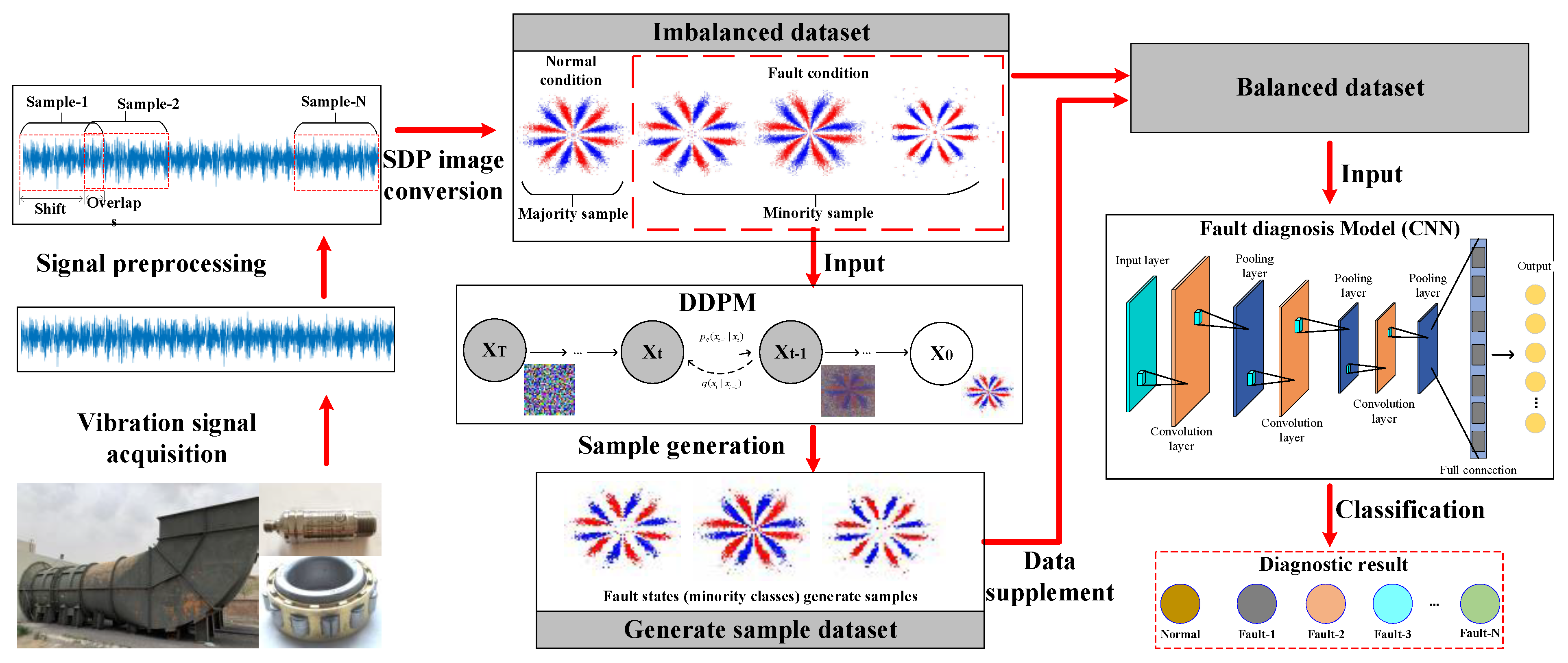
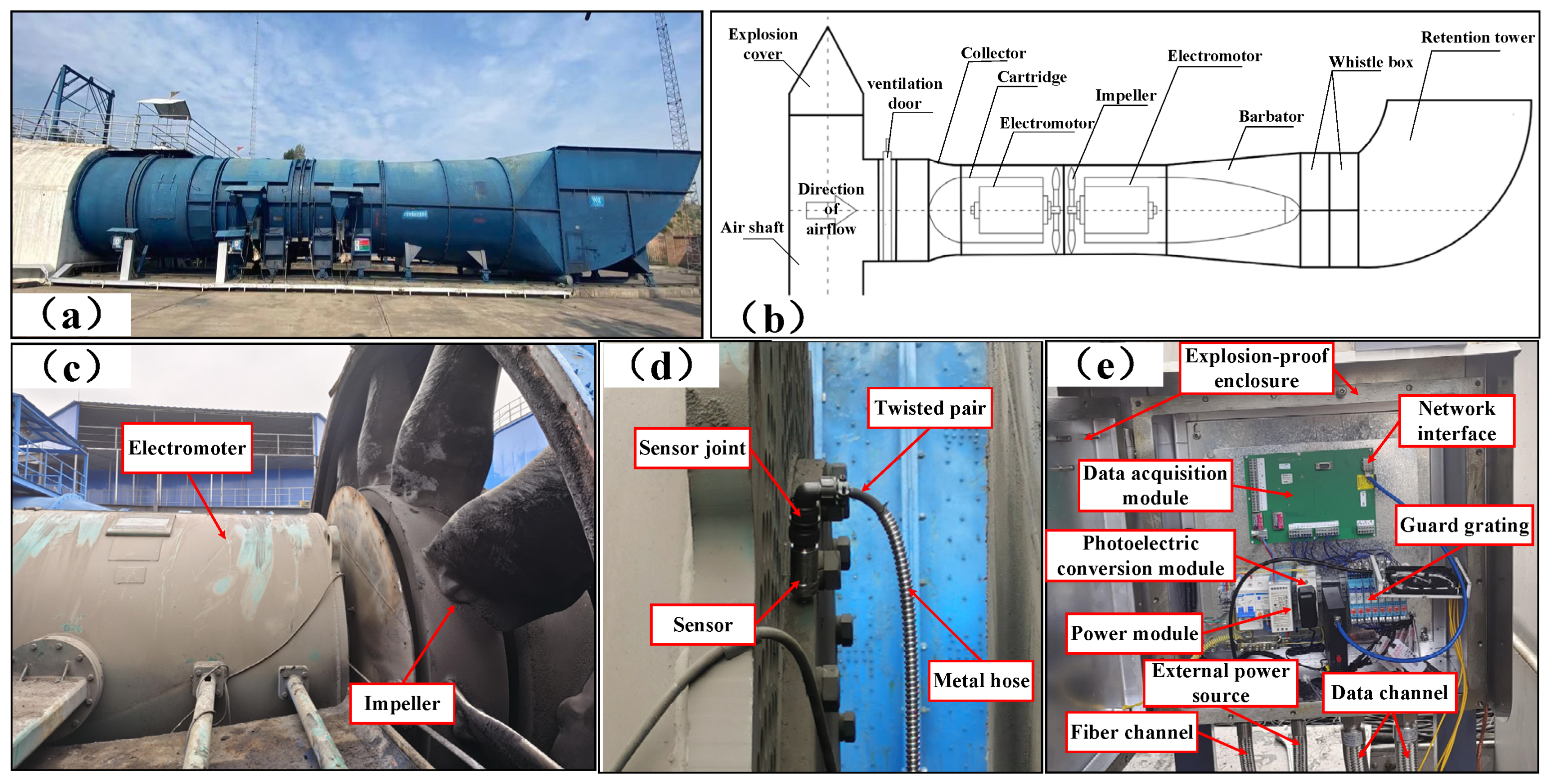
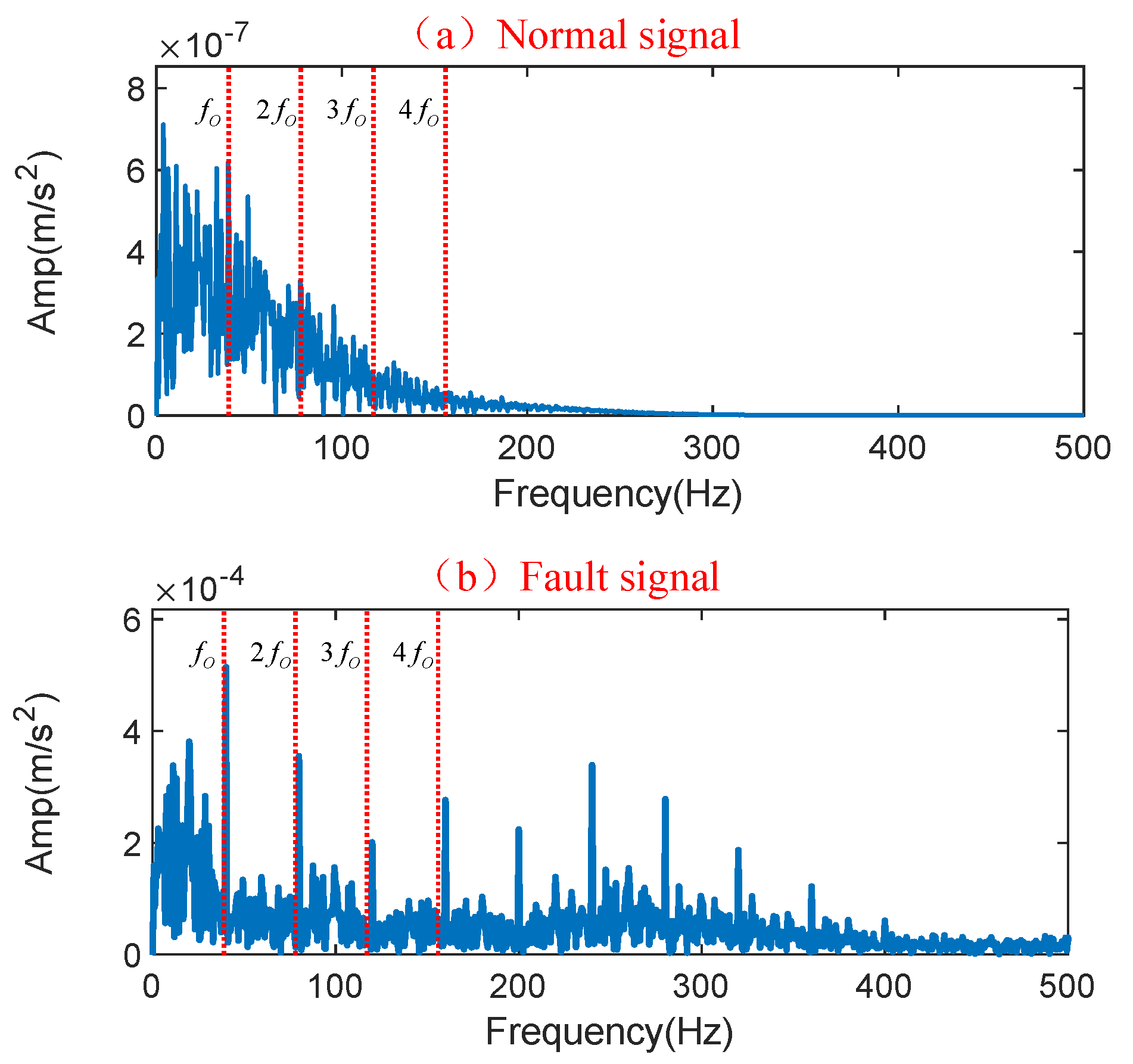
The motor’s rotation speed was 1500 r/min, and the load was 0 HP. The wire-cutting technique was utilized to set up a single point of failure on the inner ring, outer ring, and rolling element of the tested bearing. The test bench included an INV9824 accelerometer and an INV3062C collector to acquire bearing vibration signals, and the bearing vibration data’s sampling frequency was 10.24 KHz. First, the normal bearing’s vibration acceleration signal was acquired, and then three kinds of fault rolling bearings (inner ring, outer ring, and rolling-element faults) were mounted to the test bench for fault signal collection.
