
Estimating Gaussian Copulas with Missing Data with and without Expert Knowledge


Abstract
:1. Introduction
- If there was no a priori knowledge of the parametric family of all marginals, Ref. [18] proposed using the ecdf of the observed data points. Afterwards, they exclusively derived the parameters of the copula. This estimator of the marginals was biased [19,20], which is often overlooked in the copula literature, e.g., [21] (Section 4.3), [22] (Section 3), [23] (Section 3), or [24] (Section 3).
- The description of the simulation study was incomplete and the results were not reproducible.
- We give a rigorous derivation of the EM algorithm under a Gaussian copula model. Similarly to [5], it consists of two separate steps, which estimate the marginals and the copula, respectively. However, these two steps alternate.
- We show how prior knowledge about the marginals and the dependency structure can be utilized in order to achieve better results.
- We propose a flexible parametrization of the marginals when a priori knowledge is absent. This allows us to learn the underlying marginal distributions; see Figure 1.
- We provide a Python library that implements the proposed algorithm.
2. The Gaussian Copula Model
2.1. Notation and Assumptions
2.2. Properties
- Find consistent estimates for the marginal distributions .
- Find by estimating the covariance of the random vector
- The conditional density of is given bywhere , , and
- is normally distributed with mean μ and covariance .
- The expectation of with respect to the density can be expressed by
| Algorithm 1:Sampling from the conditional distribution of a Gaussian copula |
Input: Result: m samples of Calculate Calculate and as in Proposition 1 using and Draw samples from return { |
3. The EM Algorithm in the Gaussian Copula Model
3.1. The EM Algorithm
- E-Step: Calculate
- M-Step: Setand .
3.2. Applying the ECM Algorithm on the Gaussian Copula Model
3.2.1. E-Step
3.2.2. M-Step
- Set .
- Set .
Estimating
Estimating
- The summand describes how well the marginal distributions fit the (one-dimensional) data.
- The estimations of the marginals are interdependent. Hence, in order to maximize with respect to , we have to take into account all other components of .
- The first summand adjusts for the dependence structure in the data. If all observations at step are assumed to be independent, then , and this term is 0.
- More generally, the derivative depends on if and only if . This means that if implies the conditional independence of column j and k given all other columns (Equation (6)), the optimal can be found without considering . This, e.g., is the case if we set entries of the precision matrix to 0. Thus, the incorporation of prior knowledge reduces the complexity of the identification of the marginal distributions.
3.3. Modelling with Semiparametric Marginals
3.4. A Blueprint of the Algorithm
| Algorithm 2:Blueprint for the EM algorithm for the Gaussian copula model |
 |
4. Simulation Study
- Standard COPula Estimator (SCOPE): The marginal distributions are estimated by the ecdf of the observed data points. This was proposed by [18] if the parametric family is unknown, and it is the state-of-the art approach. Thus, we apply an EM algorithm to determine the correlation structure on the mapped data pointswhere is the ecdf of the observed data points in column j. Its corresponding results are indexed with SCOPE in the figures and tables.
- Known marginals: The distribution of the marginals is completely known. The idea is to eliminate the difficulty of finding them. Here, we apply the EM algorithm for the correlation structure onwhere is the real marginal distribution function. Its corresponding results are indexed with a 0 in the figures and tables.
- Markov chain–Monte Carlo (MCMC) approach [21]: The author proposed an MCMC scheme to estimate the copula in a Bayesian fashion. Therefore, Ref. [21] derived the distribution of the multivariate ranks. The marginals are treated as nuisance parameters. We employed the R package sbgcop, which is available on CRAN, as it provides not only a posterior distribution of the correlation matrix , but also imputations for missing values. In order to compare the approach with the likelihood-based methods, we setwhere are samples of the posterior distribution of the correlation matrix. For the marginals, we definedwhere is the m-th of the total of M imputations for and if can be observed. The samples were drawn from the posterior distribution. The corresponding results were indexed with the MCMC approach in the figures and tables.
