

Domain Adaptation Principal Component Analysis: Base Linear Method for Learning with Out-of-Distribution Data

 ,
,  , , , and
, , , and 
Abstract
:1. Introduction
- Select a family of classifiers in data space;
- Choose the best classifier from this family for separating the source domain samples from the target ones;
- The error of this classifier is an objective function for maximization (large classification error means that the samples are indistinguishable by the selected family of classifiers).
2. Background
2.1. Principal Component Analysis with Weighted Pairs of Observations
- Classical PCA, ;
- Supervised PCA for regression task. In case the target attribute of data points is a set of real values , , the choice of weights in Supervised PCA can be adapted accordingly. Thus, we can require that projections of points with similar values of target attribute would have smaller weights, and those pairs of data points with very different target attribute values would have larger weights. One of the simplest choices of the weight matrix, in this case, is .
- Supervised PCA for any supervising task. In principle, the weights can be a function of any standard similarity measure between data points. The closer the desired outputs are, the smaller the weights should be. They can change the sign (from the repulsion of projections, to the attraction, ) or change the strength of projection repulsion.
- Semi-supervised PCA was defined for a mixture of labeled and unlabeled data [27]. In this case, different weights can be assigned to the different types of pairs of data points (both labeled in the same class, both labeled from different classes, one labeled and one unlabeled data point, both unlabeled). One of the simplest ideas here can be that projections of unlabeled data points effectively repulse (have positive weights), while the labeled and unlabeled projections do not interact (have zero weights).
2.2. General Form of Supervised PCA for Classification Task
2.3. Domain Adaptation (DA) Problem for Classification Task
2.4. Validating Domain Adaptation Algorithms
3. Methods
3.1. Semi-Supervised PCA for a Joint Data Set
3.2. Supervised Transfer Component Analysis
3.3. Domain Adaptation Principal Component Analysis Algorithm
3.4. Implementation and Code Availability
- DAPCA model is calculated if a nonempty set of target domain is specified.
- If the set of points of the target domain is specified as empty set, then the function calculates the Supervised PCA model (see Section 2.2).
- If the pair `‘TCA’, is specified then Supervised TCA with attraction coefficient is calculated using the explicitly provided feature space (see Section 3.2).
- a scalar to have the same repulsion for all classes;
- a vector R with the number of elements corresponding to the number of classes to define the repulsion force between classes i and j as ;
- a square matrix with the number of rows and columns corresponding to the number of classes to specify a distinct repulsion force for each pair of classes.
- Standard PCA. This option is not recommended because of the large computation time;
