1. Introduction
The present work is inspired by the current practices in Information Geometry [
1,
2,
3] where minimization of divergences is an important tool. In Statistical Physics a divergence is called a relative entropy. Its importance was noted rather late in the twentieth century, after the work of Jaynes on the maximal entropy principle [
4]. Estimation in the presence of hidden variables by minimizing a divergence function is briefly discussed in Chapter 8 of [
2].
Assume now that some observation or experiment yields new statistical data. The approach is then to look for a probability distribution that reproduces the newly observed probabilities and that interpolates the data with missing information coming from a prior.
No further model assumptions are imposed. Hence, the statistical model under consideration consists of all probability distributions that are consistent with the newly obtained empirical data. Internal consistency of the empirical data ensures that the model is not empty. The update is the model point that minimizes the chosen divergence function from the prior to the manifold of the model.
In the context of Maximum Likelihood Estimation (MLE) one usually adopts a parameterized model. The dimension of the model can be kept low and properties of the model can be used to ease the calculations. One assumes that the new data can lead to a more accurate estimation of the limited number of model parameters. It can then happen that the model is misspecified [
5] and that the update is only a good approximation of the empirical data.
Here, the model is dictated by the newly acquired empirical data and the update is forced to reproduce the measured data. Finding the probability distribution is then an underdetermined problem. Minimization of the divergence from the prior probability distribution solves the underdetermination.
In Bayesian statistics, the update
of the probability
of an event
B equals
The quantities
and
are the empirical probabilities obtained after repeated measurement of event
A and its complement
. Expression (
1) has been called
Jeffrey conditioning [
6]. It implies the sufficiency conditions
and
. It is an updating rule used in Radical Probabilism [
7]. This expression is also obtained when minimizing the Hellinger distance between the prior and the model manifold. A proof of the latter follows later on in
Section 4.
The present approach is a special case of minimizing a divergence function in the presence of linear constraints. See the introduction of [
8] for an overview of early applications of this technique. Two classes of generalized distance functions satisfy a natural set of axioms: the f-divergences of Csiszár and the generalized Bregman divergences. The squared Hellinger distance belongs to the former class. The other divergence function considered here is the square Bregman divergence. Both Hellinger and square Bregman have special properties that make it easy to work with them.
A broad class of generalized Bregman divergences satisfies the Pythagorean equality [
8,
9]. Pythagorean inequalities hold for an even larger class [
10]. The Pythagorean relations derived in the present work make use of the specific properties of the Hellinger distance and of the quadratic Bregman divergence. It is unclear how to prove them for more general divergences.
One incentive for starting the present work is a paper of Banerjee, Guo, and Wang [
11,
12]. They consider the problem of predicting a random variable
given observations of a random variable
. It is well-known that the conditional expectation, as defined by Kolmogorov, is the optimal predictor. They show that this statement remains true when the metric distance is replaced by a Bregman divergence. It is shown in Theorem 2 below that a proof in a more general context yields a deviating result.
The next Section fixes notations.
Section 3 collects some results about the squared Hellinger distance and the quadratic Bregman divergence.
Section 4 discusses the optimal choice and contains the Theorems 1 and 2. The proof of the theorems can be adapted to cover the situation that a subsequent measurement also yields information on conditional probabilities. This is shown in
Section 4.3.
Section 5 treats a simple example. A final section summarizes the results of the paper.
2. Empirical Data
Consider a probability space
. A measurable subset
A of
is called an event. Its probability is denoted
and is given by
where
equals 1 when
and 0 otherwise. The conditional expectation of a random variable
f given an event
A with non-vanishing probability
is given by
The probability space reflects the prior knowledge of the system at hand. When new data become available an update procedure is used to select the posterior probability space. The latter is denoted in what follows. The corresponding probability of an event A is denoted .
The outcome of repeated experiments is the empirical probability distribution of the events, denoted . The question at hand is then to establish a criterion for finding the update of the probability distribution that is as close as possible to while reproducing the empirical results.
The event
A defines a partition
of the probability space
. As before
denotes the complement of
A in
. In what follows a slightly more general situation is considered in which the event
A is replaced by a partition
of the measure space
into subsets with non-vanishing probability. The notations
and
are used, with
Introduce the random variable
g defined by
when
. Repeated measurement of the random variable
g yields the empirical probabilities
They may deviate from the prior probabilities
. In some cases one also measures the conditional probabilities
of some other event
B.
3. A Geometric Approach
In this section two divergences are reviewed, the squared Hellinger distance and the quadratic Bregman divergence.