4.1.1. Evaluation and Analysis of Generated Images
After preprocessing the collected vibration data, the overlapping sampling technique was utilized to divide the four operating states’ vibration signals into samples, each containing 2048 sampling points. To perform sample segmentation, the first step was to set the size of the sampling window to 2048. The size of the sampling window determined the length of each sample intercept from the vibration signal. Then, the sampling step size was set to 300, which determined how far the sampling window moved through the vibration signal, allowing it to intercept the next sample. A series of overlapping sets of vibration samples were obtained using the overlapping sampling method. Finally, the vibration samples with the same window length were converted to SDP images and resized to 64 × 64 using the conversion Equations (1)–(3) in
Section 2.
As the quality of SDP images directly depends on the parameters
,
, and
, in this study, we first conducted experimental research on the parameter selection of SDP. Numerous studies have indicated that SDP images’ symmetry and shape features are more prominent when
is chosen at 60°. A reasonable selection of parameters
g and
L can promote the image quality and strengthen the distinctions between signals, allowing more apparent differentiation among various vibration signals [
43,
44]. Therefore, using the image correlation coefficient approach, the current paper verifies the correlation between images of different fault categories. For two
images, the correlation coefficient R can be described as follows:
where
A and
B describe the images’ two-dimensional gray matrices. The smaller the correlation coefficient
R of different images, the greater the difference between images. In order to better choose the optimum values of
and
to detect the SDP images of various fault states, the sum of the correlation coefficients between the SDP images of the four states is utilized as the image assessment metric in this paper, which is described as follows:
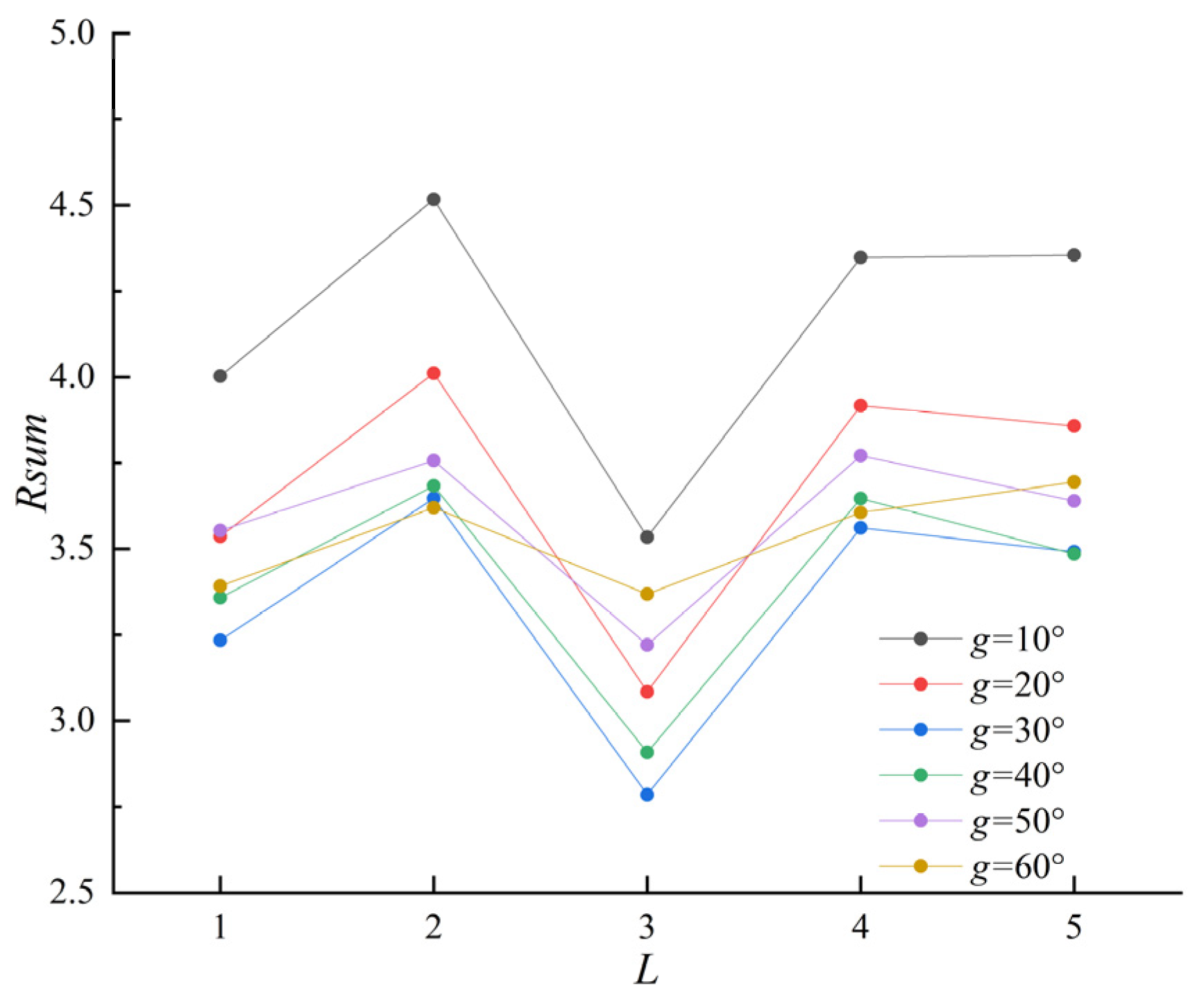
The values of
are set from 1 to 5, and the values of
are set from 10° to 60° in steps of 1 and 10°, respectively.
Figure 7 shows the sum of the correlation coefficients of the four operating SDP images. The minimum value of the sum of correlation coefficients Rsum is obtained for
= 3 and
= 30°. At this point, the correlation between the SDP images of various states is the smallest, and the recognizability is the highest.
