
A Compression-Based Method for Detecting Anomalies in Textual Data


Abstract
:1. Introduction
2. Anomaly Detection in Cybersecurity
2.1. HTTP Anomaly Detection
2.2. Spam Detection
2.3. DGA Detection
2.4. Sentiment Analysis
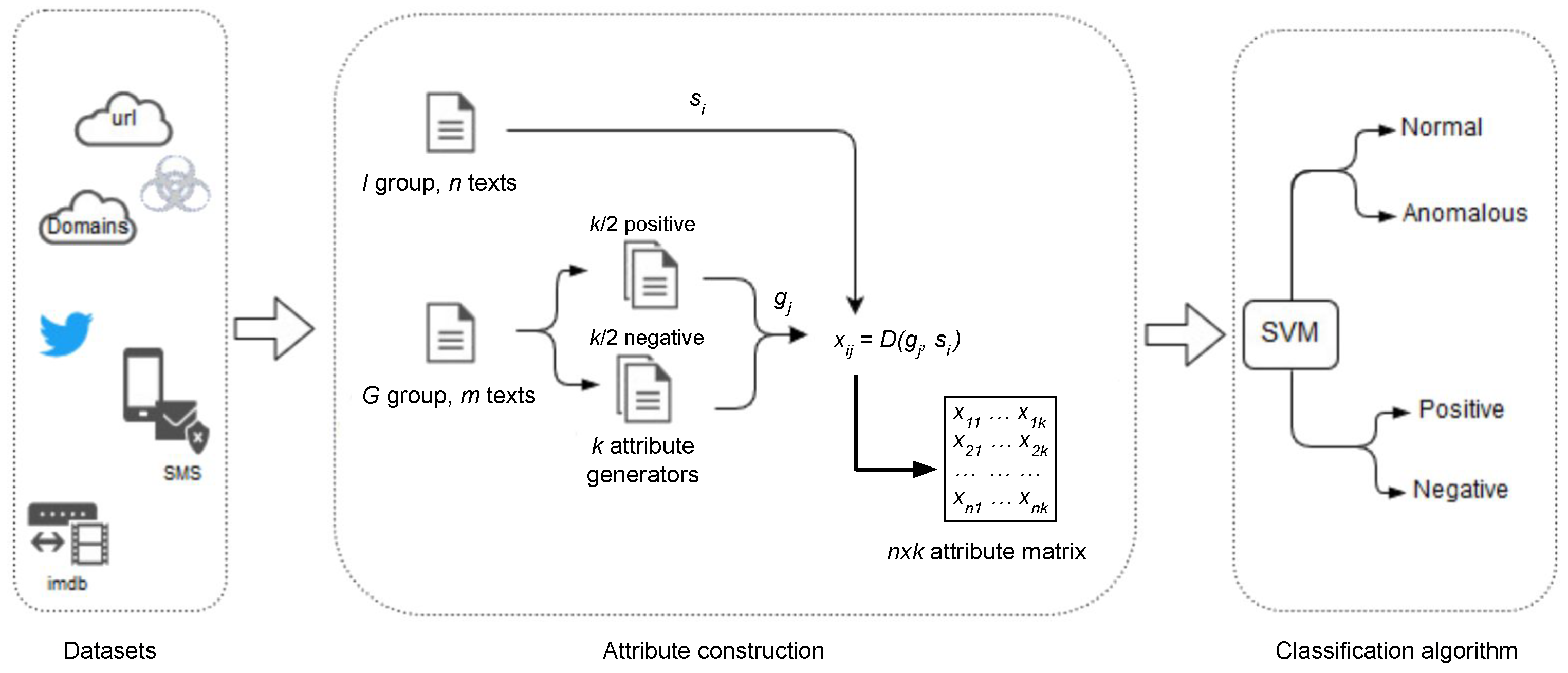
3. Materials and Methods
4. Results
4.1. Experiment 1—Malicious URL
4.1.1. Data Preparation
4.1.2. Results
4.2. Experiment 2—Spam
4.2.1. Data Preparation
4.2.2. Results
4.3. Experiment 3—DGAs
4.3.1. Data Preparation
4.3.2. Results
4.4. Experiment 4—Sentiment Analysis in Twitter
4.4.1. Data Preparation
4.4.2. Results
4.5. Experiment 5—Sentiment Analysis in Movie Reviews
4.5.1. Data Preparation
4.5.2. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ICT | Information and Communication Technologies |
| APT | Advanced Persistent Threats |
| DGA | Domain Generation Algorithm |
| OSINT | Open Source Intelligence |
| IDS | Intrusion Detection System |
| NCD | Normalized Compression Distance |
| SVM | Support Vector Machine |
| HTTP | Hypertext Transfer Protocol |
| URL | Uniform Resource Locator |
| TF | Term Frequency |
| TFIDF | Term Frequency Inverse Document Frequency |
| C&C | Command and Control |
| DNS | Domain Name System |
| PMI | Point-wise Mutual Information |
| AG | Attribute Generator |
| RBF | Radial Basis Function |
| ACC | Accuracy |
| AUC | Area Under Curve |
| SMS | Short Message Service |
| NLP | Natural Language Processing |
| IMDb | Internet Movie Database |
References
- OECD. The Economic Impact of ICT. 2004. Available online: https://www.oecd-ilibrary.org/content/publication/9789264026780-en (accessed on 13 May 2021).
- Sfakianakis, A.; Douligeris, C.; Marinos, L.; Lourenço, M.; Raghimi, O. ENISA Threat Landscape Report 2018; Technical Report ENISA; ENISA: Athens, Greece, 2019.
- Pastor-Galindo, J.; Nespoli, P.; Mármol, F.G.; Pérez, G.M. The not yet exploited goldmine of OSINT: Opportunities, open challenges and future trends. IEEE Access 2020, 8, 10282–10304. [Google Scholar]
- Chuvakin, A.; Schmidt, K.; Phillips, C. Logging and Log Management; Syngress: Boston, MA, USA, 2013; Available online: http://www.sciencedirect.com/science/article/pii/B9781597496353000257 (accessed on 13 May 2021).
- Sabottke, C.; Suciu, O.; Dumitras, T. Vulnerability disclosure in the age of social media: Exploiting twitter for predicting real-world exploits. In Proceedings of the 24th USENIX Security Symposium (USENIX Security 15), Washington, DC, USA, 12–14 August 2015; pp. 1041–1056. [Google Scholar]
- Curry, S.; Kirda, E.; Schwartz, E.; Stewart, W.; Yoran, A. Big data fuels intelligence-driven security. RSA Secur. Brief 2013. Available online: http://www.emc.com/collateral/industry-overview/big-data-fuels-intelligence-driven-security-io.pdf (accessed on 13 May 2021).
