
A Nonlinear Maximum Correntropy Information Filter for High-Dimensional Neural Decoding



Abstract
:1. Introduction
2. Nonlinear Maximum Correntropy Information Filter
3. Algorithm Derivation and Analysis
3.1. Derivation of Estimation on the Mean of Posterior
3.2. Derivation of Information Matrix
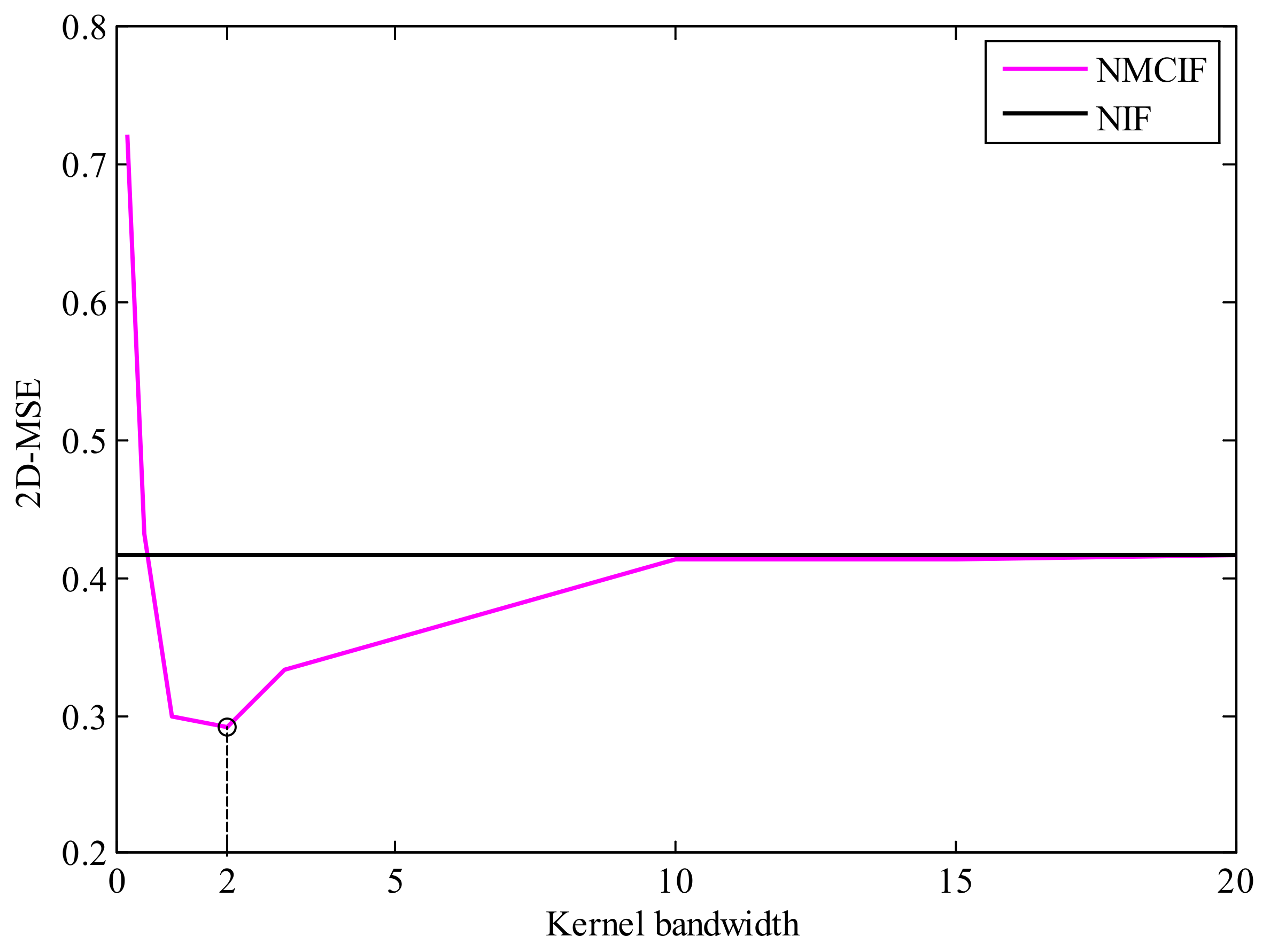
3.3. Robustness Analysis
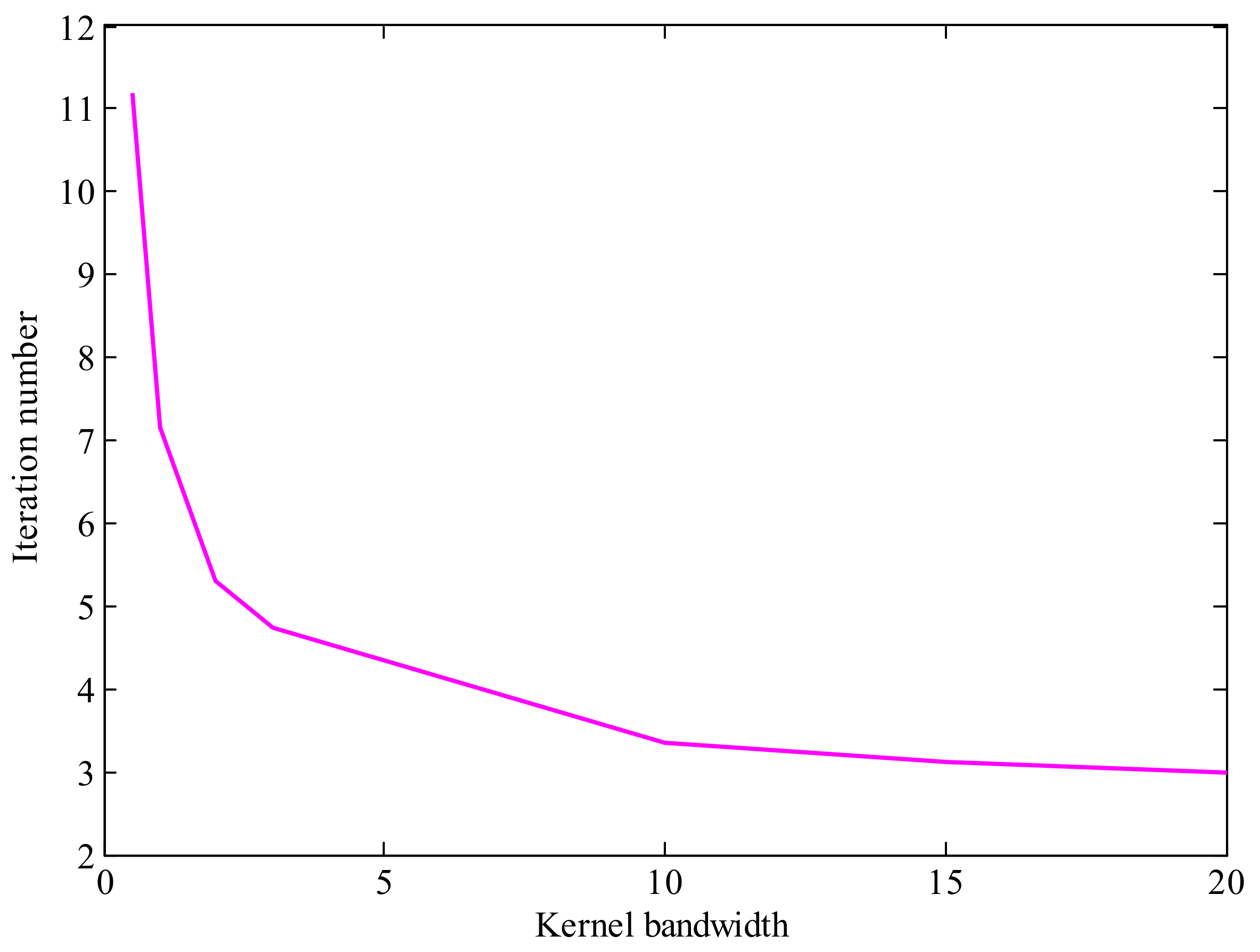
3.4. Convergence Analysis
4. Neural Decoding Using Nonlinear Maximum Correntropy Information Filter
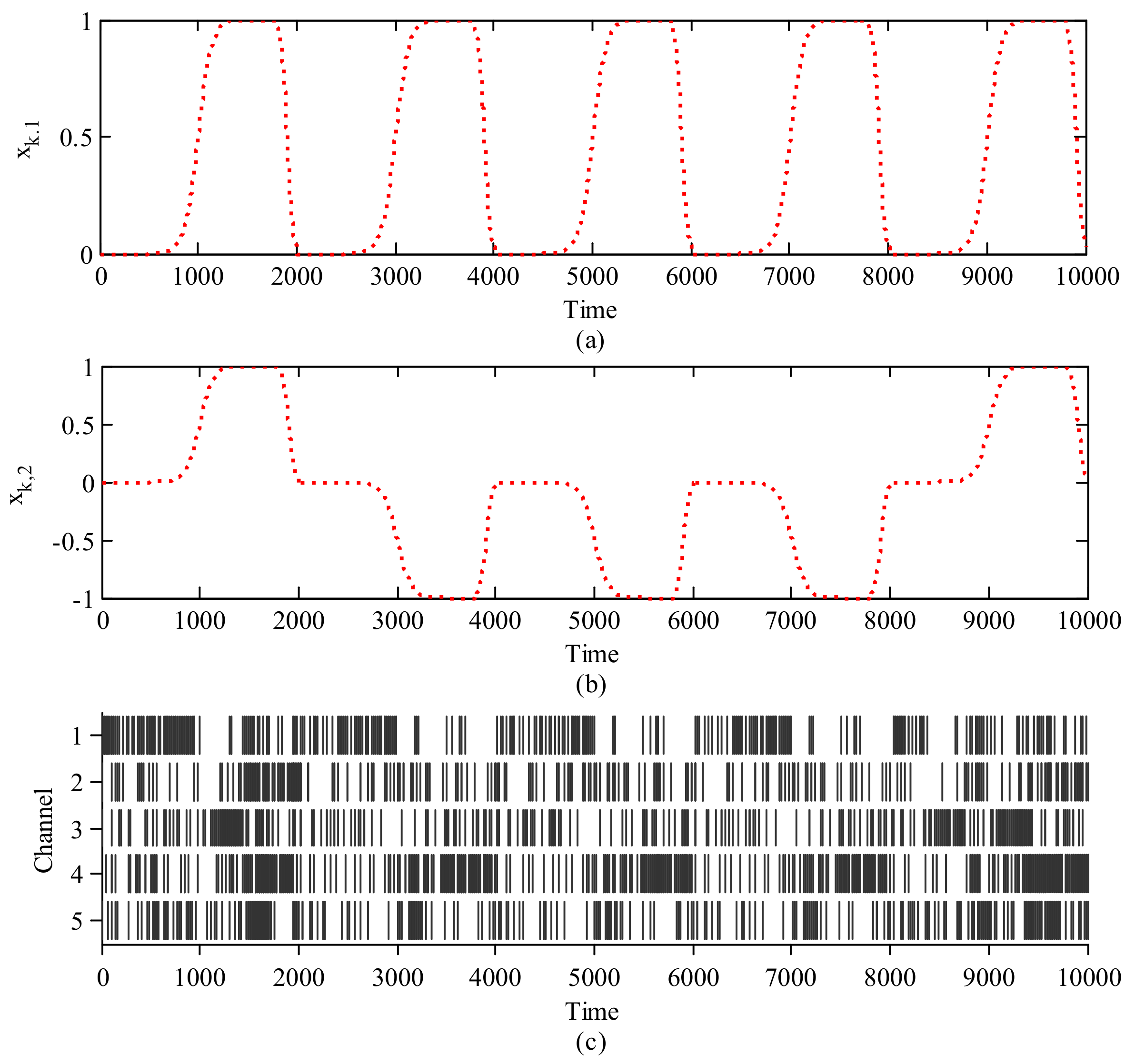
4.1. Experiment and Data Collection
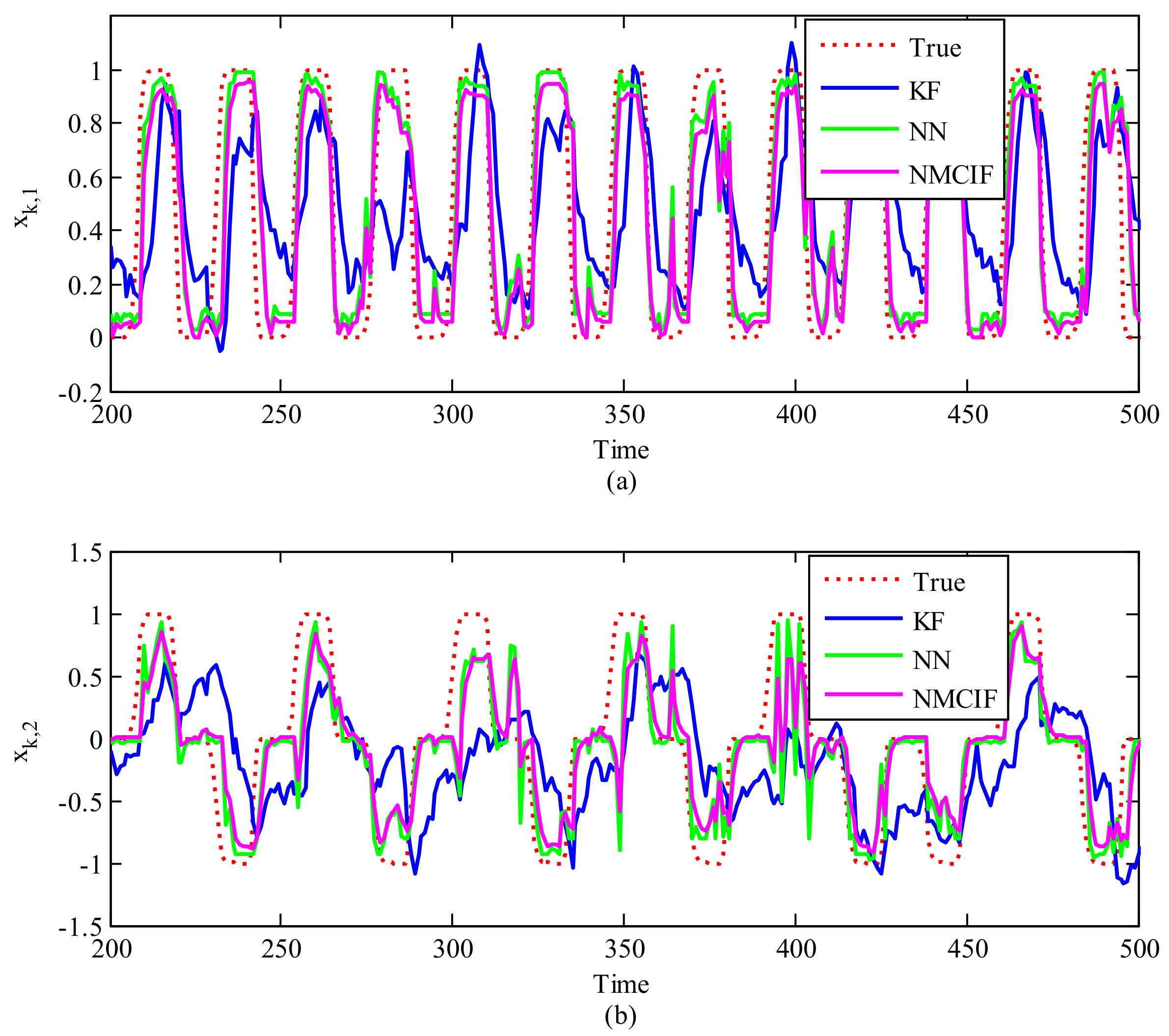
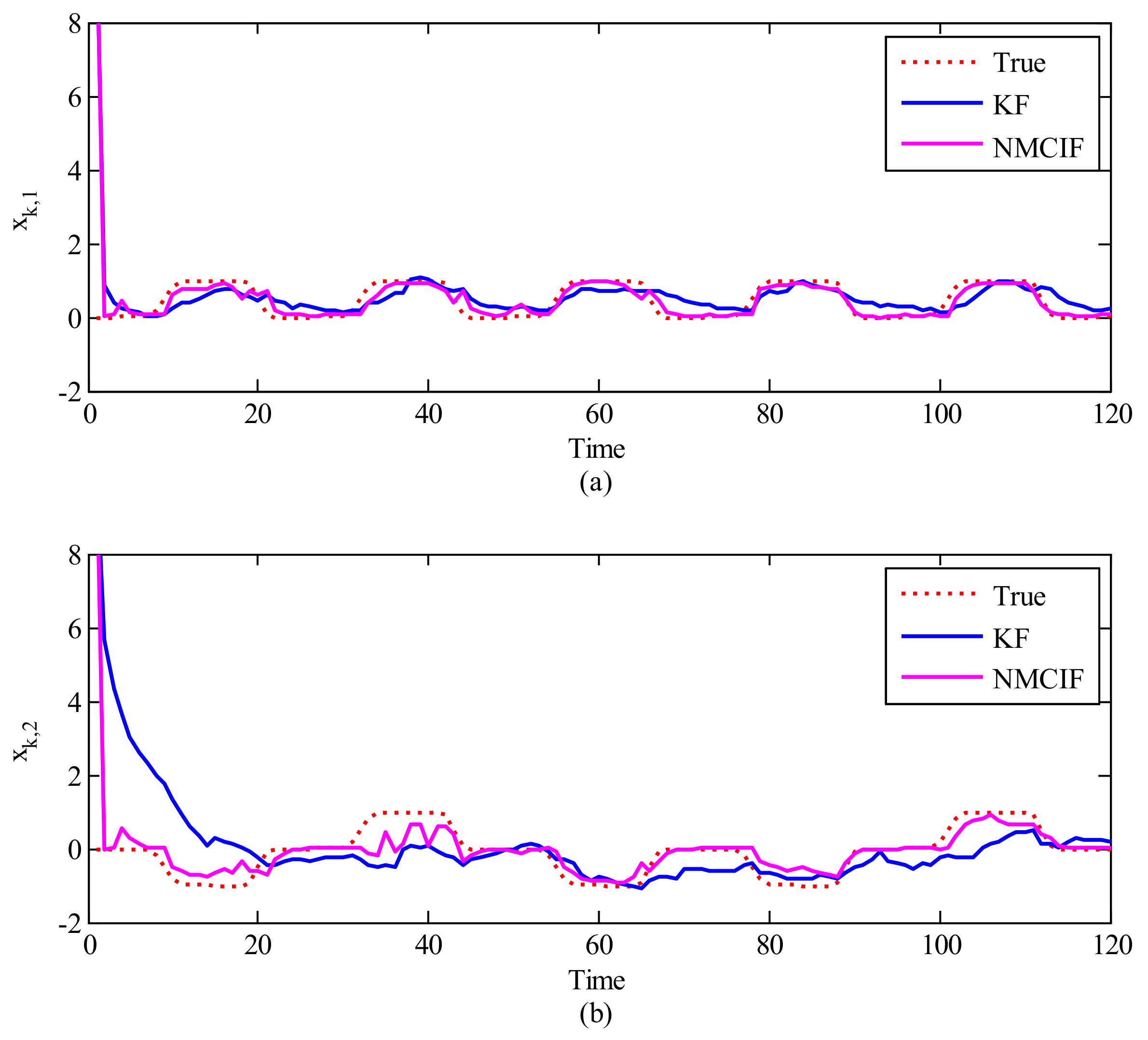
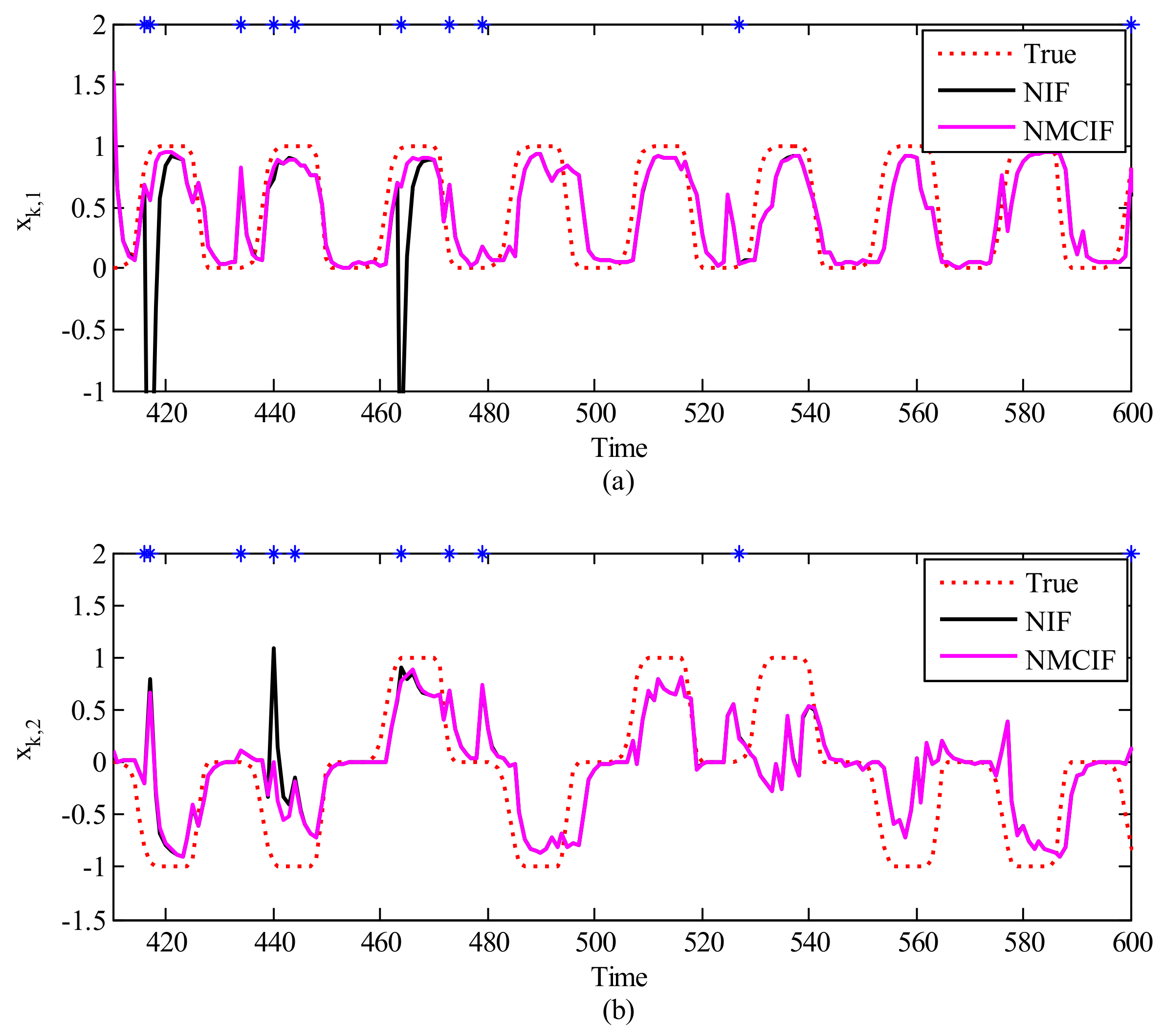
4.2. Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Derivation Process from Equation (26) to Equation (7)
Appendix B. The Relationship of the Influence Function and Asymptotic Covariance Matrix
Appendix C. The Derivation of Influence Function
Appendix D. The Solution of and
References
- Lebedev, M.A.; Nicolelis, M.A.L. Brain–machine interfaces: Past, present and future. Trends Neurosci. 2006, 29, 536–546. [Google Scholar] [CrossRef] [PubMed]
- Taylor, D.M.; Tillery, S.I.H.; Schwartz, A.B. Direct Cortical Control of 3D Neuroprosthetic Devices. Science 2002, 296, 1829–1832. [Google Scholar] [CrossRef] [PubMed]
- O’Doherty, J.E.; Lebedev, M.A.; Hanson, T.L.; Fitzsimmons, N.A.; Nicolelis, M.A.L. A brain-machine interface instructed by direct intracorticalmicrostimulation. Front. Integr. Neurosci. 2009, 3, 20. [Google Scholar]
- Orsborn, A.L.; Moorman, H.G.; Overduin, S.A.; Shanechi, M.M.; Dimitrov, D.F.; Carmena, J.M. Closed-Loop Decoder Adaptation Shapes Neural Plasticity for Skillful Neuroprosthetic Control. Neuron 2014, 82, 1380–1393. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vyas, S.; Even-Chen, N.; Stavisky, S.D.; Ryu, S.I.; Nuyujukian, P.; Shenoy, K.V. Neural Population Dynamics Underlying Motor Learning Transfer. Neuron 2018, 97, 1177–1186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wolpaw, J.R.; Birbaumer, N.; Heetderks, W.J.; McFarland, D.J.; Peckham, P.H.; Schalk, G.; Donchin, E.; Quatrano, L.A.; Robinson, C.J.; Vaughan, T.M. Brain-computer interface technology: A review of the first international meeting. IEEE Trans. Rehabil. Eng. 2000, 8, 164–173. [Google Scholar] [CrossRef] [PubMed]
