1. Introduction
With the advantages of providing global-coverage, high-throughput capability, and low-cost internet access, satellite communication has drawn significant attention from both industry and academia and is regarded as a promising solution for meeting the needs of the Internet of Remote Things (IoRT) [
1,
2]. Currently, there are three types of satellites in space that provide global service, including geosynchronous Earth orbit (GEO) satellites, medium Earth orbit (MEO) satellites and low Earth orbit (LEO) satellites [
3]. Compared with GEO and MEO satellites, LEO satellites have recently become popular due to their lower development costs, better signal strength, and the potential for large-scale LEO satellite networks that can guarantee lower transmission delays [
4,
5]. More than 40,000 LEO satellites are planned by SpaceX Starlink alone. On the other hand, LEO satellites are deployed at an altitude of 500–1500 km with an orbital period shorter than 2 h. The fast movement of LEO satellites results in a very limited window for transmission to ground devices, approximately 10 min/pass [
6]. The maximum completion time optimization for the Internet of Things (IoT) in LEO satellite-terrestrial integrated networks (STINs) was investigated in [
7], and a cooperative nonorthogonal multiple access (NOMA) scheme for data transmission was proposed. As the amount of data transferred continues to increase, it becomes increasingly challenging for LEO satellites to transmit all data within such a small transmission window, especially in remote rural areas with no terrestrial infrastructure. Moreover, in practical satellite systems, line-of-sight (LoS) communication between satellite and terrestrial users is difficult to maintain due to obstacles and shadowing [
8]. In [
9], the authors investigated unmanned aerial vehicle (UAV) swarms and LEO satellite constellation-assisted data collection for IoRT networks, where UAV swarms were used as relays to improve the channel environment. UAVs have the benefits of high mobility, flexible deployment, and LoS transmission [
10,
11]. However, when introducing UAVs in LEO-assisted IoRT networks, data transmission becomes more challenging because of the different channel characteristics of UAV-ground and UAV-satellite links, as well as the battery and cache capacity limitations of UAVs.
Considered promising technology, intelligent reflecting surfaces (IRSs) have recently received substantial attention [
12,
13,
14,
15,
16]. IRS consists of a large number of passive elements which can introduce controllable phase shifts. Intelligently adjusting these phases can change the reflected signal propagation. Therefore, it has been widely deployed in wireless communication systems to enhance the intended signal power at the receiver or mitigate the cochannel interference [
14,
15,
16]. Refs. [
14,
15] investigated the weighted sum rate and transmitted power in an IRS-aided MISO system, respectively, by jointly optimizing the transmit beamforming vectors at the base stations (BSs) and the reflective beamforming vector at the IRS. Ref. [
16] studied the secure transmission optimization for IRS-assisted STINs.
Most of the existing literature assumes that the perfect channel state information (CSI) is known. However, this assumption is impractical because the number of IRS reflecting elements is large and not capable of performing active transmission/reception and signal processing [
17]. Previous studies proposed various channel estimation schemes in the IRS-assisted multiuser system [
17,
18,
19,
20]. However, the abovementioned methods are based on the BSs have fixed locations, and the variation of BS-IRS common channel is feeble. These approaches cannot be efficiently applied to the IRS-assisted LEO satellite system since the high-speed scenarios with fast time-varying channels would be updated more frequently. In actual deployment, the high complexity channel estimation schemes and beamforming algorithms may cause the instantaneous CSI obtained by LEO satellites to be out of date [
21], which would dramatically diminish the system’s performance.
Fortunately, artificial intelligence (AI) technology provides simple approaches to address such complex problems [
21,
22,
23,
24]. Yang et al. [
22] investigated secure physical communication based on IRS under the condition of time-varying channel coefficients and proposed a deep reinforcement learning approach to jointly optimize both BS and IRS beamforming. Ge et al. [
23] established a deep transfer learning framework to solve the beamforming optimization problem for the IRS-assisted MISO system. Jiang et al. [
24] trained a graph neural network (GNN) architecture to directly map the received pilots to the IRS’s phase shifts and BS beamforming matrix. However, Ref. [
24] merges user location and pilots directly, resulting in the location features being easily ignored. In addition, due to the long distance between the satellite and users, the pilots received by the satellite is insensitive to user position information. Therefore, this approach cannot be effectively utilized in our system. Note that existing research on IRS mainly focuses on the ground cellular network system, and most research has been based on a static environment. When the application is extended to LEO satellite and the users’ location may also change, the algorithm’s computational complexity has a significant impact on performance.
