
DRL-Assisted Resource Allocation for NOMA-MEC Offloading with Hybrid SIC


Abstract
:1. Introduction
1.1. Related Works
1.2. Motivation and Contributions
- A hybrid NOMA-MEC network was proposed, in which an MEC server is deployed at the base station to serve multiple users. All users are divided into pairs, and each pair is assigned into one sub-channel. The users in each group adopt NOMA transmission with the hybrid SIC scheme in the first time duration, and the user with a longer deadline transmits the remaining data by OMA in the following time duration. We proposed a DRL-assisted user grouping framework with joint power allocation, time scheduling, and task partition assignment to minimize the offloading energy consumption under transmission latency and offloading data amount constraints.
- By assuming that the user grouping policy is given, the energy minimization problem for each group is non-convex due to the multiplications of variables and a 0–1 indicator function, which indicates two cases of decoding orders. The solution to the original problem can be obtained by solving each case separately. A multilevel programming method was proposed, where the energy minimization problem was decomposed into three sub-problems including power allocation, time scheduling, and task partition assignment. By carefully analyzing the convexity and monotonicity of each sub-problem, the solutions to all three sub-problems were obtained optimally in closed-form. The solution to the energy minimization problem for each case can be determined optimally by adaptingthe decisions successively from the lower level to the higher level (i.e., from the optimal task partition assignment to the optimal power allocation). Therefore, the solution to the original problem can be obtained by comparing the numerical results of those two cases and selecting the optimal solution with lower energy consumption.
- A DRL framework for user grouping was designed based on a deep Q-learning algorithm. We provided a training algorithm for the NN to learn the experiences based on the channel condition and delay tolerance of each user during a period of slotted time, and the user grouping policy can be learned gradually at the base station by maximizing the negative of the total offloading energy consumption.
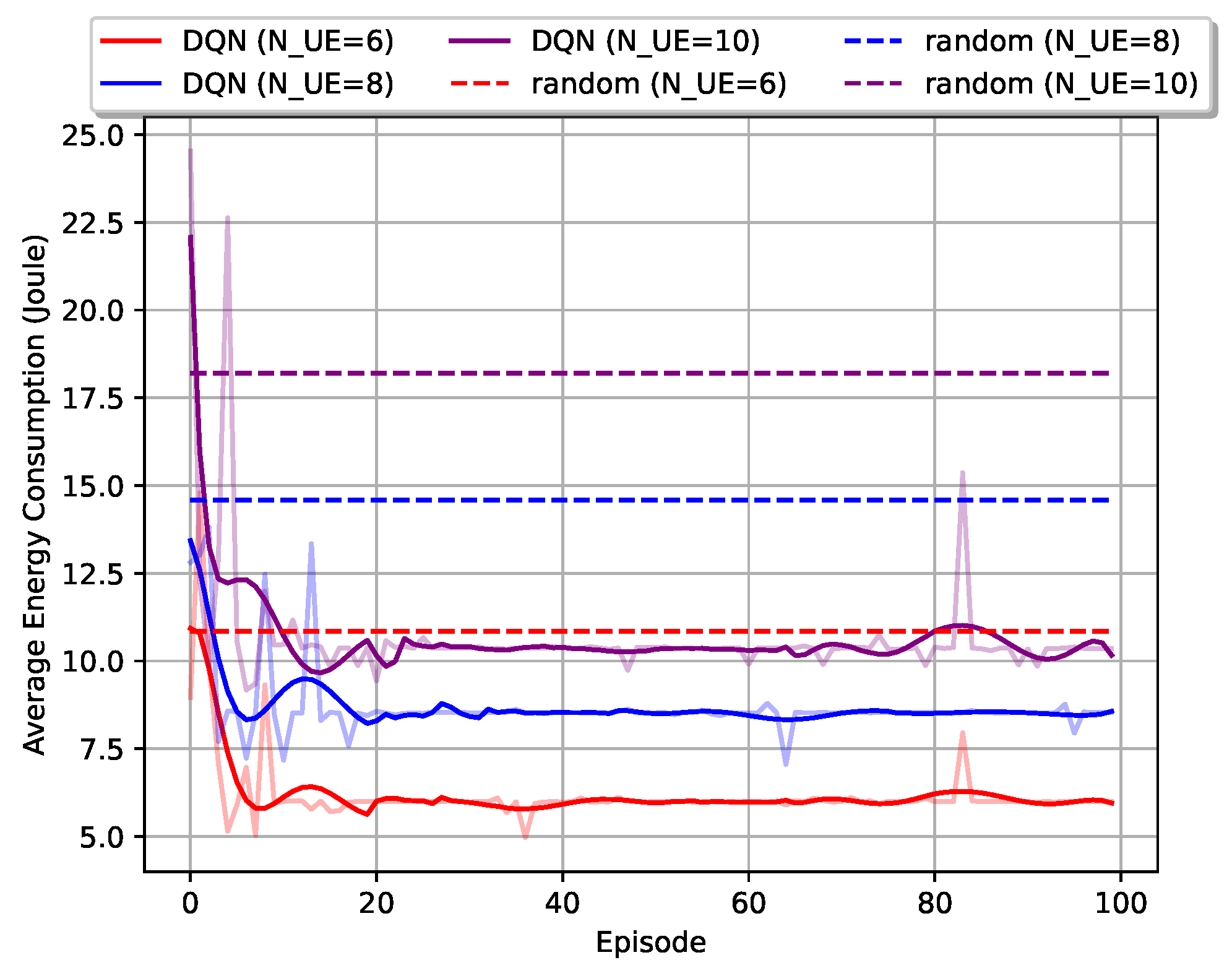
- Simulation results are provided to illustrate the convergence speed and the performance of this user grouping policy by comparing with random user grouping policy. Moreover, compared with the OMA-MEC scheme, our proposed NOME-MEC scheme can achieve superior performance with much lower energy consumption.