- Normalized PCA accordingly to paper [26];
- Supervised PCA accordingly to paper [26] (with );
- Supervised PCA described in Section 2.2 but with the same repulsion strength for all pairs of classes.
4. Results
4.1. Neural Architectures Used to Validate DAPCA on Digit Image Data
4.2. Testing DAPCA on a Toy 3-Cluster Example
4.3. Validation Test Using Amazon Review Dataset
4.4. Validation Using Handwritten Digit Images Data
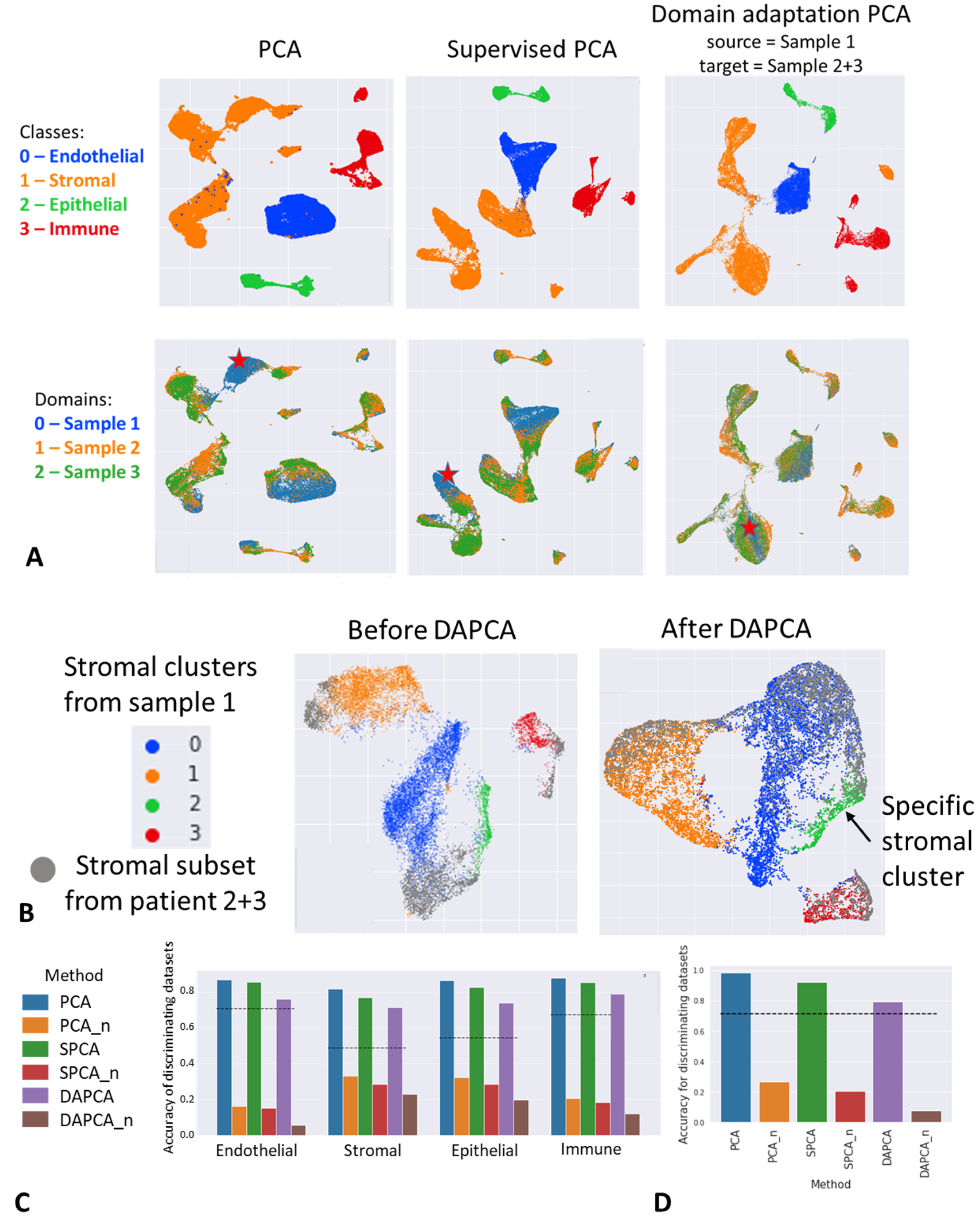
4.5. Application of DAPCA in Single-Cell Omics Data Analysis
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PCA | Principal Component Analysis |
| SPCA | Supervised Principal Component Analysis |
| DAPCA | Domain Adaptation Principal Component Analysis |
| STCA | Supervised Transfer Component Analysis |
| CORAL | Correlation Alignment |
| TCA | Transfer Component Analysis |
| UMAP | Uniform Manifold Approximation and Projection |
| t-SNE | t-distributed Stochastic Neighbor Embedding |
| MACS | Magnetic-Activated Cell Sorting |
| OOD | out-of-distribution |
| MMD | Maximum Mean Discrepancy |
Appendix A. Estimating the Computational and Memory Complexity of Supervised PCA Algorithm
References
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2030–2096. [Google Scholar] [CrossRef] [Green Version]
- You, K.; Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Universal Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Farahani, A.; Voghoei, S.; Rasheed, K.; Arabnia, H.R. A Brief Review of Domain Adaptation. In Advances in Data Science and Information Engineering; Stahlbock, R., Weiss, G.M., Abou-Nasr, M., Yang, C.Y., Arabnia, H.R., Deligiannidis, L., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 877–894. [Google Scholar] [CrossRef]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef] [Green Version]
- Shen, Z.; Liu, J.; He, Y.; Zhang, X.; Xu, R.; Yu, H.; Cui, P. Towards Out-Of-Distribution Generalization: A Survey. arXiv 2021, arXiv:2108.13624. [Google Scholar]
- Chen, M.; Xu, Z.E.; Weinberger, K.Q.; Sha, F. Marginalized Denoising Autoencoders for Domain Adaptation. In Proceedings of the 29th International Conference on Machine Learning, ICML 2012, icml.cc /Omnipress, Edinburgh, Scotland, UK, 26 June–1 July 2012. [Google Scholar]
- Hardoon, D.R.; Szedmak, S.; Shawe-Taylor, J. Canonical Correlation Analysis: An Overview with Application to Learning Methods. Neural Computation 2004, 16, 2639–2664. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neuenschwander, B.E.; Flury, B.D. Common Principal Components for Dependent Random Vectors. J. Multivar. Anal. 2000, 75, 163–183. [Google Scholar] [CrossRef] [Green Version]
- Paige, C.C.; Saunders, M.A. Towards a Generalized Singular Value Decomposition. SIAM J. Numer. Anal. 2006, 18, 398–405. [Google Scholar] [CrossRef]