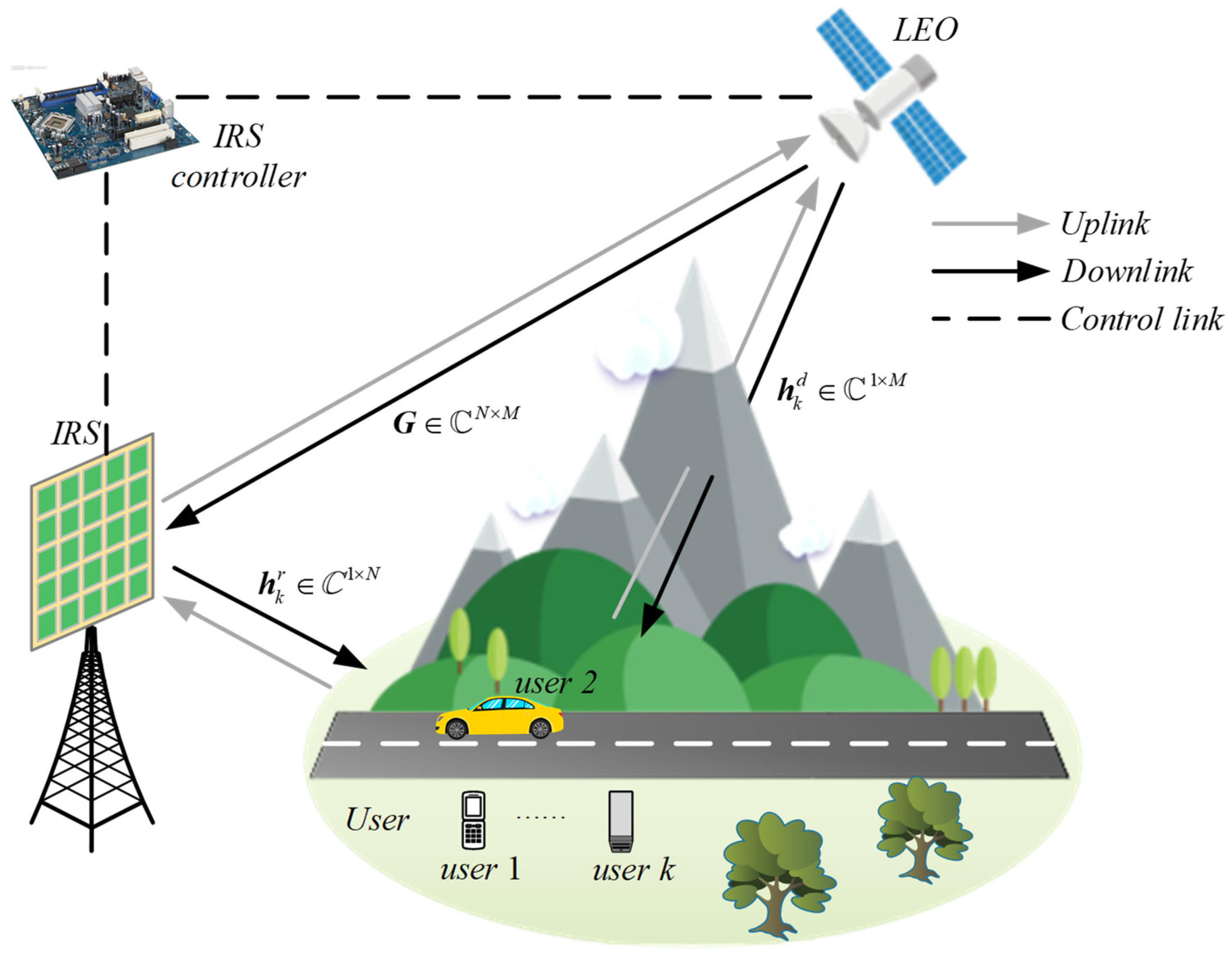
In this paper, we commit to applying AI technology to solve the complex beamforming design problem in an IRS-assisted LEO satellite communication system. Specifically, the IRS is used to provide additional reflective links to overcome the serious attenuation caused by occlusion between the LEO satellites and users’ direct links. In our work, we establish a global optimization problem for maximizing the sum-rate of mobile users by optimizing both active and passive beamforming schemes jointly. To solve this problem, we propose a robust beamforming approach based on graph attention networks (RBF-GAT). Here are the main contributions of this paper:
First, we propose a novel architecture for LEO satellite IoT networks assisted with IRS. A deep neural network (DNN) architecture based on graph attention networks (GAT) [
25] is constructed to capture dynamic network topology in real-time as a result of the mobility of the satellite and its users.
