1. Introduction
As everyone knows, the key nodes usually play a decisive role during the process of graph data mining. In order to accurately identify the so-named key nodes in graph data, a priority problem is to construct an appropriate score function for ranking nodes [
1,
2,
3,
4]. Due to its prevalence in the field of disease detection [
5,
6], information transmission [
7,
8] and rumor blocking [
9,
10], how to rank nodes in graph data has been widely studied by researchers of various vocations.
In general, there are many traditional node importance ranking methods that only considered the local structure information of nodes to construct the score function [
11,
12,
13]. For example, Lu et al. [
14] calculated the importance of nodes by means of the degree centrality method. Chen et al. [
15] constructed a multi-level neighbor information index to measure the importance of nodes, in which case only the degree information of first-order and second-order neighbors are considered. In order to distinguish the contribution of different neighbors, Katz [
16] assigned different weights to them. The neighbors that can be reached by the short route are assigned the larger weight. At the same time, the neighbors that can be reached by the long route are assigned the small weight [
17].
Up to now, many improved methods are proposed to deal with the problem of node importance ranking for graph data [
18,
19,
20]. For instance, Freeman [
21] constructed the betweenness centrality method, which described the importance of a node as the number of the shortest paths through it. In the closeness centrality method [
22], the importance score of each node can be determined through the impact ability of the target node on other nodes. Based on the hypothesis that the node located at the core position has a strong influence, the K-shell decomposition method [
23] is proposed. Yang et al. [
24] proposed a comprehensive evaluation method based on multi-attribute decision making, which took many factors that affect the importance of nodes into account. What is more, the graph learning framework is also applied to evaluate the importance of nodes, such as in reference [
25], the first graph neural network-based model is proposed to approximate betweenness and closeness centrality. Furthermore, Liu et al. [
26] proposed a novel model based on self-supervised learning and graph convolution model to rank nodes, which formulated node importance ranking problem as a learning ranking problem.
Besides what has been discussed above, the well-known information entropy that has been proposed by Shannon [
27] is also regarded as a powerful tool to measure the importance of nodes in a whole new perspective [
28,
29,
30]. For instance, Zareie et al. [
31] constructed the score function for each node, which considered the influence of neighbors on the target node with the help of information entropy. Guo et al. [
32] proposed the EnRenew method by using the voting mechanism. In this method, information entropy is regarded as the voting ability of neighbors. By taking the effect of the spreading rate on information entropy into account, a propagation feature of the node-based ranking approach is introduced in reference [
33]. Yu et al. [
34] characterized the node importance as the node propagation entropy, which was the combination of degree and clustering coefficients.
Based on the above analysis, it can be found easily that in both the information entropy-based ranking methods and traditional ranking methods, only the local structure information is used to construct score functions. However, in fact, the global structure information, i.e., the connectivity of whole graph data, usually has a huge influence on the final ranking sequence [
35,
36,
37]. In order to overcome the limitation or make full use of information from graph data, we propose a structural entropy-based node importance ranking method by considering the global structure information of graph data. We first calculate the amount of information contained in each connected component, which is denoted as the local structural entropy. Furthermore, the global structure entropy is constructed by distinguishing the different contributions of each connected component. Moreover, the effectiveness of the proposed method was tested on eight real-world datasets. The contribution of this paper can be listed as follows.
- -
The structure entropy-based node importance ranking method for graph data is proposed in terms of node removal.
- -
The local structural entropy is calculated by considering the degree of information of nodes and information entropy.
- -
The global structure entropy is constructed in terms of the connectivity of graph data.
The remainder of this paper is organized as follows.
Section 2 reviews some basic concepts, which are graph data and benchmark methods for node importance ranking.
Section 3 introduces the proposed method, i.e., the structural entropy-based node importance ranking method.
Section 4 is composed of three parts, which are the experimental platform, datasets description and evaluation criteria.
Section 5 shows the experimental results and contrastive analysis between the proposed method and five benchmark methods on eight real-world datasets.
Section 6 is the summary of this paper and gives future research directions.
3. The Proposed Method
It is well-known that most of the classical node importance ranking methods only consider the local structure information of nodes, but ignore the global structure information of graph data. For this, we combine the local and global structure information to construct the score function for all nodes. Based on the assumption that removing a more important node is likely to cause more structural variation of graph data, the score function is constructed from the perspective of node removal. Furthermore, the local and global structure information are considered comprehensively to construct the structure entropy of graph data and in which case all nodes can be ranked.
3.1. Node Removal
The graph data are defined as a connected graph if there is a route from to , or to for any nodes . Otherwise, it is a disconnected graph. For a disconnected graph, each connected part is called a connected component.
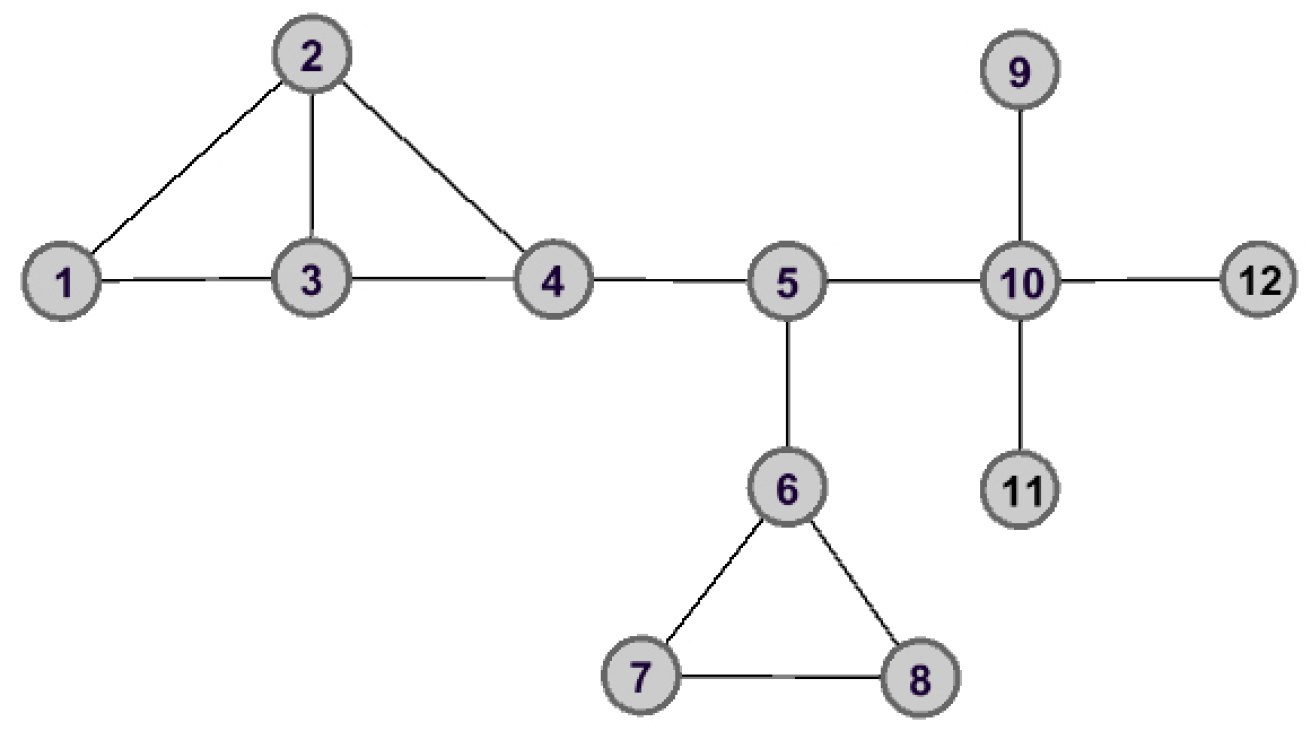
Taking
Figure 1, for example, there are 12 nodes and 14 edges. One can find that the nodes
and
have the same degree. They will be assigned the same importance score according to the
DC method. However, in fact, the importance of these two nodes is completely different.
