
Adaptive Information Sharing with Ontological Relevance Computation for Decentralized Self-Organization Systems


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Decentralized Information Sharing Problem
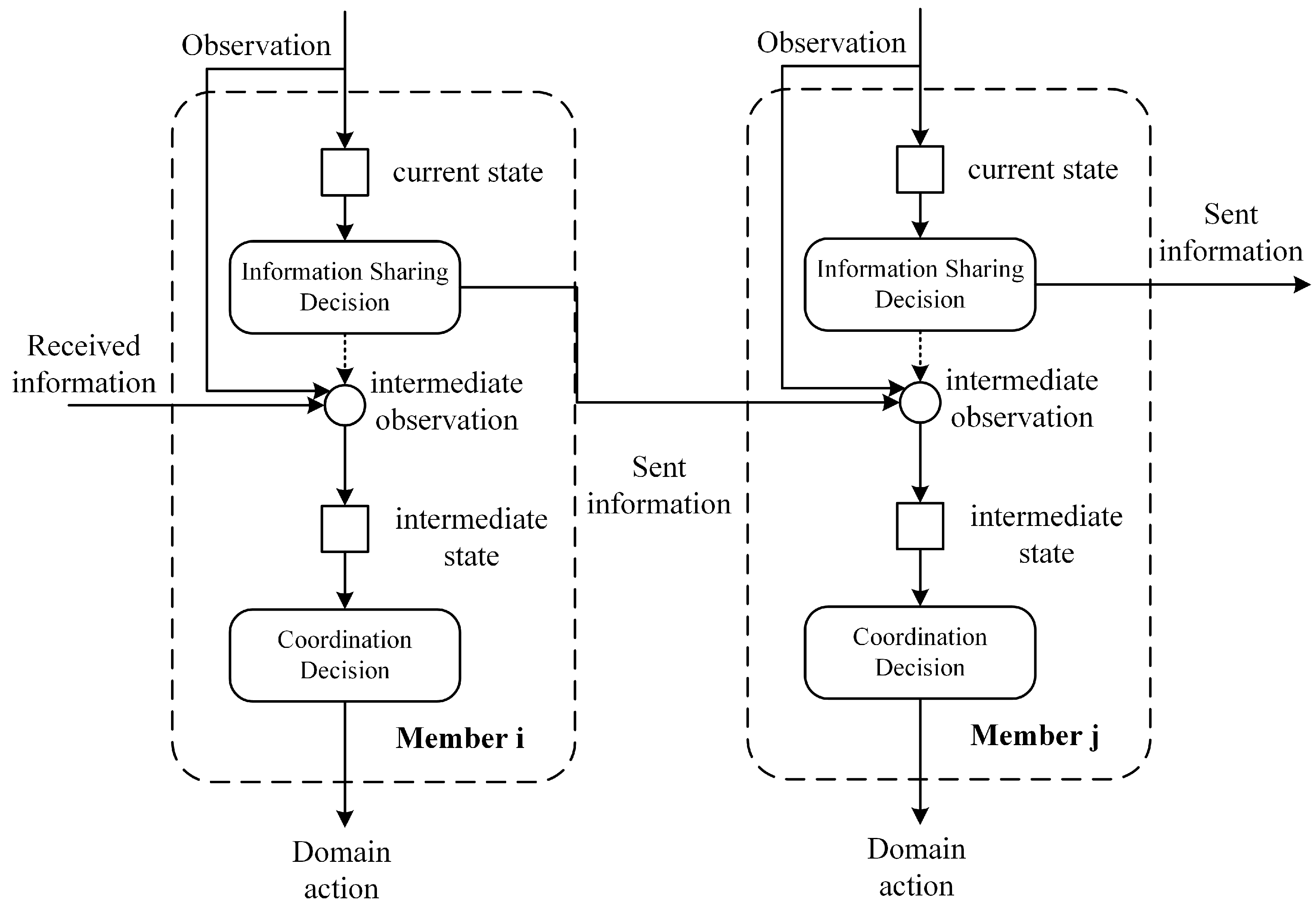
2.1. Information Sharing Decision Process
2.2. Decision Theoretical Model
- denotes the information state of the team. At time t, where is a set of information states about the system that a member of the team possesses.
- defines a member’s observation of the environment.
- defines the members’ communication sets, which consists of each member’s information, such that . Information in member a’s communication set is either received or sensed by a.
- B is the member’s perceived belief state of the team. The probability is the inferred belief of member a of the state of the team at time t.
- is the transition function, which maps the impact of team members’ communication action to the belief state. More formally, at time t, .
- represents members’ communication action. is the decision of member a on which a neighbor should receive information .
- is the reward function that returns the cost of choices made by individual members. The rewards obtained over time by individual members adopting a specific course of communication action can be viewed as random variables . For instance, when the individual members carry out their preferred actions based on a set of related information received by one of its members, , the cost of these actions is the reward, , returned by the reward function. A team receives negative values as the cost of information sharing.
