
Regularization, Bayesian Inference, and Machine Learning Methods for Inverse Problems †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
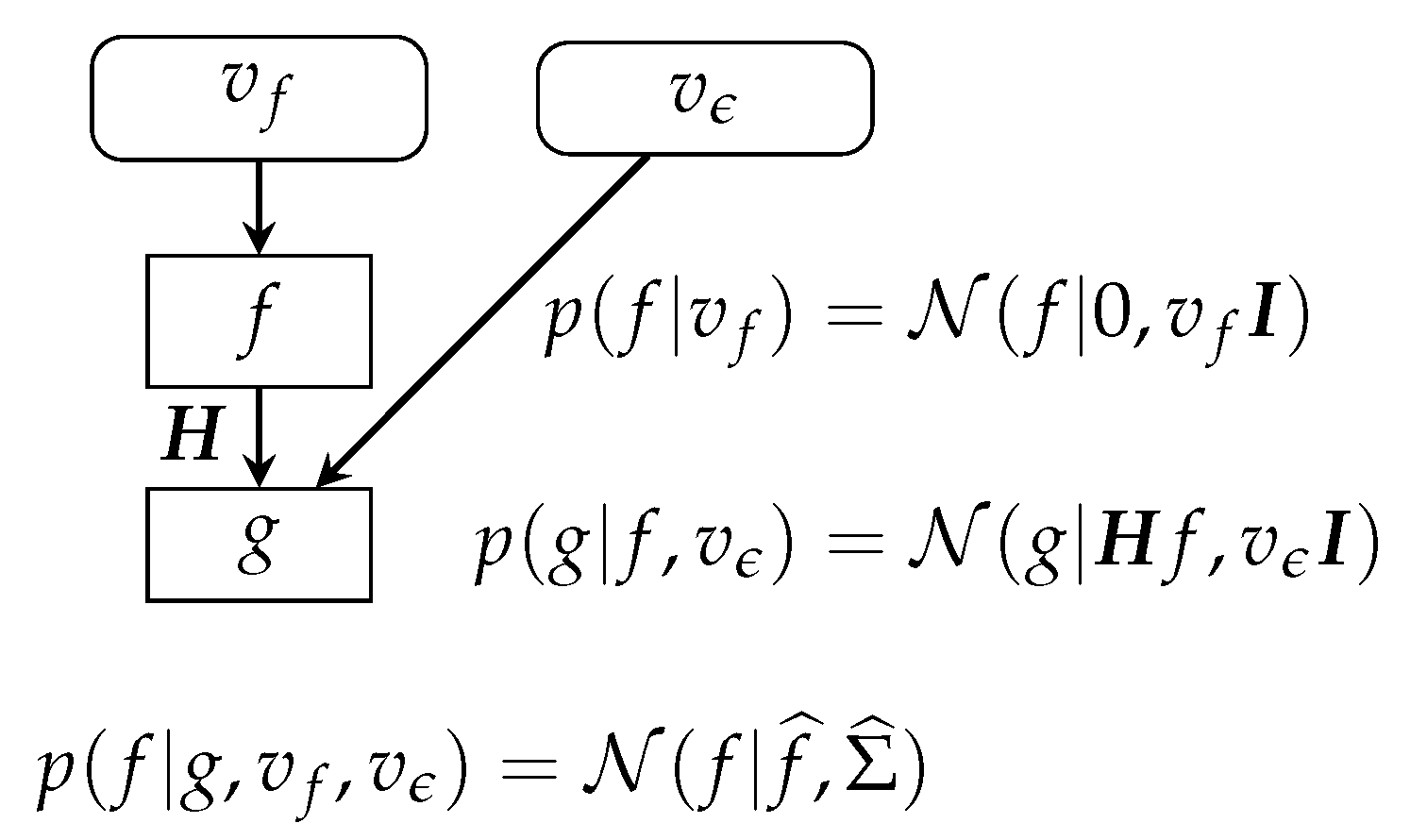{kind=link}
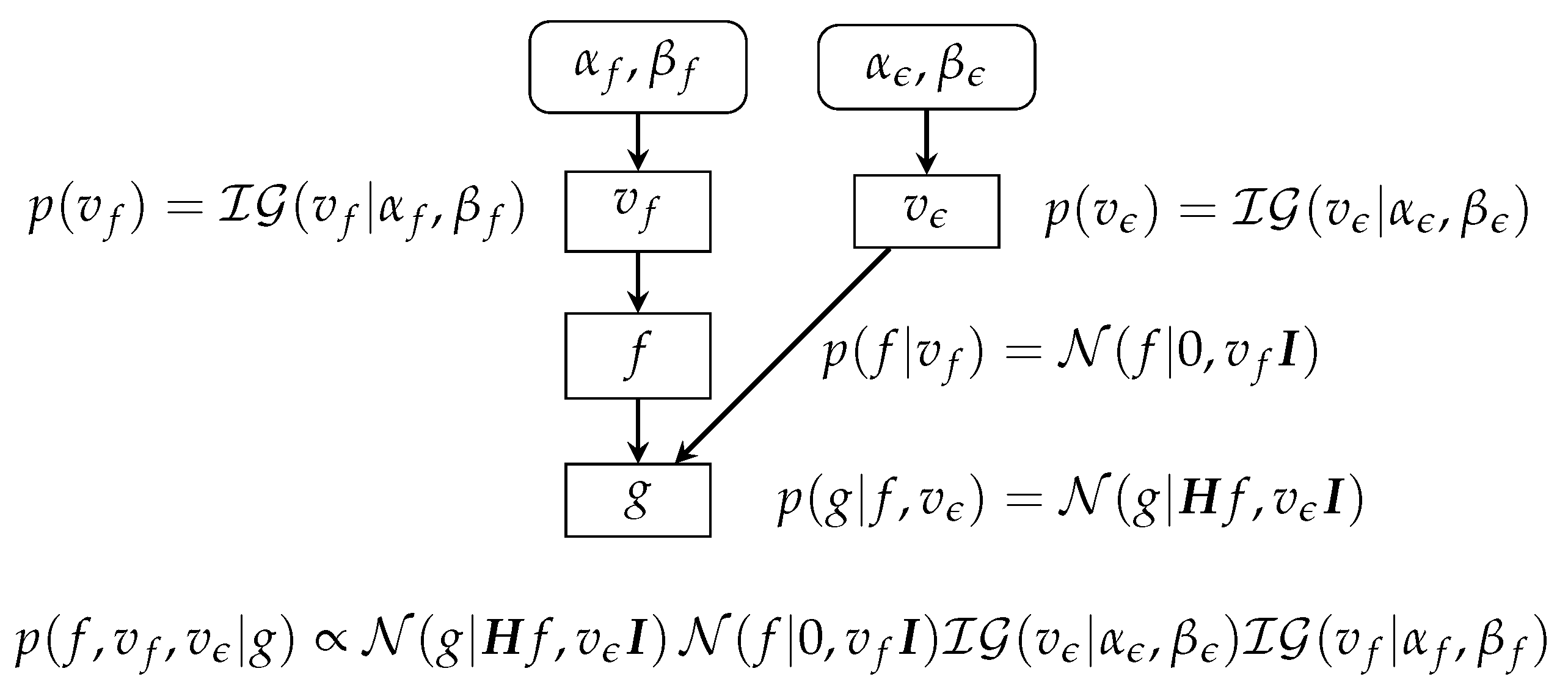{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
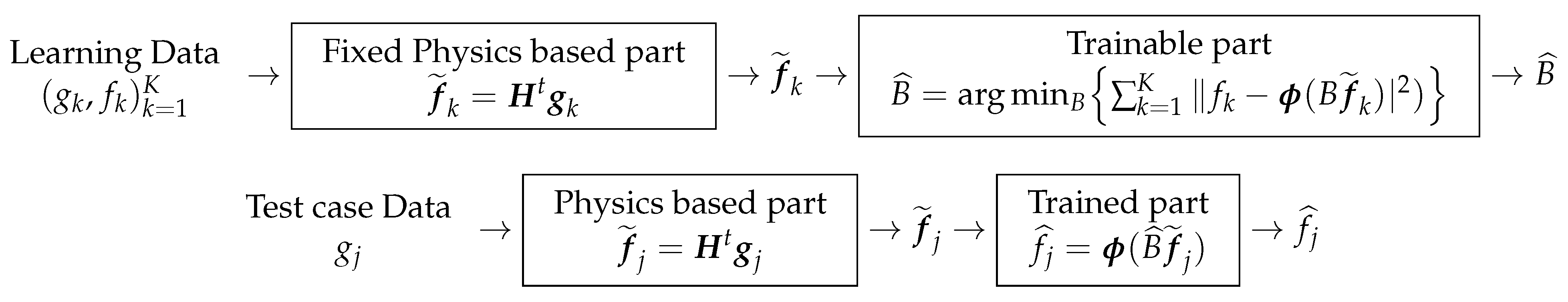{kind=link}
{kind=link}
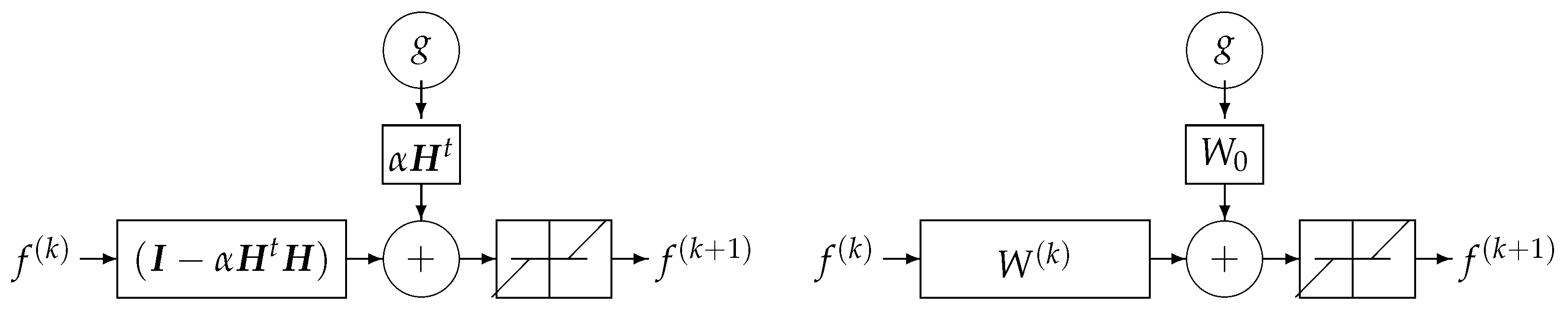{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Inverse Problems Example