3.1. Squared Hellinger Distance
For simplicity the present section is restricted to the case that the sample space is the real line.
Given two probability measures
and
, both absolutely continuous w.r.t. the Lebesgue measure, the squared Hellinger distance is the divergence
defined by
Let
be a partition of
and let
when
x belongs to
, as before. Let
and
be defined by (
2). Consider the following functions of
i, with
i in
,
where each of the
is a probability distribution with support in
. The empirical expectation of a function
is given by
.
Proposition 1. If for all i and then one haswith equality if and only if for all i. First prove the following two lemmas.
Lemma 1. Assume that the probability measure is absolutely continuous w.r.t. the measure , with Radon-Nikodym derivative given by . Then one hasand Proof. Now take to obtain the desired results. □
Lemma 2. (Pythagorean relation) For any i is Proof. The proof follows by taking in the previous lemma. □
Proof. (Proposition 1)
From the previous lemma it follows that
. Note that
implies that
and hence
. Conversely, if
then it follows from the previous lemma that
. If in addition
for all
i then it follows that for all
i Because the squared Hellinger distance is a divergence, this implies that
, which is equivalent with
. □
3.2. Bregman Divergence
In the present section the squared Hellinger distance, which is an f-divergence, is replaced by a divergence of the Bregman type. In addition let
be a finite set equipped with the counting measure
. It assigns to each subset
A of
the number of elements in
A. This number is denoted
. The expectation value
of a random variable
f w.r.t. the probability measure
is given by
Given a partition of
into sets
one can define conditional probability measures with probability mass function
given by
Similarly, conditional probability measures with probability mass function
are given by
Fix a strictly convex function
. The Bregman divergence of the probability measures
and
is defined by
with
In the case that
, which is used below, it becomes
For convenience, this case is referred to as the
quadratic Bregman divergence.
The following result, obtained with the quadratic Bregman divergence, is more elegant than the result of Lemma 2.
Proposition 2. Consider the quadratic Bregman divergence as given by (5). Let . Let be any probability measure with support in . Then the following Pythagorean relation holds. Proof. One calculates
Use now that
and the normalization of the probability measures
and
to find the desired result. □
4. The Optimal Choice
4.1. Updated Probabilities
The following result proves that the standard Kolmogorovian definition of the conditional probability minimizes the Hellinger distance between the prior probability measure
and the updated probability measure
. The optimal choice of the updated probability measure
is given by corresponding probabilities
. They satisfy
Theorem 1. Let be given a partition of the probability space with . Let be given by (2). Let denote the probability of the event and let be given strictly positive empirical probabilities , . The squared Hellinger distance as a function of σ is minimal if and only if for all i. Here, σ is any probability measure on Ω satisfyingand each of the is a probability measure with support in and absolutely continuous w.r.t. . Note that the probability measure
given by
uses the Kolmogorovian conditional probability as the predictor because the probabilities determined by the
are obtained from the prior probability distribution
by
. By the above theorem this predictor is the optimal one w.r.t. the squared Hellinger distance.
Proof. With the notations of the previous section is
Proposition 1 shows that it is minimal if and only if for all i. □
Next, consider the use of the quadratic Bregman divergence in the context of a finite probability space.
Theorem 2. Let be given a partition of the finite probability space . Let be the counting measure on defined by (3). Let be given by (2). Let denote the probability of the event and let be given strictly positive empirical probabilities , summing up to 1. Assume thatThen the following hold. - (a)
A probability distribution ν is defined by with - (b)
Let σ be any probability measure on Ω satisfying , where each of the is a probability distribution with support in . Then the quadratic Bregman divergence satisfies the Pythagorean relation - (c)
The quadratic Bregman divergence is minimal if and only if .
Proof. The assumption (6) guarantees that the are probabilities.
One calculates
In the above calculation the third line is obtained by eliminating
using the definition of
. This gives
The term
vanishes because
is constant on the set
and the probability measures
and
have support in
.
(c)
From (b) it follows that , with equality when .
Conversely, when
then (8) implies that
The empirical probabilities are strictly positive by assumption. Hence, it follows that
for all
i and hence, that
for all
i. The latter implies
. □
The optimal update
can be written as
This result is in general quite different from the update proposed by Theorem 1, which is
The updates proposed by the two theorems coincide only in the special cases that either
for all
i or that
for all
i. In the latter case the prior distribution
is replaced by the update
.
