
Unified Generative Adversarial Networks for Multidomain Fingerprint Presentation Attack Detection




Abstract
:1. Introduction
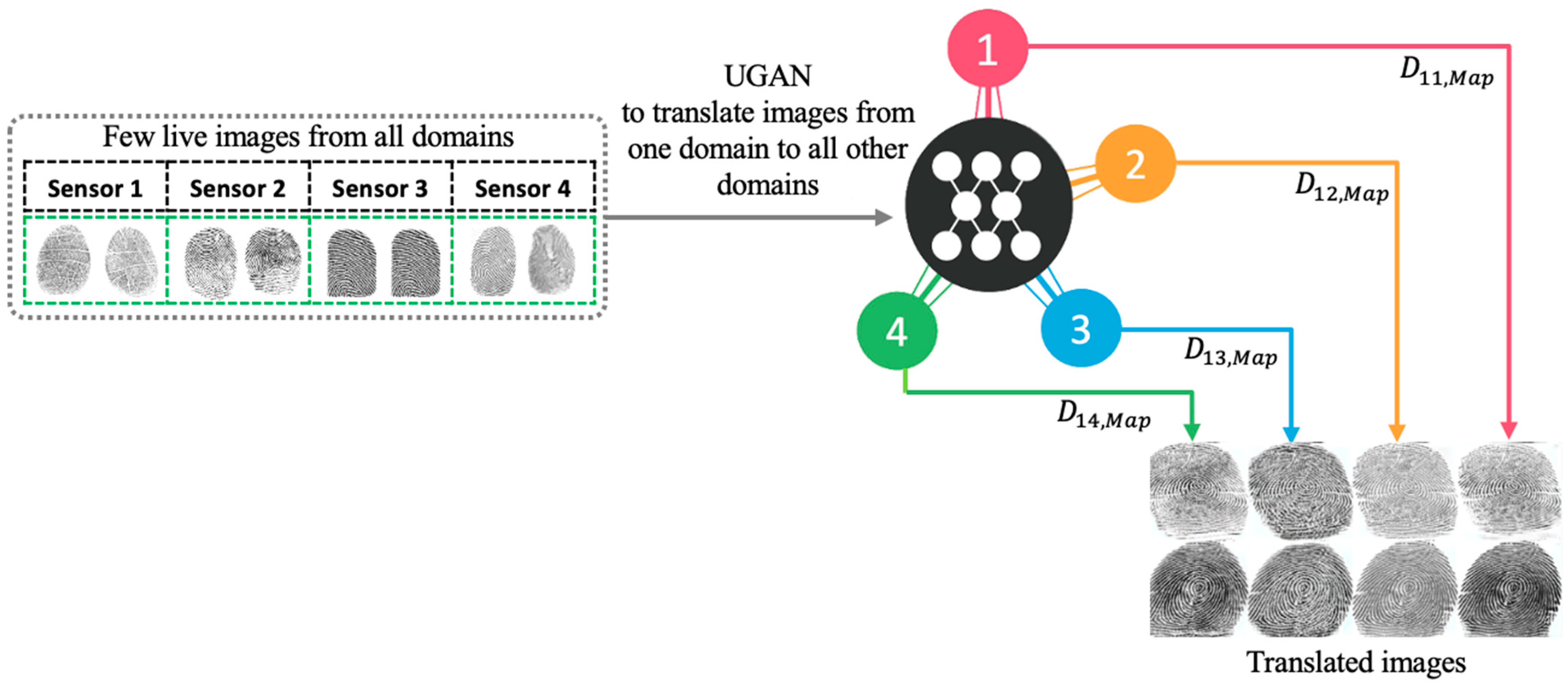
- We propose a novel domain adaptation approach for increasing the generalization ability of multiple target sensors with limited training samples using a source sensor with large labeled images.