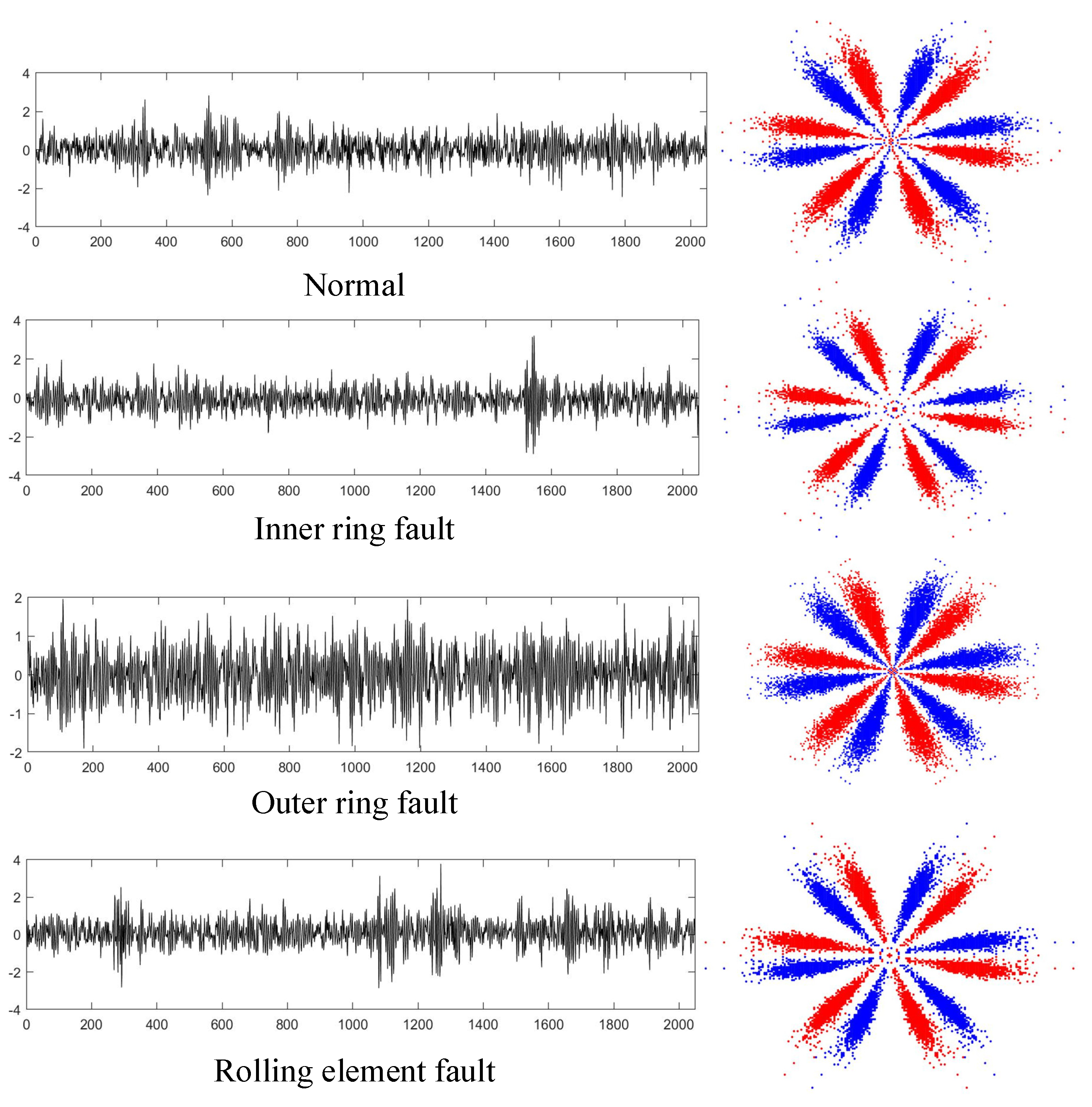
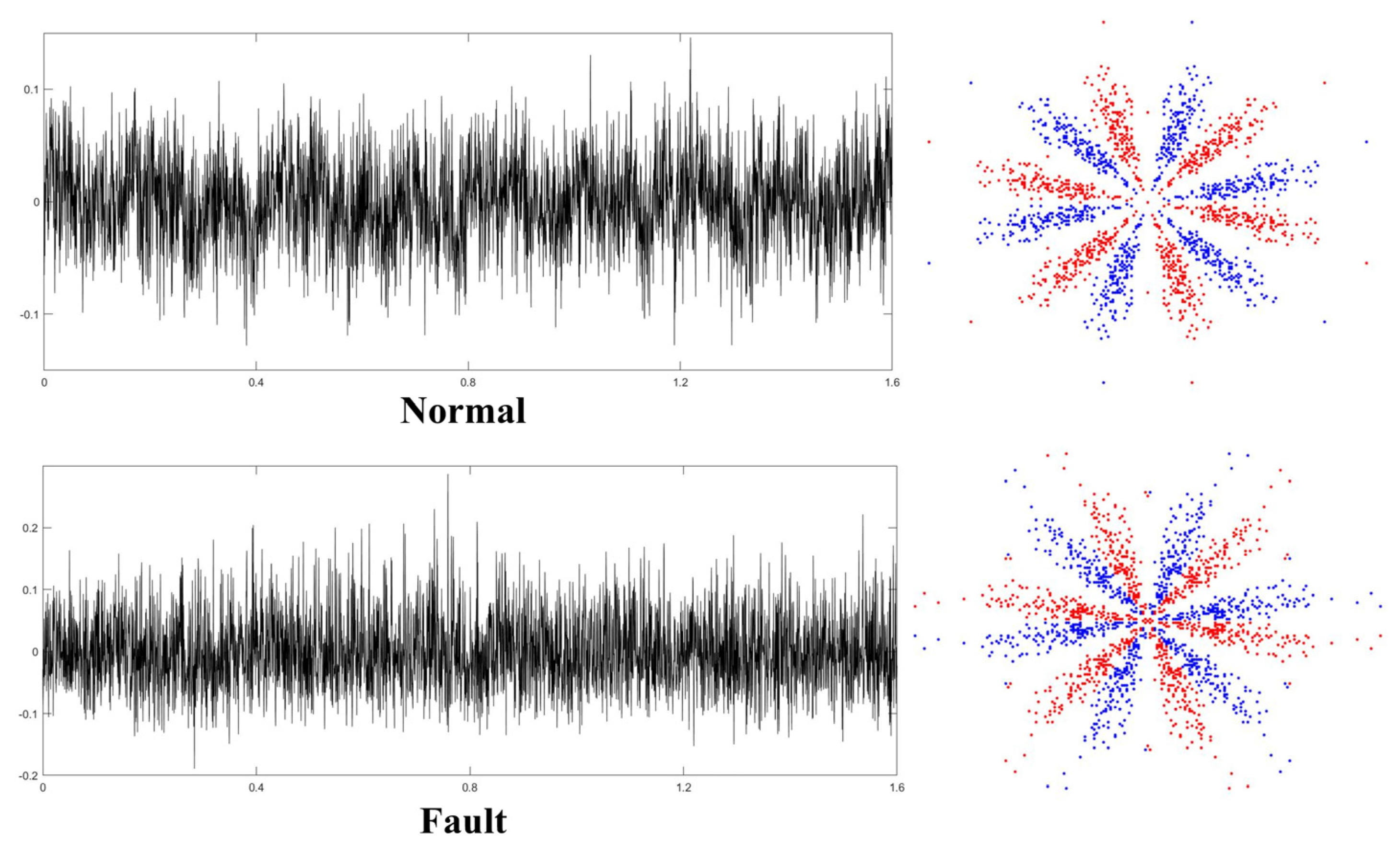
After selecting the optimal parameters, the SDP approach was utilized to transform all vibration signals into two-dimensional SDP images. The time-domain graphs of the four operating state samples of the rolling bearing and the converted SDP images are shown in
Figure 8.
In order to conduct research on rolling bearing fault diagnosis under sample imbalance conditions, a sample set for training and testing the diagnostic model based on SDP images was constructed. Therefore, 1500 samples were randomly chosen from the normal samples as training samples, and 200 samples were randomly chosen as the test samples. The other three types of faulty samples were randomly chosen from 1000 samples as training samples and 200 samples as test samples. As shown in
Table 1, an unbalanced dataset was eventually constructed artificially for the experiment.
The normal-state images in the dataset were chosen as majority class samples, and the other three fault-state images were chosen as minority class samples. After obtaining the SDP images of different operating states of rolling bearings, three minority sample images of each class were utilized as the input for training the DDPM and supplementing the imbalance sample set using the DDPM-generated images.
In order to validate the efficiency of the DDPM approach, the quality of the produced samples should be evaluated, and their impact on FD under sample imbalance conditions should be studied. The DDPM was modeled using the U-Net, a U-shaped network framework comprising an encoder, a decoder, and cross-layer connections (residual links) between the encoder and decoder. The U-Net model first achieves downsampling operations on the input through the encoder and then accomplishes upsampling operations using the decoder, with cross-layer connections employed to splice features between the encoder and decoder. The specific model parameter settings can be found in [
31]. In DDPM, a
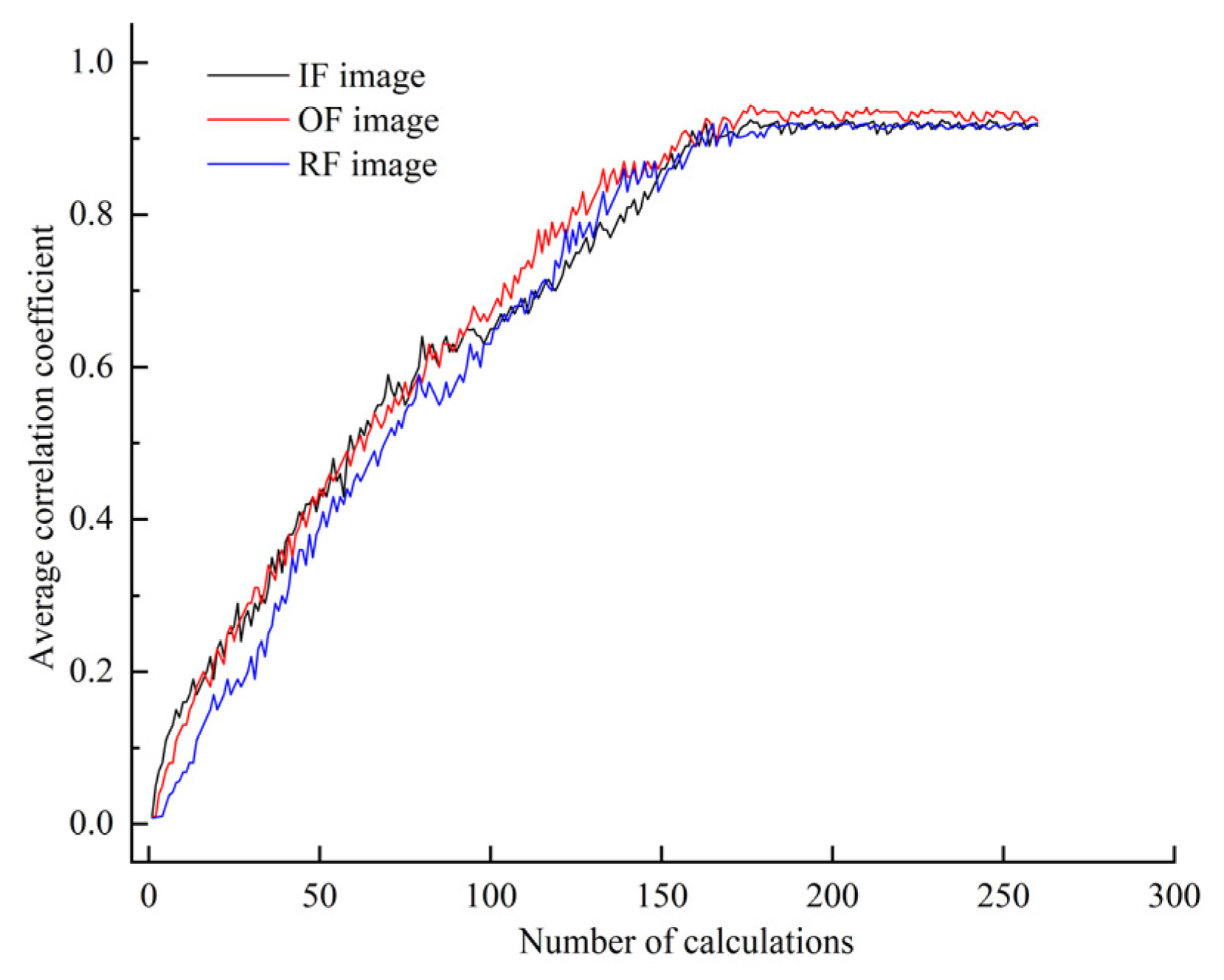
= 1000 and batch_size = 16 were chosen, and the Adam optimizer was utilized for optimizing the neural network. In the training process of DDPM, the image samples were first input into the DDPM, and a noise path was formed by propagating the noise gradually to each reversible layer through forward propagation. The conditional probability between the input image and its denoised output was then computed at the ascent step of each reversible layer, and the denoising effectiveness of the model for a given input image was measured through the conditional probability. Next, the conditional probability loss function of the DDPM was calculated, and the gradient of the loss function with respect to the model parameters was computed via the backpropagation algorithm. Then, an optimization algorithm was used to update the parameters of the DDPM according to the calculated gradient so that the loss function was gradually reduced. Finally, the process of forward propagation, calculating conditional probabilities, backpropagation, and parameter updating was repeated until a preset number of training rounds was reached or certain convergence conditions were achieved. However, the training rounds of DDPM are generally set according to manual experience and without a theoretical basis. Too many training rounds result in wasted computational resources and experiment time, while too few training rounds result in poor-quality generated images. Moreover, all of the generated images cannot be expanded and enhanced for the imbalanced dataset in the training results of DDPM. Therefore, the correlation coefficient between each generated image and the real image in the current batch was calculated every 25 rounds of training during the DDPM training process. The average of all correlation coefficients was then calculated, and the result was employed as an evaluation metric to determine whether the DDPM-generated image qualities are up to standard and can be added to the imbalanced dataset for data enhancement.