4.1. Adapting the EM Algorithm
4.2. Data Generation
- Remove every entry in D with probability . We denote the resulting data matrix (with missing entries) as .
- If and are observed, remove with probabilityWe call the resulting data matrix .
4.3. Results
4.3.1. The Effects of Dependency and Share of Missing Values
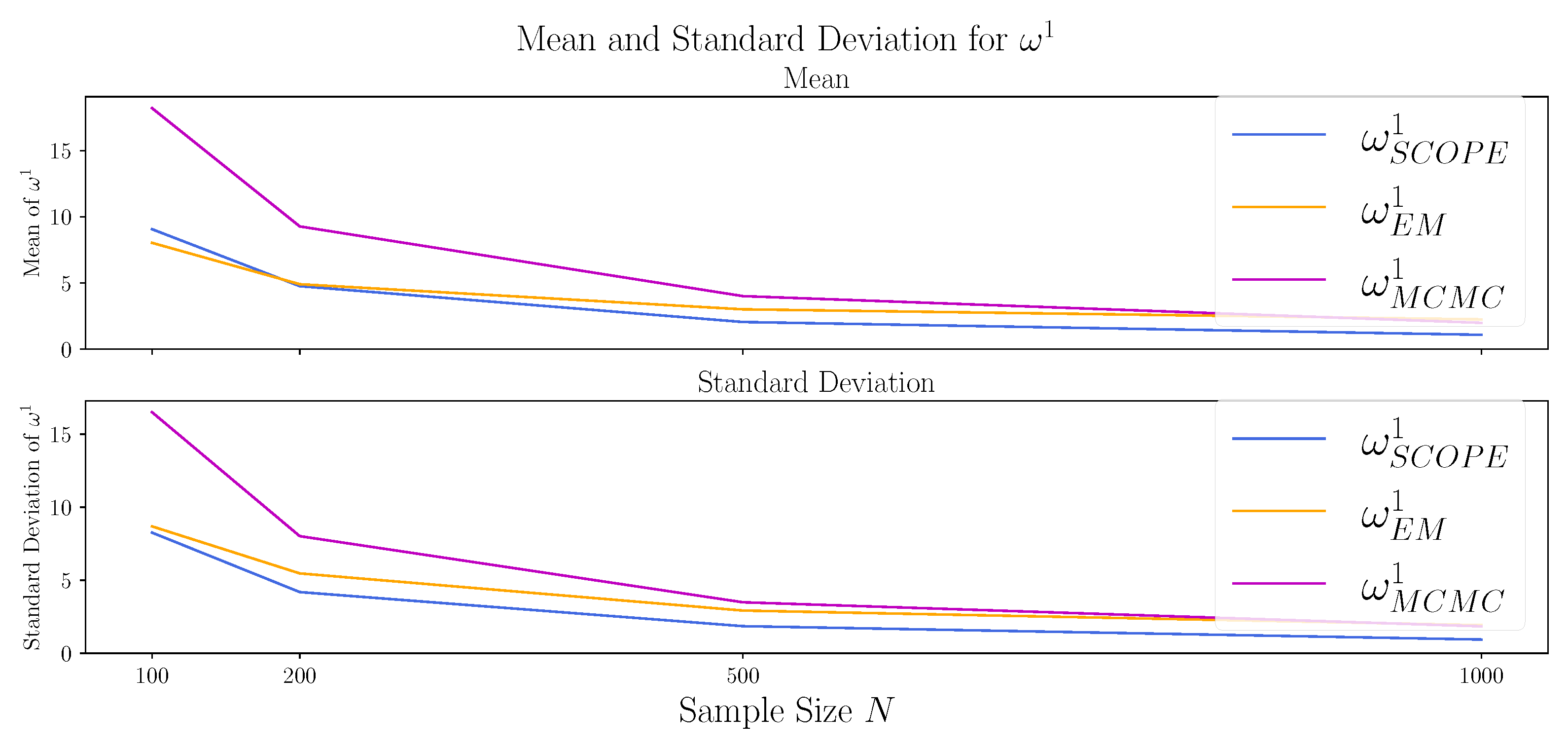
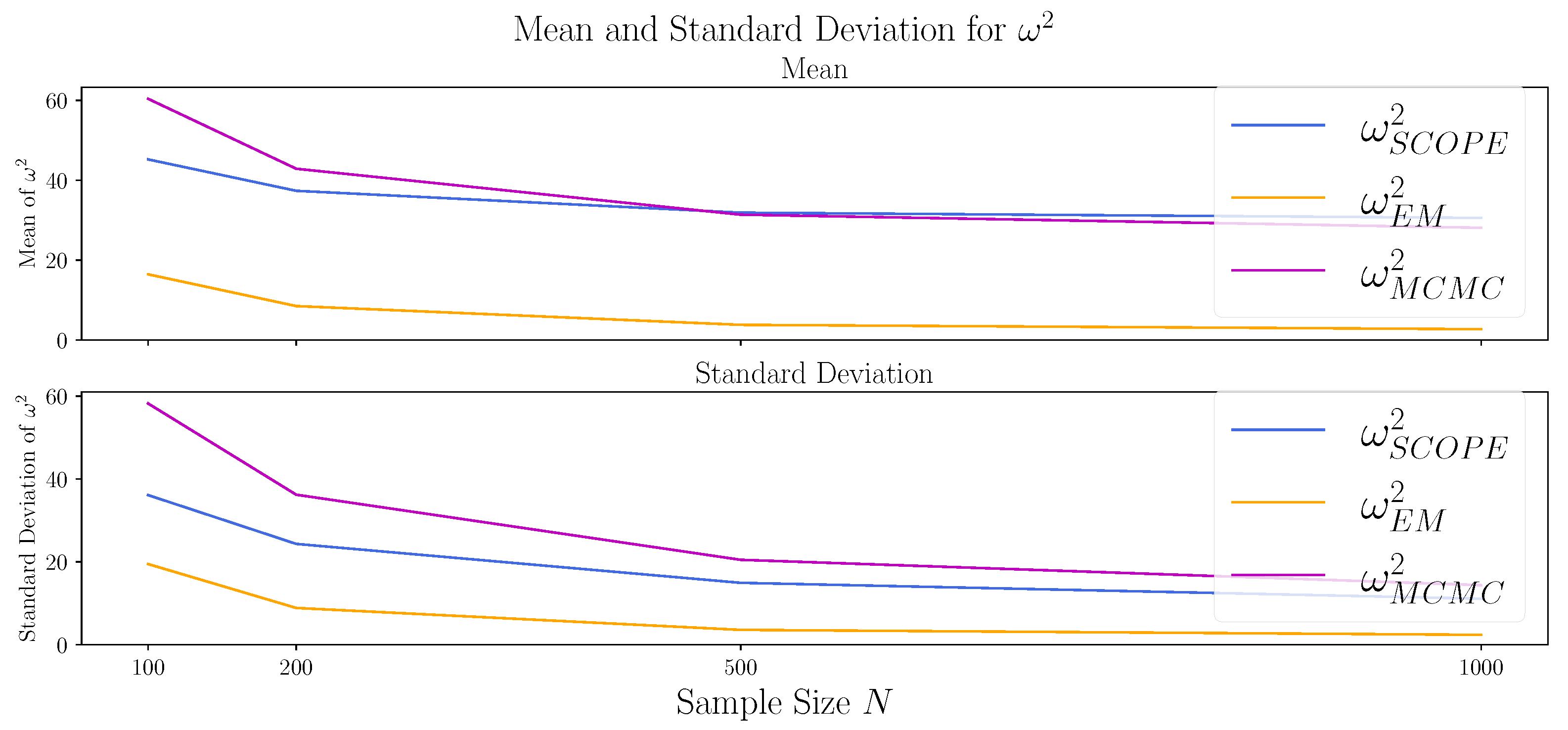
4.3.2. Varying the Sample Size N
4.3.3. The Impacts of Varying the Number of Mixtures g
4.3.4. Run Time
4.4. Inclusion of Expert Knowledge
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Technical Results
Appendix A.1. Proof of Conditional Distribution
- 1.
