
Kernel-Free Quadratic Surface Regression for Multi-Class Classification

Abstract
:1. Introduction
2. Related Works
2.1. Notations
2.2. Least Squares Regression Classifier
2.3. Discriminative Least Squares Regression Classifier
3. Kernel-Free Nonlinear Least Squares Regression Classifiers
3.1. Hard Quadratic Surface Least Squares Regression Classifier
3.2. Soft Quadratic Surface Least Squares Regression Classifier
| Algorithm 1 SQSLSR |
| Input: Training set , maximum iteration number , parameter Output: . |
4. Discussion
4.1. Convergence Analysis
4.2. Computational Complexity
4.3. Interpretability
5. Numerical Experiments
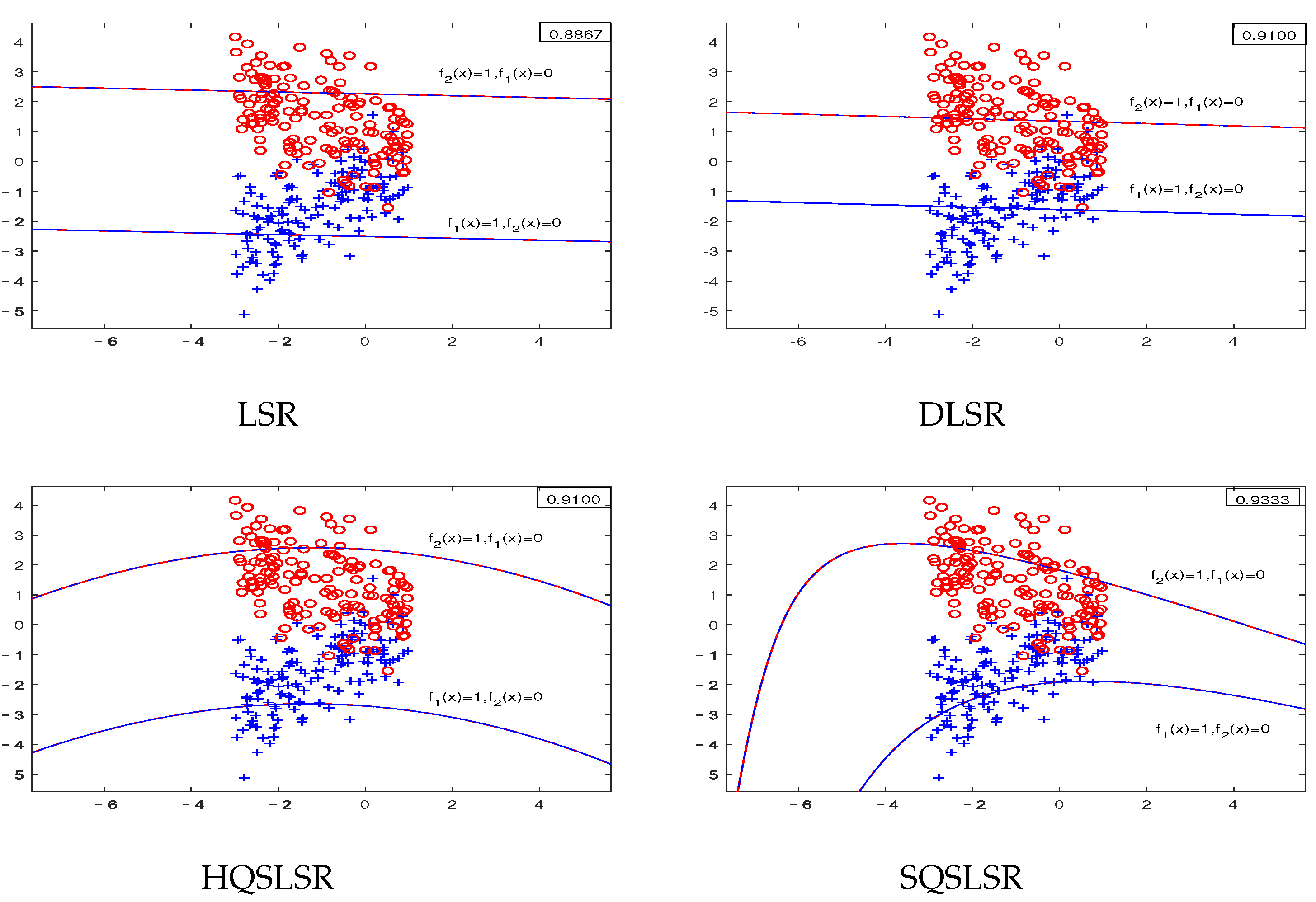
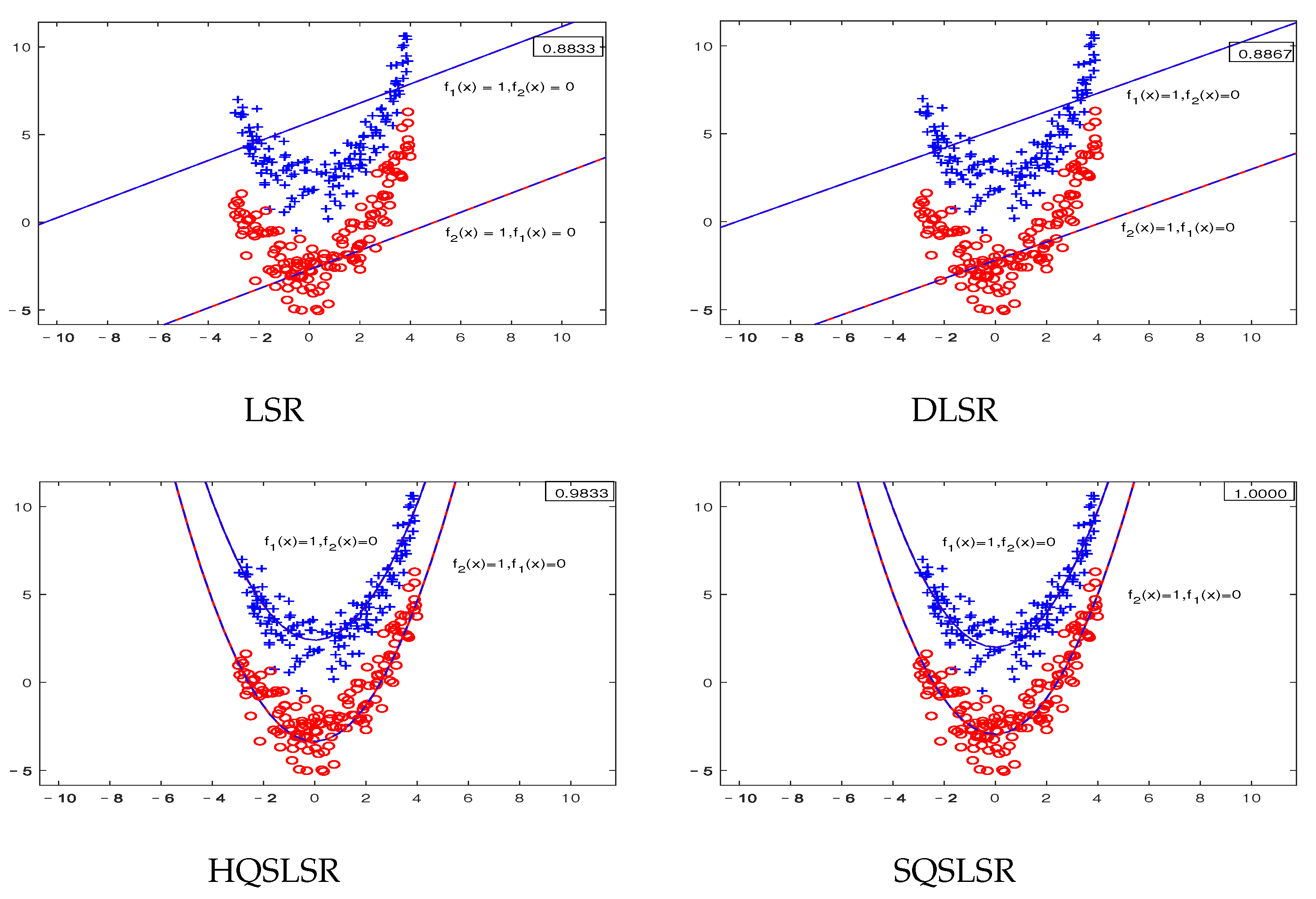
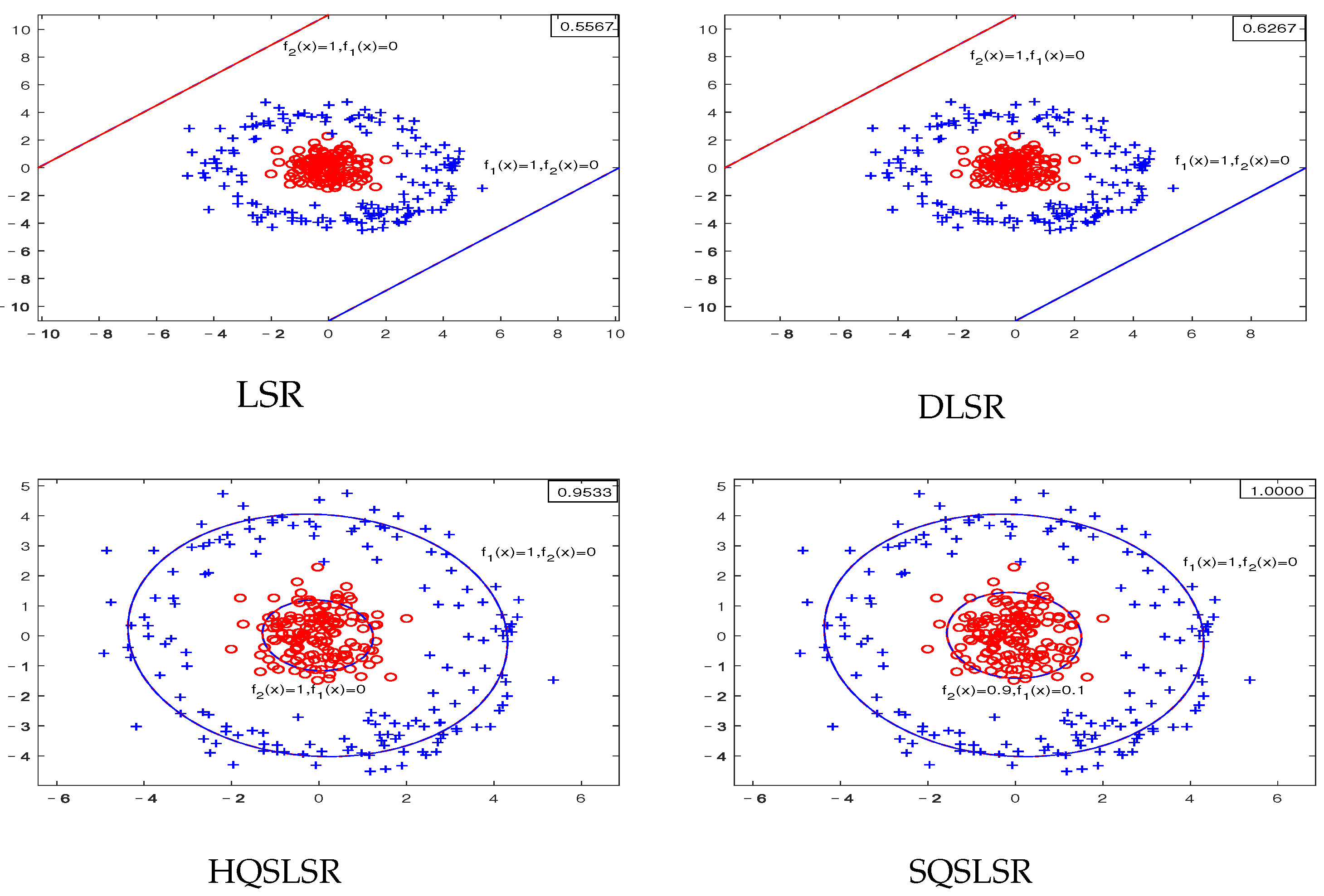
5.1. Experimental Results on Artificial Datasets
5.2. Experimental Results on Benchmark Datasets
5.3. Convergence Analysis
5.4. Statistical Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hastie, T.; Tibshirani, R.; Buja, A. Flexible discriminant analysis by optimal scoring. J. Am. Stat. Assoc. 1993, 89, 1255–1270. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. Linear methods for classification. In The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009; Volume 2, pp. 103–106. [Google Scholar]
- Xiang, S.; Nie, F.; Meng, G.; Pan, C.; Zhang, C. Discriminative least squares regression for multiclass classification and feature selection. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1738–1754. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Wang, L.; Xiang, S.; Liu, C. Retargeted least squares regression algorithm. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 2206–2213. [Google Scholar] [CrossRef] [PubMed]
