
The Causality and Uncertainty of the COVID-19 Pandemic to Bursa Malaysia Financial Services Index’s Constituents


Abstract
:1. Introduction
1.1. The Main Market Sectorial Indices and the KLFIN
1.2. Motivation and Impact behind Causal Analysis Using the KLFIN
2. Literature Review
2.1. Bursa Malaysia’s Large-, Mid- and Small-Cap: Performance Comparisons Pre- and Post-COVID-19
2.1.1. Performance of the Caps
2.1.2. The LEAP and the ACE Markets: Inducements of Growth to the Mid- and Small-Caps
2.2. Bursa Malaysia Financial Services Index: Perception and Evolution
2.2.1. Analysis and Performance
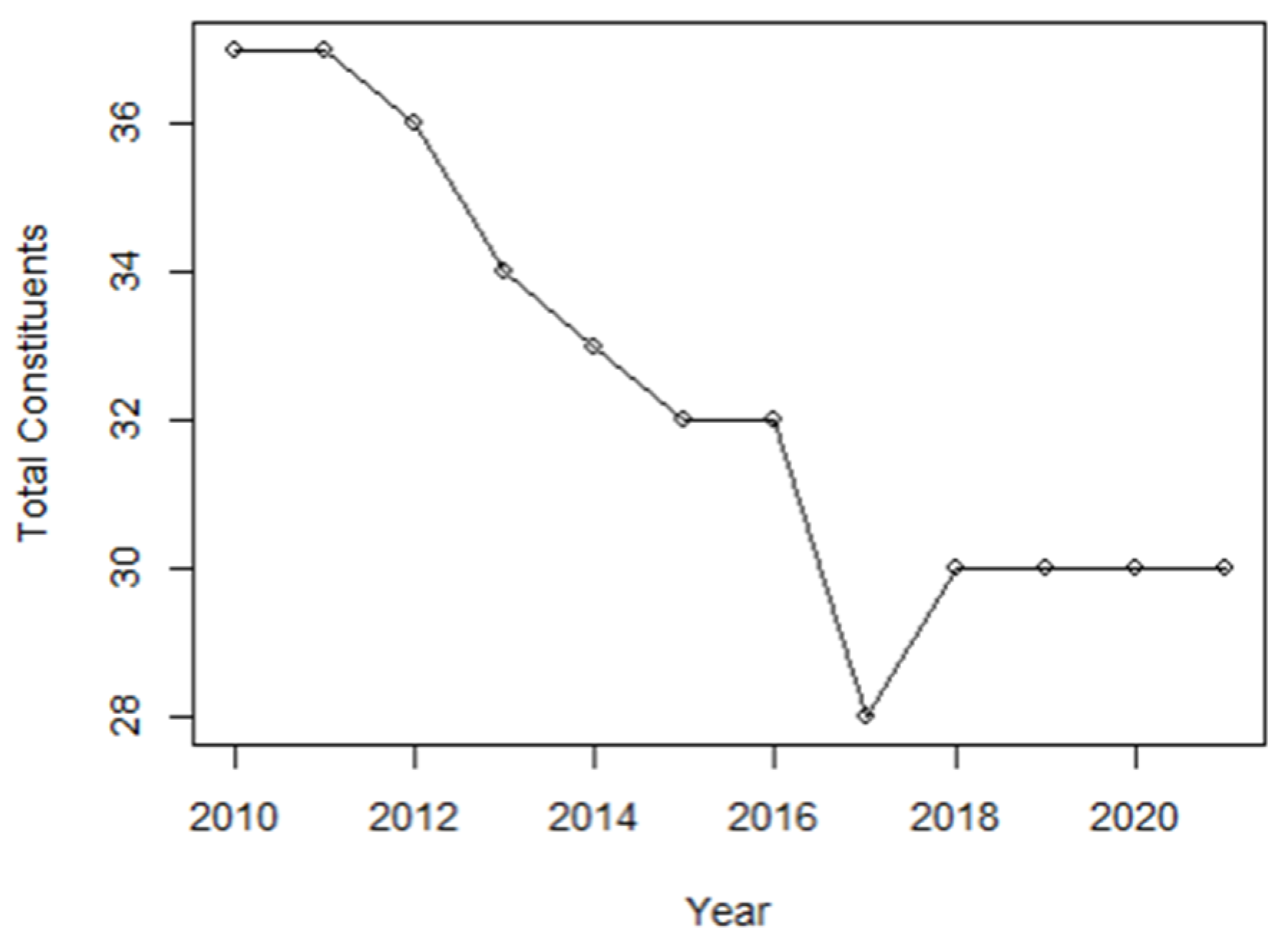
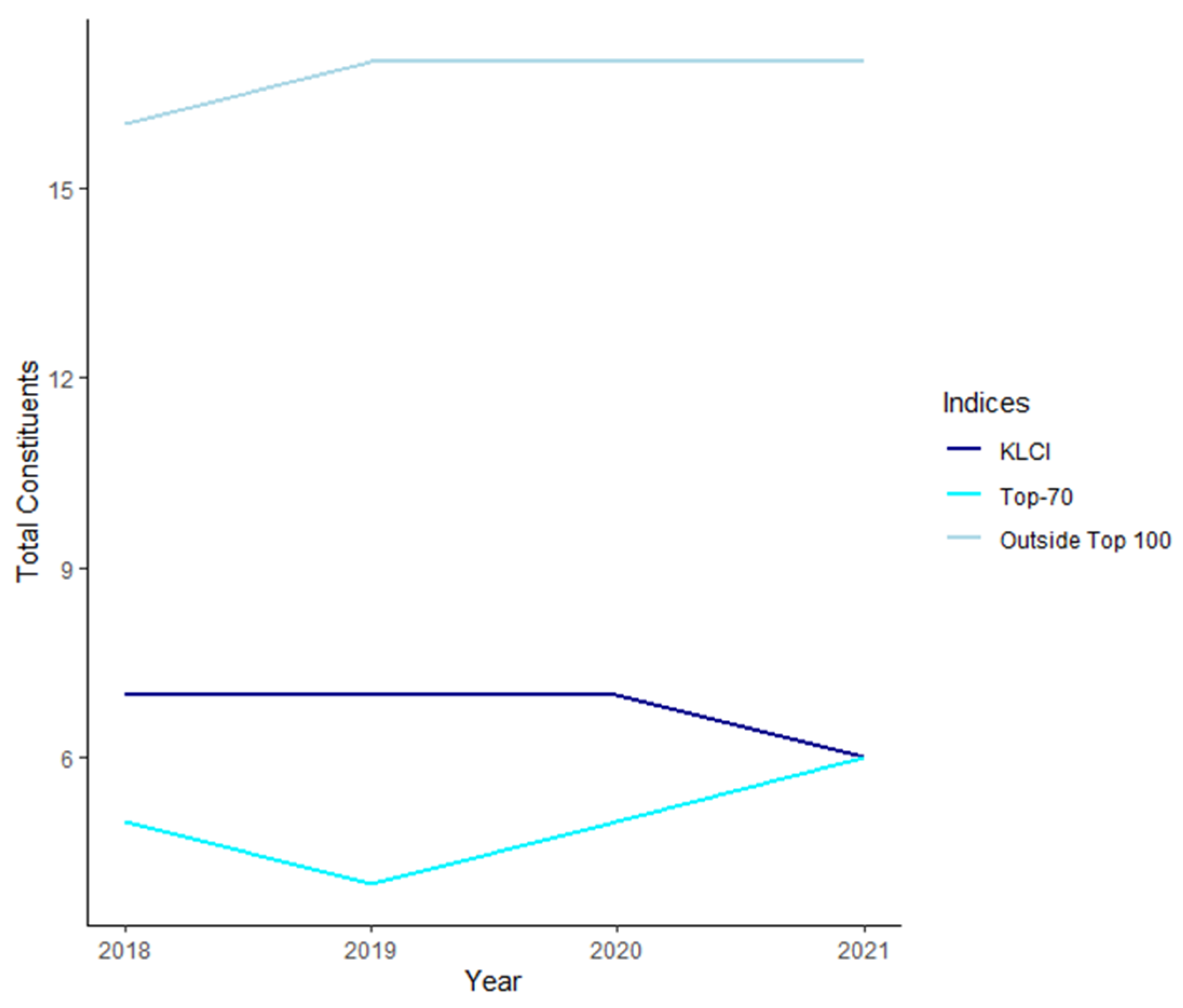
2.2.2. Evolution of the KLFIN’s Total Constitution
2.3. Causality
2.3.1. Causality: Overview, Background and Granger Causality
2.3.2. Causality: A Non-Linear View and the Uncertainty of the Constituents’ Performance
2.3.3. Causality: Effects of Financial Information Flow in International Financial Networks and the COVID-19 Pandemic
3. Methods
3.1. Stock Data
3.2. Data Processing and Testing
3.3. The Lag Time and Binning Criterion
3.3.1. G-Causality’s Lag Time
3.3.2. Transfer Entropy’s Binning
3.3.3. Comparative Criteria
4. Results
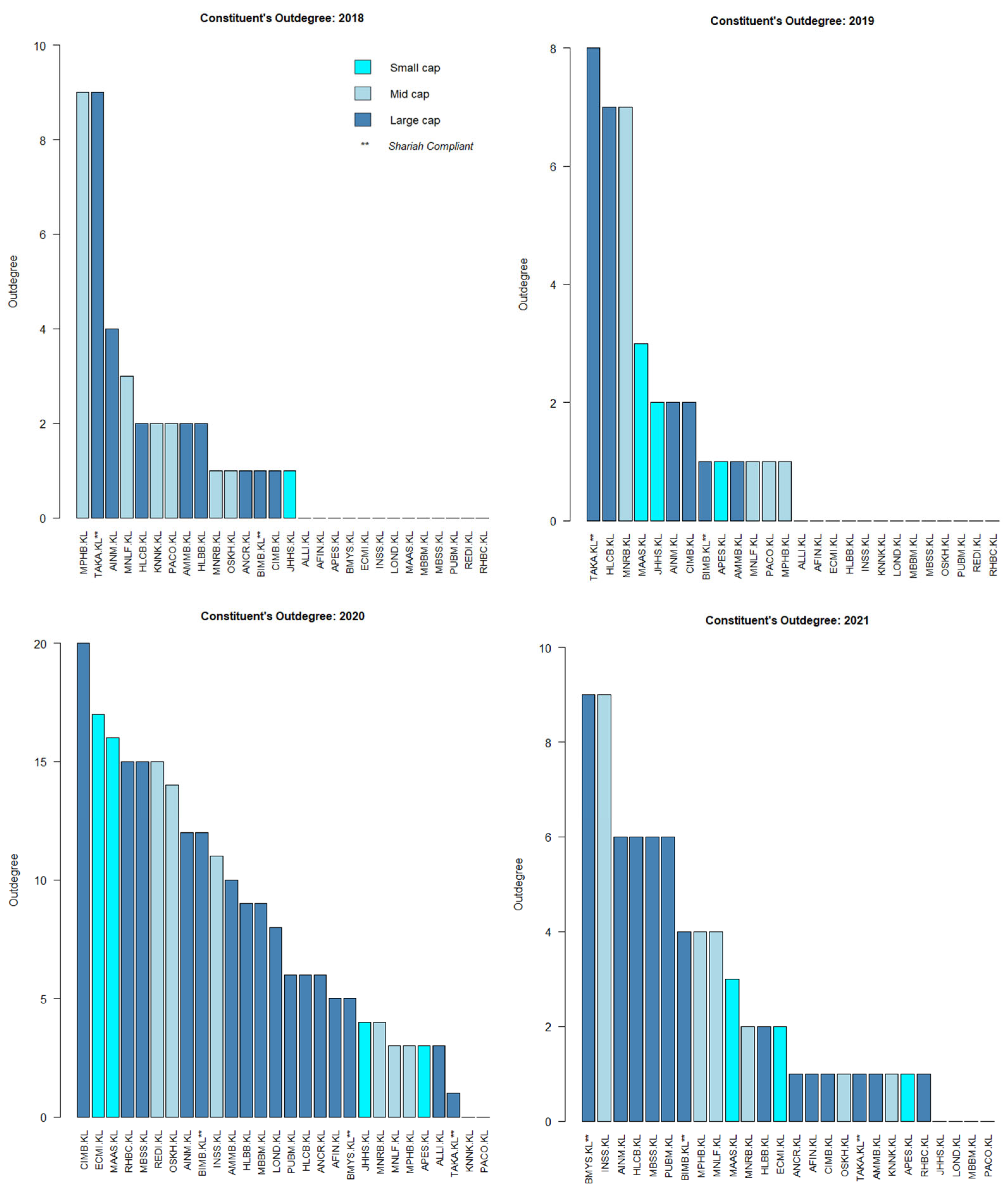
4.1. KLFIN Causality Preliminaries: Processing and G-Causality Distribution
