1. Introduction
The increasing popularity of working from home has dramatically intensified Internet traffic. To cope with heavy communication traffic, there are essentially two options. The first option involves an upgrade of the Internet network. This is, however, very expensive and not always available. The second option is much cheaper and employs compression of transmitted symbols. It also makes sense as typical multimedia communication is highly redundant. Source coding has a long history, and it can be traced back to Shannon [
1] and Huffman [
2]. The well-known Huffman code is the first compression algorithm that works very well for symbol sources, whose statistics follow the natural powers of
. Unfortunately, Internet traffic sources almost never have such simple symbol statistics.
Compression algorithms can be divided into two broad categories: lossy and lossless. Lossy compression does not allow users to recover original data but is widely used for multimedia data such as voice, music, video and picture, where a loss of a few least significant bits does not matter. Ahmed et al. [
3] have introduced a lossy compression that applies discrete cosine transform (DCT). The algorithm is now used to compress images (JPEG [
4] and HEIF formats), video (MPEG and AVC formats) and music (such as MP3 and MP4 [
5,
6]). In contrast to lossy compression, a lossless one guarantees the recovery of original data at the receiver side. The lossless compression family includes Huffman code [
2] and its variants (see [
7] for example), arithmetic coding (AC) [
8,
9,
10], Lempel–Ziv compression and its variants [
11,
12,
13], prediction by partial matching (PPM) [
14], run-length encoding (RLE) [
15] and, last but not least, asymmetric numeral systems (ANS) [
16]. Recent developments in quantum technology bring us closer to the construction of real-life quantum computers [
17]. A natural question is whether or not compression of quantum data is feasible [
18,
19]. The question has been answered in the affirmative in the work [
20], which shows how to compress an ensemble of qubits into exponentially fewer qubits. An implementation of quantum compression on IBM quantum computers is reported in the work [
21].
ANS introduced by Duda in [
16] offers a very versatile compression tool. It allows the compression of symbols that occur with an arbitrary probability distribution (statistics). ANS is also very fast in both hardware and software. Currently, ANS is the preferred compression algorithm in the IT industry. It has been adopted by Facebook, Apple, Google, Dropbox, Microsoft, and Pixar, to name a few main IT companies (for details see
https://en.wikipedia.org/wiki/Asymmetric_numeral_systems, accessed on 13 April 2023). ANS can be seen as a finite state machine (FSM) that starts from an initial state, absorbs symbols from an input source one by one and squeezes out binary encodings. The heart of an ANS algorithm is its
symbol spread function (or simply
symbol spread for short) that assigns FSM states to symbols. The assignment is completely arbitrary as long as each symbol
s is assigned a number
of states such that
, where
is probability of the symbol
s and
is the total number of states (
R is a parameter that can be chosen to obtain an acceptable approximation of
by
).
Consequently, there are two closely related problems while designing ANS. The first, called quantisation, requires from the designer to approximate a symbol probability distribution by its approximation , where is the set of all symbols (also called an alphabet). It is expected that ANS implementation for achieves a compression ratio that is as close as possible to the symbol source entropy. The second problem is the selection of a symbol spread for fixed ANS parameters. It turns out that some symbol spreads are better than others. Again, an obvious goal is to choose them in such a way that the average encoding length is as small as possible and close to the symbol source entropy.
Motivation. Designers of ANS have to strike a balance between efficiency and compression quality. The first choice that has to be made is how closely symbol probabilities need to be approximated by . Clearly, the bigger the number of states (), the better approximation and better compression. Unfortunately, a large L slows down compression. It turns out that the selection of a symbol spread has an impact on the quality of compression. For some applications, this impact cannot be ignored. This is true when ANS is applied to build a pseudorandom bit generator. In this case, the required property of ANS is minimal coding redundancy. Despite the growing popularity of ANS, there is no proof of its optimality for arbitrary symbol statistics. This work does not aim to prove optimality, but rather, it aims to develop tools that allow us to compare the compression quality of different ANS instances. It means that we are able to adaptively modify ANS in such a way that every modification provides a compression ratio gain (coding redundancy reduction). The following issues are the main drivers behind this work:
Investigating symbol quantisation and its impact on compression quality.
Understanding the impact of a chosen symbol spread on the ANS compression ratio.
Designing an algorithm that allows us to build ANS instances that maximise compression ratio or equivalently minimises coding redundancy.
Contributions. They are as follows:
The application of Markov chains to calculate ANS compression ratios. Note that Markov chains have been used in ANS analysis previously. The work [
22] applies them for analysis of ANS-based encryption while the paper [
23] uses Markov chains to prove the asymptotic optimality of ANS.
Designing “good” ANS instances whose state probabilities follow the approximation , where x is an ANS state.
A randomised algorithm that permits the building of ANS, whose compression ratio is close or alternatively equal to the best possible. The algorithm uses a pseudorandom number generator (PRNG) as a random “coin”.
An improvement of the Duda–Niemiec ANS cryptosystem that selects at random ANS instances with best compression ratios.
The rest of the work is organised as follows.
Section 2 puts the work in the context of the known source coding algorithms.
Section 3 describes the ANS compression and its algorithms.
Section 4 studies the optimality of ANS.
Section 5 shows how Markov chains can be used to calculate ANS state equilibrium probabilities and, consequently, average lengths of ANS encodings.
Section 6 presents an algorithm that produces ANS instances whose state probabilities follow the approximation
.
Section 7 describes an algorithm that permits obtaining the best (or close to it) compression ratio.
Section 8 suggests an alternative to the Duda–Niemiec ANS encryption. The alternative encryption called cryptographic ANS allows us to design an ANS secret instance whose compression ratio is close to the best one.
Section 9 presents the results of our experiments and finally,
Section 10 concludes our work.