- Wen, J.; Li, Z.; Ma, Z.; Xu, Y. Inter-class sparsity based discriminative least square regression. Neural Netw. 2016, 102, 36–47. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Ge, H.; Yang, J.; Tong, Y. Relaxed group low rank regression model for multi-class classification. Multimed. Tools Appl. 2021, 80, 9459–9477. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, X.; Pan, C. Msdlsr: Margin scalable discriminative least squares regression for multicategory classification. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 2711–2717. [Google Scholar] [CrossRef]
- Wang, L.; Liu, S.; Pan, C. RODLSR: Robust discriminative least squares regression model for multi-category classification. In Proceedings of the 2017 IEEE ICASSP, New Orleans, LA, USA, 5–9 March 2017; pp. 2407–2411. [Google Scholar]
- Fang, X.; Xu, Y.; Li, X.; Lai, Z. Regularized label relaxation linear regression. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1006–1018. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, X.; Kittler, J. Low-rank discriminative least squares regression for image classification. Signal Process. 2020, 173, 107485. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Zhou, S. Discriminative least squares regression for multiclass classification based on within-class scatter minimization. Appl. Intell. 2022, 52, 622–635. [Google Scholar] [CrossRef]
- Zhang, J.; Li, W.; Tao, R.; Du, Q. Discriminative marginalized least squares regression for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3148–3161. [Google Scholar] [CrossRef]
- Zhang, R.; Nie, F.; Li, X. Feature selection under regularized orthogonal least square regression with optimal scaling. Neurocomputing 2018, 273, 547–553. [Google Scholar] [CrossRef]
- Zhao, S.; Wu, J.; Zhang, B.; Fei, L. Low-rank inter-class sparsity based semi-flexible target least squares regression for feature representation. Pattern Recognit. 2022, 123, 108346. [Google Scholar] [CrossRef]
- An, S.; Liu, W.; Venkatesh, S. Face recognition using kernel ridge regression. In Proceedings of the 2007 IEEE CVPR, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–7. [Google Scholar]