- Nicolelis, M.A.L. Brain-machine interfaces to restore motor function and probe neural circuits. Nat. Rev. Neurosci. 2003, 4, 417–422. [Google Scholar] [CrossRef]
- Churchland, M.M.; Cunningham, J.P.; Kaufman, M.T.; Foster, J.D.; Nuyujukian, P.; Ryu, S.I.; Shenoy, K.V. Neural population dynamics during reaching. Nature 2012, 487, 51–56. [Google Scholar] [CrossRef] [Green Version]
- Musallam, S.; Corneil, B.D.; Greger, B.; Scherberger, H.; Andersen, R.A. Cognitive Control Signals for Neural Prosthetics. Science 2004, 305, 258–262. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Velliste, M.; Perel, S.; Spalding, M.C.; Whitford, A.S.; Schwartz, A.B. Cortical control of a prosthetic arm for self-feeding. Nature 2008, 453, 1098–1101. [Google Scholar] [CrossRef] [PubMed]
- Hochberg, L.R.; Serruya, M.D.; Friehs, G.M.; Mukand, J.A.; Saleh, M.; Caplan, A.H.; Branner, A.; Chen, D.; Penn, R.D.; Donoghue, J.P. Neuronal ensemble control of prosthetic devices by a human with tetraplegia. Nature 2006, 442, 164–171. [Google Scholar] [CrossRef] [PubMed]
- Hochberg, L.R.; Bacher, D.; Jarosiewicz, B.; Masse, N.Y.; Simeral, J.D.; Vogel, J.; Haddadin, S.; Liu, J.; Cash, S.S.; van der Smagt, P.; et al. Reach and grasp by people with tetraplegia using a neurally controlled robotic arm. Nature 2012, 485, 372–375. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Truccolo, W.; Friehs, G.M.; Donoghue, J.P.; Hochberg, L.R. Primary Motor Cortex Tuning to Intended Movement Kinematics in Humans with Tetraplegia. J. Neurosci. 2008, 28, 1163–1178. [Google Scholar] [CrossRef] [PubMed]
- Moritz, C.T.; Perlmutter, S.I.; Fetz, E.E. Direct control of paralysed muscles by cortical neurons. Nature 2008, 456, 639–642. [Google Scholar] [CrossRef]
- Collinger, J.L.; Wodlinger, B.; Downey, J.E.; Wang, W.; Tyler-Kabara, E.C.; Weber, D.J.; McMorland, A.J.C.; Velliste, M.; Boninger, M.L.; Schwartz, A.B. High-performance neuroprosthetic control by an individual with tetraplegia. Lancet 2013, 381, 557–564. [Google Scholar] [CrossRef] [Green Version]