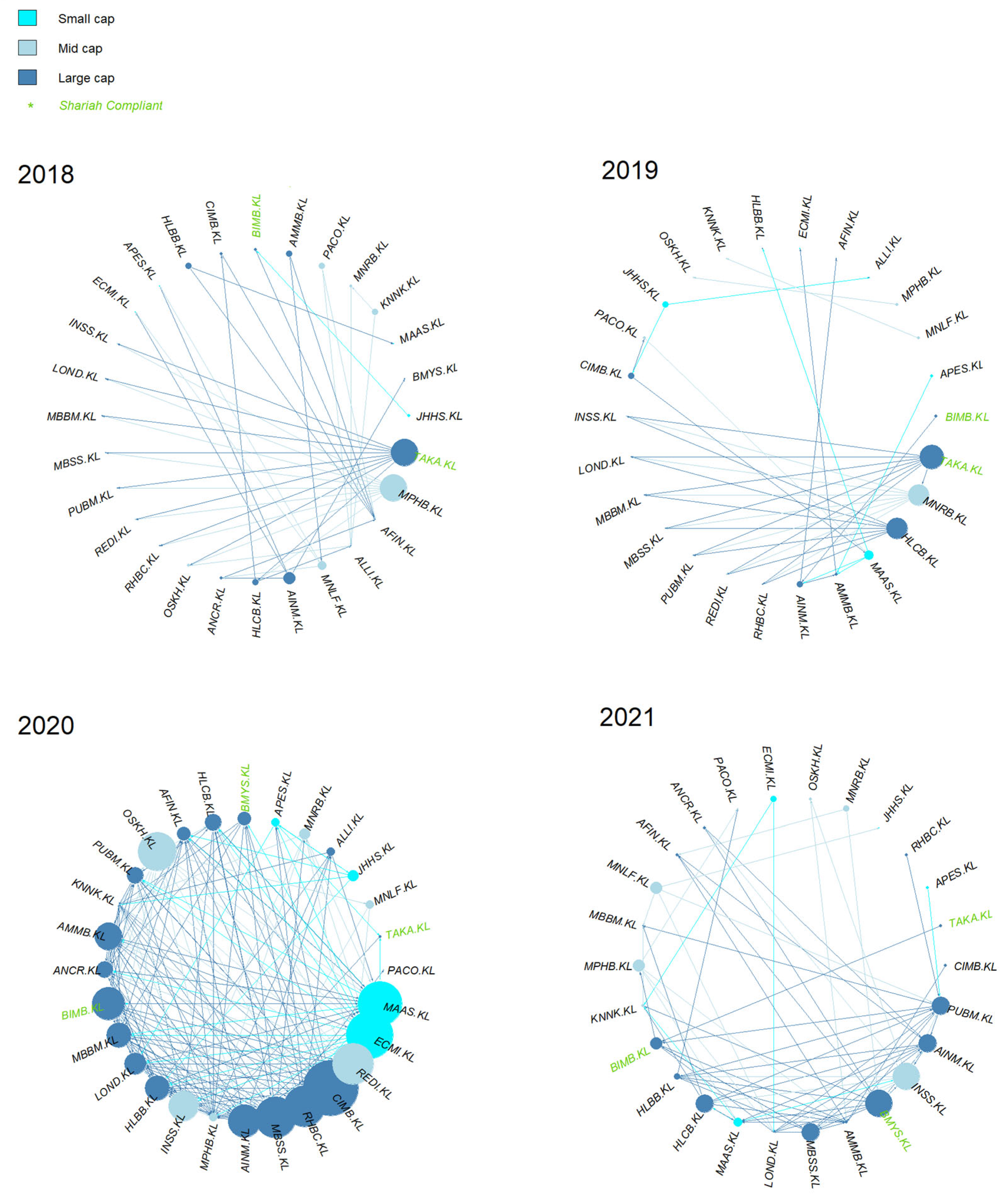
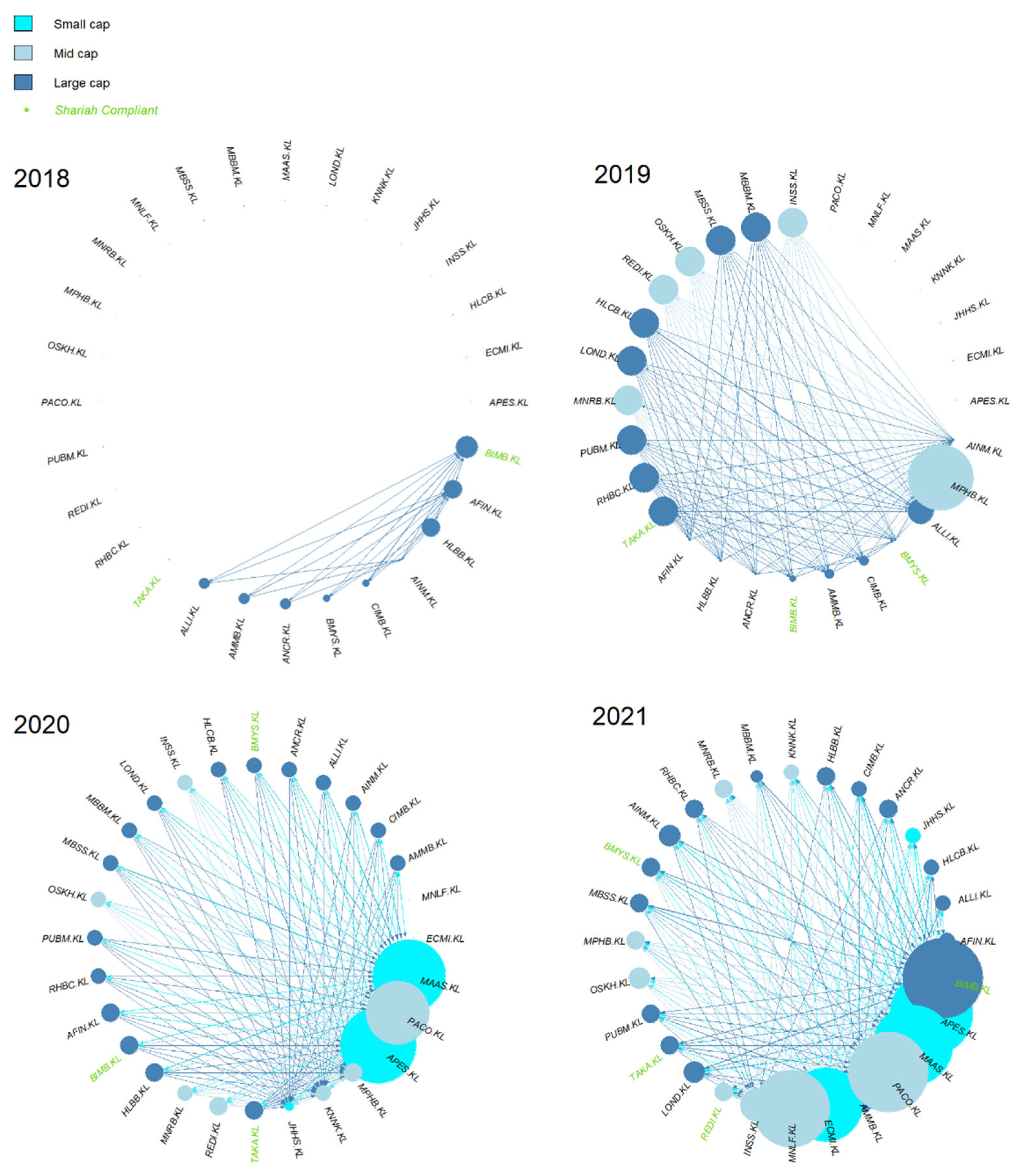
4.2. KLFIN G-Causality Market Capitalization Network
4.3. KLFIN Transfer Entropy Market Capitalization Network
4.4. KLFIN Network by Bursa Malaysia’s Sub-Sector
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. KLFIN Market Capitalization Value and Size

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instrument | Instrument Name | BM Sub-Sector | BM Market Cap (RM) | BM Market Size |
|---|---|---|---|---|
| MBBM.KL | Malayan Banking | Banking | 106.7 B | Large |
| PUBM.KL | Public Bank | Banking | 89.1 B | Large |
| CIMB.KL | CIMB Group Holdings | Banking | 51.6 B | Large |
| HLBB.KL | Hong Leong Bank | Banking | 44.1 B | Large |
| RHBC.KL | RHB Bank | Banking | 24.5 B | Large |
| HLCB.KL | Hong Leong Financial Group | Banking | 22.1 B | Large |
| AMMB.KL | AMMB Holdings | Banking | 10.3 B | Large |
| BIMB.KL | Bank Islam Malaysia ** | Banking | 6.1 B | Large |
| ALLI.KL | Alliance Bank Malaysia | Banking | 5.4 B | Large |
| BMYS.KL | Bursa Malaysia ** | Other Financials | 5.4 B | Large |
| LOND.KL | LPI Capital | Insurance | 5.4 B | Large |
| MBSS.KL | Malaysia Building Society | Other Financials | 4.3 B | Large |
| AFIN.KL | Affin Bank | Banking | 4.1 B | Large |
| ANCR.KL | Aeon Credit Service (M) | Other Financials | 3.8 B | Large |
