
A Fast Multi-Scale Generative Adversarial Network for Image Compressed Sensing


Abstract
:1. Introduction
- (1)
- A fast multi-scale generative adversarial network is proposed for image CS. The generator and discriminator are alternate training to ensure the reconstructed images are more realistic.
- (2)
- A multi-scale sampling structure is proposed, which improves image reconstruction quality through joint training with the reconstruction network.
- (3)
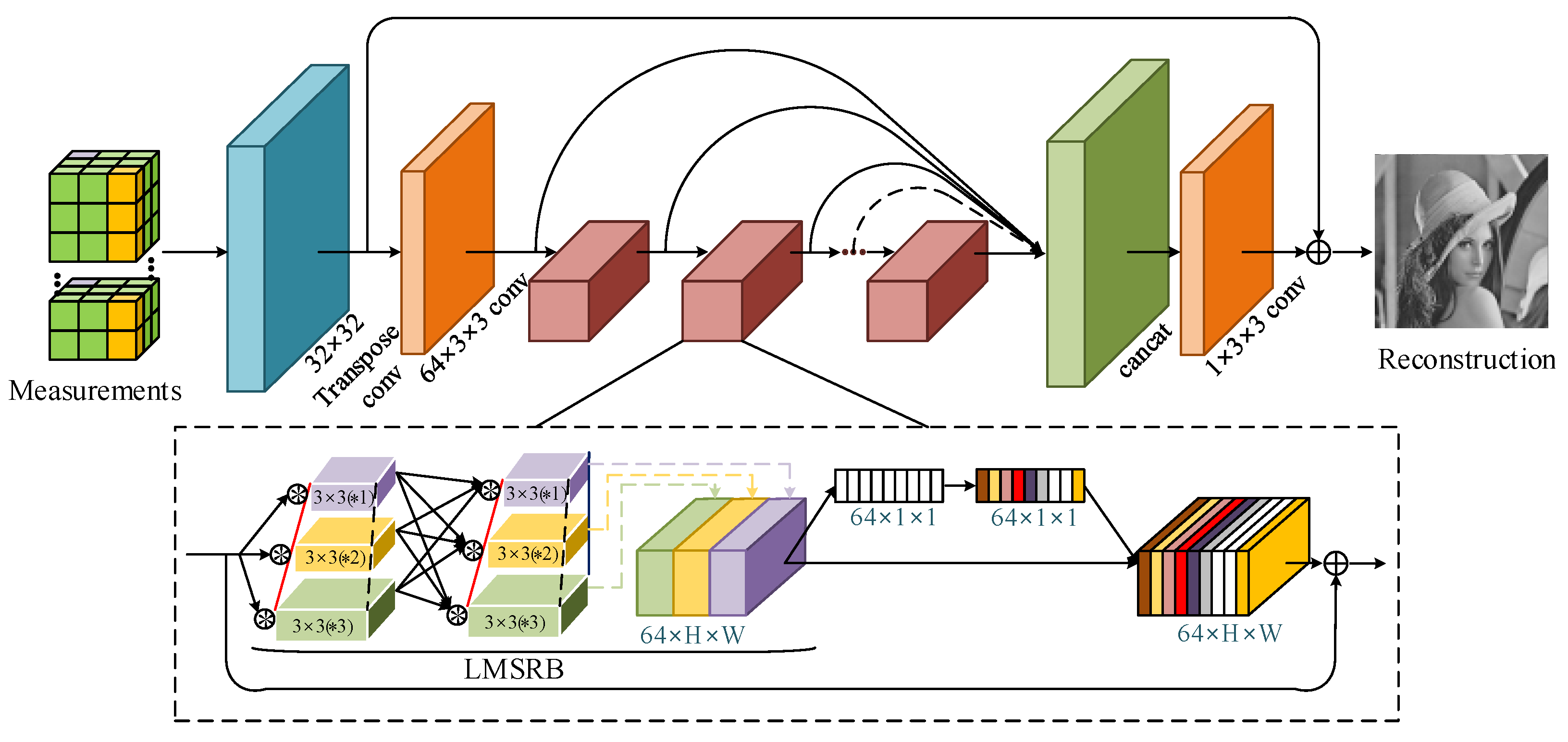
- A novel lightweight multi-scale residual block (LMSRB) is proposed, which is combined with the channel attention structure to better tradeoff between reconstruction performance and efficiency. Due to the high efficiency of the LMSRB, the image is reconstructed at high speed.
