
An Improved Chinese String Comparator for Bloom Filter Based Privacy-Preserving Record Linkage


Abstract
:1. Introduction
2. Related Work
3. Methods
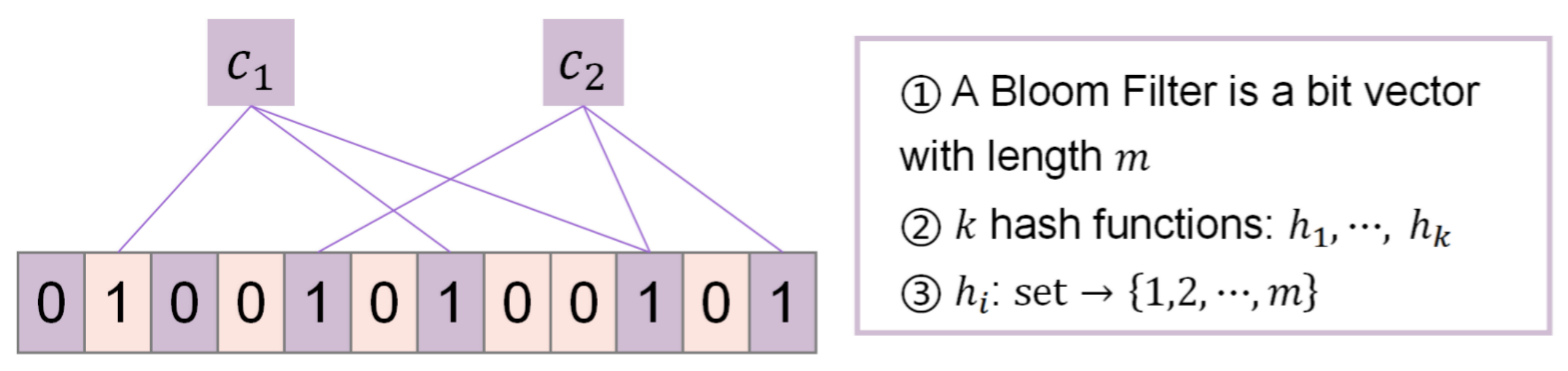
3.1. Bloom Filter
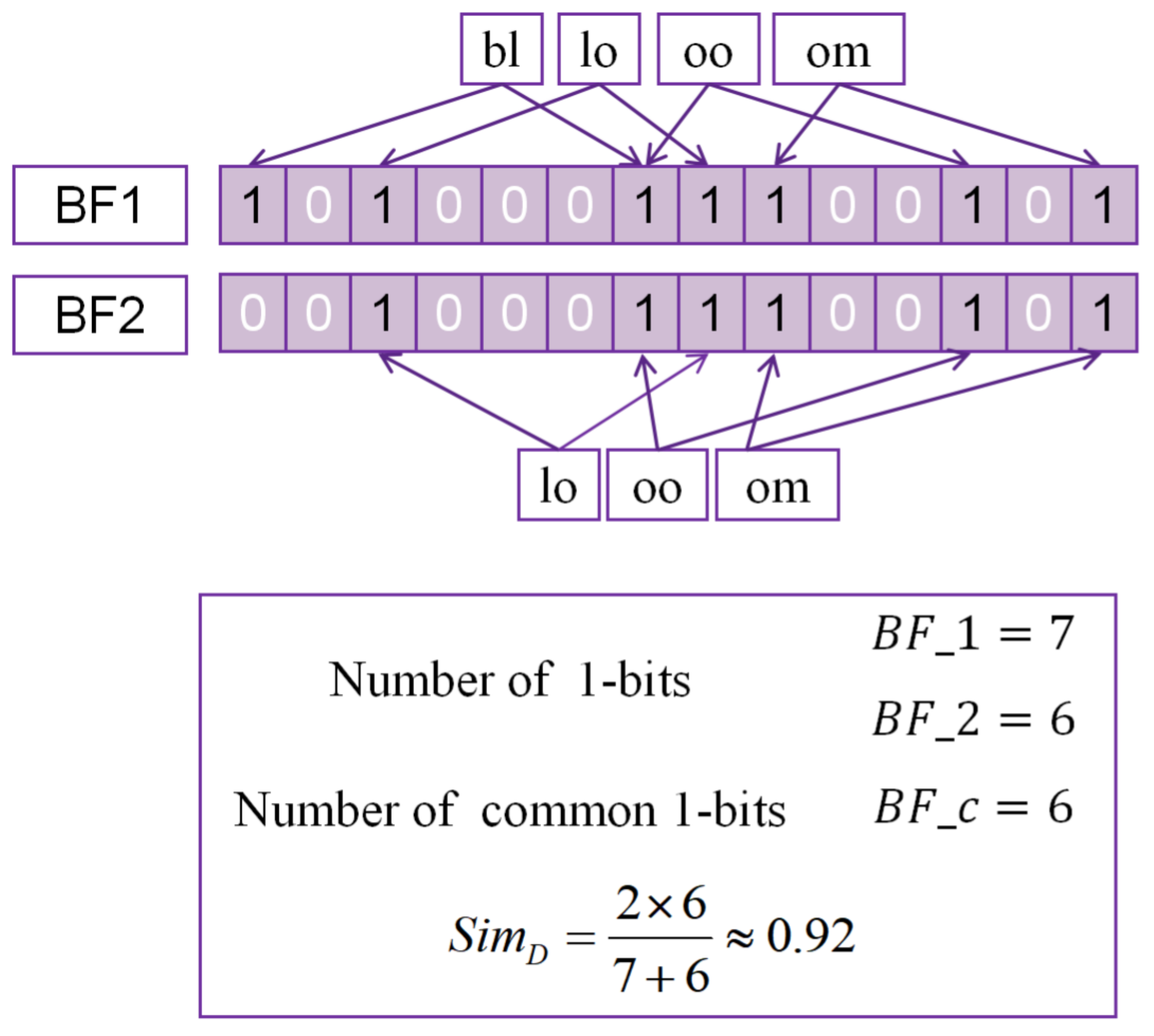
3.2. Dice Coefficient
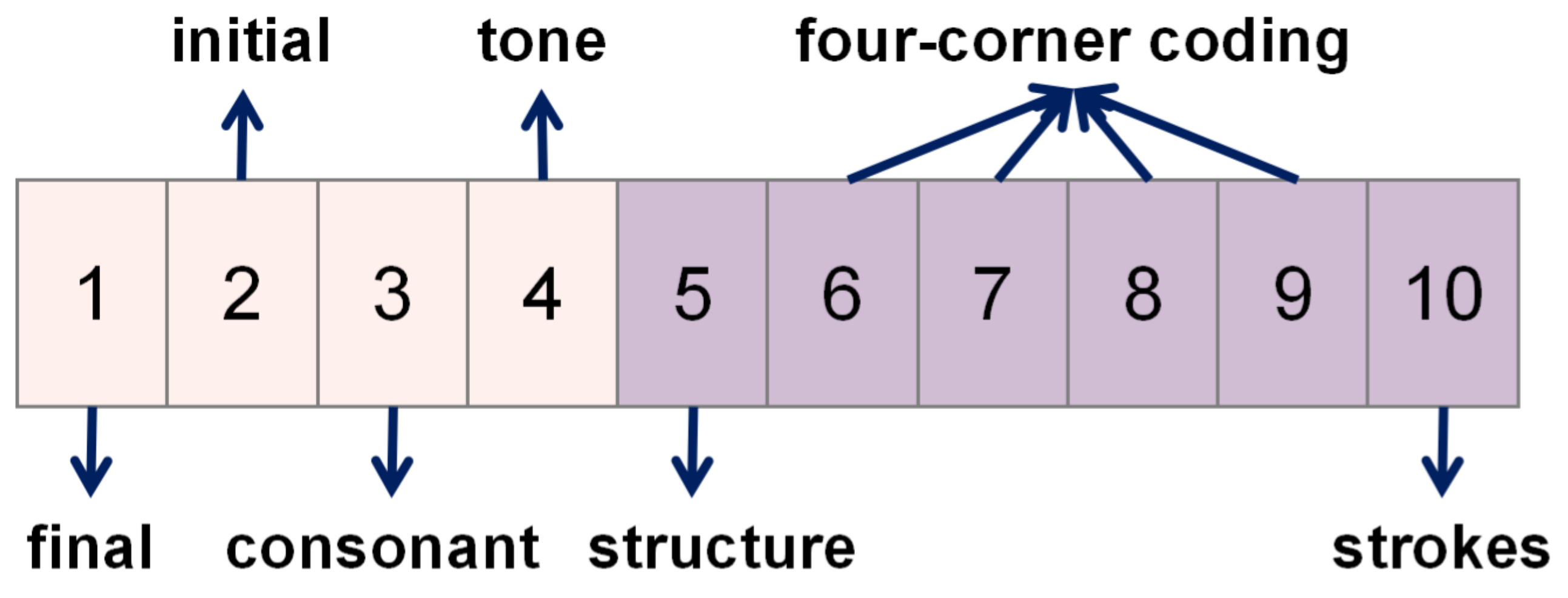
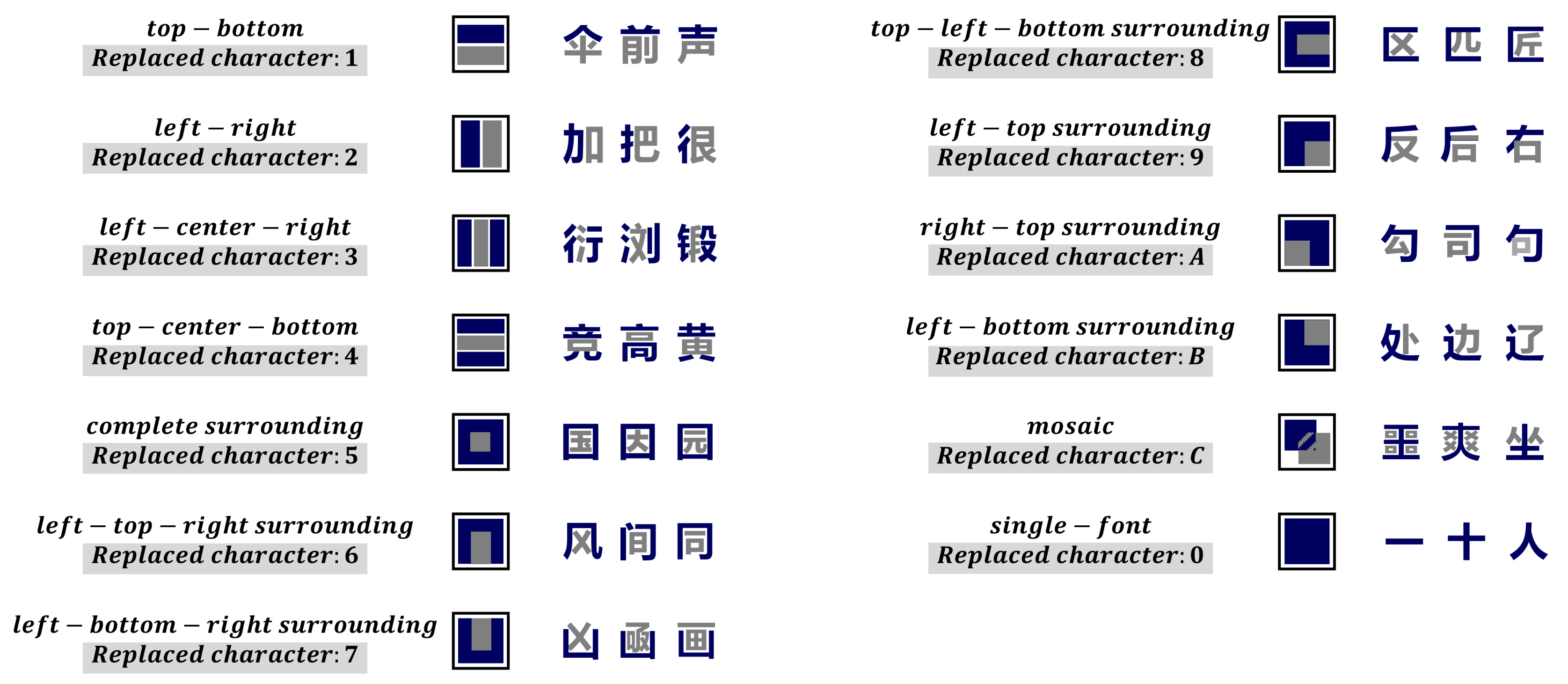
3.3. SoundShape Code