- Keogh, E.; Lonardi, S.; Ratanamahatana, C.A. Towards parameter-free data mining. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 206–215. [Google Scholar]
- Ferragina, P.; Giancarlo, R.; Greco, V.; Manzini, G.; Valiente, G. Compression-based classification of biological sequences and structures via the universal similarity metric: Experimental assessment. BMC Bioinform. 2007, 8, 252. [Google Scholar] [CrossRef] [Green Version]
- Cilibrasi, R.; Vitanyi, P. Automatic Extraction of Meaning from the Web. In Proceedings of the 2006 IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 2309–2313. [Google Scholar]
- Cilibrasi, R.; Vitányi, P.M.B. Clustering by compression. IEEE Trans. Inf. Theory 2005, 51, 1523–1545. [Google Scholar] [CrossRef] [Green Version]
- Yahalom, S. URI Anomaly Detection Using Similarity Metrics. Master’s Thesis, Tel-Aviv University, Tel-Aviv, Israel, 2008. [Google Scholar]
- de la Torre-Abaitua, G.; Lago-Fernández, L.F.; Arroyo, D. A parameter-free method for the detection of web attacks. In Proceedings of the International Joint Conference SOCO’17-CISIS’17-ICEUTE’17, León, Spain, 6–8 September 2017; Springer: Cham, Switzerland, 2017; pp. 661–671. [Google Scholar]
- Hee, C.V.; Lefever, E.; Verhoeven, B.; Mennes, J.; Desmet, B.; Pauw, G.D.; Daelemans, W.; Hoste, V. Automatic detection and prevention of cyberbullying. In Proceedings of the International Conference on Human and Social Analytics (HUSO 2015), Saint Julians, Malta, 11–16 October 2015. [Google Scholar]
- Killam, R.; Cook, P.; Stakhanova, N. Android malware classification through analysis of string literals. In Proceedings of the First Workshop on Text Analytics for Cybersecurity and Online Safety (TA-COS), Portorož, Slovenia, 23 May 2016. [Google Scholar]
- Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, K.; Martinez-Hernandez, V.; Meana HM, P.; Olivares-Mercado, J.; Sanchez, V. Social sentiment sensor in twitter for predicting cyber-attacks using L1 regularization. Sensors 2018, 18, 1380. [Google Scholar] [CrossRef] [Green Version]
- García-Teodoro, P.; Díaz-Verdejo, J.; Maciá-Fernández, G.; Vázquez, E. Anomaly-based network intrusion detection: Techniques, systems and challenges. Comput. Secur. 2009, 28, 18–28. [Google Scholar] [CrossRef]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. Network Anomaly Detection: Methods, Systems and Tools. IEEE Commun. Surv. Tutorials 2014, 16, 303–336. [Google Scholar] [CrossRef]
- Chaurasia, M.A. Comparative study of data mining techniques in intrusion dectection. Int. J. Curr. Eng. Sci. Res. 2016, 3, 107–112. [Google Scholar]
- Dong, Y.; Zhang, Y. Adaptively Detecting Malicious Queries in Web Attacks. arXiv 2017, arXiv:1701.07774. [Google Scholar]
- Hodo, E.; Bellekens, X.; Hamilton, A.; Tachtatzis, C.; Robert, A. Shallow and Deep Networks Intrusion Detection System: A Taxonomy and Survey. arXiv 2017, arXiv:1701.02145. [Google Scholar]