Second, a composite neural network combining a GAT layer and multiple fully connected (FC) layers is used to directly map the received pilots and network topology to the satellite and IRS beamforming, eliminating the necessity for channel estimation. To reduce the complexity of the RBF-GAT model, the mapping neural networks of satellite and IRS use the same feature extraction layers before the last normalization layer.
Third, we define a loss function to implement unsupervised training offline, thereby avoiding the labeling overhead that occurs in traditional supervised learning. Simulation results demonstrate that the proposed RBF-GAT approach, in well-trained conditions, will be able to approach upper-bound sum rate with a low level of computational complexity.
The remainder of this paper is organized as follows.
Section 2 introduces the IRS-assisted LEO satellite communication system model.
Section 3 describes the detailed architecture of RBF-GAT and the training process.
Section 4 gives the simulation results and the complexity analysis.
Section 5 presents the concluding remarks of this paper.
Notations: Boldface letters are used to denote vectors or matrices. , , and represent the complex, real matrices and m-dimensional real vector, respectively. The distribution of complex Gaussian random variables with mean and variance are denoted by . The term denotes the diagonalization of the vector, and denotes the transpose of the matrices. The symbol denotes the Hadamard product.
3. Proposed RBF-GAT Framework
To acquire the downlink instantaneous CSI of the LEO satellite, we follow the literature [
19] and propose a pilot transmission strategy to design the uplink pilots and the IRS phase shifts in the pilot phase. Specifically, all users send their pilot sequences with length
L to the satellite simultaneously. Each pilot can be decorrelated at the LEO satellite because all users’ pilot sequences are designed to be orthogonal. We denote the received pilots of user
k at the satellite as
, which contains rich CSI between satellite and user
k. The conventional approach of acquiring CSI uses minimum mean-squared error (MMSE), and its calculation is very complicated, especially for the IRS cascade channel.
Notably, GAT is an effective way to process structured data that are represented as a graph. In this work, the distribution of users can be regarded as a graph. K users constitute nodes of the graph, and each node is encoded as a feature vector denoted as , which is transmitted to the satellite via uplink and contains the common features (e.g., the locations of IRS and satellite) and the private features (e.g., user locations, category and priority). GAT can track the spatial fluctuations of the network in real-time by processing this feature.
In this section, we commit to training an RBF-GAT network to directly establish the mapping from and to the precoding matrix and reflect beamforming to maximize the system sum rate. We first introduce the RBF-GAT architecture in detail and then discuss the unsupervised training approach.
3.1. RBF-GAT Architecture
Our network consists of multiple GATs layers and multiple FC layers, as illustrated in
Figure 2. First, for the raw feature
obtained from the scenario, we need to map such vectors into a higher-dimensional space by a GAT layer, since the raw low-dimension feature contains less network topological information. The input to the GAT layer is a set of node features,
, where
is the dimension of raw features in each user. To transform
into a higher-level feature space of
dimension, a shared weight matrix,
, is applied to perform a linear transformation. We implement a shared self-attention mechanism
to calculate the attention coefficients of the user and its adjacent users:
Note that to indicate the topological information of the network, we computed the attention coefficients only when the distance between user
i and user
j was within certain threshold. For easy comparison, a softmax function is applied to normalize the coefficients across different adjacent users, and the final normalized coefficients
are obtained as:
where
is the set of adjacent users including itself in the current neighbourhood scope of the
i-th user. Then, these coefficients are used to calculate a linear combination of the features to produce the output features for the current network user:
where
represents a nonlinear activation function and
is the output vector of the single-head attention mechanism. To make the self-attention learning process more stable, a multi-head attention mechanism is used in this paper, which can be regarded as multiple single-head attentions executed independently in parallel, and taking the average as the output, can be represented by:
where
H is the number of attention heads,
represents the shared weight matrix of the
h-th attention head.
Then, we concatenate the received pilot
and the output features
as the composite features of user
k and denote them as
, which is a
dimensional vector because all received pilots are decomposed into real and imaginary parts.
Significantly, contains rich information about both the instantaneous CSI and network topology structure, so we use it as the input to the composite neural network. After pass through the GAT-2 layer, D FC layers and a normalization layer, the final output can be mapped directly to the precoding matrix of the satellite and the phase shift of the IRS.