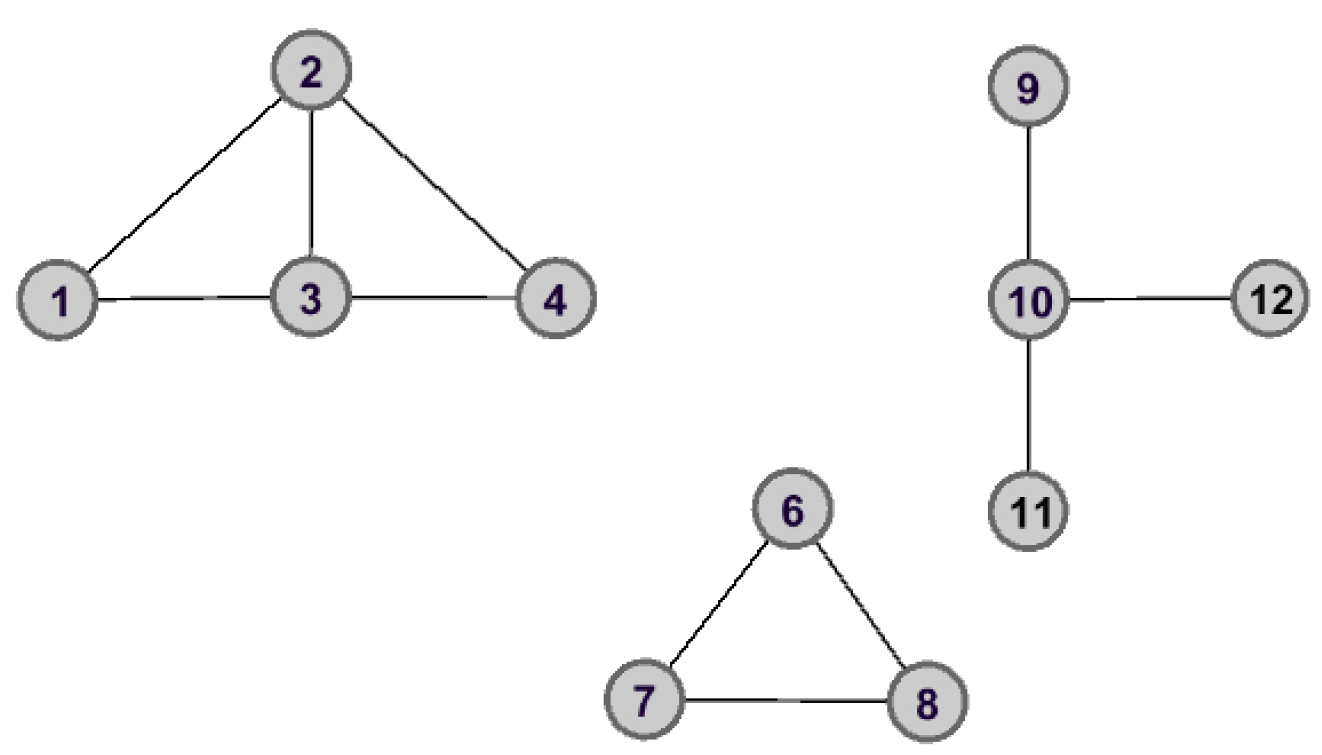
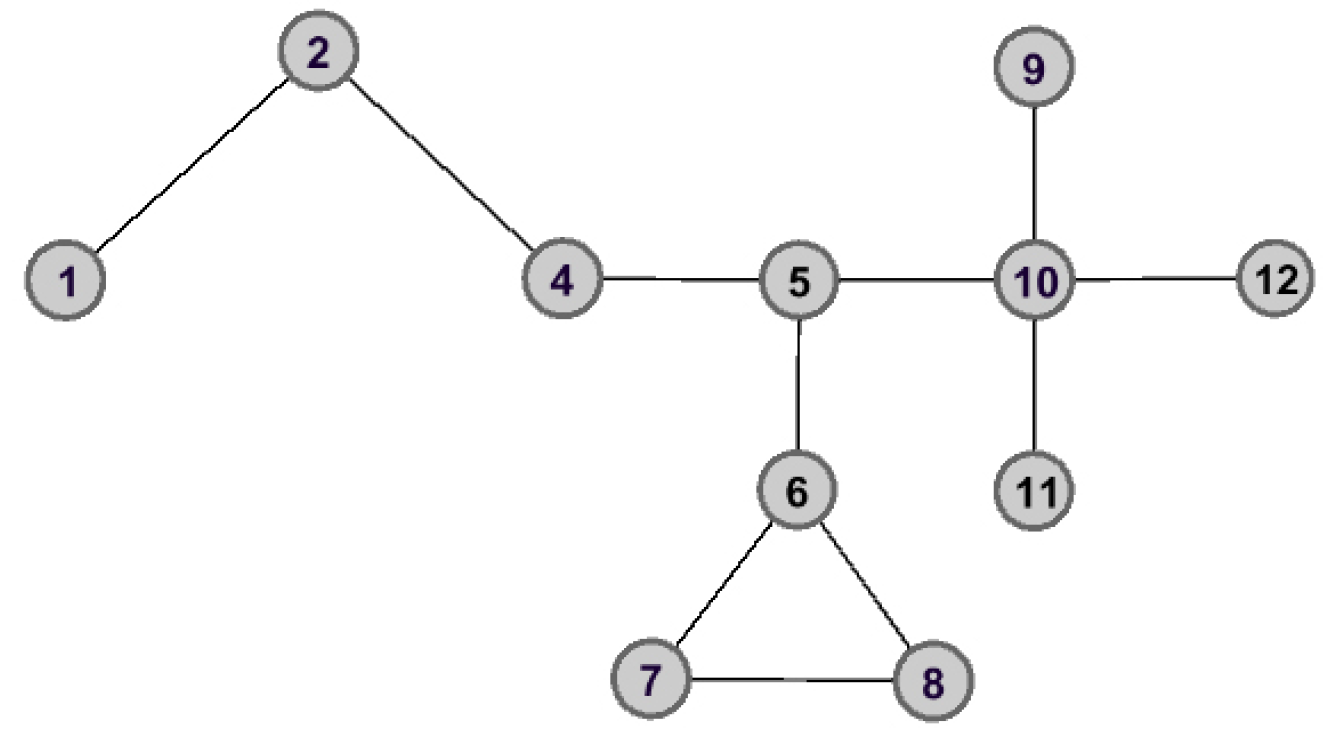
As shown in
Figure 2 and
Figure 3, the graph data are divided into three connected components when node
is removed. However, the removal of node
does not lead to great changes for the structure of graph data, and the remaining graph data is still connected. Therefore, we can make the assertation that node
would play a more important role than that of node
in the aspect of structure information.
3.2. Local Structure Entropy
Removing the important node may lead to the fact that the graph data will be divided into more than one connected component. In order to quantify the global structure information of graph data reasonably, calculating the amount of information about each connected component is a priority problem. Hereinto, we first construct the local structure entropy for each connected component with the help of information entropy.
The information entropy is usually used to measure the amount of information about an event. For the random variable
, given that its probability distribution is
, then the information entropy of
X is
Following Equation (
6), one can find that the more likely an event is to happen, the less information it contains, and vice versa. Once some nodes are removed, the graph data will be changed into more than one connected component with a high probability. This will lead to information decreasing of the corresponding connected component. That is to say, the appearance of connected components is a frequent event and it contains less structure information. This is consistent with the property of information entropy. Therefore, the amount of structure information contained in each connected component can be quantified by information entropy, and it can be defined as local structural entropy. In what follows, we give a detailed description of local structural entropy.
Given that
is graph data with
n nodes and
m edges. The initial graph data are divided into
s connected components after removing the target node from
G, denoted as
. Each connected component contains
nodes, for
. Then, the probability distribution
, for
, can be expressed as
where
for
. Obviously, this probability distribution satisfies the constraint that the sum of probability is equal to 1 for each connected component, i.e.,
.
According to Equation (
6), the local structure entropy with respect to the connected component
, for
, can be defined as
It can be easily found that Equation (
9) has the following properties.
Property 1. Given that G is graph data and is the connected component of G by removing from G. Then, one has that .
Proof. If
, taking
for example, then
. To this
If
, one has that
for any
, then
This completes the proof. □
Property 2. Given that G is a graph data and is the connected component of G by removing from G. Then, the value of is not relevant to the position of in , for .
Proof. For the connected component , the initial probability distribution is . If and change the position, the probability distribution changes into .
With the help of Equation (
9), the following result
comes naturally.
This completes the proof. □
Property 3. Given that and , respectively, are the and connected components of G by removing node from G. Then, their overall structure entropy can be expressed as the sum of local structure entropy, i.e., .
Proof. According to the Equations (
7) and (
8), the probability distributions of
and
is
and
where
, for
and
, for
.
For independent connected components
and
, their joint probability distribution can be expressed as
where
, for
and
.
With the help of Equation (
9), one can have that
This completes the proof. □
3.3. Global Structure Entropy
The key problem in this section is to quantify the information contained in the whole graph data. According to Property 3, one can find that the overall structure entropy of G can be expressed as the sum of local structure entropy about each connected component. In order to distinguish the contribution of different connected components, in what follows, we take the number of edges as the weight value of each local structure entropy.
Given that
G is graph data and taking node
as an example, the global structure entropy of
G is quantified by combining the number of edges and local structure entropy, which can be defined as
where
is the number of edges in each connected component, for
.
The information contained in graph data G will decrease if the more important node is removed. That is to say, the global structure entropy will get the smaller value of . Therefore, the global structure entropy can be regarded as a cost function. In other words, the smaller the value of , the more important the node . For this, one can obtain a possible sequence, such as , where is a certain permutation of . For example, if and only if , and if and only if .
Example 1. To make it easy to understand how to calculate the global structure entropy of each node, in what follows, we apply a simple graph data G shown in Figure 1 to describe the whole process in detail. Taking node
for example, the initial graph data is divided into three connected components after removing node
from
G, which are
and
. With the help of Equations (
7) and (
8), the probability distribution of connected components can be determined, which are
and
Then, the local structure entropy of each connected component could be obtained by Equation (
9), which are
and
With Equation (
16), the global structure entropy is
The calculation of other nodes is the same as that of
. Here, we list the top six nodes in
Table 1.
As can be seen from
Table 1, one has that
, then their importance can be ranked as
. It is worth mentioning that this is consistent with the analysis results in
Section 3.1.
