1. Introduction
Complex Network Analysis (CNA) is a crucial field that spans various disciplines, addressing network dynamics [
1,
2,
3]. In this context, the focus is on unraveling the complexities of network structure, specifically in the dynamics of link formation. The study delves into three fundamental network attributes: the homophily effect, unobserved heterogeneity, and persistence measures. Homophily, which denotes the tendency of nodes to connect with similar nodes, is a well-established phenomenon in real-world social networks [
4]. However, many node characteristics influencing linking decisions remain unobservable, outnumbering observable ones. To address this challenge, a fixed effect approach to account for unobserved heterogeneity is introduced [
5,
6,
7], as well as persistence measures as tools for quantifying time series data dependence [
8]. These measures hold significant implications for various processes, for example, in information diffusion and ecological networks (see refs. [
1,
9,
10,
11]).
While complex networks offer powerful modeling capabilities, they also present significant challenges. One major hurdle is the lack of a comprehensive metric to effectively measure unobserved heterogeneity, especially in understanding interconnected components [
12]. This metric should consider interaction abundance and latent nature, aligning with existing frameworks [
13,
14]. Furthermore, metrics assessing heterogeneity, both observed and unobserved, are intricately linked to the ways in which nodes are aggregated. From the above, an acute dilemma arises when unobserved heterogeneity is treated as an incidental parameter, independent of node aggregation. In such cases, the parameter vector dimension grows with network size, leading to non-standard estimation challenges, where classical results regarding the properties of maximum likelihood estimates (MLEs) no longer apply [
15]. Additionally, certain models (see, for example, refs. [
7,
16,
17]) disregard interdependencies in network formation. These limitations prompt essential questions: Can we devise a test for evaluating the link formation interdependence hypothesis? Is it feasible to extend the model’s scope to incorporate these interdependencies? How can we address the challenges posed by complex network structures and their inherent uncertainties for a deeper understanding of link formation dynamics?
In this work, we introduce a novel framework to tackle these complex network analysis challenges, where our approach (i) incorporates a discrete latent interaction index that integrates parametric and semiparametric components, shedding light on network formation dynamics.
The realm of network models is diverse, ranging from classical ones [
18,
19,
20] to the more recent advancements [
6,
7,
16]. In the first group of models (I), random networks [
18] aim to probabilistically study graph properties as the number of random connections increases, reflecting the disordered nature of link arrangements between different nodes. We start with the hypothesis that the proposed latent interaction index displaces the possibility of randomness in link formation. We conduct statistical significance tests based on this hypothesis. Additionally, the Watts–Strogatz model [
20] presents a rewiring model that often exhibits high clustering coefficients in “small” networks. On the other hand, the Barabási–Albert model [
19] relies on two ingredients: growth and preferential attachment. The idea is that by mimicking the dynamic mechanisms that assemble the network, we can reproduce the system’s topological properties as observed here. The second group of models (II) has been limited to studying static nonlinear dyadic models and their asymptotic properties. Because the number of individual parameters is proportional to the number of nodes, a problem of incidental parameters results in asymptotic bias [
6]. While the estimator is consistent, asymptotic bias is relevant for inference. We provide a model test based on the prevalence of transitive triads (i.e., node triples where links are transitive). Observed heterogeneity has also been incorporated through dyadic models that expand on this model, just as a probit or logit model generalizes a simple Bernoulli statistical model, which can be used in directed or undirected settings [
21]. It is possible to extend the Erdös–Rényi model to incorporate other features [
5].
Our proposed model seeks to bridge these two groups (I and II), offering a comprehensive approach to network analysis by incorporating the strengths of both.
Additionally, (ii) we present an entropy function dynamically accounting for these components, providing insights into parameters related to persistence and homophily. The estimates derived from this entropy function provide valuable information to characterize the parameters related. This framework enhances our comprehension of link formation within dynamic networks, enabling us to explore the influence of these components on network formation and evolution [
22,
23,
24].