- Kruegel, C.; Vigna, G. Anomaly Detection of Web-based Attacks. In Proceedings of the 10th ACM Conference on Computer and Communications Security, Washingtion, DC, USA, 27–30 October 2003; ACM: New York, NY, USA; pp. 251–261. [Google Scholar] [CrossRef]
- Abu-Nimeh, S.; Nappa, D.; Wang, X.; Nair, S. A comparison of machine learning techniques for phishing detection. In Proceedings of the Anti-phishing Working Groups 2nd Annual eCrime Researchers Summit, eCrime ’07, Pittsburgh, PA, USA, 4–5 October 2007; ACM: New York, NY, USA; pp. 60–69. [Google Scholar]
- Mallikarjunappa, B.; Prabhakar, D.R. A novel method of spam mail detection using text based clustering approach. Int. J. Comput. Appl. 2010, 5, 15–25. [Google Scholar]
- Tee, H. FPGA Unsolicited Commercial Email Inline Filter Design Using Levenshtein Distance Algorithm and Longest Common Subsequence Algorithm; Jabatan Sistem dan Teknologi Komputer, Fakulti Sains Komputer dan Teknologi Maklumat, Universiti Malaya: Kuala Lumpur, Malaya, 2010. [Google Scholar]
- Delany, S.J.; Bridge, D. Catching the drift: Using feature-free case-based reasoning for spam filtering. In Case-Based Reasoning Research and Development; Weber, R.O., Richter, M.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 314–328. [Google Scholar]
- Prilepok, M.; Berek, P.; Platos, J.; Snasel, V. Spam detection using data compression and signatures. Cybern. Syst. 2013, 44, 533–549. [Google Scholar] [CrossRef]
- Bratko, A.; Filipič, B.; Cormack, G.V.; Lynam, T.R.; Zupan, B. Spam filtering using statistical data compression models. J. Mach. Learn. Res. 2006, 7, 2673–2698. [Google Scholar]
- Antonakakis, M.; Perdisci, R.; Nadji, Y.; Vasiloglou, N.; Abu-Nimeh, S.; Lee, W.; Dagon, D. From throw-away traffic to bots: Detecting the rise of dga-based malware. In Proceedings of the 21st USENIX Conference on Security Symposium, Security’12, Bellevue, WA, USA, 8–10 August 2012; USENIX Association: Berkeley, CA, USA; p. 24. [Google Scholar]
- Thomas, M.; Mohaisen, A. Kindred domains: Detecting and clustering botnet domains using dns traffic. In Proceedings of the 23rd International Conference on World Wide WebWWW ’14 Companion, Seoul, Korea, 7–11 April 2014; pp. 707–712. [Google Scholar]
- Ahluwalia, A.; Traore, I.; Ganame, K.; Agarwal, N. Detecting broad length algorithmically generated domains. In Intelligent, Secure, and Dependable Systems in Distributed and Cloud Environments; Traore, I., Woungang, I., Awad, A., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 19–34. [Google Scholar]
- Woodbridge, J.; Anderson, H.S.; Ahuja, A.; Grant, D. Predicting domain generation algorithms with long short-term memory networks. arXiv 2016, arXiv:1611.00791. [Google Scholar]
- Selvi, J.; Rodríguez, R.J.; Soria-Olivas, E. Detection of algorithmically generated malicious domain names using masked n-grams. Expert Syst. Appl. 2019, 124, 156–163. [Google Scholar] [CrossRef] [Green Version]