Figure 9 shows the results.
As presented in
Figure 9, the change in the average correlation coefficient of the images with different faults begins to level off after 180 calculations when the training round of DDPM is 4500. Therefore, the DDPM training rounds were set to 5000 (epochs = 5000), as it is considered that the generated images of the DDPM after 5000 training rounds can be effectively utilized to expand the imbalanced dataset. The training weights were saved after the training, and DDPM employed the weights for image generation in subsequent experiments.
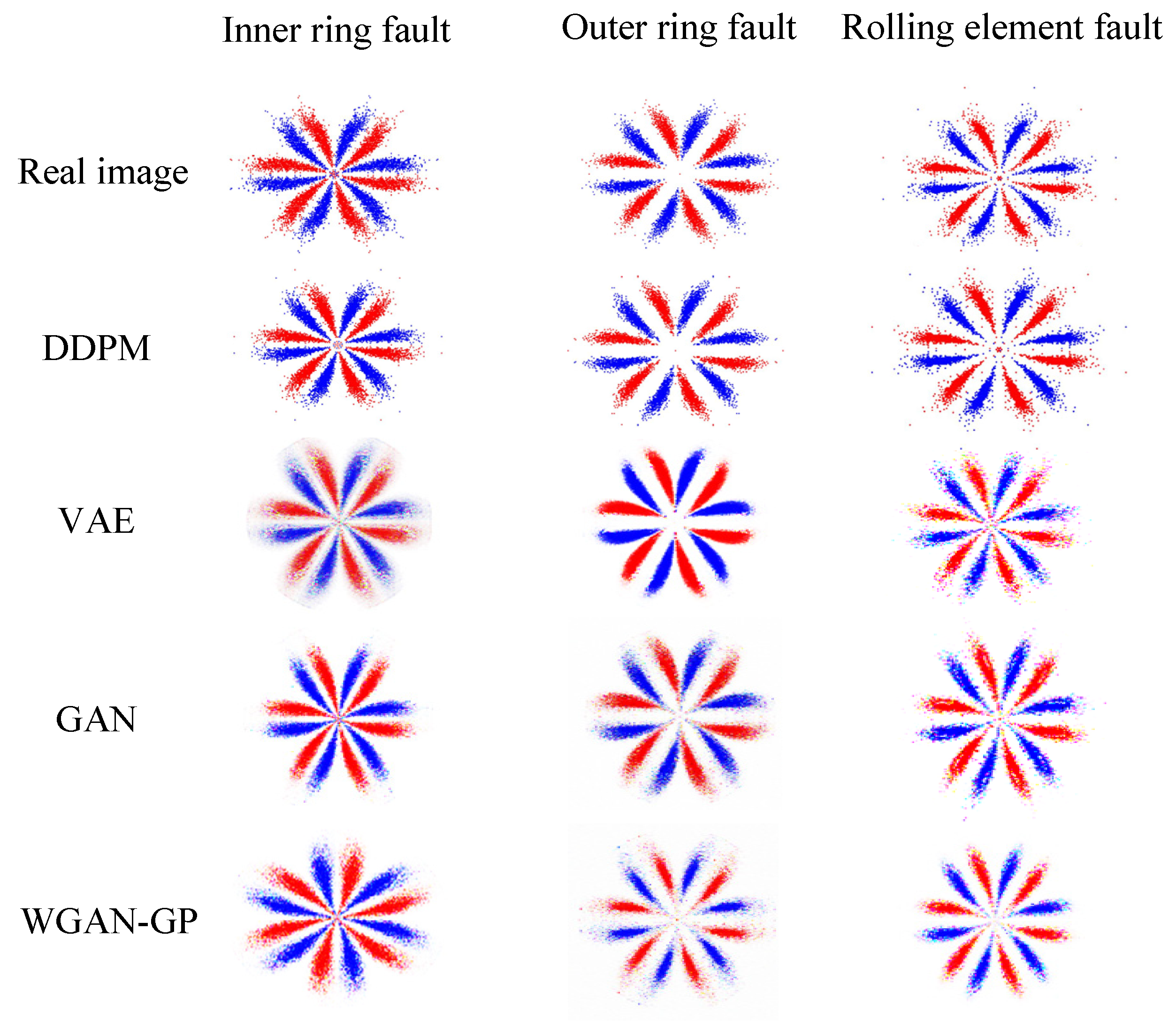
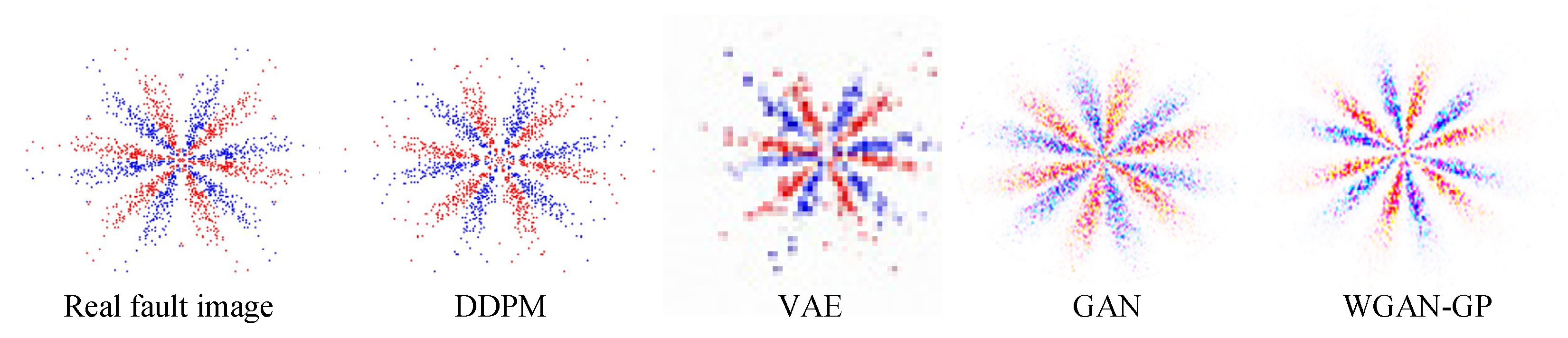
Three minority class images were separately adopted as the input, and the trained DDPM was employed for image sample generation. These were compared with the samples generated via other common generation methods, such as VAE, GAN, and WGAN-GP, as presented in
Figure 10. In this case, a fully connected network was employed to construct the encoder and decoder of VAE. The encoder and decoder structures were 4096-1024-512-64 and 20-64-512-1024-4096, respectively. The Adam optimizer was utilized for training, with a learning rate of 0.001. The discriminators and generators of GAN and WGAN-GP both employed convolutional neural networks to construct the network, and the Adam optimizer was utilized for optimizing the neural network, with a learning rate of 0.0002. A BN layer was added to the generator to normalize the data and prevent the model from overfitting, and ReLU was adopted as the activation function after the BN layer. Tanh and LeakyReLU were used as the activation functions in the output layer and the discriminator, respectively.