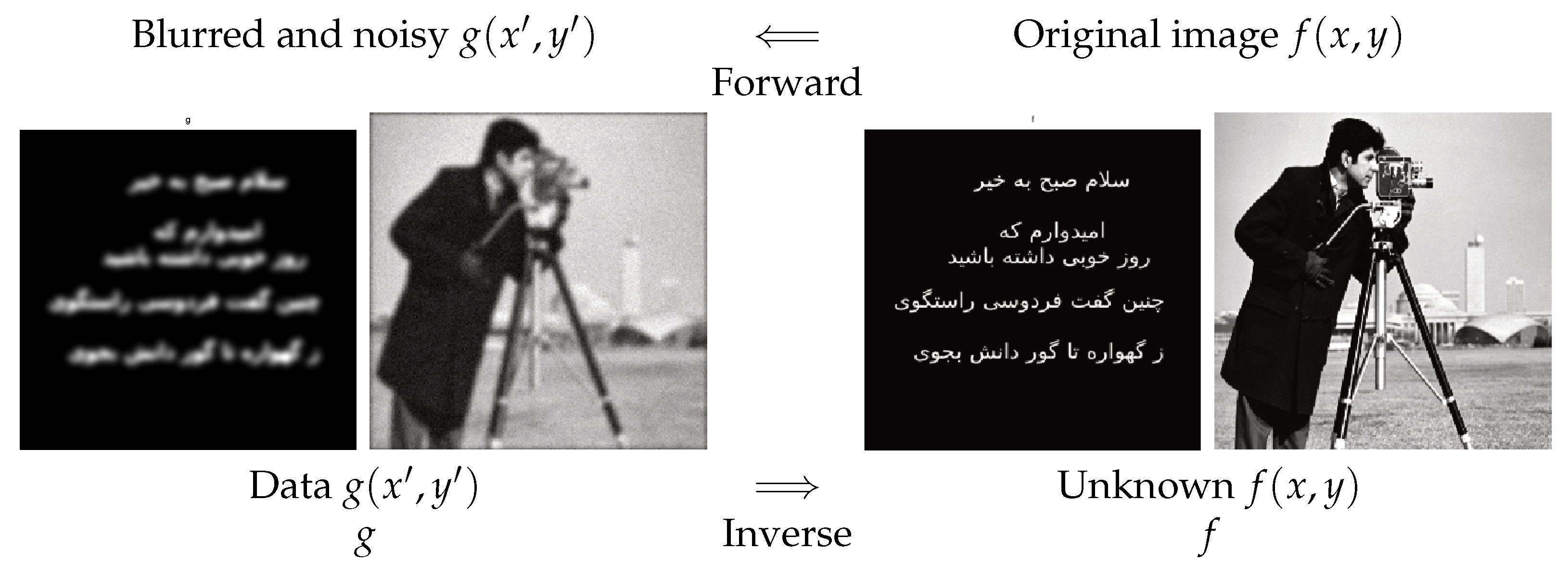
2.1. Image Restoration
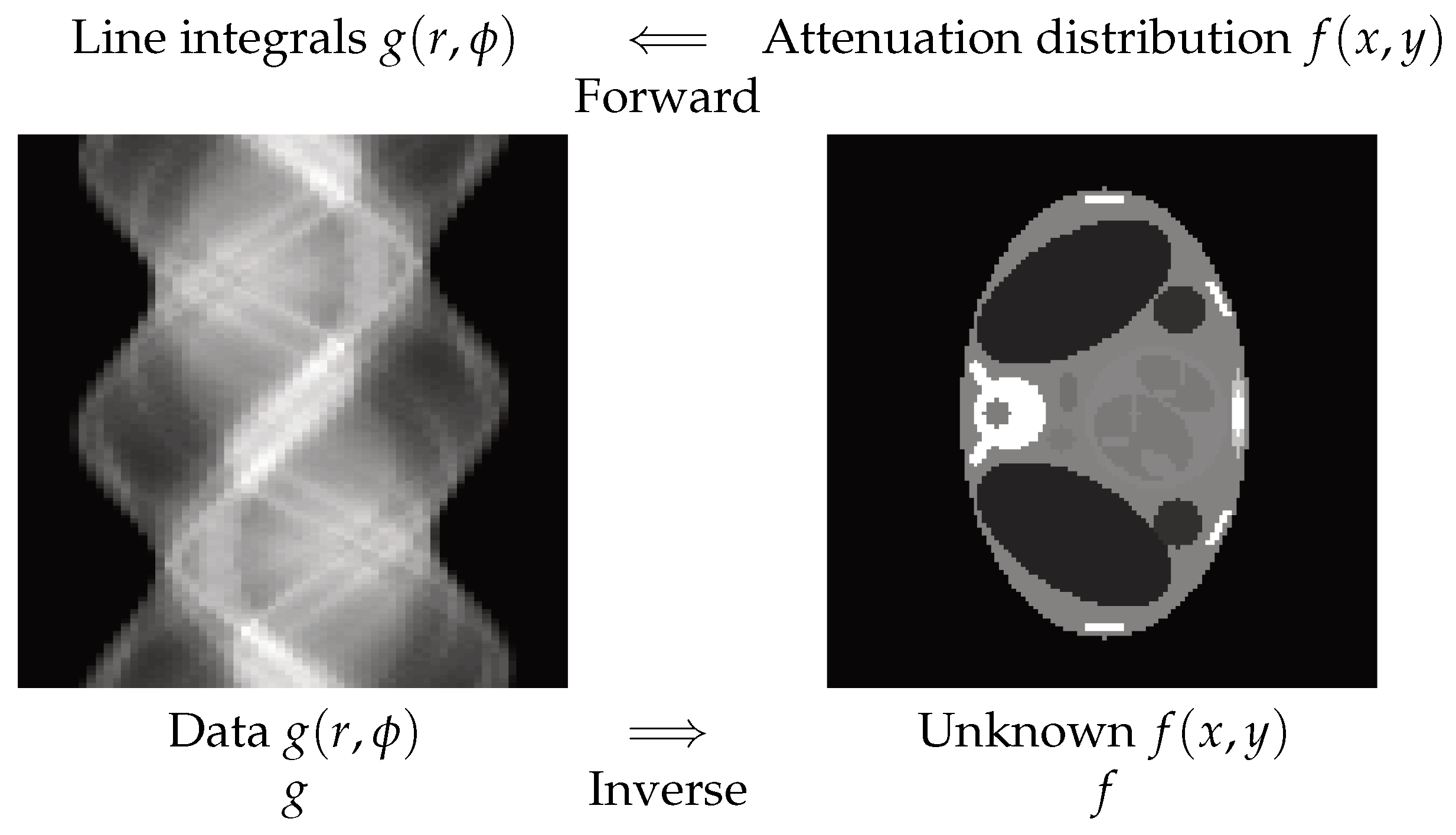
2.2. X-ray Computed Tomography
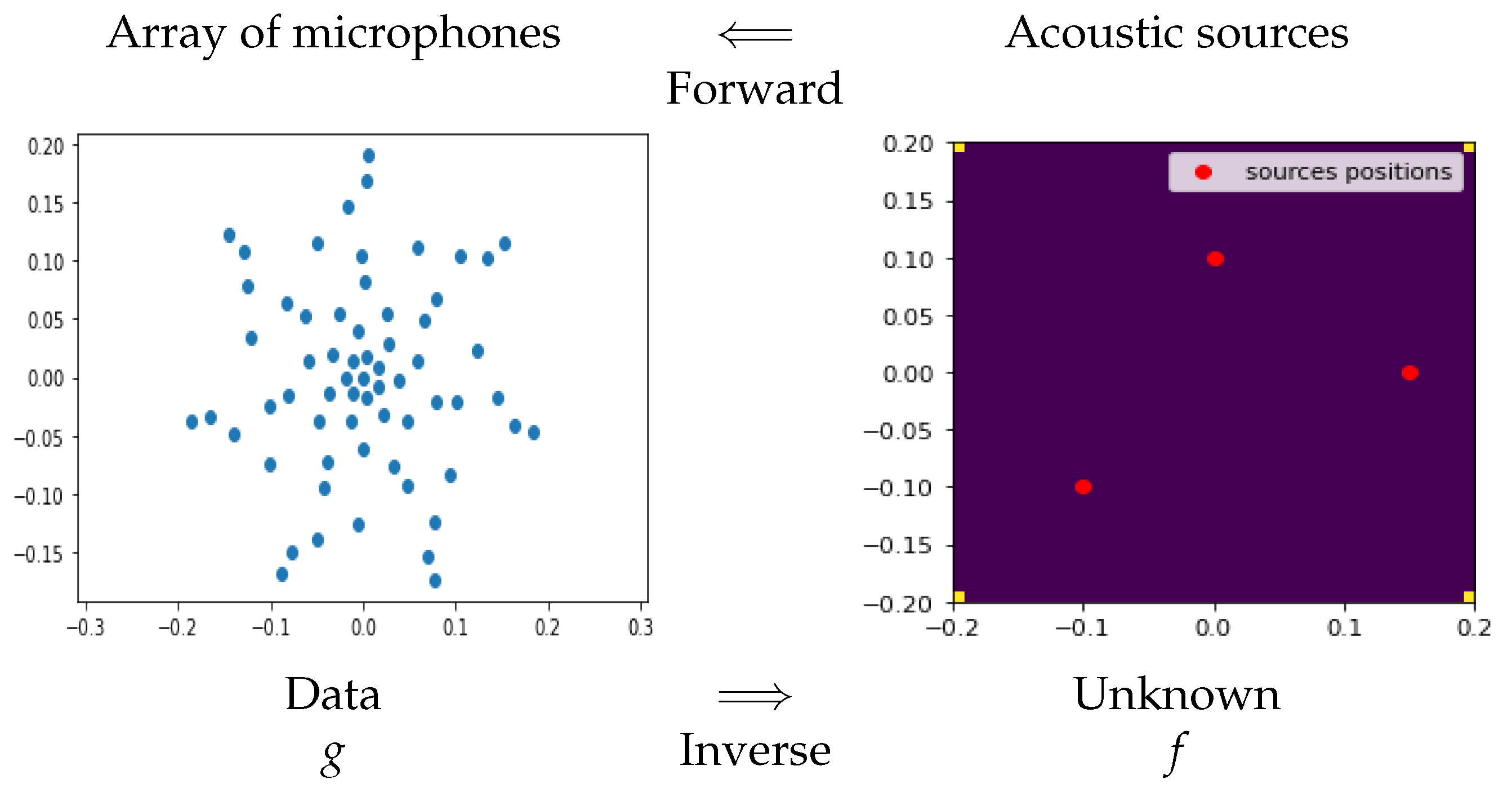
2.3. Acoustical Imaging
2.4. Microwave Imaging for Breast-Cancer Detection
2.5. Brain Imaging
2.6. Other Applications
3. Classification of Inverse Problems’ Methods
- Analytical inversion methods.