3.4. Algorithm Description
Bearing what was discussed in mind, we give the detailed process of the structure entropy-based node importance ranking method for graph data
G in Algorithm 1. For convenience, here we apply the abbreviation
SE to represent the proposed method.
| Algorithm 1: The SE method. |
![Entropy 25 00941 i001]() |
5. Results and Analysis
In this section, the performance of the proposed method SE is demonstrated on eight real-world datasets. In order to show the results more clearly, all datasets are classified into three classes in the aspect of the number of nodes, i.e., the datasets CONT and LESM with , the datasets POLB, ADJN, FOOT and NETS with , the datasets EMAI and HAMS with .
5.1. Monotonicity Analysis
In this part, we analyze the effectiveness of
SE by comparing the monotonicity of ranking sequence
R obtained by
SE with other benchmark methods.
Table 3 shows the value of monotonicity under
DC,
CC,
IKS,
WR,
GM and
SE methods. One can find that the
SE method can obtain the maximum monotonicity value on all datasets. Obviously, this advantage is independent of the number of nodes.
5.1.1. On CONT and LESM Datasets
From
Table 3, one can find that for the
CONT dataset, all methods except
DC and
IKS, the monotonicity is greater than 0.9000. The main reason is that the two methods, i.e.,
DC and
IKS methods, can be influenced easily by the degree of nodes. It is worth mentioning that the
SE method is less affected by the degree of information about nodes. Therefore, it is superior to
DC and
IKS methods in monotonicity.
On the
LESM dataset, it should be pointed out that both
SE and
GM methods can achieve the maximum value of monotonicity at the same time. From
Table 2, one can find that the
LESM dataset has a higher
value in datasets with a similar number of nodes. For datasets with dense distribution of nodes, the method that the structure information of nodes is considered during the ranking procedure can identify the importance of nodes more efficiently, such as
SE and
GM methods. This also confirms that the
SE method has great merit on small-scale datasets.
5.1.2. On POLB, ADJN, FOOT and NETS Datasets
Since the
POLB,
ADJN and
FOOT datasets have similar scales, most methods achieve similar monotonicity. In this case, the
SE method still shows obvious advantages. One can observe that the
SE method not only obtains the highest monotonicity value on all datasets but also assigns the unique order to each node on
POLB and
FOOT datasets.
Table 2 shows that
and
of the
FOOT dataset are very close. This indicates the fact that there are a large number of nodes with the same degree in the
FOOT dataset. Since the
DC method have no ability to identify the importance of these nodes, it achieves the worst monotonicity. On the contrary, the
SE method can obtain a completely monotonous ranking sequence. What is more, the difference in monotonicity value between
SE and
DC methods is as high as 0.6464. For this, we can guess that the
SE method would show better performance on large-scale graph data.
On the NETS dataset, the CC and GM methods obtain similar monotonicity values, but IKS is still the worst-performing method. Since the NETS dataset has the largest in all datasets, the distribution of nodes is dense. Obviously, the IKS method has the worst performance on this dataset. The main reason is that the IKS method mainly considers the location information of nodes largely, and usually treats nodes with adjacent locations as equally important. On the contrary, the SE method is not affected by the location of nodes and can still obtain the maximum value of monotonicity.
5.1.3. On EMAI and HAMS Datasets
For datasets with a large number of nodes, such as the
EMAI and
HAMS datasets, one can find that the
GM method shows the same advantage as the
SE method and the performance of
CC and
WR methods also increases. As shown in
Table 2, the
HAMS dataset has the highest number of nodes and the smallest clustering coefficient in all datasets, which indicates that the nodes in the
HAMS dataset are more dispersed. In fact, the biggest difference between the
HAMS and other datasets is that it contains 655 isolated nodes. Due to this special structure, the importance of most nodes cannot be identified on the
HAMS dataset. However, the
SE method still obtains the maximum value of monotonicity. This further verifies the effectiveness of the
SE method on datasets with special structure.
5.2. Node Distribution Analysis
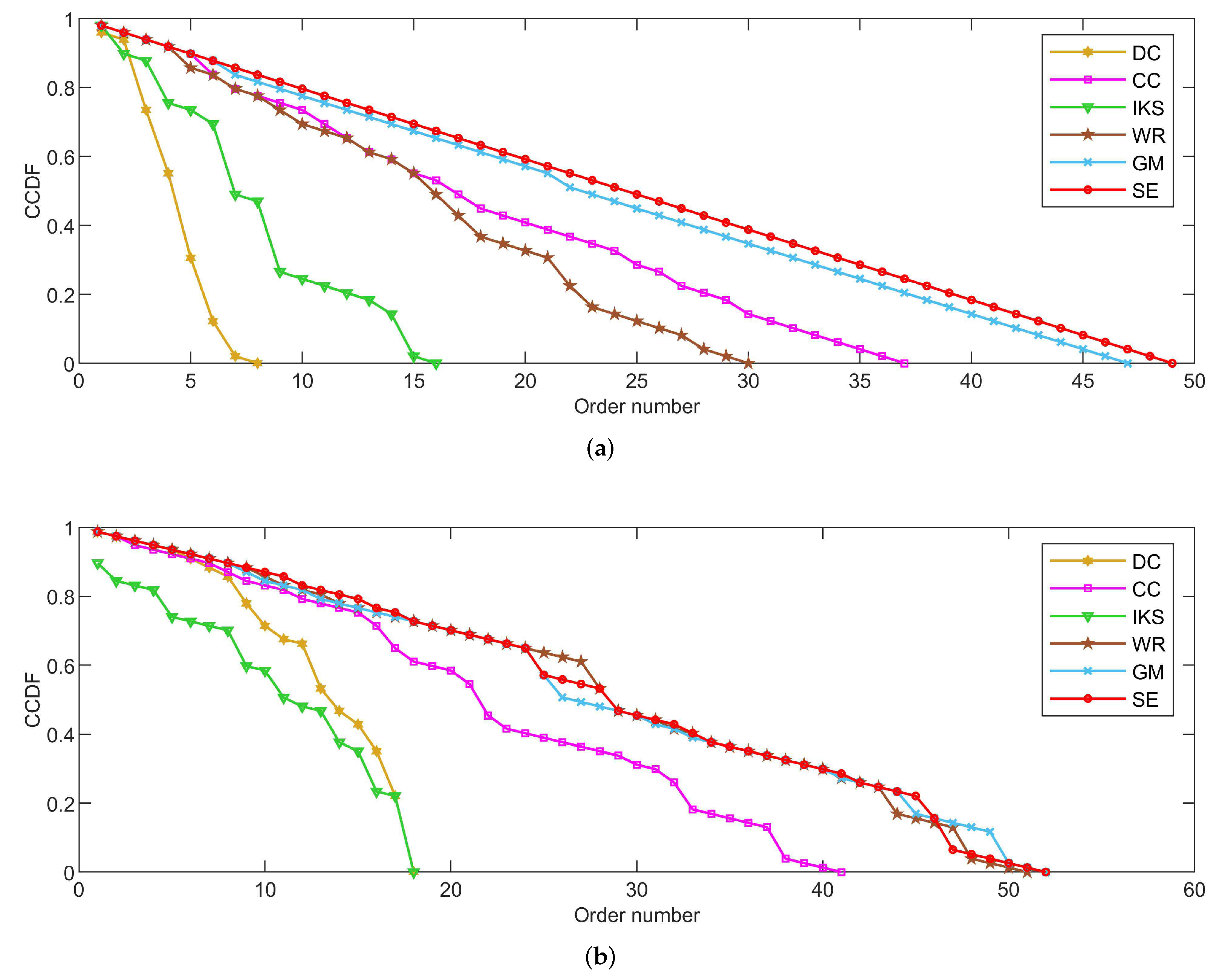
As shown in
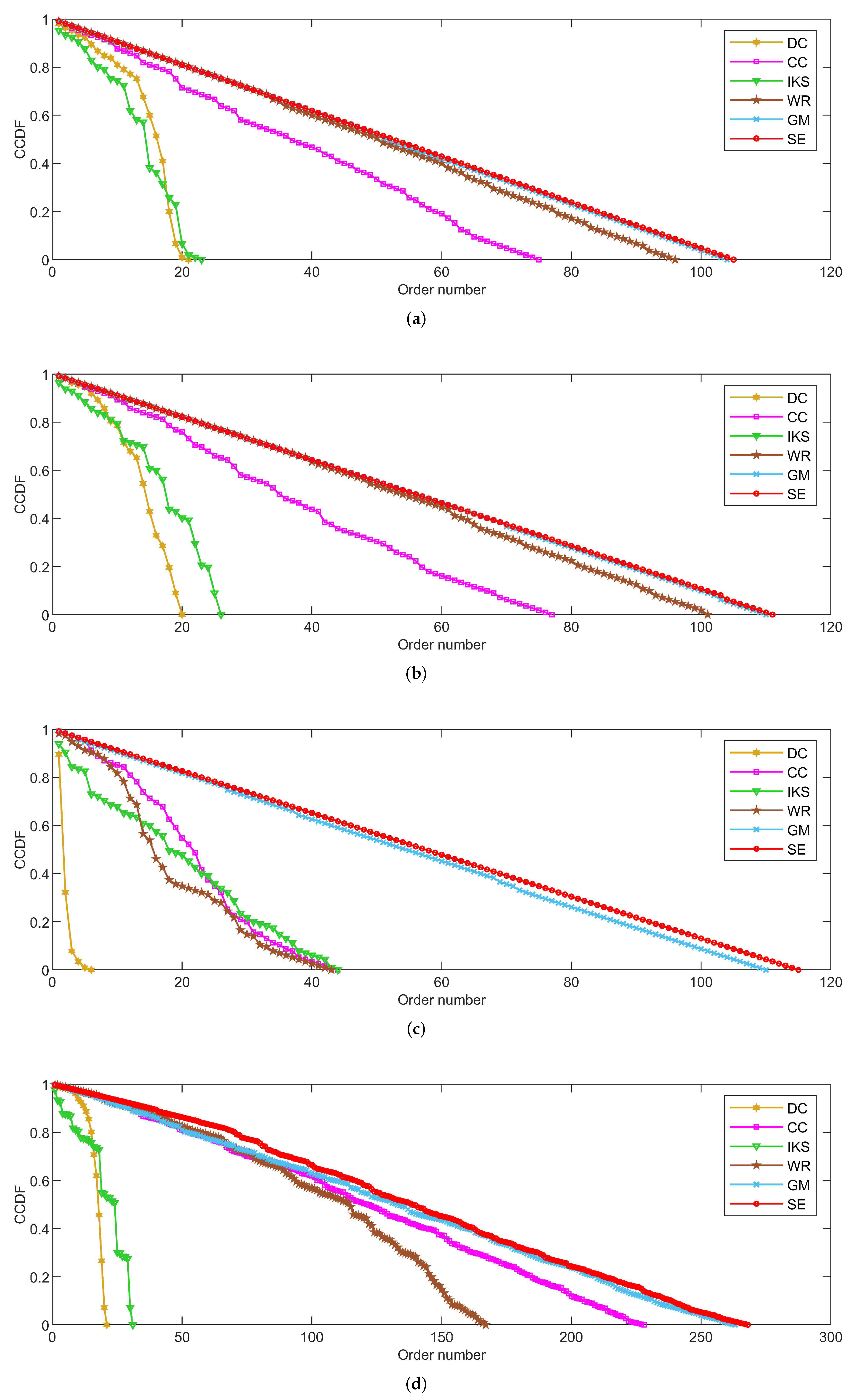
Figure 4,
Figure 5 and
Figure 6, the
CCDF curves express the node distribution of the ranking sequence obtained by different methods. Here, we mainly focus on two perspectives. On the one hand, the descending slope of curves can indicate the discriminability of the corresponding method. The method with the smoother descending slope can distribute the fewer nodes in the same order. On the other hand, we focus on the value of the horizontal axis when the value of the vertical axis is equal to 0, which can represent the total order number that can be generated by the corresponding method. The larger the order number, the better the discriminability of the corresponding method.