- Tong, V.; Nguyen, G. A method for detecting dga botnet based on semantic and cluster analysis. In Proceedings of the Seventh Symposium on Information and Communication Technology, SoICT ’16, Ho Chi Minh City, Vietnam, 8–9 December 2016; ACM: New York, NY, USA; pp. 272–277. [Google Scholar]
- Aslan, Ç.B.; Li, S.; Çelebi, F.V.; Tian, H. The World of Defacers: Looking through the Lens of Their Activities on Twitter. IEEE Access 2020, 8, 204132–204143. [Google Scholar] [CrossRef]
- Al-Rowaily, K.; Abulaish, M.; Al-Hasan Haldar, N.; Al-Rubaian, M. Bisal—A bilingual sentiment analysis lexicon to analyze dark web forums for cyber security. Digit. Investig. 2015, 14, 53–62. [Google Scholar] [CrossRef]
- Weifeng, L.; Hsinchun, C. Identifying top sellers in underground economy using deep learning-based sentiment analysis. In Proceedings of the 2014 IEEE Joint Intelligence and Security Informatics Conference, The Hague, The Netherlands, 24–26 September 2014. [Google Scholar]
- Zaeem, R.N.; Li, C.; Barber, K.S. On Sentiment of Online Fake News. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), The Hague, The Netherlands, 7–10 December 2020; pp. 760–767. [Google Scholar]
- Zollo, F.; Novak, P.K.; Del Vicario, M.; Bessi, A.; Mozetič, I.; Scala, A.; Caldarelli, G.; Quattrociocchi, W. Emotional dynamics in the age of misinformation. PLoS ONE 2015, 10, e0138740. [Google Scholar] [CrossRef]
- Deb, A.; Lerman, K.; Ferrara, E. Predicting cyber events by leveraging hacker sentiment. Information 2018, 9, 280. [Google Scholar] [CrossRef] [Green Version]
- Mittal, S.; Das, P.K.; Mulwad, V.; Joshi, A.; Finin, T. Cybertwitter: Using twitter to generate alerts for cybersecurity threats and vulnerabilities. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016. [Google Scholar]
- Liu, B.; Zhang, L. A survey of opinion mining and sentiment analysis. In Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 415–463. [Google Scholar]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- dos Santos, C.; Gatti, M. Deep convolutional neural networks for sentiment analysis of short texts. In Proceedings of the 25th International Conference on Computational Linguistics, COLING 2014, Dublin, Ireland, 23–29 August 2014; Technical Papers. pp. 69–78. [Google Scholar]
- Severyn, A.; Moschitti, A. Twitter sentiment analysis with deep convolutional neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 959–962. [Google Scholar]
- Tang, D.; Wei, F.; Qin, B.; Liu, T.; Zhou, M. Coooolll: A deep learning system for twitter sentiment classification. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 208–212. [Google Scholar]
- Tukaani-Project. A Quick Benchmark: Gzip vs. Bzip2 vs. LZMA. 2005. Available online: http://tukaani.org/lzma/benchmarks.html (accessed on 25 April 2021).