- Generalized inversion approach.
- Regularization methods.
- Bayesian inference methods.
4. Analytical Methods
- 1.
- For each angle , compute the 1D FT of ,
- 2.
- Relate it to the 2D FT of via the Fourier slice theorem and interpolate to obtain the full 2D FT of ; and
- 3.
- Compute 2D IFT to obtain
5. Generalized Inversion Approach
6. Model-Based and Regularization Approach
Regularization Methods
- quadratic: gradient-based and conjugate gradient algorithms are appropriate.
- non-quadratic but convex and differentiable: here too the gradient-based and the conjugate gradient (CG) methods can be used, but there are also a great number of convex criterion optimization algorithms.
- convex but non-differentiable: here, the notion of a sub-gradient is used.
- L2 or quadratic: ;In this case we have an analytic solution: . However, in practice, this analytic solution is not usable in high-dimensional problems. In general, as the gradient can be evaluated analytically, gradient-based algorithms are used.
- L1 (TV): convex but not differentiable at zero: ;
- Variable splitting and augmented Lagrangian
- A limited choice of the regularization term. Mainly, we have: (a) smoothness (Tikhonov) and (b) sparsity, piecewise continuous (total variation).
- Determination of the regularization parameter. Even if there are some classical methods such as the L-curve and cross validation, there are still controversial discussions about this.
- Quantification of the uncertainties: this is the main limitation of the deterministic methods, particularly in medical and biological applications where this point is important.
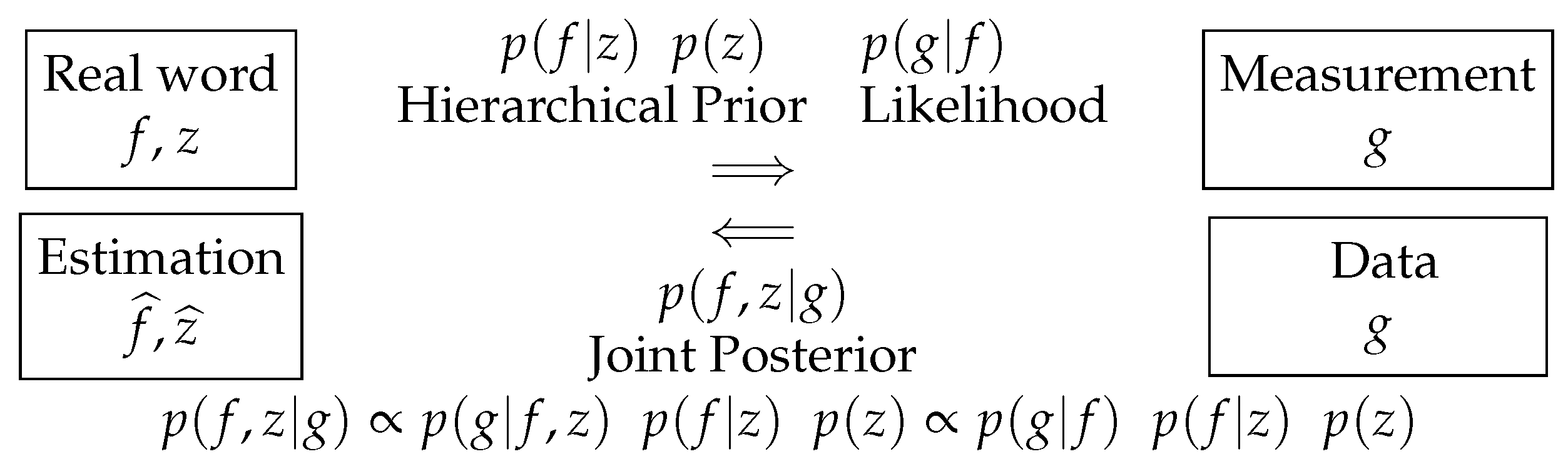
7. Bayesian-Inference Methods
7.1. Basic Idea
7.2. Gaussian Priors Case
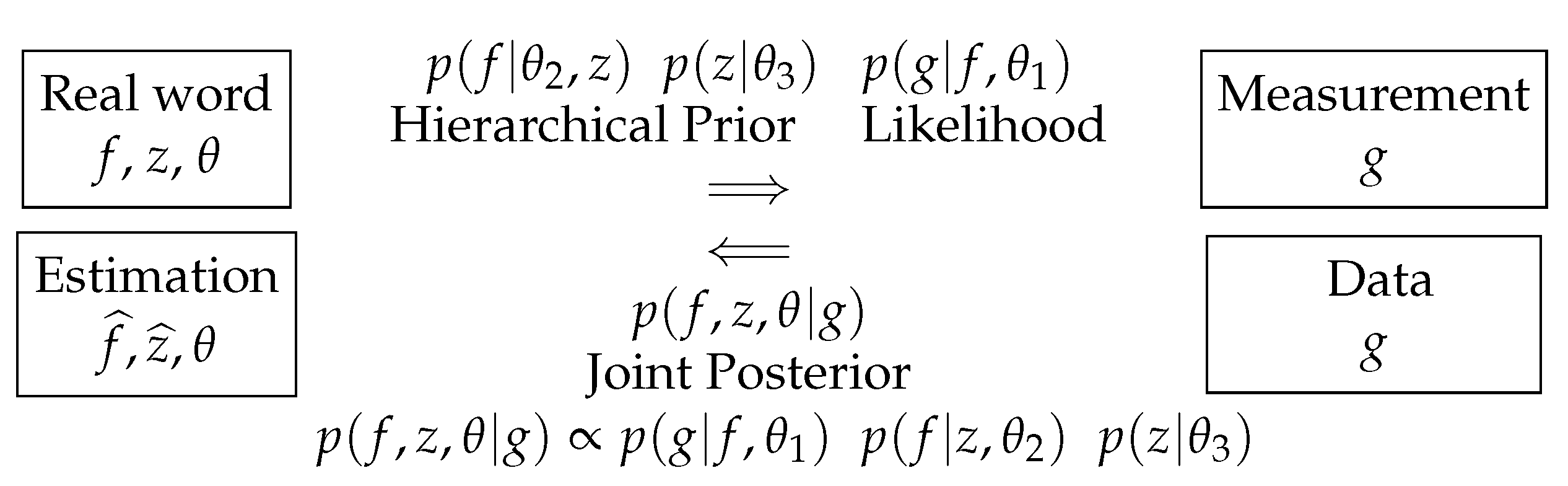
7.3. Gaussian Priors with Unknown Parameters
- JMAP: alternate optimization with respect to :Each iteration can be done in two steps:
- 1.
- Fix and to previous values and optimize with respect to f;
- 2.
- Fix f and optimize with respect to and .
The first step results in a quadratic criterion with respect to f, which results in an analytical expression for the solution, which can be used for small-dimension problems, or it can be optimized easily by any gradient-based algorithm. The second step, in this case, results in two separate explicit solutions: one for and one for . - Gibbs sampling and Markov Chain Monte Carlo (MCMC):These steps can be done using the expressions of the conditional given in Equation (18). These methods are used generally when we not only want to have a point estimator such as MAP or the posterior mean but also to quantify the uncertainties by estimations of the variances and covariances.
- Variational Bayesian Approximation (VBA): approximate by a separable one minimizing [19,55,56,57,58]. We can see that the alternate optimization of with respect to , , and result in the same expressions as in Equation (18), only the expressions for updating the parameters , and are different.The Approximate Bayesian Computation (ABC) method and, in particular, the VBA and mean-field-approximation methods are used when Gibbs sampling and MCMC methods are too expensive and we still want to quantify uncertainties, for example, estimating the variances.