- (4)
- Our FMSGAN achieves state-of-the-art performance on three datasets.
2. Related Work
3. Methods
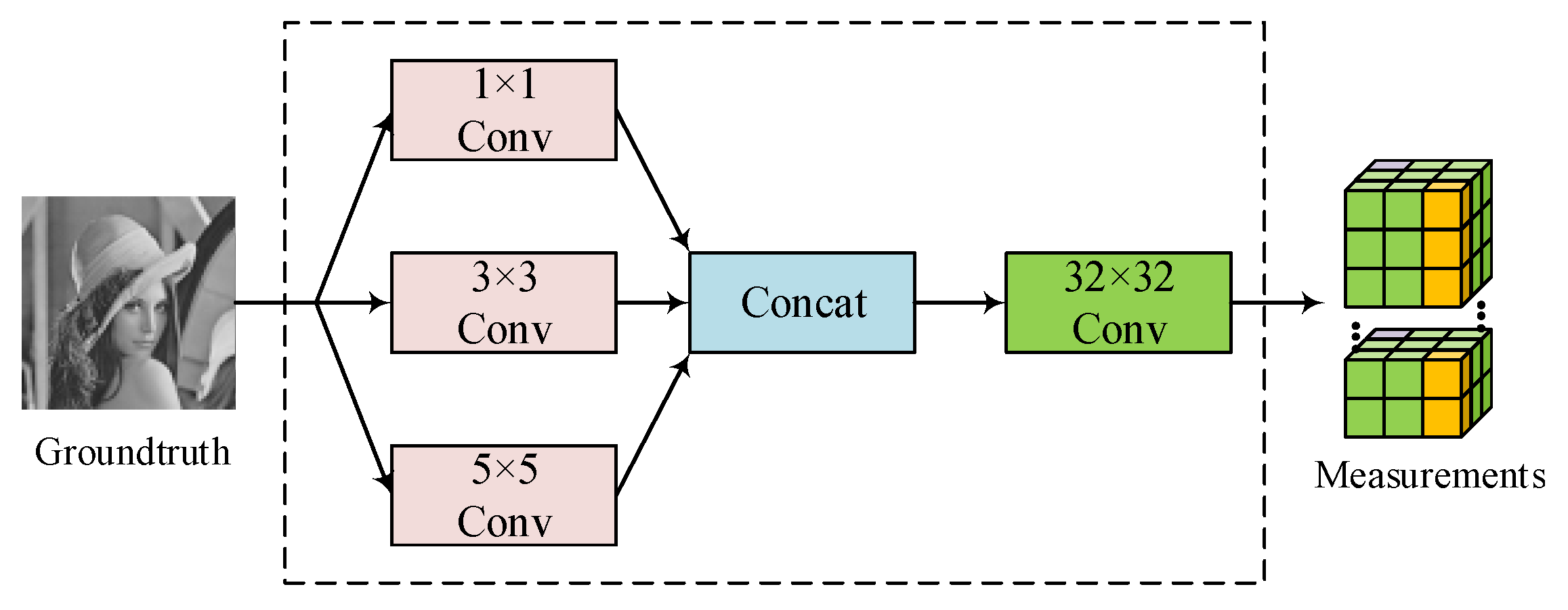
3.1. Multi-Scale Sampling Structure
3.2. Generator Structure
3.3. Discriminator Structure
