1. Introduction
We consider the first-order autoregressive process defined by
where
are random errors with mean 0 and variance
. It is well known that the regression coefficient
characterizes the properties of the process
. When
,
is called a stationary process (see Brockwell and Davis [
1]). For example, assume that
are independent and identically distributed errors with
,
, and
, with some
. Then, the least squares (LS) estimator
of
defined by
has a normal limiting distribution:
where
(see Phillips and Magdalinos [
2]). When
,
is called a random walk process (see Dickey and Fuller [
3], Wang et al. [
4]). When
,
is called an explosive process. Let
be independent and identically distributed Gaussian errors
with
, and the initial condition
. White [
5] and Anderson [
6] showed that the LS estimator
of
has a Cauchy limiting distribution:
where
is a standard Cauchy random variable. Moreover, let
c be a constant, and
, where
. If
, then
is called a near-stationary process (see Chan and Wei [
7]). Let
be independent and identically distributed errors with
,
, and
, with some
. Phillips and Magdalinos [
2] showed that the LS estimator
of
has a normal limiting distribution:
where
. If
, then
is called a near-explosive process or mildly explosive process. Phillips and Magdalinos [
2] also showed that the LS estimator
of
has a Cauchy limiting distribution:
where
.
It is interesting to study the near-stationary process and mildly explosive process based on dependent errors. For example, Buchmann and Chan [
8] considered the near-stationary process whose errors were strongly dependent random variables; Phillips and Magdalinos [
9] and Magdalinos [
10] studied the mildly explosive process whose errors were moving average process with martingale differences; Aue and Horvàth [
11] considered the mildly explosive process based on stable errors; Oh et al. [
12] studied the mildly explosive process-based strong mixing (
-mixing) errors and obtained the Cauchy limiting distribution in (
6) for the LS estimator
. It is known that the sequence of
-mixing is a weakly dependent sequence. However, they assumed that
was geometrically
-mixing, i.e.,
for some
. Obviously, it was a very strong condition. It will be more general if
is arithmetically
-mixing, i.e.,
for some
. Thus, the aim of this paper is to weaken this mixing condition. We continue to investigate the mildly explosive process based on arithmetically
-mixing errors. Compared with Oh et al. [
12], we use different inequalities of
-mixing sequences to prove the key Lemmas 1 and 2 (see
Section 2 and
Section 6). As important applications, some simulations and real data of the NASDAQ composite index from April 2011 to April 2021 are also discussed in this paper. Next, we recall the definition of
-mixing as follows:
Let
and denote
to be the
-field generated by random variables
,
. For
, we define
Definition 1. If as , then is called a strong mixing or α-mixing sequence. If for some , then is called an arithmetically α-mixing sequence. If for some , then is called a geometrically α-mixing sequence.
The
-mixing sequence is a weakly dependent sequence and several linear and nonlinear time series models satisfy the mixing properties. For more works on
-mixing and applications of regression, we refer the reader to Hall and Heyde [
13], Györfi et al. [
14], Lin and Lu [
15], Fan and Yao [
16], Jinan et al. [
17], Escudero et al. [
18], Li et al. [
19], and the references therein. Many researchers have studied mildly explosive models. For example, Arvanitis and Magdalinos [
20] studied the mildly explosive process under the stationary conditional heteroskedasticity errors; Liu et al. [
21] investigated the mildly explosive process under the anti-persistent errors; Wang and Yu [
22] studied the explosive process without Gaussian errors; Kim et al. [
23] studied the explosive process without identically distributed errors. Furthermore, many researchers have used the mildly explosive model to study the behavior of economic growth and rational bubble problems, see Magdalinos and Phillips [
24], Phillips et al. [
25], Oh et al. [
12], Liu et al. [
21], and the references therein.
The rest of this paper is organized as follows. First, some conditions in Assumption (1) and two important Lemmas 1 and 2 are presented in
Section 2. Consequently, the Cauchy limiting distribution for LS estimator
and the confidence interval of
are obtained in
Section 2 (see Theorem 1). We also give some remarks about the existing studies of the Cauchy limiting distribution in
Section 2. As applications, some simulations on the empirical probability of the confidence interval for
and the empirical density for
and
are presented in
Section 3, which agree with the Cauchy limiting distribution in (
6). In
Section 4, the mildly explosive process is used to analyze the real data from the NASDAQ composite index from April 2011 to April 2021. It is a takeoff period of technology stocks and a faster increase in U.S. Treasury yields. Some conclusions and future research are discussed in
Section 5. Finally, the proofs of main results are presented in
Section 6. Throughout the paper, as
, let
and
respectively denote the convergence in probability and in distribution. Let
denote some positive constants not depending on
n, which may be different in various places. If
X and
Y have the same distribution, we denote it as
.