- Liu, J.; Wang, C.; Gao, J.; Han, J. Multi-view clustering via joint nonnegative matrix factorization. In Proceedings of the 13th SIAM International Conference on Data Mining, Austin, TX, USA, 2–4 May 2013; pp. 252–260. [Google Scholar] [CrossRef] [Green Version]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.P.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by Kernel Maximum Mean Discrepancy. Bioinformatics 2006, 22, e49–e57. [Google Scholar] [CrossRef]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised Visual Domain Adaptation Using Subspace Alignment. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar] [CrossRef] [Green Version]
- Sun, B.; Feng, J.; Saenko, K. Correlation Alignment for Unsupervised Domain Adaptation. In Domain Adaptation in Computer Vision Applications; Csurka, G., Ed.; Springer International Publishing: Cham, Switzerland, 2017; pp. 153–171. [Google Scholar] [CrossRef] [Green Version]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In Computer Vision—ECCV 2016 Workshops; Hua, G., Jégou, H., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 443–450. [Google Scholar]
- Liang, J.; He, R.; Sun, Z.; Tan, T. Aggregating Randomized Clustering-Promoting Invariant Projections for Domain Adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1027–1042. [Google Scholar] [CrossRef]
- Haghverdi, L.; Lun, A.T.; Morgan, M.D.; Marioni, J.C. Batch effects in single-cell RNA-sequencing data are corrected by matching mutual nearest neighbors. Nat. Biotechnol. 2018, 36, 421–427. [Google Scholar] [CrossRef]
- Peyré, G.; Cuturi, M. Computational Optimal Transport: With Applications to Data Science. Found. Trends® Mach. Learn. 2019, 11, 355–607. [Google Scholar] [CrossRef]
- Gorban, A.N.; Grechuk, B.; Mirkes, E.M.; Stasenko, S.V.; Tyukin, I.Y. High-dimensional separability for one-and few-shot learning. Entropy 2021, 23, 1090. [Google Scholar] [CrossRef]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Barshan, E.; Ghodsi, A.; Azimifar, Z.; Zolghadri Jahromi, M. Supervised principal component analysis: Visualization, classification and regression on subspaces and submanifolds. Pattern Recognit. 2011, 44, 1357–1371. [Google Scholar] [CrossRef]
- Rao, C.R. The Use and Interpretation of Principal Component Analysis in Applied Research. Sankhyā: Indian J. Stat. Ser. A 1964, 26, 329–358. [Google Scholar]
- Giuliani, A. The application of principal component analysis to drug discovery and biomedical data. Drug Discov. Today 2017, 22, 1069–1076. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis; Springer: New York, NY, USA, 1986. [Google Scholar] [CrossRef]
- Gorban, A.; Kégl, B.; Wunch, D.; Zinovyev, A. (Eds.) Principal Manifolds for Data Visualisation and Dimension Reduction; Lecture Notes in Computational Science and Engineering; Springer: Berlin, Germany, 2008; p. 340. [Google Scholar] [CrossRef] [Green Version]
- Koren, Y.; Carmel, L. Robust linear dimensionality reduction. IEEE Trans. Vis. Comput. Graph. 2004, 10, 459–470. [Google Scholar] [CrossRef]
- Song, Y.; Nie, F.; Zhang, C.; Xiang, S. A unified framework for semi-supervised dimensionality reduction. Pattern Recognit. 2008, 41, 2789–2799. [Google Scholar] [CrossRef]
- Gorban, A.N.; Mirkes, E.M.; Zinovyev, A. Supervised PCA. 2016. Available online: https://github.com/Mirkes/SupervisedPCA (accessed on 9 September 2016).