The entropy of the update when event
is observed, according to Theorem 1, equals
. According to Theorem 2 it equals
If
then it follows that
The former inequality follows because the entropy is a concave function. The latter follows because entropy is maximal for the uniform distribution
. On the other hand, if
then one has
In the latter case the decrease of the entropy is stronger than in the case of the update based on the squared Hellinger distance. In conclusion, the update relying on the quadratic Bregman divergence looses details of the prior distribution by making a convex combination with a uniform distribution weighed with the probabilities of the observation. It does this moreso for the events with observed probability larger than predicted; this is when
.
Note that Theorem 2 cannot always be applied because it contains restrictions on the empirical probabilities. In particular, if the prior probability of some point x in vanishes then the condition (6) requires that the empirical probability of the partition to which the point x belongs is larger than or equal to the prior probability .
4.2. Update of Conditional Probabilities
The two previous theorems assume that no empirical information is available about conditional probabilities. If such information is present then an optimal choice should make use of it. In one case the solution of the problem is straightforward. If the probabilities are available together with all conditional probabilities and there exists an update which reproduces these results then it is unique. Two cases remain: (1) The information about the conditional probabilities is incomplete; (2) the information is internally inconsistent – no update exists which reproduces the data.
Let us tackle the problem by considering the case that the only information that is available besides the probabilities
is the vector of conditional probabilities
of a fixed event
B, given the outcome of the measurement of the random variable
g as introduced in
Section 2.
The following result is independent of the choice of divergence function.
Proposition 3. Fix an event B in Ω. Assume that the conditional probabilities , , are strictly positive and strictly less than 1. Assume in addition that for all i. Then there exists an update ν with corresponding probabilities such that and , .
Proof. An obvious choice is to take
of the form
with
of the form
with
and
. Normalization of the
gives the conditions
Reproduction of the conditional probabilities gives the conditions
The latter gives
The normalization condition (9) becomes
It has a positive solution for
because
and
. □
4.3. The Hellinger Case
The optimal updates can be derived easily from Theorem 1. Double the partition by introduction of the following sets
They have prior probabilities
. Corresponding prior measures
are defined by
The empirical probability of the set
is taken equal to
, that of
equals
. The optimal update
follows from Theorem 1 and is given by
By construction it is
One now verifies that
and
, which is the intended result.
4.4. The Bregman Case
Next consider the optimization with the quadratic Bregman divergence. Probability distributions
are defined by
Introduce the notations
Then the condition for Theorem 2 to hold is that
for all
. The optimal probability distribution
is given by
5. Example
Assume that the prior probability distribution is binomial with parameters
, where
n is known with certainty. The probability mass function is given by
The probability distribution and the value of the parameter
are for instance the result of theoretical modeling of the experiment. Or they are obtained from a different kind of experiment.
The experiment under consideration yields accurate values for the probability of the two events and . The problem at hand is to predict by extrapolation the probability of the event for other values of k. A fit of the data with a binomial distribution is likely to fail because two accurate data points are given to determine a single parameter . The binomial model can be misspecified.
The geometric approach followed in the present paper yields an update from the binomial distribution to another distribution, one which is reproducing the data. The update is conducted in an unbiased manner. Quite often one is tempted to replace the model, in the case of the binomial model, by a model with one extra free parameter.
Let us see what are the results of minimizing divergence functions. The probability space
is the set of integers
equipped with the uniform measure. Choose events
This gives for
The optimal update according to Theorem 1, minimizing the Hellinger distance, is given by the probabilities
In particular, the probability mass function
becomes
The optimal update according to Theorem 2, minimizing the quadratic Bregman divergence, is given by (7). The auxiliary measures
,
, and
have probability mass functions given by
and
The probability mass function
becomes
The condition (6) is the requirement that all
are non-negative. Because the probabilities
can become very small this essentially means that
should be larger than
. The amount of probability missing in the empirical probabilities
and
is equally distributed over the remaining
points of
. On the other hand, when minimizing the Hellinger distance the excess or shortage of probability is compensated by multiplying all remaining probabilities by a constant factor.