2. Results
We consider the mildly explosive process
where
for some
,
, and
. In addition,
are mean zeros of
-mixing errors. Some conditions in Assumption 1 are listed as follows:
Assumption 1. Let and for some ;
Let be a strictly stationarity sequence of arithmetically α-mixing with , where δ is defined by ;
Let for some , and , where δ is defined by ; in addition, let .
In order to prove the limiting distribution of the LS estimator
of
, the normalized sample covariance
can be approximated by the product of the stochastic sequences
Then, we have the following lemmas:
Lemma 1. Let the conditions (A1)–(A3) hold. Then, as ,where means convergence in the mean square. Lemma 2. Let the the conditions (A1)–(A3) hold. Then, as , the sequences and defined by (
8)
satisfywhere X and Y are two independent random variables with and Combining this with Lemmas 1 and 2, we have the following Cauchy limiting distribution for the LS estimator of as follows:
Theorem 1. Let the conditions of Lemmas 1 and 2 be satisfied. Then, as , we havewhere X and Y are two independent random variables defined by (
11),
and is a standard Cauchy random variable. Remark 1. Let : Let be a strictly stationarity sequence of geometrically α-mixing; Let with some , , and . Under the assumptions , , and , Oh et al. [12] considered the mildly explosive process (7) and obtained Lemmas 1 and 2 and Theorem 1, which extended Theorem 4.3 of Phillips and Magdalinos [2] based on independent errors to geometrically α-mixing errors. In order to weaken geometrically α-mixing, we use the inequalities from Doukhan and Louhichi [26] and Yang [27] to re-prove the key Lemmas 1 and 2. Thus, the mixing coefficients need to satisfy for some . For details, please the proofs of Lemmas 1 and 2 in Section 6. If positive parameter δ coming from moment condition is large, then the mixing coefficient is weak. Similarly, if positive parameter δ is small, then the mixing coefficient becomes strong. If , then is a geometrically decaying. So the condition in assumption becomes . Thus, we extend the results of Phillips and Magdalinos [2] and Oh et al. [12] to arithmetically α-mixing case. In Section 3, we give some simulations for the LS estimator in a mildly explosive process, which agree with Theorem 1. Meanwhile, the mildly explosive model is used to analyze the data of the NASDAQ composite index from April 2011 to April 2021 in Section 4. Remark 2. For some , , and , we take in (
14)
and obtainandwhere it uses the fact that . Here, means , as . Moreover, by Proposition A.1 of Phillips and Magdalinos [2], it has . Combining with , we have and (or see Oh et al. [12]). Let be the significance level. Then, as in Phillips et al. [25], (
14)
in Theorem 1 suggests that a confidence interval for can be constructed aswhere and are the lower bound and upper bound for respectively, and is the two-tailed α percentile critical value of the standard Cauchy distribution. For example, , , and . 3. Simulations
In this section, we conduct some simulations to evaluate the LS estimator
defined by (
2). The experimental data
are a realization from the following first-order autoregressive model
where
,
for some
,
, and
. In addition,
are mean zero random errors. Let the error vector
satisfy the Gaussian model such that
Here,
, and
is the covariance matrix satisfying
for some
.
is a positive symmetric matrix. Moreover, it is easy to check that the sequence
is geometrically
-mixing. For any moment of Gaussian random variable, it is finite. Combining this with Remark 1,
is
.
Firstly, we show the simulation of the empirical probability of the confidence interval (CI) for
defined by (
17). We consider the following parameter settings
The number of replications is always set at 10000 and the level of significance is 0.05. Let
be the indicator function. Applying (
17), we calculate the empirical probability of the true value
, i.e.,
where
and
are the two CI bounds of
in the
replication. The results are shown in
Table 1 and
Table 2.
From
Table 1 and
Table 2, we see that the CIs under
were relatively better than
. It may be that the volatility of
with
is relatively larger than the one with
. The CIs had good finite sample performance when
c was relatively large, and
was between 0.5 and 0.7. When
, it can be seen that the empirical probability was close to the nominal probability
.