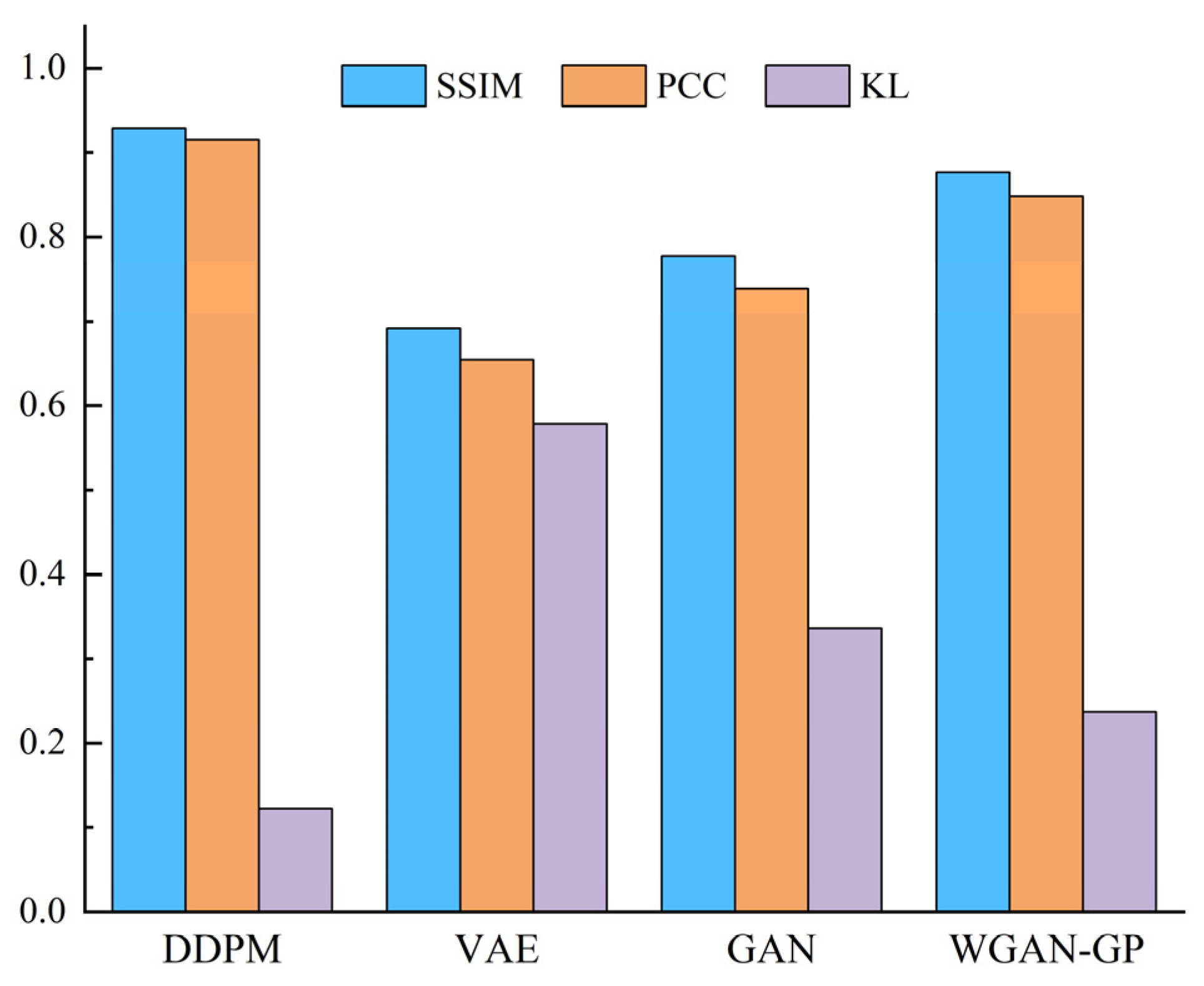
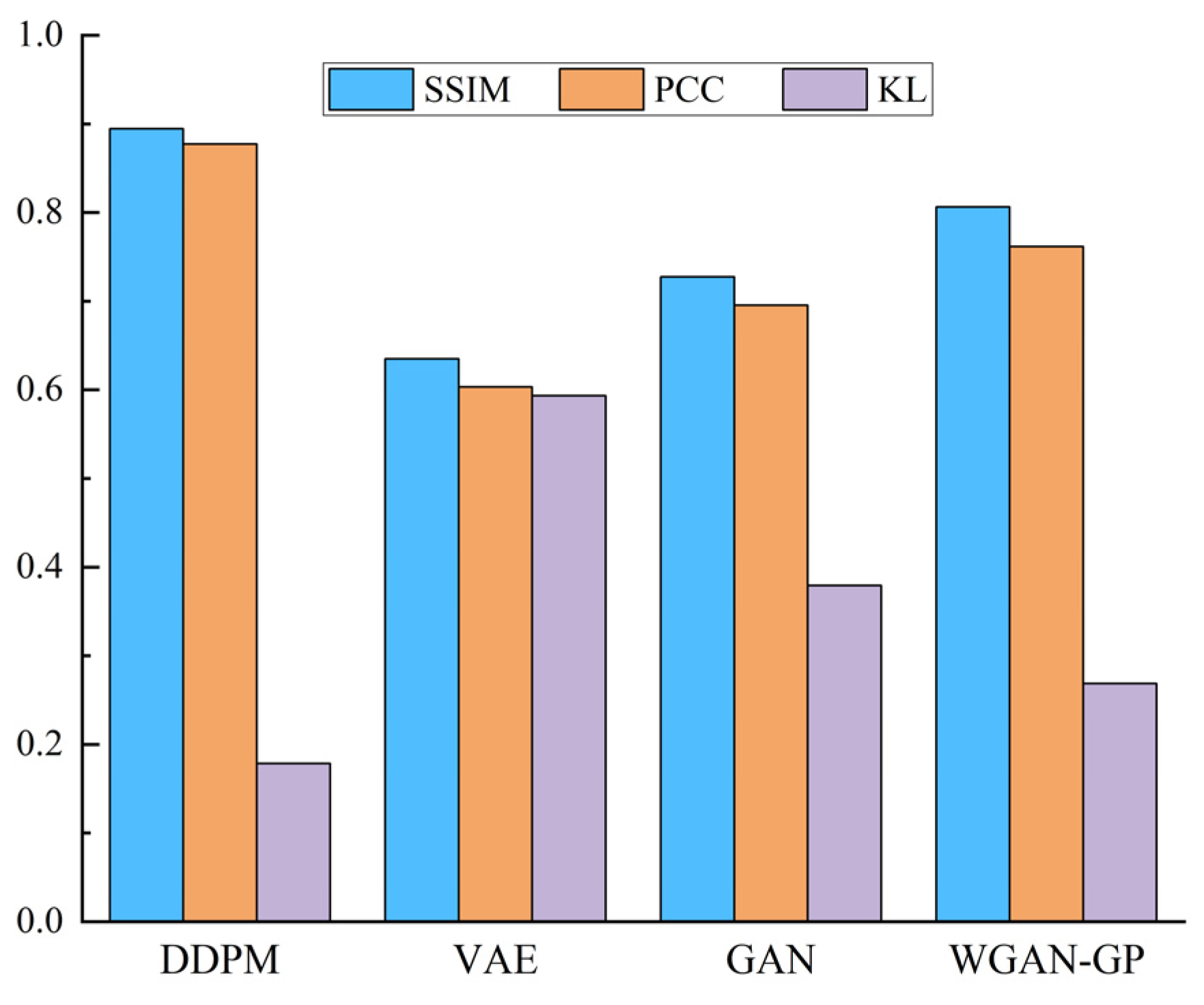
Figure 10 shows that the DDPM-generated images are intuitively more similar to the actual image, specifically in that the shape features and geometric center of the SDP image are more similar to the actual image. This demonstrates the superiority of the DDPM-generated images’ quality and image similarity to other generation approaches. In order to quantitatively assess the quality of the produced images, ten produced images were selected from the generated images of each method. Then, the structural similarity (SSIM), Pearson’s correlation coefficient (PCC), and KL divergence (KL) between all the produced images and the relative real images were calculated, and the mean value of the above indexes was chosen as the assessment basis for the quality of the produced images, as presented in
Figure 11. The SSIM determines the similarity of two images whose value changes from 0 to 1. The larger the SSIM value, the more similar the image is. PCC is an indicator that reflects the correlation between different distributions and takes a value between 0 and 1. The larger the PCC value, the more similar the distribution. KL measures the difference between distributions and takes a value from 0 to
; the smaller the KL value, the more similar the distribution.
Figure 11 shows that the presented DDPM approach generates images superior to other generation approaches in all evaluation metrics. It shows that the images produced using the DDPM approach have high quality, a similar appearance between the produced and real images, and similar feature distribution. Therefore, using DDPM to generate a few class fault images to complement the imbalance dataset is a feasible and effective approach.