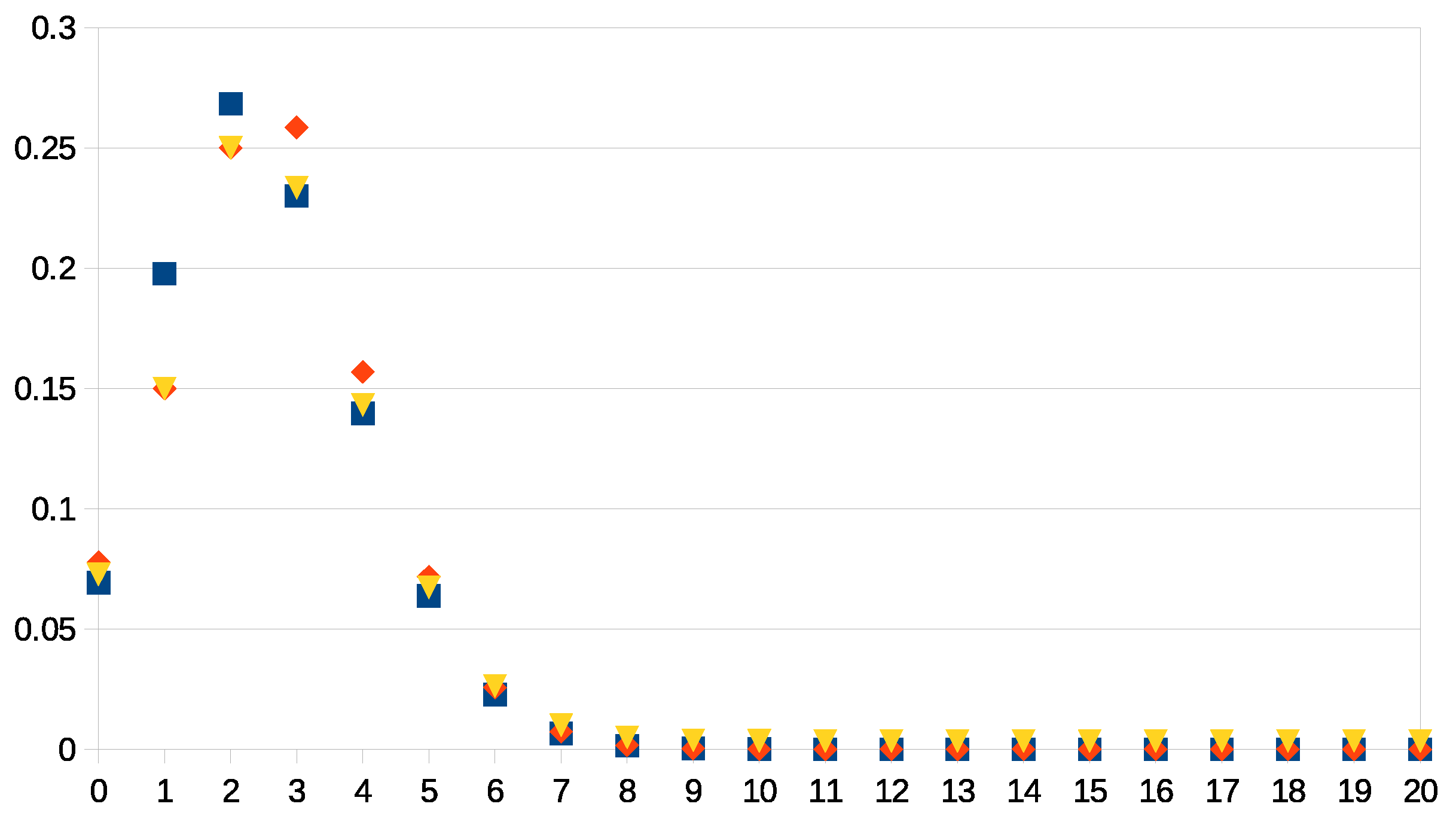
A numerical comparison with
and
is found in
Figure 1. The empirical values are
and
. The difference with the prior values
and
is made large enough to amplify the effects of the update.
6. Summary
It is well known that the use of unmodified prior conditional probabilities is the optimal way for updating a probability distribution after new data become available. The update procedure minimizes the Hellinger distance between prior and posterior probability distributions. For the sake of completeness a proof is given in Theorem 1.
Alternatively, one can minimize the quadratic Bregman divergence instead of the Hellinger distance. The result is given in Theorem 2. The conservation of probability is handled in a different way in the two cases, either by multiplying prior probabilities with a suitable factor or by adding an appropriate term.
The example of
Section 5 shows that the two update procedures have different effects and that neither of them may be satisfactory. This raises the question whether the present approach should be improved by choosing divergences other than Hellinger or Bregman.
In the present research, the work of Banerjee, Guo, and Wang [
11] was considered as well. They prove that minimization of the Hellinger distance can be replaced by minimization of a Bregman divergence, without modifying the outcome. It is shown in Theorem 2 that, in a different context, the use of the Bregman divergence yields results quite distinct from those obtained by minimizing the Hellinger distance.



{kind=link}