- We inspect the conditional density function:Using well-known factorization lemmas and using the Schur complement (see, for example, [48] (Section 4.3.4)) applied on , we encounter
- 2.
- The distribution offollows with a change-of-variable argument. Using Equation (A1), we observe for any measurable set A thatwhere, in the second equation, we used the transformation and the fact that
- 3.
- This proof is analogous to the one above, and we finally obtain
Appendix A.2. Closed-Form Solution of the E-Step for θ = θ t
Appendix A.3. Maximizer of argmax Σ,Σ jj =1∀j=1,…,p λ(θ t, Σ|θ t, Σ t )
Appendix B. Details of the Simulation Studies
Appendix B.1. Drawing Samples from the Joint Distributions
Appendix B.1.1. Estimators of the Percentile Function
- In the case of SCOPE, consider the marginal observed data points, which we assume to be ordered . We use the following linearly interpolated estimator for the percentile function:
- To estimate the percentile function for the mixture models, we choose with equal probability (all Gaussians have equal weight) one component of the mixture and then draw a random number with its mean and standard deviation , . In this manner, we generate samples . The estimator for the percentile function is then chosen to be analogous to the one above. A higher leads to a more exact result. We choose to be 10,000.
Appendix B.1.2. Sampling
Appendix B.2. Missing Mechanism for Section 4.4
- Again, we remove every entry in the data matrix D with probability . The resulting data matrix (with missing entries) is denoted as
- If , , and are observed, we remove with probabilitywhereand .
Appendix B.3. Complementary Figures





References
- Thurow, M.; Dumpert, F.; Ramosaj, B.; Pauly, M. Imputing missings in official statistics for general tasks–our vote for distributional accuracy. Stat. J. IAOS 2021, 37, 1379–1390. [Google Scholar] [CrossRef]
- Liu, Y.; Dillon, T.; Yu, W.; Rahayu, W.; Mostafa, F. Missing value imputation for industrial IoT sensor data with large gaps. IEEE Internet Things J. 2020, 7, 6855–6867. [Google Scholar] [CrossRef]
- Silverman, B. Density Estimation for Statistics and Data Analysis; Routledge: London, UK, 2018. [Google Scholar]
- Kertel, M.; Harmeling, S.; Pauly, M. Learning causal graphs in manufacturing domains using structural equation models. arXiv 2022, arXiv:2210.14573. [Google Scholar] [CrossRef]
- Genest, C.; Ghoudi, K.; Rivest, L.P. A semiparametric estimation procedure of dependence parameters in multivariate families of distributions. Biometrika 1995, 82, 543–552. [Google Scholar] [CrossRef]
- Liu, H.; Han, F.; Yuan, M.; Lafferty, J.; Wasserman, L. High-dimensional semiparametric gaussian copula graphical models. Ann. Stat. 2012, 40, 2293–2326. [Google Scholar] [CrossRef]
- Titterington, D.; Mill, G. Kernel-based density estimates from incomplete data. J. R. Stat. Soc. Ser. B Methodol. 1983, 45, 258–266. [Google Scholar] [CrossRef]
- Dempster, A.; Laird, N.; Rubin, D. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B Methodol. 1977, 39, 1–22. [Google Scholar]
- Shen, C.; Weissfeld, L. A copula model for repeated measurements with non-ignorable non-monotone missing outcome. Stat. Med. 2006, 25, 2427–2440. [Google Scholar] [CrossRef]