| TAKA.KL | Syarikat Takaful Malaysia Keluarga ** | Insurance | 2.9 B | Large |
| AINM.KL | Allianz Malaysia | Insurance | 2.3 B | Large |
| OSKH.KL | OSK Holdings | Other Financials | 1.9 B | Mid |
| HLGC.KL | Hong Leong Capital | Other Financials | 1.4 B | Mid |
| REDI.KL | RCE Capital ** | Other Financials | 1.3 B | Mid |
| MPHB.KL | MPHB Capital | Insurance | 1.0 B | Mid |
| MNRB.KL | MNRB Holdings | Insurance | 783.1 M | Mid |
| KNNK.KL | Kenanga Investment Bank | Other Financials | 747.0 M | Mid |
| INSS.KL | Insas | Other Financials | 520.5 M | Mid |
| MNLF.KL | Manulife Holdings | Insurance | 514.1 M | Mid |
| PACO.KL | Pacific and Orient | Insurance | 299.9 M | Mid |
| APES.KL | Apex Equity Holdings | Other Financials | 195.5 M | Small |
| MAAS.KL | MAA Group | Insurance | 135.8 M | Small |
| ECMI.KL | Ecm Libra Group | Other Financials | 87.6 M | Small |
| JHHS.KL | Johan Holdings | Other Financials | 86.4 M | Small |
References
- Sekuriti, Suruhanjaya about the SC. Available online: https://www.sc.com.my/about/about-the-sc (accessed on 1 May 2022).
- Misman, F.N.; Roslan, S.; Mat Aladin, M.I. General Election and Stock Market Performance: A Malaysian Case. Int. J. Financ. Res. 2020, 11, 139–145. [Google Scholar] [CrossRef]