3.4. Proposed Method for Similarity Calculation
3.5. Probabilistic Record Linkage Proposed by Winkler
4. Experiments
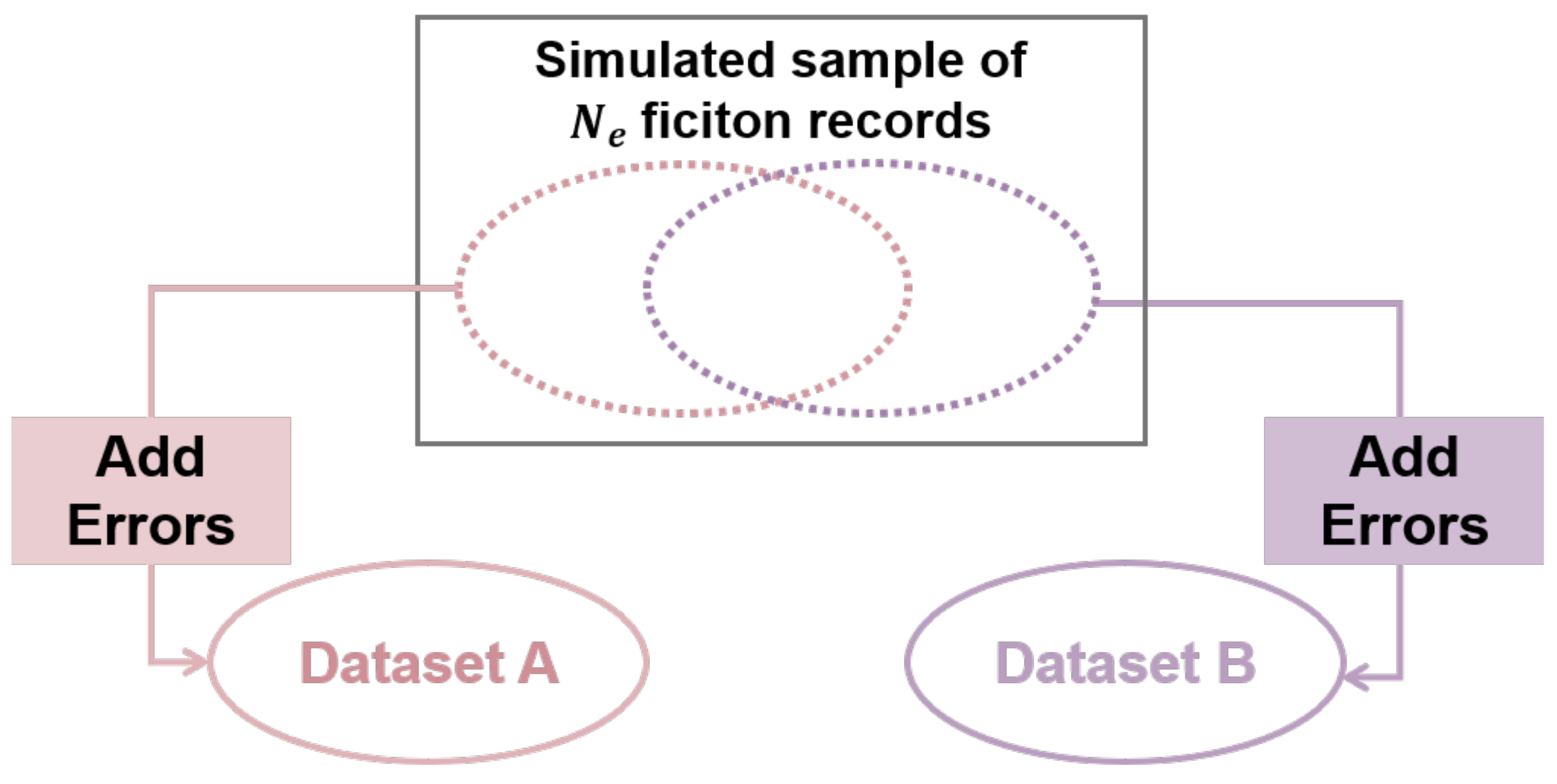
4.1. Dataset Construction
- <Name> 蔡宇 (Cai Yu) <Name>
- <Address> 山西省运城地区永济市 (Yongji, Yuncheng, Shanxi) <Address>
- <Sex> 女 (female) <Sex>
- <Birthdate> 19970621 <Birthdate>
- <ID> 2019308110080 <ID>
- SubstitutionIn the dataset, substitution errors often occur due to handwriting errors, scanning errors, oral transmission and other problems. We divide the error into the phonetic error and spelling error. For example: (1) characters with the same pronunciation but different shapes: “张” (zhang) and “章” (zhang); (2) Similar shapes: “闪” (shan) and “问” (wen). We use the Chinese homophone lexicon and Chinese type near lexicon to randomly replace the characters in dataset B.
- <Name> 蔡雨 (Cai Yu) <Name>
- <Address> 山西省运城地区永济市 (Yongji, Yuncheng, Shanxi) <Address>
- <Sex> 女 (female) <Sex>
- <Birthdate> 19970621 <Birthdate>
- <ID> 2019308110080 <ID>
- <Name> 蔡宁 (Cai Ning) <Name>
- <Address> 山西省运城地区永济市 (Yongji, Yuncheng, Shanxi) <Address>
- <Sex> 女 (female) <Sex>
- <Birthdate> 19970621 <Birthdate>
- <ID> 2019308110080 <ID>
- 2.