To provide a comprehensive view, it is important to note that each entropy metric used in network analysis offers unique insights into network characteristics and its various components. However, it is widely acknowledged within the field that not all of these metrics can be universally applied to all categories of networks. In fact, this wealth of research is dispersed across numerous disciplines [
1,
17,
22,
23,
25,
26], making it challenging to identify the available metrics and understand the specific contexts in which they are applicable. Additionally, this dispersion complicates our ability to determine areas in need of further development.
These entropy metrics often depend on probability distributions based on various factors, such as node degrees [
27,
28], the degree and strength of node neighbors [
23,
29,
30], or degrees associated with subgraphs of nodes [
31]. Path-based metrics, considering sequences of linked nodes and repetitions of nodes and edges, are also common [
32,
33,
34]. Moreover, entropy metrics explore other factors like closeness and information functionals [
35,
36]. Some metrics rely on probability distribution, including Bayes posterior probability, although specific calculation methods may not always be clear [
37]. Notably, Wang et al. [
38] introduced a combined metric, where the first part is calculated as the sum of closeness centrality and the clustering coefficient.
Ecological research has a long-standing tradition of studying co-occurrence and co-abundance patterns. These patterns often signify non-random species co-occurrence, indicating that interactions play a significant role in community structure—either by fostering aggregation or promoting avoidance/exclusion—thus influencing the overall community dynamics. Macro-ecological interaction networks illustrate that such patterns bolster community robustness and functionality, crucial for comprehending community dynamics and productivity [
25,
39]. Microorganisms engage in diverse relationships, encompassing both antagonistic and cooperative interactions. With the advancements in sequencing technologies, we now have access to substantial datasets for analysis. This allows for the construction of co-occurrence networks using correlation coefficients or similar metrics. However, interpreting these networks, especially in microbial surveys with poorly understood organism behaviors, presents significant challenges [
11,
17,
40].
The complexity of microbial communities makes it challenging to validate community-wide interactions due to the multitude of species and limited experimental approaches. Consequently, modeling microbial populations using simplified growth and interaction rules offers an alternative approach to simulate the dynamics of these intricate multispecies communities. In this study, we consider the model proposal as an application for identifying microbial networks. Concretely, we apply our dynamic network formation model on an 18S rRNA gene amplicon dataset. The original dataset comprises 19 samples, and we observe a total of 3831 OTU (Operative Taxonomic Unity) entries. These observations are obtained through Lagrangian sampling as part of a study conducted by Hu et al. [
40].
This work starts by providing an introduction to our notations, delineating the symbols and conventions used throughout this study. The organization of this paper is as follows: In
Section 2, we present the proposed model; then, in
Section 3, we introduce the entropy function. In
Section 4, simulation results are presented, and in
Section 5 we apply the model focused on the microbial network identification.
Section 6 provides the conclusions and discussions, while all proofs of the theorems and elimination of fixed effects are present in
Appendix A.
Notation 1. Network is an ordered pair of sets V and E, where V is a set finite nonempty of elements named nodes, and the set E is composed of two-element subsets of V named edges. If i and j are connected, constitutes a dyad, and j is a neighbor of i. Along the work, we use notation to indicate , and similarly to indicate .
2. Structural Model
We consider a dynamic group interaction scenario consisting of a large population of connected nodes. We let is the index of a random sample of size N from this population at time . Each node i has a profile defined as , where is an aggregated vector of the observed time-varying characteristics, contains unobserved information assuming the t-invariant. We let be a compact subset of , and is distributed compactly and continuously on the same support, conditional on , i.e., for all , is a compact subset of .
Linking decisions are a binary choice that depends solely on the characteristics of the two nodes connected by the link. We observe relationships between nodes through the indicator variable , where if node j interacts (success) with node i at time t and (failure) otherwise. Parameter can be interpreted as the detection rate of the interaction between nodes i, j. Connections are undirected (i.e., ), and self-ties are ruled out (i.e., for all t). For each , there is a corresponding socio-matrix that captures the interaction dynamics between nodes i and j across all time steps.