We denote
as the output of the second GAT layer, which is also the input of the first FC layer. According to Equation (13),
can be expressed as:
where
and
are the normalized attention coefficients and the shared weight matrix of the
h-th multihead attentions, respectively. In addition, we chosethe node-wise mean function as an aggregation function to aggregate the output characteristics of the GAT layer and concatenate it into each FC layer by using skip connect.
After
D FC layers, the final output vectors, denoted as
, are passed to the normalization layer to produce the precoding matrix
and phase shift matrix
while ensuring the constraint of phase shift and transmit power. As with [
20], we input
to the linear layer
with 2
MK FC units and the linear layer
with 2
N FC units. Then, the normalization layer outputs the real and imaginary components of the optimization variables. Finally, the complex solution can be obtained by combining the real and imaginary components.
3.2. Unsupervised Training
Since it is difficult for the IRS-assisted LEO satellite system to obtain data labels, we cannot train it by a classic deep learning algorithm with supervised learning techniques. Thus, unsupervised training is adopted for training the network. We define the loss function as:
where
represents the total number of training samples in a batch. To generate a training dataset, first, we generate the channel data according to the channel model discussed in
Section 2. Then, all users transmit orthogonal pilot signals and additional information (i.e., location, priority, etc.) to the satellite. The LEO satellite can recover the pilots of all users from the received pilots and use it as part of the input of the neural network. The details of the training procedure are summarized in Algorithm 1.
Note that our model is trained offline, thus, the training process does not increase its computational complexity. During training, we use the stochastic gradient descent method to update the neural network parameters to minimize the loss function, which is equivalent to maximizing the objective function P1.
| Algorithm 1 Training procedure for RBF-GAT. |
| Input: learning rate , maximal epoch , batch size , training samples ,. |
| Output: Optimal network weights parameter |
| 1: Randomly initialize network parameter . |
| 2: Calculate loss according to Equation (16) and initialize . |
| 3: for do |
| 4: for do |
| 5: Initialize the phase shift matrix and generate received pilot according to [19] |
| 6: Randomly select samples to compose a batch task. |
| 7: Update the network weights parameter as by Adam optimizer. |
| 8: end for |
| 9: Calculate loss according to Equation (16). |
| 10: if do |
| 11: Set , and save network weights. |
| 12: else |
| 13: Update and judge whether the learning rate needs to be updated. |
| 14: end if |
| 15: end for |
4. Simulation and Numerical Results
This section uses numerical simulations to evaluate the performance achieved by the proposed RBF-GAT for the sum-rate maximization problem. We first set the simulation parameters of the training neural network and IRS-assisted LEO satellite communication system. Then, we compare the RBF-GAT with several benchmarks proposed in prior works. Finally, we show the simulation results and analyze the computational complexities of the proposed RBF-GAT method. The simulation experiments conducted in this study were performed on a computer equipped with an Intel(R) Core(TM) i7-8700 processor @3.19 GHz, 64 GB RAM. The simulation platform utilized Python 3.6, and the neural network in the RBF-GAT was constructed using TensorFlow 1.6.
4.1. Simulation Parameter Setting
We use four attention heads (
H = 4) and adopt three FCs (
D = 3) in the proposed network. The names of the FC layers are denoted as
,
and
, respectively. In addition, we set
as a 10-dimensional vector (
F = 10) that contains the priority information and the location information of user k, IRS and LEO satellites. The parameters of all layers are summarized in
Table 1.
For network training, we use the Adam optimizer with an initial learning rate , the number of maximal epochs is set to 350, and for each epoch, we generate iterations to update the weights of the network. The batch size is set to 1000. To accelerate the convergence, the learning rate decays by a factor of 0.3 when the validation loss does not decrease for 5 consecutive epochs. Due to the statistical properties of the channel and the noise in the uplink pilot transmission, all the calculation results are generated based on averaging over 1000 instances.
For the considered IRS-assisted LEO satellite system, we assume that the LEO satellite altitude is 1000 km and that the satellite is equipped with
M = 8 antennas. An IRS with 64 passive element locations at (0,0) and height 20 m. IRS is configured as an 8 × 8 uniform rectangular array. There are 6 terrestrial users uniformly distributed in a square area of [0, 200] m × [0, 200] m. We set the length of the uplink pilots to
L = 20 for each user, and the user’s transmission power to 15 dBm. The uplink channels from users to IRS, from IRS to the LEO satellite, and from users to the LEO satellite are generated according to the channel model discussed in
Section 2. The details of the coefficients are given in
Table 2.