- Gomes, M.; Radice, R.; Camarena Brenes, J.; Marra, G. Copula selection models for non-Gaussian outcomes that are missing not at random. Stat. Med. 2019, 38, 480–496. [Google Scholar] [CrossRef]
- Rubin, D.B. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Cui, R.; Groot, P.; Heskes, T. Learning causal structure from mixed data with missing values using Gaussian copula models. Stat. Comput. 2019, 29, 311–333. [Google Scholar] [CrossRef]
- Wang, H.; Fazayeli, F.; Chatterjee, S.; Banerjee, A. Gaussian copula precision estimation with missing values. In Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, Reykjavik, Iceland, 22–25 April 2014; PMLR: Reykjavik, Iceland, 2014; Volume 33, pp. 978–986. [Google Scholar]
- Hamori, S.; Motegi, K.; Zhang, Z. Calibration estimation of semiparametric copula models with data missing at random. J. Multivar. Anal. 2019, 173, 85–109. [Google Scholar] [CrossRef]
- Robins, J.M.; Gill, R.D. Non-response models for the analysis of non-monotone ignorable missing data. Stat. Med. 1997, 16, 39–56. [Google Scholar] [CrossRef]
- Sun, B.; Tchetgen, E.J.T. On inverse probability weighting for nonmonotone missing at random data. J. Am. Stat. Assoc. 2018, 113, 369–379. [Google Scholar] [CrossRef] [PubMed]
- Seaman, S.R.; White, I.R. Review of inverse probability weighting for dealing with missing data. Stat. Methods Med. Res. 2013, 22, 278–295. [Google Scholar] [CrossRef]
- Ding, W.; Song, P. EM algorithm in gaussian copula with missing data. Comput. Stat. Data Anal. 2016, 101, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Efromovich, S. Adaptive nonparametric density estimation with missing observations. J. Stat. Plan. Inference 2013, 143, 637–650. [Google Scholar] [CrossRef]
- Dubnicka, S.R. Kernel density estimation with missing data and auxiliary variables. Aust. N. Z. J. Stat. 2009, 51, 247–270. [Google Scholar] [CrossRef]
- Hoff, P. Extending the rank likelihood for semiparametric copula estimation. Ann. Appl. Stat. 2007, 1, 265–283. [Google Scholar] [CrossRef]
- Hollenbach, F.; Bojinov, I.; Minhas, S.; Metternich, N.; Ward, M.; Volfovsky, A. Multiple imputation using gaussian copulas. Sociol. Methods Res. 2021, 50, 1259–1283. [Google Scholar] [CrossRef] [Green Version]
- Di Lascio, F.; Giannerini, S.; Reale, A. Exploring copulas for the imputation of complex dependent data. Stat. Methods Appl. 2015, 24, 159–175. [Google Scholar] [CrossRef]
- Houari, R.; Bounceur, A.; Kechadi, T.; Tari, A.; Euler, R. A new method for estimation of missing data based on sampling methods for data mining. Adv. Intell. Syst. Comput. 2013, 225, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Sklar, A. Fonctions de repartition an dimensions et leurs marges. Publ. Inst. Statist. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Wei, G.; Tanner, M. A monte carlo implementation of the EM algorithm and the poor man’s data augmentation algorithms. J. Am. Stat. Assoc. 1990, 85, 699–704. [Google Scholar] [CrossRef]
- Meng, X.L.; Rubin, D. Maximum likelihood estimation via the ECM algorithm: A general framework. Biometrika 1993, 80, 267–278. [Google Scholar] [CrossRef]