- Sekuriti, Suruhanjaya. SC and Bursa Malaysia Grant Waiver for Companies Seeking to List. Available online: https://www.sc.com.my/resources/media/media-release/sc-and-bursa-malaysia-grant-waiver-for-companies-seeking-to-list (accessed on 1 May 2022).
- Malaysia, Bursa. Initial Public Offering: How Do You Apply? Available online: https://bursaacademy.bursamarketplace.com/en/article/equities/initial-public-offering-how-do-you-apply-1 (accessed on 30 April 2022).
- Malaysia, Bursa. Listing on Bursa Malaysia. Available online: https://www.bursamalaysia.com/listing/get_listed/listing_process (accessed on 30 April 2022).
- Malaysia, Bursa. Going Public: A Practical Guide to Listing on Bursa Malaysia. Available online: https://www.bursamalaysia.com/sites/5d809dcf39fba22790cad230/assets/5ea8ea6339fba25885eecafa/Going_public_guide_2020.pdf (accessed on 30 April 2022).
- Malaysia, Bursa. FTSE Bursa Malaysia KLCI. Available online: https://www.bursamalaysia.com/trade/our_products_services/indices/ftse_bursa_malaysia_indices/ftse_bursa_malaysia_klci (accessed on 4 April 2022).
- Alyasa-Gan, S.S.; Che-Yahya, N. Intended Use of IPO Proceeds and Survival of Listed Companies in Malaysia. J. Risk Financ. Manag. 2022, 15, 145. [Google Scholar] [CrossRef]
- Malaysia, Bursa. Listing on Bursa Malaysia. Available online: https://www.bursamalaysia.com/listing/get_listed/listing_criteria (accessed on 2 May 2022).