- Zhang, X.; Chao, W.; Li, Z.; Liu, C.; Li, R. Multi-modal kernel ridge regression for social image classification. Appl. Soft Comput. 2018, 67, 117–125. [Google Scholar] [CrossRef]
- Dagher, I. Quadratic kernel-free nonlinear support vector machine. J. Glob. Optim. 2008, 41, 15–30. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Luo, J.; Fang, S.; Deng, A.; Guo, X. Soft quadratic surface support vector machine for binary classification. Asia Pac. J. Oper. Res. 2016, 33, 1650046. [Google Scholar] [CrossRef]
- Mousavi, J.; Gao, Z.; Han, L.; Lim, A. Quadratic surface support vector machine with L1 norm regularization. J. Ind. Manag. Optim. 2022, 18, 1835–1861. [Google Scholar] [CrossRef]
- Zhan, Y.; Bai, Y.; Zhang, W.; Ying, S. A p-admm for sparse quadratic kernel-free least squares semi-supervised support vector machine. Neurocomputing 2018, 306, 37–50. [Google Scholar] [CrossRef]
- Gao, Z.; Fang, S.; Gao, X.; Luo, J.; Medhin, N. A novel kernel-free least squares twin support vector machine for fast and accurate multi-class classification. Knowl. Based Syst. 2021, 226, 107123. [Google Scholar] [CrossRef]
- Luo, A.; Yan, X.; Luo, J. A novel chinese points of interest classification method based on weighted quadratic surface support vector machine. Neural Process. Lett. 2022, 54, 1–20. [Google Scholar] [CrossRef]
- Ye, J.; Yang, Z.; Li, Z. Quadratic hyper-surface kernel-free least squares support vector regression. Intell. Data Anal. 2021, 25, 265–281. [Google Scholar] [CrossRef]
- Luo, J.; Tian, Y.; Yan, X. Clustering via fuzzy one-class quadratic surface support vector machine. Soft Comput. 2017, 21, 5859–5865. [Google Scholar] [CrossRef]
- Bai, Y.; Han, X.; Chen, T.; Yu, H. Quadratic kernel-free least squares support vector machine for target diseases classification. J. Comb. Optim. 2015, 30, 850–870. [Google Scholar] [CrossRef]