- DenormalizationIt is heterogeneous for information in real datasets because different organizations have their own requirements for data quality. Thus, the data collected, such as addresses may not be uniform. As a result, we produce some nonuniform information in the synthetic dataset. For example, we randomly delete some information in the address field (such as province, city or region), and the city in the address in data is omitted:
- <Name> 蔡宇 (Cai Yu) <Name>
- <Address> 山西省运城地区 (Yuncheng, Shanxi) <Address>
- <Sex> 女 (female) <Sex>
- <Birthdate> 19970621 <Birthdate>
- <ID> 2019308110080 <ID>


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment Number | The Value of | Experiment Number | The Value of |
|---|---|---|---|
| 1 | 0.72 | 6 | 0.57 |
| 2 | 0.74 | 7 | 0.29 |
| 3 | 0.56 | 8 | 0.52 |
| 4 | 0.56 | 9 | 0.74 |
| 5 | 1.00 | 10 | 0.42 |
4.2. Experimental Design
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Roos, L.L.; Walld, R.; Wajda, A.; Hartford, B.K. Record linkage strategies, outpatient procedures, and administrative data. Med. Care 1996, 34, 570–582. [Google Scholar] [CrossRef] [PubMed]
- Randall, S.M.; Ferrante, A.M.; Boyd, J.H.; Bauer, J.K.; Semmens, J.B. Privacy-preserving record linkage on large real world datasets. J. Biomed. Inform. 2014, 50, 205–212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bonomi, L.; Xiong, L.; Chen, R.; Fung, B.C.M. Privacy Preserving Record Linkage via grams Projections. arXiv 2012, arXiv:1208.2773. [Google Scholar]
- Inan, A.; Kantarcioglu, M.; Ghinita, G.; Bertino, E. Private Record Matching Using Differential Privacy. In Proceedings of the 13th International Conference on Extending Database Technology, Lausanne, Switzerland, 22–26 March 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 123–134. [Google Scholar] [CrossRef]
- Kuzu, M.; Kantarcioglu, M.; Inan, A.; Bertino, E.; Durham, E.; Malin, B. Efficient Privacy-Aware Record Integration. In Proceedings of the 16th International Conference on Extending Database Technology, Genoa, Italy, 18–22 March 2013; pp. 167–178. [Google Scholar] [CrossRef] [Green Version]
- Vatsalan, D.; Sehili, Z.; Christen, P.; Rahm, E. Privacy-Preserving Record Linkage for Big Data: Current Approaches and Research Challenges. In Handbook of Big Data Technologies; Springer International Publishing: Cham, Switzerland, 2017; pp. 851–895. [Google Scholar] [CrossRef]
- Smith, D. Secure pseudonymisation for privacy-preserving probabilistic record linkage. J. Inf. Secur. Appl. 2017, 34, 271–279. [Google Scholar] [CrossRef] [Green Version]
- Shekokar, N.; Shelake, V.M. An Enhanced Approach for Privacy Preserving Record Linkage during Data Integration. In Proceedings of the 2020 6th International Conference on Information Management (ICIM), London, UK, 27–29 March 2020; pp. 152–156. [Google Scholar] [CrossRef]