2.3. Practical Information Sharing Model
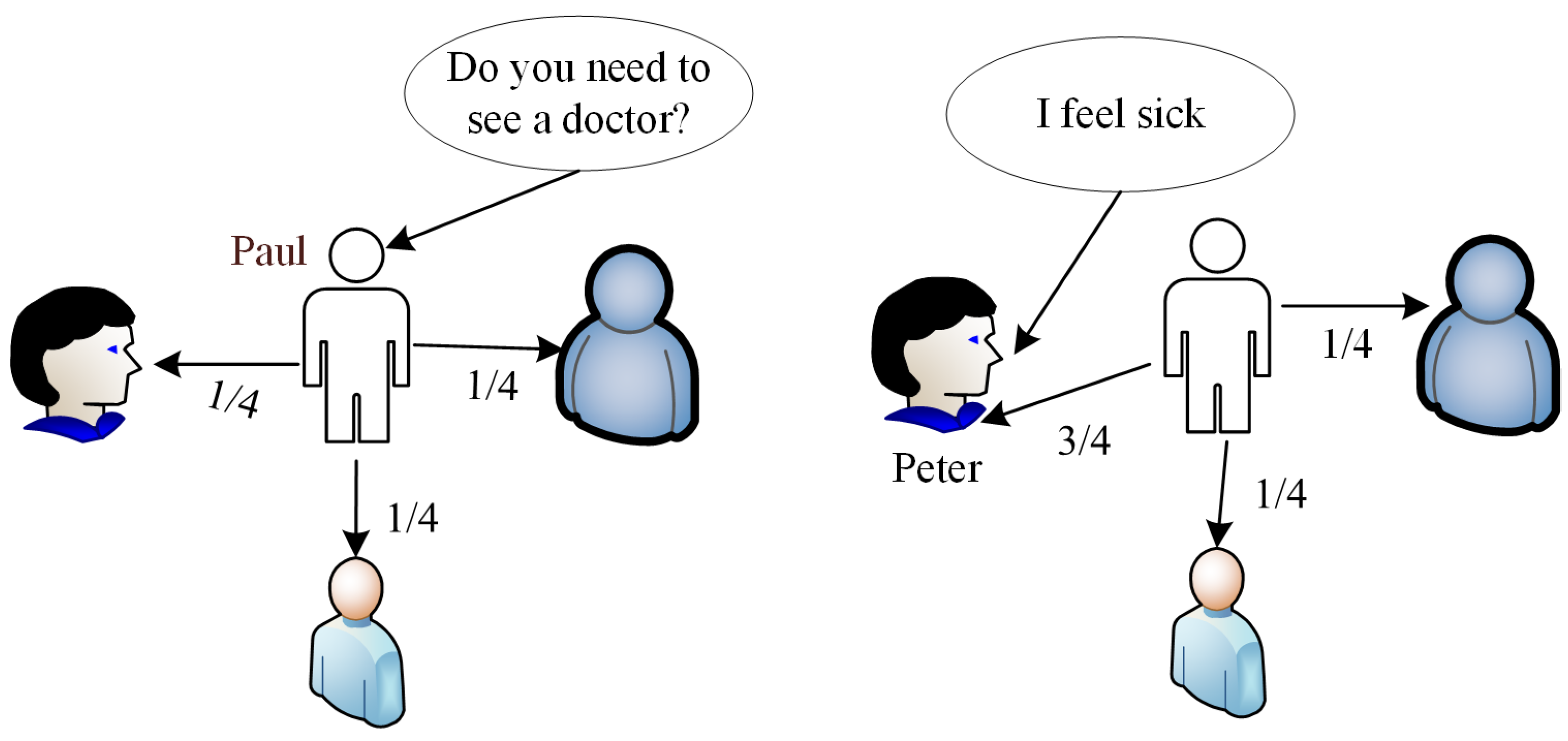
3. Ontological Approach for Computing Information Relevance
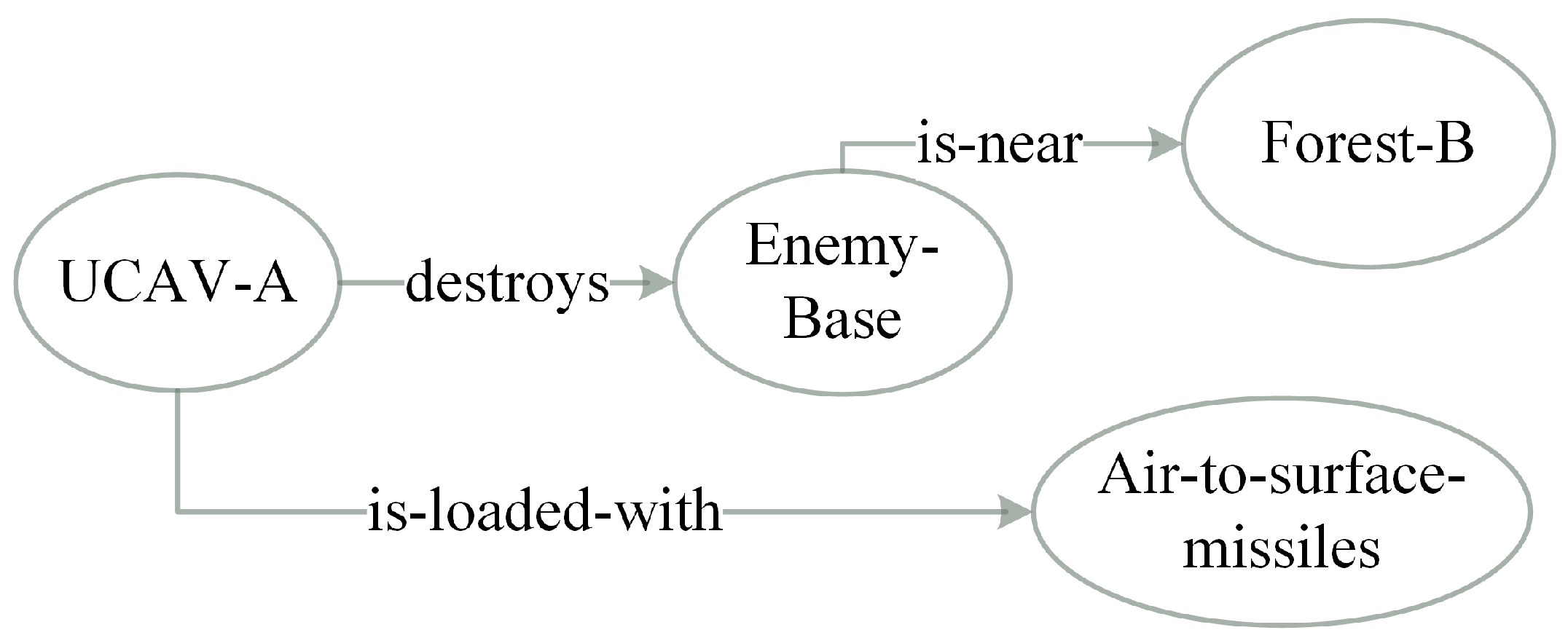
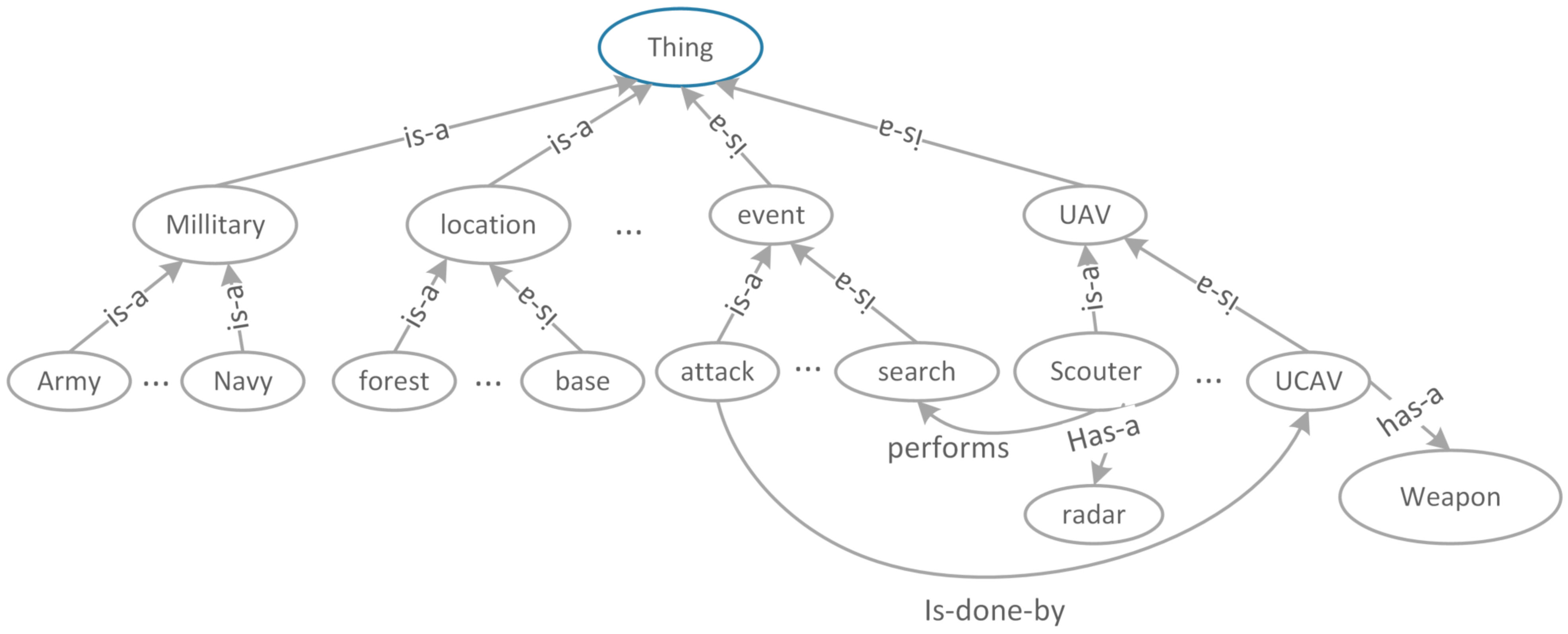
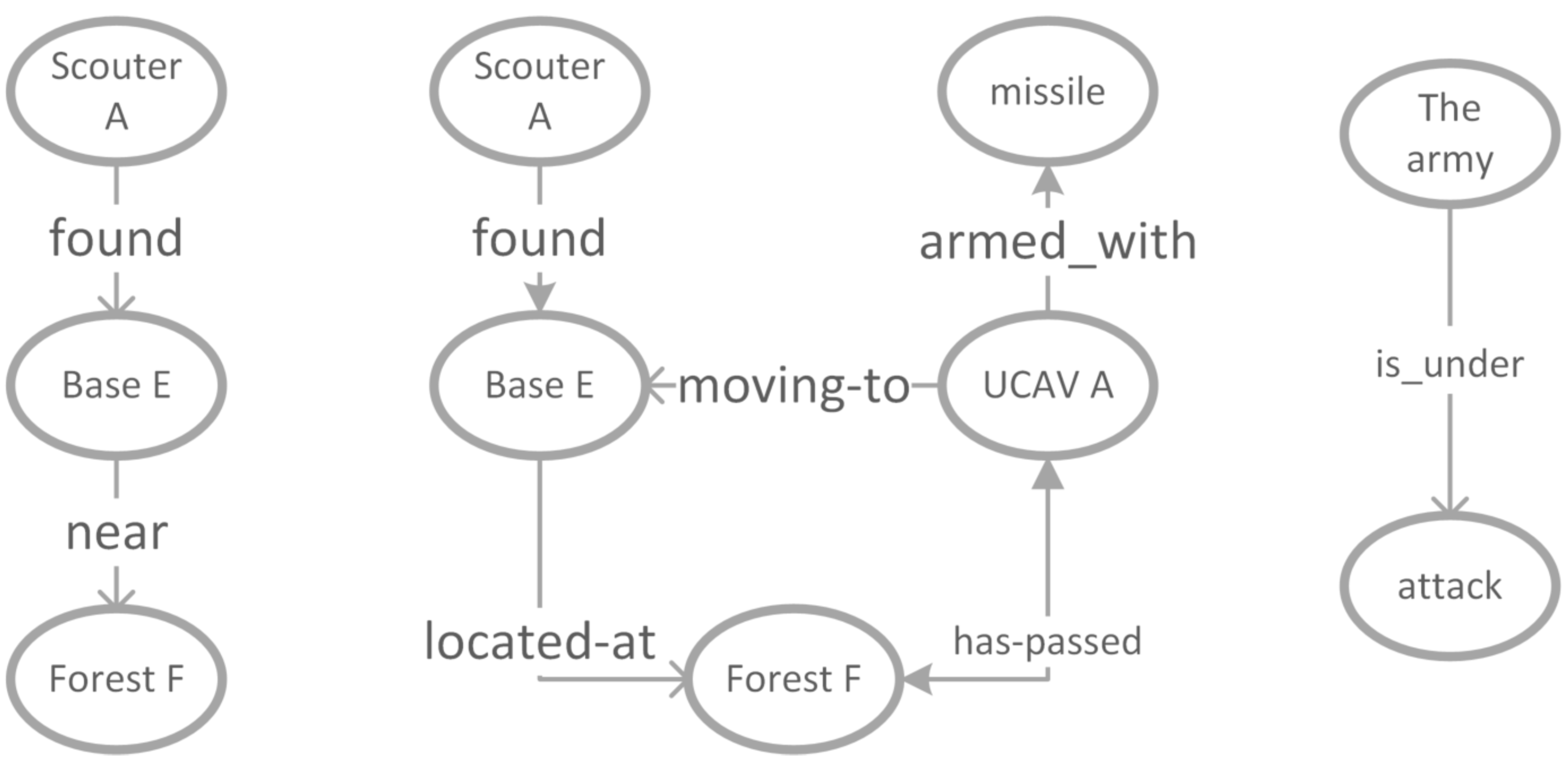
3.1. Ontology Graph Representation