3.4. Cost Function
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Results
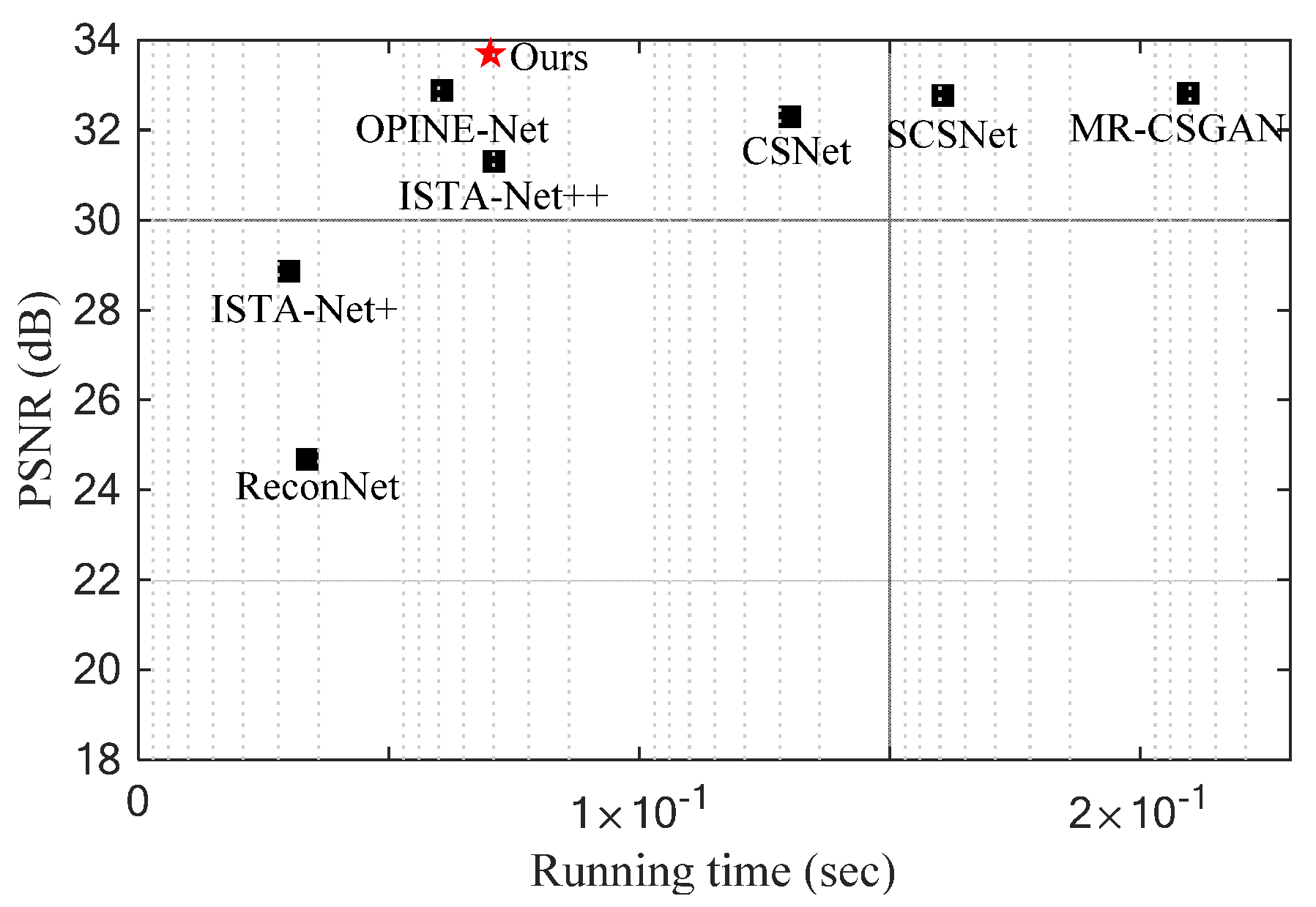
4.3.1. Comparison to Other State-of-the-Art Methods
4.3.2. Ablation Study
- The MSS
- 2.
- The LMSRB vs. the MSRB
- 3.