- Gilja, V.; Pandarinath, C.; Blabe, C.H.; Nuyujukian, P.; Simeral, J.D.; Sarma, A.A.; Sorice, B.L.; Perge, J.A.; Jarosiewicz, B.; Hochberg, L.R.; et al. Clinical translation of a high-performance neural prosthesis. Nat. Med. 2015, 21, 1142–1145. [Google Scholar] [CrossRef] [Green Version]
- Bouton, C.E.; Shaikhouni, A.; Annetta, N.V.; Bockbrader, M.A.; Friedenberg, D.A.; Nielson, D.M.; Sharma, G.; Sederberg, P.B.; Glenn, B.C.; Mysiw, W.J.; et al. Restoring cortical control of functional movement in a human with quadriplegia. Nat. Med. 2016, 533, 247–250. [Google Scholar] [CrossRef]
- Ajiboye, A.B.; Willett, F.R.; Young, D.R.; Memberg, W.D.; Murphy, B.A.; Miller, J.P.; Walter, B.L.; Sweet, J.A.; Hoyen, H.A.; Keith, M.W.; et al. Restoration of reaching and grasping movements through brain-controlled muscle stimulation in a person with tetraplegia: A proof-of-concept demonstration. Lancet 2017, 389, 1821–1830. [Google Scholar] [CrossRef] [Green Version]
- Brandman, D.M.; Hosman, T.; Saab, J.; Burkhart, M.C.; Shanahan, B.E.; Ciancibello, J.G.; Sarma, A.A.; Milstein, D.J.; Vargas-Irwin, C.E.; Franco, B.; et al. Rapid calibration of an intracortical brain–computer interface for people with tetraplegia. J. Neural Eng. 2018, 15, 1–14. [Google Scholar] [CrossRef]
- Gilja, V.; Nuyujukian, P.; Chestek, C.A.; Cunningham, J.P.; Yu, B.M.; Fan, J.M.; Churchland, M.M.; Kaufman, M.T.; Kao, J.C.; Ryu, S.I.; et al. A high-performance neural prosthesis enabled by control algorithm design. Nat. Neurosci. 2012, 15, 1752–1757. [Google Scholar] [CrossRef] [Green Version]
- Malik, W.Q.; Truccolo, W.; Brown, E.N.; Hochberg, L.R. Efficient Decoding With Steady-State Kalman Filter in Neural Interface Systems. IEEE Trans. Neural Syst. Rehabil. Eng. 2011, 19, 25–34. [Google Scholar] [CrossRef] [Green Version]
- Homer, M.L.; Perge, J.A.; Black, M.J.; Harrison, M.T.; Cash, S.S.; Hochberg, L.R. Adaptive Offset Correction for Intracortical Brain-Computer Interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 239–248. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.; Gao, Y.; Bienenstock, E.; Donoghue, J.P.; Black, M.J. Bayesian Population Decoding of Motor Cortical Activity Using a Kalman Filter. Neural Comput. 2006, 18, 80–118. [Google Scholar] [CrossRef]
