
Improved Transformer-Based Dual-Path Network with Amplitude and Complex Domain Feature Fusion for Speech Enhancement

Abstract
:1. Introduction
2. Proposed Dual-Path Speech Enhancement Network
2.1. Encoder
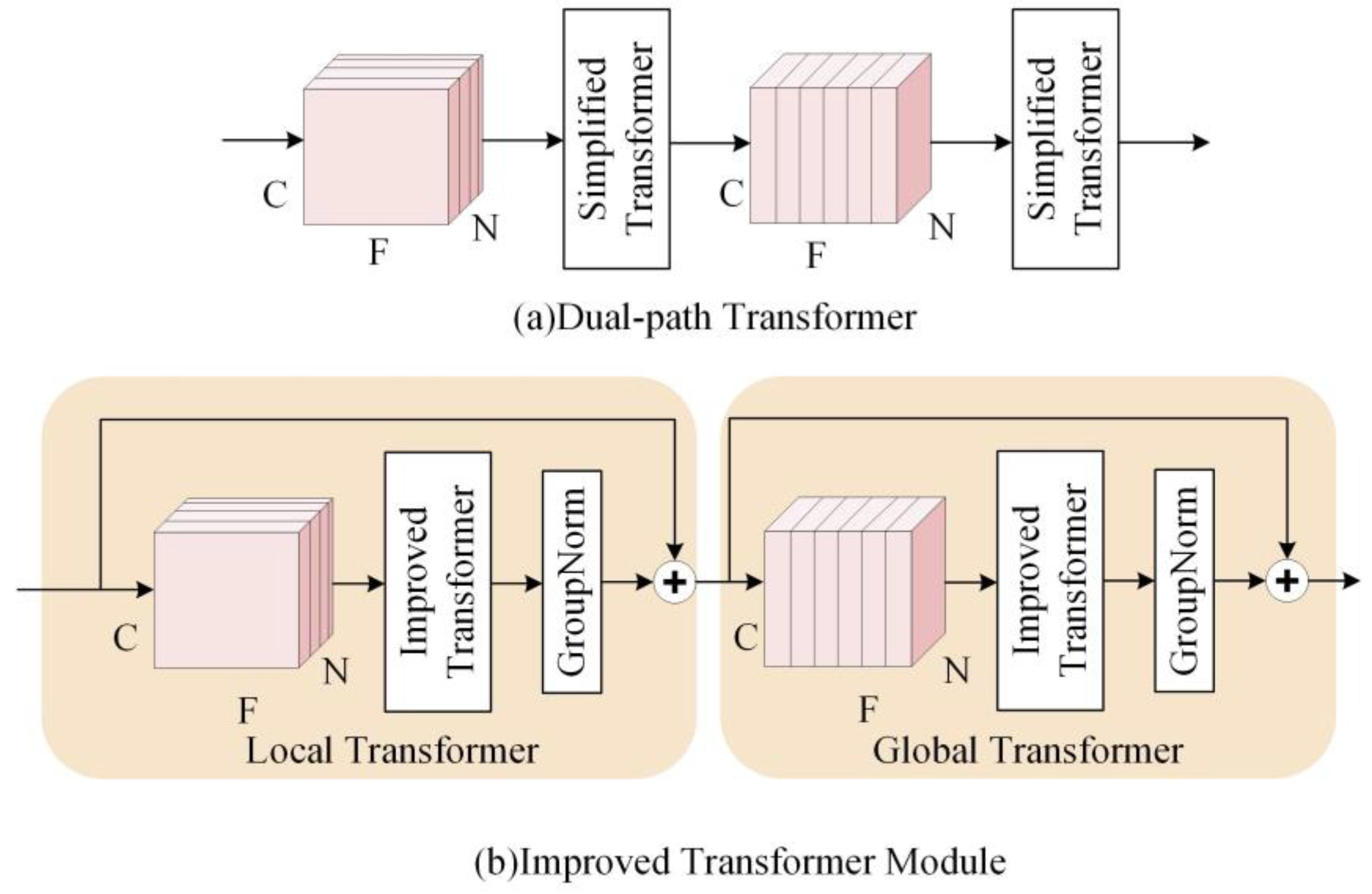
2.2. Improved Transformer Module
2.2.1. Improved Transformer
2.2.2. The Architecture of Improved Transformer Module
2.3. Attention-Aware Feature Fusion Module
2.4. Masking Module
2.5. Decoder
2.6. Loss Function
3. Experimental Setup
3.1. Datasets
3.2. Training Setup
3.3. Evaluation Metrics
4. Results and Analysis
4.1. Comparison with Other Methods
4.1.1. Objective Metrics Comparison
4.1.2. Enhanced Spectrogram Comparison
4.2. Ablation Experiments
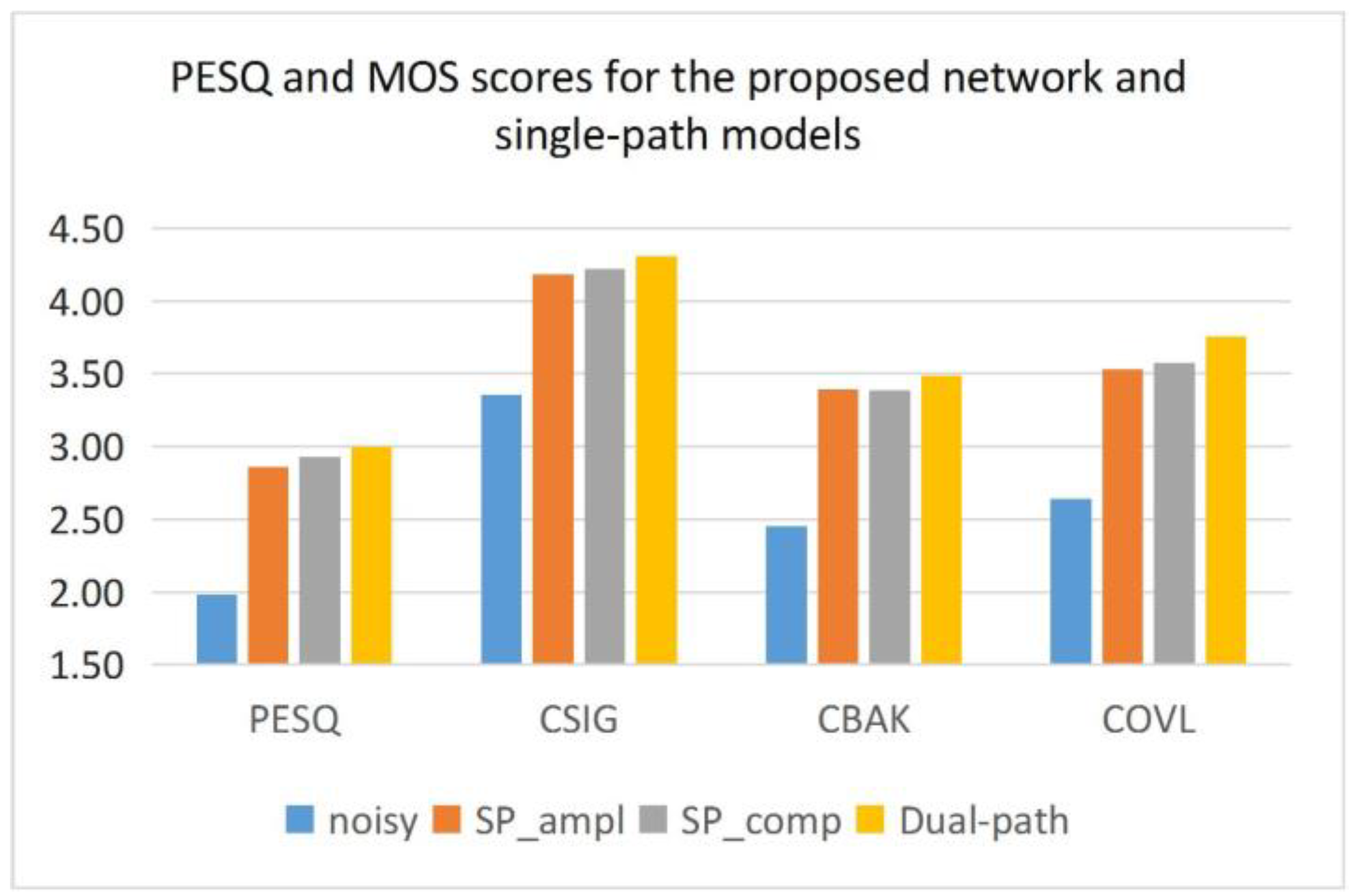
4.2.1. The Superiority of Dual-Path Structure
4.2.2. The Necessity of Improved Transformer Module
4.2.3. The Effectiveness of Attention-aware Feature Fusion Module
4.3. Different Placements of Multiplication Modules on the Effectiveness of the Mask-based Approach
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Taherian, H.; Wang, Z.Q.; Chang, J.; Wang, D. Robust speaker recognition based on single-channel and multi-channel speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1293–1302. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. A generalized subspace approach for enhancing speech corrupted by colored noise. IEEE/ACM Trans. Audio Speech Lang. Process. 2003, 11, 334–341. [Google Scholar] [CrossRef] [Green Version]
- Boll, S. Suppression of acoustic noise in speech using spectral subtraction. IEEE/ACM Trans. Audio Speech Lang. Process. 1979, 27, 113–120. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. De-noising by soft-thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Chen, Z.; Yoshioka, T. Dual-Path RNN: Efficient Long Sequence Modeling for Time-Domain Single-Channel Speech Separation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 46–50. [Google Scholar]
- Fu, S.-W.; Tsao, Y.; Lu, X. SNR-aware convolutional neural network modeling for speech enhancement. In Proceedings of the INTERSPEECH 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 3768–3772. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1701.02477. [Google Scholar]