We parameterize the latent interaction structure according to the probability of each link
:
where
1 denotes the indicator function. The
q-dimensional vector
with
and
captures the autocorrelation or cumulative nonlinear persistence of the time series [
8]. Variable
is a known transformation of
. This function is symmetric, so that
. For example, if
and
are location coordinates,
is equal to the “distance” between
i and
j. This choice was implemented under the consideration that nodes only form connections if they are close enough [
7,
16,
21]. Vector
is an unknown model parameter that parameterizes homophily preferences. The parameter vector is
, with
being a compact subset of
. Variable
denotes the memory effect of connections that node
i and
j have had in common up to time
t. Variable
is a component that varies with unobserved attributes by node pairs as in Graham’s model [
7], and
represent an idiosyncratic component that is assumed to be independent and identically distributed over time. Moreover, this component is assumed to be independent across pairs, although not necessarily identically distributed; it is
It is important to note that Equation (
1) captures in a parsimonious way three forces that researchers consider important for bond formation [
41]. First, linkages are state dependent; equally, the linkage returns for
i and
j are higher in the current period if they were also connected in previous periods. Second, there are returns to “triadic closure”, profit is higher if transitive aspects are considered in the interaction between nodes. In addition, Rule (
1) is more general instead of taking
and
for all
, which would imply that only direct entailments are important, not autocorrelation and particular incentives for interaction.
The degree of a node is defined as the number of links it possesses, which can be represented as the sum of connections it has with other nodes, and denoted as . The network’s degree sequence is obtained by summing the rows (or columns) of the adjacency matrix, resulting in an vector .
We denote
For parameter values
and
, we define the link probability
.
With the information presented above, we are now able to outline the principal assumptions that significantly influence our work:
Assumption 1. Equations (1) and (2) specify a dynamic model of node interactions. The conditional likelihood of link is given by Here, Assumption 1 implies that the idiosyncratic component of link surplus,
, is a standard logistic random variable that is independently and identically distributed across pairs of nodes. The assumption that links are formed independently of each other based on agent attributes may hold in some situations but not in others. Specifically, Equation (
1) and Assumption 1 are suitable for scenarios where link formation is predominantly bilateral. This is particularly relevant in certain types of friendship and trade networks, as well as in models of specific types of conflicts between nation-states [
42,
43]. In these contexts, the incorporation of unobserved node characteristics into the link formation model represents a significant and useful generalization relative to many commonly used models.
The objective pursued here is to study the identification and estimation problems posed by the shape according to Equation (
1) and Assumption 1. This set encompasses a useful class of empirical examples and represents a natural starting point for a formal statistical analysis. In this context, early methodological work focused on introducing unobserved correlated heterogeneity into static choice models [
44,
45]. Subsequent work incorporated a chance for stated dependence in choice [
46].
The estimated value of the parameters, denoted by
are the solution to the population conditional maximum likelihood problem
for every
. Here,
denotes the expectation with respect to the distribution of the data conditional on the unobserved effects.
Assumption 2. - (i)
Asymptotics: We consider limits of sequences where approaches a constant value c as both N and T rise to infinity, where c is a finite number greater than zero.
- (ii)
Sampling: Conditional on , is independent across the dyad, and for , is the σ-field generated by , and is the σ-field generated by .
- (iii)
Compact support: The support of is a compact subset of .
- (iv)
Concavity: For all , is strictly concave over .
Just for completeness, Assumption 2 (i) defines the large-
T asymptotic framework and is the same as in Hahn and Kuersteiner [
47]. The relative rate exactly balances the order of the bias and variance producing a non-degenerate asymptotic distribution. Assumption 2 (ii) imposes neither identical distribution nor stationarity over the time series dimension, conditional on the unobserved effects, unlike most of the large-
T panel literature [
47]. Additionally, it is used to bound covariances and moments in the application of the Laws of Large Numbers (LLN), as we see below, it could be replaced by other conditions that guarantee the applicability of these results. Assumption 2 (iii) is standard in the context of nonlinear estimation problems [
48]. It implies that the observed component of link surplus,
, has bounded support. This simplifies the proofs of the main theorems, especially those of the ML estimator. Furthermore, (iv) imposes smoothness and moment conditions in the log-likelihood function and its derivatives. These conditions guarantee that the higher-order stochastic expansions of the fixed effect estimator that we use to characterize the asymptotic bias are well-defined, and the remaining terms of these expansions are bounded. In addition, this guarantees that all the elements of
have cross-sectional and time series variation. In addition, it also guarantees that
is the unique solution to the population problem (given by Equation (
6)), that is, all the parameters are point identified. The existence and uniqueness of the solution to the population problem are guaranteed by our Assumptions 2, including the concavity of the objective function in all parameters.