2. Arithmetic Coding versus Asymmetric Numeral Systems
Two variants of ANS (tabled tANS and range rANS) are often used as a direct replacement not only for Huffman coding to improve compression ratio but also for arithmetic coding (AC [
8,
9,
10]) to improve speed. In contrast to Huffman coding (which can handle whole bits only), AC and ANS can process fractions of bits. This requires an additional buffer to store bit fractions and accumulate them until getting a whole bit, which is next released into the output bitstream. AC applies a buffer that stores a range represented by two numbers whose length depends on the probability of encoded symbols. On the other hand, ANS maintains a buffer with a single natural number, whose length reflects both the probability of the encoded symbol and the previous contents of the buffer. In other words, compared to AC, ANS needs a single number only to store the current state.
For both AC and ANS, there are two possible implementation options. The first applies basic arithmetic operations (addition, multiplication and division) performed on large states very close to Shannon entropy. This option has a lower memory cost and is convenient for vectorisation in CPU/GPU architectures. More importantly, it allows for the modification of symbol probabilities on the fly. This option is used in both AC and rANS. The second option translates compression into FSM. It avoids arithmetic operations (especially multiplication) and is recommended for fixed symbol probability distributions. Importantly, it allows for joint compression and encryption. This option is used by quasi-AC, M coder, and tANS.
2.1. Arithmetics: AC versus rANS
A classical AC for binary alphabet (bitwise) uses one multiplication per symbol and two for a large alphabet. In contrast, rANS uses one multiplication per symbol no matter how big the alphabet is. This is true for the rANS decoder, as its encoder requires integer division, which is notoriously expensive on most CPU architectures. However, in many applications, decoding speed is more important than encoding speed. One of the fundamental differences between AC and ANS is encoding and decoding orders. For AC, the orders are the same, while for ANS, decoding is executed in reverse. This means that AC is advantageous for some applications, such as streaming. On the other hand, the ANS reverse decoding order enables methods such as the alias method (
https://fgiesen.wordpress.com/2014/02/18/rans-with-static-probability-distributions, accessed on 13 April 2023) and the BB-ANS method of Townsend et al. [
24], which are not possible with AC. rANS uses a state determined by a single natural number that makes low-level optimisation and vectorisation possible. In contrast, AC has to keep two numbers that define a state and a current range.
In practice, rANS is used for relatively large alphabets ranging from
to
symbols, whose probability distribution needs a regular update. For static probability distribution, rANS applies alphabets with 256 symbols. It also copes very well with much larger alphabets with, say,
symbols [
25]. An obvious advantage of a large alphabet used in rANS is a reduction of the required number of steps. Consider two alphabets: one with two and the other with 256 symbols. The number of steps for the larger alphabet can then be reduced by the factor of 8, and there is no need for binary conversion of states. A drawback of rANS with large alphabets is the growing size of tables and an increase in the number of variables. A typical compromise to cope with the dilemma is to deploy byte-oriented arithmetics.
In contrast, AC is usually applied for binary alphabets [
26,
27]. As we have already pointed out, this creates a significant computational overhead as symbols of large alphabets need to be represented in binary. Fortunately, AC can also work directly with large alphabets. This is referred to as range coding. Note that the implementation of both AC and rANS requires a similar number of operations (with the exception that rANS needs a single multiplication per symbol while AC needs two). However, the main advantage of rANS over AC is a shorter state. A state for AC is determined by two numbers, while a state for rANS consists of a single integer. Moreover, rANS is easier to parallelise due to the fact that the decoder goes through the exact same states as the encoder (albeit in reverse order) [
28]. Consequently, rANS low-level implementations can be easily optimised and vectorised (SIMD, GPU).
2.2. FSM Representation: Quasi-AC, M Coders and tANS
It turns out that the most expensive arithmetic operation applied in compression is multiplication. To improve efficiency, the idea is to eliminate multiplication altogether. This can be done for a majority of popular entropy coders with a relatively small number of states. As an entropy coder can be seen as FSM, it is enough to determine its state-transition table. An encoding table accepts a pair (symbol, current state) and outputs (binary encoding, next state). Clearly, there must exist a corresponding decoding table that reverses encoding. Quasi-AC is an example of an FSM representation for AC (
https://kuscholarworks.ku.edu/bitstream/handle/1808/7210/HoV93.qtfull.pdf;sequence=1, accessed on 13 April 2023). There is also a very popular 64-state M coder (
https://iphome.hhi.de/marpe/mcoder.htm, accessed on 13 April 2023), which is the core of the Context Adaptive Binary Arithmetic Coder (CABAC). The coder is used in MPEG video compressors. As far as we know, all FSM variants of AC are restricted to binary alphabets. Theoretically, larger alphabets can also be converted into their binary equivalents. However, the number of states would be much larger than for ANS as each AC state consists of a pair of numbers (the range). In contrast, thanks to single-number states, ANS can be easily converted into its FSM equivalent for a large alphabet. Table-based ANS (tANS) usually uses from 4 to 8 times more states than the alphabet size. It means that for an alphabet containing 256 symbols, tANS needs 2048 states. This tANS variant is used in a popular FSE implementation of the Zstandard compressor and it rebuilds encoding/decoding tables for every new symbol frame (30 kB in length).
2.3. LIFO Handling and Statistical Modelling
ANS works according to the last-in-first-out (LIFO) principle. This technical difficulty is solved by encoding symbols backwards and storing a final state. Then decoding can proceed forward from the final state. If an initial encoding state is fixed and known to a decoder, then the decoder can verify decompression correctness. This way, we obtain a popular checksum mechanism for free. For simple statistical models (like Markov), we can directly encode backwards and use a context of future-forward decoding. For more sophisticated models (like a popular adaptive update of the probability distribution) we can use an additional buffer to store symbol statistics. An encoder first makes a statistical analysis of incoming symbols in their natural (forward) order. It stores the observed probability distribution of symbols in the buffer. Knowing probability distribution, the encoder can next design an appropriate instance of ANS and share it with the decoder. Finally, the encoder processes symbols backwards. The decoder recovers symbols in their natural order. Note that the decoder needs to know where a binary frame terminates. There are essentially the following two options: in the first, we can fix the length of a binary frame; in the second option, we can use a sentinel value that is chosen from a set of low-probability symbols (that do not occur in the current symbol frame).