From the results, it can be found that the SE method can obtain the smoother descending slope and the maximum order number on most datasets. That is to say, the SE method should distribute the fewer nodes to the same order and more clearly identify the importance of different nodes compared with benchmark methods.
5.2.1. On CONT and LESM Datasets
Figure 4 is the curves of
CCDF on
CONT and
LESM datasets. Obviously, the
SE method obtains the smoothest descending slope and descends keeping in a straight line as shown in
Figure 4a. What is more, the total order number obtained by the
SE method is 49, which is equivalent to the node number of
CONT dataset. In other words, only one node is located at the corresponding location of the ranking sequence. Nicely, this is consistent with that of
Table 3.
From
Figure 4b, it can be easily found that both
GM and
SE methods obtain the maximum order number 52 at the same time. However, that of
DC and
IKS methods is 18, which means that there are 59 nodes whose importance cannot be identified. Such defects are more evident on larger-scale datasets and this can be confirmed by the following experiments. In addition, although there is no method that can completely identify the importance of all nodes, the
SE method shows greater advantage when the order number is between 10 and 20.
Figure 4.
The curves of CCDF on (a) CONT and (b) LESM datasets.
Figure 4.
The curves of CCDF on (a) CONT and (b) LESM datasets.
5.2.2. On POLB, ADJN, FOOT and NETS Datasets
Figure 5 is the curves of
CCDF on
POLB,
ADJN,
FOOT and
NETS datasets. As can be seen, the advantage of the
SE method is obvious. On the one hand, the
SE method achieves the maximum order number on all datasets. This reflects the fact that the
SE method can distribute fewer nodes to the same order compared with other benchmark methods. On the other hand, the
SE method obtains the smoothest descending slope in all of the comparison methods. Especially on the
POLB and
FOOT datasets,
SE is the only method that can descend keeping in a straight line. For this, we can guess that the
SE method would show better performance on large-scale datasets.
On the whole, the performance of DC and IKS methods is relatively poor. The order number obtained by DC and IKS methods is only to of the total number of nodes. This means that nearly to of nodes’ importance cannot be identified. Frankly speaking, they cannot be regarded as good ranking methods.
Figure 5.
The curves of CCDF on (a) POLB; (b) ADJN; (c) FOOT; and (d) NETS datasets.
Figure 5.
The curves of CCDF on (a) POLB; (b) ADJN; (c) FOOT; and (d) NETS datasets.
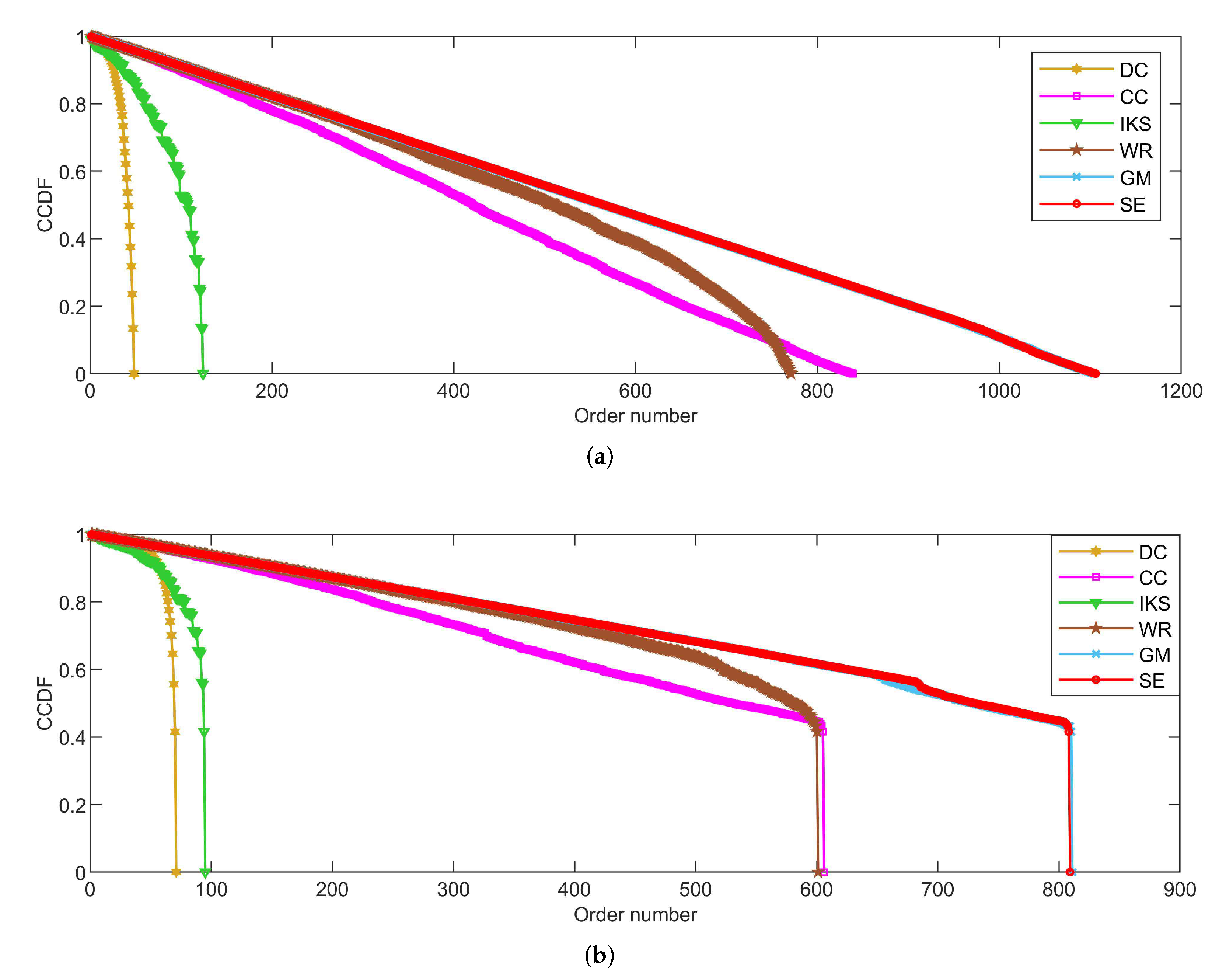
5.2.3. On EMAI and HAMS Datasets
Figure 6 is the curves of
CCDF for two large-scale datasets, i.e., the
EMAI and
HAMS datasets. As can be seen, the performance of all methods can be divided into three categories roughly, i.e., well-performing
SE and
GM methods, moderately-performing
CC and
WR methods, and poorly-performing
DC and
IKS methods. Especially in
Figure 6b, it should be pointed out that the curves of
CCDF obtained by all methods have a process of vertical decline. The main reason for this phenomenon is that it is difficult to identify the importance of isolated nodes. Here, the importance score of an isolated node is set to the minimum in all methods. Although the importance of isolated nodes is not significant, this special structure can affect the importance scores of other nodes. From
Figure 6b, it can be easily seen that the
SE method still obtains the smoothest descending slope in all comparison methods. What is more, the biggest difference in total order numbers between
SE and other methods can exceed 700. This further validates the effectiveness of
SE method proposed in this paper.