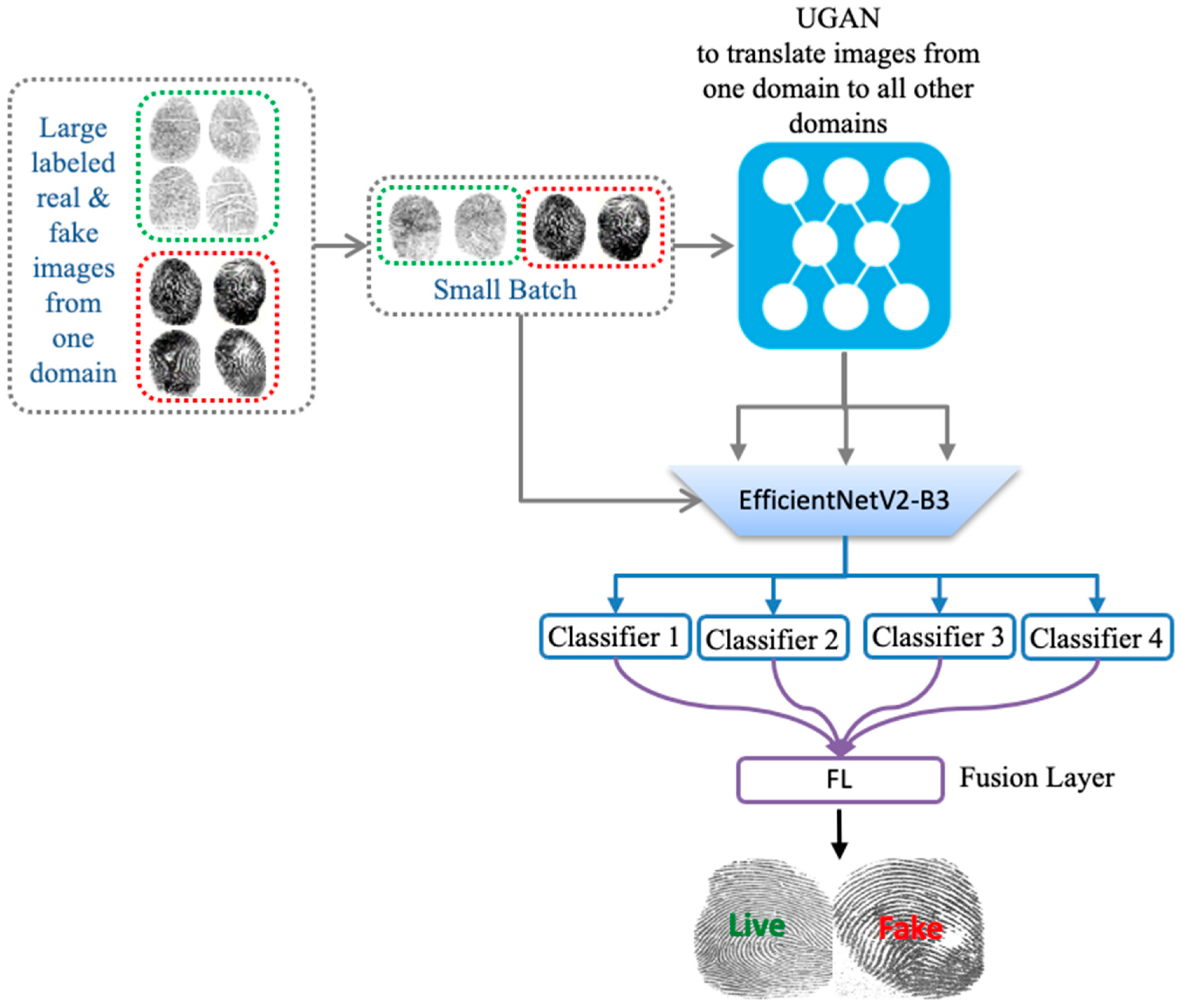
- The method uses a UGAN model that learns across all domains using a joint optimization problem.
- Additionally, it uses a weighted fusion layer for fusing the outputs of these multiple domains.
- The experimental results show that this method can increase the accuracy up to 80.44% compared to 67.80% for the nonadaptation case.