- Scikit Learn. Scikit-Learn: Machine Learning in Python—Scikit-Learn 0.18.1 Documentation. Available online: http://scikit-learn.org/stable/ (accessed on 29 March 2017).
- Torrano-Gimenez, C.; Nguyen, H.T.; Alvarez, G.; Franke, K. Combining expert knowledge with automatic feature extraction for reliable web attack detection. Secur. Commun. Netw. 2015, 8, 2750–2767. [Google Scholar] [CrossRef] [Green Version]
- CSIC-Dataset. HTTP DATASET CSIC. 2010. Available online: http://www.isi.csic.es/dataset/ (accessed on 29 March 2017).
- Nguyen, H.T.; Torrano-Gimenez, C.; Alvarez, G.; Petrović, S.; Franke, K. Application of the generic feature selection measure in detection of web attacks. In Computational Intelligence in Security for Information Systems; Springer: Berlin/Heidelberg, Germany, 2011; pp. 25–32. [Google Scholar]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The stanford corenlp natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Almeida, T.A.; Hidalgo, J.M.G.; Yamakami, A. Contributions to the study of sms spam filtering: New collection and results. In Proceedings of the 11th ACM Symposium on Document Engineering DocEng ’11, Mountain View, CA, USA, 19–22 September 2011; ACM: New York, NY, USA; pp. 259–262. [Google Scholar]
- Lison, P.; Mavroeidis, V. Automatic detection of malware-generated domains with recurrent neural models. arXiv 2017, arXiv:1709.07102. [Google Scholar]
- Go, A.; Bhayani, R.; Huang, L. Twitter Sentiment Classification Using Distant Supervision; Technical Report; Stanford University: Stanford, CA, USA, 2009. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 142–150. [Google Scholar]
- Samtani, S.; Kantarcioglu, M.; Chen, H. Trailblazing the Artificial Intelligence for Cybersecurity Discipline: A Multi-Disciplinary Research Roadmap. ACM Trans. Manag. Inf. Syst. 2020. [Google Scholar] [CrossRef]
- Lillis, D.; Becker, B.; O’Sullivan, T.; Scanlon, M. Current challenges and future research areas for digital forensic investigation. arXiv 2016, arXiv:1604.03850. [Google Scholar]
- de la Torre-Abaitua, G.; Lago-Fernández, L.; Arroyo, D. On the application of compression based metrics to identifying anomalous behaviour in web traffic. Log. J. IGPL 2020, 28, 546–557. [Google Scholar] [CrossRef]
- Resende, J.S.; Martins, R.; Antunes, L. A Survey on Using Kolmogorov Complexity in Cybersecurity. Entropy 2019, 21, 1196. [Google Scholar] [CrossRef] [Green Version]
- Larriva-Novo, X.; Sánchez-Zas, C.; Villagrá, V.A.; Vega-Barbas, M.; Rivera, D. An Approach for the Application of a Dynamic Multi-Class Classifier for Network Intrusion Detection Systems. Electronics 2020, 9, 1759. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
| URL | DGA | Spam | Movie Reviews | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Normal | anom. | Normal | DGA | Normal | Spam | posit. | negat. | posit. | negat. | |
| 138 | 147 | 15 | 20 | 72 | 139 | 74 | 74 | 1325 | 1294 | |
| 97 | 107 | 5 | 7 | 58 | 29 | 36 | 37 | 1032 | 946 | |
| Q1 | 59 | 63 | 11 | 15 | 33 | 133 | 44 | 44 | 691 | 706 |
| Q2 | 71 | 85 | 14 | 20 | 52 | 149 | 69 | 70 | 968 | 973 |
| Q3 | 248 | 251 | 17 | 28 | 93 | 157 | 103 | 104 | 1614 | 1568 |