1.3. Organizations
2. System Model and Problem Formulation
2.1. System Model
2.2. Problem Formulation
3. Energy Minimization for NOMA-MEC with the Hybrid SIC Scheme
3.1. Power Allocation
- 1.
- For , is decoded first, and the power allocation for this decoding order is presented in the following three offloading scenarios:
- (a)
- When and , offloads in both time durations, which is termed hybrid NOMA. Given the following two feasible ranges, the optimal power allocation can be expressed as follows:
- i.
- If ,
- ii.
- If ,
- (b)
- When only offloads during the first time duration , this scheme is termed pure NOMA, and the power allocation is obtained as:,
- (c)
- When , chooses to offload solely during the section time duration , and the optimal power allocation is:,
- 2.
- For , is decoded first, and similarly, the power allocation for this decoding order is given in three scenarios:
- (a)
- When and , , the hybrid NOMA power allocation is given by:if ,
- (b)
- When , the pure NOMA case can be obtained as:
- (c)
- When , the OMA case is the same as (26).
3.2. Time Scheduling
3.3. Offloading Task Partition Assignment
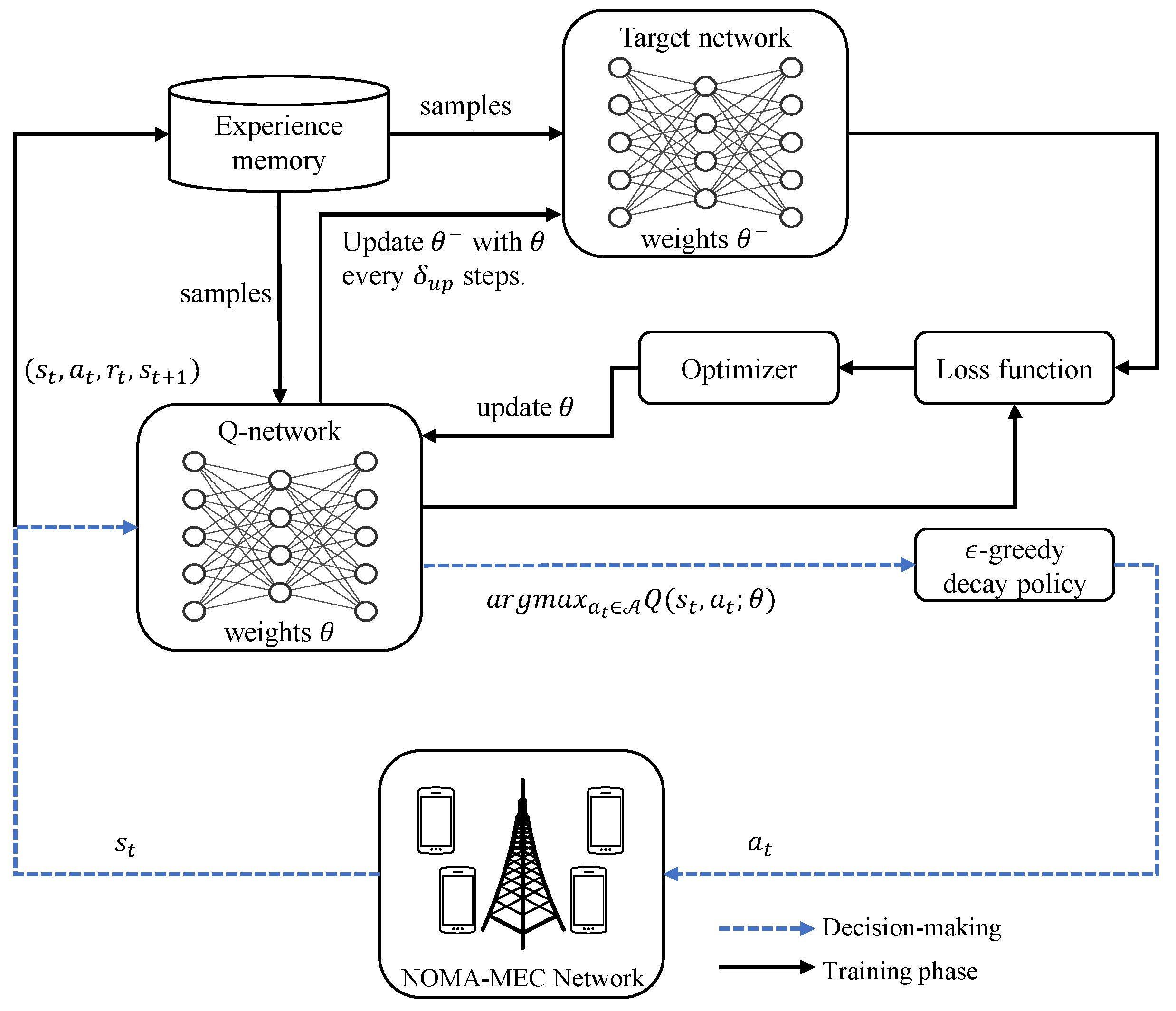
4. Deep Reinforcement Learning Framework for User Grouping
4.1. The DRL Framework
- (1)
- State space: The state is characterized by the current channel gains and offloading deadlines of all users since the user grouping is mainly determined by those two factors. Therefore, the state can be expressed as:
- (2)
- Action space: At each time slot t, the agent takes an action , which contains all the possible user grouping decisions . The action is defined as:where indicates that is assigned to group . In our proposed scheme, two different users can only be assigned to each group.