2.4. Industry Status
For AC, there are implementations that achieve compression speeds from ∼50 (alphabet with two symbols) to ∼150 MB/s/core (alphabet with 256 symbols). On the other hand, consider ANS: its compression speed ranges from ∼500 (for FSE implementation of tANS) to ∼1500 MB/s/core (for vectorised SIMD rANS) (see
https://github.com/jkbonfield/rans_static,
https://sites.google.com/site/powturbo/entropy-coder, accessed on 13 April 2023). For GPU, there are available vectorised rANS implementations (e.g., Facebook or NVidia) reaching speeds of hundreds GB/s (see
https://github.com/facebookresearch/dietgpu,
https://developer.nvidia.com/blog/latest-releases-and-resources-feb-3-10/#software-releases, accessed on 13 April 2023). To our best knowledge, we are not aware of such fast implementations for AC. There are also available FPGA implementations processing one symbol per cycle [
29]. As a consequence, in recent years, ANS has started to dominate the compression market for various applications. Notable examples include compression for:
General purpose—Facebook Zstandard (tANS) [
30] has become probably the most popular replacement of the gzip algorithm (built-in Linux kernel),
Genetic data—almost the default is CRAM (rANS) citecram, which is a part of the SAMtools library,
3D data (meshes, point clouds)—the Google Draco 3D compressor (rANS) used by Pixar,
The exception is video compression, which is still dominated by AC. This is due to the following two factors: the first one concerns intellectual property and patent issues in relation to the legacy compression algorithms (
https://en.wikipedia.org/wiki/Asymmetric_numeral_systems, accessed on 13 April 2023); the second factor is backward encoding required by ANS, which complicates the implementation of compression.
3. Asymmetric Numeral Systems
Here we do not describe the ideas behind ANS design. Instead, we refer the reader to original papers by Duda [
16,
32] and the ANS Wikipedia page, whose URL address is given in the previous section. A friendly introduction to ANS can be found in the work [
22]. The ANS algorithm suite includes initialisation, compression (encoding), and decompression (decoding). Algorithm 1 shows initialisation— it also serves as a reference for basic ANS notation.
| Algorithm 1: ANS Initialisation |
Input: a symbols source , its symbol probability distribution and a parameter . Output: instantiation of encoding and decoding functions: Steps: proceed as follows: Calculate the number of states ; Determine the set of states ; Compute integer , where is probability of s; ; Choose symbol spread function , where denotes a set of states assigned to the symbol s and ; Establish coding function for , which assigns states according to symbol spread function; Compute for and . It gives the number of output bits per symbol; Construct decoding function , which for , assigns its unique symbol (given by the symbol spread function) and the integer y, where . Note that ; Calculate , which determines the number of bits that need to be read out from the bitstream;
|
A compression algorithm accepts a symbol sequence
and outputs a bitstream
. In most cases, the probability distribution of symbols is unknown so it has to be calculated. This is done by pushing symbols one by one to a stack and counting their occurrences. When the last symbol
is processed, the symbol statistics are known, and compression can start. It means that compression starts from the last symbol
. Algorithm 2 describes the ANS compression steps.
| Algorithm 2: ANS Encoding |
Input: a symbol sequence and an initial state , where . Output: a bitstream , where and is state in i-th step. ![Entropy 25 00672 i001]() store the final state ; |
Note that the bitstream is created by the concatenation of individual encodings. This is denoted by
, where
is a binary encoding (sequence of
k bits);
. Decompression steps are shown in Algorithm 3. Note that
and
stand for the
k least and most significant bits of
, respectively.
| Algorithm 3: ANS Decoding |
Input: a bitstream and the final state . Output: symbol sequence . ![Entropy 25 00672 i002]() |
ANS Example
Given a symbol alphabet
, where
,
,
and the parameter
. The number of states is
and the state set equals to
. A symbol spread
can be chosen at random as long as (1) the number of elements in
equals to
and (2) the chosen states in
are in the increasing order. So we assume that
where
,
and
. The encoding table
is shown in
Table 1.
This example is used throughout the work to illustrate our considerations.
4. Optimality of ANS—Bounds and Limits
There are two main factors that determine how well ANS compresses symbol sequences: (1) compression quality of the underlying ANS encoder and (2) the length of auxiliary data needed by a decoder to recover symbols from bitstream. Auxiliary data include symbol statistics, the ANS spread function, a chosen sentinel value (or the length of bitstream), and the final ANS state. Note that auxiliary data introduces a loss of compression quality. The loss is significant for relatively short symbol sequences, but it becomes negligible for very long files. In this section, our considerations are focused on ANS compression quality only. We ignore auxiliary data.
Given an ANS instance designed for a memoryless symbol alphabet with its probability distribution
and the parameter
R. The set of all ANS states is
. ANS is optimal if the average length of the binary encoding is equal to the alphabet entropy or
where a sequence
consists of
ℓ symbols. The sequence
is also called a symbol frame. The same symbols of the frame can be grouped so we get
Note that
. So we have proven the following lemma.
Lemma 1. Given an alphabet whose probability distribution is and ANS for . Then ANS is optimal if and only ifwhere is a symbol sequence, which repeats every symbol times. A caveat—strictly speaking Equation (
3) holds when probabilities
are natural powers of
. In other cases, the left-hand side is a rational number while the right-hand side is an irrational one. Consequently, Equation (
3) is an approximation determined by the applied calculation precision.
Let us have a closer look at how ANS encodes symbols. According to Algorithm 2, a symbol
s is encoded into
, where
and
. The length
of encoding depends on the state
x. The shortest encoding is when
and the longest when
. It means that
As
, we get
. Consider a general case when
. Then
. If
, then the inequality
points to a single encoding length
. The above leads us to the following conclusion.