Together with the above, and denoting , through to Parts (iii) and (iv) from Assumption 2 in combination with being a compact subset of , our findings imply that for some and for all and . An implication of this fact is that is a bounded random variable. A more involved argument shows that it is possible to estimate the difference between and with uniform accuracy.
With the aforementioned assumptions in place, we can now elucidate the primary theorems that are providential through the work:
Theorem 1. Under Assumptions 1 and 2,with probability . Theorem 1 suggests that as more data are collected (increasing N) and a broader time horizon is considered (increasing T), the difference between latent variables and observed probabilities becomes relatively small and tends to be more bounded. This interpretation may be relevant for assessing the accuracy or validity of a latent model in relation to real observations within a network. The term in the upper bound can be interpreted as a measure of the uncertainty associated with the difference between latent variables and observations. As N and T grow, uncertainty decreases.
The following theorem is related to a generalized form of the Law of Large Numbers (LLN) adapted to the context of complex networks.
Theorem 2. Under Assumptions 1 and 2, we assume thatis finite for all t and is a filtration with respect to ; then,uniformly in . In the LLN, the average of random variables is expected to converge to the expected value as the sample size grows. In this case, the sum of certain probability functions
for all dyads in the network converges in probability towards a sum of probabilities associated with the dyads. Convergence in probability implies that as the network size (or the number of dyads) grows, the conditional expectation of the discrete choice probabilities approaches the expected value of those probabilities for all dyads. This can have significant implications in the theory of complex networks. For example, the stability of emergent patterns: if the result holds, it implies that as the network grows, emergent patterns in discrete choices may become more stable and predictable, providing a deeper understanding of collective behavior in the network [
49].
3. Exploring the Entropy
Combining Assumption 1 and conditional on
,
and
, we write
for the log-likelihood contribution of link