3.2. Information Semantic Relevance Model
3.3. Concepts Relevance Computation Approach
3.4. Dynamic Update of the Knowledge Graph
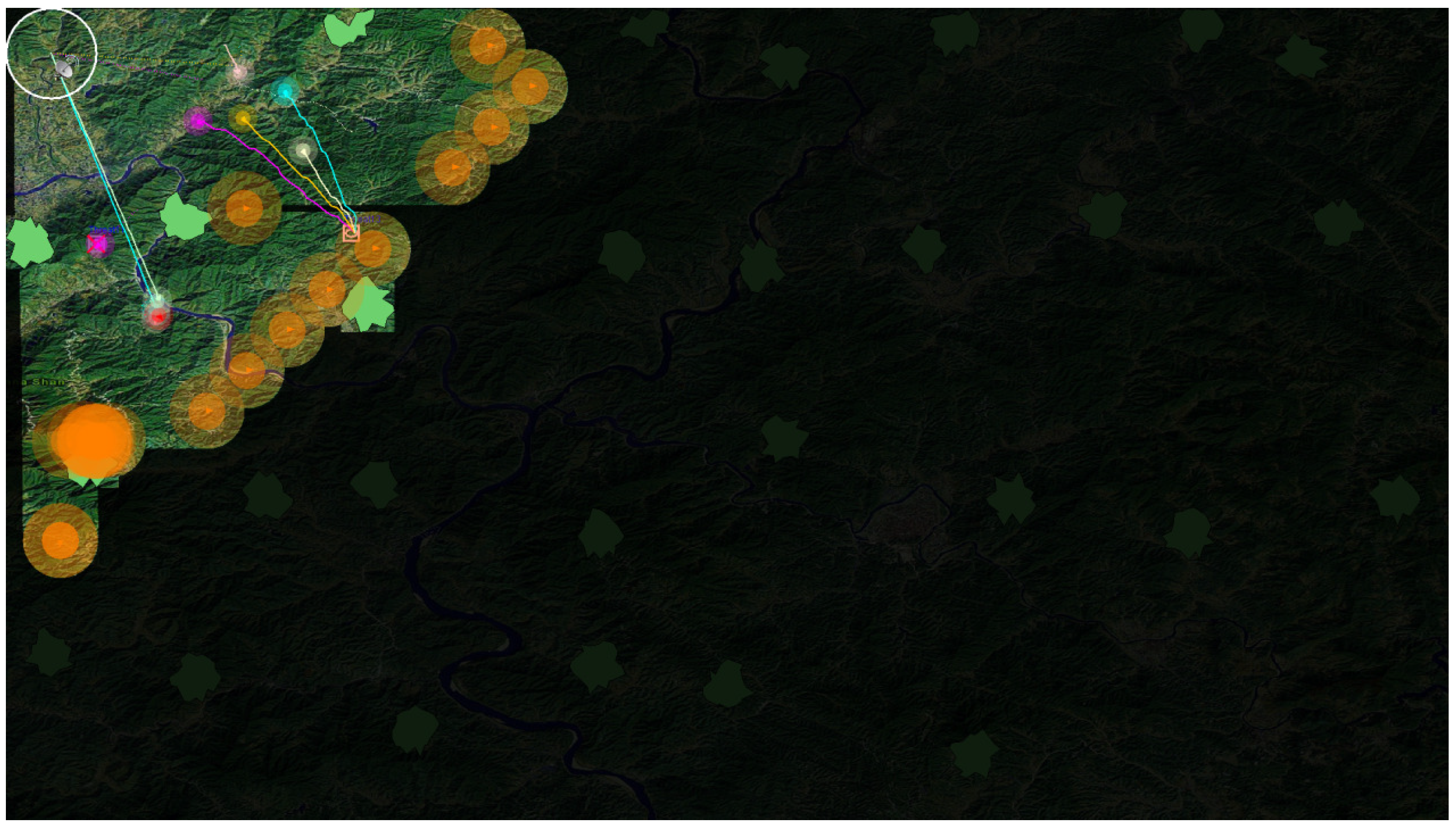
4. Simulation and Results
4.1. Simulation Setup
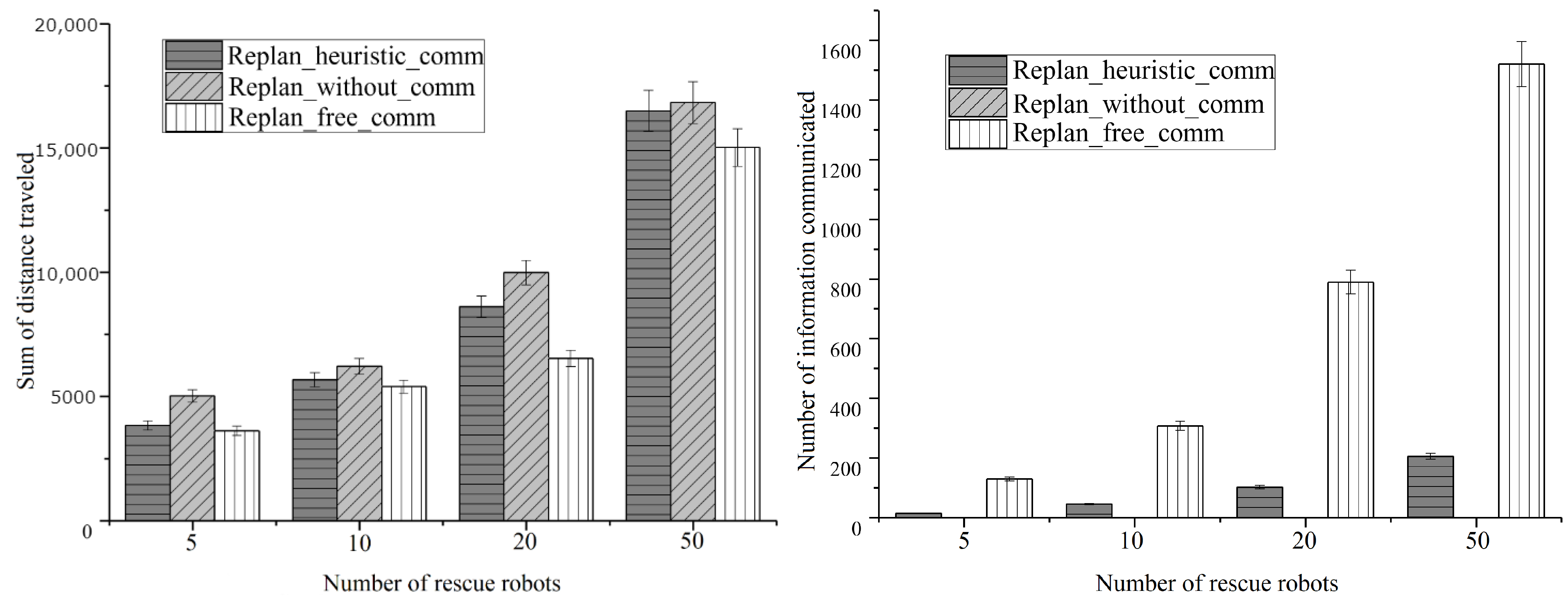
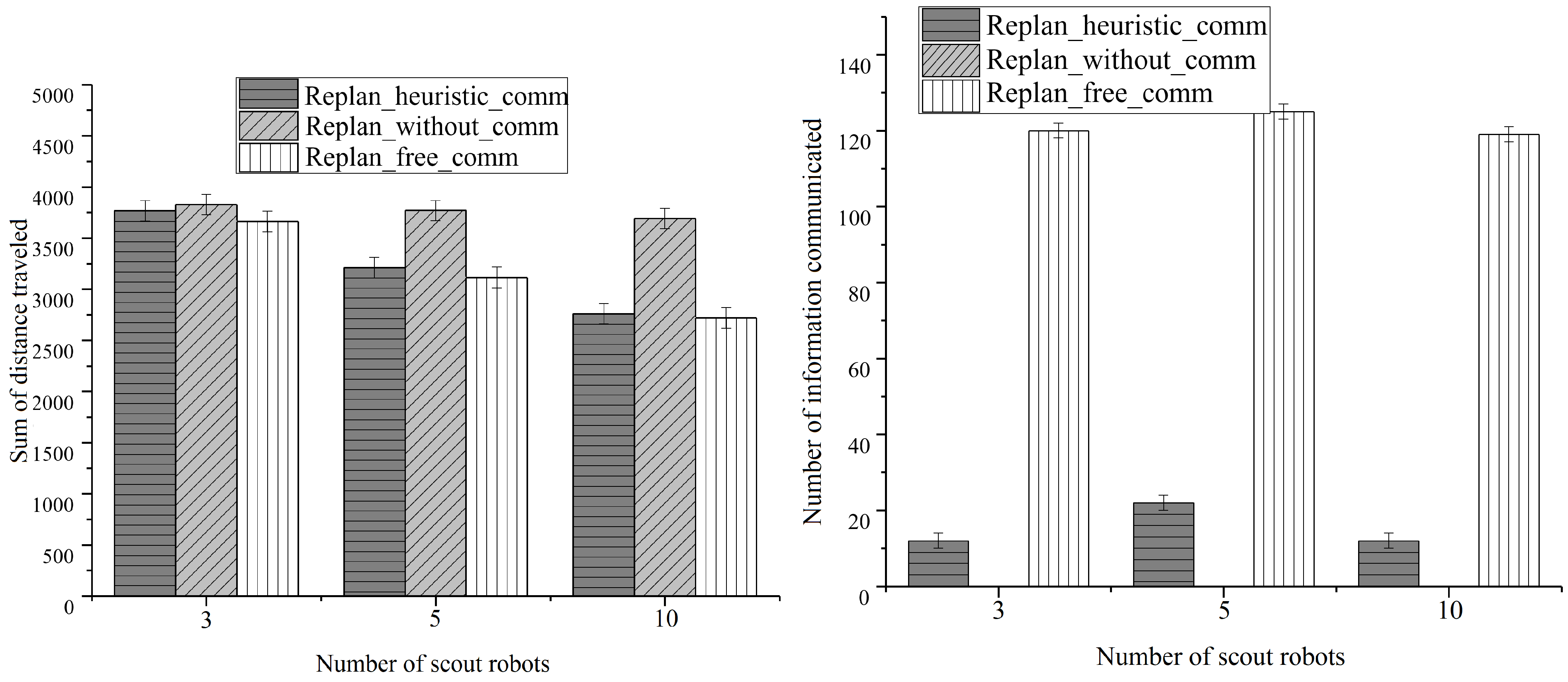
- Replan_heuristic_comm: represents our designed ontological relevance based information sharing algorithm where robots inference semantic information received and pro-actively share the information so that less information is relayed, but robots are rewarded with shorter length of routes being traveled for saving the same number of victims.
- Replan_without_comm: Performing search victims and rescuing them by the robots themselves without sharing any information. It is considered as the baseline of team performance.
- Replan_free_comm: each robot connects with all others, which forms a fully connected network. A robot shares its own information to any of the others freely. As there is no information sharing cost being considered, robots are able to get the full map of information. Although its performance could be understood as the upper limit, the information sharing cost should be huge.