Next, by (
15), (
16),
, and
, we give some histograms to illustrate
where
is a standard Cauchy random variable. We consider the following parameter settings
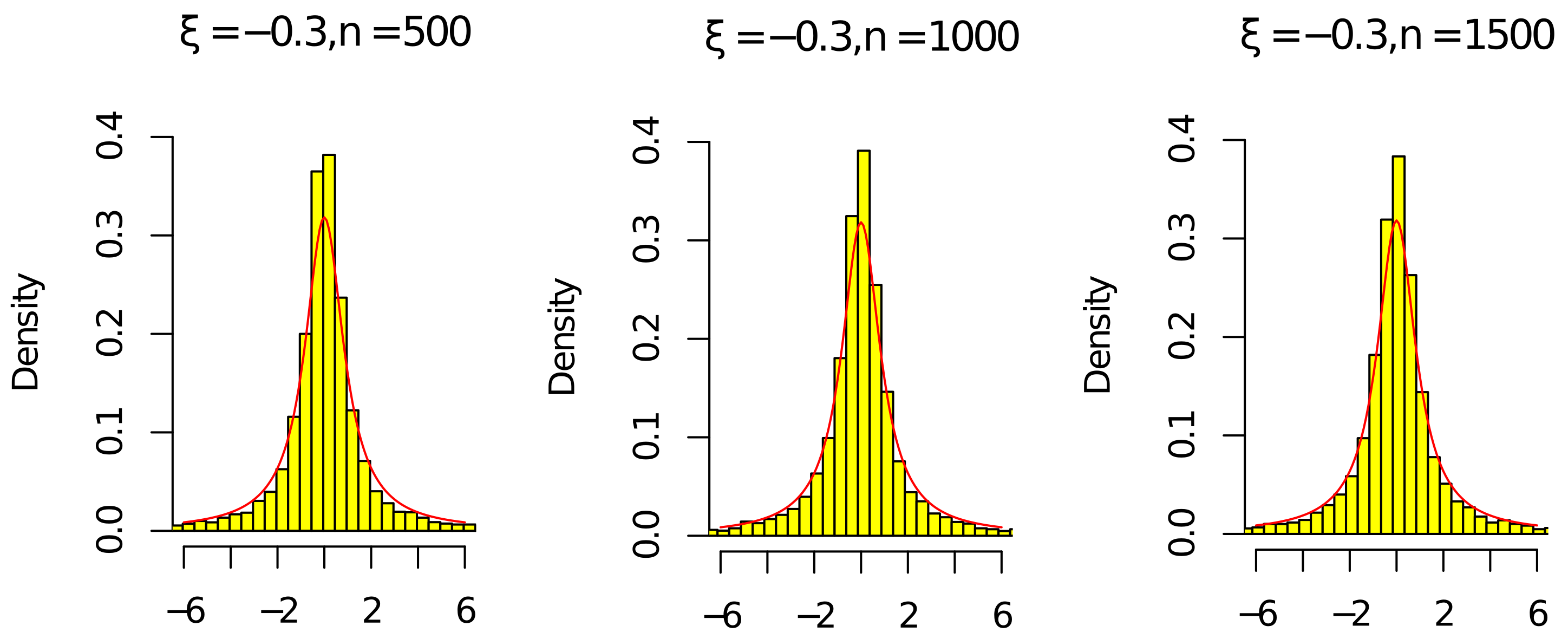
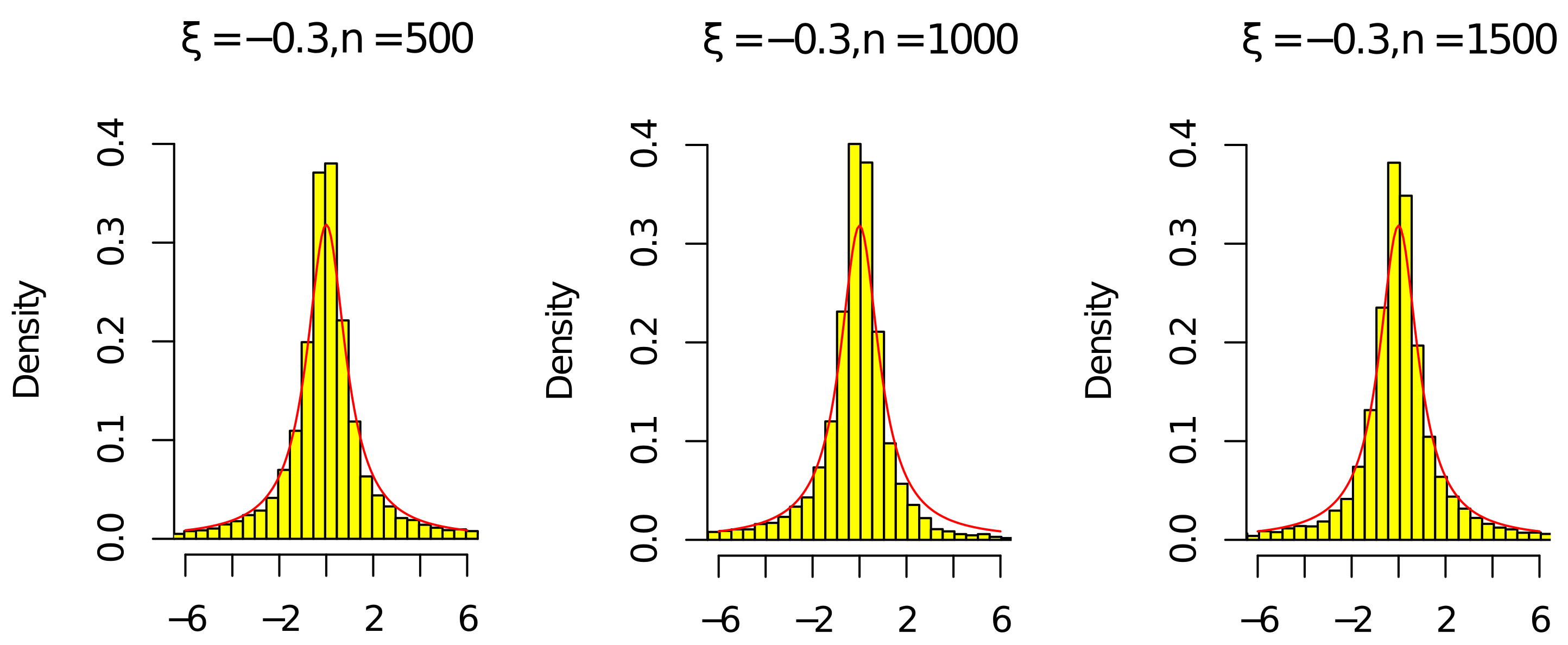
According to
Figure 1,
Figure 2,
Figure 3 and
Figure 4, the histograms
and
under
were relatively better than the ones under
(the volatility of
with
was relatively larger than the one with
). As the sample
n increased, the histograms
and
were close to the red line of the density of the standard Cauchy random variable. Thus, the results in
Figure 1,
Figure 2,
Figure 3 and
Figure 4 and
Table 1 and
Table 2 agree with (
14) in Theorem 1. Since the histograms with different
c and
were similar, we omit them here.
4. Real Data Analysis
In this section, we use the mildly explosive model (
7) and confidence interval estimation in (
17) to study the NASDAQ composite index during an inflation period. Similar to Phillips et al. [
25] and Liu et al. [
21], we consider the log-NASDAQ composite index for the period from April 2011 to April 2021, which contained 2522 observations denoted by
,
. In addition, we let
and
. The scatter plots of
are shown in
Figure 5. According to
Figure 5, the process of
was increasing. Then, we used the Augmented Dickey Fuller Test (ADF Test, see [
28]) to conduct the unit root test. The ADF test was −3.069 with Lag order 1, while the
p-value of the ADF test was 0.1257. This means that the process of