- Guo, J.; Levina, E.; Michailidis, G.; Zhu, J. Graphical models for ordinal data. J. Comput. Graph. Stat. 2015, 24, 183–204. [Google Scholar] [CrossRef] [Green Version]
- McLachlan, G.; Lee, S.; Rathnayake, S. Finite mixture models. Annu. Rev. Stat. Its Appl. 2019, 6, 355–378. [Google Scholar] [CrossRef]
- Hwang, J.; Lay, S.; Lippman, A. Nonparametric multivariate density estimation: A comparative study. IEEE Trans. Signal Process. 1994, 42, 2795–2810. [Google Scholar] [CrossRef] [Green Version]
- Scott, D.; Sain, S. Multidimensional density estimation. Handb. Stat. 2005, 24, 229–261. [Google Scholar]
- Zuo, Y.; Cui, Y.; Yu, G.; Li, R.; Ressom, H. Incorporating prior biological knowledge for network-based differential gene expression analysis using differentially weighted graphical LASSO. BMC Bioinform. 2017, 18, 99. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Jackson, S.A. Gene network reconstruction by integration of prior biological knowledge. G3 Genes Genomes Genet. 2015, 5, 1075–1079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Joyce, J.M. Kullback-Leibler divergence. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar]
- Contreras-Reyes, J.E.; Arellano-Valle, R.B. Kullback–Leibler divergence measure for multivariate skew-normal distributions. Entropy 2012, 14, 1606–1626. [Google Scholar] [CrossRef] [Green Version]
- Honaker, J.; King, G.; Blackwell, M. Amelia II: A program for missing data. J. Stat. Softw. 2011, 45, 1–47. [Google Scholar] [CrossRef]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and explainability of artificial intelligence in medicine. WIREs Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dinu, V.; Zhao, H.; Miller, P.L. Integrating domain knowledge with statistical and data mining methods for high-density genomic SNP disease association analysis. J. Biomed. Inform. 2007, 40, 750–760. [Google Scholar] [CrossRef] [Green Version]
- Rubin, D. Multiple imputation after 18+ years. J. Am. Stat. Assoc. 1996, 91, 473–489. [Google Scholar] [CrossRef]
- Van Buuren, S. Flexible Imputation of Missing Data; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Ramosaj, B.; Pauly, M. Predicting missing values: A comparative study on non-parametric approaches for imputation. Comput. Stat. 2019, 34, 1741–1764. [Google Scholar] [CrossRef]
- Ramosaj, B.; Amro, L.; Pauly, M. A cautionary tale on using imputation methods for inference in matched-pairs design. Bioinformatics 2020, 36, 3099–3106. [Google Scholar] [CrossRef]
- Zhao, Y.; Udell, M. Missing value imputation for mixed data via gaussian copula. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 636–646. [Google Scholar] [CrossRef]
- Rubin, D.B. Causal Inference Using Potential Outcomes: Design, Modeling, Decisions. J. Am. Stat. Assoc. 2005, 100, 322–331. [Google Scholar] [CrossRef]
- Ding, P.; Li, F. Causal inference: A missing data perspective. Stat. Sci. 2017, 33. [Google Scholar] [CrossRef] [Green Version]
- Käärik, E.; Käärik, M. Modeling dropouts by conditional distribution, a copula-based approach. J. Stat. Plan. Inference 2009, 139, 3830–3835. [Google Scholar] [CrossRef]
- Murphy, K. Machine Learning: A Probabilistic Perspective; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | Standard Deviation | ||||||
