the region indicating comparatively less diagnostic information is provided by + predictions but comparatively more by − predictions.
There is an alternative view of the diagrammatic format presented in
Figure 6. Scenarios A, B and D all have the same likelihood ratios,
= 5.333 and
= 0.198 (see
Figure 3). What differs between scenarios is the prior probability
. We can remove the gridlines indicating the relative entropies for Scenario A and plot the underlying prior probability contour (
Figure 7). In
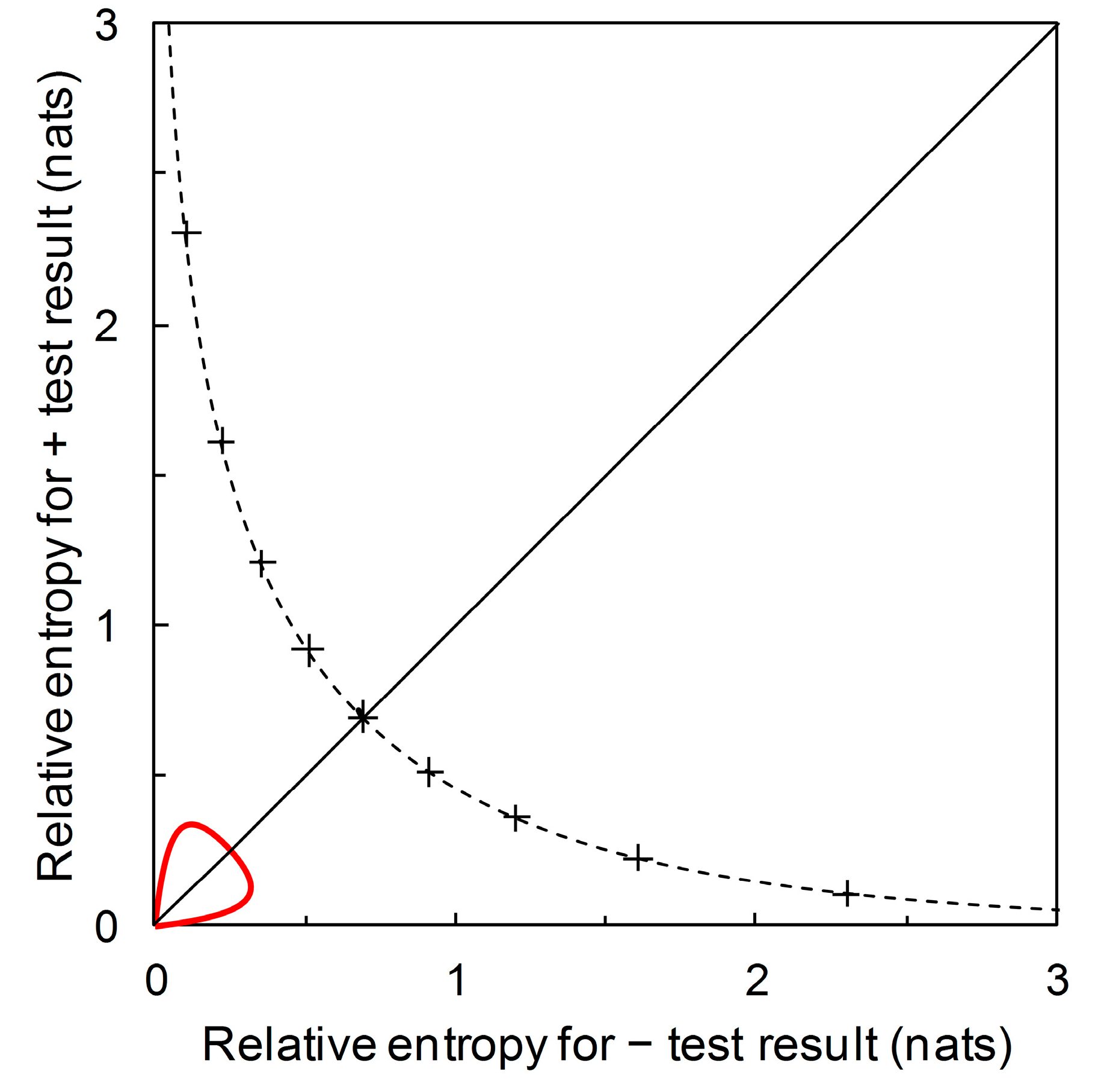
Figure 7, starting at the origin and moving clockwise, prior probability increases as we move along the contour. The contour has maximum points with respect to both the horizontal axis and the vertical axis. The maximum value of the contour with respect to the horizontal axis is:
and the maximum value of the contour with respect to the vertical axis is:
The corresponding values of
and
, respectively, can then be calculated by substitution into Equations (7) and (8). The two maxima (together with the origin) divide the prior probability contour into three monotone segments (see
Figure 7). As
increases, we observe a segment where
and
are both increasing (this includes Scenario B), then one where
is decreasing and
is increasing, this includes Scenario A), and then one where
and
are both decreasing (this includes Scenario D).
From
Figure 7, we see that for the predictor based on Scenarios A, B and D, a + prediction provides most diagnostic information around prior probability 0.2 <
< 0.3. A – prediction provides most diagnostic information around prior probability 0.7 <
< 0.8. Recall that this contour describes performance (in terms of diagnostic information provided) for predictors with
sensitivity = 0.833 and
specificity = 0.844 (
Table 2) (alternatively expressed as likelihood ratios
= 5.333 and
= 0.198). No additional data beyond
sensitivity and
specificity are required in order to produce this graphical plot; that is to say, by considering the whole range of prior probability we remove the requirement for any particular values. The point where the contour intersects the main diagonal of the plot is where
=
. In this case, we find that
=
at prior probability ≈ 0.5 (
Figure 7). At lower prior probabilities, + predictions provide more diagnostic information than – predictions, while at higher prior probabilities, the converse is the case. This contour’s balance of relative entropies at prior probability ≈ 0.5 is noteworthy because it is not necessarily the case that there is always scope for such balance.