- Effect of cost function
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Candes, E.J.; Wakin, M.B. An Introduction to Compressive Sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Li, Y.; Dai, W.; Zhou, J.; Xiong, H.; Zheng, Y.F. Structured Sparse Representation with Union of Data-Driven Linear and Multilinear Subspaces Model for Compressive Video Sampling. IEEE Trans. Signal Process. 2017, 65, 5062–5077. [Google Scholar] [CrossRef]
- Yu, W.K. Super Sub-Nyquist Single-Pixel Imaging by Means of Cake-Cutting Hadamard Basis Sort. Sensors 2019, 19, 4122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Deng, C.; Liu, Y.; Yuan, X.; Suo, J.; Dai, Q. Ten-mega-pixel snapshot compressive imaging with a hybrid coded aperture. Photonics Res. 2021, 9, 2277–2287. [Google Scholar] [CrossRef]
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Guo, Y.; et al. DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruction. IEEE Trans. Med. Imaging 2018, 37, 1310–1321. [Google Scholar] [CrossRef] [Green Version]
- Fowler, J.E.; Mun, S.; Tramel, E.W. Multiscale block compressed sensing with smoothed projected landweber reconstruction. In Proceedings of the 19th European Signal Processing Conference, Barcelona, Spain, 29 August–2 September 2011; pp. 564–568. [Google Scholar]
- Canh, T.N.; Dinh, K.Q.; Jeon, B. Multi-scale/multi-resolution Kronecker compressive imaging. In Proceedings of the 2015 IEEE International Conference on Image Processing, Quebec City, Canada, 27–30 September 2015; pp. 2700–2704. [Google Scholar]
- Jin, J.; Xing, L.; Shen, J.; Li, R.; Yang, M.; Zhou, Z. Design of a Dynamic Sparse Circulant Measurement Matrix Based on a New Compound Sine Chaotic Map. IEEE Access 2022, 10, 10827–10837. [Google Scholar] [CrossRef]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable Optimization-Inspired Deep Network for Image Compressive Sensing. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1828–1837. [Google Scholar]
- Tropp, J.A.; Gilbert, A.C. Signal Recovery from Random Measurements Via Orthogonal Matching Pursuit. IEEE Trans. Inf. Theory 2017, 53, 4655–4666. [Google Scholar] [CrossRef] [Green Version]
- Needell, D.; Tropp, J.A. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmon. Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef] [Green Version]
- Figueiredo, M.A.T.; Nowak, R.D.; Wright, S.J. Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems. IEEE J. Sel. Top. Signal Process. 2007, 1, 586–597. [Google Scholar] [CrossRef] [Green Version]
- Wright, S.J.; Nowak, R.D.; Figueiredo, M.A.T. Sparse reconstruction by separable approximation. IEEE Trans. Signal Process. 2009, 57, 2479–2493. [Google Scholar] [CrossRef] [Green Version]
- Daubechies, I.; Defrise, M.; De Mol, C. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 2004, 57, 1413–1457. [Google Scholar] [CrossRef] [Green Version]