- Thayer, J.F. On the importance of inhibition: Central and peripheral manifestations of nonlinear inhibitory processes in neural systems. Dose-Response 2006, 4, 2–21. [Google Scholar] [CrossRef]
- Yang, Y.; Dewald, J.P.A.; van der Helm, F.C.T.; Schouten, A.C. Unveiling neural coupling within the sensorimotor system: Directionality and nonlinearity. Eur. J. Neurosci. 2018, 48, 2407–2415. [Google Scholar] [CrossRef] [Green Version]
- Anderson, B.; Moore, J. Optimal Filtering; Prentice-Hall: New York, NY, USA, 1979. [Google Scholar]
- Julier, S.; Uhlmann, J.; Durrant-Whyte, H.F. A new method for the nonlinear transformation of means and covariances in filters and estimators. IEEE Trans. Autom. Control. 2000, 45, 477–482. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; O’Doherty, J.E.; Hanson, T.L.; Lebedev, M.A.; Henriquez, C.S.; Nicolelis, M.A.L. Unscented Kalman Filter for Brain-Machine Interfaces. PLoS ONE 2009, 54, e6243. [Google Scholar] [CrossRef] [Green Version]
- Arasaratnam, I.; Haykin, S. Cubature Kalman filters. IEEE Trans. Autom. Control. 2009, 54, 1254–1269. [Google Scholar] [CrossRef] [Green Version]
- Truccolp, W.; Eden, U.T.; Fellows, M.R.; Donoghue, J.P.; Brown, E.N. A Point Process Framework for Relating Neural Spiking Activity to Spiking History, Neural Ensemble, and Extrinsic Covariate Effects. J. Neurophysiol. 2005, 93, 1074–1089. [Google Scholar] [CrossRef] [Green Version]
- Qian, C.; Sun, X.; Zhang, S.; Xing, D.; Li, H.; Zheng, X.; Pan, G.; Wang, Y. Nonlinear Modeling of Neural Interaction for Spike Prediction Using the Staged Point-Process Model. Neural Comput. 2018, 30, 3189–3226. [Google Scholar] [CrossRef]
- Qian, C.; Sun, X.; Wang, Y.; Zheng, X.; Wang, Y.; Pan, G. Binless Kernel Machine: Modeling Spike Train Transformation for Cognitive Neural Prostheses. Neural Comput. 2018, 32, 1863–1900. [Google Scholar] [CrossRef] [PubMed]
- Ando, T.; Konishi, S. Neural Network Nonlinear Regression Modeling and Information Criteria. In Proceedings of the Advances in Statistics, Combinatorics & Related Areas-selected Papers from the Scra-fim Viii-the Wollongong Conference, Wollongong, Australia, 19–21 December 2002; pp. 11–22. [Google Scholar]