. Since entropy characterizes the logarithm of the number of different nodes that can be separated in the stochastic dynamics of the network [
37,
50], we use Equation (
8) to provide a new node interaction detection rate. We note that by the asymptotic equipartition property (AEP) (see, e.g., ref. [
51]), we have
converging in probability to the entropy of
C, denoted as
, where
C represents the socio-matrix of the network. Formally,
where the variable
k ranges from 1 to +
∞, indicating that all possible configurations of connections that do not exist between nodes
i and
j are considered. Expression
represents the probability of there not being a connection between nodes
i and
j at time step
t. Therefore, Equation (
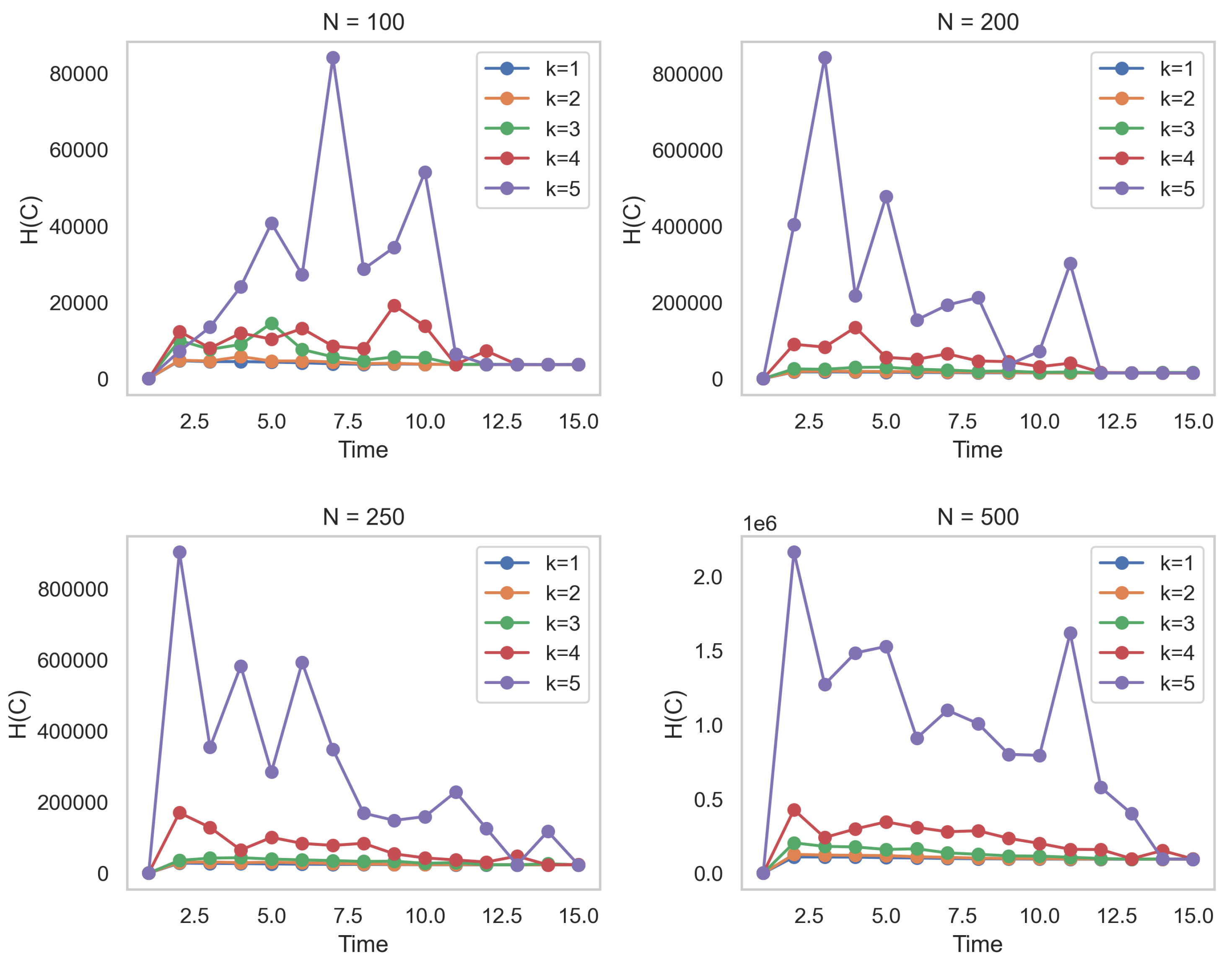
9) combines the influences of both existing and non-existing connections at each time step to compute the entropy of the dynamic network. For the sake of completeness,
Figure 1 shows the behavior of the entropy
for values of
N nodes. It is crucial to note that Equation (
9) comprehensively encompasses the charging capability of the logistics distribution—a facet that some propositions tend to disregard [
52]. For the sake of completeness,
Figure 1 shows the behavior of the entropy
for values of
N nodes.
The following theorems establish consistency of
(Equation (
4)):
Theorem 3. Under Assumptions 1 and 2, we have that Theorem 2 provides a foundation for drawing inferences about the parameter vector encompassing homophily and nonlinear persistence. However, attaining asymptotic normality, for reasons we elaborate on, cannot be guaranteed. The consistency test for models with only individual effects is based on partitioning the log-likelihood into the sum of individual log-likelihoods that depend on a fixed number of parameters, the model parameter, and the corresponding individual effect. The individual log-likelihood maximizers are then consistent estimators of all parameters as they become large according to standard arguments. This approach does not work on network structure because there is no partition of the data that are only affected by a fixed number of parameters and whose size grows with sample size [
6].
To achieve asymptotic normality over the observed, we first need to control for the unobserved and second to establish consistency in the estimated entropy function, which depends on both components.