2. Proposed Method
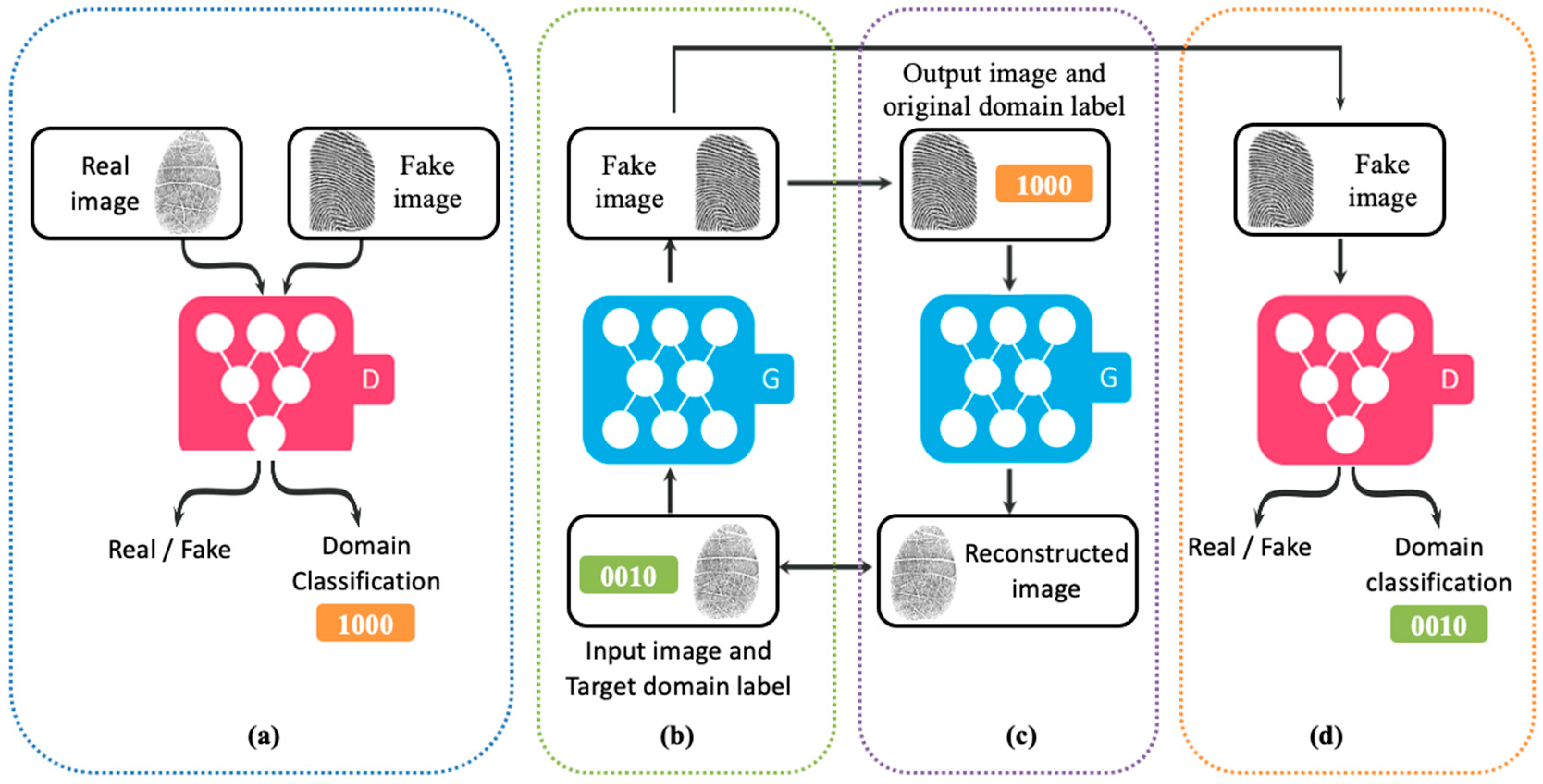
2.1. Multidomain Translation with UGAN
2.2. Multiple Classifier Fusion
| Algorithm 1 |
| Input: Fingerprint image. |
| First Step: Train a translation model that learns transfer mappings for different domains. |
|