- Essex, A. Secure Approximate String Matching for Privacy-Preserving Record Linkage. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2623–2632. [Google Scholar] [CrossRef]
- Schnell, R.; Bachteler, T.; Reiher, J. Privacy-preserving record linkage using Bloom filters. BMC Med Inform. Decis. Mak. 2009, 9, 41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christen, P.; Vidanage, A.; Ranbaduge, T.; Schnell, R. Pattern-Mining Based Cryptanalysis of Bloom Filters for Privacy-Preserving Record Linkage. In Advances in Knowledge Discovery and Data Mining; Phung, D., Tseng, V.S., Webb, G.I., Ho, B., Ganji, M., Rashidi, L., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 530–542. [Google Scholar]
- Ranbaduge, T.; Schnell, R. Securing Bloom Filters for Privacy-Preserving Record Linkage; Association for Computing Machinery: New York, NY, USA, 2020; pp. 2185–2188. [Google Scholar]
- Burkhardt, S.; Kärkkäinen, J. Better Filtering with Gapped q-Grams. In Combinatorial Pattern Matching; Lecture Notes in Computer Science; Landau, G.M., Amir, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 73–85. [Google Scholar] [CrossRef]
- Xu, S.; Zheng, M.; Li, X. String Comparators for Chinese-Characters-Based Record Linkages. IEEE Access 2021, 9, 3735–3743. [Google Scholar] [CrossRef]
- Durham, E.A.; Kantarcioglu, M.; Xue, Y.; Toth, C.; Kuzu, M.; Malin, B. Composite Bloom Filters for Secure Record Linkage. IEEE Trans. Knowl. Data Eng. 2014, 26, 2956–2968. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Niedermeyer, F.; Steinmetzer, S.; Kroll, M.; Schnell, R. Cryptanalysis of Basic Bloom Filters Used for Privacy Preserving Record Linkage. J. Priv. Confidentiality 2014, 6, 59–79. [Google Scholar]
- Zhang, B. Phone-shape combination, location code—A Chinese character coding scheme using stroke order. Power Syst. Autom. 1980, 4, 37–38. (In Chinese) [Google Scholar]
- Chen, Q.W.; Hao, Y.L.; Qiu, S.Y. Study on Stroke Coding Input Method of Chinese Characaters. J. Shantou Univ. Sci. Ed. 2007, 26, 255–257. [Google Scholar]
- Chen, Q.W. Study on Pinyin-Stroke Coding Input Method of Chinese Characters. Microcomput. Inf. 2010, 26, 252–257. [Google Scholar]
- Chen, Q.W.; Yu, W. Chinese Character Inputting Method of New Phonogram Code. Chinese Patent No. CN201210018390.6, 17 February 2016. (In Chinese). [Google Scholar]
- Du, B. Method of Inputting CHINESE Characters Using the Holo-Information Code for Chinese Characters and Keyboard Therefor. U.S. Patent No. 5,475,767, 12 December 1995. [Google Scholar]
- Wang, H.; Zhang, Y.; Yang, L.; Wang, C. Chinese Text Error Correction Suggestion Generation Based on SoundShape Code; Springer International Publishing: Cham, Switzerland, 2020; pp. 423–432. [Google Scholar]
- Christen, P.; Ranbaduge, T.; Vatsalan, D.; Schnell, R. Precise and Fast Cryptanalysis for Bloom Filter Based Privacy-Preserving Record Linkage. IEEE Trans. Knowl. Data Eng. 2019, 31, 2164–2177. [Google Scholar] [CrossRef]