- Chao, L.; Han, J.; Yan, L.; Sun, L.; Huang, F.; Zhu, Z.; Wei, S.; Ji, H.; Ma, D. Fast compressed sensing analysis for imaging reconstruction with primal dual interior point algorithm. Opt. Lasers Eng. 2020, 129, 106082. [Google Scholar] [CrossRef]
- Dinh, K.Q.; Jeon, B. Iterative Weighted Recovery for Block-Based Compressive Sensing of Image/Video at a Low Subrate. IEEE Trans. Circuits Syst. 2017, 27, 2294–2308. [Google Scholar] [CrossRef]
- Jiang, D.; Zhang, S.; Dai, L.; Dai, Y. Multi-scale generative adversarial network for image super-resolution. Soft Comput. 2022, 26, 3631–3641. [Google Scholar]
- Shan, B.; Fang, Y. A Cross Entropy Based Deep Neural Network Model for Road Extraction from Satellite Images. Entropy 2020, 22, 535. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, Z.; Ren, Q.; Xu, Y.; Yu, Y. Dense U-net Based on Patch-Based Learning for Retinal Vessel Segmentation. Entropy 2019, 21, 168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, J.; Yuan, W.; Tu, Y. Image compressed sensing using multi-scale residual generative adversarial network. Vis. Comput. 2021. [Google Scholar] [CrossRef]
- Shi, W.; Jiang, F.; Liu, S.; Zhao, D. Image Compressed Sensing Using Convolutional Neural Network. IEEE Trans. Image Process. 2020, 29, 375–388. [Google Scholar] [CrossRef]
- Du, R.; Gkatzikis, L.; Fischione, C.; Xiao, M. Energy Efficient Sensor Activation for Water Distribution Networks Based on Compressive Sensing. IEEE J. Sel. Areas Commun. 2015, 33, 2997–3010. [Google Scholar] [CrossRef]
- Li, S.; Xu, L.D.; Wang, X. Compressed Sensing Signal and Data Acquisition in Wireless Sensor Networks and Internet of Things. IEEE Trans. Industr. Inform. 2013, 9, 2177–2186. [Google Scholar] [CrossRef] [Green Version]
- Rostami, M.; Cheung, N.M.; Quek, T.Q.S. Compressed sensing of diffusion fields under heat equation constraint. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 4271–4274. [Google Scholar]
- Razzaque, M.; Dobson, S. Energy-Efficient Sensing in Wireless Sensor Networks Using Compressed Sensing. Sensors 2014, 14, 2822–2859. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hoover, R.; Daniel, L.; Gonzalo, R.A. Multi-spectral compressive snapshot imaging using RGB image sensors. Opt. Express 2015, 23, 12207–12221. [Google Scholar]
- Canh, T.N.; Jeon, B. Multi-Scale Deep Compressive Sensing Network. In Proceedings of the 2018 IEEE Visual Communications and Image Processing, Taiwan, China, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Yang, Y.; Liu, F.; Li, M.; Jin, J.; Weber, E.; Liu, Q.; Crozier, S. Pseudo-Polar Fourier Transform-Based Compressed Sensing MRI. IEEE. Trans. Biomed. Eng. 2017, 64, 816–825. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Zhang, Z.; Ren, F. LAPRAN: A Scalable Laplacian Pyramid Reconstructive Adversarial Network for Flexible Compressive Sensing Reconstruction. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Shi, W.; Jiang, F.; Liu, S.; Zhao, D. Scalable Convolutional Neural Network for Image Compressed Sensing. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Shi, W.; Jiang, F.; Liu, S.; Zhao, D. Multi-Scale Deep Networks for Image Compressed Sensing. In Proceedings of the 25th IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 46–50. [Google Scholar]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic Decomposition by Basis Pursuit. SIAM Rev. Soc. Ind. Appl. Math. 2001, 43, 129–159. [Google Scholar] [CrossRef] [Green Version]
