
Self-Supervised Variational Auto-Encoders



Abstract
:1. Introduction
2. Background
2.1. Variational Auto-Encoders
2.2. VAEs with Bijective Priors
3. Method
3.1. Motivation
3.2. Model Formulation
3.3. Generation and Reconstruction in selfVAE
3.4. Hierarchical Self-Supervised VAE
4. Experiments
4.1. Experimental Setup
- Datasets We evaluated the proposed model on the CIFAR-10, Imagenette64, and CelebA datasets:
- -
- CIFAR-10 The CIFAR-10 (https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 11 June 2021)) dataset is a well-known image benchmark data containing 60,000 training natural images and 10,000 validation natural images. Each image is of size 32 px × 32 px. From the training data, we put aside randomly selected images as the test set. We augmented the training data by using random horizontal flips and random affine transformations and normalized the data uniformly in the range (0, 1).
- -
- Imagenette64 Imagenette64 (https://github.com/fastai/imagenette (accessed on 11 June 2021)) is a subset of 10 easily classified classes from Imagenet https://www.image-net.org/ (accessed on 11 June 2021 ) (tench, English springer, cassette player, chain saw, church, French horn, garbage truck, gas pump, golf ball, and parachute). We downscaled the dataset to 64 px × 64 px images. Similarly to CIFAR-10, we put aside randomly selected training images as the test set. We used the same data augmentation as in CIFAR-10. Please note that Imagenette64 is not equivalent to Imagenet64.
- -
- CelebA The Large-scale CelebFaces Attributes (CelebA)(http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html (accessed on 11 June 2021)) dataset consists of images of celebrities. We cropped the original images on the 40 vertical and 15 horizontal components of the top left corner of the crop box, where the height and width were cropped to 148. In addition to the uniform normalization of the image, no other augmentation was applied.
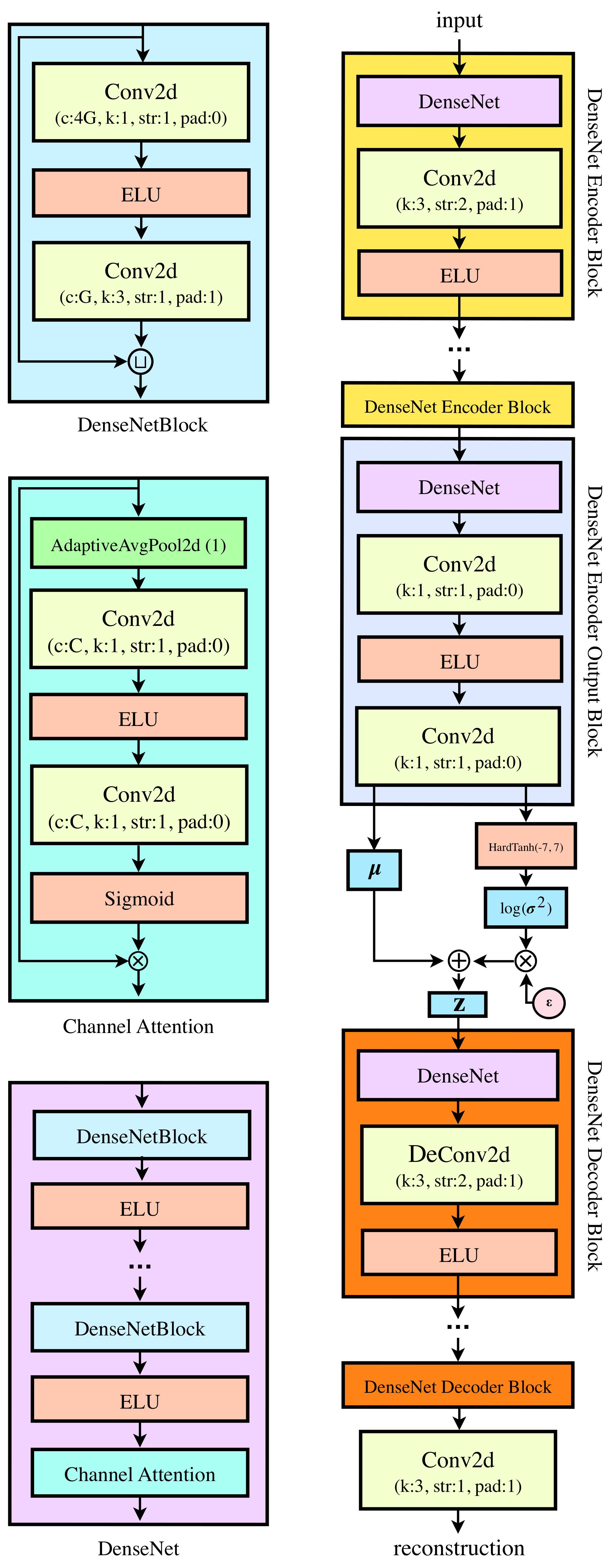
- Architectures The encoders and decoders consisted of building blocks composed of DenseNets [30], channel-wise attention [31], and ELUs [32] as activation functions. The dimensionality of all the latent variables was kept at , and all models were trained using AdaMax [33] with data-dependent initialization [34]. Regarding the selfVAEs, in CIFAR-10, we used an architecture with a single downscaled transformation (selfVAE-downscale), while, on the remaining two datasets (CelebA and Imagenette64), we used a hierarchical three-leveled selfVAE with downscaling, and a selfVAE with sketching. Note that using sketching multiple times would result in no new data representation.All models were employed with the bijective prior (RealNVP). All models were comparable in terms of the number of parameters (the range of the weights of all models was from 32 million to 42 million). Due to our limited computational resources, these were the largest models that we were able to train. A fair comparison to the current SOTA models that use over 100 million weights [12,13] is, therefore, slightly skewed. For more details on the model architectures, please refer to the Appendix A.1.