- Malaysia, Bursa. Gain Your Share of Wealth on the Stock Market. Available online: https://www.bursamalaysia.com/about_bursa/media_centre/articles/gain-your-share-of-wealth-on-the-stock-market (accessed on 1 May 2022).
- Che-Yahya, N.; Alyasa-Gan, S.S. Explaining Dividend Payout: Evidence from Malaysia’s Blue-Chip Companies. J. Asian Financ. Econ. Bus. 2020, 7, 783–793. [Google Scholar] [CrossRef]
- Mohd Jaapar, A.; Ahmad Chukari, N.; Tarmizi, S.N.S. The Effect of COVID-19 Pandemic on Large-cap Stocks in Malaysia. Malays. J. Sci. Health Technol. 2021, 7, 8–14. [Google Scholar] [CrossRef]
- Sekuriti, Suruhanjaya. Securities Commision Malaysia Annual Report 2021: Capital Market Review and Outlook; Securities Commision Malaysia: Malaysia, 2021; pp. 15–21. [Google Scholar]
- Siti Sarah Alyasa-Gan, N.C.Y. IPO Initial Motivations and Survival of Malaysian Companies. Empir. Econ. Lett. 2021, 2, 103–113. [Google Scholar]
- Shari, W. Survival of the Malaysian initial public offerings. Manag. Sci. Lett. 2019, 9, 607–620. [Google Scholar] [CrossRef]
- Khamis, A.; Seong, C.M.; Xuan, K.; Hang, G.C.; WengHao, W.; Chung, A.Y. Investigate the Effect of Macroeconomics Factor to Malaysian Stock Market Using Granger Causality Analysis. Int. J. Appl. Sci. Res. 2021, 4, 65–72. [Google Scholar]
- Malaysia, Bursa. Understanding Indices. Available online: https://www.bursamalaysia.com/reference/insights/securities/investing_basic/understanding_indices (accessed on 28 May 2022).
- Malaysia, Bursa. Bursa Malaysia Sectorial Index Series. Available online: https://www.bursamalaysia.com/sites/5d809dcf39fba22790cad230/assets/61a6f54b39fba22db47c75b6/BM_Sectorial_Index_Series_Factsheet_Nov21.pdf (accessed on 30 November 2021).
- Group, F.R. FTSE Russell Factsheet: FTSE Bursa Malaysia KLCI. Available online: https://research.ftserussell.com/Analytics/FactSheets/temp/b63173e5-aed2-4d95-99a4-24a8e5beb636.pdf (accessed on 30 April 2022).
- Abdullah, N.I.R. Maybank Traders’ Almanac—KLFIN Index: Consolidation with a Chance of Rebound; Maybank: Malaysia, 2018; pp. 1–7. [Google Scholar]
- Malaysia, Bursa. Anticipation of OPR Hike Spurred Trading in Financial Stocks; Bursa Malaysia: Malaysia, 2022. [Google Scholar]
- Shamsabadi, H.A.; Rasiah, D. An Empirical Study on Performance and Risk-Return Relationship of Industries within Bursa Malaysia. Aust. J. Basic Appl. Sci. 2013, 1, 156–165. [Google Scholar]
- Bank, Public. Public Bank 2018 Annual Report; Public Bank: Malaysia, 2018; pp. 1–302. [Google Scholar]
- Maybank. Maybank Annual Report 2018; Maybank: Malaysia, 2018; pp. 1–141. [Google Scholar]
- Abdullah, N.I.R. Traders ’ Almanac Technical Trading Ideas—KLFIN Rebound off 50-Day EMA Line; Maybank Investment Bank Berhad: Malaysia, 2022; pp. 1–8. [Google Scholar]
- Malaysia, Bursa. Indices Information: BM Financial Services. Available online: https://www.bursamalaysia.com/trade/trading_resources/listing_directory/indices-profile?stock_code=0010I (accessed on 30 April 2022).
- David Ng, C.Y.; Lim, B.K.; Chong, H.L. Sectoral analysis of calendar effects in Malaysia: Post financial crisis (1998–2008). Afr. J. Bus. Manag. 2011, 5, 5600–5611. [Google Scholar] [CrossRef]
- Sekuriti, Suruhanjaya. Senarai Sekuriti Patuh Syariah Oleh Majlis Penasihat Syariah Suruhanjaya Sekuriti Malaysia (25/5/2018); Suruhanjaya Sekuriti Malaysia: Malaysia, 2018; pp. 1–37. [Google Scholar]
- Sekuriti, Suruhanjaya. Senarai Sekuriti Patuh Syariah Oleh Majlis Penasihat Syariah Suruhanjaya Sekuriti Malaysia (30/11/2018); Suruhanjaya Sekuriti Malaysia: Malaysia, 2018; pp. 1–39. [Google Scholar]
- Sekuriti, Suruhanjaya. Senarai Sekuriti Patuh Syariah Oleh Majlis Penasihat Syariah Suruhanjaya Sekuriti Malaysia (29/11/2019); Suruhanjaya Sekuriti Malaysia: Malaysia, 2019; pp. 1–36. [Google Scholar]
- Malaysia, Securities Commission. List of Shariah Compliant Securities (29/5/2020); Suruhanjaya Sekuriti Malaysia: Malaysia, 2020; pp. 1–26. [Google Scholar]
- Malaysia, Securities Commission. List of Shariah Compliant Securities (27/11/2020); Suruhanjaya Sekuriti Malaysia: Malaysia, 2020; pp. 1–30. [Google Scholar]
- Malaysia, Securities Commission. List of Shariah Compliant Securities (28/5/2021); Suruhanjaya Sekuriti Malaysia: Malaysia, 2021; pp. 1–30. [Google Scholar]
- Malaysia, Securities Commission. List of Shariah Compliant Securities (26/11/2021); Suruhanjaya Sekuriti Malaysia: Malaysia, 2021; pp. 1–29. [Google Scholar]
- Granger, C.J.W. Investigating Causal Relations by Econometric Models and Cross-spectral Methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Mutual, Public. Impact of Large- and Small-Cap Stocks on Fund Performance. Available online: https://www.publicmutual.com.my/Menu/Learning-Hub/Impact-of-Large-and-Small-Cap-Stocks-on-Fund-Performance (accessed on 30 April 2022).