| Four Examples of Normal Queries |
|---|
| . modo=registro&login=beveridg&password=camale%F3nica&nombre=Stefani&apellidos=Gimeno+Cadaveira& |
| email=morando%40sandrasummer.gy&dni=91059337Z&direccion=C%2F+Bobala+111+4A&ciudad=Mog%E1n& |
| cp=46293&provincia=Castell%F3n&ntc=8975566519527853&B1=Registrar |
| . id=1&nombre=Queso+Manchego&precio=39&cantidad=57&B1=A%F1adir+al+carrito |
| . modo=insertar&precio=5588&B1=Confirmar |
| . modo=registro&login=ouellett2&password=radicalmente&nombre=Ranquel&apellidos=Orra& |
| email=hodo%40deltamarina.my&dni=18518539C&direccion=Fructuoso+Alvarez%2C+55+& |
| ciudad=Bay%E1rcal&cp=17742&provincia=Palencia&ntc=3322562441567993&B1=Registrar |
| Four Examples of Anomalous Queries |
| . modo=insertar&precioA=900&B1=Pasar+por+caja |
| . modo=entrar&login=dedie&pwd=M50879RIST44& |
| remember=bob%40%3CSCRipt%3Ealert%28Paros%29%3C%2FscrIPT%3E.parosproxy.org&B1=Entrar |
| . modo=registro&login=alix&password=venI%21A&nombreA=Imelda&apellidos=Delb%F3n+Coll& |
| email=holister%40brunoseguridad.cf&dni=80525673M&direccion=Plza.+Noria+De+La+Huerta+68%2C+& |
| ciudad=Alcudia+de+Veo&cp=28690&provincia=%C1vila&ntc=6551003767368321&B1=Registrar |
| . modo=entrar&login=bienek&pwd=cloqu%27e%2Fro&remember=off&B1=Entrar |
| k | C | Acc. | AUC | |
|---|---|---|---|---|
| 8 | 1.0 | 100.0 | 0.909 | |
| 16 | 10.0 | 10.0 | 0.946 | |
| 32 | 1.0 | 10.0 | 0.968 | |
| 80 | 1.0 | 10.0 | 0.95 ± 0.02 | 0.975 |
| 160 | 2.0 | 5.0 | 0.95 ± 0.02 | 0.974 |
| Four Examples of Ham SMS |
|---|
| . What you doing?how are you? |
| . Ok lar... Joking wif u oni... |
| 3. Cos i was out shopping wif darren jus now n i called them 2 ask wat present he wan lor. Then he |
| started guessing who i was wif n he finally guessed darren lor. |
| . MY NO. IN LUTON 0125698789 RING ME IF UR AROUND! H* |
| dun say so early hor... U c already then say... |
| Four Examples of Spam SMS |
| 1. FreeMsg: Txt: CALL to No: 86888 & claim your reward of 3 hours talk time to use from your phone |
| now! ubscribe6GBP |
| . mnth inc 3hrs 16 stop?txtStop |
| . Sunshine Quiz! Win a super Sony DVD recorder if you canname the capital of Australia? Text MQUIZ |
| to 82277. B |
| . URGENT! Your Mobile No 07808726822 was awarded a L2,000 Bonus Caller Prize on 02/09/03! This is |
| our 2nd attempt to |
| contact YOU! Call 0871-872-9758 BOX95QU |
| k | C | Acc. | AUC | |
|---|---|---|---|---|
| 8 | 1.5 | 100 | ||
| 16 | 1.5 | 50 | ||
| 32 | 1.5 | 25 | ||
| 80 | 5 | 25 | ||
| 160 | 1.5 | 25 | 0.904 ± 0.01 | 0.96 |
| Normal Domain | Malicious Domain |
|---|---|
| cfre.org | ofdhiydrrttpblp.com |
| fabricadericos.com | puciftnfkplcbhp.net |
| earthrootgaming.com | tahathil.ru |
| google.com | thisarmedindependent.com |
| facebook.com | cgoellwcvwti.com |
| mail.ru | ufaqzt.cn |
| k | C | Acc. | AUC | |
|---|---|---|---|---|
| 8 | 100 | 25 | ||
| 16 | 0.5 | 25 | ||
| 32 | 0.5 | 25 | ||
| 80 | 1 | 25 | 0.941 ± 0.004 | 0.98 |
| 160 | 5 | 25 | 0.97 |
| Five Examples of Positive Tweets |
|---|
| . happy sunny sunday peeps xxx |
| . in worrk now chilling out and cleaning the gym oiss easy!! im supervisor today hahahahaha |