- Mitzenmacher, M. Compressed Bloom filters. IEEE/ACM Trans. Netw. 2002, 10, 604–612. [Google Scholar] [CrossRef]
- Chen, M.; Du, Q.; Shao, Y.; Long, H. Chinese characters similarity comparison algorithm based on phonetic code and shape code. Inf. Technol. 2018, 11, 73–75. [Google Scholar]
- Winkler, W.E. Improved Decision Rules in The Fellegi-Sunter Model of Record Linkage. In Proceedings of the Section on Survey Research Methods; American Statistical Association: Alexandria, VA, USA, 1993; pp. 274–279. [Google Scholar]
- Fellegi, I.P.; Sunter, A.B. A Theory for Record Linkage. J. Am. Stat. Assoc. 1969, 64, 1183–1210. [Google Scholar] [CrossRef]
- Li, X.; Guttmann, A.; Cipière, S.; Maigne, L.; Demongeot, J.; Boire, J.Y.; Ouchchane, L. Implementation of an extended Fellegi-Sunter probabilistic record linkage method using the Jaro-Winkler string comparator. In Proceedings of the IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI), Valencia, Spain, 1–4 June 2014; pp. 375–379. [Google Scholar] [CrossRef]
- Hand, D.; Christen, P. A note on using the F-measure for evaluating record linkage algorithms. Stat. Comput. 2018, 28, 539–547. [Google Scholar] [CrossRef] [Green Version]





| FINAL | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| a | – | 1 | o | – | 2 | e | – | 3 | i | – | 4 |
| u | – | 5 | v | – | 6 | ai | – | 7 | ei | – | 7 |
| ui | – | 8 | ao | – | 9 | ou | – | A | iu | – | B |
| ie | – | C | ve | – | D | er | – | E | an | – | F |
| en | – | G | in | – | H | un | – | I | ven | – | J |
| ang | – | F | eng | – | I | ing | – | H | ong | – | K |
| INITIAL | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| b | – | 1 | p | – | 2 | m | – | 3 | f | – | 4 |
| d | – | 5 | t | – | 6 | n | – | 7 | l | – | 7 |
| g | – | 8 | k | – | 9 | h | – | A | j | – | B |
| q | – | C | x | – | D | zh | – | E | ch | – | F |
| sh | – | G | r | – | H | z | – | E | c | – | F |
| s | – | G | y | – | I | w | – | J | |||
| Character | SoundShape Code | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 中 | K | E | 0 | 1 | C | 5 | 0 | 0 | 0 | 4 |
| 国 | 2 | 8 | 5 | 2 | 5 | 6 | 0 | 1 | 0 | 8 |
| 北 | 7 | 1 | 0 | 3 | 1 | 1 | 2 | 1 | 1 | 5 |
| 京 | H | B | 0 | 1 | 4 | 0 | 0 | 9 | 0 | 8 |
| Sum | B | Y | 5 | 7 | M | C | 2 | B | 1 | P |
| Character | Digit | Position | Calculation | Result |
|---|---|---|---|---|
| 中 | K | 1 | “K” | 20 |
| 国 | 2 | 2 | 4 | |
| 北 | 7 | 3 | 21 | |
| 京 | H | 4 | “H” | 68 |
| Sum | 113 |
| Character | SoundShape Code | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 中 | K | E | 0 | 1 | C | 5 | 0 | 0 | 0 | 4 |
| 国 | 2 | 8 | 5 | 2 | 5 | 6 | 0 | 1 | 0 | 8 |
| 北 | 7 | 1 | 0 | 3 | 1 | 1 | 2 | 1 | 1 | 5 |
| 京 | H | B | 0 | 1 | 4 | 0 | 0 | 9 | 0 | 8 |
| Sum | 8 | 7 | A | I | 6 | K | 6 | 6 | 3 | W |
| Character | SSC | Dice Similarity |
|---|---|---|