We assess node performance and select a group of exogenous nodes to serve as a “testing ground”. To achieve this, we examine the conditional expectation of
and
, conditioning on the observable characteristics of node
k, and the characteristics of nodes
i and
j based on
and
. We denote
as the expected value of
and
. According to Parzen’s estimation [
53] and Rosenblatt’s remarks [
54], we define dyadic extension for monadic data by
Here,
is a density function satisfying the following conditions: (i)
for all
x, (ii) symmetric around zero (
), (iii)
if
, and integrates to one (
). Bandwidth
is assumed to be a positive, deterministic sequence that tends to zero as
.
Lemma 1. Under Assumptions 1 and 2, we have .
There are at least two approaches to the estimation of unobserved heterogeneity (fixed effects). The first lies in a computational perspective [
6,
55]. For these purposes, the solution of the (
6) program for
is the same as in the solution of the program that imposes
with
, a vector of
N-ones, directly as a constraint on the optimization, which is invariant to normalization. This constrained program has good computational properties because its objective function is concave and smooth in all the parameters. The second alternative arises from Parzen’s estimations of a density function [
53]. This alternative is also efficient for the estimation of unobserved heterogeneity. The problem of estimating a probability density function over the unobserved is sometimes similar to the problem of estimating maximum likelihood parameters. However, in a network setting, it is more similar to estimating the spectral density function of a stationary process [
53]. Focusing on the second alternative, the following argument shows that it is possible to estimate unobserved heterogeneity with a given probability of occurrence. We consider
as a vector consisting of
. We let
be a Lipschitz function, differentiable, a symmetric kernel function, and
as in Theorem 2.
Theorem 4. Under Lemma 1, we definefor all with being bandwidth. Then, . Chatterjee, Diaconis, and Sly [
56] demonstrated the uniform consistency of estimator
in the model that does not incorporate dyad-level covariates. The key to this theorem is the following: In sparse network sequences, we effectively witness
linking decisions made by each node, which means that we observe whether node
i links to every other node
j. This unique feature of the problem allows for consistent estimation of
for each node. The argument becomes tedious because of the interdependence of the linking decisions in the sequences of nodes
i and
j. However, this dependence is weak, only arising via the presence of
in both link sequences. Establishing asymptotic normality of
is also involved. This is because the sampling properties of
are influenced by the estimation error in
. This influence generates a bias in the limit distribution of
. This bias is similar to that which arises in large
N, large-
T joint fixed effects estimation of non-linear panel data models [
47].
To state the form of the limit distribution, we let and be the entropy computed over the parameter vector and , respectively. Our objective is to estimate quantity within the family of networks that contains nodes i and j. Our estimator is expected to provide a reliable estimate of . Here, we state the following result:
Theorem 5. Under Assumptions 1 and 2,with probability . This inequality demonstrates that our estimator enjoys uniform consistency within class . In simpler terms, it implies that, as our sample size N and time period T increase, the maximum absolute difference between our estimator and the true value across all sets becomes small. The probability that the bound holds is stated to be , meaning that it holds with high probability as the size of the network and the number of time steps grow large. This result provides an upper bound on the discrepancy between the estimated and true entropy, ensuring the reliability of the estimation in the context of the class of networks .
Now, via definition
we are in a position to show
Theorem 6. Under Assumptions 1 and 2, To converge to a normal distribution, the difference between estimator
and true value
has to be bias-corrected and rated proportionally to the number of nodes
N and time
T. In the dense network setting considered here,
is estimated based on the observed linking decisions about
potential links. Therefore, the rate of convergence
is the conventional parametric rate corresponding to the sample size [
5,
7].
We finalize this section showing some functional dimensions of the entropy function, given by
Theorem 7. Under Assumptions 1 and 2, we have that:
- (i)
whereand - (ii)
If and are two filtrations with respect to , thenwhere and
Theorem 7 states that the entropy of the dynamic network C is bounded by the mutual information between successive states of the filtrations and . This means that as the states of the network become more predictable and related to each other, the entropy decreases, implying greater structure and order in the network. Conversely, if the states are more independent and random, the entropy increases, reflecting a more chaotic and less predictable structure in the network.