Lemma 2. Given ANS described by Algorithm 2. Then a symbol s is encoded into a binary string of the length , where
Consider a general case of a symbol alphabet
with an arbitrary probability distribution
(not necessarily the natural powers of
). Given an ANS instance designed for the distribution
p and the set of states
. We start from an observation that the average length (the expectation) of binary encoding of a single symbol
into a binary encoding
is equal to
where a state probability distribution is
. Note that optimal encoding of
occurs when
and does not (directly) depend on the encoding function
C. It, however, has a direct impact on state probabilities. Assume that we have found an ANS instance which is optimal. This means that each symbol is compressed into its binary encodings whose expected length equal to the symbol entropy. This implies that the following system of equations must hold:
Consequently, we have proven the lemma presented below.
Lemma 3. Given an ANS instance designed for the symbol probability distribution and the set of states . Then ANS is optimal if its state probabilities satisfy relations given by Equation (6). Let us discuss briefly the consequences of Lemma 3.
In general, ANS allows us to attain close to optimal compression. However, finding an appropriate coding function C seems to be a challenge, especially for a large enough R, where enumeration of all possible C is not possible. There is also a possibility that there is no such C.
The system given by Equation (
6) is underdetermined so its solutions create a linear subspace. To see that this is true, it is enough to observe that for a given symbol, the symbol spread assigns more than one ANS state. Consequently, we have
equations in
variables.
The work [
33] shows how to change the state probabilities so they follow a uniform distribution using a pseudorandom bit generator (PRBG). This interference has been necessary to provide confidentiality and integrity of a compressed stream. Unfortunately, the price to pay is a loss of compression ratio. This approach can be applied here. It would involve a design of PRBG with fine control of probability distribution, which could be a very difficult task. Additionally, running PRBG would be much more expensive than a single call to
C.
An optimistic conclusion is that ANS has no structural weaknesses. Whether or not it attains close to optimal compression ratio depends on the coding function C or alternatively on the symbol spread.
It is important to make clear the difference between the optimal and the best compression ratios. Given an instance of ANS. We can exhaustively run through all possible symbol spreads and identify the one whose compression ratio is the best. This obviously does not guarantee that such ANS is optimal.
5. State Probabilities and Markov Chains
ANS can be looked at as FSM, whose internal state changes during compression. The behaviour of ANS states is probabilistic and can be characterised by state probability distribution . For a given symbol , the average encoding length of s is , where is the length of an encoding assigned to s when ANS is in the state x (see Algorithm 2). The average length of ANS encodings is . When we deal with an optimal ANS, then , which also means that for all . Typically, compression quality is characterised by a ratio between the length of a symbol sequence and the length of the corresponding bitstream. A better measure from our point of view is coding redundancy, which is defined as . The measure has the following advantages:
Easy identification of an optimal ANS instance when ;
Quick comparison of two ANS instances—a better ANS has a smaller ;
Fast calculation of the length of a redundant part of bitstream, which is bits, where ℓ is the number of symbols in the input sequence.
To determine
for an ANS instance, it is necessary to calculate probability distribution
. It depends on a (random) selection of symbol spread. Note that ANS state transitions are probabilistic and can be described by a matrix. If one of the matrix eigenvalues is equal to
, then the corresponding eigenvector points to an equilibrium probability of the related Markov chain [
23,
34,
35,
36]. Note that the ANS Markov chain is in equilibrium when state probabilities do not change after processing single symbols.
Algorithm 4 shows steps for the construction of a system of linear equations, whose solution gives an equilibrium probability distribution
. The encoding table
shows transition of a state
x to the next state
while encoding/compressing a symbol
s.
| Algorithm 4: Equilibrium of ANS States |
Input: ANS encoding table and symbol probability distribution . Output: probability distribution of ANS Markov chain equilibrium. Steps: • initialise matrix M to all zeros except the main diagonal for and the last row, where for ; • create a vector B with entries with all zero entries except the last entry equal to 1; ![Entropy 25 00672 i003]() • solve using Gaussian elimination; • return X→; |
Example 1. Consider the ANS instance from Table 1. According to the above algorithm, we obtain a matrix M as follows:The vector . The equilibrium probabilities areNow it is easy to calculate both the average encoding length and alphabet entropy . ANS leaves a coding redundancy bits per symbol. Let us change the symbol spread by swapping states 25 with 28 so we have the following symbol spreadThe encoding function is:The encoding table is given in Table 2. After running Algorithm 4, we obtain equilibrium probabilities as follows:The average encoding length . This ANS instance leaves coding redundancy bits per symbol. Clearly, it offers better compression than the first variant. The following remarks summarise the above discussion:
The extensive practical experience and asymptotic optimality of ANS (see [
23]) justifies the conclusion that ANS offers a very close-to-optimal compression when the parameter
R is big enough so
for all
. In general, however, for arbitrary symbol statistics, ANS tends to leave coding redundancy
.
In some applications where ANS compression is being used heavily (for instance, video/teleconference streaming), it makes sense to optimise ANS so is as small as possible. Note that the smaller , the more random the bitstreams. This may increase the security level of systems that use compression (for instance, joint compression and encryption).
It is possible to find the best ANS instance by an exhaustive search through all distinct symbol spreads. For states, we need to search through ANS instances. This is doable for a relatively small number of states. For ANS in our example, the search space includes instances. For a bigger L (say, above 50), an exhaustive search is intractable.
6. Tuning ANS Symbol Spreads
For the compression algorithms such as Zstandard and LZFSE, a typical symbol alphabet contains
elements. To obtain a meaningful approximation of the alphabet statistics, we need a bigger number
L of states. A rough evaluation of compression ratio penalty given in [
37] tells us that choosing
incurs a entropy loss of
bits/symbol; if
, then
and if
, then
. This confirms an obvious intuition that the bigger number of states
L, the better approximation and, consequently, compression ratio. However, there is a “sweet spot” for
L, where its further increase slows compression algorithm but without a noticeable compression ratio gain.
Apart from approximation accuracy of symbol probabilities so , the symbol spread has an impact on compression ratio. Intuitively, one would expect that symbol spread is chosen uniformly at random from all possibilities. It is easy to notice that they grow exponentially with L. An important observation is that the probability distribution of ANS states during compression is not uniform. In fact, a state occurs with probability that can be approximated as . Note that this is beneficial for a compression ratio, as smaller states (with shorter encodings) are preferred over larger ones (with longer encodings). The natural probability bias of states has an impact on the compression ratio, making some symbol spreads better than the others. Let us take a closer look at how to choose symbol spread so it maintains the natural bias.