- Academy, B. Mid & Small Cap Stocks Deliver Better Returns Over the Long Term. Available online: https://bursaacademy.bursamarketplace.com/en/article/equities/mid-small-cap-stocks-deliver-better-returns-over-the-long-term#:~:text=In%20Malaysia%2C%20mid%20cap%20stocks,capitalisation%20of%20less%20than%20RM200m (accessed on 3 May 2022).
- ifca.asia. Robust Economy Lifts Corporate Earnings. Available online: https://ifca.asia/robust-economy-lifts-corporate-earnings-2/ (accessed on 28 May 2022).
- Yi, L.Y. More than 700 Companies Valued at Below US$100 Million on Bursa. Available online: https://www.theedgemarkets.com/article/more-700-companies-valued-below-us100-million-bursa (accessed on 28 May 2022).
- isaham. Maksud di Sebalik Market Cap. Available online: https://www.isaham.my/blog/maksud-di-sebalik-market-cap (accessed on 28 May 2022).
- Horng, L.M. Small-Mid Caps: Can 2020 Defy The Odds? RHB: Malaysia, 2020; p. 9. [Google Scholar]
- Malaysia, Securities Commission. Securities Commission Malaysia: Capital Market Masterplan 3; Securities Commission Malaysia: Malaysia, 2021; p. 122. [Google Scholar]
- Sekuriti, Suruhanjaya. Securities Commission Malaysia: Annual Report 2020; Securities Commission Malaysia: Malaysia, 2020; pp. 1–219. [Google Scholar]
- Rahman, A.R. Can SMEs Make the Leap? Malaysian Institute of Accountants: Malaysia, 2018; p. 5. [Google Scholar]
- Loke, A. Listing in Malaysia; BT Insight: Malaysia, 2019; pp. 22–23. [Google Scholar]
- Ghasemi, M.; Ab Razak, N.H. Determinants of Profitability in ACE Market Bursa Malaysia: Evidence from Panel Models. Int. J. Econ. Manag. 2017, 11, 847–869. [Google Scholar]
- Refinitiv. Datastream. Datastream Subscription Service. Available online: https://www.refinitiv.com/content/dam/marketing/en_us/documents/fact-sheets/datastream-economic-data-macro-research-fact-sheet.pdf (accessed on 30 April 2022).
- Viandiny, N.U. Analisis Keterkaitan Antar Indeks Harga Saham Sektor Keuangan: Studi Pada Negara Indonesia dan Malaysia. J. Ilm. Mhs. Fak. Ekon. Dan Bisnis Univ. Brawijaya 2017, 5, 9. [Google Scholar]
- Kok, S.C.; Munir, Q.; Lean, H.H. Informational Efficiency of Finance Stocks in Malaysia: A Two-Regime Nonlinear Threshold Autoregressive Approach. Int. J. Bus. Soc. 2019, 10, 59–74. [Google Scholar]
- Ramzani, A. Banking Needs Catalyst But Growth Prevails; Kenanga Research: Malaysia, 2020; pp. 1–12. [Google Scholar]
- Mantegna, R.N. Hierarchical Structure in Financial Markets. Eur. Phys. J. B 1999, 11, 193–197. [Google Scholar] [CrossRef] [Green Version]
- Bressler, S.L.; Seth, A.K. Wiener-Granger Causality: A well established methodology. NeuroImage 2011, 58, 323–329. [Google Scholar] [CrossRef]
- Pearl, J. Causality: Models, Reasoning and Inference, 2nd ed.; Cambridge University Press: USA, 2011; p. 464. [Google Scholar]
- Katerina Hlavácková-Schindler, M.P.M.V.J.B. Causality Detection Based on Information-Theoretic Approaches in Time Series Analysis. Phys. Rep. 2007, 441, 1–46. [Google Scholar] [CrossRef]
- Holland, P.W. Statistics and Causal Inference. J. Am. Stat. Assoc. 1986, 81, 945–960. [Google Scholar] [CrossRef]
- Oxford Learners Dictionaries. Available online: https://www.oxfordlearnersdictionaries.com/definition/english/causality?q=Causality (accessed on 30 April 2022).
- James, R.G.; Barnett, N.; Crutchfield, J.P. Information Flows? A Critique of Transfer Entropies. Phys. Rev. Lett. 2016, 116, 238701. [Google Scholar] [CrossRef]
- Stavroglou, S.; Pantelous, A.; Soramaki, K.; Zuev, K. Causality networks of financial assets. J. Netw. Theory Financ. 2017, 3, 17–67. [Google Scholar] [CrossRef] [Green Version]
- Shojaie, A.; Fox, E.B. Granger Causality: A Review and Recent Advances. Annu. Rev. Stat. Its Appl. 2022, 9, 289–319. [Google Scholar] [CrossRef]
- Chen, P.; Hsiao, C.-Y. Looking behind Granger causality. Munich Pers. RePEc Arch. 2010, 1, 5. [Google Scholar]
- Durcheva, M.; Tsankov, P. Granger causality networks of S&P 500 stocks. AIP Conf. Proc. 2021, 2333, 110014. [Google Scholar] [CrossRef]
- Mun, H.W.; Siong, E.C.; Thing, T.C. Stock Market and Economic Growth in Malaysia: Causality Test. Asian Soc. Sci. 2009, 4, 86–92. [Google Scholar] [CrossRef] [Green Version]
- Ang, J.B.; McKibbin, W.J. Financial liberalization, financial sector development and growth: Evidence from Malaysia. J. Dev. Econ. 2007, 84, 215–233. [Google Scholar] [CrossRef]
- Granger, C.W.J.; Clive, W.J. Granger Prize Lecture: Time Series Analysis, Cointegration, and Applications. Available online: https://www.nobelprize.org/prizes/economic-sciences/2003/granger/lecture/ (accessed on 30 April 2022).