|---|---|---|---|---|---|---|---|
| Setting | Method | ||||||
| EM | 8.55 | 10.41 | 0.107 | 9.30 | 11.67 | 0.139 | |
| 0 | - | - | 0.109 | - | - | 0.144 | |
| SCOPE | 9.13 | 12.25 | 0.105 | 8.47 | 11.00 | 0.144 | |
| MCMC | 18.21 | 24.99 | 0.094 | 16.62 | 21.89 | 0.127 | |
| EM | 8.03 | 16.48 | 0.455 | 8.68 | 19.47 | 0.139 | |
| 0 | - | - | 0.498 | - | - | 0.138 | |
| SCOPE | 9.06 | 45.25 | 0.486 | 8.25 | 36.11 | 0.143 | |
| MCMC | 17.90 | 59.34 | 0.393 | 16.13 | 57.15 | 0.131 | |
| Mean | Standard Deviation | ||||||
|---|---|---|---|---|---|---|---|
| N | Method | ||||||
| EM | 8.03 | 16.48 | 0.455 | 8.68 | 19.47 | 0.139 | |
| 0 | - | - | 0.498 | - | - | 0.138 | |
| SCOPE | 9.06 | 45.25 | 0.486 | 8.25 | 36.11 | 0.143 | |
| MCMC | 17.90 | 59.34 | 0.393 | 16.13 | 57.15 | 0.131 | |
| EM | 4.91 | 8.53 | 0.469 | 5.46 | 8.88 | 0.098 | |
| 0 | - | - | 0.500 | - | - | 0.094 | |
| SCOPE | 4.76 | 37.38 | 0.493 | 4.18 | 25.35 | 0.096 | |
| MCMC | 9.27 | 42.91 | 0.370 | 8.01 | 36.23 | 0.089 | |
| EM | 3.01 | 3.83 | 0.480 | 2.92 | 3.59 | 0.063 | |
| 0 | - | - | 0.499 | - | - | 0.060 | |
| SCOPE | 2.05 | 31.92 | 0.497 | 1.85 | 14.95 | 0.060 | |
| MCMC | 4.01 | 31.41 | 0.0360 | 3.49 | 20.51 | 0.051 | |
| EM | 2.25 | 2.74 | 0.486 | 1.92 | 2.40 | 0.047 | |
| 0 | - | - | 0.500 | - | - | 0.042 | |
| SCOPE | 1.08 | 30.60 | 0.499 | 0.93 | 11.13 | 0.043 | |
| MCMC | 1.99 | 28.13 | 0.365 | 1.84 | 14.49 | 0.037 | |
| Mean | Standard Deviation | |||||
|---|---|---|---|---|---|---|
| # Mixtures | ||||||
| 13.82 | 16.38 | 0.469 | 14.17 | 19.69 | 0.145 | |
| 8.03 | 16.48 | 0.455 | 8.68 | 19.47 | 0.139 | |
| 7.17 | 18.73 | 0.454 | 7.48 | 20.98 | 0.140 | |
| Run Time in Seconds | ||
|---|---|---|
| Method | Mean | Standard Deviation |
| EM () | 21.78 | 3.27 |
| EM () | 55.94 | 11.39 |
| EM () | 161.57 | 38.00 |
| SCOPE | 0.45 | 0.11 |
| MCMC | 12.98 | 0.87 |
| Mean | Standard Deviation | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | ||||||||
| EM | 12.12 | 13.38 | 21.15 | 0.229 | 13.89 | 14.25 | 22.44 | 0.113 |
| KP, EM | 12.04 | 13.28 | 19.66 | 0.182 | 13.93 | 14.37 | 20.88 | 0.111 |
| 0 | - | - | - | 0.227 | - | - | - | 0.108 |
| SCOPE | 17.57 | 17.55 | 26.69 | 0.232 | 16.75 | 15.55 | 24.84 | 0.113 |
| MCMC | 36.85 | 35.70 | 80.22 | 0.263 | 32.82 | 33.24 | 78.57 | 0.140 |
| Mean() | Standard Deviation() | |
|---|---|---|
| EM | 1.37 | 0.53 |
| KP, EM | 1.26 | 0.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kertel, M.; Pauly, M. Estimating Gaussian Copulas with Missing Data with and without Expert Knowledge. Entropy 2022, 24, 1849. https://doi.org/10.3390/e24121849
Kertel M, Pauly M. Estimating Gaussian Copulas with Missing Data with and without Expert Knowledge. Entropy. 2022; 24(12):1849. https://doi.org/10.3390/e24121849
Chicago/Turabian StyleKertel, Maximilian, and Markus Pauly. 2022. "Estimating Gaussian Copulas with Missing Data with and without Expert Knowledge" Entropy 24, no. 12: 1849. https://doi.org/10.3390/e24121849
APA StyleKertel, M., & Pauly, M. (2022). Estimating Gaussian Copulas with Missing Data with and without Expert Knowledge. Entropy, 24(12), 1849. https://doi.org/10.3390/e24121849