4.2. Simulation Results as Time Varies
4.3. Scalability under Variable Number of Rescue Robots
4.4. Scalability under Variable Exploration Rate
5. Summary and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Di Marzo Serugendo, G.; Gleizes, M.P.; Karageorgos, A. Self-organization in multi-agent systems. Knowl. Eng. Rev. 2005, 20, 165–189. [Google Scholar] [CrossRef] [Green Version]
- Parunak, H.V.D.; Brueckner, S.A. Software engineering for self-organizing systems. Knowl. Eng. Rev. 2015, 30, 419–434. [Google Scholar] [CrossRef] [Green Version]
- Narzisi, G.; Mysore, V.; Mishra, B. Multi-objective evolutionary optimization of agent-based models: An application to emergency response planning. In Proceedings of the 2nd IASTED International Conference on Computational Intelligence, CI 2006, San Francisco, CA, USA, 20–22 November 2006; pp. 224–230. [Google Scholar]
- Castillo, O.; Trujillo, L.; Melin, P. Multiple Objective Genetic Algorithms for Path-planning Optimization in Autonomous Mobile Robots. Soft Comput. 2007, 11, 269–279. [Google Scholar] [CrossRef]
- Aberdeen, D.; Thiébaux, S.; Zhang, L. Decision-Theoretic Military Operations Planning. In Proceedings of the ICAPS, Whistler, BC, Canada, 3–7 June 2004. [Google Scholar]
- Schranz, M.; Umlauft, M.; Sende, M.; Elmenreich, W. Swarm Robotic Behaviors and Current Applications. Front. Robot. AI 2020, 7, 36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Morisawa, T.; Hayashi, K.; Mizuuchi, I. Allocating Multiple Types of Tasks to Heterogeneous Agents Based on the Theory of Comparative Advantage. J. Robot. 2018, 2018. [Google Scholar] [CrossRef] [Green Version]
- Ashby, W.R. Principles of the Self-Organizing Dynamic System. J. Gen. Psychol. 1947, 37, 125–128. [Google Scholar] [CrossRef] [PubMed]
- Kuze, N.; Kominami, D.; Kashima, K.; Hashimoto, T.; Murata, M. Controlling Large-Scale Self-Organized Networks with Lightweight Cost for Fast Adaptation to Changing Environments. ACM Trans. Auton. Adapt. Syst. 2016, 11. [Google Scholar] [CrossRef]
- Kuze, N.; Kominami, D.; Kashima, K.; Hashimoto, T.; Murata, M. Hierarchical Optimal Control Method for Controlling Large-Scale Self-Organizing Networks. ACM Trans. Auton. Adapt. Syst. 2017, 12. [Google Scholar] [CrossRef]
- Gao, C.; Zhen, Z.; Gong, H. A self-organized search and attack algorithm for multiple unmanned aerial vehicles. Aerosp. Sci. Technol. 2016, 54, 229–240. [Google Scholar] [CrossRef]
- Orfanus, D.; Pignaton de Freitas, E.; Eliassen, F. Self-Organization as a Supporting Paradigm for Military UAV Relay Networks. IEEE Commun. Lett. 2016, 20, 804–807. [Google Scholar] [CrossRef]
- Sokhova, Z.B. Model of Self-organizing System of Autonomous Agents. In Advances in Neural Computation, Machine Learning, and Cognitive Research IV; Kryzhanovsky, B., Dunin-Barkowski, W., Redko, V., Tiumentsev, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 93–100. [Google Scholar]
- Rosas, F.; Mediano, P.A.; Ugarte, M.; Jensen, H.J. An Information-Theoretic Approach to Self-Organisation: Emergence of Complex Interdependencies in Coupled Dynamical Systems. Entropy 2018, 20, 793. [Google Scholar] [CrossRef] [Green Version]
- Kuze, N.; Kominami, D.; Kashima, K.; Hashimoto, T.; Murata, M. Self-Organizing Control Mechanism Based on Collective Decision-Making for Information Uncertainty. ACM Trans. Auton. Adapt. Syst. 2018, 13. [Google Scholar] [CrossRef]
- Tamma, V.; Bench-Capon, T. An ontology model to facilitate knowledge-sharing in multi-agent systems. Knowl. Eng. Rev. 2002, 17, 41–60. [Google Scholar] [CrossRef]
- Heylighen, F. Self-organization in Communicating Groups: The Emergence of Coordination, Shared References and Collective Intelligence. In Complexity Perspectives on Language, Communication and Society; Massip-Bonet, À., Bastardas-Boada, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–149. [Google Scholar]
- Xuan, P.; Lesser, V.; Zilberstein, S. Communication Decisions in Multi-agent Cooperation: Model and Experiments. Proc. Int. Conf. Auton. Agents 2001. [Google Scholar] [CrossRef]
- Gmytrasiewicz, P.; Durfee, E.; Wehe, D.K. The Utility of Communication in Coordinating Intelligent Agents. In Proceedings of the AAAI-91, Anaheim, CA, USA, 14–19 July 1991; pp. 166–172. [Google Scholar]
- Bernstein, D.S.; Zilberstein, S.; Immerman, N. The Complexity of Decentralized Control of Markov Decision Processes. arXiv 2013, arXiv:1301.3836. [Google Scholar] [CrossRef]
- Carlin, A.; Zilberstein, S. Myopic and Non-myopic Communication under Partial Observability. In Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, Milan, Italy, 15–18 September 2009; Volume 2, pp. 331–338. [Google Scholar]