- Zhao, H.; Zarar, S.; Tashev, I.; Lee, C.-H. Convolutional-Recurrent Neural Networks for Speech Enhancement. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2401–2405. [Google Scholar]
- Braun, S.; Gamper, H.; Reddy, C.K.A.; Tashev, I. Towards Efficient Models for Real-Time Deep Noise Suppression. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 656–660. [Google Scholar]
- Le, X.; Chen, H.; Chen, K.; Lu, J. DPCRN: Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement. arXiv 2021, arXiv:2107.05429. [Google Scholar]
- Wang, H.; Wang, D. Neural cascade architecture with triple-domain loss for speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 734–743. [Google Scholar] [CrossRef] [PubMed]
- Weng, W.; Zhu, X. INet: Convolutional Networks for Biomedical Image Segmentation. IEEE Access 2021, 9, 16591–16603. [Google Scholar] [CrossRef]
- Zhao, S.; Nguyen, T.H.; Ma, B. Monaural Speech Enhancement with Complex Convolutional Block Attention Module and Joint Time Frequency Losses. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6648–6652. [Google Scholar]
- Zhang, G.; Wang, C.; Yu, L.; Wei, J. Multi-Scale Temporal Frequency Convolutional Network with Axial Attention for Multi-Channel Speech Enhancement. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Marina Bay Sands, Singapore, 23–27 May 2022; pp. 9206–9210. [Google Scholar]
- Subakan, C.; Ravanelli, M.; Cornell, S.; Bronzi, M.; Zhong, J. Attention Is All You Need in Speech Separation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 21–25. [Google Scholar]
- Fu, Y.; Liu, Y.; Li, J.; Luo, D.; Lv, S.; Jv, Y.; Xie, L. Uformer: A Unet Based Dilated Complex & Real Dual-Path Conformer Network for Simultaneous Speech Enhancement and Dereverberation. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Marina Bay Sands, Singapore, 23–27 May 2022; pp. 7417–7421. [Google Scholar]
- Wang, K.; He, B.; Zhu, W.P. TSTNN: Two-Stage Transformer Based Neural Network for Speech Enhancement in the Time Domain. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7098–7102. [Google Scholar]
- Xu, Y.; Du, J.; Dai, L.-R.; Lee, C.-H. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 7–19. [Google Scholar] [CrossRef]
- Erdogan, H.; Hershey, J.R.; Watanabe, S.; Roux, J.L. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 708–712. [Google Scholar]