4.2. Benchmark Schemes for Comparison
After the RBF-GAT was trained offline, we compared its performance with the following benchmarks:
Upper Bound: Let the CSI of all channels is perfectly known at the IRS and the LEO satellite, and we optimize the sum-rate maximization problem by the block coordinate descent (BCD) algorithm proposed in [
14], which can be treated as the system performance upper bound but, in reality, it is difficult to realize. We stop the BCD algorithm after 2000 iterations.
Deep Learning(GNN): Adopt a GNN architecture proposed in [
24] to capture the interactions among all users and the LEO satellite. The user locations and received pilots are directly concatenated as the input feature, and then train the model offline in an unsupervised manner.
Deep Learning(MLP): Design a multi-layer perceptron (MLP), which is composed of a simple network including multiple layers with several neurons, to establish the mapping from pilots and location to beamforming. This method has been studied in [
30].
Without IRS: Let
N = 0, and then the precoding matrix of the LEO satellite is optimized using the alternating optimization algorithm presented in [
14].
Random Phase: The IRS phase shift matrix is initialized with random value, and the alternating optimization algorithm proposed in [
14] is then applied to optimize the precoding matrix of the LEO satellite.
4.3. Numerical Results
In this subsection, we present the numerical results of the proposed approach. We assume that the users’ locations are fixed within a time slot, the time slot is small enough and the low-complexity RBF-GAT can implement active and passive beamforming within the time slot.
To verify the convergence rate of the proposed RBF-GAT scheme, we plot the loss value during training versus the number of epochs with three different training parameters.
Figure 3 shows that the proposed scheme converges to a locally optimal solution in less than 200 training epochs. In addition, the smaller the number of IRS reflection elements or users, the faster the convergence speed of the algorithm. This is because the number of users or IRS elements is positively correlated with the number of weight parameters to be trained.
Figure 4 shows the sum-rate versus the number of users under different schemes. The sum-rates under all considered schemes increase with an increasing number of users
K, and the larger the value of
K is, the slower the growth trend. This phenomenon can be explained by the concavity of the log function from the sum rate. It is seen that those methods aided with IRS observably exceed the one without IRS, and the performance gain by deploying IRS is inappreciable if the phase shift matrix is initialized by random value. Moreover, both RBF-GAT and GNN can achieve performance close to the upper boundary, but the proposed RBF-GAT consistently outperforms GNN, and the gap increases with
K. The reason for the increase is that the LEO satellite is insensitive to user’s location information, in contrast to GNN directly merging the position coordinates of the user, RBF-GAT can effectively capture the dynamic network topology by GAT layers. Thus, the proposed RBF-GAT is more suitable for IRS-aided LEO satellite dynamic scenario communication.
