
Conditional Deep Gaussian Processes: Empirical Bayes Hyperdata Learning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Background
3.1. Gaussian Process
3.2. Deep Gaussian Process
3.3. Marginal Prior, Covariance and Marginal Likelihood
4. Model
4.1. Conditional Deep Gaussian Process
4.2. When Conditional DGP Is Almost a GP
4.3. Non-Gaussian Aspect
5. Results
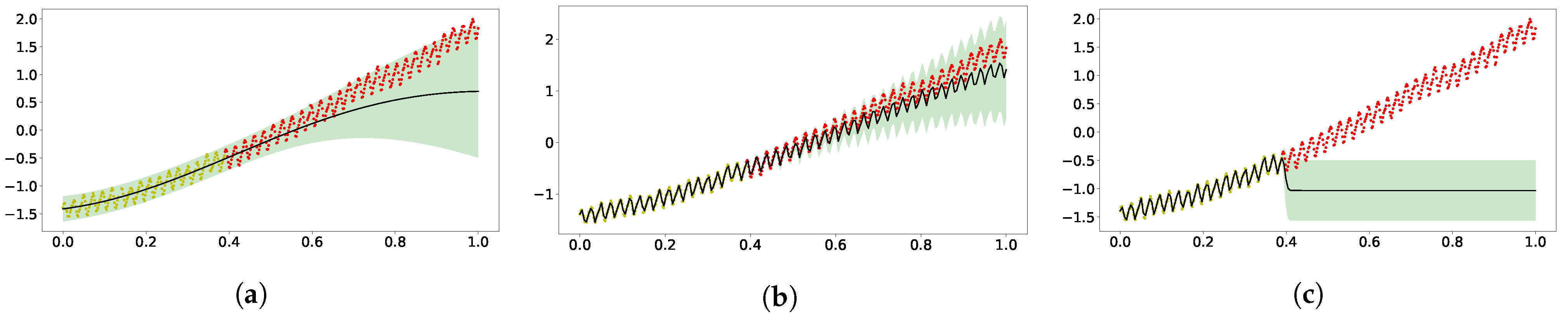
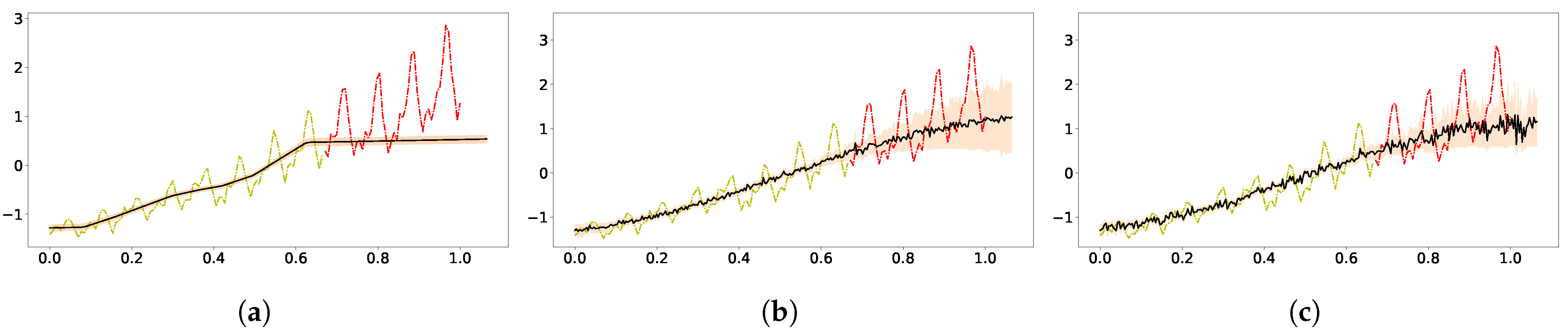
5.1. Mauna Loa Data
5.2. Airline Data
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GP | Gaussian Process |
| DGP | Deep Gaussian Process |
| DKL | Deep Kernel Learning |
| SE | Squared Exponential |
Appendix A
References
- Damianou, A.; Lawrence, N. Deep gaussian processes. In Proceedings of the Artificial Intelligence and Statistics, Scottsdale, AZ, USA, 29 April–1 May 2013; pp. 207–215. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Process for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Minka, T.P. Expectation propagation for approximate Bayesian inference. In Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence, Seattle, WA, USA, 2–5 August 2001; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2001; pp. 362–369. [Google Scholar]
- Bui, T.; Hernández-Lobato, D.; Hernandez-Lobato, J.; Li, Y.; Turner, R. Deep Gaussian processes for regression using approximate expectation propagation. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1472–1481. [Google Scholar]
- Salimbeni, H.; Deisenroth, M. Doubly stochastic variational inference for deep gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Salimbeni, H.; Dutordoir, V.; Hensman, J.; Deisenroth, M.P. Deep Gaussian Processes with Importance-Weighted Variational Inference. arXiv 2019, arXiv:1905.05435. [Google Scholar]
- Yu, H.; Chen, Y.; Low, B.K.H.; Jaillet, P.; Dai, Z. Implicit Posterior Variational Inference for Deep Gaussian Processes. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 14502–14513. [Google Scholar]
- Ustyuzhaninov, I.; Kazlauskaite, I.; Kaiser, M.; Bodin, E.; Campbell, N.; Ek, C.H. Compositional uncertainty in deep Gaussian processes. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Virtual, 3–6 August 2020; pp. 480–489. [Google Scholar]
- Havasi, M.; Hernández-Lobato, J.M.; Murillo-Fuentes, J.J. Inference in deep Gaussian processes using stochastic gradient Hamiltonian Monte Carlo. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 7506–7516. [Google Scholar]
- Duvenaud, D.; Rippel, O.; Adams, R.; Ghahramani, Z. Avoiding pathologies in very deep networks. In Proceedings of the Artificial Intelligence and Statistics, Reykjavik, Iceland, 22–25 April 2014; pp. 202–210. [Google Scholar]
- Dunlop, M.M.; Girolami, M.A.; Stuart, A.M.; Teckentrup, A.L. How deep are deep Gaussian processes? J. Mach. Learn. Res. 2018, 19, 2100–2145. [Google Scholar]
- Tong, A.; Choi, J. Characterizing Deep Gaussian Processes via Nonlinear Recurrence Systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 9915–9922. [Google Scholar]
- Agrawal, D.; Papamarkou, T.; Hinkle, J.D. Wide Neural Networks with Bottlenecks are Deep Gaussian Processes. J. Mach. Learn. Res. 2020, 21, 1–66. [Google Scholar]
- Pleiss, G.; Cunningham, J.P. The Limitations of Large Width in Neural Networks: A Deep Gaussian Process Perspective. arXiv 2021, arXiv:2106.06529. [Google Scholar]
- Wilson, A.G.; Hu, Z.; Salakhutdinov, R.; Xing, E.P. Deep kernel learning. In Proceedings of the Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 370–378. [Google Scholar]
- Salakhutdinov, R.; Hinton, G.E. Using Deep Belief Nets to Learn Covariance Kernels for Gaussian Processes. Citeseer 2007, 7, 1249–1256. [Google Scholar]
- Calandra, R.; Peters, J.; Rasmussen, C.E.; Deisenroth, M.P. Manifold Gaussian processes for regression. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3338–3345. [Google Scholar]