- Kim, S.P.; Sanchez, J.C.; Rao, Y.N.; Erdogmus, D.; Carmena, J.M.; Lebedev, M.A.; Nicolelis, M.A.L.; Principe, J.C. A comparison of optimal MIMO linear and nonlinear models for brain–machine interfaces. J. Neural Eng. 2006, 3, 145–161. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tagliabue, M.; Francis, N.; Hao, Y.; Duret, M.; Brochier, T.; Riehle, A.; Maier, M.A.; Eskiizmirliler, S. Estimation of two-digit grip type and grip force level by frequency decoding of motor cortex activity for a BMI application. In Proceedings of the International Conference on Advanced Robotis (ICAR), Istanbul, Turkey, 27–31 July 2015; pp. 308–315. [Google Scholar]
- Sadiq, M.T.; Yu, X.; Yuan, Z.; Zeming, F.; Rehman, A.U.; Ullah, I.; Li, G.; Xiao, G. Motor Imagery EEG Signals Decoding by Multivariate Empirical Wavelet Transform-Based Framework for Robust Brain–Computer Interfaces. IEEE Access 2019, 7, 171431–171451. [Google Scholar] [CrossRef]
- Willett, F.R.; Avansino, D.T.; Hochberg, L.R.; Henderson, J.M.; Shenoy, K.V. High-performance brain-to-text communication via handwriting. Nature 2021, 593, 249–254. [Google Scholar] [CrossRef]
- Wang, P.; Jiang, A.; Liu, X.; Shang, J.; Zhang, L. LSTM-Based EEG Classification in Motor Imagery Tasks. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 2086–2095. [Google Scholar] [CrossRef]
- Asgharpour, M.; Foodeh, R.; Daliri, M.R. Regularized Kalman filter for brain-computer interfaces using local field potential signals. J. Neurosci. Methods 2021, 350, 109022. [Google Scholar] [CrossRef]
- Irwin, Z.T.; Schroeder, K.E.; Vu, P.P.; Bullard, A.J.; Tat, D.M.; Nu, C.S.; Vaskov, A.; Nason, S.R.; Thompson, D.E.; Bentley, J.N.; et al. Neural Control of finger movement via intracortical brain-machine interface. J. Neural Eng. 2017, 14, 066004. [Google Scholar] [CrossRef]
- Simon, D. Optimal State Estimation: Kalman, H∞ and Nonlinear Approaches; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Schick, I.; Mitter, S.K. Robust recursive estimation in the presence of heavy-tailed observation noise. Ann. Stat. 1994, 22, 1045–1080. [Google Scholar] [CrossRef]
- Principe, J.C. Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives; Springer: New York, NY, USA, 2010. [Google Scholar]