8. Imaging inside the Body: From Data Acquisition to Decision
- Data acquisition:
- Image reconstruction by analytical methods:
- Post-processing (segmentation, contour detection, and selection of region of interest):
- Understanding and decision:
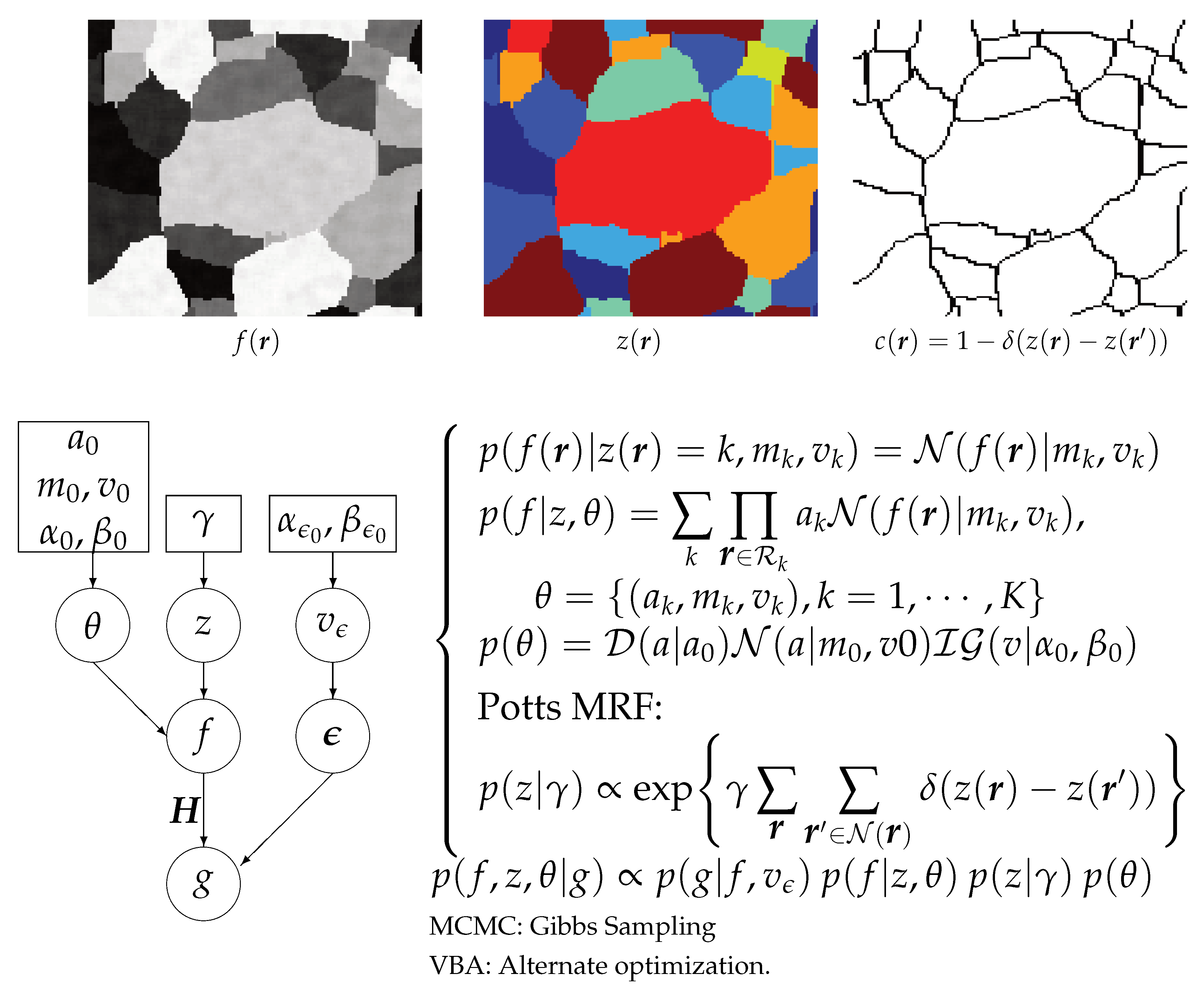
8.1. Bayesian Joint Reconstruction and Segmentation
- does not depend on z, so it can be written as .
- If we choose for a Gaussian law, then becomes a Gauss–Markov–Potts model [19].
- We can use the joint posterior to infer on : we may just do JMAP:
- When the iterations finished, we obtain an estimate of the reconstructed image f and its segmentation z when using JMAP and also the covariance of f as well as the parameters of the posterior laws of z
8.2. Advantages of the Bayesian Framework
- Large flexibility of prior models.
- -
- Smoothness (Gaussian and Gauss–Markov).
- -
- Direct sparsity (double exp., heavy-tailed distributions).
- -
- Sparsity in the transform domain (double exp., heavy-tailed distributions on the WT coefficients).
- -
- Piecewise continuous (DE or Student-t on the gradient).
- -
- Objects composed of only a few materials (Gauss–Markov–Potts), ...
- Possibility of estimating hyperparameters via JMAP or VBA.
- Natural ways to take account for uncertainties and to quantify the remaining uncertainties.
8.3. Imaging inside the Body: From Data to Decision: Classical or Machine Learning
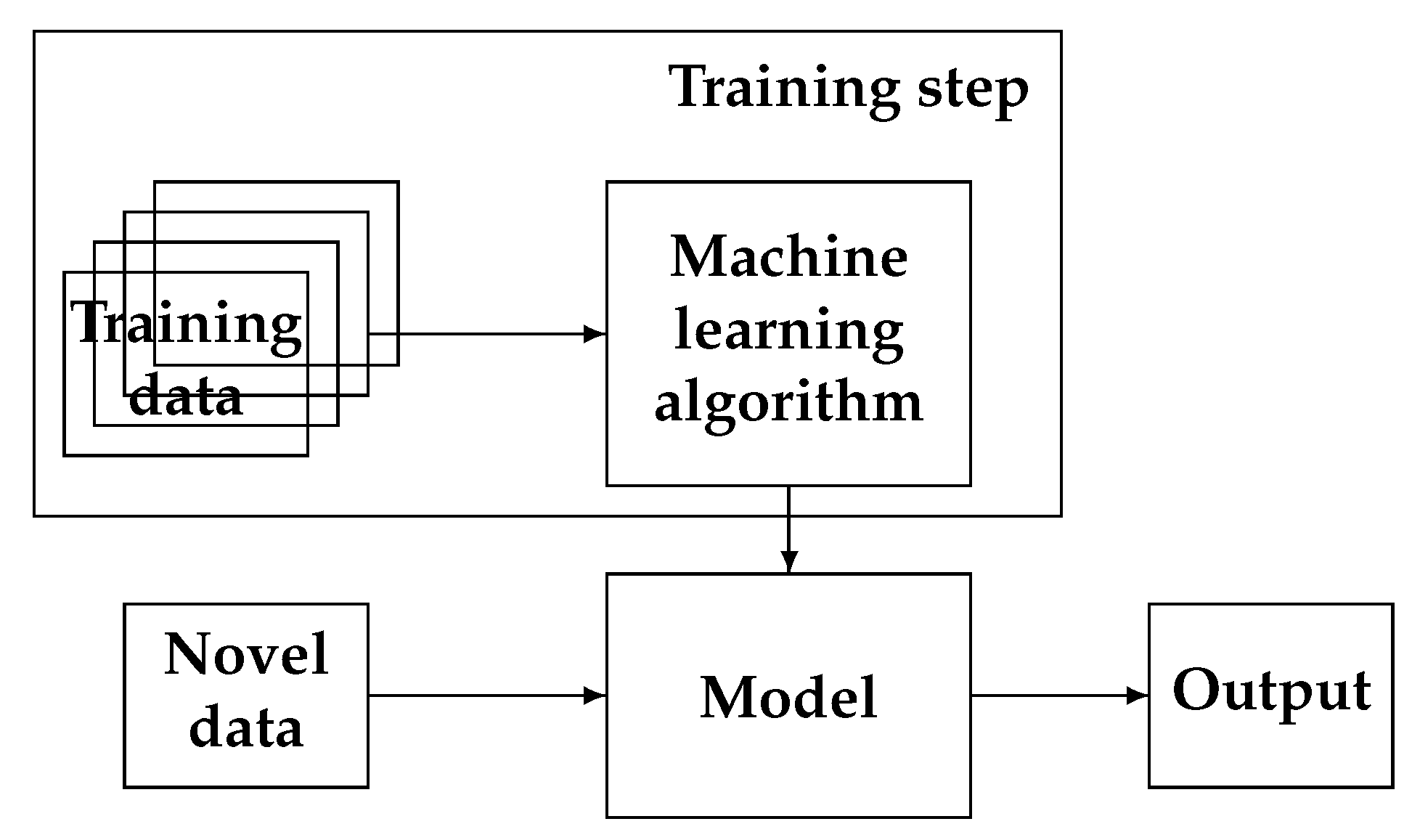
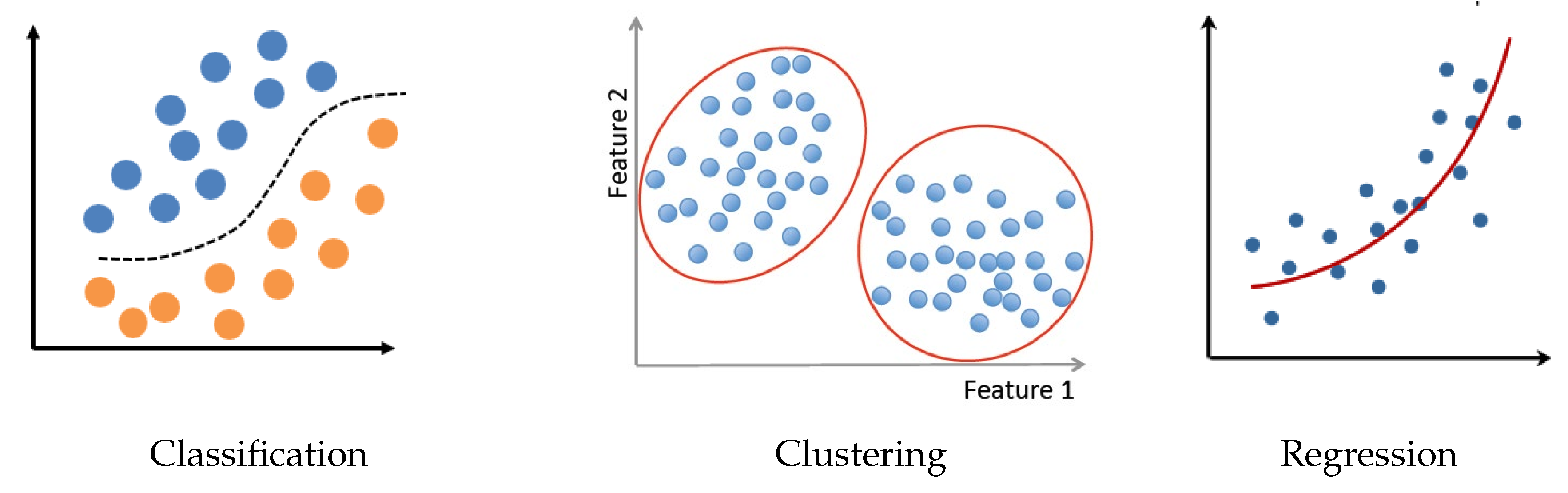
9. Machine Learning’s Basic Idea
- Classification (supervised and semi-supervised);
- Clustering (unsupervised classification when the data do not yet have labels);
- Regression (continuous parameter estimation).