| 陈欣晨(Chen Xinchen) | EV03WK06YL | 0.736 |
| 陈欣辰(Chen Xinchen) | EV034L16YH | |
| 李住(Li Zhu) | 9S0GBQ0Y17 | 0.526 |
| 李往(Li Wang) | JX5FBQ0Y18 |
| Character | SSC | Dice Similarity of Sound Codes | Dice Similarity of Shape Codes | Results Similarity |
|---|---|---|---|---|
| 陈欣晨 (Chen Xinchen) | EV03WK06YL | 1.000 | 0.200 | 0.600 |
| 陈欣辰 (Chen Xinchen) | EV034L16YH | |||
| 李住 (Li Zhu) | 9S0GBQ0Y17 | 0.000 | 0.857 | 0.428 |
| 李往 (Li Wang) | JX5FBQ0Y18 |
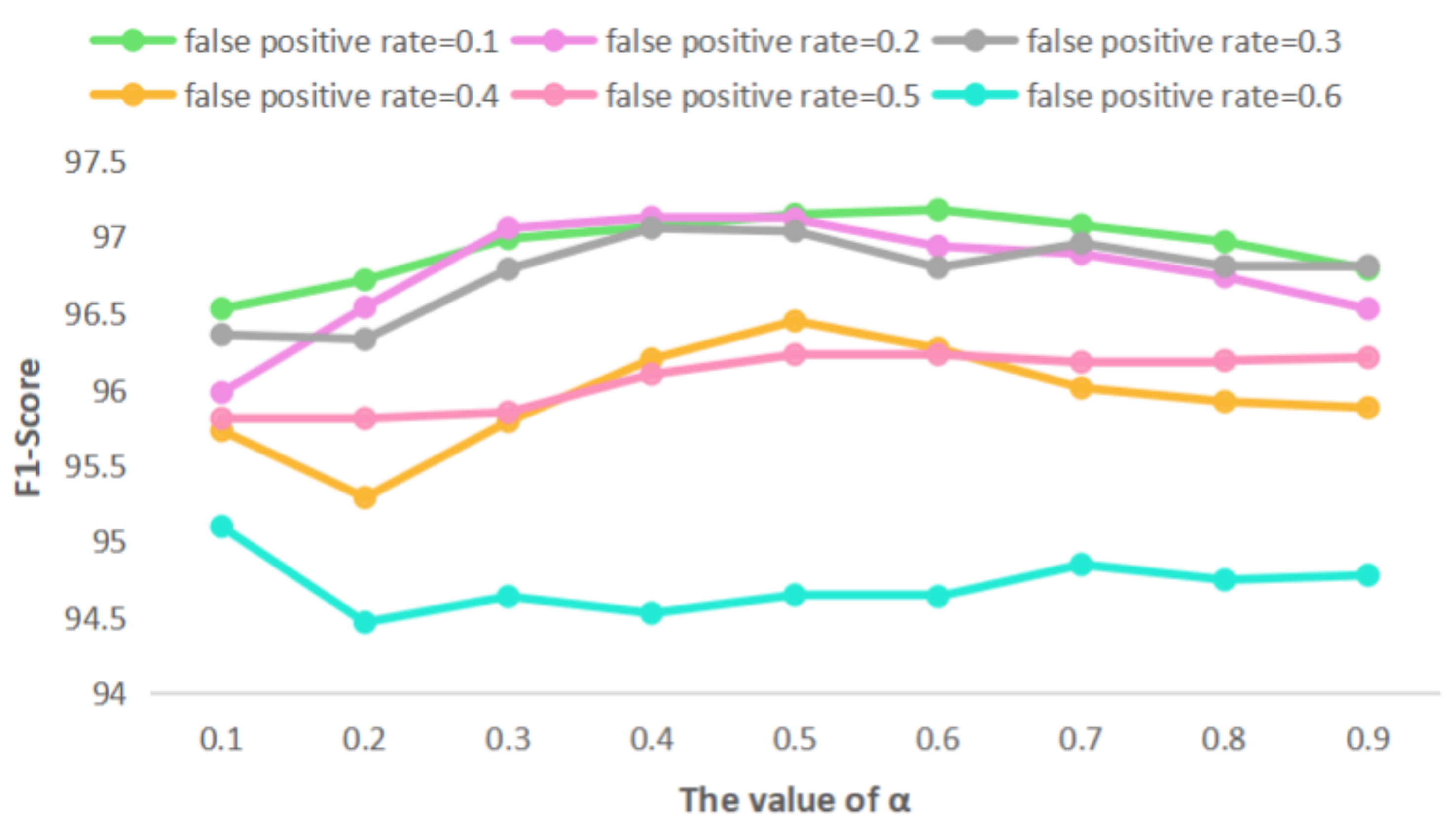
| Rate = 0.1 | Rate = 0.2 | Rate = 0.3 | Rate = 0.4 | Rate = 0.5 | Rate = 0.6 | |
|---|---|---|---|---|---|---|
| the original SSC similarity | 93.52 ± 2.33 | 93.58 ± 2.45 | 94.37 ± 2.54 | 94.79 ± 2.38 | 94.06 ± 2.12 | 94.81 ± 2.73 |
| 96.53 ± 1.39 | 95.98 ± 1.01 | 96.36 ± 1.29 | 95.73 ± 1.39 | 95.81 ± 1.73 | 95.10 ± 1.51 | |
| 96.72 ± 1.28 | 96.54 ± 1.32 | 96.33 ± 1.09 | 95.29 ± 1.08 | 95.81 ± 1.73 | 94.47 ± 1.48 | |
| 96.99 ± 1.35 | 97.06 ± 1.34 | 96.79 ± 1.19 | 95.79 ± 0.97 | 95.85 ± 1.22 | 94.64 ± 1.48 | |
| 97.07 ± 1.39 | 97.13 ± 1.37 | 97.06 ± 1.24 | 96.20 ± 0.91 | 96.10 ± 1.06 | 94.53 ± 0.62 | |
| 97.15 ± 1.42 | 97.12 ± 1.33 | 97.04 ± 1.23 | 96.45 ± 0.97 | 96.23 ± 0.94 | 94.65 ± 0.55 | |
| 97.18 ± 1.44 | 96.94 ± 1.35 | 96.80 ± 1.09 | 96.27 ± 0.83 | 96.23 ± 0.93 | 94.64 ± 0.51 | |
| 97.08 ± 1.35 | 96.89 ± 1.29 | 96.96 ± 1.19 | 96.01 ± 0.71 | 96.18 ± 0.83 | 94.85 ± 0.55 | |
| 96.97 ± 1.18 | 96.74 ± 1.06 | 96.81 ± 1.12 | 95.92 ± 0.67 | 96.19 ± 0.85 | 94.75 ± 0.49 | |
| 96.79 ± 1.04 | 96.53 ± 0.89 | 96.81 ± 1.11 | 95.88 ± 0.70 | 96.21 ± 0.82 | 94.78 ± 0.47 |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| the original SSC similarity | 93.77 | 93.29 | 93.52 |
| Proportion with | 97.16 | 96.99 | 97.07 |
| Proportion with | 97.27 | 97.04 | 97.15 |
| Proportion with | 97.32 | 97.04 | 97.18 |
| Method | Runtime (s) |
|---|---|
| the original SSC similarity | 21.67 |
| Proportion with | 13.98 |
| Proportion with | 13.29 |
| Proportion with | 13.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, S.; Qian, Y.; Zhang, R.; Wang, Y.; Li, X. An Improved Chinese String Comparator for Bloom Filter Based Privacy-Preserving Record Linkage. Entropy 2021, 23, 1091. https://doi.org/10.3390/e23081091
Sun S, Qian Y, Zhang R, Wang Y, Li X. An Improved Chinese String Comparator for Bloom Filter Based Privacy-Preserving Record Linkage. Entropy. 2021; 23(8):1091. https://doi.org/10.3390/e23081091
Chicago/Turabian StyleSun, Siqi, Yining Qian, Ruoshi Zhang, Yanqi Wang, and Xinran Li. 2021. "An Improved Chinese String Comparator for Bloom Filter Based Privacy-Preserving Record Linkage" Entropy 23, no. 8: 1091. https://doi.org/10.3390/e23081091
APA StyleSun, S., Qian, Y., Zhang, R., Wang, Y., & Li, X. (2021). An Improved Chinese String Comparator for Bloom Filter Based Privacy-Preserving Record Linkage. Entropy, 23(8), 1091. https://doi.org/10.3390/e23081091