- Lavanya, T.; Nagarajan, T.; Vijayalakshmi, P. Multi-Level Single-Channel Speech Enhancement Using a Unified Framework for Estimating Magnitude and Phase Spectra. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1315–1327. [Google Scholar] [CrossRef]
- Li, A.; Liu, W.; Luo, X.; Zheng, C.; Li, X. ICASSP 2021 Deep Noise Suppression Challenge: Decoupling Magnitude and Phase Optimization with a Two-Stage Deep Network. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6628–6632. [Google Scholar]
- Williamson, D.S.; Wang, Y.; Wang, D. Complex ratio masking for monaural speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 483–492. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y. Survey on Deep Multi-modal Data Analytics: Collaboration, Rivalry, and Fusion. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–25. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, X.; Wang, D. Fusing Bone-Conduction and Air-Conduction Sensors for Complex-Domain Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 3134–3143. [Google Scholar] [CrossRef]
- Luo, Y.; Mesgarani, N. Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Chen, J.; Mao, Q.; Liu, D. Dual-Path Transformer Network: Direct Context-Aware Modeling for End-to-End Monaural Speech Separation. arXiv 2020, arXiv:2007.13975. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional Feature Fusion. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 14 June 2021; pp. 3559–3568. [Google Scholar]
- Li, A.; Liu, W.; Zheng, C.; Fan, C.; Li, X. Two heads are better than one: A two-stage complex spectral mapping approach for monaural speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1829–1843. [Google Scholar] [CrossRef]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Pandey, A.; Wang, D. Densely Connected Neural Network with Dilated Convolutions for Real-Time Speech Enhancement in The Time Domain. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6629–6633. [Google Scholar]
- Valentini-Botinhao, C.; Wang, X.; Takaki, S.; Yamagishi, J. Speech Enhancement for a Noise-Robust Text-to-Speech Synthesis System using Deep Recurrent Neural Networks. In Proceedings of the INTERSPEECH 2016, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Hu, Y.; Loizou, P.C. Evaluation of objective quality measures for speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2008, 16, 229–238. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PESQ | CSIG | CBAK | COVL | SNR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SNR | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 |