- Sompairac, N.; Nazarov, P.V.; Czerwinska, U.; Cantini, L.; Biton, A.; Molkenov, A.; Zhumadilov, Z.; Barillot, E.; Radvanyi, F.; Gorban, A.; et al. Independent component analysis for unraveling the complexity of cancer omics datasets. Int. J. Mol. Sci. 2019, 20, 4414. [Google Scholar] [CrossRef] [Green Version]
- Hicks, S.C.; Townes, F.W.; Teng, M.; Irizarry, R.A. Missing data and technical variability in single-cell RNA-sequencing experiments. Biostatistics 2018, 19, 562–578. [Google Scholar] [CrossRef]
- Krumm, N.; Sudmant, P.H.; Ko, A.; O’Roak, B.J.; Malig, M.; Coe, B.P.; Quinlan, A.R.; Nickerson, D.A.; Eichler, E.E.; Project, N.E.S.; et al. Copy number variation detection and genotyping from exome sequence data. Genome Res. 2012, 22, 1525–1532. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cangelosi, R.; Goriely, A. Component retention in principal component analysis with application to cDNA microarray data. Biol. Direct 2007, 2, 1–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gorban, A.N.; Mirkes, E.M.; Tyukin, I.Y. How deep should be the depth of convolutional neural networks: A backyard dog case study. Cogn. Comput. 2020, 12, 388–397. [Google Scholar] [CrossRef] [Green Version]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A Kernel Two-Sample Test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Lähnemann, D.; Köster, J.; Szczurek, E.; McCarthy, D.J.; Hicks, S.C.; Robinson, M.D.; Vallejos, C.A.; Campbell, K.R.; Beerenwinkel, N.; Mahfouz, A.; et al. Eleven grand challenges in single-cell data science. Genome Biol. 2020, 21, 1–35. [Google Scholar] [CrossRef] [PubMed]
- Argelaguet, R.; Cuomo, A.S.; Stegle, O.; Marioni, J.C. Computational principles and challenges in single-cell data integration. Nat. Biotechnol. 2021, 39, 1202–1215. [Google Scholar] [CrossRef] [PubMed]
- Travaglini, K.J.; Nabhan, A.N.; Penland, L.; Sinha, R.; Gillich, A.; Sit, R.V.; Chang, S.; Conley, S.D.; Mori, Y.; Seita, J.; et al. A molecular cell atlas of the human lung from single-cell RNA sequencing. Nature 2020, 587, 619–625. [Google Scholar] [CrossRef]
- Tsuyuzaki, K.; Sato, H.; Sato, K.; Nikaido, I. Benchmarking principal component analysis for large-scale single-cell RNA-sequencing. Genome Biol. 2020, 21, 9. [Google Scholar] [CrossRef] [Green Version]
- Cuccu, A.; Francescangeli, F.; De Angelis, M.L.; Bruselles, A.; Giuliani, A.; Zeuner, A. Analysis of Dormancy-Associated Transcriptional Networks Reveals a Shared Quiescence Signature in Lung and Colorectal Cancer. Int. J. Mol. Sci. 2022, 23, 9869. [Google Scholar] [CrossRef]
- Bac, J.; Mirkes, E.M.; Gorban, A.N.; Tyukin, I.; Zinovyev, A. Scikit-dimension: A python package for intrinsic dimension estimation. Entropy 2021, 23, 1368. [Google Scholar] [CrossRef]
- Facco, E.; D’Errico, M.; Rodriguez, A.; Laio, A. Estimating the intrinsic dimension of datasets by a minimal neighborhood information. Sci. Rep. 2017, 7, 12140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pestov, V. Is the k-NN classifier in high dimensions affected by the curse of dimensionality? Comput. Math. Appl. 2013, 65, 1427–1437. [Google Scholar] [CrossRef]
- Mirkes, E.M.; Allohibi, J.; Gorban, A.N. Fractional Norms and Quasinorms Do Not Help to Overcome the Curse of Dimensionality. Entropy 2020, 22, 1105. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N.; Sumner, N.R.; Zinovyev, A.Y. Topological grammars for data approximation. Appl. Math. Lett. 2007, 20, 382–386. [Google Scholar] [CrossRef] [Green Version]
- Albergante, L.; Mirkes, E.; Bac, J.; Chen, H.; Martin, A.; Faure, L.; Barillot, E.; Pinello, L.; Gorban, A.; Zinovyev, A. Robust and scalable learning of complex intrinsic dataset geometry via ElPiGraph. Entropy 2020, 22, 296. [Google Scholar] [CrossRef] [Green Version]