Recall that for a given symbol and state , the encoding algorithm (see Algorithm 2) calculates , extracts k least significant bits of the state as the encoding of s and finds the next state , where is equivalent to a symbol spread and . Consider properties of coding function that are used in our discussion.
Fact 1. Given a symbol s and coding function . Then the collection of states is divided into state intervals , where
Each interval consists of all consecutive states that share the same value for all ,
Coding function assigns the same state for and ,
The cardinality of is , where and .
Example 2. Take into account ANS described in Table 1. For the symbol , the collection of states splits into intervals as follows: | | |
| ; | ; | ; |
Note that cardinalities of are powers of 2 or and . As the encoding function is constant in the interval , it makes sense to use a shorthand instead of for .
Assume that we know probabilities of states of , then the following conclusion can be derived from Fact 1.
Corollary 1. Given an ANS instance defined by Algorithms 1–3. Then for each symbol , state probabilities have to satisfy the following relations: Recall that those state probabilities can be approximated by
. As Equation (
7) requires summing up probabilities of consecutive states, we need the following fact.
Fact 2. Given an initial part of the harmonic series , then it can be approximated as shown belowwhere the constant . It is easy to obtain an approximation of the series , which is , where . Now, we are ready to find out a preferred state for our symbol spread. Let us take into account Equation (
7). Using the above established facts and our assumed approximation
, the left-hand side of the equation becomes
where
r is the first state in
and
—the last and
. As we have assumed that the state
, where
y points the preferred state that needs to be included into
, we obtain
This brings us to the following conclusion.
Corollary 2. Given ANS as defined above, then a preferred state y for determined for a symbol s iswhere and an integer closest to y and it is added to . Algorithm 5 shows an algorithm for the calculation of symbol spread with preferred states.
| Algorithm 5: Symbol Spread Tuning |
Input: ANS number of states and symbol probability distribution . Output: symbol spread determined by for . Steps: initialise for ; ![Entropy 25 00672 i004]() • Remove collisions from so for ; • Return or equivalently for ; |
Let us consider the following example.
Example 3. Take ANS from Section 3 with states and three symbols that occur with probabilities , and , respectively. For the symbol , the set of states splits into subsets: , and . Let us compute the preferred state y for . It is , where and . For , we obtain . For , we obtain . After rounding to the closest integers, . In similar way, we calculate and . Clearly, there are a few collisions, for example, the state 18 belongs to both and . They need to be removed. We accept . The colliding states in other sets are replaced by their closest neighbours, which are free. This obviously makes sense as neighbour states share similar probabilities. The final symbol spread is as follows We can compute the average encoding length by computing equilibrium probabilities, which for the above symbol spread, is . It turns out that this is the best compression ratio, as argued in Section 7. In contrast, the average lengths of symbol spreads in Example 1 are and . Algorithm 5 may produce many symbol spreads with slightly different compression ratios. Preferred positions need to be rounded to the closest integers. Additionally, there may be collisions in sets () that have to be removed. Intuitively, we are searching for a symbol spread that is the best match for preferred positions. In other words, we need to introduce an appropriate distance to measure the match.
Definition 1. Given ANS with a symbol spread and a collection of preferred positions calculated according to Equation (9). Then the distance between them is computed aswhere y is the preferred position that is taken by x. Finding the best match for a calculated
is equivalent to identification of a symbols spread
such that
where the symbol spread
runs through all possibilities.
Algorithm 6 illustrates a simple and heuristic algorithm for finding
.
| Algorithm 6: Finding Symbol Spread |
Input: ANS number of states , symbol probability distribution and Output: symbol spread determined by for Steps: Create a table with three rows and columns; Put all consecutive states (i.e., in increasing order in the first row; Insert all numbers from in increasing order in the second row together with their symbol labels in the third row; Read out all states from the first row that correspond to appropriate symbol labels (in the third row); Return or equivalently for ;
|
Example 4. Consider again the ANS from Section 3 with states and three symbols that occur with probabilities , , and , respectively. We follow Algorithm 6 and obtain the following table:After the calculation of equilibrium probabilities, we obtain the average encoding length, which is . The following observations are relevant:
The algorithm for tuning symbol spreads is very inexpensive and can be easily applied for ANS with a large number of states (bigger than ). It gives a good compression ratio.
Equation (
9) gives a rational number that needs to be rounded up or down. Additionally, preferred states pointed by it are likely to collide. Algorithm 5 computes a symbol spread, which follows the preferred positions.
Equation (
9) indicates that preferred states are likely to be uniformly distributed over
.
It seems that finding such that attains minimum does not guarantee the best compression ratio. However, it results in an ANS instance with a “good” compression ratio. This could be a starting point to continue searching for ANS with a better compression ratio.