was nonstationary. Thus, the mildly explosive model
was considered to fit the process of
. We let
be the residuals of errors
,
, where
is the LS estimator of
defined by (
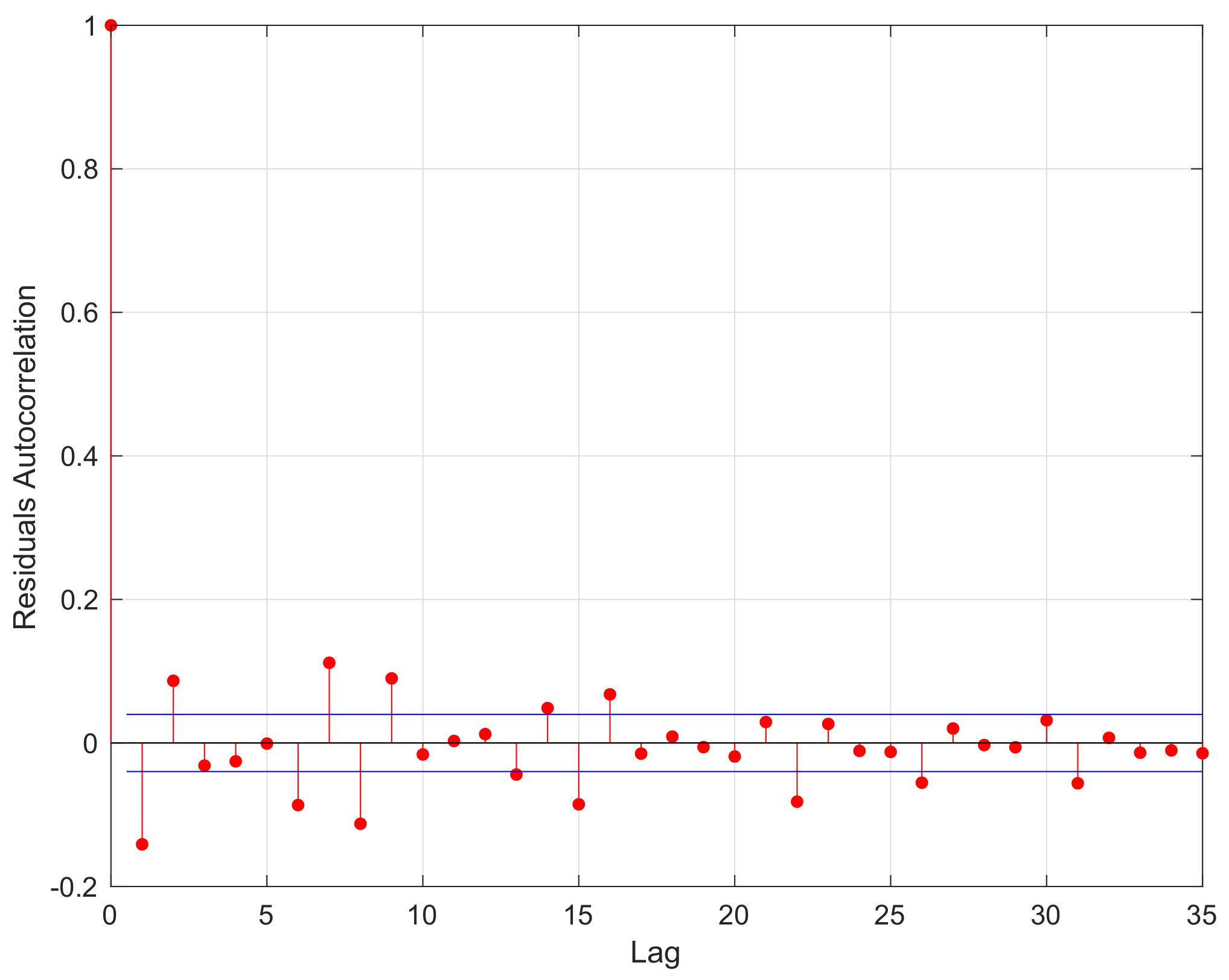
2). Then, the residuals’ autocorrelation function (ACF) of
is shown in
Figure 6.
According to
Figure 6, the autocorrelation coefficients for the residuals were around 0 as the Lag increased, which satisfied the property of
-mixing data. Then, the curves of the LS estimator
defined by (
2), lower bound
and upper bound
, for
are also shown in
Figure 7,
defined by (
17) is the value of the standard Cauchy distribution with significance level
. With
, the curves of
,
, and
are presented in
Figure 7.
According to
Figure 7, the values of
approached 1 as sample
n increased, while the lower bound
and upper bound
were around 1. In addition, by (
17), we let
, and
,
. The curves of
and
are also shown in
Figure 5. According to
Figure 5, the curve
was between curves
and
, while the curve widths of
and
were very small. Furthermore, the period from April 2011 to April 2021 was the takeoff period of technology stocks and a faster increase in U.S. Treasury yields. Thus, these real data are a good use of the mildly explosive model and the Cauchy limiting distribution of the LS estimator in Theorem 1.
5. Conclusions and Discussion
The study of the mildly explosive process has received much attention from researchers, as it can be used to test the explosive behavior of economic growth. Phillips and Magdalinos [
2] considered the mildly explosive process (
7) based on independent errors and obtained the Cauchy limiting distribution of the LS estimator
of
. Oh et al. [
12] extended Phillips and Magdalinos [
2] to geometrically
-mixing errors. Obviously, the assumption of geometrically
-mixing was very strong. Thus, we considered the mildly explosive process based on arithmetically
-mixing errors. Under the condition of the mixing coefficients
for some
, we re-proved the key Lemmas 1 and 2. Consequently, the Cauchy limiting distribution for
in Theorem 1 also held true. In order to illustrate the main result of the Cauchy limiting distribution, some simulations of the empirical probability of the confidence interval and the empirical density for
were presented in
Section 4. It had a good finite sample performances. As an application, we used the mildly explosive process to analyze real data from the NASDAQ composite index from April 2011 to April 2021. It was a takeoff period of technology stocks and a faster increase in U.S. Treasury yields. Moreover, it is of interest for researchers to study the random walk process, near-stationary process, mildly explosive process, and explosive process under heteroskedasticity errors (see Arvanitis and Magdalinos [
20]), anti-persistent errors (see Liu et al. [
21]), and other missing dependent data in the future.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}