- Gao, Z.; Wang, Y.; Huang, M.; Luo, J.; Tang, S. A kernel-free fuzzy reduced quadratic surface ν-support vector machine with applications. Appl. Soft Comput. 2022, 127, 109390. [Google Scholar] [CrossRef]
- Luo, J.; Yan, X.; Tian, Y. Unsupervised quadratic surface support vector machine with application to credit risk assessment. Eur. J. Oper. Res. 2020, 280, 1008–1017. [Google Scholar] [CrossRef]
- Gao, Z.; Fang, S.; Luo, J.; Medhin, N. A kernel-free double well potential support vector machine with applications. Eur. J. Oper. Res. 2021, 290, 248–262. [Google Scholar] [CrossRef]
- Hsu, C.; Lin, C. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2022, 13, 415–425. [Google Scholar]
- Demšar, J. Statistical comparisons of classifiers over multiple datasets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Garciía, S.; Fernández, A.; Luengo, J.; Francisco, H. Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 2010, 180, 2044–2064. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Samples | Attributes | Class |
|---|---|---|---|
| Haberman | 306 | 3 | 2 |
| Appendicitis | 106 | 7 | 2 |
| Monk-2 | 432 | 6 | 2 |
| Breast | 277 | 9 | 2 |
| Seeds | 210 | 7 | 3 |
| Iris | 150 | 4 | 3 |
| Contraceptive | 1473 | 9 | 3 |
| Balance | 625 | 4 | 3 |
| Vehicle | 846 | 18 | 4 |
| X8D5K | 1000 | 8 | 5 |
| Vowel | 990 | 13 | 6 |
| Ecoli | 366 | 7 | 6 |
| Segmentationation | 2310 | 19 | 7 |
| Zoo | 101 | 16 | 7 |
| Yeast | 1484 | 8 | 10 |
| Led7digit | 500 | 7 | 11 |
| LSR | DLSR | SVM-L | SVM-R | QSSVM | LDA | KRR-R | KRR-P | LRDLSR | WCSDLSR | reg-LSDWPTSVM | HQSLSR | SQSLSR | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Haberman | Acc±Std | |||||||||||||
| Time (s) | 0.0004 | 0.0030 | 1.0636 | 1.1224 | 0.9023 | 0.0016 | 0.2093 | 0.2407 | 0.0685 | 0.0086 | 0.0369 | 0.0044 | 0.0048 | |
| Monk-2 | Acc±Std | |||||||||||||
| Time (s) | 0.0008 | 0.0030 | 1.4425 | 2.4677 | 1.8716 | 0.0716 | 0.4212 | 0.4564 | 0.0390 | 0.0184 | 0.7327 | 0.0082 | 0.0102 | |
| Appendicitis | Acc±Std | |||||||||||||