7. Optimisation of ANS
7.1. Case Study
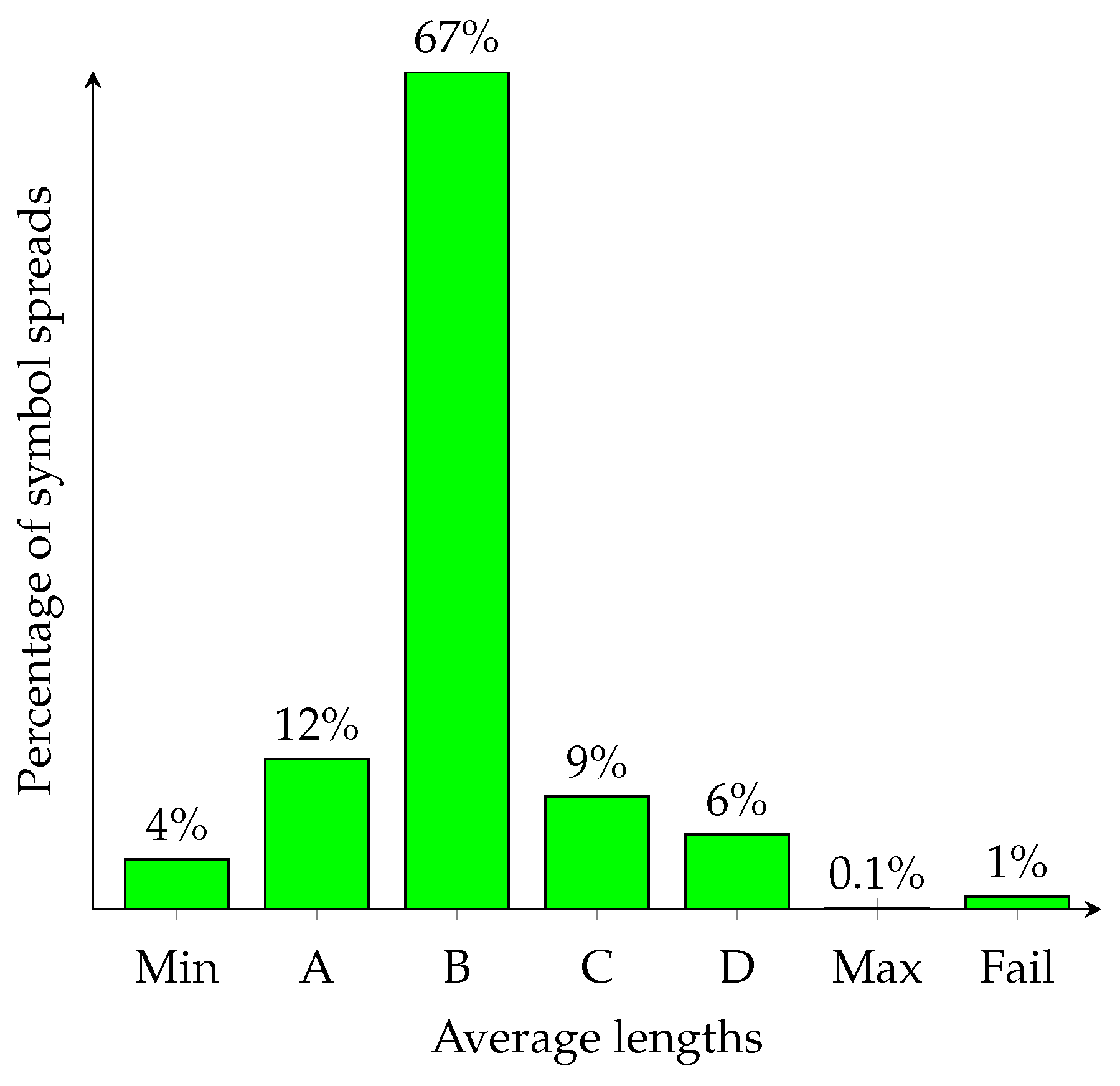
Consider a toy instance of ANS with three symbols that occur with probabilities
and 16 states (i.e.,
). We have implemented software in PARI/GP ( PARI is a free software developed by Henri Cohen. PARI stands for Pascal ARIthmetic and GP—Great Programmable calculator.) that searches through all possible instances of ANS symbol spreads (there are
such instances). For each spread, we have calculated equilibrium probabilities for the corresponding Markov chain. This allows us to compute the average length of a symbol (in bits/symbol). The results are shown in
Figure 1.
Unfortunately, there is a small fraction of ANS instances whose equilibrium probabilities are impossible to establish as the corresponding system is linearly dependent (its rank is 15). An example of symbol spread with the shortest average encoding length is:
In contrast, the following symbol spread function has the longest average encoding length:
Clearly, a careful designer of ANS is likely to use a pseudorandom number generator to select symbol spreads. There is better than
probability that such an instance has the average encoding length somewhere in the interval
. On the other hand, a careless designer is likely to fall into a trap and choose one of the worst symbol spreads.
7.2. Optimal ANS for Fixed ANS Parameters
The idea is to start from a random symbol spread. Then, we continue swapping pairs of ANS states. After each swap, we calculate the coding redundancy of a new ANS instance. If its redundancy is smaller than the old instance redundancy, then we keep the change. Otherwise, we select a new pair of states for the next swap. Details are given in Algorithm 7.
| Algorithm 7: Search for Optimal ANS |
Input: symbol probability distribution and parameter R such that for all s Output: symbol spread or encoding table of ANS with the smallest coding redundancy Steps: • Initialise symbol spread using PRBG; • Determine the corresponding and calculate its redundancy ; • Assume a required minimum redundancy threshold T; ![Entropy 25 00672 i005]() • Return and ; |
We have implemented the algorithm in the PARI/GP environment. Our experiment is executed for the 16-state ANS and three symbols that occur with probabilities . As the algorithm is probabilistic, its behaviour varies depending on specific coin tosses that determine state swaps. Our starting symbol spread is a spread with the longest average encoding length, i.e., , , ). This is the worst case.
The algorithm continues to swap state pairs until the average length equals the minimum
(the best compression ratio). We have run the algorithm
times. The results are presented in
Table 3. The main efficiency measure is the total number of swaps of ANS state pairs that is required in order to achieve the best compression ratio. Note that each state swap forces the algorithm to redesign ANS. As the algorithm uses PRBG, the number of state swaps varies. The algorithm works very well and successfully achieves the best compression ratio every time. In
Table 3, we introduce “good swaps”. It means that any good swap produces an ANS instance whose average encoding length gets smaller. This also means that in the worst case, we need only 19 swaps to produce the optimal ANS. Optimality here is understood as the minimum coding redundancy.