| Second Step: Train EfficientNetV2 coupled with a fusion layer for feature extraction and classification by optimizing a binary cross-entropy loss. |
|
3. Experiments
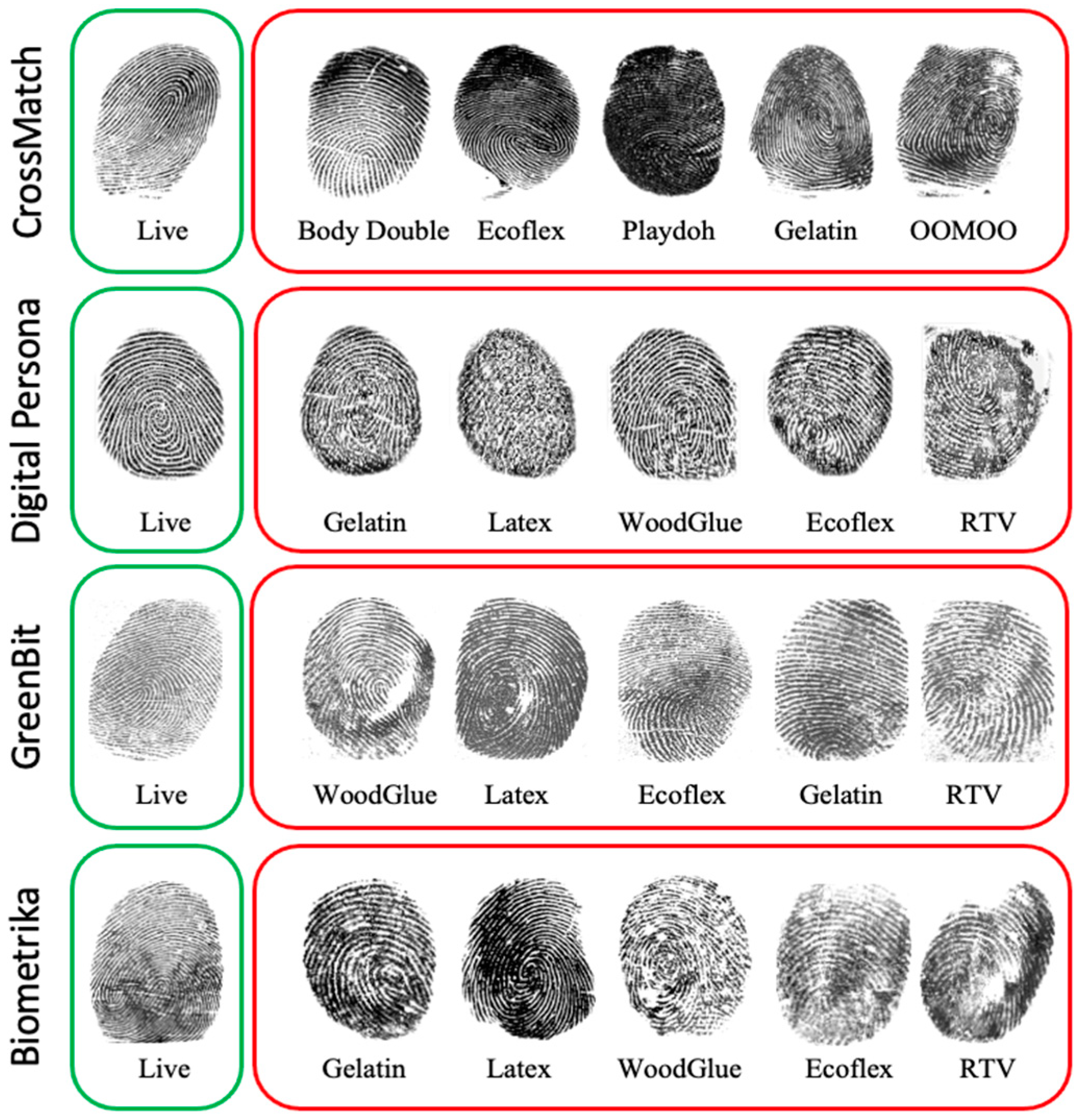
3.1. Dataset Description
3.2. Experiment Setup and Performance Metrics
- Accuracy: rate of correctly classified live and fake fingerprints.