| Noisy | 1.43 | 1.77 | 2.11 | 2.61 | 2.62 | 3.15 | 3.59 | 4.05 | 1.79 | 2.22 | 2.63 | 3.17 | 1.96 | 2.42 | 2.84 | 3.34 | 1.75 | 6.28 | 10.97 | 15.94 |
| TSTNN(2) | 2.20 | 2.65 | 2.90 | 3.26 | 3.54 | 3.97 | 4.20 | 4.50 | 2.95 | 3.30 | 3.50 | 3.76 | 2.86 | 3.32 | 3.56 | 3.91 | 15.54 | 17.98 | 19.39 | 20.28 |
| TSTNN(4) | 2.33 | 2.77 | 3.02 | 3.38 | 3.68 | 4.11 | 4.35 | 4.64 | 3.03 | 3.37 | 3.57 | 3.82 | 3.00 | 3.45 | 3.70 | 4.05 | 15.80 | 18.16 | 19.35 | 20.66 |
| Dual-path(1) | 2.45 | 2.91 | 3.14 | 3.49 | 3.83 | 4.24 | 4.45 | 4.72 | 3.08 | 3.42 | 3.61 | 3.84 | 3.14 | 3.59 | 4.15 | 4.15 | 15.73 | 18.13 | 19.41 | 20.65 |
| Dual-path(2) | 2.56 | 3.03 | 3.28 | 3.61 | 3.92 | 4.33 | 4.56 | 4.80 | 3.16 | 3.47 | 3.65 | 3.87 | 3.24 | 3.70 | 3.95 | 4.26 | 15.92 | 18.24 | 19.51 | 20.76 |
| TSTNN(2) | TSTNN(4) | Dual-Path(1) | Dual-Path(2) | |
|---|---|---|---|---|
| Param(million) | 0.7401 | 0.9248 | 0.6602 | 0.7525 |
| PESQ | CSIG | CBAK | COVL | SNR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SNR | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 |
| Noisy | 1.43 | 1.77 | 2.11 | 2.61 | 2.62 | 3.15 | 3.59 | 4.05 | 1.79 | 2.22 | 2.63 | 3.17 | 1.96 | 2.42 | 2.84 | 3.34 | 1.75 | 6.28 | 10.97 | 15.94 |
| SP_ampl | 2.32 | 2.75 | 3.03 | 3.35 | 3.66 | 4.08 | 4.36 | 4.62 | 2.96 | 3.30 | 3.53 | 3.79 | 2.98 | 3.42 | 3.71 | 4.02 | 15.21 | 17.69 | 19.16 | 20.82 |
| SP_comp | 2.38 | 2.83 | 3.11 | 3.41 | 3.70 | 4.12 | 4.43 | 4.63 | 2.96 | 3.36 | 3.56 | 3.66 | 2.99 | 3.43 | 3.79 | 4.09 | 15.44 | 17.90 | 19.00 | 19.96 |
| Dual-path | 2.45 | 2.91 | 3.14 | 3.49 | 3.83 | 4.24 | 4.45 | 4.72 | 3.08 | 3.42 | 3.61 | 3.84 | 3.14 | 3.59 | 4.15 | 4.15 | 15.73 | 18.13 | 19.41 | 20.65 |
| PESQ | CSIG | CBAK | COVL | SNR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SNR | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 |
| noisy | 1.43 | 1.77 | 2.11 | 2.61 | 2.62 | 3.15 | 3.59 | 4.05 | 1.79 | 2.22 | 2.63 | 3.17 | 1.96 | 2.42 | 2.84 | 3.34 | 1.75 | 6.28 | 10.97 | 15.94 |
| No_ITM | 2.23 | 2.70 | 2.95 | 3.30 | 3.60 | 4.07 | 4.30 | 4.60 | 2.93 | 3.29 | 3.48 | 3.71 | 2.91 | 3.40 | 3.64 | 3.98 | 15.22 | 17.69 | 18.98 | 19.96 |