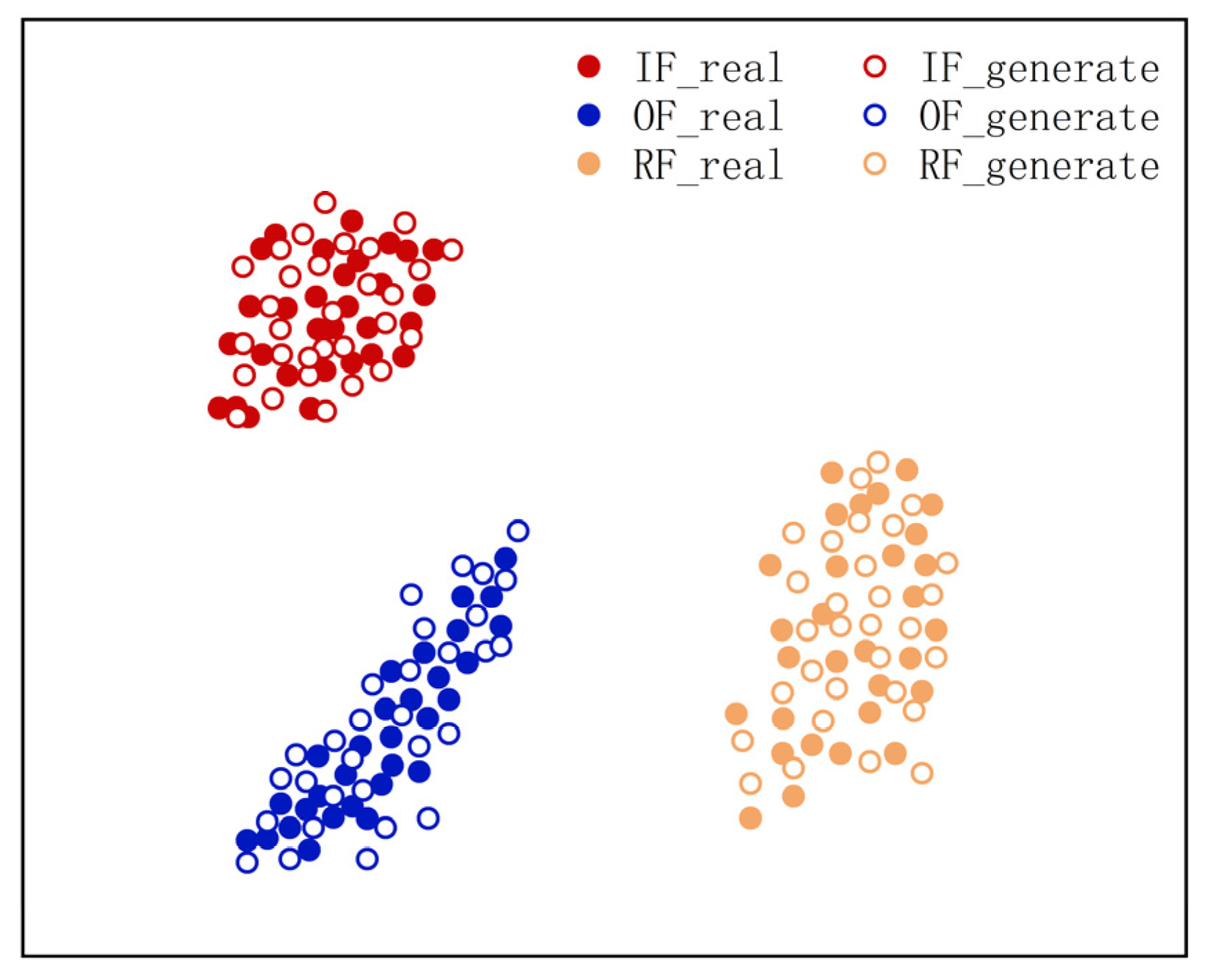
In order to further describe the advantages of the DDPM approach for generating images, the t-SNE method [
45] was used to visualize the partial DDPM-generated and real images of three fault types in a reduced dimension, and the visualization results of the sample distribution verified the similarity between the produced and actual images.
Figure 12 shows the results.
As presented in
Figure 12, the produced and actual images can be aggregated into one class, and their feature distributions are in the same area and do not overlap. This indicates that the DDPM-generated image samples have high similarity to the real image samples without identical feature distributions. It also illustrates that DDPM can effectively fit the feature distribution of real images and that the produced images have sample diversity and high similarity.
In summary, DDPM can generate high-quality image samples. Compared with other generation approaches, the DDPM-produced samples have a higher similarity to the real samples and are better at enhancing and complementing the unbalanced sample set.
4.1.2. Bearing Fault Diagnosis Research under Multiple Sample Imbalance Conditions
The efficiency of deep neural network-based FD approaches depends on the number of training samples. Under the sample imbalance condition, the sample generation method can effectively solve the diagnostic model’s insufficient precision due to the lack of a few classes of training samples. However, the produced samples are derived from the real ones and can only complement, but not completely replace, the real samples for a few classes of real samples.
In this study, we conducted different experiments on the imbalance rate of a few classes of samples to assess the influence of the complementary number of produced samples on the fault diagnosis accuracy. According to the multiple imbalance rate settings, in the experiments, a few classes (fault states) of samples were first generated using the DDPM method, and then data augmentation was performed on the imbalance sample set, i.e., the produced samples were used to supplement the real samples and finally obtain a mixed sample set, as described in
Table 2.
In all the mixed sample sets, data augmentation was performed only in the training set, and the test set comprised only the original real samples to ensure consistent results. Moreover, the number of majority class (normal state) samples employed for training was not fixed and was the same as the number of expanded minority class ones.
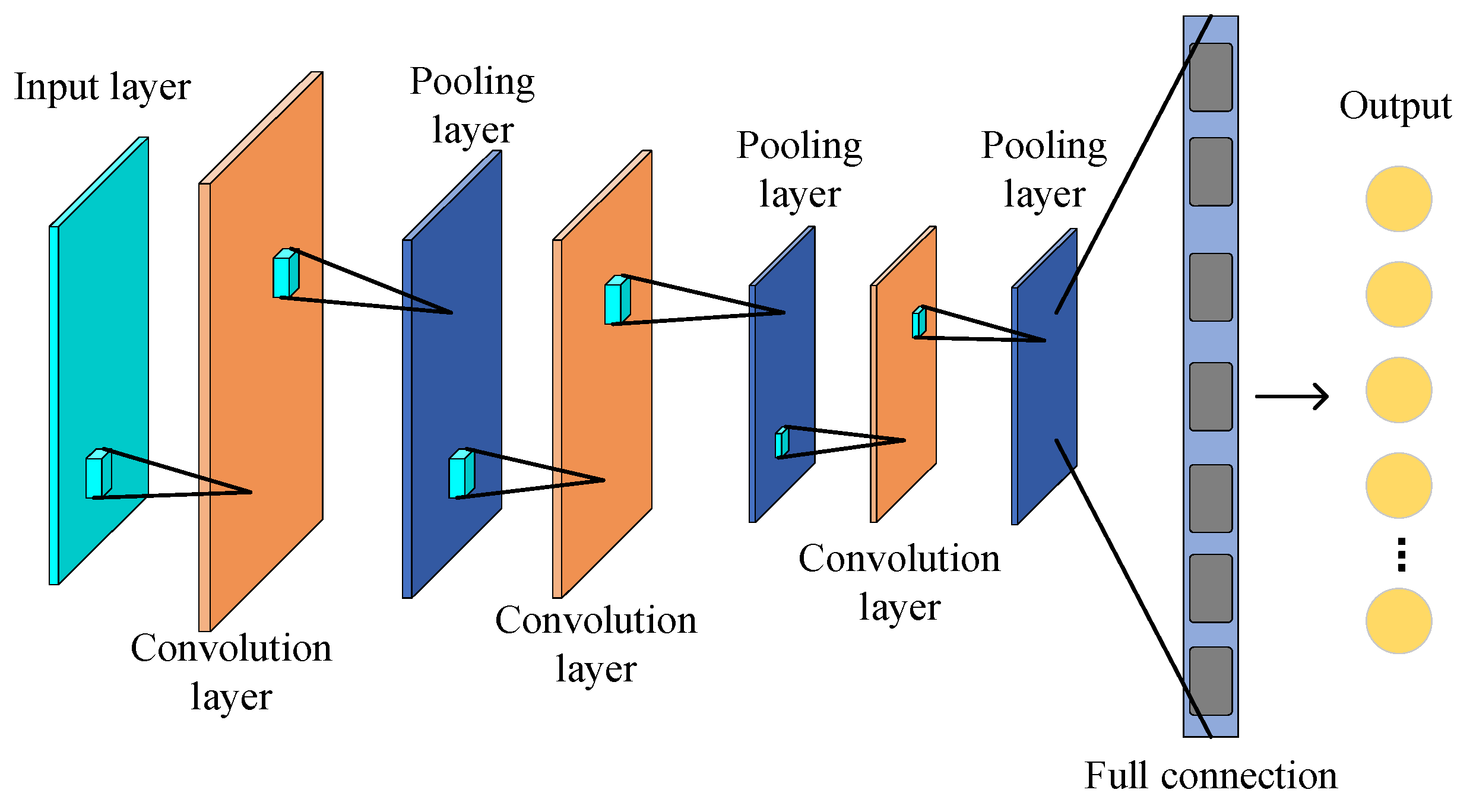
The presented CNN-based fault diagnosis model was trained using the above dataset, and the trained model was evaluated through the test set. The CNN diagnosis model comprised five alternately connected convolutional and pooling layers, two fully connected layers, and a SoftMax classifier. The size of the convolutional kernel was 3 × 3, the number of convolutional kernels was 16, 32, 32, 64, and 128; for the pooling layer, 2 × 2 maximum pooling was used; the activation function was ReLU; and the number of nodes in the fully connected layer was 1024 and 256. In order to avoid the network from overfitting, a BN layer was added after the first convolutional layer, and a dropout operation was added after the fully connected layer, where the value was set to 0.25. The model was trained with a batch_size = 64 and an epoch = 500, and the learning rate was chosen as 0.001. The model utilized a zero-padding method to increase the dimensionality so that the feature map size remained the same before and after convolution. In the training process of CNN, the weights and biases of the model first had to be initialized using small random numbers. Then, the data were passed from the input layer all the way to the output layer through a forward propagation process. During forward propagation, CNN extracted image features through a series of convolution operations, activation functions, and pooling operations. After that, the output of the forward propagation was compared with the real label, and the value of the loss function was calculated. Next, CNN calculated the gradient of the loss function with respect to the model parameters via backpropagation, and the Adam optimization algorithm was used to update the model parameters so that the value of the loss function gradually would approach the optimal solution. Finally, the process of forward propagation, computation of losses, backpropagation, and parameter updating was repeated until a preset number of training rounds was reached, or certain convergence conditions were achieved.