Figure 6.
The curves of CCDF on (a) EMAI and (b) HAMS datasets.
Figure 6.
The curves of CCDF on (a) EMAI and (b) HAMS datasets.
5.3. Robustness Analysis
In this subsection, we evaluate the robustness of the method by comparing the curves of and of SE method with that of other benchmark methods.
- -
The left side of
Figure 7,
Figure 8,
Figure 9 and
Figure 10 is the curves of
, which shows the number changes of connected components. The horizontal axis of subfigures represents the proportion of removed nodes and the vertical axis represents the number of connected components after removing nodes from the dataset.
- -
The right side of
Figure 7,
Figure 8,
Figure 9 and
Figure 10 is the curves of
, which shows the variation of the maximum connected component. The horizontal axis of subfigures represents the proportion of removed nodes and the vertical axis represents the value of
calculated by Equation (
20).
The larger value of and the smaller value of , the stronger the robustness of the corresponding ranking method. From the result, it can be found that the curves of SE method obtain the faster uptrend and the curves of SE method obtain the faster downtrend in most datasets as the proportion of removed nodes increases.
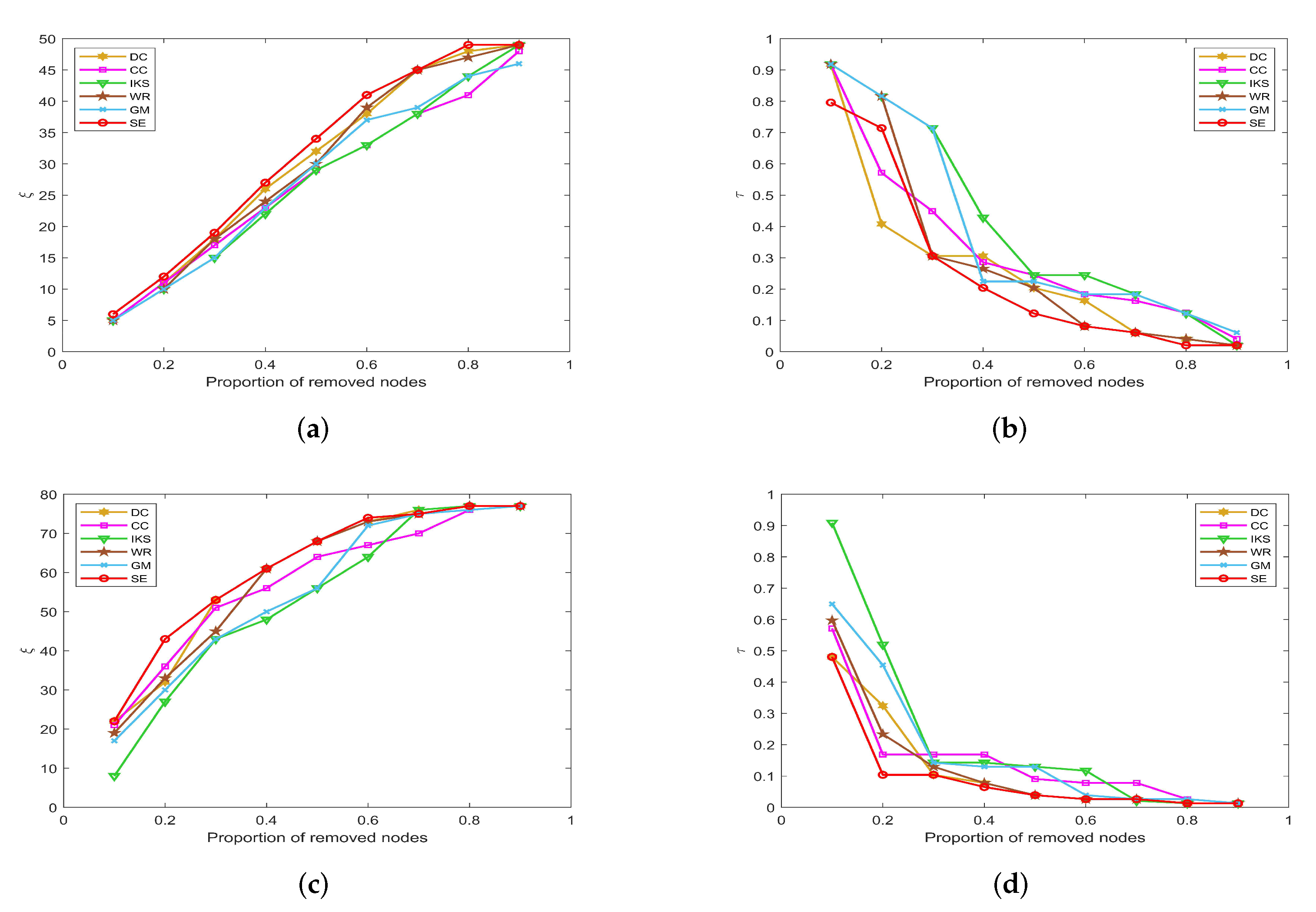
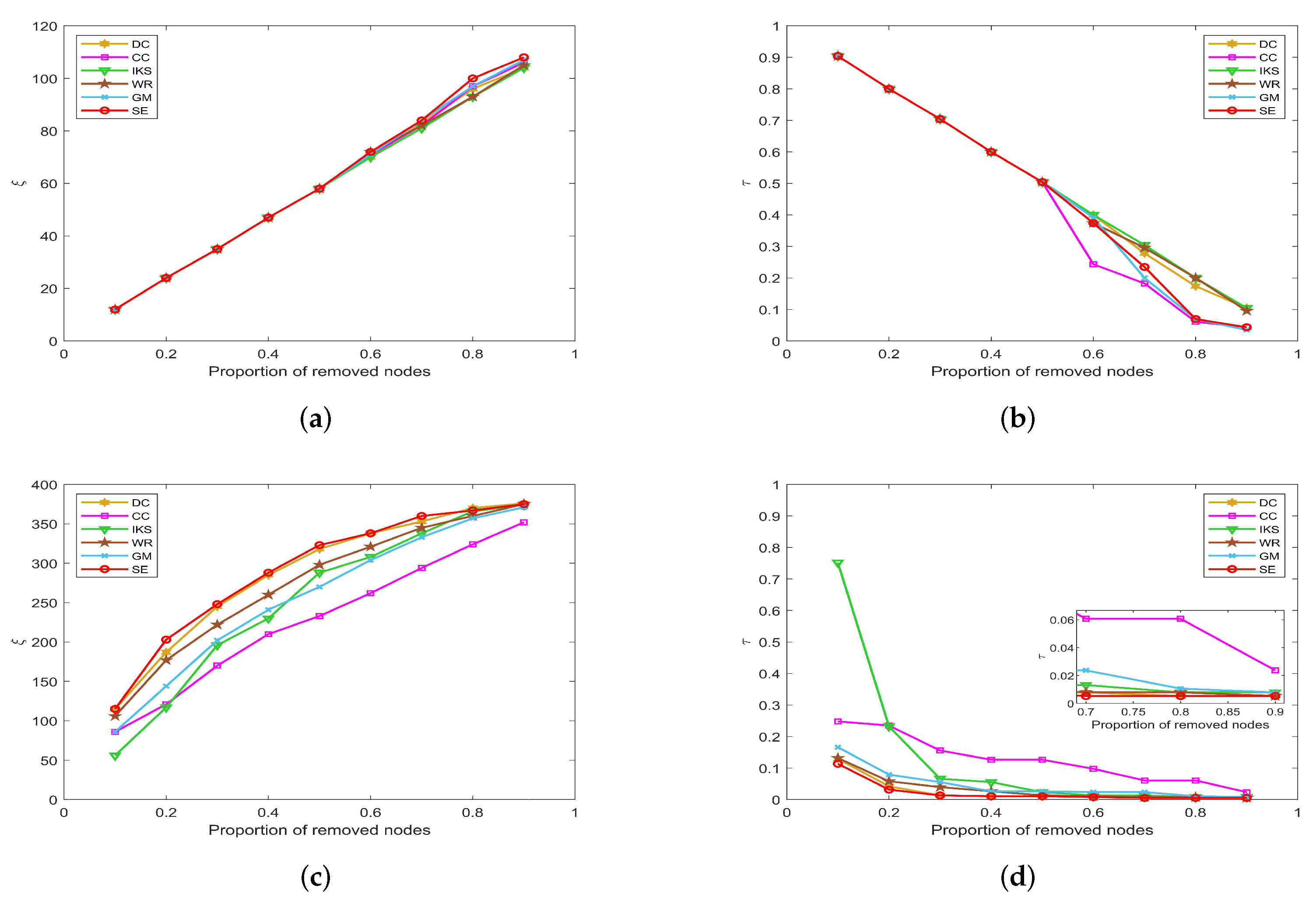
5.3.1. On CONT and LESM Datasets
Figure 7 is the curves of
and
on
CONT and
LESM datasets. As can be seen from
Figure 7a, when the proportion of removed nodes changes from 10% to 90%, the
SE method can always obtain the maximum value of
. Obviously, the
SE method has the most obvious upward trend compared with other methods. In
Figure 7b, when the proportion of removed nodes is only 10%, the
value of all methods is equal to 0.9184 except
SE method. In fact, the value of
obtained by
SE method only is 0.7959, which is 0.1225 lower than other methods. This advantage is more pronounced after the proportion of removed nodes reaches 30%.