- Barnett, L.; Barrett, A.B.; Seth, A.K. Granger causality and transfer entropy are equivalent for gaussian variables. Phys. Rev. Lett. 2009, 103, 238701. [Google Scholar] [CrossRef] [Green Version]
- Siggiridou, E.; Koutlis, C.; Tsimpiris, A.; Kugiumtzis, D. Evaluation of Granger Causality Measures for Constructing Networks from Multivariate Time Series. Entropy 2019, 21, 1080. [Google Scholar] [CrossRef] [Green Version]
- Stokes, P.A.; Purdon, P.L. A study of problems encountered in Granger causality analysis from a neuroscience perspective. Proc. Natl. Acad. Sci. USA 2017, 114, E7063–E7072. [Google Scholar] [CrossRef] [Green Version]
- Diks, C.; Fang, H. Transfer Entropy for Nonparametric Granger Causality Detection: An Evaluation of Different Resampling Methods. Entropy 2017, 19, 372. [Google Scholar] [CrossRef] [Green Version]
- Zaremba, A.; Aste, T. Measures of Causality in Complex Datasets with Application to Financial Data. Entropy 2014, 16, 2309–2349. [Google Scholar] [CrossRef] [Green Version]
- Diks, C.; Fang, H. A Consistent Nonparametric Test for Granger Non-Causality Based on the Transfer Entropy. Entropy 2020, 22, 1123. [Google Scholar] [CrossRef]
- Raubitzek, S.; Neubauer, T. Combining Measures of Signal Complexity and Machine Learning for Time Series Analyis: A Review. Entropy 2021, 23, 1672. [Google Scholar] [CrossRef]
- Villaverde, A.F.; Ross, J.; Morán, F.; Banga, J.R. MIDER: Network inference with mutual information distance and entropy reduction. PLoS ONE 2014, 9, e96732. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Syczewska, E.M.; Struzik, Z.R. Granger Causality and Transfer Entropy for Financial Returns. Acta Phys. Pol. A 2015, 127, A-129–A-135. [Google Scholar] [CrossRef]
- Marks; Gelder, M. In Reply: Behaviour Therapy. Br. J. Psychiatry 1966, 112, 211–212. [Google Scholar] [CrossRef]
- Liu, A.; Chen, J.; Yang, S.Y.; Hawkes, A.G. The flow of information in trading: An entropy approach to market regimes. Entropy 2020, 22, 1064. [Google Scholar] [CrossRef]
- Maghyereh, A.; Abdoh, H.; Awartani, B. Have returns and volatilities for financial assets responded to implied volatility during the COVID-19 pandemic? J. Commod. Mark. 2021, 26, 100194. [Google Scholar] [CrossRef]
- Guo, X.; Zhang, H.; Tian, T. Development of stock correlation networks using mutual information and financial big data. PLoS ONE 2018, 13, e0195941. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 2, 461–464. [Google Scholar] [CrossRef] [Green Version]
- Baek, S.K.; Jung, W.-S.; Kwon, O.; Moon, H.-T. Transfer Entropy Analysis of the Stock Market. arXiv 2005. [Google Scholar]
- Korbel, J.; Jiang, X.; Zheng, B. Transfer entropy between communities in complex financial networks. Entropy 2019, 21, 1124. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 1991; Volume 1, p. 576. [Google Scholar]
- Behrendt, S.; Dimpfl, T.; Peter, F.J.; Zimmermann, D.J. RTransferEntropy—Quantifying information flow between different time series using effective transfer entropy. SoftwareX 2019, 10, 100265. [Google Scholar] [CrossRef]
- Fiedor, P. Granger-causal nonlinear financial networks. J. Netw. Theory Financ. 2015, 1, 53–82. [Google Scholar] [CrossRef]
- Huang, W.Q.; Wang, D. A return spillover network perspective analysis of Chinese financial institutions’ systemic importance. Phys. A Stat. Mech. Its Appl. 2018, 509, 405–421. [Google Scholar] [CrossRef]
- Chiang, T.C. Evidence of Economic Policy Uncertainty and COVID-19 Pandemic on Global Stock Returns. J. Risk Financ. Manag. 2022, 15, 28. [Google Scholar] [CrossRef]
- Gherghina, Ș.C.; Armeanu, D.Ș.; Joldeș, C.C. Stock market reactions to COVID-19 pandemic outbreak: Quantitative evidence from ARDL bounds tests and granger causality analysis. Int. J. Environ. Res. Public Health 2020, 17, 6729. [Google Scholar] [CrossRef]
- Hayat, M.A.; Ghulam, H.; Batool, M.; Naeem, M.Z.; Ejaz, A.; Spulbar, C.; Birau, R. Investigating the Causal Linkages among Inflation, Interest Rate, and Economic Growth in Pakistan under the Influence of COVID-19 Pandemic: A Wavelet Transformation Approach. J. Risk Financ. Manag. 2021, 14, 277. [Google Scholar] [CrossRef]
- Muhlack, N.; Soost, C.; Henrich, C.J. Does Weather Still Affect The Stock Market?: New Insights Into The Effects Of Weather On Returns, Volatility, And Trading Volume. Schmalenbach J. Bus. Res. 2021, 74, 1–35. [Google Scholar] [CrossRef]
- Azzouza, A. The effect of financial liberalization on Malaysian economic growth. Theor. Appl. Econ. 2021, XXVIII, 19–32. [Google Scholar]
- Hussin, M.Y.M.; Yusof, Y.A.; Muhammad, F.; Razak, A.A.; Hashim, E.; Marwan, N.F. The Integration of Islamic Stock Markets: Does a Problem for Investors. Labu. E-J. Muamalat Soc. 2013, 7, 17–27. [Google Scholar]
- Efendi, R.; Arbaiy, N.; Deris, M.M. A new procedure in stock market forecasting based on fuzzy random auto-regression time series model. Inf. Sci. 2018, 441, 113–132. [Google Scholar] [CrossRef]
- Zakaria, Z.; Shamsuddin, S. Relationship between Stock Futures Index and Cash Prices Index: Empirical Evidence Based on Malaysia Data. J. Bus. Stud. Q. 2012, 4, 103–112. [Google Scholar]
- Mathworks. Trend-Stationary vs. Difference-Stationary Processes. Available online: https://www.mathworks.com/help/econ/trend-stationary-vs-difference-stationary.html (accessed on 27 May 2022).
- Nau, R. Stationarity and Differencing. Available online: https://people.duke.edu/~rnau/411diff.htm (accessed on 25 May 2022).