- Ober, S.W.; Rasmussen, C.E.; van der Wilk, M. The promises and pitfalls of deep kernel learning. arXiv 2021, arXiv:2102.12108. [Google Scholar]
- Titsias, M. Variational learning of inducing variables in sparse Gaussian processes. In Proceedings of the Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, 16–18 April 2009; pp. 567–574. [Google Scholar]
- Titsias, M.; Lawrence, N. Bayesian Gaussian process latent variable model. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 844–851. [Google Scholar]
- Matthews, A.G.d.G.; Hensman, J.; Turner, R.; Ghahramani, Z. On sparse variational methods and the Kullback–Leibler divergence between stochastic processes. In Proceedings of the Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 231–239. [Google Scholar]
- Lu, C.K.; Yang, S.C.H.; Hao, X.; Shafto, P. Interpretable deep Gaussian processes with moments. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 26–28 August 2020; pp. 613–623. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Garnelo, M.; Rosenbaum, D.; Maddison, C.; Ramalho, T.; Saxton, D.; Shanahan, M.; Teh, Y.W.; Rezende, D.; Eslami, S.A. Conditional Neural Processes. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1704–1713. [Google Scholar]
- Snelson, E.; Ghahramani, Z.; Rasmussen, C.E. Warped gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 13–18 December 2004; pp. 337–344. [Google Scholar]
- Lázaro-Gredilla, M. Bayesian warped Gaussian processes. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1619–1627. [Google Scholar]
- Ma, C.; Li, Y.; Hernández-Lobato, J.M. Variational implicit processes. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 4222–4233. [Google Scholar]
- Ustyuzhaninov, I.; Kazlauskaite, I.; Ek, C.H.; Campbell, N. Monotonic gaussian process flows. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sicily, Italy, 26–28 August 2020; pp. 3057–3067. [Google Scholar]
- Telgarsky, M. Benefits of depth in neural networks. In Proceedings of the Conference on Learning Theory, New York, NY, USA, 23–26 June 2016; pp. 1517–1539. [Google Scholar]
- Pearce, T.; Tsuchida, R.; Zaki, M.; Brintrup, A.; Neely, A. Expressive priors in bayesian neural networks: Kernel combinations and periodic functions. In Proceedings of the Uncertainty in Artificial Intelligence, Virtual, 3–6 August 2020; pp. 134–144. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1050–1059. [Google Scholar]
- Cutajar, K.; Bonilla, E.V.; Michiardi, P.; Filippone, M. andom feature expansions for deep Gaussian processes. In Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, Sydney, Australia, 6–11 August 2017; pp. 884–893. [Google Scholar]
- Rahimi, A.; Recht, B. Random features for large-scale kernel machines. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–11 December 2008; pp. 1177–1184. [Google Scholar]
- Cho, Y.; Saul, L.K. Kernel methods for deep learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 342–350. [Google Scholar]
- Schölkopf, B.; Smola, A.; Müller, K.R. Nonlinear component analysis as a kernel eigenvalue problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef] [Green Version]
- Girard, A.; Rasmussen, C.E.; Candela, J.Q.; Murray-Smith, R. Gaussian process priors with uncertain inputs application to multiple-step ahead time series forecasting. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–13 December 2003; pp. 545–552. [Google Scholar]
- Muandet, K.; Fukumizu, K.; Dinuzzo, F.; Schölkopf, B. Learning from distributions via support measure machines. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 10–18. [Google Scholar]
- Li, Y.; Swersky, K.; Zemel, R. Generative moment matching networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1718–1727. [Google Scholar]