In order to diminish the effect of chance errors, all datasets were tested 10 times, and their diagnostic efficiency was evaluated through the mean precision of the 10 test results.
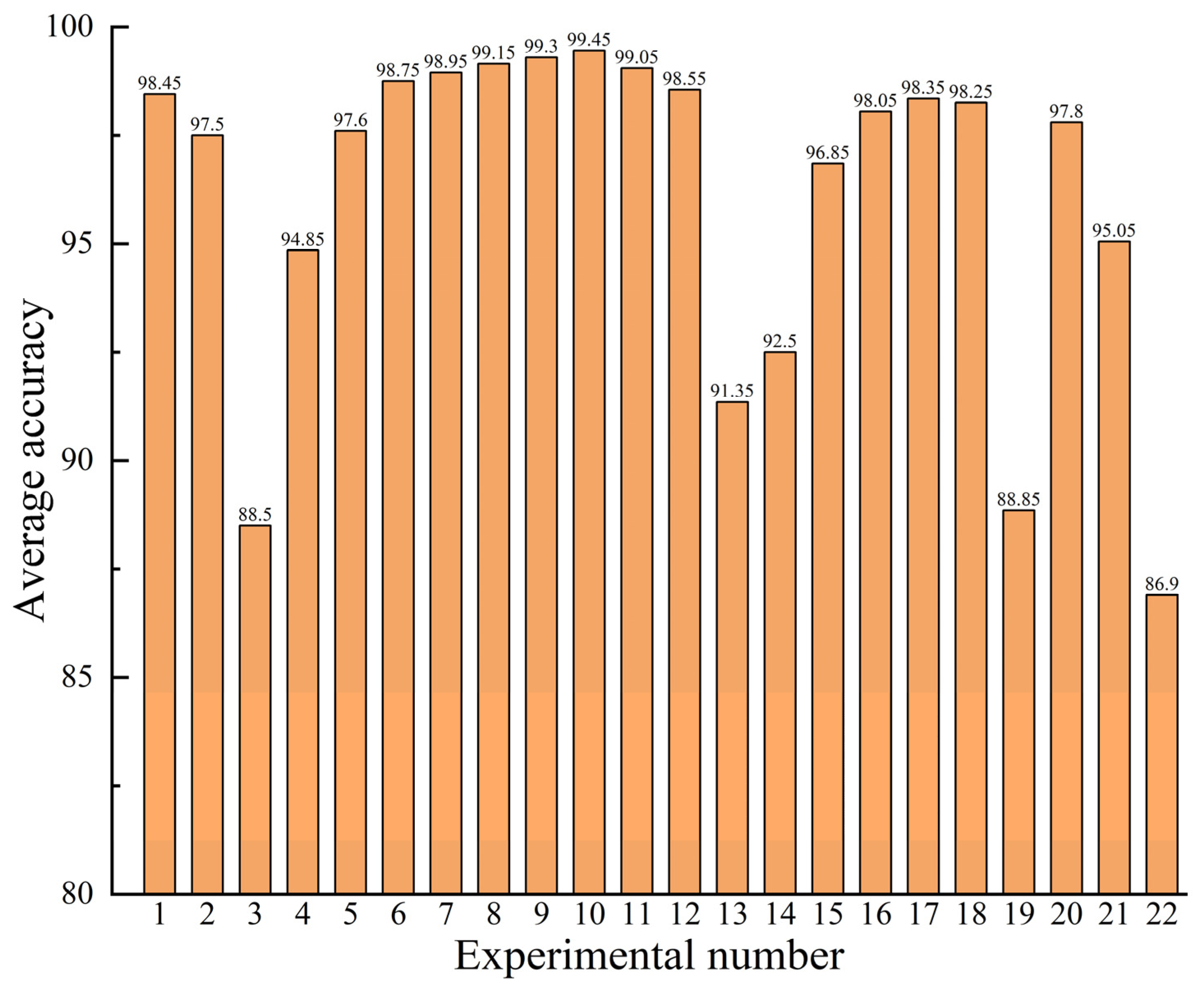
Table 2 and
Figure 13 present the average accuracy of the FD model on all datasets.
Considering the above experiments, Experiments 1–3 only involved the original real samples, Experiments 4–19 were conducted using the generated samples for data augmentation, and Experiments 20–22 were conducted using only the generated samples for training the diagnostic model.
The analysis of the results of Experiments 1–3 and Experiments 20–22 indicates that the efficiency of the FD model trained on the produced samples only is lower than that using the real samples only. The reason for this is that the generated sample is extracted from the actual sample, which only supplements the real sample and cannot completely replace it. Moreover, it can be concluded from Experiments 3, 19, and 22 that the diagnostic accuracy is low for less than 500 training samples, indicating that the number of training samples considerably affects the diagnosis model’s precision.
The comparison of the results of Experiment 1 with Experiments 6–12 and Experiment 2 with Experiments 16–18 indicate that the diagnostic accuracy can be effectively improved by adding additional produced samples to the training sample set for sample enhancement in FD model training. When the ratio of the number of generated samples to the number of real samples is between 0.25 and 1, there is a considerable improvement in the diagnosis model’s accuracy. The best improvement in diagnostic precision can be attained when the number of generated samples is half the number of real ones. Data enhancement using generated samples for unbalanced datasets is an effective method when performing FD under sample imbalance situations, and the efficiency and feasibility of the presented approach are also illustrated.
However, the number of added generated samples is not as high as possible during sample augmentation. The results of the comparisons of Experiment 1 with Experiments 4–7 and Experiment 2 with Experiments 13–15 show that adding more generated samples than real samples cannot significantly affect the diagnostic model and enhance diagnostic efficiency. The accuracy of the diagnostic model is reduced when adding too many generated samples. This is because the generated samples contain other information about the real samples’ characteristics and generation errors. Excessive interference can degrade the diagnosis model’s efficiency, further illustrating that the generated samples cannot completely replace the real ones.
4.1.3. Application of Sample Generation Method in Rolling Bearing Fault Diagnosis
In order to further assess the feasibility of adding produced samples to the imbalanced sample set for data augmentation in FD and the efficiency of the presented approach, the proposed method was validated via experiments.
In these experiments, different sample generation methods were first used to supplement the data of the unbalanced sample set shown in
Table 1 and reach the sample equilibrium state. The optimal number of supplements was employed, i.e., 500 additional generated images were added to the image sample for each class of fault states to make the number of images in the minority class (fault state) equal to that in the majority class (normal state). Experimental validation was then performed using a mixed sample set, as presented in
Table 3.
The above dataset was employed to train the CNN diagnosis model, while its architecture and parameter settings were kept unchanged. Meanwhile, to evaluate the efficiency of the presented approach, other diagnosis models, like the support vector machine (SVM), random forest (RF), and BP neural network, were trained based on the same dataset for comparison. The CNN diagnosis model used in this paper adopted the SDP image directly as the input, while the SDP image’s texture feature parameters were chosen as the inputs of other diagnosis models. The accuracy of different datasets in different fault diagnosis models was then evaluated using the test set. In order to alleviate the impact of chance errors, each method was tested 10 times, and their diagnostic efficiencies were evaluated through the mean precision of the 10 test results, as presented in
Table 4.
The experimental results indicate that the classification precision of all fault diagnosis approaches on the mixed dataset with the addition of the produced samples is superior to the unbalanced dataset. The reason for this is that the hybrid dataset has more image samples that can be employed for training. This reveals that when performing FD under the sample imbalance condition, using the sample generation method to generate additional minority class samples for supplementing the imbalanced dataset can effectively increase the classification precision of the FD model and solve the low diagnosis precision problem caused by the lack of training samples.
Meanwhile, the test results of all the fault diagnosis models on the mixed sample set indicate that generating a few classes of samples for data supplementation using the DDPM method can improve the diagnosis classification precision compared with other generation methods. This reflects that the images generated via the DDPM method have better quality, with higher similarity to the real images and a better enhancement of the original unbalanced data. The DDPM-based sample generation method can be utilized as an efficient data enhancement method to promote the diagnostic precision and generalization efficiency of FD classifiers under unbalanced sample conditions.
The experimental results also indicate that the presented CNN FD model achieves the highest diagnostic precision on all datasets, which is because the CNN model is a deep neural network. Compared with the other three shallow networks, CNN is able to extract more and deeper characteristics to efficiently characterize the complicated mapping relationship between RB vibration signals and fault states. Another reason for this is that the input of CNN is an SDP image, which can be better characterized for rolling bearing faults. At the same time, the inputs of SVM, RF, and BP neural networks are the SDP images’ texture feature parameters, which are subject to uncertainty caused by human interference in the extraction procedure, and some critical fault features may be lost.