Figure 7.
The curves of and on (a,b) CONT and (c,d) LESM datasets.
Figure 7.
The curves of and on (a,b) CONT and (c,d) LESM datasets.
On the
LESM dataset, as shown in
Figure 7c,d, the differences between the six methods are obvious. Especially when the proportion of removed nodes is 20%, the value of
corresponding to
DC,
CC,
IKS,
WR,
GM and
SE methods is 32, 36, 27, 33, 30 and 43, respectively. Obviously, the
SE method is superior to other methods. What is more, the value of
corresponding to the above methods is 0.3247, 0.1688, 0.5193, 0.2338, 0.4545 and 0.1039, respectively. One can find that the difference between the
SE and
IKS method is as high as 0.4154. That is to say, the maximum connected component of the
IKS method contains 40 nodes, while that of the
SE method contains only 8 nodes. This fully confirms that
SE method has better robustness in small-scale datasets.
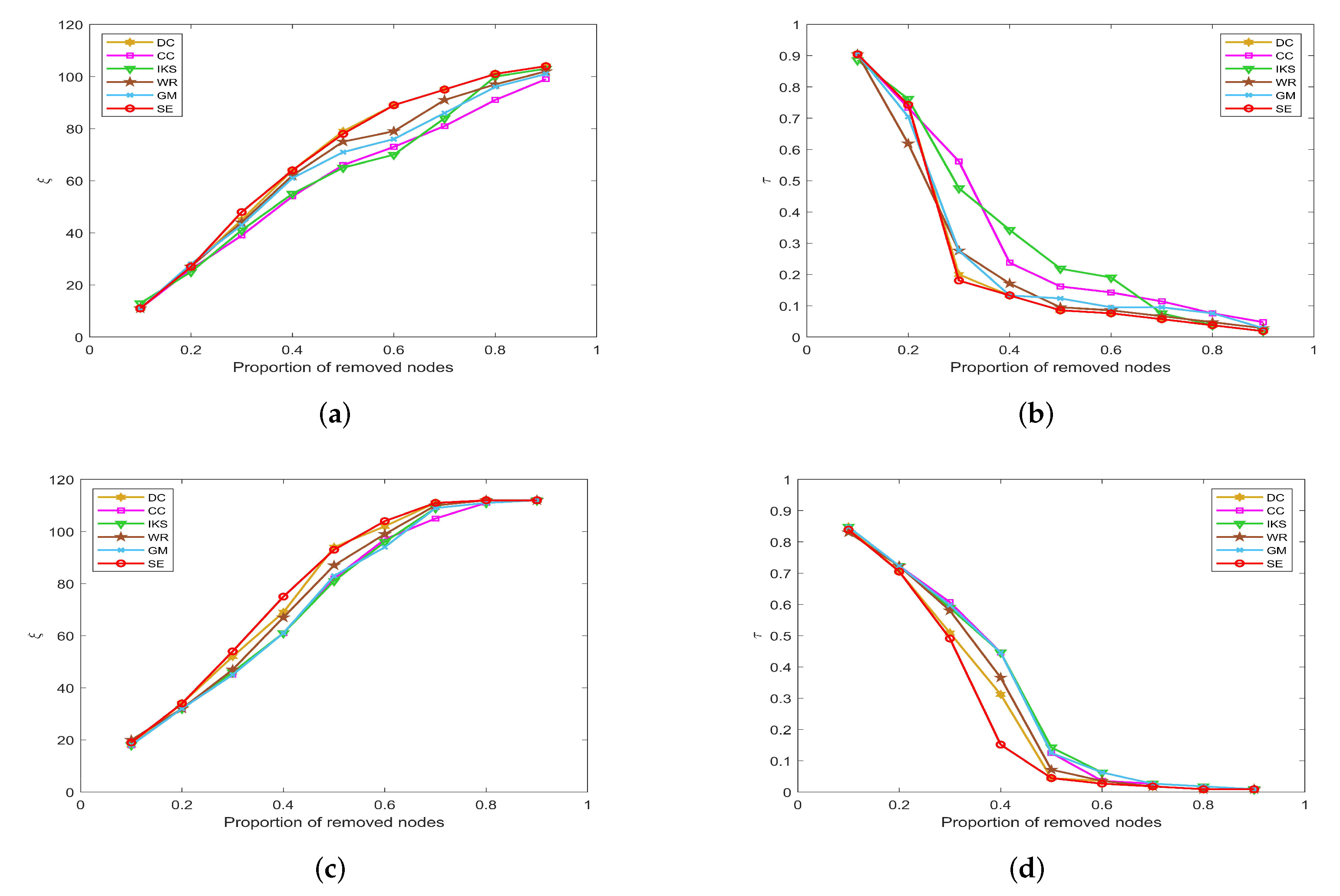
5.3.2. On POLB, ADJN, FOOT and NETS Datasets
Figure 8 is the curves of
and
on
POLB and
ADJN datasets. With the increase in dataset scale, the robustness of the
CC method decreases significantly, but the advantage of the
DC method becomes more obvious. As shown in
Figure 8a,c, both
DC and
SE methods obtain the same value of
in most cases. The main reason is that the
DC method regards the nodes with larger degrees as the more important nodes, and these nodes can affect the number of connected components to a great extent. On the whole, the robustness of the
IKS method is relatively poor. From
Figure 8b,d, it can be found that the curves of
corresponding to the
SE method can maintain the fastest downtrend when the proportion of removed nodes starts from 30%.
Figure 8.
The curves of and on (a,b) POLB and (c,d) ADJN datasets.
Figure 8.
The curves of and on (a,b) POLB and (c,d) ADJN datasets.
Figure 9 is the curves of
and
on
FOOT and
NETS datasets. One can observe that all methods obtain similar ranking sequences on
FOOT dataset. As shown in
Figure 9a,b, six ranking methods show the same robustness until the proportion of removed nodes is as high as 50%. However, in fact, when the proportion of removed nodes is greater than 50%, the
SE method obtains the largest value of
, and the
CC method obtains the smallest value of
.
Figure 9.
The curves of and on (a,b) FOOT and (c,d) NETS datasets.
Figure 9.
The curves of and on (a,b) FOOT and (c,d) NETS datasets.
It is a pity that the
CC method does not show better robustness on datasets with more nodes, such as the
NETS dataset. From
Figure 9c, it can be found that the value of
obtained by the
CC method is much lower than that of other methods, and the maximum difference between
CC and
SE methods reaches as high as 90. Similarly, as shown in
Figure 9d, the value of
corresponding to the
CC method is much higher than other methods, and the maximum difference between
CC and
SE methods is as high as 0.2031. For this, we can guess that the
SE method would show more excellent robustness on large-scale dataset.
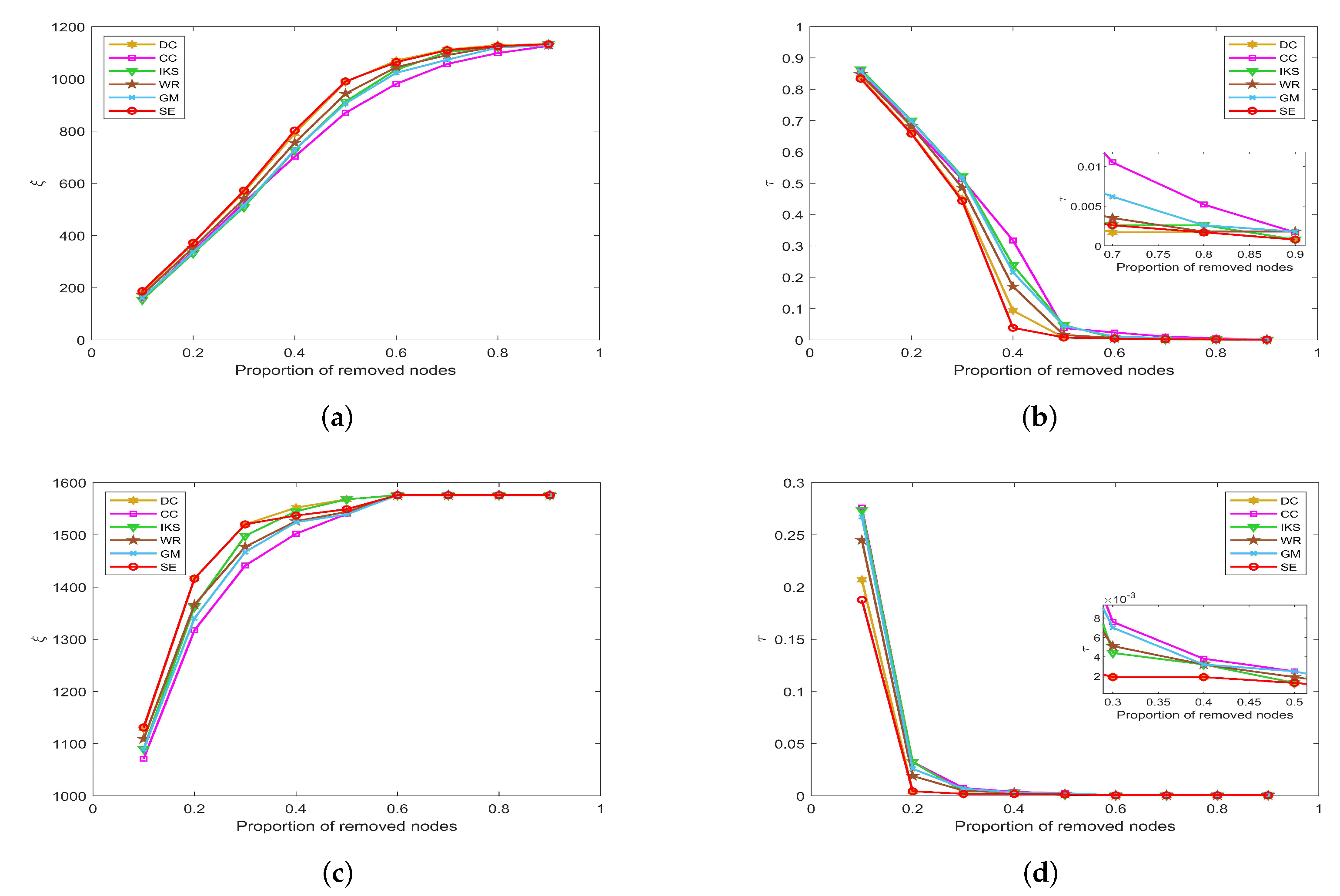
5.3.3. On EMAI and HAMS Datasets
Figure 10 is the curves of
and
on
EMAI and
HAMS datasets. As shown in
Figure 10a,b, the
SE and
DC methods can maintain absolute superiority compared with other benchmark methods.