| Time (s) | 0.0010 | 0.0032 | 0.1221 | 0.1271 | 0.1310 | 0.0724 | 0.0380 | 0.0119 | 0.0405 | 0.0256 | 1.1540 | 0.0044 | 0.0044 | |
| Breast | Acc±Std | |||||||||||||
| Time (s) | 0.0009 | 0.0032 | 1.0349 | 0.8887 | 0.9383 | 0.0048 | 0.1807 | 0.1891 | 0.0389 | 0.0077 | 6.7008 | 0.0080 | 0.0086 | |
| Seeds | Acc±Std | |||||||||||||
| Time (s) | 0.0027 | 0.0070 | 0.6734 | 0.9577 | 0.7920 | 0.0067 | 0.1166 | 0.1360 | 0.0393 | 0.0096 | 1.7335 | 0.0058 | 0.0474 | |
| Iris | Acc±Std | |||||||||||||
| Time (s) | 0.0040 | 0.0028 | 0.3334 | 0.4720 | 0.2308 | 0.0042 | 0.0590 | 0.0640 | 0.0400 | 0.0053 | 0.1385 | 0.0032 | 0.0032 | |
| Contraceptive | Acc±Std | |||||||||||||
| Time (s) | 0.0033 | 0.0340 | 50.5654 | 49.5618 | 152.4766 | 0.0197 | 5.6963 | 6.4789 | 0.0836 | 1.0946 | 39.7778 | 0.0478 | 0.4666 | |
| Balance | Acc±Std | |||||||||||||
| Time (s) | 0.0022 | 0.0100 | 0.8838 | 6.8447 | 1.8852 | 0.0050 | 1.0122 | 1.0689 | 0.0703 | 0.1482 | 0.1496 | 0.0122 | 0.6072 | |
| X8D5K | Acc±Std | |||||||||||||
| Time (s) | 0.0134 | 0.0023 | 17.1786 | 19.3314 | 41.5740 | 0.0617 | 3.4147 | 3.7119 | 0.1361 | 0.4812 | 27.1015 | 0.0277 | 0.1834 | |
| Vehicle | Acc±Std | |||||||||||||
| Time (s) | 0.0025 | 0.0356 | 21.2842 | 25.7992 | 414.1790 | 0.0737 | 2.4283 | 1.9887 | 0.0976 | 0.4068 | 4872.9805 | 0.0810 | 0.1314 | |
| Zoo | Acc±Std | |||||||||||||
| Time (s) | 0.0118 | 0.0179 | 0.6321 | 0.2503 | 2.3420 | 0.0358 | 0.1827 | 0.2904 | 0.0840 | 0.0161 | 3486.3605 | 0.0072 | 0.0540 | |
| Yeast | Acc±Std | |||||||||||||
| Time (s) | 0.0058 | 1.3578 | 145.6627 | 158.0168 | 109.6964 | 0.0837 | 12.8849 | 27.3849 | 0.2602 | 2.2958 | 132.7344 | 0.0452 | 1.6300 | |
| Ecoli | Acc±Std | |||||||||||||
| Time (s) | 0.0020 | 0.0518 | 4.3479 | 5.6260 | 5.8922 | 0.0037 | 2.2895 | 1.4722 | 0.1105 | 0.1738 | 8.5413 | 0.0088 | 0.0594 | |
| Led7digit | Acc±Std | |||||||||||||
| Time (s) | 0.0031 | 0.4414 | 14.8471 | 81.7604 | 29.9238 | 0.0072 | 1.3508 | 1.4445 | 0.1476 | 0.3050 | 0.25.4077 | 0.0116 | 0.4652 | |