The complexity of Algorithm 7 is , where is the number of iterations of the main loop of the algorithm. The most expensive part is the Gaussian elimination needed to find equilibrium probabilities. It takes steps. We assume that we need swaps to obtain a required redundancy with high probability. In other words, the algorithm becomes very expensive when the number of states L is bigger than . This is unfortunate, however, the good news is that a system of linear equations defining equilibrium probabilities is sparse. Consider a simple geometric symbol probability distribution . Assume that ANS has states. A simple calculation indicates that the matrix M in the relation for the Markov equilibrium has ≈99% zeros. It means that we can speed up the search for the optimal ANS in the following way:
Further efficiency improvements can be achieved by taking a closer look at swapping operations. For the sake of argument, consider a swap of two states and their matrices M and that describe their Markov chain probabilities before and after the swap, respectively. There are essentially two distinct cases when the swap is:
Simple, i.e., only two rows of
M are affected by the swap. The matrix entries outside the main diagonal are swapped, but entries on the main diagonal need to be handled with care as they do not change if their values are
. For instance, take ANS from
Table 1. Let us swap the states 25 and 26. The rows of
M before swap are
The rows after the state swap are
The matrix after swap can be obtained by , where is a sparse matrix that translates M into . As argued above, the equilibrium solution is , where . We still need to calculate ; however, it is possible to recycle a part of the computations performed while computing . This is possible as M and share the same entries (except the two rows that correspond to the state swap),
Complex, i.e., more than two rows need to be modified. This occurs when a swap causes a cascade of swaps that are needed to restore the increasing order in their respective
. For example, consider ANS from
Table 1 and swap the states 22 and 26.
To obtain a valid ANS instance, we need two extra swaps. The calculation of can still be supported by the computations for but the matrices M and differ on more than two rows.
7.3. Optimalisation with Quantisation
So far we have assumed that ; or at least is a very close approximation of . However, this is not always true. In practice, there are two issues that need to be dealt with.
The first is the fact that may have two “good” approximations when , where . So, we can choose . This occurs more frequently when the number L is relatively small.
The second issue happens when there is a tail of symbols whose probabilities are small enough so . It means that symbols have to be assigned to single states . This is equivalent to an artificial increase of symbol probabilities of the tail to . Note that , which is equivalent to . Consequently, the number of states in the symbol spread for other symbols has to be reduced.
The research question in hand (also called quantisation) is defined as follows. Given that a symbol probability distribution , we have to ask: How do we design ANS so its compression is optimal (or close to it), where ANS is built for the symbol probability distribution , where approximates , where , and ?
Let us consider the following algorithms.
Exhaustive search through all possible quantised ANS, where an ANS instance is determined by a selection of , where . For each selection, we run Algorithm 7. Finally, we choose the ANS instance with the best compression ratio. Unfortunately, the complexity of the algorithm is exponential or more precisely, . A possible tail of t symbols reduces complexity as all t symbols are assigned a single state and the next t low probability symbols are assigned states. Higher are ignored in order to compensate states that have been taken by the tail symbols. Note also that some of the selections for must be rejected if .
Best-fit quantised ANS. The idea is to start from symbols from the tail, where has to be 1. Symbols with high probabilities are assigned , while symbols with low probabilities . Symbols with mid-range probabilities are randomly assigned . The intuition behind the algorithm is the fact that selection of higher reduces the average length of encodings and vice versa. Now we can run Algorithm 7 to find the optimal (or close to it) ANS.
To recap our discussion, we make the following remarks:
Finding ANS with the optimal compression ratio is of prime concern to anyone who would like to either maximise communication bandwidth or remove as much redundancy as possible from bitstreams. We model the asymptotic behaviour of ANS by Markov chains. The calculated equilibrium probabilities allow us to precisely determine the average length of binary encodings and, consequently, the ANS compression ratio.
Search for the best ANS can be done in two steps. (1) We run Algorithm either 5 or 6 that tunes symbol spread using an approximation of state probabilities. The algorithm is very efficient, and its complexity is
. Unfortunately, it does not guarantee that the calculated ANS instance is optimal/best. (2) Next, we execute Algorithm 7. Its initial symbol spread has been calculated in the previous step. The randomised algorithm usually attains the best (or close to it) ANS in practice (see experiments in
Section 9).
Algorithm 7 can be sped up by using a specialised sparse matrix inversion algorithm together with reusing computations from previous inversions. This allows us to find a close-to best ANS for the number L of states in the range . The range is the most used in practice.
The number of iterations
contributes to the complexity of Algorithm 7. In general, the bigger
, the higher the probability that the algorithm produces the best ANS. In fact,
is enough to obtain ANS with a close to the best compression ratio with high probability, where
is a small integer (say 2 or 3) —see our experiments in
Section 9.
8. Cryptographic ANS
Duda and Niemiec [
39] have proposed a randomised ANS, where its symbols spread is chosen at random. To make it practical, the authors suggest replacing truly random coin tosses with a pseudorandom number generator (PRNG), which is controlled by a relatively short random seed/key. The two communicating parties can agree on a common secret key
K. Both sender and receiver use it to select their symbol spread using PRNG controlled by
K. The sender can build an appropriate encoding table, while the receiver—the matching decoding table. Consequently, the parties can use compression as encryption. Although such encryption does not provide a high degree of protection (especially against integrity and statistics attacks—see [
22,
33]), it could be used effectively in low-security applications. The price to pay is a complete lack of control over the compression ratio of ANS. This weakness can be mitigated by applying our Algorithm 7.
Note that the symbol spread
is public but
is secret as to reconstruct it, an adversary needs to recover
K and execute Algorithm 7. The cryptographic ANS is illustrated in
Table 4. Unlike the Duda–Niemiec ANS, it achieves a close to the best compression ratio. However, the effective security level (the length of the cryptographic key) is determined by the number of ANS instances produced by Algorithm 7. For instance, the ANS from
Figure 1 guarantees 15-bit security (or
). For ANS with a large number of states, it is difficult to determine a precise security level. However, this may be acceptable for low-security applications.