Table 2 shows that the
EMAI dataset has the largest value of
m and
is as high as 9.6230. For this kind of tightly connected large-scale dataset, the
CC and
IKS methods perform poorly, and WE and
GM methods are always in the middle position. The advantages of
DC and
SE methods are not easy to distinguish. It should be pointed out that all methods are close to the minimum value of
when the proportion of removed nodes is greater than 40%. However, in fact, when the proportion of removed nodes is equal to 40%, the
SE method is significantly better than other methods. This fully confirms that the
SE method has better robustness compared with other benchmark methods.
Figure 10.
The curves of and on (a,b) EMAI and (c,d) HAMS datasets.
Figure 10.
The curves of and on (a,b) EMAI and (c,d) HAMS datasets.
By observing
Figure 10c,d, the value of
and
will not change after the proportion of removed nodes is greater than 60%. The reason is that the
HAMS dataset contains 655 isolated nodes, which is more than 40% of the total number of nodes. However, in fact, the
SE method can obtain the minimum value of
when the proportion of removed nodes is between 10% and 50%. This further verifies that the
SE method is also more robust for datasets with special structures.
5.4. Accuracy Analysis
In this part, we mainly analyze the accuracy of the
SE method to identify key nodes in terms of the
SIR model. Herein, we select the top 2, 4, 6, 8 and 10 nodes listed in the front of the ranking sequence as seeds for datasets with
. For datasets with more than 1000 nodes, we select top 20, 40, 60, 80 and 100 nodes as seeds. In terms of the
SIR model, one can find that the disease cannot spread if the infected probability
is too small. The main reason is that the seeds have only a small probability to affect their neighbors. Conversely, when the infected probability is too high, all nodes will become infected state. This is meaningless for accuracy analysis. Therefore, we mainly consider the propagation ability of seeds at the threshold of infected probability [
46], i.e.,
and
.
Figure 11,
Figure 12 and
Figure 13 show the propagation ability of seeds obtained by six ranking methods on eight real-world datasets. From the results, one can find that the
SE method can obtain a more accurate ranking sequence.
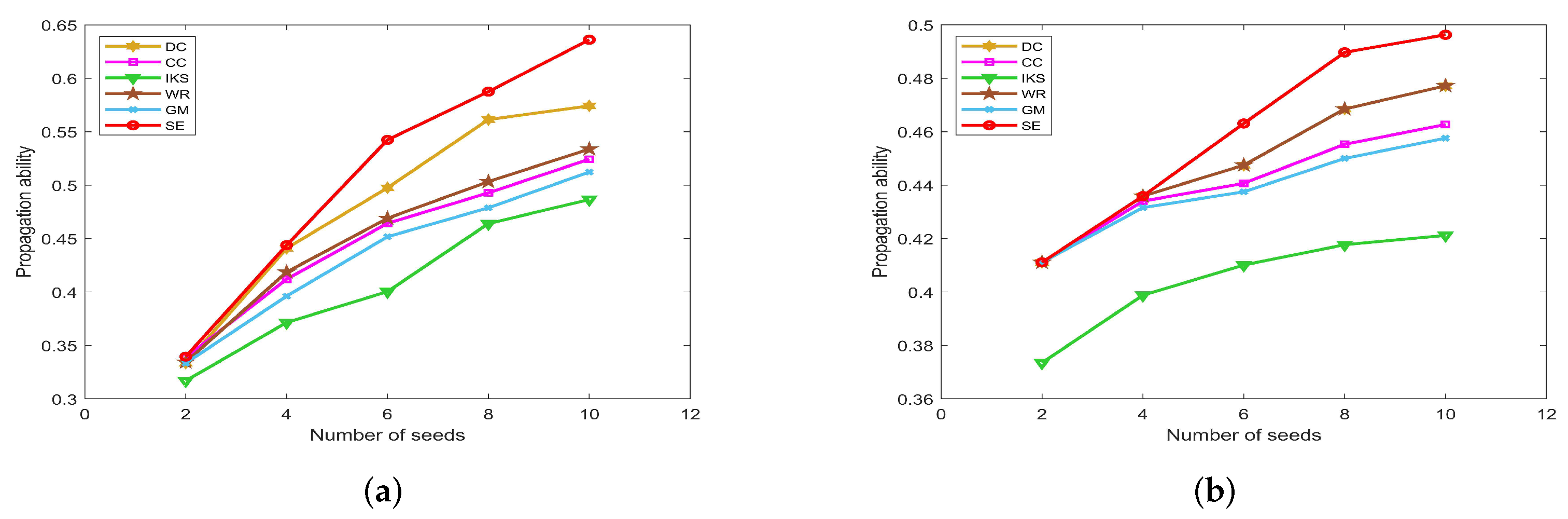
5.4.1. On CONT and LESM Datasets
Figure 11 is the propagation ability of key nodes obtained by different methods on two small-scale datasets. Obviously, the
SE method shows a more pronounced upward trend. That is to say, the top 10 key nodes obtained by the
SE method have much higher propagation ability compared with other benchmark methods. Especially for the
CONT dataset, the maximum propagation ability of
SE method is 0.6361, which is 0.1495 higher than that of
IKS method. Similarly, the maximum propagation ability of the
SE method is 0.4963 on the
LESM dataset, which is 0.0751 higher than that of the
IKS method. Certainly, the
IKS method performs poorly in most experiments. It can be seen from the previous experiments that the
IKS method is not clear to identify the importance of different nodes. As a result, these nodes obtain the lowest propagation ability.
Figure 11.
The propagation ability of seeds on (a) CONT and (b) LESM datasets.
Figure 11.
The propagation ability of seeds on (a) CONT and (b) LESM datasets.
Figure 11a shows the fact that the
DC method is obviously superior to the
WR method on the
CONT dataset. However, the propagation ability curves of
DC and
WR methods completely coincide on
LESM dataset, as shown in
Figure 11b. This is mainly because the top 10 nodes obtained by these two methods are the same. As can be seen from the foregoing discussion, both
DC and
WR methods consider the degree information of nodes. If the dataset contains many nodes with the same degree, the accuracy of
DC and
WR methods will decrease significantly. On the contrary, the
DC and
WR methods can obtain more accurate ranking sequences for datasets with significantly different degrees of nodes, such as the
LESM dataset. However, in fact, the
SE method takes the local and global structure information into account, and the accuracy of it is obviously better than that of
DC and
WR methods.