- Average classification error (ACE):
4. Results
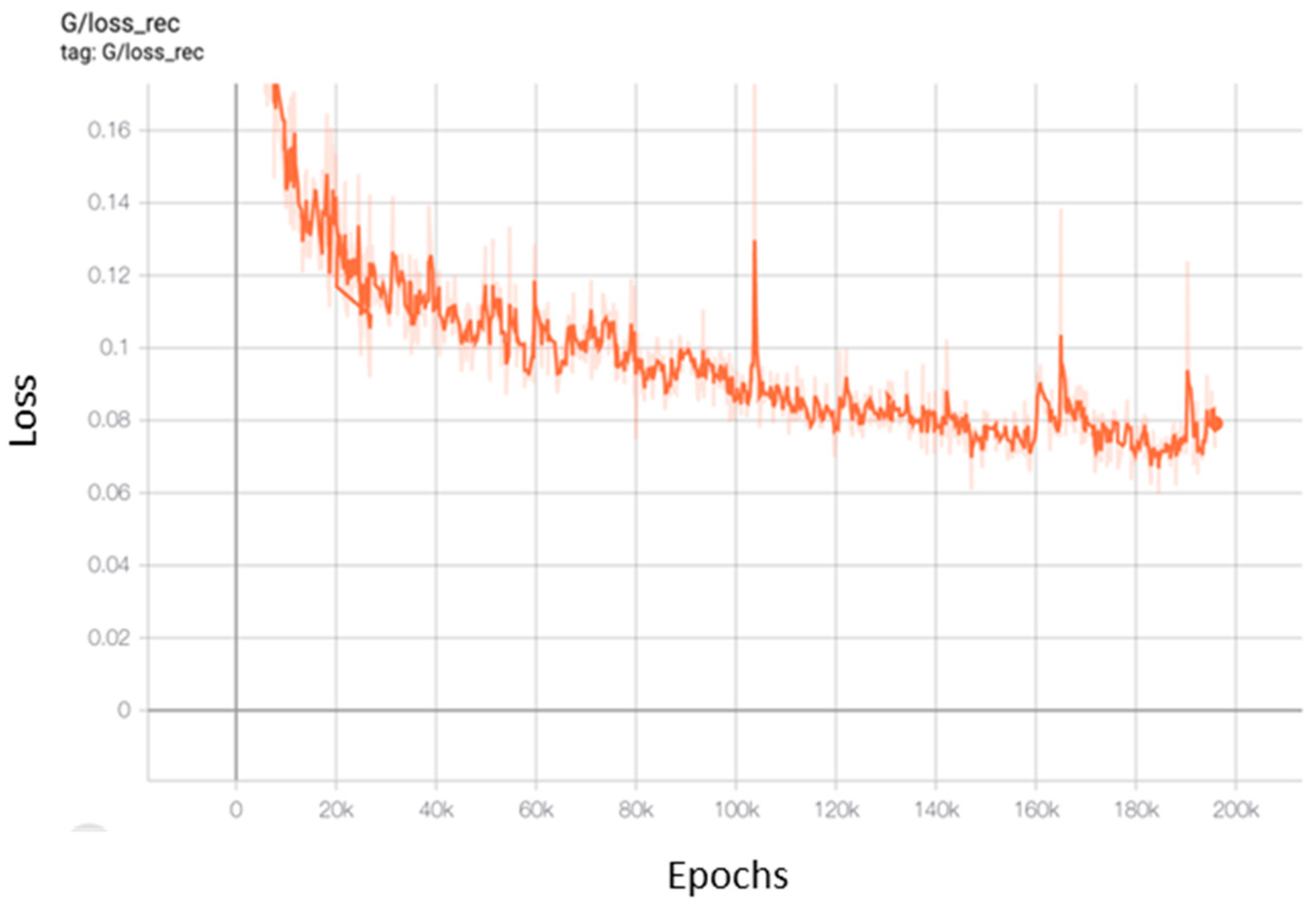
4.1. Multidomain Translation
4.2. Classification
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mordini, E.; Tzovaras, D. (Eds.) Second Generation Biometrics: The Ethical, Legal and Social Context; The International Library of Ethics, Law and Technology; Springer Science & Business Media: Berlin, Germany, 2012; ISBN 978-94-007-3891-1. [Google Scholar]
- Chugh, T.; Cao, K.; Jain, A.K. Fingerprint spoof detection using minutiae-based local patches. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 581–589. [Google Scholar]
- International Standards Organization. ISO/IEC 30107-1:2016. Information Technology—Biometric Presentation Attack Detection—Part 1: Framework; International Organization for Standardization: Geneva, Switzerland, 2016. [Google Scholar]
- Zwiesele, A.; Munde, A.; Busch, C.; Daum, H. BioIS study. Comparative study of biometric identification systems. In Proceedings of the IEEE 34th Annual 2000 International Carnahan Conference on Security Technology (Cat. No.00CH37083), Ottawa, ON, Canada, 23–25 October 2000. [Google Scholar] [CrossRef]
- Matsumoto, T.; Matsumoto, H.; Yamada, K.; Hoshino, S. Impact of artificial “gummy” fingers on fingerprint systems. In Proceedings of the Optical Security and Counterfeit Deterrence Techniques IV, San Jose, CA, USA, 19–25 January 2002; International Society for Optics and Photonics: Bellingham, WA, USA, 2002; Volume 4677, pp. 275–289. [Google Scholar]
- Schuckers, S. Presentations and attacks, and spoofs, oh my. Image Vis. Comput. 2016, 55, 26–30. [Google Scholar] [CrossRef] [Green Version]
- Engelsma, J.J.; Cao, K.; Jain, A.K. RaspiReader: An Open Source Fingerprint Reader Facilitating Spoof Detection. arXiv 2017, arXiv:1708.07887. [Google Scholar]
- Drahanský, M.; Dolezel, M.; Vana, J.; Brezinova, E.; Yim, J.; Shim, K. New Optical Methods for Liveness Detection on Fingers. BioMed Res. Int. 2013, 2013, 197925. [Google Scholar] [CrossRef] [PubMed]
- Hengfoss, C.; Kulcke, A.; Mull, G.; Edler, C.; Püschel, K.; Jopp, E. Dynamic liveness and forgeries detection of the finger surface on the basis of spectroscopy in the 400-1650 nm region. Forensic Sci. Int. 2011, 212, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Gomez-Barrero, M.; Kolberg, J.; Busch, C. Towards Fingerprint Presentation Attack Detection Based on Short Wave Infrared Imaging and Spectral Signatures. In Proceedings of the Norwegian Information Security Conference (NISK), Bergen, Norway, 18–20 September 2018. [Google Scholar]