- Biswas, S.; Kundu, S.; Das, S. Inducing Niching Behavior in Differential Evolution Through Local Information Sharing. IEEE Trans. Evol. Comput. 2015, 19, 246–263. [Google Scholar] [CrossRef]
- Wanasinghe, T.R.; Mann, G.K.I.; Gosine, R.G. Decentralized Cooperative Localization for Heterogeneous Multi-robot System Using Split Covariance Intersection Filter. In Proceedings of the 2014 Canadian Conference on Computer and Robot Vision, Montreal, QC, Canada, 6–9 May 2014; pp. 167–174. [Google Scholar]
- Charniak, E. Bayesian Networks Without Tears: Making Bayesian Networks More Accessible to the Probabilistically Unsophisticated. AI Mag. 1991, 12, 50–63. [Google Scholar]
- Burgard, W.; Moors, M.; Stachniss, C.; Schneider, F.E. Coordinated multi-robot exploration. IEEE Trans. Robot. 2005, 21, 376–386. [Google Scholar] [CrossRef] [Green Version]
- Amato, C.; Konidaris, G.D.; Kaelbling, L.P. Planning with Macro-actions in Decentralized POMDPs. In Proceedings of the 2014 International Conference on Autonomous Agents and Multi-agent Systems, AAMAS ’14, Paris, France, 5–9 May 2014; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2014; pp. 1273–1280. [Google Scholar]
- Kauffman, S.A. Origins of Order in Evolution: Self-Organization and Selection. In Understanding Origins: Contemporary Views on the Origin of Life, Mind and Society; Varela, F.J., Dupuy, J.P., Eds.; Springer: Dordrecht, The Netherlands, 1992; pp. 153–181. [Google Scholar]
- Xu, Y.; Lewis, M.; Sycara, K.; Scerri, P. An efficient information sharing approach for large scale multi-agent team. In Proceedings of the 2008 11th International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–8. [Google Scholar]
- Zambak, A.F. The Frame Problem. In Philosophy and Theory of Artificial Intelligence; Müller, V.C., Ed.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 307–319. [Google Scholar]
- Shanahan, M. Solving the Frame Problem: A Mathematical Investigation of the Common Sense Law of Inertia; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Alkahtani, N.H.; Almohsen, S.; Alkahtani, N.M.; abdullah almalki, G.; Meshref, S.S.; Kurdi, H. A Semantic Multi-Agent system to Exchange Information between Hospitals. Procedia Comput. Sci. 2017, 109, 704–709. [Google Scholar] [CrossRef]
- Mitra, P.; Wiederhold, G.; Kersten, M. A graph-oriented model for articulation of ontology interdependencies. In Proceedings of the International Conference on Extending Database Technology, Konstanz, Germany, 27–31 March 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 86–100. [Google Scholar]
- Wu, Z.; Palmer, M. Verb Semantics and Lexical Selection. arXiv 1994, arXiv:cmp-lg/9406033. [Google Scholar]
- Tsiogkas, N.; Papadimitriou, G.; Saigol, Z.; Lane, D. Efficient multi-AUV cooperation using semantic knowledge representation for underwater archaeology missions. In Proceedings of the 2014 Oceans, St. John’s, NL, Canada, 14–19 September 2014; pp. 1–6. [Google Scholar]
- Bevacqua, G.; Cacace, J.; Finzi, A.; Lippiello, V. Mixed-Initiative Planning and Execution for Multiple Drones in Search and Rescue Missions. In Proceedings of the International Conference on Automated Planning and Scheduling, ICAPS, Jerusalem, Israel, 7–11 June 2015. [Google Scholar]
- Ravankar, A.; Ravankar, A.A.; Kobayashi, Y.; Emaru, T. Symbiotic Navigation in Multi-Robot Systems with Remote Obstacle Knowledge Sharing. Sensors 2017, 17, 1581. [Google Scholar] [CrossRef] [Green Version]
- Developers, E. “Eclipse RDF4J | The Eclipse Foundation”, Eclipse RDF4J. 2021. Available online: https://rdf4j.org/ (accessed on 9 March 2021).
- Michail, D.; Kinable, J.; Naveh, B.; Sichi, J.V. JGraphT—A Java Library for Graph Data Structures and Algorithms. ACM Trans. Math. Softw. 2020, 46, 1–29. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Ran, W.; Nantogma, S.; Xu, Y. Adaptive Information Sharing with Ontological Relevance Computation for Decentralized Self-Organization Systems. Entropy 2021, 23, 342. https://doi.org/10.3390/e23030342
Liu W, Ran W, Nantogma S, Xu Y. Adaptive Information Sharing with Ontological Relevance Computation for Decentralized Self-Organization Systems. Entropy. 2021; 23(3):342. https://doi.org/10.3390/e23030342
Chicago/Turabian StyleLiu, Wei, Weizhi Ran, Sulemana Nantogma, and Yang Xu. 2021. "Adaptive Information Sharing with Ontological Relevance Computation for Decentralized Self-Organization Systems" Entropy 23, no. 3: 342. https://doi.org/10.3390/e23030342
APA StyleLiu, W., Ran, W., Nantogma, S., & Xu, Y. (2021). Adaptive Information Sharing with Ontological Relevance Computation for Decentralized Self-Organization Systems. Entropy, 23(3), 342. https://doi.org/10.3390/e23030342