| Vowel | Acc±Std | |||||||||||||
| Time (s) | 0.0039 | 0.2780 | 74.6948 | 81.7602 | 485.9184 | 0.1485 | 5.7673 | 11.1241 | 0.3047 | 2.0553 | 1044.9018 | 0.0434 | 3.1902 | |
| Segmentation | Acc±Std | |||||||||||||
| Time (s) | 0.0060 | 0.4242 | 299.6623 | 294.5338 | 3053.9000 | 0.3877 | 23.1303 | 20.1449 | 0.2635 | 6.6594 | 8310.9828 | 0.2028 | 3.9048 |
| Dataset | Sensitivity | Specificity | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Appendicitis | Haberman | Contraceptive | X8D5K | Ecoli | Yeast | Appendicitis | Haberman | Contraceptive | X8D5K | Ecoli | Yeast | |
| LSR | 0.2273 | 0.2143 | 0.4740 | 1.0000 | 0.7247 | 0.3986 | 0.9375 | 0.9551 | 0.7434 | 1.0000 | 0.9709 | 0.9389 |
| DLSR | 0.4400 | 0.2250 | 0.4788 | 1.0000 | 0.7167 | 0.3814 | 0.9647 | 0.9511 | 0.7422 | 1.0000 | 0.9704 | 0.9405 |
| SVM(line) | 0.4000 | 0.1875 | 0.4016 | 0.9910 | 0.8559 | 0.4677 | 0.9412 | 0.9200 | 0.6958 | 0.9977 | 0.9667 | 0.9357 |
| SVM(rbf) | 0.5000 | 0.3058 | 0.4755 | 1.0000 | 0.8476 | 0.5533 | 0.9294 | 0.8444 | 0.7403 | 1.0000 | 0.9655 | 0.9424 |
| QSSVM | 0.5142 | 0.2070 | 0.3530 | 0.9960 | 0.7014 | 0.4062 | 0.9412 | 0.9467 | 0.7424 | 1.0000 | 0.9659 | 0.9361 |
| LDA | 0.5633 | 0.5214 | 0.4871 | 1.0000 | 0.8223 | 0.5556 | 0.6592 | 0.7236 | 0.7584 | 1.0000 | 0.9609 | 0.9398 |
| KRR-R | 0.4521 | 0.2222 | 0.5280 | 1.0000 | 0.7139 | 0.5552 | 0.9306 | 0.9387 | 0.7626 | 1.0000 | 0.9705 | 0.9467 |
| KRR-P | 0.4948 | 0.3000 | 0.5234 | 1.0000 | 0.8536 | 0.5367 | 0.9640 | 0.9376 | 0.7635 | 1.0000 | 0.9717 | 0.9339 |
| LRDLSR | 0.400 | 0.2250 | 0.6128 | 1.0000 | 0.5317 | 0.3036 | 0.9333 | 0.9504 | 0.7439 | 1.0000 | 0.9662 | 0.9354 |
| WCSDLSR | 0.3333 | 0.3684 | 0.4653 | 1.0000 | 0.7854 | 0.3269 | 0.9444 | 0.9446 | 0.7370 | 1.0000 | 0.9630 | 0.9380 |
| reg-DWPDSVM | 0.4867 | 0.4111 | 0.4730 | 1.0000 | 0.8540 | 0.5248 | 0.9422 | 0.9149 | 0.7300 | 1.0000 | 0.9716 | 0.94511 |