- (3)
- Rewards: The immediate reward is described by the sum of the energy consumption of each group after choosing the action under state . The numerical result of the energy consumption in each group can be obtained by solving the problem . Therefore, the reward is defined as:
4.2. DQN-Based NOMA User Grouping Algorithm
| Algorithm 1 DQN-based user-grouping algorithm. |
|
5. Simulation Results
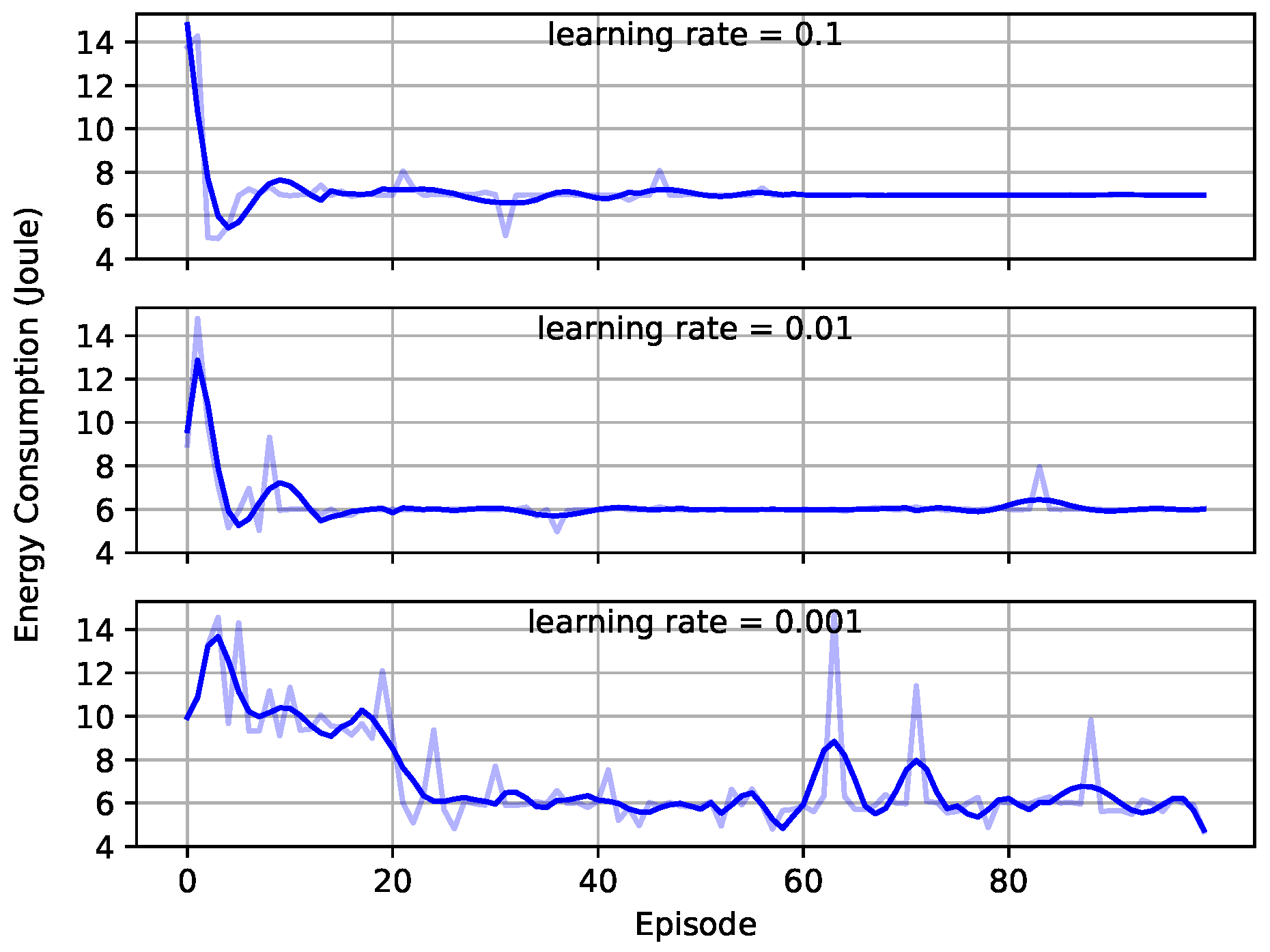
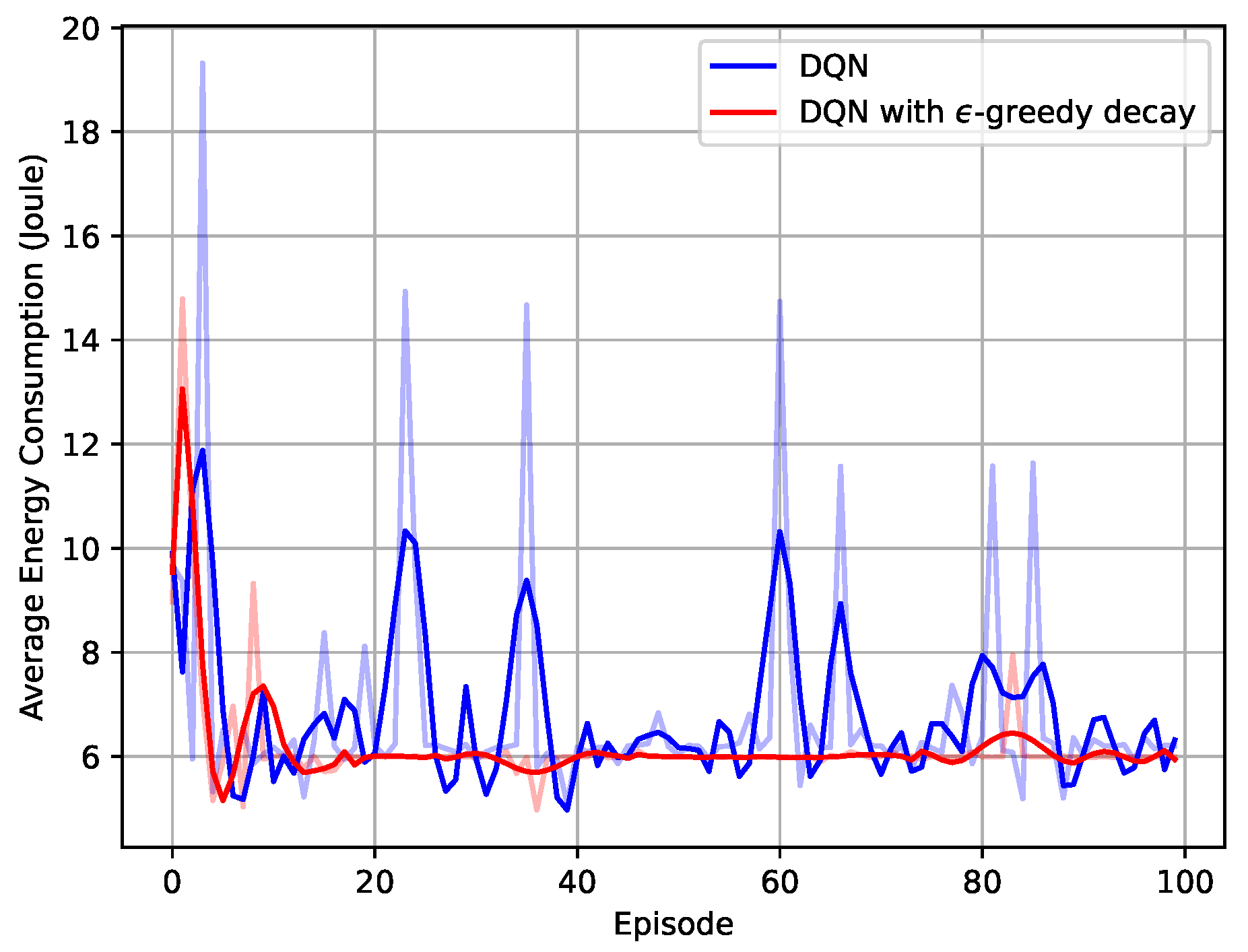
5.1. Convergence of the Framework
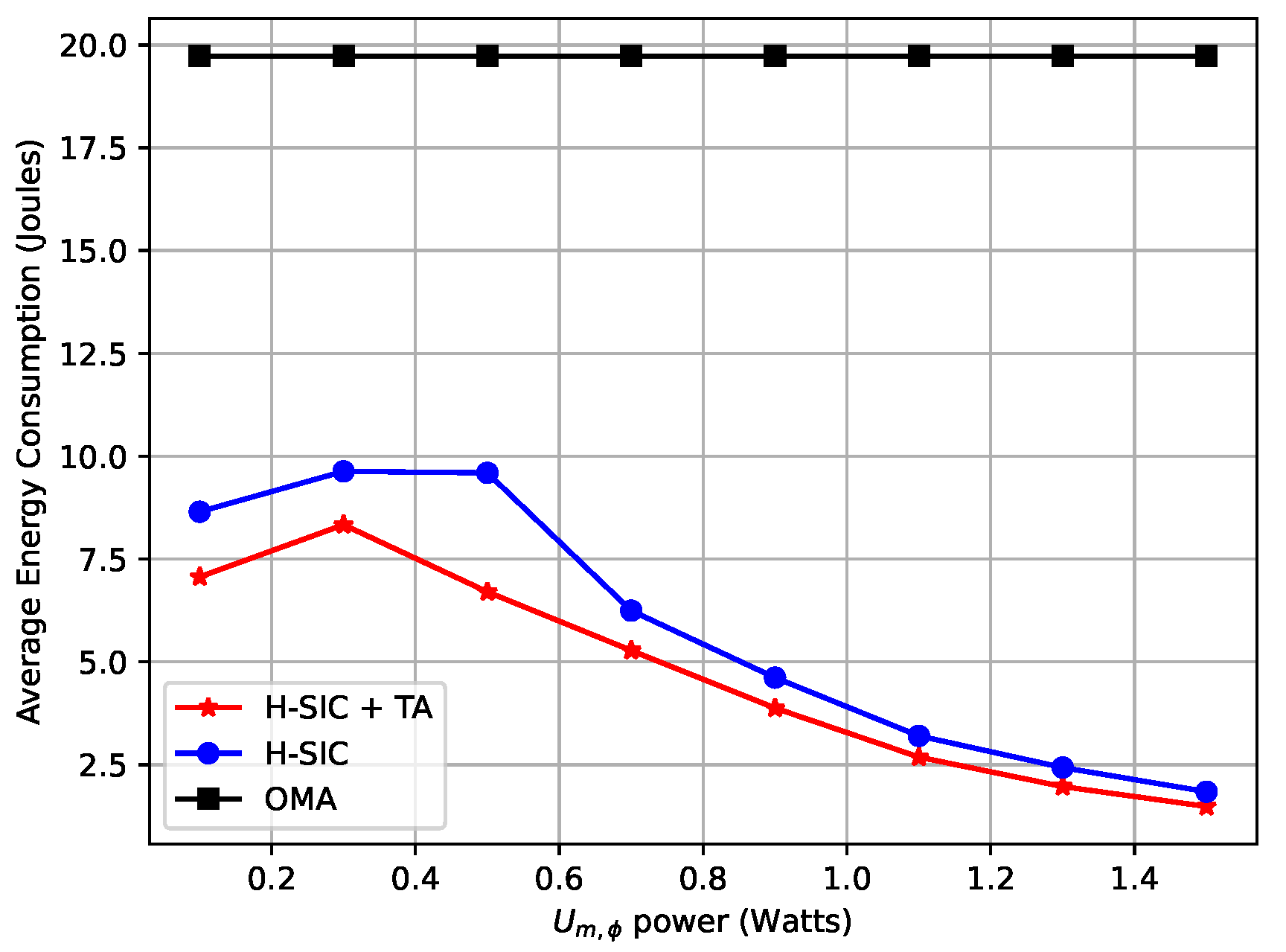
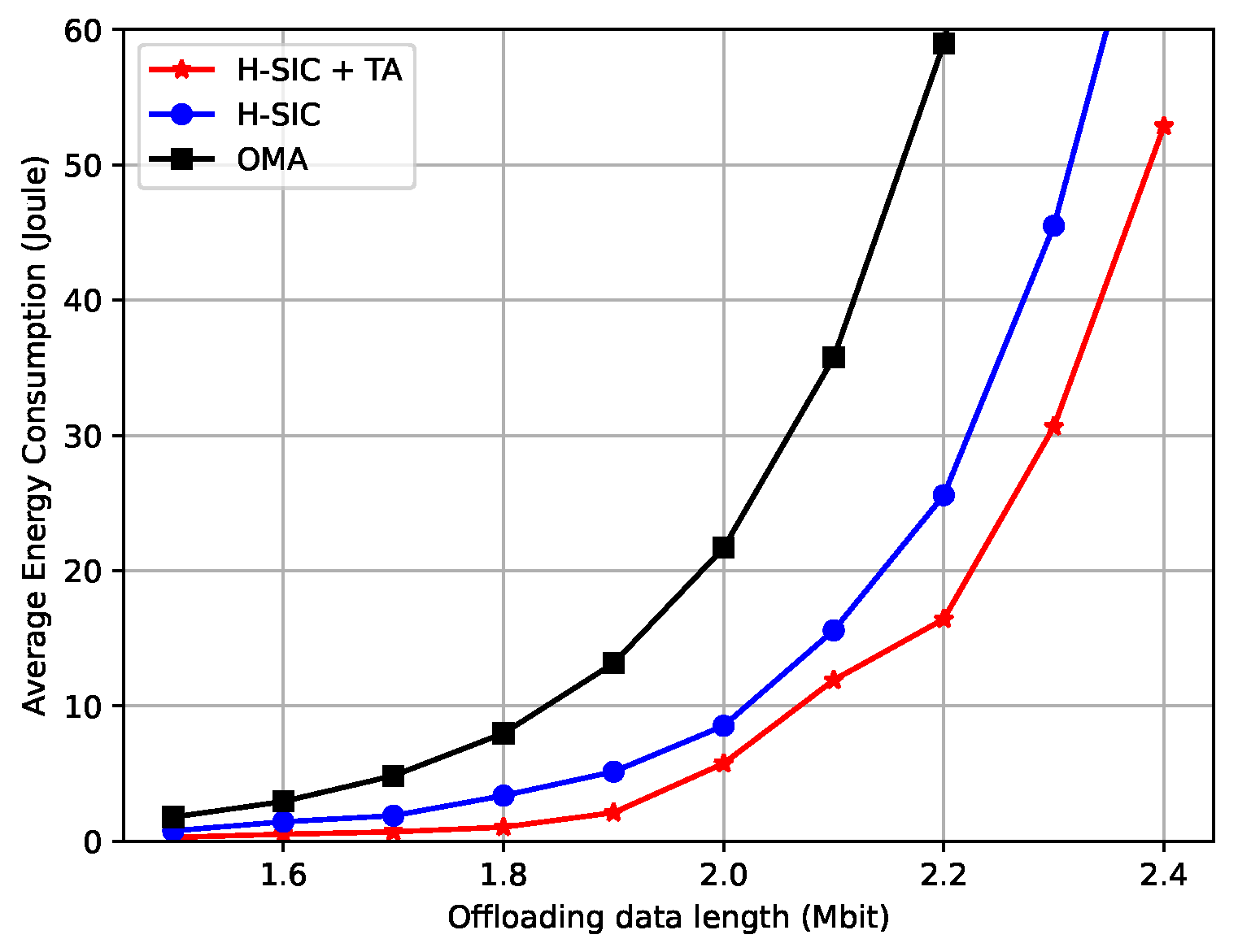
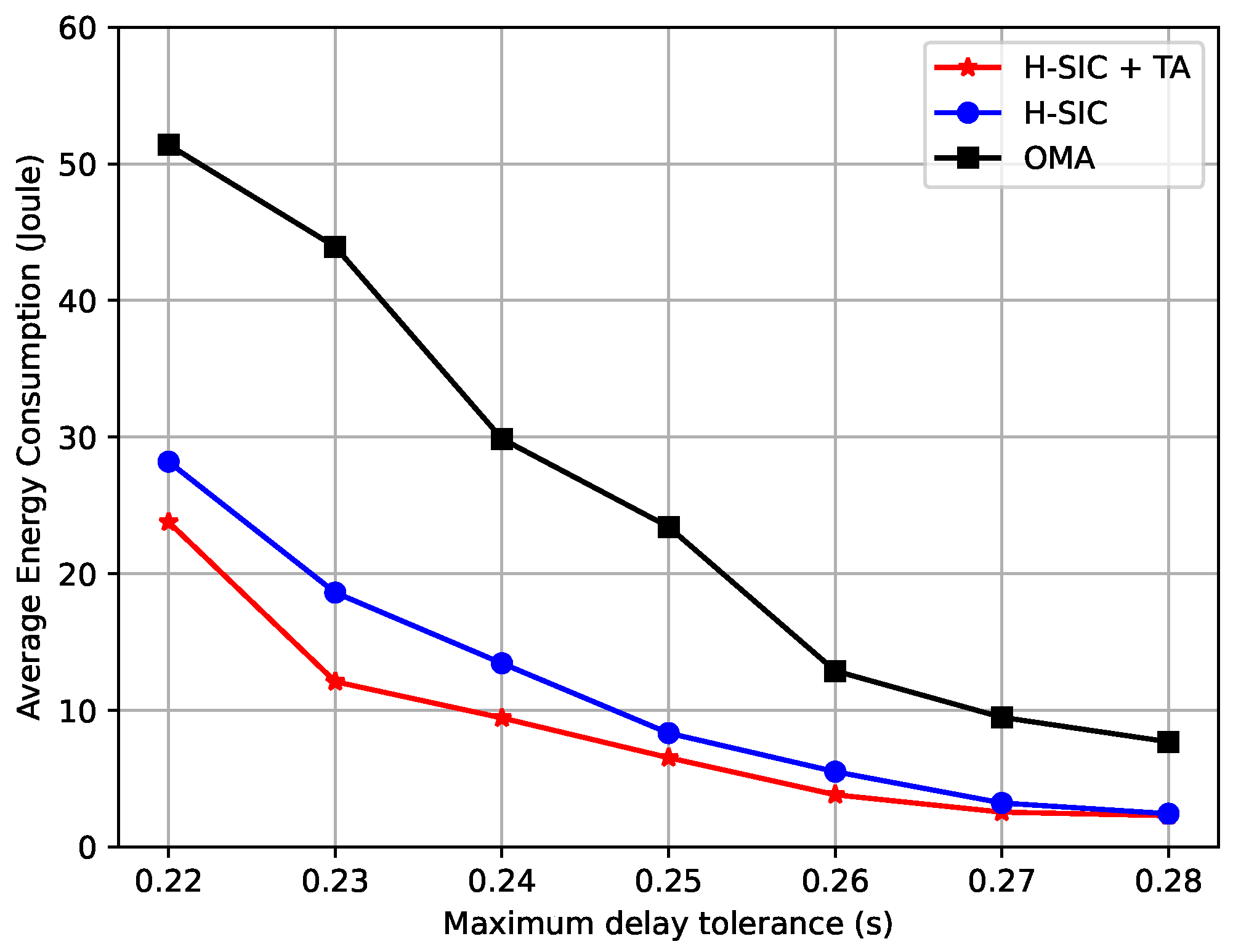
5.2. Average Performance of the Proposed Scheme
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Theorem 1
- Hybrid NOMA: , , and .
- -
- If :
- -
- If :where .
- Pure NOMA: , :where .