- Akinduko, A.A.; Mirkes, E.M.; Gorban, A.N. SOM: Stochastic initialization versus principal components. Inf. Sci. 2016, 364–365, 213–221. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Saul, N.; Großberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Kramer, M.A. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Name | Reference | Principle | Optimi-zation-Based | Low Dimensional Embedding | Use Class Labels in Source |
|---|---|---|---|---|---|
| Principal Component Analysis (PCA) | [20] | Maximizes the sum of squared distances between projections of data points. | yes | yes | no |
| Supervised Principal Component Analysis (SPCA) | [21], this paper | Maximizes the difference between the sum of squared distances between projections of data points in different classes, and the sum of squared distances between projections of data points in the same classes (with weights) | yes | yes | yes |
| Transfer Component Analysis (TCA) | [3] | Minimizes the Minimal Mean Discrepancy measure between projections of source and target | yes | yes | no |
| Supervised Transfer Component Analysis (STCA) | this paper | The optimization functional is the one of SPCA plus the sum of squared distances between the mean vectors of projections of data features is minimized | yes | yes | yes |
| Subspace Alignment (SA) | [13] | Rotation of the k principal components of the source to the k principal components of the target | no | yes | no |
| Correlation Alignment for Unsupervised Domain Adaptation (CORAL) | [14] | Stretches the source distribution onto the target distribution. The source is whitened and then “recolored” to the covariance of the target, without reducing dimensionality. The transformation of the source optimizes the functional , where are the source and target covariance matrices. | yes | no | no |
| Aggregating Randomized Clustering-Promoting Invariant Projections | [16] | Minimizes the dissimilarity between projection distributions plus the mean squared distance of the data point projections from the centroids of their corresponding classes. Pseudolabels are assigned to the target via randomized projection approach and majority vote rule | yes | yes | yes |
| Domain Adaptation PCA (DAPCA) | this paper | DAPCA Maximizes the weighted sum of three following functionals: (a) For the source: the sum of squared distances between projections of data points in different classes and the weighted sum of squared distances between projections of data points in the same classes (as in SPCA). (b) For the target: the sum of squared distances between projections of data points (as in PCA). (c) Between source and target: the sum of squared distances between projection of a target point and its k closest projections from the source. | yes | yes | yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mirkes, E.M.; Bac, J.; Fouché, A.; Stasenko, S.V.; Zinovyev, A.; Gorban, A.N. Domain Adaptation Principal Component Analysis: Base Linear Method for Learning with Out-of-Distribution Data. Entropy 2023, 25, 33. https://doi.org/10.3390/e25010033
Mirkes EM, Bac J, Fouché A, Stasenko SV, Zinovyev A, Gorban AN. Domain Adaptation Principal Component Analysis: Base Linear Method for Learning with Out-of-Distribution Data. Entropy. 2023; 25(1):33. https://doi.org/10.3390/e25010033
Chicago/Turabian StyleMirkes, Evgeny M., Jonathan Bac, Aziz Fouché, Sergey V. Stasenko, Andrei Zinovyev, and Alexander N. Gorban. 2023. "Domain Adaptation Principal Component Analysis: Base Linear Method for Learning with Out-of-Distribution Data" Entropy 25, no. 1: 33. https://doi.org/10.3390/e25010033
APA StyleMirkes, E. M., Bac, J., Fouché, A., Stasenko, S. V., Zinovyev, A., & Gorban, A. N. (2023). Domain Adaptation Principal Component Analysis: Base Linear Method for Learning with Out-of-Distribution Data. Entropy, 25(1), 33. https://doi.org/10.3390/e25010033