4. Benchmark and Simulations
In this section, we studied the finite sample performance of procedures in Monte Carlo simulations, where the programming language used for these simulations is Matlab. We compared the development and robustness of our network formation model using the Erdös–Rényi [
18] and Barabási–Albert [
19]-type networks. The Barabási–Albert network was generated with a connection probability of
and a new number of links in each period equal to five. These comparisons were made with the metrics of degree distribution, clustering coefficient, and entropy value. The experiment was based on the latent index formation rule with specification
Here,
,
is a random vector with a norm of less than one and
,
being independent and identically distributed random variables simulated by
, with size networks of 100, 150, 200, 250 and 500. For larger sample sizes, the behavior of the entropy function is, on average, similar. With this specification, nodes with an even index prefer links to nodes with an even index over links to nodes with an odd index, and vice versa for nodes with an odd index. Through 1000 repetitions of the experiment, we show the reproducibility and dynamics of the constructed networks. A 15-step time experiment was proposed. In addition,
with
for all
. The descriptive characteristics of the network formation are shown in
Table 1. Based on
Table 1, we can perform a comparative analysis between the three generated networks.
Mean Degree: The mean degree represents the average number of connections that nodes have in the network. In the simulated network, the mean degree decreases as the network size increases, suggesting that nodes tend to be less connected to each other. This could be influenced by the parameters of the network generation model, such as , , and p, which affect the probability of forming new connections at each time step. On the other hand, the Erdös–Rényi and Barabási–Albert networks maintain their mean degree relatively constant, indicating that their connection generation process is not strongly influenced by network size.
Standard Deviation of Degree: The standard deviation of the degree measures the variability in the number of connections that nodes have in the network. In the simulated network, the standard deviation of the degree tends to decrease as the size of the network increases, implying that node degrees become more homogeneous. This could be a desirable feature in some contexts, as it indicates that the simulated network tends to have a more uniform degree distribution, which is associated with greater robustness and stability in its structure.
Clustering Coefficient: The clustering coefficient measures the proportion of connections that exist between the neighbors of a given node. In the simulated network and Erdöss–Rényi networks, the clustering coefficient tends to decrease as the size of the network increases. This suggests that nodes tend to be less interconnected compared to smaller networks. On the other hand, in the Barabási–Albert network, the clustering coefficient remains at one, indicating that neighboring nodes are highly connected. This result is characteristic of Barabási–Albert scale-free networks, where new nodes tend to preferentially connect to existing nodes with higher degrees, resulting in high clustering among the neighbors of each node.
Regarding the convergence order, it is observed that the simulated network exhibits an intermediate behavior between Erdös–Rényi and Barabási–Albert networks in terms of mean degree and clustering coefficient. While Erdös–Rényi networks are more homogeneous and less clustered, and Barabási–Albert networks are more heterogeneous and highly clustered, the simulated network shows intermediate characteristics, making it suitable for representing systems that contain elements of both tendencies.
Concerning entropy, we validated the development of entropy
across the same number of network sizes over three time periods. We compared the results with Erdös-Rényi entropy [
57] and Shannon entropy [
58].
Table 2 summarizes the results obtained from 1000 simulations. The analysis shows that entropy
performs consistently well across various network sizes and time periods. It demonstrates competitive values compared to Shannon entropy and outperforms Erdös–Renyi entropy significantly. The results indicate that
is a reliable and effective measure to capture the information flow in network dynamics. The lower values obtained by
compared to Shannon entropy suggest that it provides a more informative representation of the network’s complexity. Furthermore, the increasing trend of
with network size indicates that it effectively captures the growing complexity of larger networks, indicating that larger networks tend to have more structure and order. Overall, these findings support the usefulness of
as an entropy measure for analyzing network dynamics and information flow. Higher Shannon entropy values indicate greater diversity or complexity within the networks. In this context, Shannon entropy decreases as the size of the network increases, which implies greater self-organization and less uncertainty within larger networks.
6. Discussion and Conclusions
Motivated to explore the field of CNA, we study the introduction of a latent interaction index, addressing the limitations inherent in traditional compositional similarity indices, taking into account both observed and unobserved heterogeneity per node, particularly in the context of large and complex networks.