| HQSLSR | 0.5700 | 0.3875 | 0.5249 | 1.0000 | 8581 | 0.5575 | 0.9647 | 0.9467 | 0.7671 | 1.0000 | 0.9765 | 0.9465 |
| SQSLSR | 0.6824 | 0.3176 | 0.5226 | 1.0000 | 0.8647 | 0.5629 | 0.9667 | 0.9511 | 0.7795 | 1.0000 | 0.9797 | 0.9460 |
| Datasets | LSR | DLSR | SVM-L | SVM-R | QSVM | LDA | KRR-R | KRR-P | LRDLSR | WCSDLSR | reg-LSDWPTSVM | HQSLSR | SQSLSR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Haberman | 12 | 5 | 11 | 6 | 7.5 | 13 | 9 | 4 | 10 | 3 | 7.5 | 2 | 1 |
| Monk-2 | 12 | 11 | 8 | 1 | 3 | 10 | 7 | 6 | 9 | 13 | 2 | 5 | 4 |
| Appendicitis | 9 | 7 | 10 | 3 | 6 | 13 | 12 | 5 | 8 | 11 | 4 | 2 | 1 |
| Breast | 9 | 7 | 6 | 4 | 13 | 11 | 3 | 8 | 5 | 10 | 12 | 2 | 1 |
| Seeds | 10 | 6 | 13 | 11 | 12 | 5 | 8 | 3.5 | 3.5 | 9 | 7 | 2 | 1 |
| Iris | 10.5 | 9 | 13 | 2.5 | 8 | 7 | 6 | 4 | 10.5 | 12 | 5 | 1 | 2.5 |
| Contraceptive | 8 | 7 | 13 | 1 | 12 | 6 | 4 | 5 | 10 | 9 | 11 | 2 | 3 |
| Balance | 11 | 10 | 12 | 7 | 1 | 3 | 4 | 5 | 9 | 8 | 6 | 3 | 2 |
| X8D5K | 6 | 6 | 13 | 6 | 12 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 |
| Vehicle | 9 | 6 | 13 | 12 | 4.5 | 4.5 | 7 | 2 | 8 | 11 | 10 | 3 | 1 |
| Zoo | 7 | 6 | 11 | 9.5 | 12 | 13 | 8 | 4 | 5 | 9.5 | 3 | 2 | 1 |
| Yeast | 8 | 6 | 12 | 4 | 7 | 13 | 5 | 3 | 11 | 9 | 10 | 2 | 1 |
| Ecoli | 13 | 10 | 11 | 3 | 8 | 6 | 12 | 1 | 9 | 7 | 5 | 2 | 4 |
| Led7digit | 7 | 4 | 13 | 11 | 12 | 1 | 5 | 6 | 8 | 9 | 10 | 3 | 2 |
| Vowel | 11 | 10 | 12 | 2 | 6 | 8 | 1 | 7 | 9 | 13 | 3 | 5 | 4 |
| Segmentation | 12.5 | 12.5 | 6 | 2 | 5 | 8 | 4 | 9 | 10 | 11 | 7 | 3 | 1 |
| Average ranks | 9.6875 | 7.65625 | 11.0625 | 5.3125 | 8.0625 | 8.59375 | 6.3125 | 4.9062 | 8.1875 | 9.40625 | 6.78125 | 2.8125 | 2.21875 |
| Datasets | LSR | DLSR | SVM-L | SVM-R | QSVM | LDA | KRR-R | KRR-P | LRDLSR | WCSDLSR | reg-LSDWPTSVM | HQSLSR | SQSLSR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Haberman | 1 | 3 | 12 | 13 | 11 | 2 | 9 | 10 | 8 | 6 | 7 | 4 | 5 |