| Dual-path | 2.45 | 2.91 | 3.14 | 3.49 | 3.83 | 4.24 | 4.45 | 4.72 | 3.08 | 3.42 | 3.61 | 3.84 | 3.14 | 3.59 | 4.15 | 4.15 | 15.73 | 18.13 | 19.41 | 20.65 |
| PESQ | CSIG | CBAK | COVL | SNR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SNR | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 |
| Noisy | 1.43 | 1.77 | 2.11 | 2.61 | 2.62 | 3.15 | 3.59 | 4.05 | 1.79 | 2.22 | 2.63 | 3.17 | 1.96 | 2.42 | 2.84 | 3.34 | 1.75 | 6.28 | 10.97 | 15.94 |
| No_AFF | 2.33 | 2.77 | 3.01 | 3.32 | 3.73 | 4.15 | 4.38 | 4.64 | 2.99 | 3.32 | 3.49 | 3.70 | 3.03 | 3.47 | 3.71 | 4.01 | 15.30 | 17.51 | 18.50 | 19.41 |
| Dual-path | 2.45 | 2.91 | 3.14 | 3.49 | 3.83 | 4.24 | 4.45 | 4.72 | 3.08 | 3.42 | 3.61 | 3.84 | 3.14 | 3.59 | 4.15 | 4.15 | 15.73 | 18.13 | 19.41 | 20.65 |
| PESQ | CSIG | CBAK | COVL | SNR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SNR | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 | 2.50 | 7.50 | 12.50 | 17.50 |
| Noisy | 1.43 | 1.77 | 2.11 | 2.61 | 2.62 | 3.15 | 3.59 | 4.05 | 1.79 | 2.22 | 2.63 | 3.17 | 1.96 | 2.42 | 2.84 | 3.34 | 1.75 | 6.28 | 10.97 | 15.94 |
| D_M | 2.34 | 2.77 | 3.00 | 3.37 | 3.53 | 3.99 | 4.26 | 4.57 | 2.95 | 3.31 | 3.51 | 3.83 | 2.91 | 3.38 | 3.63 | 4.01 | 15.63 | 18.10 | 19.33 | 21.35 |
| Dual-path | 2.45 | 2.91 | 3.14 | 3.49 | 3.83 | 4.24 | 4.45 | 4.72 | 3.08 | 3.42 | 3.61 | 3.84 | 3.14 | 3.59 | 4.15 | 4.15 | 15.73 | 18.13 | 19.41 | 20.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, M.; Wan, H. Improved Transformer-Based Dual-Path Network with Amplitude and Complex Domain Feature Fusion for Speech Enhancement. Entropy 2023, 25, 228. https://doi.org/10.3390/e25020228
Ye M, Wan H. Improved Transformer-Based Dual-Path Network with Amplitude and Complex Domain Feature Fusion for Speech Enhancement. Entropy. 2023; 25(2):228. https://doi.org/10.3390/e25020228
Chicago/Turabian StyleYe, Moujia, and Hongjie Wan. 2023. "Improved Transformer-Based Dual-Path Network with Amplitude and Complex Domain Feature Fusion for Speech Enhancement" Entropy 25, no. 2: 228. https://doi.org/10.3390/e25020228
APA StyleYe, M., & Wan, H. (2023). Improved Transformer-Based Dual-Path Network with Amplitude and Complex Domain Feature Fusion for Speech Enhancement. Entropy, 25(2), 228. https://doi.org/10.3390/e25020228