- Quiñonero-Candela, J.; Rasmussen, C.E. A unifying view of sparse approximate Gaussian process regression. J. Mach. Learn. Res. 2005, 6, 1939–1959. [Google Scholar]
- Shi, J.; Titsias, M.K.; Mnih, A. Sparse Orthogonal Variational Inference for Gaussian Processes. arXiv 2019, arXiv:1910.10596. [Google Scholar]
- Lázaro-Gredilla, M.; Figueiras-Vidal, A.R. Inter-domain Gaussian Processes for Sparse Inference using Inducing Features. Citeseer 2009, 22, 1087–1095. [Google Scholar]
- Dutordoir, V.; Durrande, N.; Hensman, J. Sparse Gaussian processes with spherical harmonic features. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 2793–2802. [Google Scholar]
- Dutordoir, V.; Hensman, J.; van der Wilk, M.; Ek, C.H.; Ghahramani, Z.; Durrande, N. Deep Neural Networks as Point Estimates for Deep Gaussian Processes. arXiv 2021, arXiv:2105.04504. [Google Scholar]
- Rudner, T.G.; Sejdinovic, D.; Gal, Y. Inter-domain deep Gaussian processes. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 8286–8294. [Google Scholar]
- Ober, S.W.; Aitchison, L. Global inducing point variational posteriors for bayesian neural networks and deep gaussian processes. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8248–8259. [Google Scholar]
- GPy. GPy: A Gaussian Process Framework in Python. 2012. Available online: http://github.com/SheffieldML/GPy (accessed on 15 October 2021).
- Lu, C.K.; Shafto, P. Conditional Deep Gaussian Process: Multi-fidelity kernel learning. arXiv 2021, arXiv:2002.02826. [Google Scholar]
- Isserlis, L. On a formula for the product-moment coefficient of any order of a normal frequency distribution in any number of variables. Biometrika 1918, 12, 134–139. [Google Scholar] [CrossRef] [Green Version]
- Vladimirova, M.; Verbeek, J.; Mesejo, P.; Arbel, J. Understanding priors in bayesian neural networks at the unit level. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6458–6467. [Google Scholar]
- Yaida, S. Non-Gaussian processes and neural networks at finite widths. In Proceedings of the First Mathematical and Scientific Machine Learning Conference, Virtual, 20–24 July 2020; pp. 165–192. [Google Scholar]
- Zavatone-Veth, J.; Pehlevan, C. Exact marginal prior distributions of finite Bayesian neural networks. arXiv 2021, arXiv:2104.11734. [Google Scholar]
- Duvenaud, D.; Lloyd, J.; Grosse, R.; Tenenbaum, J.; Zoubin, G. Structure discovery in nonparametric regression through compositional kernel search. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; pp. 1166–1174. [Google Scholar]
- Sun, S.; Zhang, G.; Wang, C.; Zeng, W.; Li, J.; Grosse, R. Differentiable compositional kernel learning for Gaussian processes. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4828–4837. [Google Scholar]
- Mhaskar, H.; Liao, Q.; Poggio, T. Learning functions: When is deep better than shallow. arXiv 2016, arXiv:1603.00988. [Google Scholar]
- Dutordoir, V.; Salimbeni, H.; Hambro, E.; McLeod, J.; Leibfried, F.; Artemev, A.; van der Wilk, M.; Deisenroth, M.P.; Hensman, J.; John, S. Pflux: A library for Deep Gaussian Processes. arXiv 2021, arXiv:2104.05674. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, C.-K.; Shafto, P. Conditional Deep Gaussian Processes: Empirical Bayes Hyperdata Learning. Entropy 2021, 23, 1387. https://doi.org/10.3390/e23111387
Lu C-K, Shafto P. Conditional Deep Gaussian Processes: Empirical Bayes Hyperdata Learning. Entropy. 2021; 23(11):1387. https://doi.org/10.3390/e23111387
Chicago/Turabian StyleLu, Chi-Ken, and Patrick Shafto. 2021. "Conditional Deep Gaussian Processes: Empirical Bayes Hyperdata Learning" Entropy 23, no. 11: 1387. https://doi.org/10.3390/e23111387
APA StyleLu, C. -K., & Shafto, P. (2021). Conditional Deep Gaussian Processes: Empirical Bayes Hyperdata Learning. Entropy, 23(11), 1387. https://doi.org/10.3390/e23111387