- Zhang, Y.; Shi, D.; Zhan, X.; Cao, D.; Zhu, K.; Li, Z. Slim-ResCNN: A Deep Residual Convolutional Neural Network for Fingerprint Liveness Detection. IEEE Access 2019, 7, 91476–91487. [Google Scholar] [CrossRef]
- Ghiani, L.; Marcialis, G.L.; Roli, F. Fingerprint liveness detection by local phase quantization. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan,, 11–15 November 2012; pp. 537–540. [Google Scholar]
- Nguyen, T.H.B.; Park, E.; Cui, X.; Nguyen, V.H.; Kim, H. fPADnet: Small and Efficient Convolutional Neural Network for Presentation Attack Detection. Sensors 2018, 18, 2532. [Google Scholar] [CrossRef] [Green Version]
- Kho, J.B.; Lee, W.; Choi, H.; Kim, J. An incremental learning method for spoof fingerprint detection. Expert Syst. Appl. 2019, 116, 52–64. [Google Scholar] [CrossRef]
- Kim, H.; Cui, X.; Kim, M.-G.; Nguyen, T.H.B. Fingerprint Generation and Presentation Attack Detection using Deep Neural Networks. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 30 March 2019; pp. 375–378. [Google Scholar]
- Tolosana, R.; Gomez-Barrero, M.; Busch, C.; Ortega-Garcia, J. Biometric Presentation Attack Detection: Beyond the Visible Spectrum. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1261–1275. [Google Scholar] [CrossRef] [Green Version]
- Jomaa, R.M.; Mathkour, H.; Bazi, Y.; Islam, M.S. End-to-End Deep Learning Fusion of Fingerprint and Electrocardiogram Signals for Presentation Attack Detection. Sensors 2020, 20, 2085. [Google Scholar] [CrossRef] [Green Version]
- Rattani, A.; Scheirer, W.J.; Ross, A. Open Set Fingerprint Spoof Detection Across Novel Fabrication Materials. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2447–2460. [Google Scholar] [CrossRef]
- Ding, Y.; Ross, A. An ensemble of one-class SVMs for fingerprint spoof detection across different fabrication materials. In Proceedings of the 2016 IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, United Arab Emirates, 4–7 December 2016; pp. 1–6. [Google Scholar]
- Nogueira, R.F.; de Alencar Lotufo, R.; Campos Machado, R. Fingerprint Liveness Detection Using Convolutional Neural Networks. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1206–1213. [Google Scholar] [CrossRef]
- Chugh, T.; Cao, K.; Jain, A.K. Fingerprint Spoof Buster: Use of Minutiae-Centered Patches. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2190–2202. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, S.; Zhan, X.; Li, Z.; Gao, M.; Gao, C. FLDNet: Light Dense CNN for Fingerprint Liveness Detection. IEEE Access 2020, 8, 84141–84152. [Google Scholar] [CrossRef]