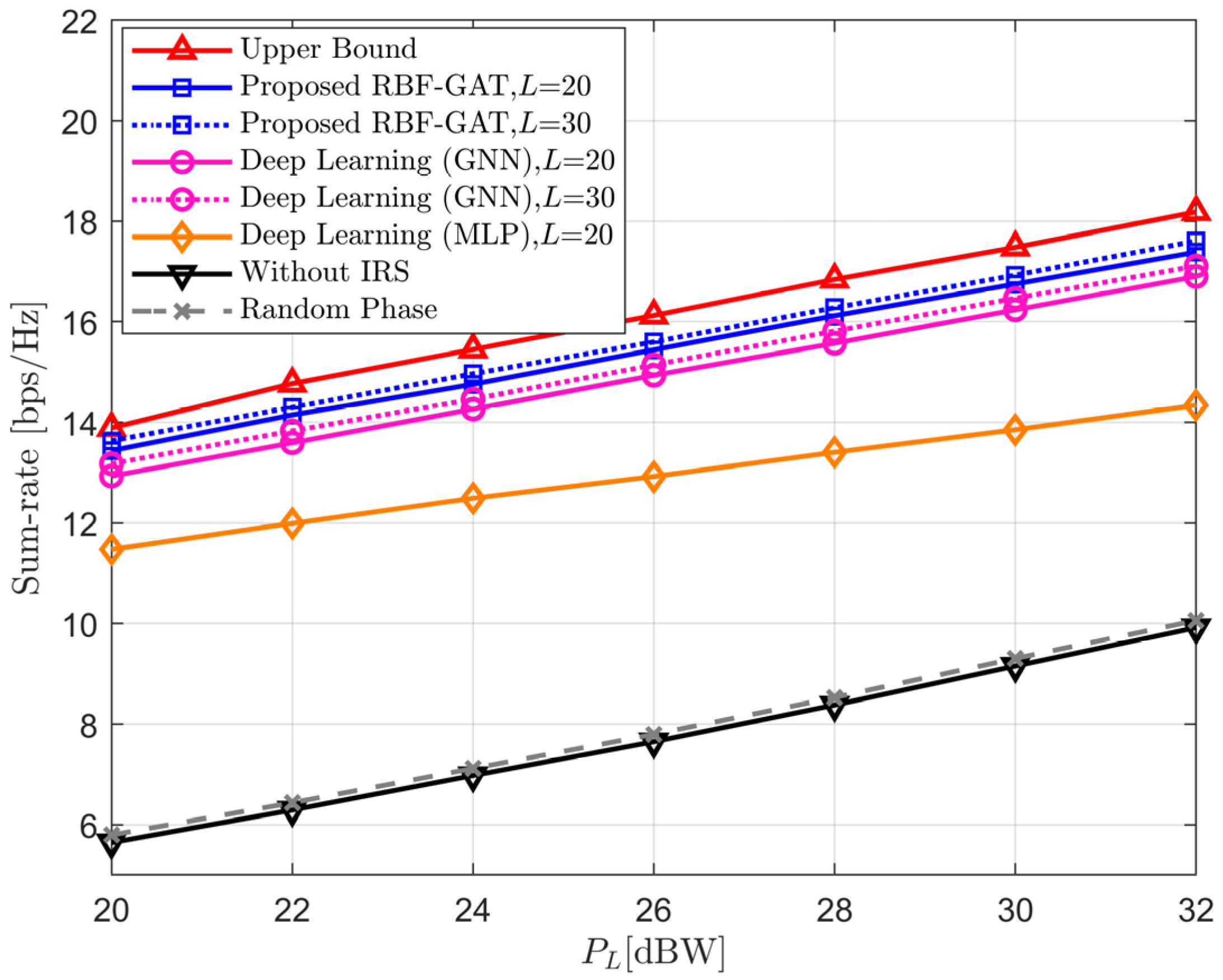
Figure 5 illustrates the sum-rate of different schemes with respect to the transmit power
when
N = 64. It is observed that the sum-rate increases for all considered schemes as the transmission power increases, and the random phase method still has only a weak gain. As we expected, the performance of RBF-GAT is always closest to the upper boundary under the condition of equal pilot length. In addition, as the pilot length increases, the rate sum also increases but never exceeds the upper boundary. This is because the longer the pilot signal received is, the richer the CSI contained. Thus, more features can be learned by the neural network. On the other hand, increasing the pilot length will also lead to a larger delay in data transmission. In practical applications, we should make trade-offs according to different requirements.
Figure 6 shows the sum-rate versus the number of elements of the IRS in four different schemes. In
Figure 6, we set the number of feeds at LEO satellite as
M = 8, pilot length as
L = 20, and the transmit power of LEO satellite as
We can find that the sum-rate of the without IRS method remains constant and the random phase method increase slightly as the numbers of IRS element grows. From
Figure 5 and
Figure 6, we can calculate that the proposed RBF-GAT approach can achieve more than 95% of the performance provided by the upper bound. In addition, both the number of IRS elements and the increase in transmit power can improve the sum-rate. However, compared to increasing the transmit power, increasing the IRS elements to improve the sum-rate performance is a more energy-efficient scheme due to the IRS elements being passive. The above numerical simulations further validate the robustness and effectiveness of our proposed RBF-GAT schemes.
4.4. Computational Complexity Analysis
The complexity of the BCD is
[
14], where
is the number of iterations and does not include the complexity of the channel estimation. For IRSs with passive elements, the conventional least square channel estimation methods have a computational complexity of
with
L <
NM. In our proposed RBF-GAT method, the channel estimation is omitted. For the training stage, let
Z1,
Z2, and
Z3 denote the number of neurons in the three FC layers in turn. The computational complexity of the proposed RBF-GAT scheme in each iteration is
. In the training phase, the model is trained for
epochs, with each epoch being
iterations. Hence, the total computational complexity of the proposed method is
The high computational complexity training process is performed offline. Therefore, the actual computational complexity of our proposed method is only linear in
M,
N and
K.
Due to the GNN and MLP methods are also established by neural networks, and they have approximate computational complexity as the proposed RBF-GAT. However, the proposed method achieves better performance, which is shown in the previous subsection. It is easy to see that the proposed RBF-GAT method has lower computational complexity and has significant advantages in the dynamic scenarios of satellite communication.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}