- Liu, W.; Pokharel, P.P.; Principe, J.C. Correntropy: Properties and applications in non-Gaussian signal processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Santamaria, I.; Pokharel, P.P.; Principe, J.C. Generalized correlation function: Definition, properties, and application to blind equalization. IEEE Trans. Signal Process. 2006, 54, 2187–2197. [Google Scholar] [CrossRef] [Green Version]
- Singh, A.; Principe, J.C. Using correntropy as a cost function in linear adaptive filters. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Atlanta, GA, USA, 14–19 June 2009; pp. 2950–2955. [Google Scholar]
- Shi, L.; Lin, Y. Convex combination of adaptive filters under the maximum correntropy criterion in impulsive interference. IEEE Signal Process. Lett. 2014, 21, 1385–1388. [Google Scholar] [CrossRef]
- Liu, X.; Qu, H.; Zhao, J.; Chen, B. State space maximum correntropy filter. Signal Process. 2017, 130, 152–158. [Google Scholar] [CrossRef]
- He, R.; Hu, B.G.; Zheng, W.S.; Kong, X.W. Robust principal component analysis based on maximum correntropy criterion. IEEE Trans. Image Process. 2011, 20, 1485–1494. [Google Scholar]
- He, R.; Zheng, W.S.; Hu, B.G. Maximum correntropy criterion for robust face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1561–1576. [Google Scholar]
- Du, B.; Tang, X.; Wang, Z.; Zhang, L.; Tao, D. Robust Graph-Based Semisupervised Learning for Noisy Labeled Data via Maximum Correntropy Criterion. IEEE Trans. Cybern. 2019, 49, 1440–1453. [Google Scholar] [CrossRef]
- Mandanas, F.D.; Kotropoulos, C.L. Robust Multidimensional Scaling Using a Maximum Correntropy Criterion. IEEE Trans. Signal Process. 2017, 65, 919–932. [Google Scholar] [CrossRef]
- Bretscher, O. Linear Algebra with Applications: Fourth Edition; Pearson Prentice Hall: Hoboken, NJ, USA, 2009. [Google Scholar]
- Singh, A.; Principe, J.C. A closed form recursive solution for maximum correntropy training. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, USA, 15–19 March 2010; pp. 2070–2073. [Google Scholar]
- Chen, B.; Liu, X.; Zhao, H.; Principe, J.C. Maximum correntropy Kalman filter. Automatica 2017, 76, 70–77. [Google Scholar] [CrossRef] [Green Version]
- Hampel, F.R.; Ronchetti, E.M.; Rousseeuw, P.J.; Stahel, W.A. Robust Statistics: The Approach Based on Influence Functions; John Wiley & Sons: New York, NY, USA, 1986. [Google Scholar]