- González-Soler, L.J.; Gomez-Barrero, M.; Chang, L.; Pérez-Suárez, A.; Busch, C. Fingerprint Presentation Attack Detection Based on Local Features Encoding for Unknown Attacks. arXiv 2019, arXiv:1908.10163. [Google Scholar]
- Orrù, G.; Casula, R.; Tuveri, P.; Bazzoni, C.; Dessalvi, G.; Micheletto, M.; Ghiani, L.; Marcialis, G.L. LivDet in Action—Fingerprint Liveness Detection Competition 2019. arXiv 2019, arXiv:1905.00639. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Wang, Z.; She, Q.; Ward, T.E. Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy. arXiv 2020, arXiv:1906.01529. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. arXiv 2018, arXiv:1611.07004. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2020, arXiv:1703.10593. [Google Scholar]
- Gajawada, R.; Popli, A.; Chugh, T.; Namboodiri, A.; Jain, A.K. Universal Material Translator: Towards Spoof Fingerprint Generalization. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–8. [Google Scholar]
- Chugh, T.; Jain, A.K. Fingerprint Spoof Generalization. arXiv 2019, arXiv:1912.02710. [Google Scholar]
- Sandouka, S.B.; Bazi, Y.; Alajlan, N. Transformers and Generative Adversarial Networks for Liveness Detection in Multitarget Fingerprint Sensors. Sensors 2021, 21, 699. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. arXiv 2018, arXiv:1711.09020. [Google Scholar]
- Mura, V.; Ghiani, L.; Marcialis, G.L.; Roli, F.; Yambay, D.A.; Schuckers, S.A. LivDet 2015 fingerprint liveness detection competition 2015. In Proceedings of the 2015 IEEE 7th International Conference on Biometrics Theory, Applications and Systems (BTAS), Arlington, VA, USA, 8–11 September 2015; pp. 1–6. [Google Scholar]
- International Organization for Standardization. Information Technology—Biometric Presentation Attack Detection—Part 3: Testing and Reporting; International Organization for Standardization: Geneva, Switzerland, 2017. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Parameters |
|---|---|
| EfficientNetV2-S | 24 M |
| EfficientNetV2-M | 55 M |
| EfficientNetV2-L | 120 M |
| EfficientNetV2-B0 | 7.1 M |
| EfficientNetV2-B1 | 8.1 M |
| EfficientNetV2-B2 | 10.1 M |
| EfficientNetV2-B3 | 14.4 M |
| Sensor | Image Size (px) | Resolution (dpi) | Material | Number of Training (Live/Spoof) | Number of Testing (Live/Spoof) |
|---|---|---|---|---|---|
| GreenBit | 500 × 500 | 500 | Ecoflex, gelatin, latex, wood glue, liquid Ecoflex *, OOMOO *, and RTV * | 1000/1000 | 1000/1500 |
| Biometrika | 1000 × 1000 | 1000 | 1000/1000 | 1000/1500 | |
| Digital Persona | 252 × 324 | 500 | 1000/1000 | 1000/1500 | |