- Beck, A.; Teboulle, M. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef] [Green Version]
- Afonso, M.V.; Bioucas-Dias, J.M.; Figueiredo, M.A.T. An Augmented Lagrangian Approach to the Constrained Optimization Formulation of Imaging Inverse Problems. IEEE Trans. Image Process. 2011, 20, 681–695. [Google Scholar] [CrossRef] [Green Version]
- Hegde, C.; Indyk, P.; Schmidt, L. A fast approximation algorithm for tree-sparse recovery. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 1842–1846. [Google Scholar]
- Cui, W.; Liu, S.; Jiang, F.; Zhao, D. Image Compressed Sensing Using Non-local Neural Network. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Candes, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Tramel, E.W.; Fowler, J.E. Compressed-sensing recovery of images and video using multihypothesis predictions. In Proceedings of the 2011 Conference Record of the Forty Fifth Asilomar Conference on Signals, Systerms and Computers, Pacific Grove, CA, USA, 6–9 November 2011. [Google Scholar]
- Metzler, C.A.; Mousavi, A.; Baraniuk, R.G. Learned D-AMP: Principled Neural Network Based Compressive Image Recovery. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, J.; Zhao, C.; Gao, W. Optimization-Inspired Compact Deep Compressive Sensing. IEEE J. Sel. Top. Signal Process. 2020, 14, 765–774. [Google Scholar] [CrossRef] [Green Version]
- You, D.; Xie, J.; Zhang, J. ISTA-NET++: Flexible Deep Unfolding Network for Compressive Sensing. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo, Shenzhen, China, 5–9 July 2021. [Google Scholar]
- Zhang, Z.; Liu, Y.; Liu, J.; Wen, F.; Zhu, C. AMP-Net: Denoising-Based Deep Unfolding for Compressive Image Sensing. IEEE Trans. Image Process. 2021, 30, 1487–1500. [Google Scholar] [CrossRef]
- Mousavi, A.; Patel, A.B.; Baraniuk, R.G. A deep learning approach to structured signal recovery. In Proceedings of the 53rd Annual IEEE Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 29 September–2 October 2015; pp. 1336–1343. [Google Scholar]
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. ReconNet: Non-Iterative Reconstruction of Images from Compressively Sensed Measurements. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Shi, W.; Jiang, F.; Zhang, S.; Zhao, D. Deep networks for compressed image sensing. In Proceedings of the IEEE International Conference on Multimedia and Expo, Hong Kong, 10–14 July 2017; pp. 877–882. [Google Scholar]