- Huber, P.J.; Ronchetti, E.M. Robust Statistics, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Protter, M.H.; Morrey, C.B. A First Course in Real Analysis; Springer: New York, NY, USA, 1977. [Google Scholar]
- Taylor, A.E. L’Hospital’s Rule. Am. Math. Mon. 1952, 59, 20–24. [Google Scholar] [CrossRef]
- Agarwal, R.P.; Meehan, M.; Regan, D.O. Fixed Point Theory and Applications; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Chen, B.; Wang, J.; Zhao, H.; Zheng, N.; Principe, J.C. Convergence of a fixed-point algorithm under maximum correntropy criterion. IEEE Signal Process. Lett. 2015, 22, 1723–1727. [Google Scholar] [CrossRef]
- Ortega, J.R.; Rheinboldt, W.C. Iterative Solution of Nonlinear Equations in Several Variables; Academic Press: London, UK, 1970. [Google Scholar]
- Liu, X.; Shen, X.; Chen, S.; Zhang, X.; Huang, Y.; Wang, Y.; Wang, Y. Hierarchical Dynamical Model for Multiple Cortical Neural Decoding. Neural Comput. 2021, 33, 1372–1401. [Google Scholar] [CrossRef]
- Carmena, J.M.; Lebedev, M.A.; Crist, R.E.; O’Doherty, J.E.; Santucci, D.M.; Dimitrov, D.F.; Patil, P.G.; Henriquez, C.S.; Nicolelis, M.A.L. Learning to Control a Brain–Machine Interface for Reaching and Grasping by Primates. PLoS Biol. 2003, 1, e42. [Google Scholar] [CrossRef] [Green Version]
- She, X.; Liao, Y.; Li, H.; Zhang, Q.; Wang, Y.; Zheng, X. Clustering and observation on neuron tuning property for brain machine interfaces. In Proceedings of the International Conference on Multisensor Fusion and Information Integration for Intelligent Systems (MFI), Beijing, China, 28–29 September 2014; pp. 1–8. [Google Scholar]
- Zhang, Z.; Chen, S.; Yang, Z.; Wang, Y. Tracking the Time Varying Neural Tuning via Adam on Point Process Observations. In Proceedings of the 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 195–198. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- DiGiovanna, J.; Mahmoudi, B.; Fortes, J.; Principe, J.C.; Sanchez, J.C. Coadaptive Brain-Machine Interface via Reinforcement Learning. IEEE Trans. Biomed. Eng. 2009, 56, 54–64. [Google Scholar] [CrossRef] [PubMed]
- Arduin, P.; Fregnac, Y.; Shulz, D.E.; Ego-Stengel, V. “Master” Neurons Induced by Operant Conditioning in Motor Cortex during a Brain-Machine Interface Task. J. Neurosci. 2013, 33, 8308–8320. [Google Scholar] [CrossRef] [Green Version]