| Monk-2 | 1 | 2 | 11 | 13 | 12 | 7 | 8 | 9 | 6 | 5 | 10 | 3 | 4 |
| Appendicitis | 1 | 2 | 10 | 11 | 12 | 9 | 7 | 5 | 8 | 6 | 13 | 3.5 | 3.5 |
| Breast | 1 | 2 | 12 | 10 | 11 | 3 | 8 | 9 | 7 | 4 | 13 | 5 | 6 |
| Seeds | 1 | 4 | 10 | 12 | 11 | 3 | 8 | 9 | 6 | 5 | 13 | 2 | 7 |
| Iris | 4 | 1 | 12 | 13 | 11 | 5 | 8 | 9 | 7 | 6 | 10 | 2.5 | 2.5 |
| Contraceptive | 1 | 3 | 12 | 11 | 13 | 2 | 8 | 9 | 5 | 7 | 10 | 4 | 6 |
| Balance | 1 | 3 | 9 | 13 | 12 | 2 | 10 | 11 | 5 | 6 | 7 | 4 | 8 |
| X8D5K | 2 | 1 | 10 | 11 | 13 | 4 | 8 | 9 | 5 | 7 | 12 | 3 | 6 |
| Vehicle | 1 | 2 | 10 | 11 | 12 | 3 | 9 | 8 | 5 | 7 | 13 | 4 | 6 |
| Zoo | 2 | 4 | 11 | 9 | 12 | 5 | 8 | 10 | 7 | 3 | 13 | 1 | 6 |
| Yeast | 1 | 5 | 12 | 13 | 10 | 3 | 8 | 9 | 4 | 7 | 11 | 2 | 6 |
| Ecoli | 1 | 4 | 10 | 11 | 12 | 2 | 9 | 8 | 6 | 7 | 13 | 3 | 5 |
| Led7digit | 1 | 6 | 10 | 13 | 12 | 2 | 8 | 9 | 4 | 5 | 11 | 3 | 7 |
| Vowel | 1 | 4 | 10 | 11 | 12 | 3 | 8 | 9 | 5 | 6 | 13 | 2 | 7 |
| Segmentation | 1 | 5 | 11 | 10 | 12 | 4 | 9 | 8 | 3 | 7 | 13 | 2 | 6 |
| Average ranks | 1.3125 | 3.1875 | 10.7500 | 11.5625 | 11.7500 | 3.6875 | 8.3125 | 8.8125 | 5.6875 | 5.8750 | 11.3750 | 3 | 5.6875 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Yang, Z.; Ye, J.; Yang, X. Kernel-Free Quadratic Surface Regression for Multi-Class Classification. Entropy 2023, 25, 1103. https://doi.org/10.3390/e25071103
Wang C, Yang Z, Ye J, Yang X. Kernel-Free Quadratic Surface Regression for Multi-Class Classification. Entropy. 2023; 25(7):1103. https://doi.org/10.3390/e25071103
Chicago/Turabian StyleWang, Changlin, Zhixia Yang, Junyou Ye, and Xue Yang. 2023. "Kernel-Free Quadratic Surface Regression for Multi-Class Classification" Entropy 25, no. 7: 1103. https://doi.org/10.3390/e25071103
APA StyleWang, C., Yang, Z., Ye, J., & Yang, X. (2023). Kernel-Free Quadratic Surface Regression for Multi-Class Classification. Entropy, 25(7), 1103. https://doi.org/10.3390/e25071103