- Zhou, S.; He, Y.; Liu, Y.; Li, C.; Zhang, J. Multi-Channel Deep Networks for Block-Based Image Compressive Sensing. IEEE Trans. Multimed. 2021, 23, 2627–2640. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | Year | Rate = 1% | Rate = 4% | Rate = 10% | Rate = 25% | Avg. | SD | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| ReconNet | 2016 | 18.09 | 0.4136 | 21.65 | 0.5455 | 24.68 | 0.6770 | 27.42 | 0.7812 | 22.95 | 0.6043 | 3.4743 | 0.1382 |
| ISTA-Net+ | 2018 | 18.51 | 0.4427 | 23.51 | 0.6692 | 28.87 | 0.8437 | 34.69 | 0.9391 | 26.40 | 0.7237 | 6.0297 | 0.1889 |
| SCSNet | 2019 | 24.25 | 0.6469 | 28.98 | 0.8471 | 32.75 | 0.9081 | 36.77 | 0.9622 | 30.69 | 0.8411 | 4.6262 | 0.1193 |
| CSNet* | 2020 | 24.03 | 0.6380 | 28.78 | 0.8215 | 32.33 | 0.9016 | 36.55 | 0.9614 | 30.42 | 0.8306 | 4.6029 | 0.1218 |
| OPINE-Net | 2020 | 21.86 | 0.6010 | 28.06 | 0.8364 | 32.88 | 0.9263 | 37.47 | 0.9617 | 30.07 | 0.8314 | 5.7901 | 0.1406 |
| ISTA-Net++ | 2021 | 20.90 | 0.5310 | 26.52 | 0.7909 | 31.30 | 0.8999 | 36.09 | 0.9554 | 28.70 | 0.7943 | 5.6339 | 0.1631 |
| MR_CSGAN | 2021 | 24.42 | 0.6451 | 28.86 | 0.8310 | 32.85 | 0.9157 | 37.59 | 0.9629 | 30.93 | 0.8387 | 4.8659 | 0.1213 |
| AMP-Net | 2021 | 23.11 | 0.6490 | 28.83 | 0.8376 | 33.40 | 0.9161 | 38.01 | 0.9585 | 30.84 | 0.8403 | 5.5171 | 0.1187 |
| Ours | 24.57 | 0.6696 | 29.32 | 0.8539 | 33.70 | 0.9304 | 37.95 | 0.9658 | 31.38 | 0.8549 | 4.9791 | 0.1144 | |
| Approaches | Year | Rate = 1% | Rate = 4% | Rate = 10% | Rate = 25% | Avg. | SD | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| ReconNet | 2016 | 18.10 | 0.3911 | 20.72 | 0.4890 | 22.89 | 0.5971 | 25.35 | 0.7117 | 21.77 | 0.5472 | 2.6759 | 0.1197 |
| ISTA-Net+ | 2018 | 18.31 | 0.4140 | 22.29 | 0.5851 | 26.36 | 0.7439 | 31.15 | 0.8807 | 24.53 | 0.6560 | 4.7665 | 0.1745 |
| SCSNet | 2019 | 22.84 | 0.5630 | 26.31 | 0.7226 | 29.25 | 0.8180 | 33.21 | 0.9105 | 27.90 | 0.7535 | 3.8128 | 0.1285 |
| CSNet* | 2020 | 22.71 | 0.5561 | 26.15 | 0.7138 | 28.94 | 0.8121 | 33.11 | 0.9009 | 27.73 | 0.7457 | 3.8113 | 0.1279 |
| OPINE-Net | 2020 | 21.47 | 0.5421 | 25.77 | 0.7276 | 29.18 | 0.8409 | 33.43 | 0.9251 | 27.46 | 0.7590 | 4.3970 | 0.1435 |
| ISTA-Net++ | 2021 | 20.43 | 0.4736 | 24.62 | 0.6863 | 28.11 | 0.8131 | 32.37 | 0.9090 | 26.38 | 0.7205 | 4.3981 | 0.1630 |
| MR_CSGAN | 2021 | 23.07 | 0.5623 | 26.54 | 0.7243 | 29.40 | 0.8345 | 33.72 | 0.9261 | 28.18 | 0.7618 | 3.9045 | 0.1355 |
| AMP-Net | 2021 | 22.57 | 0.5733 | 26.61 | 0.7217 | 29.88 | 0.8129 | 34.27 | 0.9210 | 28.33 | 0.7572 | 4.2960 | 0.1275 |
| Ours | 23.20 | 0.5793 | 26.82 | 0.7440 | 29.97 | 0.8522 | 33.95 | 0.9292 | 28.49 | 0.7762 | 3.9615 | 0.1313 | |
| Approaches | Year | Rate = 1% | Rate = 4% | Rate = 10% | Rate = 25% | Avg. | SD | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIN | ||
| ReconNet | 2016 | 19.18 | 0.4026 | 21.25 | 0.4905 | 23.11 | 0.5885 | 25.22 | 0.7031 | 22.19 | 0.5462 | 2.2344 | 0.1119 |
| ISTA-Net+ | 2018 | 19.20 | 0.4054 | 22.22 | 0.5421 | 25.21 | 0.6899 | 30.01 | 0.8451 | 24.16 | 0.6206 | 3.9903 | 0.1641 |
| SCSNet | 2019 | 23.77 | 0.5481 | 26.49 | 0.6935 | 28.61 | 0.7841 | 31.94 | 0.9015 | 27.70 | 0.7318 | 2.9881 | 0.1292 |