- Evaluation We approximated the negative log-likelihood using 512 IW-samples [16] and express the scores in bits per dimension (bpd). Additionally, for CIFAR-10, we used the Fréchet Inception Distance (FID) [35]. We used the FID score indicating that sometimes the likelihood-based models achieved very low bpd; however, their perceptual quality was lower.
4.2. Quantitative Results
4.3. Qualitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Neural Network Architecture
Appendix A.2. Self-Supervised VAE—Unconditional Generations
Appendix A.3. Self-Supervised VAE—Sketch Reconstructions


Qualitative Analysis

Appendix A.4. Additional Results

References
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. arXiv 2014, arXiv:1401.4082. [Google Scholar]
- Van den Berg, R.; Hasenclever, L.; Tomczak, J.M.; Welling, M. Sylvester Normalizing Flows for Variational Inference. arXiv 2018, arXiv:1803.05649. [Google Scholar]
- Hoogeboom, E.; Satorras, V.G.; Tomczak, J.M.; Welling, M. The Convolution Exponential and Generalized Sylvester Flows. arXiv 2020, arXiv:2006.01910. [Google Scholar]
- Maaløe, L.; Sønderby, C.K.; Sønderby, S.K.; Winther, O. Auxiliary Deep Generative Models. arXiv 2016, arXiv:1602.05473. [Google Scholar]
- Chen, X.; Kingma, D.P.; Salimans, T.; Duan, Y.; Dhariwal, P.; Schulman, J.; Sutskever, I.; Abbeel, P. Variational Lossy Autoencoder. arXiv 2016, arXiv:1611.02731. [Google Scholar]
- Habibian, A.; Rozendaal, T.V.; Tomczak, J.M.; Cohen, T.S. Video compression with rate-distortion autoencoders. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7033–7042. [Google Scholar]
- Lavda, F.; Gregorová, M.; Kalousis, A. Data-dependent conditional priors for unsupervised learning of multimodal data. Entropy 2020, 22, 888. [Google Scholar] [CrossRef]
- Lin, S.; Clark, R. LaDDer: Latent Data Distribution Modelling with a Generative Prior. arXiv 2020, arXiv:2009.00088. [Google Scholar]
- Tomczak, J.M.; Welling, M. VAE with a VampPrior. arXiv 2017, arXiv:1705.07120. [Google Scholar]
- Gulrajani, I.; Kumar, K.; Ahmed, F.; Taiga, A.A.; Visin, F.; Vazquez, D.; Courville, A. PixelVAE: A Latent Variable Model for Natural Images. arXiv 2016, arXiv:1611.05013. [Google Scholar]
- Zhao, S.; Song, J.; Ermon, S. Learning hierarchical features from deep generative models. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 4091–4099. [Google Scholar]
- Maaløe, L.; Fraccaro, M.; Liévin, V.; Winther, O. BIVA: A Very Deep Hierarchy of Latent Variables for Generative Modeling. arXiv 2019, arXiv:1902.02102. [Google Scholar]
- Vahdat, A.; Kautz, J. NVAE: A Deep Hierarchical Variational Autoencoder. arXiv 2020, arXiv:2007.03898. [Google Scholar]
- Jordan, M.I.; Ghahramani, Z.; Jaakkola, T.S.; Saul, L.K. An introduction to variational methods for graphical models. In Machine Learning; MIT Press: Cambridge, MA, USA, 1999; pp. 183–233. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Burda, Y.; Grosse, R.; Salakhutdinov, R. Importance Weighted Autoencoders. arXiv 2015, arXiv:1509.00519. [Google Scholar]
- Hoffman, M.D.; Johnson, M.J. Elbo surgery: Yet another way to carve up the variational evidence lower bound. In Proceedings of the NIPS 2016 Workshop on Advances in Approximate Bayesian Inference, Barcelona, Spain, 9 December 2016; Volume 1, p. 2. [Google Scholar]
- Rosca, M.; Lakshminarayanan, B.; Mohamed, S. Distribution Matching in Variational Inference. arXiv 2018, arXiv:1802.06847. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using Real NVP. arXiv 2016, arXiv:1605.08803. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative Flow with Invertible 1x1 Convolutions. arXiv 2018, arXiv:1807.03039. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Split-brain autoencoders: Unsupervised learning by cross-channel prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1058–1067. [Google Scholar]