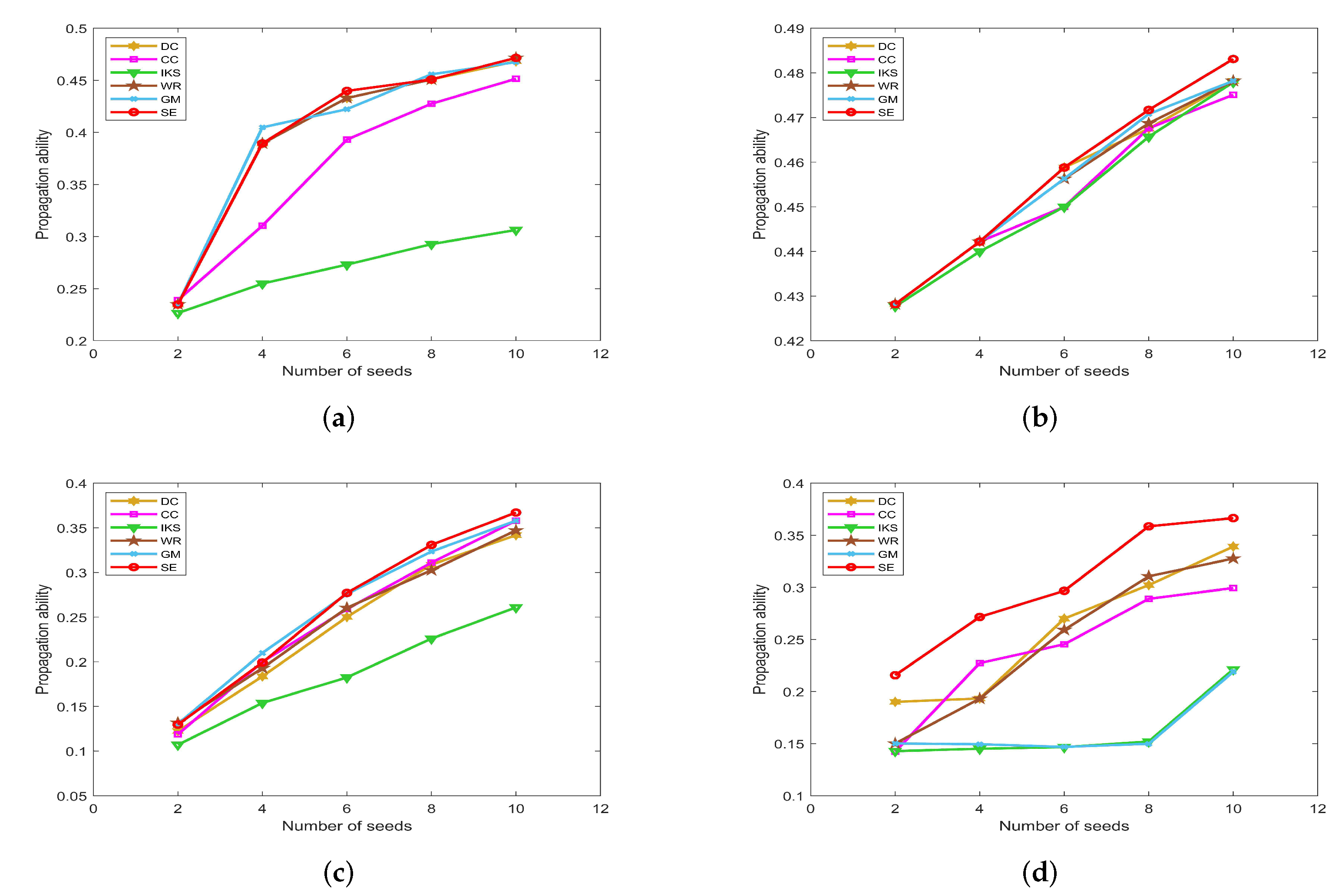
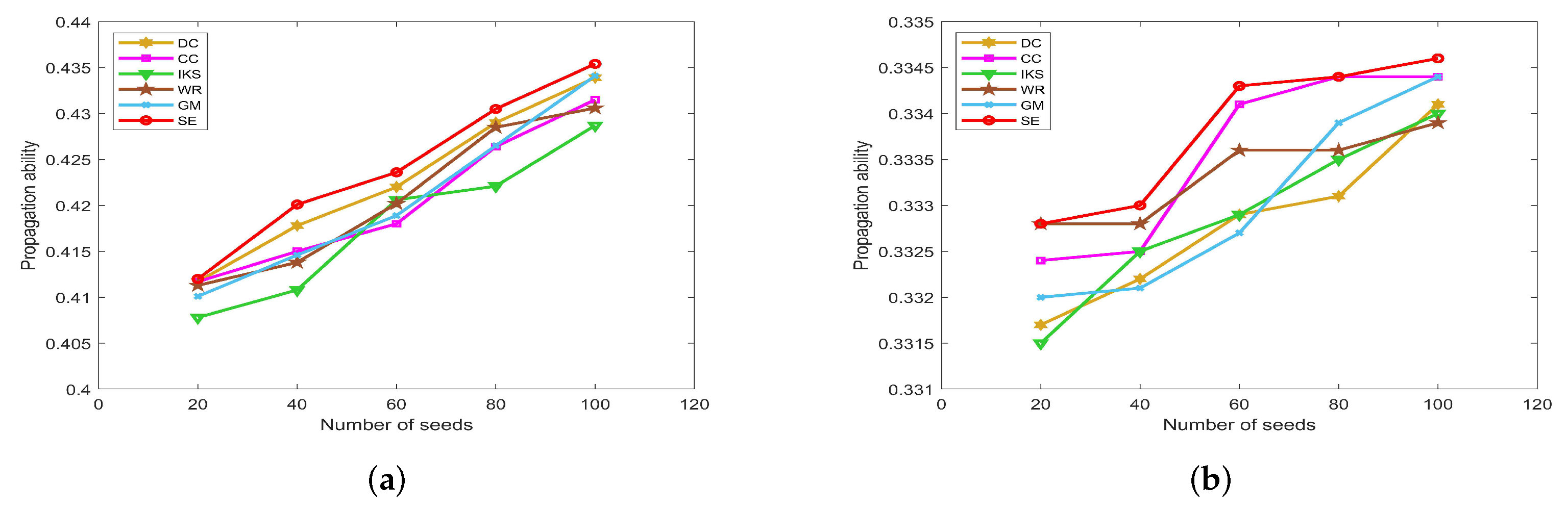
5.4.2. On POLB, ADJN, FOOT and NETS Datasets
Figure 12 is the propagation ability of key nodes obtained by different methods on
POLB,
ADJN,
FOOT and
NETS datasets. On
POLB dataset, the propagation ability curves of
DC,
WR,
GM and
SE methods all have an obvious upward trend, while the
IKS is still the worst-performing method as shown in
Figure 12a.
By observing
Figure 12b,c, it can be found that the distribution of propagation ability curves is relatively dense. The main reason is that most of the methods obtain the same key nodes. For example, all methods treat nodes 18 and 3 as the top 2 key nodes except
IKS method on
ADJN dataset. Therefore, most methods achieve similar propagation ability curves. In this case, it should be pointed out that the
SE method still has a slight advantage.
Figure 12.
The propagation ability of seeds on (a) POLB; (b) ADJN; (c) FOOT; and (d) NETS datasets.
Figure 12.
The propagation ability of seeds on (a) POLB; (b) ADJN; (c) FOOT; and (d) NETS datasets.
This advantage of the
SE method is more significant on the
NETS dataset. As can be seen from
Figure 12d, it obtains the maximum propagation ability among all of the benchmark methods. Especially when the number of seeds is 8, the propagation ability of the
SE method is 0.2087 higher than that of the
GM method and 0.2065 higher than that of the
IKS method. This means that the key nodes obtained by the
SE method can infect 136 nodes, which is 79 higher than that of the
GM method and 78 higher than that of the
IKS method. Therefore, we can conclude that the ranking sequence obtained by the
SE method is more accurate compared with other benchmark methods.
5.4.3. On EMAI and HAMS Datasets
Figure 13 is the curves of propagation ability on
EMAI and
HAMS datasets. As the scale of the dataset increases, the number of seeds we selected also increases to 100. From
Figure 13a, one can find that the
SE method can maintain the obvious upward trend. One can find that the
SE method outperforms the other benchmark methods after the number of seeds exceeds 20. Since the special structure of the
HAMS dataset, the variation range of propagation ability is small. For this, the
SE method still has a slight advantage compared with other methods as shown in
Figure 13b. This further confirms that the
SE method has higher ranking accuracy compared with other benchmark methods.
Figure 13.
The propagation ability of seeds on (a) EMAI and (b) HAMS datasets.
Figure 13.
The propagation ability of seeds on (a) EMAI and (b) HAMS datasets.
5.5. Computational Complexity Analysis
Given that is a graph data with n nodes and m edges, and the proposed SE method includes two stages in the process of constructing the score function for nodes. Firstly, the computational complexity of calculating the local structure entropy is , where s is the number of connected components in G. Secondly, the computational complexity of calculating the global structure entropy is . Therefore, the total computational complexity of SE method is .
Table 4 lists the computational complexity of the proposed
SE method and other benchmark methods. One can find that the computational complexity of the
CC method is
, and that of the
GM method is
[
47]. Due to
s being the number of connected components after removing the target node, the value of
s is far smaller than
m and
n. That is to say, the computational complexity of the
SE method is much lower than that of the
CC and
GM methods. Although
DC and
IKS methods have the lowest computational complexity, their performance is far worse than that of other methods in previous experiments. In general, although the computational complexity of the
SE method is in the middle position among all comparison methods, it can obtain better ranking results.
6. Conclusions
In order to further explore the influence of structure information on node importance, this paper has designed a structure entropy-based node importance ranking method. The score function of node importance is constructed from the perspective of node removal, which transformed the importance of nodes into the global structure entropy of graph data. After removing the target node, the local structural entropy of the connected component is calculated by using the degree information of nodes. Furthermore, the global structure entropy of graph data is constructed in terms of the number of connected components. A large number of experiments demonstrated that the proposed method is more advantageous in aspects of monotonicity, node distribution and ranking accuracy.
Although the proposed method has better performance on most datasets, it is not hard to see that this paper only discussed the undirected and unweighted graph data with less than 2000 nodes due to the limitation of the experimental platform. In our following studies, we will seek more resources to verify the performance of the proposed method on larger-scale graph data and other types of graph data.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}