- OMA: , :
Appendix B. Proof of Proposition 1
Appendix C. Proof to Proposition 2
- For the case in (22), the stationary condition is obtained as:Therefore, the KKT conditions can be written as follows:For , , and (A38) can be rewritten as:Define , , and . The optimal task assignment coefficient can be derived as:The optimal task assignment ratio can be expressed as:
- For the case in (23):The stationary condition can be expressed as:where .For , , constraint (A48) can be rearranged as:Define , . The above equation can be rewritten as:Hence, the optimal task partition assignment ratio is:
References
- Nduwayezu, M.; Pham, Q.; Hwang, W. Online Computation Offloading in NOMA-Based Multi-Access Edge Computing: A Deep Reinforcement Learning Approach. IEEE Access 2020, 8, 99098–99109. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, H.; Wang, R.; Zhang, Y. Reducing Offloading Latency for Digital Twin Edge Networks in 6G. IEEE Trans. Veh. Technol. 2020, 69, 12240–12251. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, X.; Xia, J.; Fan, L. Deep reinforcement learning based mobile edge computing for intelligent Internet of Things. Phys. Commun. 2020, 43, 101184. [Google Scholar] [CrossRef]
- Li, L.; Cheng, Q.; Tang, X.; Bai, T.; Chen, W.; Ding, Z.; Han, Z. Resource Allocation for NOMA-MEC Systems in Ultra-Dense Networks: A Learning Aided Mean-Field Game Approach. IEEE Trans. Wirel. Commun. 2021, 20, 1487–1500. [Google Scholar] [CrossRef]
- Bai, T.; Pan, C.; Deng, Y.; Elkashlan, M.; Nallanathan, A.; Hanzo, L. Latency Minimization for Intelligent Reflecting Surface Aided Mobile Edge Computing. IEEE J. Sel. Areas Commun. 2020, 38, 2666–2682. [Google Scholar] [CrossRef]
- Dinh, H.T.; Lee, C.; Niyato, D.; Wang, P. A survey of mobile cloud computing: Architecture, applications, and approaches. Wirel. Commun. Mob. Comput. 2013, 13, 1587–1611. [Google Scholar] [CrossRef]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile Edge Computing: A Survey. IEEE Internet Things J. 2018, 5, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Liu, Y.; Chen, F. NOMA-Aided Mobile Edge Computing via User Cooperation. IEEE Trans. Commun. 2020, 68, 2221–2235. [Google Scholar] [CrossRef] [Green Version]
- Chen, A.; Yang, Z.; Lyu, B.; Xu, B. System Delay Minimization for NOMA-Based Cognitive Mobile Edge Computing. IEEE Access 2020, 8, 62228–62237. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Dao, N.N.; Pham, Q.V.; Tu, N.H.; Thanh, T.T.; Bao, V.N.Q.; Lakew, D.S.; Cho, S. Survey on Aerial Radio Access Networks: Toward a Comprehensive 6G Access Infrastructure. IEEE Commun. Surv. Tutor. 2021. [Google Scholar] [CrossRef]
- Makki, B.; Chitti, K.; Behravan, A.; Alouini, M.S. A Survey of NOMA: Current Status and Open Research Challenges. IEEE Open J. Commun. Soc. 2020, 1, 179–189. [Google Scholar] [CrossRef] [Green Version]
- Vaezi, M.; Aruma Baduge, G.A.; Liu, Y.; Arafa, A.; Fang, F.; Ding, Z. Interplay Between NOMA and Other Emerging Technologies: A Survey. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 900–919. [Google Scholar] [CrossRef] [Green Version]
- Fang, F.; Xu, Y.; Ding, Z.; Shen, C.; Peng, M.; Karagiannidis, G.K. Optimal Resource Allocation for Delay Minimization in NOMA-MEC Networks. IEEE Trans. Commun. 2020, 68, 7867–7881. [Google Scholar] [CrossRef]
- Zeng, M.; Nguyen, N.; Dobre, O.A.; Poor, H.V. Delay Minimization for NOMA-Assisted MEC Under Power and Energy Constraints. IEEE Wirel. Commun. Lett. 2019, 8, 1657–1661. [Google Scholar] [CrossRef]
- Song, Z.; Liu, Y.; Sun, X. Joint Radio and Computational Resource Allocation for NOMA-Based Mobile Edge Computing in Heterogeneous Networks. IEEE Commun. Lett. 2018, 22, 2559–2562. [Google Scholar] [CrossRef]