| CSNet* | 2020 | 23.71 | 0.5431 | 26.11 | 0.6789 | 28.45 | 0.7779 | 31.69 | 0.8901 | 27.49 | 0.7225 | 2.9476 | 0.1277 |
| OPINE-Net | 2020 | 21.89 | 0.5000 | 25.00 | 0.6673 | 27.55 | 0.7903 | 31.20 | 0.8982 | 26.41 | 0.7140 | 3.4155 | 0.1481 |
| ISTA-Net++ | 2021 | 21.08 | 0.4511 | 24.21 | 0.6340 | 26.85 | 0.7644 | 30.40 | 0.8813 | 25.64 | 0.6827 | 3.4264 | 0.1598 |
| MR-CSGAN | 2021 | 23.85 | 0.5443 | 26.35 | 0.6886 | 28.59 | 0.8018 | 32.28 | 0.9101 | 27.77 | 0.7362 | 3.0982 | 0.1357 |
| Ours | 23.95 | 0.5527 | 26.52 | 0.7010 | 28.92 | 0.8145 | 32.48 | 0.9125 | 27.97 | 0.7452 | 3.1427 | 0.1340 | |
| Methods | Avg. | SD | Platform |
|---|---|---|---|
| ReconNet | 0.0195 s | - | Intel Xeon E5-1650 CPU + NVIDIA GTX980 GPU |
| CSNet | 0.0751 s | - | AMD Core 3700X CPU + NVIDIA RTX3090 GPU |
| SCSNet | 0.0927 s | - | |
| ISTA-Net+ | 0.0174 s | 0.0091 s | Intel Xeon E5-2620 CPU + GeForce RTX1080Ti GPU |
| OPINE-Net | 0.0350 s | 0.0072 s | |
| ISTA-Net++ | 0.0410 s | 0.0103 s | |
| MR-CSGAN | 0.1210 s | 0.0143 s | |
| Ours | 0.0406 s | 0.0095 s |
| Methods | PSNR | |||
|---|---|---|---|---|
| Rate = 1% | Rate = 4% | Rate = 10% | Rate = 25% | |
| w/o MSS | 23.02 | 26.61 | 29.60 | 33.77 |
| w/MSS | 23.20 | 26.82 | 29.97 | 33.95 |
| Methods | Rate = 1% | Rate = 4% | Rate = 10% | Rate = 25% | ||||
|---|---|---|---|---|---|---|---|---|
| Avg. | SD | Avg. | SD | Avg. | SD | Avg. | SD | |
| LMSRB Based | 0.0390 s | 0.0094 s | 0.0398 s | 0.0095 s | 0.0406 s | 0.0095 s | 0.0410 s | 0.0097 s |
| MSRB Based | 0.1189 s | 0.0143 s | 0.1200 s | 0.0142 s | 0.1210 s | 0.0144 s | 0.1219 s | 0.0154 s |
| Setting | Pixel Loss | Adv Loss | Perceptual Loss | PSNR | |
|---|---|---|---|---|---|
| Set5 | Set14 | ||||
| (a) | ✓ | ✕ | ✕ | 33.47 | 29.80 |
| (b) | ✓ | ✓ | ✕ | 33.48 | 29.83 |
| (c) | ✓ | ✕ | ✓ | 33.65 | 29.96 |
| (d) | ✓ | ✓ | ✓ | 33.70 | 29.97 |
| Setting | q | K | V | PSNR | |
|---|---|---|---|---|---|
| Set5 | Set14 | ||||
| (e) | 1 | 0.006 | 0.01 | 33.61 | 29.98 |
| (f) | 1 | 0.006 | 0.0001 | 33.67 | 29.95 |
| (g) | 1 | 0.06 | 0.001 | 32.64 | 29.39 |
| (h) | 1 | 0.0006 | 0.001 | 33.60 | 29.81 |
| (i) | 1 | 0.006 | 0.001 | 33.70 | 29.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Zhu, A.; Xu, Y.; Yin, H.; Hua, G. A Fast Multi-Scale Generative Adversarial Network for Image Compressed Sensing. Entropy 2022, 24, 775. https://doi.org/10.3390/e24060775
Li W, Zhu A, Xu Y, Yin H, Hua G. A Fast Multi-Scale Generative Adversarial Network for Image Compressed Sensing. Entropy. 2022; 24(6):775. https://doi.org/10.3390/e24060775
Chicago/Turabian StyleLi, Wenzong, Aichun Zhu, Yonggang Xu, Hongsheng Yin, and Gang Hua. 2022. "A Fast Multi-Scale Generative Adversarial Network for Image Compressed Sensing" Entropy 24, no. 6: 775. https://doi.org/10.3390/e24060775
APA StyleLi, W., Zhu, A., Xu, Y., Yin, H., & Hua, G. (2022). A Fast Multi-Scale Generative Adversarial Network for Image Compressed Sensing. Entropy, 24(6), 775. https://doi.org/10.3390/e24060775