10. Neural Networks, Machine Learning, and Inverse Problems
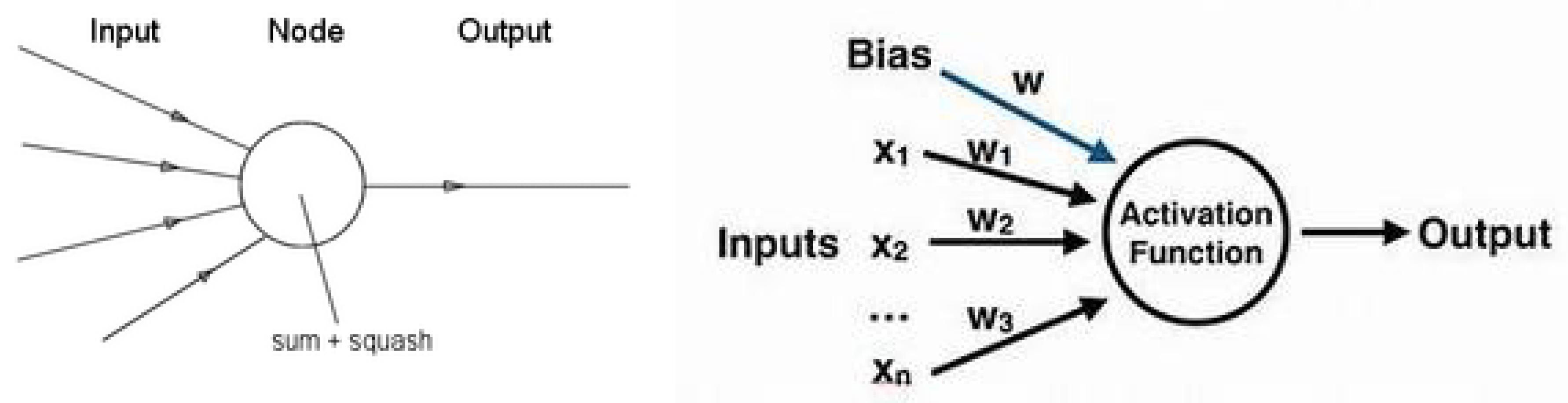
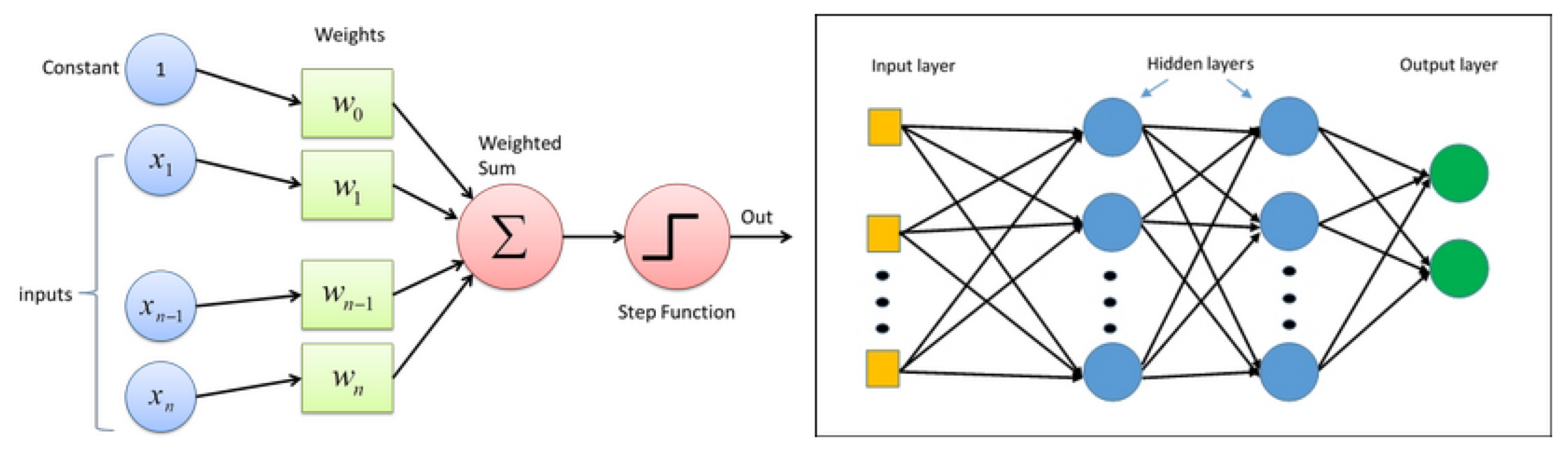
10.1. Neural Networks
10.2. NN and Learning
- Classification (supervised learning)A set of data with labels (classes) are given. The objective during the training is to use them for training the network, which is then used for classifying a new income .
- Clustering (unsupervised learning)A set of data is given. The objective is to cluster them in different classes .
- Regression with all data (supervised learning).A set of data are given. The objective is to find a function F describing the relation between them: or explicitly for any x (extrapolation or interpolation).
10.3. Modeling, Identification, and Inversion
- Forward modeling and inversion
- Identification of a system and the training step of NN
- Inversion (inference) or using the NN-trained model
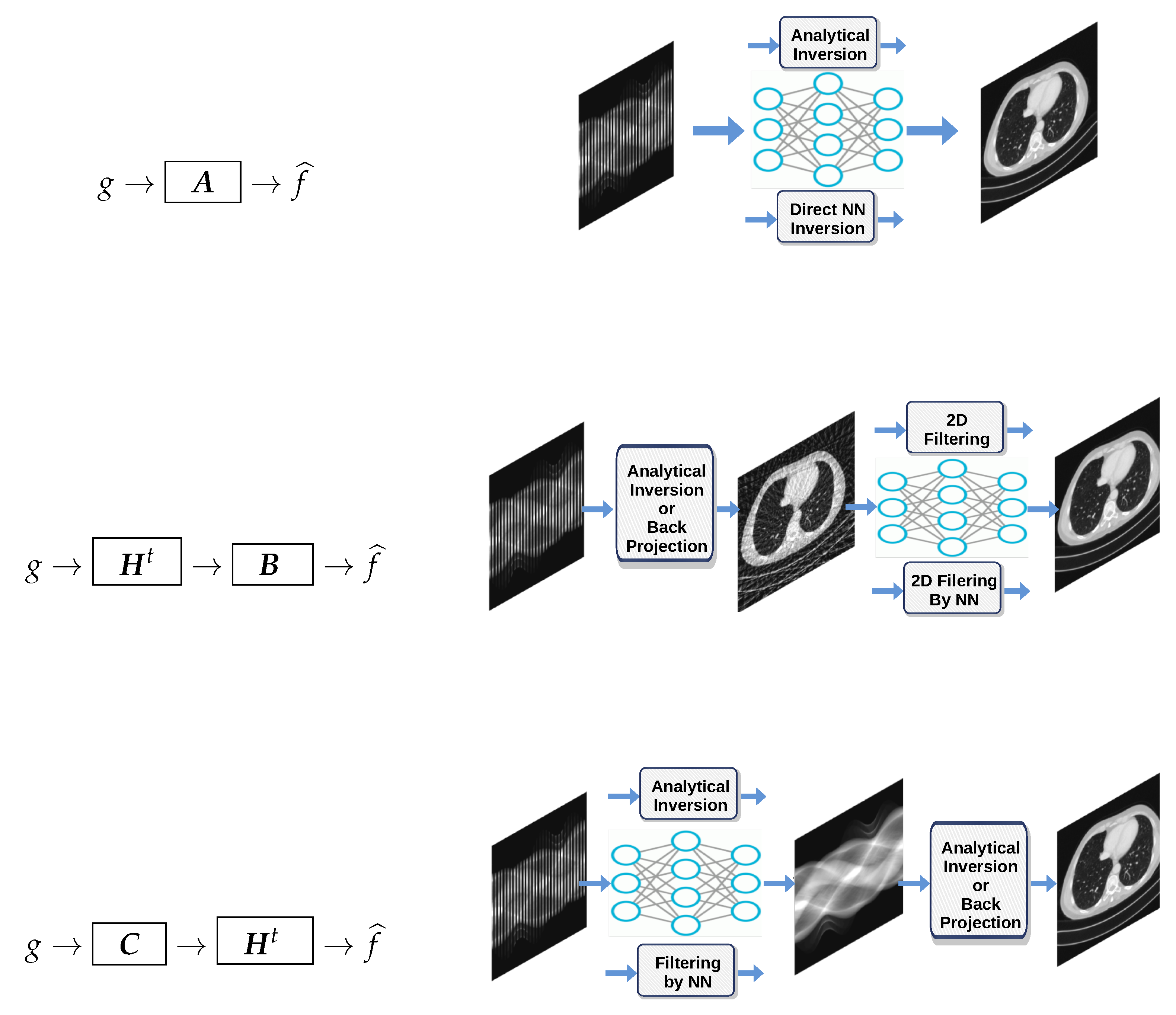
11. ML for Inverse Problems
11.1. First Example: A Linear One- or Two-Layer Feed-Forward NN
11.2. Second Example: Image Denoising with a Two-Layer CNN
11.3. Third Example: A Deep-Learning Equivalence
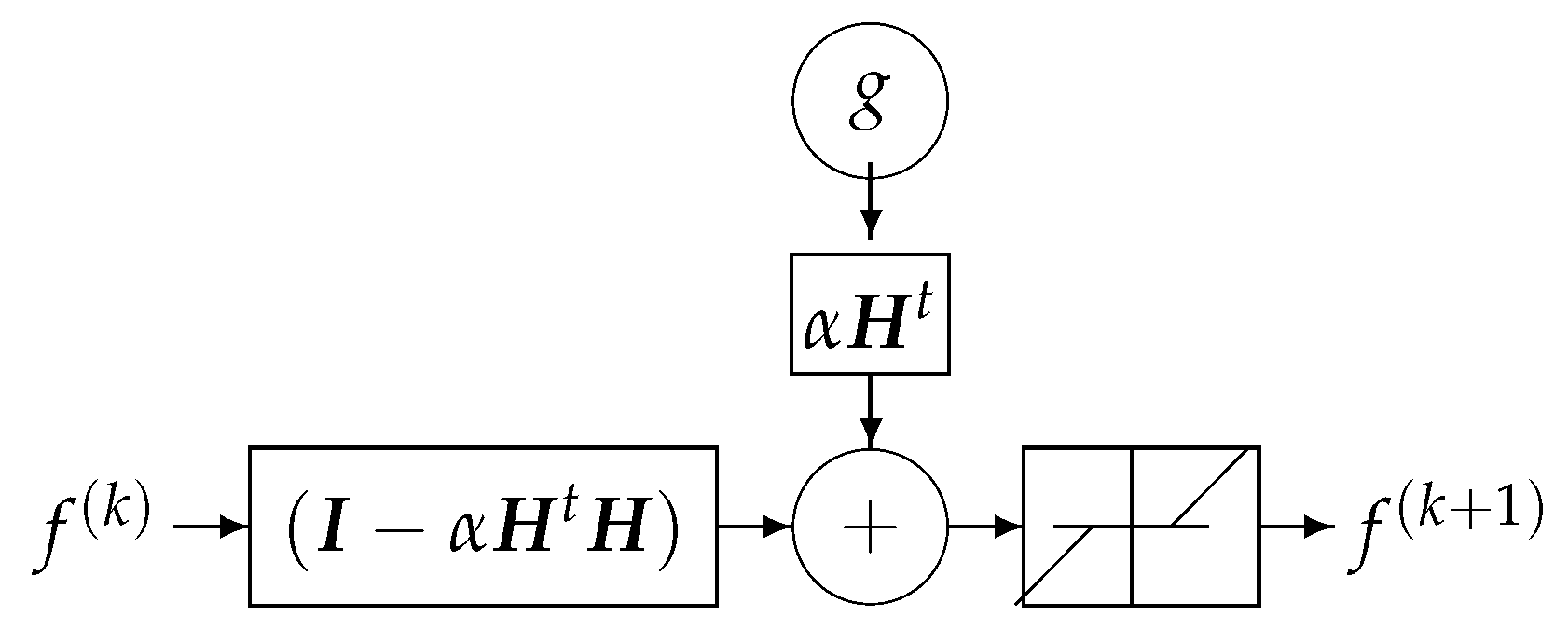
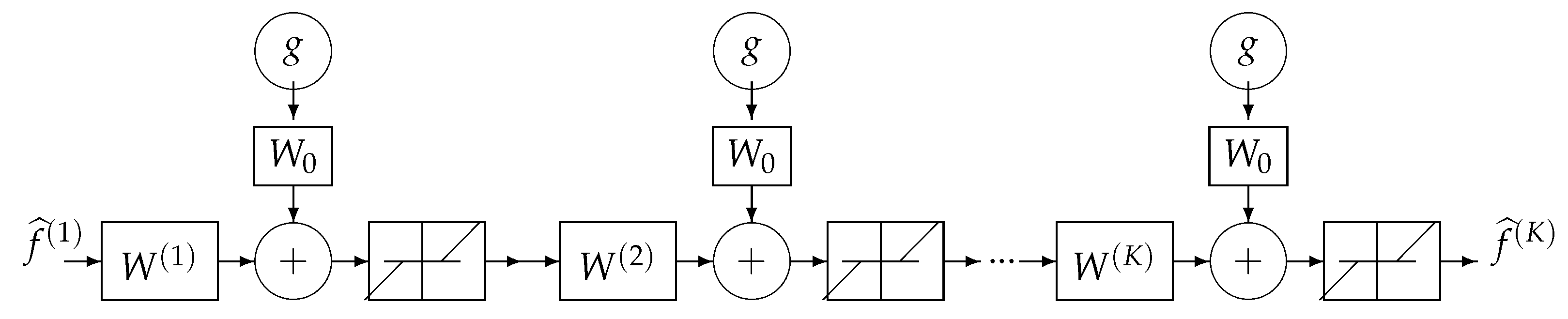
11.4. Fourth Example: Regularization and NN
- can also be approximated by a convolution and thus considered as a filtering operator;
- can be considered as a bias term and is also a convolution operator; and
- is a nonlinear point-wise operator. In particular, when f is a positive quantity, this soft thresholding operator can be compared to the ReLU activation function of NN. See Figure 20.
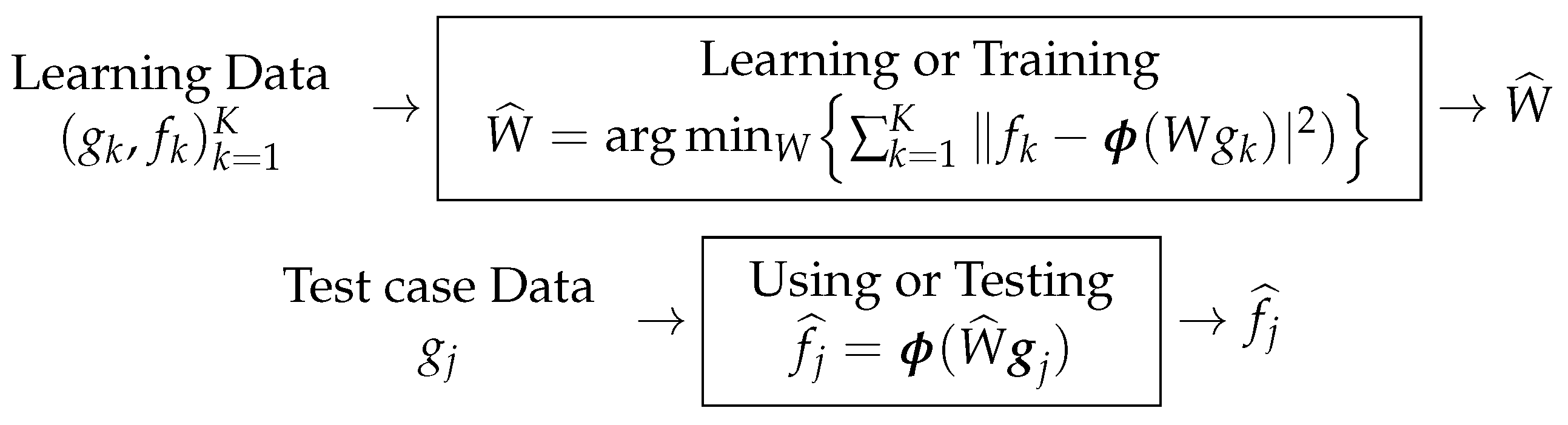
12. ML General Approach
Fully Learned Method
13. Physics-Based ML
13.1. Decomposition of the NN Structure to Fixed and Trainable Parts
13.2. Using Singular-Value Decomposition of Forward and Backward Operators
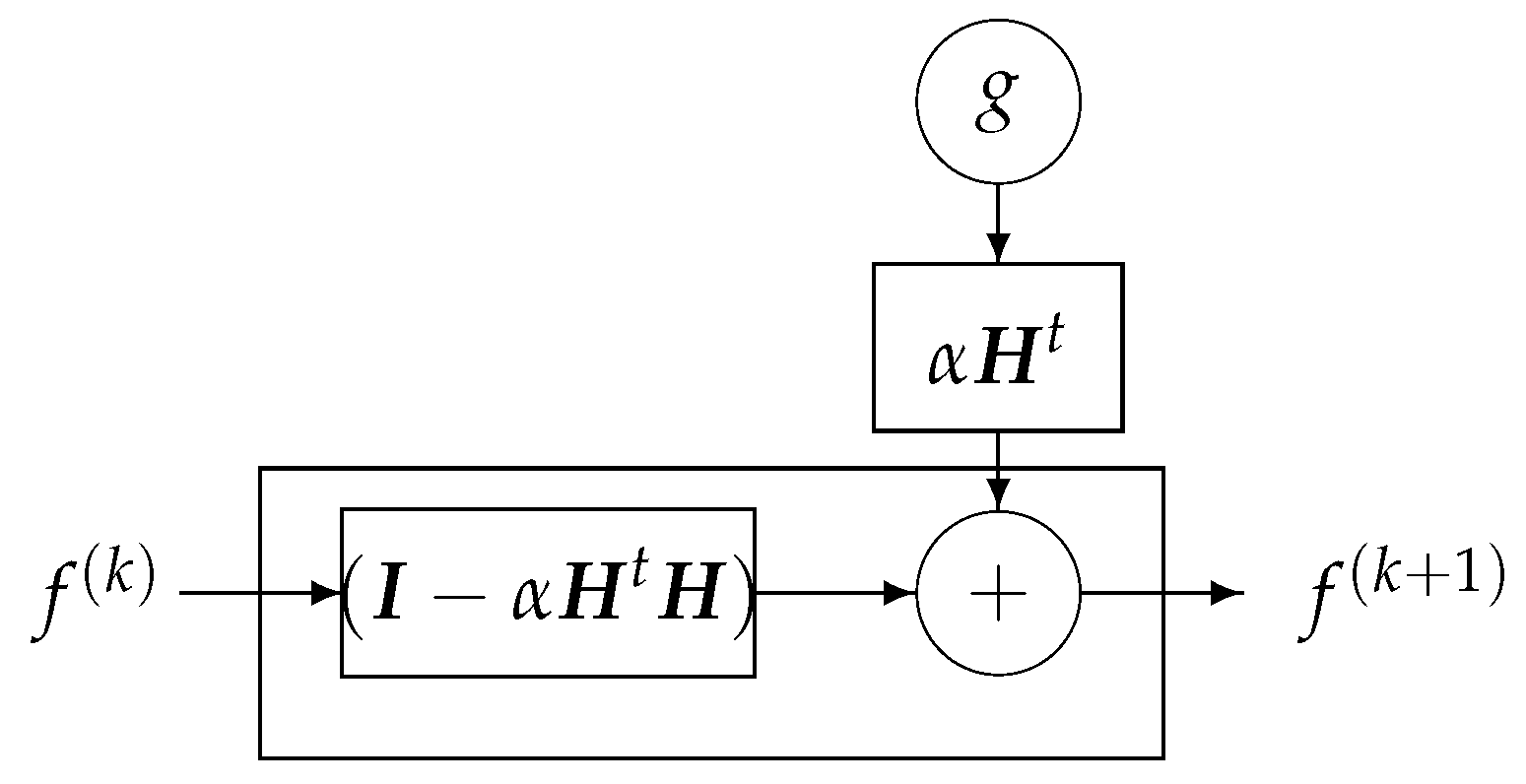
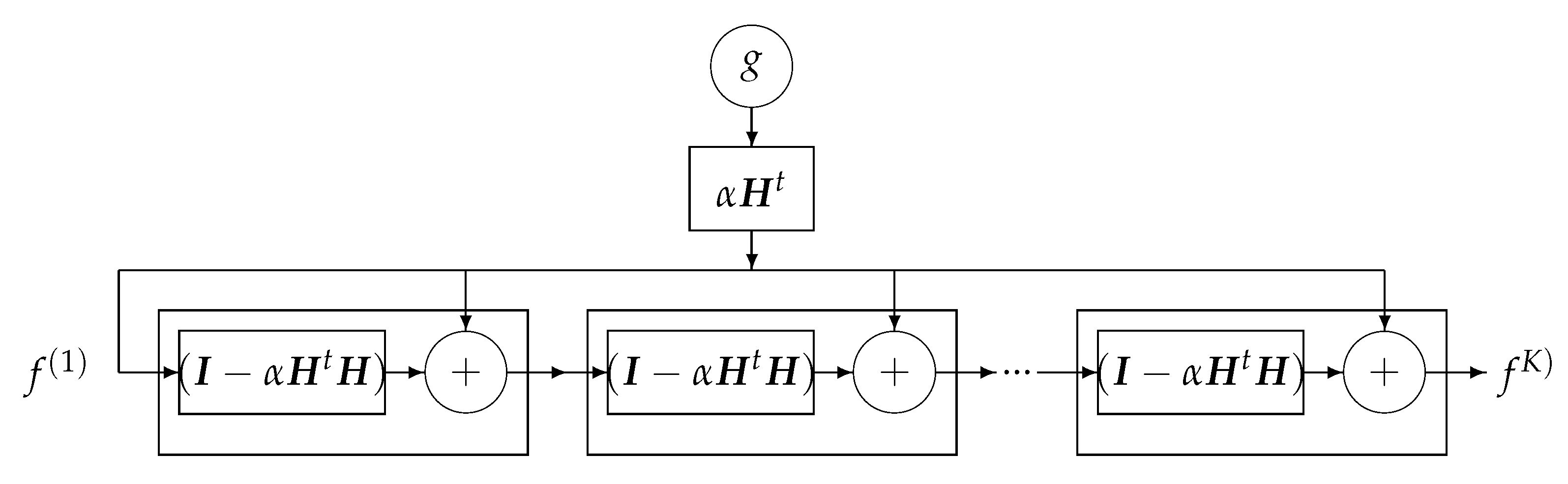
DL Structure Based on Iterative Inversion Algorithm
14. Conclusions and Challenges
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bioucas-Dias, J.M.; Figueiredo, M.A. An iterative algorithm for linear inverse problems with compound regularizers. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 685–688. [Google Scholar]
- Ghadimi, E.; Teixeira, A.; Shames, I.; Johansson, M. Optimal parameter selection for the alternating direction method of multipliers (ADMM): Quadratic problems. IEEE Trans. Autom. Control 2015, 60, 644–658. [Google Scholar] [CrossRef] [Green Version]
- Chambolle, A.; Dossal, C. On the convergence of the iterates of “FISTA”. J. Optim. Theory Appl. 2015, 166, 25. [Google Scholar]
- Ayasso, H.; Duchêne, B.; Mohammad-Djafari, A. MCMC and variational approaches for Bayesian inversion in diffraction imaging. Regul. Bayesian Methods Inverse Probl. Signal Image Process. 2015, 201, 224. [Google Scholar]
- Florea, M.I.; Vorobyov, S.A. A robust FISTA-like algorithm. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4521–4525. [Google Scholar]
- Mohammad-Djafari, A. Inverse problems in imaging science: From classical regularization methods to state of the art Bayesian methods. In Proceedings of the International Image Processing, Applications and Systems Conference, New York, NY, USA, 12–14 December 2014; pp. 1–2. [Google Scholar] [CrossRef]
- Mohammad-Djafari, A. Bayesian inference with hierarchical prior models for inverse problems in imaging systems. In Proceedings of the 2013 8th International Workshop on Systems, Signal Processing and their Applications (WoSSPA), Algiers, Algeria, 12–15 May 2013; pp. 7–18. [Google Scholar] [CrossRef] [Green Version]
- Mohammad-Djafari, A. Bayesian approach with prior models which enforce sparsity in signal and image processing. EURASIP J. Adv. Signal Process. 2012, 2012, 52. [Google Scholar] [CrossRef] [Green Version]
- Ayasso, H.; Duchêne, B.; Mohammad-Djafari, A. Bayesian inversion for optical diffraction tomography. J. Mod. Opt. 2010, 57, 765–776. [Google Scholar] [CrossRef]
- Ren, D.; Zhang, K.; Wang, Q.; Hu, Q.; Zuo, W. Neural Blind Deconvolution Using Deep Priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Online, 14–19 June 2020; pp. 3338–3347. [Google Scholar]