Recall from
Section 3.1 that we start with disease prevalence as an estimate of the prior probability
of need for a crop protection intervention. The information required (from a predictor) for certainty is then
denominated in the appropriate information units. This is the amount of information that would result in a posterior probability of need for an intervention equal to one. Similarly,
, denominated in the appropriate information units, is the amount of information that would result in a posterior probability of no need for an intervention equal to one. We can plot the contour for these information contents on the diagrammatic format of
Figure 7. This contour, illustrated in
Figure 8, indicates the upper limit for the performance of any binary predictor. No phytopathological data are required to calculate this contour.
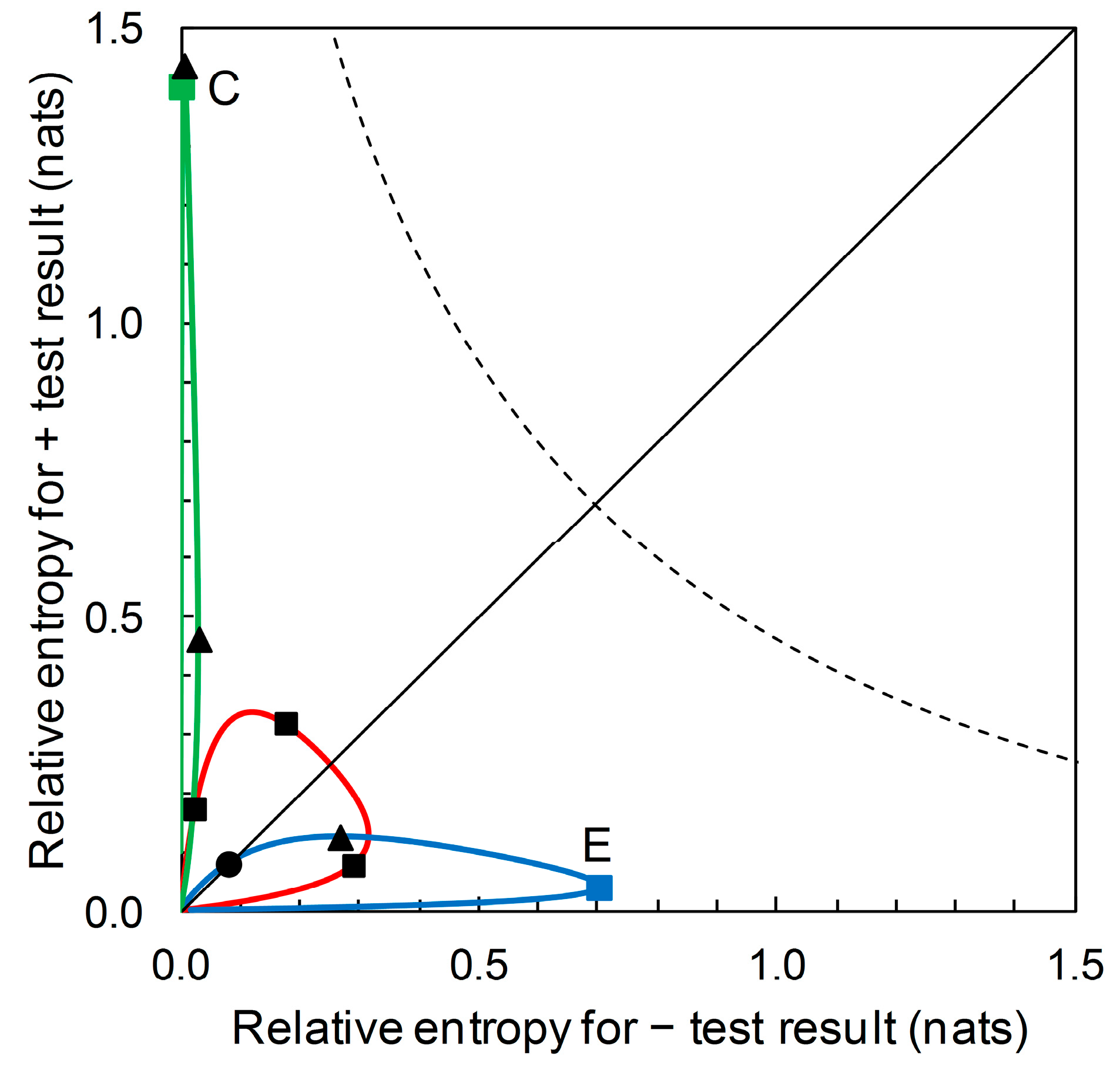
The diagrammatic format of
Figure 7 (for Scenarios A, B and D) can accommodate prior probability contours for other Scenarios (i.e., for predictors based on different
sensitivity and
specificity values). For example,
Figure 9 shows, in addition, the prior probability contours for the predictors based on Scenario C (with
sensitivity = 0.39 and
specificity = 0.99) and on Scenario E (with
sensitivity = 0.944 and
specificity = 0.656). We observe that a predictor based on Scenario C’s
sensitivity and
specificity values potentially provides a large amount of diagnostic information from a + prediction, but over a very narrow range of prior probabilities. Scenario C itself represents one such predictor. The amount of diagnostic information from − predictions is very low over the whole range of prior probabilities. A predictor based on Scenario E’s
sensitivity and
specificity values potentially provides a large amount of diagnostic information from − predictions over a narrow range of prior probabilities. Scenario E itself represents one such predictor. The amount of diagnostic information from + predictions remains low over the whole range of prior probabilities.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}