- Hénaff, O.J.; Srinivas, A.; De Fauw, J.; Razavi, A.; Doersch, C.; Eslami, S.; Oord, A.V.d. Data-efficient image recognition with contrastive predictive coding. arXiv 2019, arXiv:1905.09272. [Google Scholar]
- Oord, A.V.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Liu, X.; Zhang, F.; Hou, Z.; Wang, Z.; Mian, L.; Zhang, J.; Tang, J. Self-supervised Learning: Generative or Contrastive. arXiv 2020, arXiv:2006.08218. [Google Scholar]
- Chang, H.; Yeung, D.Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; Volume 1, p. I. [Google Scholar]
- Gatopoulos, I.; Stol, M.; Tomczak, J.M. Super-resolution Variational Auto-Encoders. arXiv 2020, arXiv:2006.05218. [Google Scholar]
- Chakraborty, S.; Chakravarty, D. A new discrete probability distribution with integer support on (−∞,∞). Commun. Stat. Theory Methods 2016, 45, 492–505. [Google Scholar] [CrossRef]
- Salimans, T.; Karpathy, A.; Chen, X.; Kingma, D.P. PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications. arXiv 2017, arXiv:1701.05517. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. arXiv 2018, arXiv:1807.02758. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Salimans, T.; Kingma, D.P. Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks. arXiv 2016, arXiv:1602.07868. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. arXiv 2017, arXiv:1706.08500. [Google Scholar]
- Van den Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel Recurrent Neural Networks. arXiv 2016, arXiv:1601.06759. [Google Scholar]
- Chen, R.T.Q.; Behrmann, J.; Duvenaud, D.; Jacobsen, J.H. Residual Flows for Invertible Generative Modeling. arXiv 2019, arXiv:1906.02735. [Google Scholar]
- Child, R. Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images. arXiv 2020, arXiv:2011.10650. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. arXiv 2020, arXiv:2006.11239. [Google Scholar]
- Mentzer, F.; Agustsson, E.; Tschannen, M.; Timofte, R.; Gool, L.V. Practical full resolution learned lossless image compression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 January 2019; pp. 10629–10638. [Google Scholar]
- Razavi, A.; van den Oord, A.; Vinyals, O. Generating diverse high-fidelity images with vq-vae-2. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2019; pp. 14866–14876. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. arXiv 2016, arXiv:1609.05158. [Google Scholar]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Gastal, E.S.L.; Oliveira, M.M. Domain Transform for Edge-Aware Image and Video Processing. ACM TOG 2011, 30, 1–12. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | bpd↓ | FID ↓ |
|---|---|---|---|
| CIFAR-10 | PixelCNN [36] | 3.14 | 65.93 |
| GLOW [20] | 3.35 | 65.93 | |
| ResidualFlow [37] | 3.28 | 46.37 | |
| BIVA [12] | 3.08 | - | |
| NVAE [13] | 2.91 | - | |
| Very deep VAEs [38] | 2.87 | ||
| DDPM [39] | 3.75 | 5.24 (3.17 *) | |
| VAE (ours) | 3.51 | 41.36 (37.25 *) | |
| selfVAE-downscale | 3.65 | 34.71 (29.95 *) | |
| CelebA | RealNVP [19] | 3.02 | - |
| VAE (ours) | 3.12 | - | |
| selfVAE-sketch | 3.24 | - | |
| selfVAE-downscale-3lvl | 2.88 | - | |
| Imagenette64 | VAE (ours) | 3.85 | - |
| selfVAE-downscale-3lvl | 3.70 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gatopoulos, I.; Tomczak, J.M. Self-Supervised Variational Auto-Encoders. Entropy 2021, 23, 747. https://doi.org/10.3390/e23060747
Gatopoulos I, Tomczak JM. Self-Supervised Variational Auto-Encoders. Entropy. 2021; 23(6):747. https://doi.org/10.3390/e23060747
Chicago/Turabian StyleGatopoulos, Ioannis, and Jakub M. Tomczak. 2021. "Self-Supervised Variational Auto-Encoders" Entropy 23, no. 6: 747. https://doi.org/10.3390/e23060747
APA StyleGatopoulos, I., & Tomczak, J. M. (2021). Self-Supervised Variational Auto-Encoders. Entropy, 23(6), 747. https://doi.org/10.3390/e23060747