- Bertocchi, C.; Chouzenoux, E.; Corbineau, M.C.; Pesquet, J.C.; Prato, M. Deep Unfolding of a Proximal Interior Point Method for Image Restoration. Inverse Probl. 2019, 36, 034005. [Google Scholar] [CrossRef] [Green Version]
- Jospin, L.V.; Buntine, W.L.; Boussaid, F.; Laga, H.; Bennamoun, M. Hands-on Bayesian Neural Networks—A Tutorial for Deep Learning Users. arXiv 2020, arXiv:2007.06823. [Google Scholar]
- Monga, V.; Li, Y.; Eldar, Y.C. Algorithm Unrolling: Interpretable, Efficient Deep Learning for Signal and Image Processing. IEEE Signal Process. Mag. 2021, 38, 18–44. [Google Scholar] [CrossRef]
- Gilton, D.; Ongie, G.; Willett, R. Model Adaptation for Inverse Problems in Imaging. IEEE Trans. Comput. Imaging 2021, 7, 661–674. [Google Scholar] [CrossRef]
- Repetti, A.; Pereyra, M.; Wiaux, Y. Scalable Bayesian Uncertainty Quantification in Imaging Inverse Problems via Convex Optimization. SIAM J. Imaging Sci. 2019, 12, 87–118. [Google Scholar] [CrossRef] [Green Version]
- Mohammad-Djafari, A. Gauss-Markov-Potts Priors for Images in Computer Tomography resulting to Joint Optimal Reconstruction and Segmentation. Int. J. Tomogr. Stat. 2008, 11, 76–92. [Google Scholar]
- Ayasso, H.; Mohammad-Djafari, A. Joint NDT image restoration and segmentation using Gauss–Markov–Potts prior models and variational bayesian computation. IEEE Trans. Image Process. 2010, 19, 2265–2277. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Féron, O.; Duchêne, B.; Mohammad-Djafari, A. Microwave imaging of inhomogeneous objects made of a finite number of dielectric and conductive materials from experimental data. Inverse Probl. 2005, 21, S95. [Google Scholar] [CrossRef]
- Chapdelaine, C.; Mohammad-Djafari, A.; Gac, N.; Parra, E. A 3D Bayesian Computed Tomography Reconstruction Algorithm with Gauss-Markov-Potts Prior Model and its Application to Real Data. Fundam. Inform. 2017, 155, 373–405. [Google Scholar] [CrossRef] [Green Version]
- Chun, I.Y.; Huang, Z.; Lim, H.; Fessler, J. Momentum-Net: Fast and convergent iterative neural network for inverse problems. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Sandhu, A.I.; Shaukat, S.A.; Desmal, A.; Bagci, H. ANN-assisted CoSaMP Algorithm for Linear Electromagnetic Imaging of Spatially Sparse Domains. IEEE Trans. Antennas Propag. 2021. [Google Scholar] [CrossRef]
- Fang, Z. A High-Efficient Hybrid Physics-Informed Neural Networks Based on Convolutional Neural Network. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Husain, Z.; Madjid, N.A.; Liatsis, P. Tactile sensing using machine learning-driven Electrical Impedance Tomography. IEEE Sens. J. 2021. [Google Scholar] [CrossRef]
- Ongie, G.; Jalal, A.; Metzler, C.A.; Baraniuk, R.G.; Dimakis, A.G.; Willett, R. Deep Learning Techniques for Inverse Problems in Imaging. IEEE J. Sel. Areas Inf. Theory 2020, 1, 39–56. [Google Scholar] [CrossRef]
- Gilton, D.; Ongie, G.; Willett, R. Neumann Networks for Linear Inverse Problems in Imaging. IEEE Trans. Comput. Imaging 2020, 6, 328–343. [Google Scholar] [CrossRef]
- Gong, D.; Zhang, Z.; Shi, Q.; van den Hengel, A.; Shen, C.; Zhang, Y. Learning Deep Gradient Descent Optimization for Image Deconvolution. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5468–5482. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, J.; Zhang, J.; Zhang, X.; Zhou, W. A Deep Learning-Based Method for Heat Source Layout Inverse Design. IEEE Access 2020, 8, 140038–140053. [Google Scholar] [CrossRef]
- Peng, P.; Jalali, S.; Yuan, X. Solving Inverse Problems via Auto-Encoders. IEEE J. Sel. Areas Inf. Theory 2020, 1, 312–323. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Li, B.; Jiang, J. Hessian Free Convolutional Dictionary Learning for Hyperspectral Imagery With Application to Compressive Chromo-Tomography. IEEE Access 2020, 8, 104216–104231. [Google Scholar] [CrossRef]
- de Haan, K.; Rivenson, Y.; Wu, Y.; Ozcan, A. Deep-Learning-Based Image Reconstruction and Enhancement in Optical Microscopy. Proc. IEEE 2020, 108, 30–50. [Google Scholar] [CrossRef]
- Lu, F.; Wu, J.; Huang, J.; Qiu, X. Restricted-Boltzmann-Based Extreme Learning Machine for Gas Path Fault Diagnosis of Turbofan Engine. IEEE Trans. Ind. Inform. 2020, 16, 959–968. [Google Scholar] [CrossRef]