| CrossMatch | 640 × 480 | 500 | Playdoh, Body Double, Ecoflex, OOMOO *, and Gelatin * | 1500/1500 | 1500/1448 |
| Sensor in Testing | Biometrika | Digital Persona | CrossMatch | ||||
|---|---|---|---|---|---|---|---|
| Algorithm | Acc | ACE | Acc | ACE | Acc | ACE | |
| Without Adaptation | 83.68 | 20.20 | 66.60 | 41.75 | 63.97 | 35.47 | |
| Sandouka et al. [31] | 91.20 | 10.20 | 81.20 | 23.21 | 76.96 | 23.06 | |
| Proposed Method | 90.52 | 11.38 | 83.84 | 19.43 | 77.30 | 22.63 | |
| Sensor in Testing | Biometrika | Digital Persona | CrossMatch | ||||
|---|---|---|---|---|---|---|---|
| Algorithm | Acc | ACE | Acc | ACE | Acc | ACE | |
| Without Adaptation | 80.12 | 16.76 | 87.28 | 12.33 | 57.86 | 42.81 | |
| Sandouka et al. [31] | 89.52 | 9.81 | 86.72 | 15.30 | 69.77 | 30.62 | |
| Proposed Method | 89.68 | 8.75 | 87.52 | 14.00 | 69.84 | 30.60 | |
| Sensor in Testing | Biometrika | Digital Persona | CrossMatch | ||||
|---|---|---|---|---|---|---|---|
| Algorithm | Acc | ACE | Acc | ACE | Acc | ACE | |
| Without Adaptation | 52.40 | 39.78 | 70.36 | 25.13 | 60.31 | 40.36 | |
| Sandouka et al. [31] | 85.36 | 13.05 | 84.96 | 14.28 | 69.02 | 31.36 | |
| Proposed Method | 81.12 | 16.15 | 85.36 | 14.21 | 75.40 | 24.79 | |
| Sensor in Testing | Biometrika | Digital Persona | CrossMatch | ||||
|---|---|---|---|---|---|---|---|
| Algorithm | Acc | ACE | Acc | ACE | Acc | ACE | |
| Without Adaptation | 70.76 | 26.90 | 70.04 | 29.08 | 50.32 | 44.86 | |
| Sandouka et al. [31] | 80.04 | 17.43 | 76.24 | 22.61 | 60.70 | 35.51 | |
| Proposed Method | 84.44 | 13.90 | 78.04 | 18.40 | 62.31 | 30.25 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sandouka, S.B.; Bazi, Y.; Alhichri, H.; Alajlan, N. Unified Generative Adversarial Networks for Multidomain Fingerprint Presentation Attack Detection. Entropy 2021, 23, 1089. https://doi.org/10.3390/e23081089
Sandouka SB, Bazi Y, Alhichri H, Alajlan N. Unified Generative Adversarial Networks for Multidomain Fingerprint Presentation Attack Detection. Entropy. 2021; 23(8):1089. https://doi.org/10.3390/e23081089
Chicago/Turabian StyleSandouka, Soha B., Yakoub Bazi, Haikel Alhichri, and Naif Alajlan. 2021. "Unified Generative Adversarial Networks for Multidomain Fingerprint Presentation Attack Detection" Entropy 23, no. 8: 1089. https://doi.org/10.3390/e23081089
APA StyleSandouka, S. B., Bazi, Y., Alhichri, H., & Alajlan, N. (2021). Unified Generative Adversarial Networks for Multidomain Fingerprint Presentation Attack Detection. Entropy, 23(8), 1089. https://doi.org/10.3390/e23081089