9. Experiments
Algorithm 7 has been implemented using the Go language and has been executed on a MacBook Pro with an M1 chip. The algorithm has been slightly modified so it finds both the lower and upper bounds for
. The lower bound points to ANS, which is close to the best. In contrast, the upper bound shows ANS, whose coding redundancy
is big (close to the worst case). Note that a random selection of spreads produces ANS instances whose
fall somewhere between the bounds. The following results have been obtained for
iterations of the
FOR loop.
| # ANS States | 128 | 256 | 512 | 1024 |
| 1.5770 | 4.1869 | 1.0470 | 2.7868 |
| 0.0346 | 0.0298 | 0.0348 | 0.0306 |
| # Spreads with | 22 | 68 | 138 | 156 |
| # Spreads with | 149 | 357 | 701 | 1044 |
| Search Time for | 1 m 12 s | 8 m 30 s | 1 h 11 m 37 s | 9 h 2 m 59 s |
| Search Time for | 1 m 23 s | 8 m 13 s | 1 h 9 m 58 s | 8 h 47 m 5 s |
We have increased the number of iterations of the
FOR loop to
, where
n is the number of states for
. The results are presented below.
| n | 512 | 1024 |
| # Iterations | 262,144 | 1,048,576 |
| # Good Swaps | 508 | 792 |
| 1.0222607274 | 2.5842 |
| after additional rounds | 1.0222607271 | 2.5842 |
| # Additional Rounds | | |
| Better Spreads Found in Additional Rounds | 8 | 0 |
| Execution Time | 872 m | 6115 m |
We see that due to the probabilistic nature of the Algorithm 7, even after a large number of iterations, there is a non-zero chance of finding a spread with lower
. In practise, there are time restrictions imposed on the time needed for the execution of Algorithm 7. The following results illustrate how much time is needed between two consecutive good swaps that improve
. The number of iterations of the
FOR loop is
.
| # ANS States | 128 | 256 | 512 | 1024 |
| Tunning Time | 54 ms | 235 ms | 300 ms | 374 ms |
| Optimisation Time | 1 m 12 s | 8 m 30 s | 1h 11 m 37 | 9 h 2 m 59 s |
| # Good Swaps | 22 | 68 | 138 | 156 |
| Time between Two Good Swaps | 3 s | 7 s | 31 s | 209 s |
| Average Gain per Good Swap | 3 | 2.2 | 2.4 | 3.7 |
| 1.5 | 4.1 | 1.04 | 2.78 |
Note that matrix inversion consititues the main computational overhead of Algorithm 7. The experiments presented above have applied a standard Gaussian elimination (GE) for matrix inversion, whose complexity is
. Algorithm 7 can be sped up by (1) using a more efficient algorithm for sparse matrix inversion (SMI) and (2) recycling computations from previous matrix inversions. The table below gives the complexity of Algorithm 7 for different matrix inversion algorithms and for the classical and quantum computers.
| Classical Computer | Quantum Computer |
| GE | SMI [38] | SMI [40] | GE [41] |
| | | |
The experiments have confirmed that Algorithm 7 works well and is practical for . However, for a larger L, it grows slower and quickly becomes impractical. Optimisation of Algorithm 7 is beyond the scope of this work, and it is left for our possible future investigations. Note that the algorithm becomes very fast when it uses quantum matrix inversion.
The third column shows the sizes of files compressed using an instance of ANS with a random spread. The fourth column gives sizes of the corpus files when compressed with an instance ANS with optimised symbol spread. On average, we are getting a roughly 2.4% improvement in compression rates.
Discussion
The main goal of compression is to reduce the redundancy of a file by encoding more frequent symbols into shorter binary strings and less frequent symbols into longer ones. Typically, for compression to work, it is necessary to describe the symbol statistics by its symbol probabilities. In this case, a file can be treated as a sequence of independent and identically distributed (i.i.d.) random variables, which correspond to the occurrence of single symbols. Clearly, such single-symbol statistics do not reflect all existing probabilistic characteristics of the file. Consequently, even the best (lossless) compression algorithm is not able to squeeze the average length of a single symbol beyond the symbol alphabet entropy. To achieve a better compression ratio, it is necessary to model file statistics by considering
N-symbol alphabets, where
(see [
42]). Clearly, the higher
N, the better approximation of real statistics of the file and, consequently, better the compression rate. But the price to pay is a significant (exponential) increase in the compression complexity. We would like to emphasise that given a fixed symbol alphabet, both AC and ANS allow us to achieve a compression ratio close to the alphabet entropy. The main difference is processing speed which allows ANS to compress files for better file statistics (for
N-symbol alphabets with higher
N). Let us compare CPU implementations of AC and ANS. AC can reach speed of ≈200 MB/s/core while ANS achieves a speed of ≈2000 MB/s/core. For GPU implementations, ANS can be run 100 times faster than AC. This implies that, assuming the same computing resources, ANS provides better compression ratios compared to AC. This is due to the fact that ANS is faster and can apply more complex statistics for
N-symbol alphabets (a higher
N).
10. Conclusions
The work addresses an important practical problem of compression quality of the ANS algorithm. In the description of ANS, its symbol spread can be chosen at random. Each symbol spread has its own characteristic probability distribution of ANS states. Knowing the distribution, it is possible to compute the ANS compression ratio or, alternatively, its coding redundancy .
We present two algorithms that allow a user to choose symbol spreads that minimise . Algorithm 5 determines an ANS instance (its symbol spread) whose state probabilities follow the natural ANS state bias. It is fast even for , but unfortunately, it does not provide the minimal . Algorithm 7 provides a solution. It is able to find minimal with a probability that depends on the number of random coin tosses .
We have conducted an experiment for that shows the behaviour of the average length of ANS encodings. Further experiments have confirmed that matrix inversion creates a bottleneck in Algorithm 7 and makes it impractical for a large L. An immediate remedy is the application of specialised algorithms for sparse matrix inversion, together with recycling computations from previous matrix inversions. Development of a fast version of Algorithm 7 is left as a part of our future research.
The main research challenge is, however, how to construct ANS instances in such a way that their minimum coding redundancy is guaranteed by design. It means that we have to understand the interplay between symbol spreads and their equilibrium probabilities. As ANS is also FSM, it can be visualised as a random graph whose structure is determined by symbol spread. This brings us to an interesting link between ANS and random graphs [
43].


 ,
, 








{kind=link}