| go me!!!! Clon show!!!! |
| . is craving sun chips I think im going to go get some now...lol xo |
| . Congratulations! so glad to hear you’ve had a great weekend at the markets |
| . I just noticed that I use a lot of smiley faces when I talk. lmfao |
| Five Examples of Negative Tweets |
| . I think im going to be pulling a late night to finish this |
| . Im sad to see my aunt in jail She was arrested for being a very loud drunk lady |
| . grrr bad hayfever day already |
| 4. Furthermore, - I am sunburned. I am hurting Had a good time at meet yesterday, but walked all over |
| creation and now am very tired. |
| . I’m so bored. No one is talking on MSN, there is nothing to do, and I have got no texts.. |
| k | C | Acc. | AUC |
|---|---|---|---|
| 8 | |||
| 16 | |||
| 32 | |||
| 80 | |||
| 160 | 0.01 | 0.767 ± 0.003 | 0.849 ± 0.002 |
| Two Examples of Positive Reviews |
|---|
| . I havent seen that movie in 20 or more years but I remember the attack scene with the horses |
| wearing gas-masks vividly, this scene ranks way up there with the best of them including the |
| beach scene on Saving private Ryan, I recommend it strongly. |
| . Now this is what I’d call a good horror. With occult/supernatural undertones, this nice |
| low-budget French movie caught my attention from the very first scene. This proves you do not |
| need wild FX or lots of gore to make an effective horror movie. |
| Two Examples of Negative Reviews |
| . The power rangers is definitely the worst television show and completely ridiculous plastic toy |
| line in the history of the United States. There is absolutely nothing even remotely |
| entertaining about this completely awful television show. |
| . Some people are saying that this film was "funny". This film is not "funny" at all. Since when |
| is Freddy Krueger supposed to be "funny"? I would call it funnily crap. This film is supposed |
| to be a Horror film, not a comedy. If Freddy had a daughter, would not that information have |
| surfaced like in the first one!? The ending was also just plain stupid and cheesy, exactly |
| like the rest of it. |
| k | C | Acc. | AUC | |
|---|---|---|---|---|
| 8 | 0.5 | 0.1 | ||
| 16 | 5 | 0.1 | ||
| 32 | 1.5 | 0.1 | ||
| 80 | 20 | 0.1 | ||
| 160 | 0.5 | 0.1 | 0.8590 ± 0.012 | 0.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de la Torre-Abaitua, G.; Lago-Fernández, L.F.; Arroyo, D. A Compression-Based Method for Detecting Anomalies in Textual Data. Entropy 2021, 23, 618. https://doi.org/10.3390/e23050618
de la Torre-Abaitua G, Lago-Fernández LF, Arroyo D. A Compression-Based Method for Detecting Anomalies in Textual Data. Entropy. 2021; 23(5):618. https://doi.org/10.3390/e23050618
Chicago/Turabian Stylede la Torre-Abaitua, Gonzalo, Luis Fernando Lago-Fernández, and David Arroyo. 2021. "A Compression-Based Method for Detecting Anomalies in Textual Data" Entropy 23, no. 5: 618. https://doi.org/10.3390/e23050618
APA Stylede la Torre-Abaitua, G., Lago-Fernández, L. F., & Arroyo, D. (2021). A Compression-Based Method for Detecting Anomalies in Textual Data. Entropy, 23(5), 618. https://doi.org/10.3390/e23050618