- Zheng, J.; Peng, L. A Deep Learning Compensated Back Projection for Image Reconstruction of Electrical Capacitance Tomography. IEEE Sens. J. 2020, 20, 4879–4890. [Google Scholar] [CrossRef]
- Ren, S.; Sun, K.; Tan, C.; Dong, F. A Two-Stage Deep Learning Method for Robust Shape Reconstruction With Electrical Impedance Tomography. IEEE Trans. Instrum. Meas. 2020, 69, 4887–4897. [Google Scholar] [CrossRef]
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Guo, Y.; et al. DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruction. IEEE Trans. Med. Imaging 2018, 37, 1310–1321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stahlhut, C.; Morup, M.; Winther, O.; Hansen, L.K. Hierarchical Bayesian model for simultaneous EEG source and forward model reconstruction (SOFOMORE). In Proceedings of the 2009 IEEE International Workshop on Machine Learning for Signal Processing, Grenoble, France, 1–4 September 2009; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Idier, J. Bayesian Approach to Inverse Problems; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Mohammad-Djafari, A. Problèmes Inverses en Imagerie et en Vision en Deux Volumes Inséparables; Traité Signal et Image, IC2; ISTE-WILEY: Hoboken, NJ, USA, 2009. [Google Scholar]
- Mohammad-Djafari, A. Inverse Problems in Vision and 3D Tomography; ISTE-Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]
- Penrose, R. A Generalized Inverse for Matrices. Math. Proc. Camb. Philos. Soc. 1955, 51, 406–413. [Google Scholar] [CrossRef] [Green Version]
- Carasso, A.S. Direct Blind Deconvolution. SIAM J. Appl. Math. 2001, 61, 1980–2007. [Google Scholar] [CrossRef]
- Chan, T.; Wong, C.K. Total variation blind deconvolution. IEEE Trans. Image Process. 1998, 7, 370–375. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chu, N.; Mohammad-Djafari, A.; Gac, N.; Picheral, J. A variational Bayesian approximation approach via a sparsity enforcing prior in acoustic imaging. In Proceedings of the 2014 13th Workshop on Information Optics (WIO), Neuchatel, Switzerland, 7–11 July 2014; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Chu, N.; Mohammad-Djafari, A.; Picheral, J. Robust Bayesian super-resolution approach via sparsity enforcing a priori for near-field aeroacoustic source imaging. J. Sound Vib. 2013, 332, 4369–4389. [Google Scholar] [CrossRef] [Green Version]
- Chu, N.; Ning, Y.; Yu, L.; Huang, Q.; Wu, D. A Fast and Robust Localization Method for Low-Frequency Acoustic Source: Variational Bayesian Inference based on Non-Synchronous Array Measurements. IEEE Trans. Instrum. Meas. 2020, 70, 1–18. [Google Scholar] [CrossRef]
- Chu, N.; Zhao, H.; Yu, L.; Huang, Q.; Ning, Y. Fast and High-Resolution Acoustic Beamforming: A Convolution Accelerated Deconvolution Implementation. IEEE Trans. Instrum. Meas. 2020, 70, 1–15. [Google Scholar] [CrossRef]
- Gharsalli, L.; Duchêne, B.; Mohammad-Djafari, A.; Ayasso, H. Microwave tomography for breast cancer detection within a variational Bayesian approach. In Proceedings of the 21st European Signal Processing Conference (EUSIPCO 2013), Marrakech, Morocco, 9–13 September 2013; pp. 1–5. [Google Scholar]
- Gharsalli, L.; Duchêne, B.; Mohammad-Djafari, A.; Ayasso, H. A Gauss-Markov mixture prior model for a variational Bayesian approach to microwave breast imaging. In Proceedings of the 2014 IEEE Conference on Antenna Measurements Applications (CAMA), Vasteras, Sweden, 3–6 September 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Premel, D.; Mohammad-Djafari, A. Eddy current tomography in cylindrical geometry. IEEE Trans. Magn. 1995, 31, 2000–2003. [Google Scholar] [CrossRef]
- Kak, A.C.; Slaney, M. Principles of Computerized Tomographic Imaging; SIAM: Philadelphia, PA, USA, 2001. [Google Scholar]
- Jackson, J.I.; Meyer, C.H.; Nishimura, D.G.; Macovski, A. Selection of a convolution function for Fourier inversion using gridding [computerized tomography application]. IEEE Trans. Med. Imaging 1991, 10, 473–478. [Google Scholar] [CrossRef] [Green Version]
- Osher, S.; Burger, M.; Goldfarb, D.; Xu, J.; Yin, W. An iterative regularization method for total variation-based image restoration. Multiscale Model. Simul. 2005, 4, 460–489. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, J.; Yin, W.; Zhang, Y. A new alternating minimization algorithm for total variation image reconstruction. SIAM J. Imaging Sci. 2008, 1, 248–272. [Google Scholar] [CrossRef]