- Boi, F.; Moraitis, T.; Feo, V.D.; Diotalevi, F.; Bartolozzi, C.; Indiveri, G.; Vato, A. A Bidirectional Brain-Machine Interface Featuring a Neuromorphic Hardware Decoder. Fronriers Neurosci. 2016, 10, 563. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simeral, J.D.; Kim, S.P.; Black, M.J.; Donoghue, J.P.; Hochberg, L.R. Neural control of cursor trajectory and click by a human with tetraplegia 1000 days after implant of an intracortical microelectrode array. J. Neural Eng. 2011, 8, 025027. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rao, C. Linear Statistical Inference and its Applications, 2nd ed.; John Wiley& Sons: New York, NY, USA, 1973. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 2D-MSE of in Rat_A | 2D-MSE of in Rat_B |
|---|---|---|
| KF | 0.5783 ± 0.1074 | 0.5558 ± 0.0653 |
| NN | 0.2633 ± 0.0787 | 0.4119 ± 0.0588 |
| NMCIF | 0.2451 ± 0.0684 | 0.3906 ± 0.0491 |
| Method | 2D-MSE of in Rat_A | 2D-MSE of in Rat_B |
|---|---|---|
| KF | 2.8686 ± 0.2112 | 1.8142 ± 0.1218 |
| NMCIF | 1.8978 ± 0.0661 | 1.3425 ± 0.0477 |
| Method | 2D-MSE of in Rat_A | 2D-MSE of in Rat_B |
|---|---|---|
| NIF | 0.4113 ± 0.1165 | 0.4962 ± 0.0456 |
| NMCIF_A | 0.2933 ± 0.0630 | 0.4548 ± 0.0453 |
| NMCIF_B | 0.2898 ± 0.0637 | 0.4517 ± 0.0437 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Chen, S.; Shen, X.; Zhang, X.; Wang, Y. A Nonlinear Maximum Correntropy Information Filter for High-Dimensional Neural Decoding. Entropy 2021, 23, 743. https://doi.org/10.3390/e23060743
Liu X, Chen S, Shen X, Zhang X, Wang Y. A Nonlinear Maximum Correntropy Information Filter for High-Dimensional Neural Decoding. Entropy. 2021; 23(6):743. https://doi.org/10.3390/e23060743
Chicago/Turabian StyleLiu, Xi, Shuhang Chen, Xiang Shen, Xiang Zhang, and Yiwen Wang. 2021. "A Nonlinear Maximum Correntropy Information Filter for High-Dimensional Neural Decoding" Entropy 23, no. 6: 743. https://doi.org/10.3390/e23060743
APA StyleLiu, X., Chen, S., Shen, X., Zhang, X., & Wang, Y. (2021). A Nonlinear Maximum Correntropy Information Filter for High-Dimensional Neural Decoding. Entropy, 23(6), 743. https://doi.org/10.3390/e23060743