- Sifat, I.M.; Thaker, H.M.T. Predictive power of web search behavior in five ASEAN stock markets. Res. Int. Bus. Financ. 2020, 52, 101191. [Google Scholar] [CrossRef]
- Nguyen, H.M.; Thai-Thuong Le, Q.; Ho, C.M.; Nguyen, T.C.; Vo, D.H. Does financial development matter for economic growth in the emerging markets? Borsa Istanb. Rev. 2021, 22, 688–698. [Google Scholar] [CrossRef]
- Sahabuddin, M.; Muhammad, J.; Dato’ Hjyahya, M.H.; Shah, S.M.; Rahman, M.M. The co-movement between shariah compliant and sectorial stock indexes performance in bursa Malaysia. Asian Econ. Financ. Rev. 2018, 8, 515–524. [Google Scholar] [CrossRef]
- Caserini, N.A.; Pagnottoni, P. Effective transfer entropy to measure information flows in credit markets. Stat. Methods Appl. 2021. [Google Scholar] [CrossRef]
- Kim, M.; Sayama, H. Predicting stock market movements using network science: An information theoretic approach. Appl. Netw. Sci. 2017, 2, 35. [Google Scholar] [CrossRef] [Green Version]
- Musa, M.H.; Razak, F.A. Directed network of Shariah-compliant stock in Bursa Malaysia. J. Phys. Conf. Ser. 2021, 1988, 012019. [Google Scholar] [CrossRef]
- Keskin, Z.; Aste, T. Information-theoretic measures for non-linear causality detection: Application to social media sentiment and cryptocurrency prices. R. Soc. Open Sci. 2020, 7, 200863. [Google Scholar] [CrossRef]
- Amblard, P.O.; Michel, O.J.J. On directed information theory and Granger causality graphs. J. Comput. Neurosci. 2011, 30, 7–16. [Google Scholar] [CrossRef]
- Malaysia, Bursa. Bursa Malaysia Sector Classification of Applicants or Listed Issuers; Bursa Malaysia: Malaysia, 2021; pp. 1–2. [Google Scholar]
- Malaysia, Bursa. APEX EQ HLD. Available online: https://www.bursamarketplace.com/mkt/themarket/stock/APES/profile (accessed on 15 July 2022).
- Malaysia, Bursa. PACIFIC & ORIENT. Available online: https://www.bursamarketplace.com/mkt/themarket/stock/PACO (accessed on 15 July 2022).
- Malaysia, Bursa. MAA GROUP. Available online: https://www.bursamarketplace.com/mkt/themarket/stock/MAAS/profile (accessed on 15 July 2022).
- Malaysia, Bank Negara. About the Bank. Available online: https://www.bnm.gov.my/introduction (accessed on 1 August 2022).
- Malaysia, Bank Negara. Financial Sector Blueprint 2022–2026; Bank Negara Malaysia: Malaysia, 2022; pp. 1–128. [Google Scholar]
- Abdul Razak, F.; Jensen, H.J. Quantifying ‘causality’ in complex systems: Understanding transfer entropy. PLoS ONE 2014, 9, e99462. [Google Scholar] [CrossRef] [Green Version]
- Papana, A. Connectivity Analysis for Multivariate Time Series: Correlation vs. Causality. Entropy 2021, 23, 1570. [Google Scholar] [CrossRef] [PubMed]
- Razak, F.A.; Jensen, H.J. Estimation of information theoretic measures on the Ising model. AIP Conf. Proc. 2014, 56–61. [Google Scholar] [CrossRef]
- Abdul Razak, F.; Ahmad Shahabuddin, F. Malaysian Household Income Distribution: A Fractal Point of View. Sains Malays. 2018, 47, 2187–2194. [Google Scholar] [CrossRef]
- Razak, F.A. The derivation of mutual information and covariance function using centered random variables. AIP Conf. Proc. 2014, 883–889. [Google Scholar] [CrossRef]
- Lloyd Demetrius, T.M. Robustness and network evolution—An entropic principle. Phys. A Stat. Mech. Its Appl. 2005, 346, 682–696. [Google Scholar] [CrossRef]
- Musa, M.H.; Zuhud, D.A.Z.; Ismail, M.; Bahaludin, H.; Razak, F.A. Correlation and Mutual Information Based Networks of Malaysian Stocks. 2022, 1–20, Work in progress. [Google Scholar]













| Constituent 1 | Constituent 2 | AIC | Wald-Significance’s p-Value | G-Causality |
|---|---|---|---|---|
| MPHB.KL | ALLI.KL | 1 | 0.01278 | Yes |
| MPHB.KL | AFIN.KL | 7 | 0.00105 | Yes |
| MPHB.KL | AMMB.KL | 1 | 0.02037 | Yes |
| MPHB.KL | HLBB.KL | 8 | 0.00002 | Yes |
| MPHB.KL | HLCB.KL | 1 | 0.00000 | Yes |
| MPHB.KL | INSS.KL | 1 | 0.00000 | Yes |
| MPHB.KL | LOND.KL | 1 | 0.00000 | Yes |
| MPHB.KL | MBBM.KL | 1 | 0.00000 | Yes |
| MPHB.KL | MBSS.KL | 1 | 0.00000 | Yes |
| MPHB.KL | OSKH.KL | 1 | 0.00000 | Yes |
| MPHB.KL | PUBML.KL | 1 | 0.00000 | Yes |
| MPHB.KL | REDI.KL | 1 | 0.00000 | Yes |
| MPHB.KL | RHBC.KL | 1 | 0.00000 | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuhud, D.A.Z.; Musa, M.H.; Ismail, M.; Bahaludin, H.; Razak, F.A. The Causality and Uncertainty of the COVID-19 Pandemic to Bursa Malaysia Financial Services Index’s Constituents. Entropy 2022, 24, 1100. https://doi.org/10.3390/e24081100
Zuhud DAZ, Musa MH, Ismail M, Bahaludin H, Razak FA. The Causality and Uncertainty of the COVID-19 Pandemic to Bursa Malaysia Financial Services Index’s Constituents. Entropy. 2022; 24(8):1100. https://doi.org/10.3390/e24081100
Chicago/Turabian StyleZuhud, Daeng Ahmad Zuhri, Muhammad Hasannudin Musa, Munira Ismail, Hafizah Bahaludin, and Fatimah Abdul Razak. 2022. "The Causality and Uncertainty of the COVID-19 Pandemic to Bursa Malaysia Financial Services Index’s Constituents" Entropy 24, no. 8: 1100. https://doi.org/10.3390/e24081100
APA StyleZuhud, D. A. Z., Musa, M. H., Ismail, M., Bahaludin, H., & Razak, F. A. (2022). The Causality and Uncertainty of the COVID-19 Pandemic to Bursa Malaysia Financial Services Index’s Constituents. Entropy, 24(8), 1100. https://doi.org/10.3390/e24081100