This index addresses a limitation in network formation, namely interdependence. The study of complex network formation in the presence of interdependencies is one of the focal points of recent theoretical and empirical research on networks [
5,
7,
16]. However, with the exception of Graham’s [
7] and Dzemski’s [
5] models, none of these papers incorporate unobserved correlated heterogeneity within the modeling framework, unlike the approach used here. The results obtained through the development of this index (Theorems 1 and 2) demonstrate uniform consistency with respect to the homophily parameter vector and fixed effects. This assures us that the proposed index yields statistically replicable results, in line with the principles of the law of large numbers and its applicability across various domains [
2,
25].
Together with the above, we formulate a Shannon-type entropy measure to quantify network density. We further establish optimal boundaries for this measurement by utilizing insights from network topology. Additionally, we present asymptotic properties of pointwise estimation using this entropy function. This analytical approach allows us the application of scrutiny on the structural dynamics of composition, offering valuable insights into the intricate interactions within the network. Here, it is important to note the relevance of dyads contributing to this measure, as a consequence of both observed and unobserved factors. In contrast to some studied entropy measures that do not take these characteristics into account [
23,
27,
29,
34,
36], it might be more useful and comprehensive for future research in various fields to conduct a deeper exploration of what other factors and dimensions could potentially influence the contributions of dyads in the network and, consequently, network entropy.
The results indicate that as network states become more predictable and interconnected, network entropy decreases. This decrease in entropy signifies a greater degree of structure and order within the network. Conversely, when network states exhibit greater independence and randomness, entropy increases, reflecting a more chaotic and less predictable network structure. These findings align with previous research on the interplay between network structure and entropy [
13,
14,
63].
The application of the Shannon-type entropy function provides a robust measure for quantifying network complexity. By establishing optimal bounds for entropy estimation based on network topology, we ensure the accuracy of our analysis and enhance our ability to distinguish networks with varying complexity levels. This contributes to a more nuanced understanding of network dynamics and interactions. Simulations and comparisons with Erdös–Rényi and Barabási–Albert-type networks, in addition to the utilization of Erdös–Rényi and Shannon-type entropy, further validate the effectiveness of our proposed method. Our results demonstrate that the proposed index successfully distinguishes between networks with different degrees of complexity, even outperforming classical models in certain cases [
18,
19].
Despite the inherent complexity of microbiological data [
40,
61], our method offers a promising avenue for studying and comprehending the intricate relationships within these interaction networks and their implications under various parameter specifications. The ecological results presented here are currently under discussion with experts in the field. However, we acknowledge the possibility of simplifications and extensions of the model proposed here.
The theoretical results presented in this article allow us formulation of two statements. First, the interdependence structure in forming complex networks should not be independent of the objective parameters and unobservable node effects. This would enable researchers to discover causal relationships based on these parameters and the network formation itself, complementing some of the discussed network models [
37,
38]. Second, entropy measures on network structures could be more robust and consistent if only the dyads influencing their structure were considered. It is well-known that biased estimates in entropy measures of networks arise from the influence of
false dyads on the system [
64]. The entropy metric presented here is based solely on the contributing dyads of the network.
In conclusion, this approach enables us to capture both observed and unobserved heterogeneity per node, providing a more comprehensive understanding of interactions within ecological communities and other intricate networks. The proposed latent interaction index proves to be an invaluable tool for characterizing the structural dynamics of networks. Additionally, it is feasible to design a test to evaluate interdependencies in link formation. It is more plausible to assume that these interdependencies establish a bounded degree between pairwise interactions [
21,
24]. The proposed model provides feasibility and evidence of how to incorporate these interdependencies, which in many cases are probabilities conditioned on triads (groups of three nodes) [
5,
7]. It is worth noting that these probabilities introduce a bias in the linkage decision [
6]. While work has been extensive in reducing this bias in mono-nodal estimation [
16,
46,
47], little is known about multi-nodal structures. This inherent uncertainty led to the introduction of the entropy function studied here. It possesses the property of reflecting parameter estimates as a function of the true parameters, meaning that the estimated entropy converges to the true entropy. This finding could be a valuable contribution to the challenge of multinodal estimates.







{kind=link}
{kind=link}