- Goldstein, T.; Osher, S. The split Bregman method for L1-regularized problems. SIAM J. Imaging Sci. 2009, 2, 323–343. [Google Scholar] [CrossRef]
- Sun, Y.; Wu, Z.; Xu, X.; Wohlberg, B.; Kamilov, U.S. Scalable Plug-and-Play ADMM With Convergence Guarantees. IEEE Trans. Comput. Imaging 2021, 7, 849–863. [Google Scholar] [CrossRef]
- Mohammad-Djafari, A. Joint estimation of parameters and hyperparameters in a Bayesian approach of solving inverse problems. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 16–19 September 1996; Volume 1, pp. 473–476. [Google Scholar] [CrossRef] [Green Version]
- Mohammad-Djafari, A.; Ayasso, H. Variational Bayes and mean field approximations for Markov field unsupervised estimation. In Proceedings of the 2009 IEEE International Workshop on Machine Learning for Signal Processing, Grenoble, France, 1–4 September 2009; pp. 1–6. [Google Scholar]
- Blei, D.; Kucukelbir, A.; McAuliffe, J. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2016, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Mohammad-Djafari, A.; Gac, N. X-ray Computed Tomography using a sparsity enforcing prior model based on Haar transformation in a Bayesian framework. Fundam. Inform. 2017, 155, 449–480. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Gac, N.; Mohammad-Djafari, A. Bayesian 3D X-ray computed tomography image reconstruction with a scaled Gaussian mixture prior model. AIP Conf. Proc. 2015, 1641, 556–563. [Google Scholar]
- Chapdelaine, C.; Mohammad-Djafari, A.; Gac, N.; Parra, E. A Joint Segmentation and Reconstruction Algorithm for 3D Bayesian Computed Tomography Using Gauss-Markov-Potts Prior Model. In Proceedings of the 42nd IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Chapdelaine, C.; Gac, N.; Mohammad-Djafari, A.; Parra, E. New GPU implementation of Separable Footprint Projector and Backprojector: First results. In Proceedings of the 5th International Conference on Image Formation in X-Ray Computed Tomography, Baltimore, MD, USA, 4 November 2018. [Google Scholar]
- Chapdelaine, C. Variational Bayesian Approach and Gauss-Markov-Potts prior model. arXiv 2018, arXiv:1808.09552. [Google Scholar]
- Ciresan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Flexible, High Performance Convolutional Neural Networks for Image Classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 1237–1242. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. arXiv 2013, arXiv:1311.2901. [Google Scholar]
- Nan, Y.; Quan, Y.; Ji, H. Variational-EM-Based Deep Learning for Noise-Blind Image Deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Online, 13–19 June 2020. [Google Scholar]
- Saul, L.K.; Roweis, S.T. Think globally, fit locally: Unsupervised learning of low dimensional manifolds. J. Mach. Learn. Res. 2003, 4, 119–155. [Google Scholar]
- Arel, I.; Rose, D.C.; Karnowski, T.P. Deep machine learning—A new frontier in artificial intelligence research. Comput. Intell. Mag. 2010, 5, 13–18. [Google Scholar] [CrossRef]
- Cho, K.; Raiko, T.; Ilin, A. Enhanced gradient for training restricted Boltzmann machines. Neural Comput. 2013, 25, 805–831. [Google Scholar] [CrossRef]
- Cho, K. Foundations and Advances in Deep Learning. Ph.D. Thesis, Aalto University School of Science, Espoo, Finland, 2014. [Google Scholar]

























Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammad-Djafari, A. Regularization, Bayesian Inference, and Machine Learning Methods for Inverse Problems. Entropy 2021, 23, 1673. https://doi.org/10.3390/e23121673
Mohammad-Djafari A. Regularization, Bayesian Inference, and Machine Learning Methods for Inverse Problems. Entropy. 2021; 23(12):1673. https://doi.org/10.3390/e23121673
Chicago/Turabian StyleMohammad-Djafari, Ali. 2021. "Regularization, Bayesian Inference, and Machine Learning Methods for Inverse Problems" Entropy 23, no. 12: 1673. https://doi.org/10.3390/e23121673
APA StyleMohammad-Djafari, A. (2021). Regularization, Bayesian Inference, and Machine Learning Methods for Inverse Problems. Entropy, 23(12), 1673. https://doi.org/10.3390/e23121673