- Xu, C.; Zheng, G.; Zhao, X. Energy-Minimization Task Offloading and Resource Allocation for Mobile Edge Computing in NOMA Heterogeneous Networks. IEEE Trans. Veh. Technol. 2020, 69, 16001–16016. [Google Scholar] [CrossRef]
- Wang, F.; Xu, J.; Ding, Z. Multi-Antenna NOMA for Computation Offloading in Multiuser Mobile Edge Computing Systems. IEEE Trans. Commun. 2019, 67, 2450–2463. [Google Scholar] [CrossRef] [Green Version]
- Ding, Z.; Xu, J.; Dobre, O.A.; Poor, H.V. Joint Power and Time Allocation for NOMA–MEC Offloading. IEEE Trans. Veh. Technol. 2019, 68, 6207–6211. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Wang, J.; Huang, Y.; Fang, F.; Navaie, K.; Ding, Z. Resource Allocation for Hybrid NOMA MEC Offloading. IEEE Trans. Wirel. Commun. 2020, 19, 4964–4977. [Google Scholar] [CrossRef]
- Li, H.; Fang, F.; Ding, Z. Joint resource allocation for hybrid NOMA-assisted MEC in 6G networks. Digit. Commun. Netw. 2020, 6, 241–252. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Y.; Shen, R.; Xu, Y.; Zheng, F.C. DRL-Based Energy-Efficient Resource Allocation Frameworks for Uplink NOMA Systems. IEEE Internet Things J. 2020, 7, 7279–7294. [Google Scholar] [CrossRef]
- He, C.; Hu, Y.; Chen, Y.; Zeng, B. Joint Power Allocation and Channel Assignment for NOMA with Deep Reinforcement Learning. IEEE J. Sel. Areas Commun. 2019, 37, 2200–2210. [Google Scholar] [CrossRef]
- Ding, Z.; Yang, Z.; Fan, P.; Poor, H.V. On the Performance of Non-Orthogonal Multiple Access in 5G Systems with Randomly Deployed Users. IEEE Signal Process. Lett. 2014, 21, 1501–1505. [Google Scholar] [CrossRef] [Green Version]
- Ding, Z.; Fan, P.; Poor, H.V. Impact of User Pairing on 5G Nonorthogonal Multiple-Access Downlink Transmissions. IEEE Trans. Veh. Technol. 2016, 65, 6010–6023. [Google Scholar] [CrossRef]
- Zeng, M.; Hao, W.; Dobre, O.A.; Ding, Z.; Poor, H.V. Power Minimization for Multi-Cell Uplink NOMA With Imperfect SIC. IEEE Wirel. Commun. Lett. 2020, 9, 2030–2034. [Google Scholar] [CrossRef]
- Ding, Z.; Schober, R.; Poor, H.V. Unveiling the Importance of SIC in NOMA Systems—Part 1: State of the Art and Recent Findings. IEEE Commun. Lett. 2020, 24, 2373–2377. [Google Scholar] [CrossRef]
- Ding, Z.; Schober, R.; Poor, H.V. Unveiling the Importance of SIC in NOMA Systems—Part II: New Results and Future Directions. IEEE Commun. Lett. 2020, 24, 2378–2382. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.A.; Fidjeland, A.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]









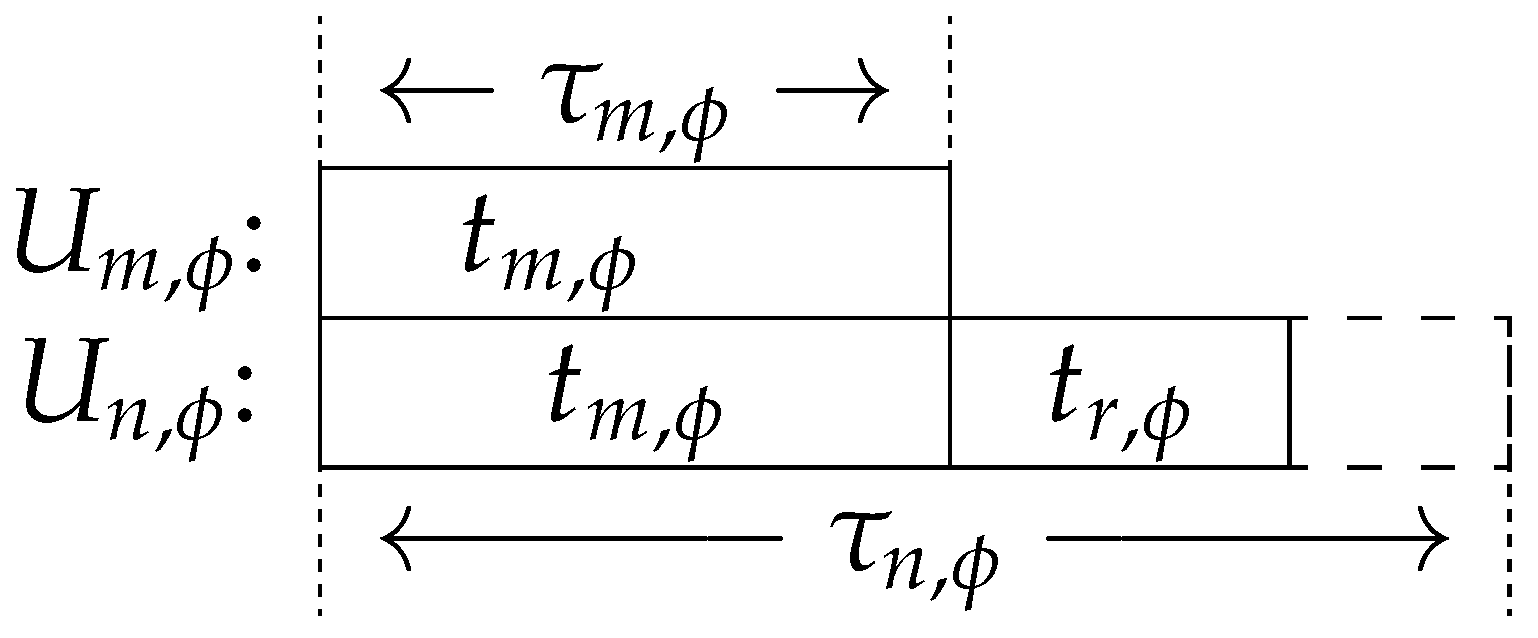{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Effective capacitance coefficient | |
| Number of CPU cycles required per bit | |
| Transmission bandwidth B | 2 MHz |
| Path loss exponent | |
| Noise spectral density | dBm/Hz |
| Maximum cell radius | 1000 m |
| Minimum distance to the base station | 50 m |
| -greedy coefficient | 0.5–0.01 |
| -greedy decay steps | 2000 |
| Discount factor | |
| Reply memory size | 20,000 |
| Batch size | 64 |
| Target network update interval | 10 |
| Number of episode | 100 |
| Number of time steps | 500 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Fang, F.; Ding, Z. DRL-Assisted Resource Allocation for NOMA-MEC Offloading with Hybrid SIC. Entropy 2021, 23, 613. https://doi.org/10.3390/e23050613
Li H, Fang F, Ding Z. DRL-Assisted Resource Allocation for NOMA-MEC Offloading with Hybrid SIC. Entropy. 2021; 23(5):613. https://doi.org/10.3390/e23050613
Chicago/Turabian StyleLi, Haodong, Fang Fang, and Zhiguo Ding. 2021. "DRL-Assisted Resource Allocation for NOMA-MEC Offloading with Hybrid SIC" Entropy 23, no. 5: 613. https://doi.org/10.3390/e23050613
APA StyleLi, H., Fang, F., & Ding, Z. (2021). DRL-Assisted Resource Allocation for NOMA-MEC Offloading with Hybrid SIC. Entropy, 23(5), 613. https://doi.org/10.3390/e23050613