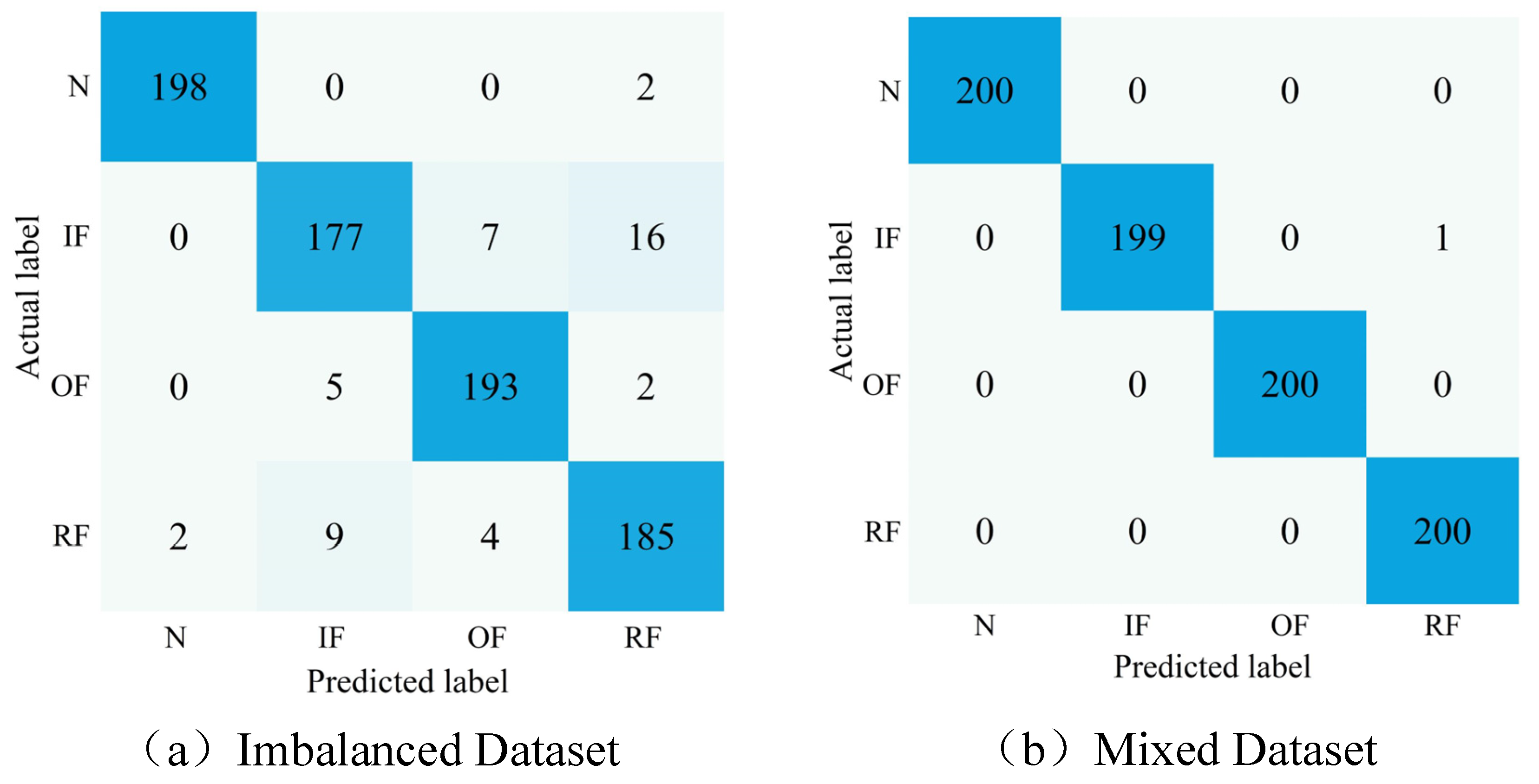
In order to further illustrate the efficiency of the developed approach,
Figure 14 shows the confusion matrix for the first experiment when employing the CNN model for FD and the classification of the imbalanced and mixed datasets after sample enhancement using DDPM. The confusion matrix’s vertical coordinates describe the actual label of the classification, and the horizontal coordinates describe the predicted label. The confusion matrix’s main diagonal elements describe the number of truly classified samples in the current category.
The classification effect of the CNN FD model in a mixed dataset is considerably better than that on the unbalanced dataset. Enhancing the unbalanced dataset using DDPM-generated image samples can improve the diagnostic model’s classification precision in unbalanced situations. Meanwhile, the mentioned results also indicate that the FD method using the SDP images, DDPM, and CNN model presented in the current work can accurately classify rolling bearings’ different operating conditions in the sample imbalance conditions, demonstrating the efficiency of the presented approach.
In order to illustrate the advantages of the SDP images used in this paper for the rolling bearing fault diagnosis task, we also converted the vibration samples of rolling bearings into vibration grayscale images, short-time Fourier transform (STFT) images, and wavelet images, which are commonly used in fault diagnosis research, and carried out the comparison experiments. In the experiment, the corresponding types of image samples were firstly generated using DDPM, and then a mixed dataset was constructed by utilizing various types of real images and generated images, and the number of all samples in the dataset was set in the same way as that of the SDP images in
Table 3. Finally, we performed fault diagnosis using different kinds of images as inputs and using the CNN diagnostic model proposed above, and the diagnostic results are shown in
Table 5. In
Table 5, the grayscale image directly converts the amplitude of the vibration signal into grayscale values obtained, the STFT image uses the Hamming window as the window function, and the wavelet image uses the Morlet wavelet as the wavelet basis function.
From the results, it can be observed that the CNN diagnostic model has the highest accuracy when using SDP images as input. This is followed by the wavelet image, STFT image, and grayscale image, respectively. This is due to the grayscale image only being obtained based on the amplitude of the vibration signal, and some fault features may be lost during the conversion process. The SFTF image allows for the analysis of the signal through a fixed-size time window, which has a limited time-frequency resolution. Wavelet images, as a result of the wavelet transform, may have boundary effects and frequency aliasing. Moreover, the wavelet transform needs to set the basis function in advance, which cannot meet the adaptive requirements of the data and has limitations in dealing with nonlinear unstable signals. Compared with the above images, an SDP image only converts the vibration signal into an SDP image in polar coordinates, as SDP images are able to contain more information concerning fault characteristics and are more suitable for carrying out rolling bearing fault diagnosis tasks.
In order to further illustrate the advantages of deep learning methods in fault diagnosis, as well as to further validate the robustness and effectiveness of the proposed methods, we conducted experimental comparisons by utilizing some widely used deep learning-based fault diagnosis models in the field of fault diagnosis. The datasets used in the experiments were all mixed datasets with sample balance reached after data supplementation using DDPM-generated images. In order to eliminate the effect of chance errors, each method was tested 10 times, and diagnostic performances were evaluated using the average accuracy of the 10 test results, which are shown in
Table 6.
In the experiments, the architecture and parameter settings of the CNN diagnostic model remained unchanged. CBAM-CNN was added to the CNN model with the CBAM attention mechanism. CBAM incorporated both channel attention and spatial attention, which allowed the model to focus on regions where fault characteristics were more pronounced. The 1D-CNN model consisted of five convolutional layers, two fully connected layers, and a SoftMax classifier. The input for the 1D-CNN was a 1 × 2048 vibrating sample; the size of the convolutional kernel was 1 × 32; the number of convolutional kernels was 16, 32, 32, 64, and 128, respectively; the activation function was ReLU; and the number of nodes in the fully connected layer was 1024 and 256. The diagnostic model based on the deep belief network (DBN) consisted of one input layer, one output layer, and four hidden layers. The number of nodes in the hidden layers was 512, 256, 128, 64, and 32, and the hidden layer activation function was Sigmoid. The diagnostic model based on the stacked autoencoder (SAE) consisted of one input layer, one output layer, and four hidden layers. The number of nodes in the hidden layers was 512, 256, 128, 64, and 32, and the hidden layer activation function was ReLU.
From the experimental results, it can be seen that the CNN diagnostic method used in this paper outperforms other deep learning diagnostic methods in terms of accuracy, reaching 99.45%. This indicates that the method proposed in this paper has significant advantages over other deep learning diagnostic methods. When using the same vibration image as input, the diagnostic accuracy of CNN is significantly higher than that of DBN and SAE. This is because CNN is better able to extract the local features and spatial information in the image, which is more suitable for processing image data. Also, the diagnostic accuracy of CBAM-CNN and 1D-CNN is higher than that of DBN and SAE, which indicates that the CNN model is more capable of fault feature extraction. In addition, because the 1D vibration signals are weaker than vibration images in characterizing fault features, the diagnostic accuracy of 1D-CNN with 1D vibration signals as input is 1.72% lower than that of the method proposed in this paper. Moreover, although CBAM-CNN adds a CBAM attention mechanism to the foundation of CNN, the diagnostic accuracy of the CBAM-CNN is not significantly different from that of CNN in the proposed method in this paper or is even slightly decreased. This indicates that the sensory field of the CNN model was sufficient for fitting the target features to the data before adding the attention mechanism, so the diagnostic performance of the CNN did not change significantly after the addition of the attention mechanism. In addition, adding an attention mechanism increases the model parameters, which may increase the likelihood of overfitting in the CNN model.
It is worth noting that the diagnostic results reveal that the accuracy of all deep learning fault diagnosis methods is higher than 95%. This is because, compared with traditional shallow diagnostic models such as BPNN and SVM, deep learning models do not need to extract fault features manually, thus reducing the uncertainty of manual feature extraction. It also indicates that deep learning models have stronger feature extraction and processing capabilities, which makes them more suitable for fault diagnosis research.
Moreover, we also compared the standard deviations of the diagnostic accuracy of the different methods. The standard deviation of the accuracy rate can reflect variations in the diagnostic model’s performance in different experiments or different datasets and can indicate the robustness of the diagnostic model to some extent. From the experimental results, it can be found that the CNN diagnostic method proposed in this paper has the smallest standard deviation of accuracy, which indicates that the model has the most stable performance in multiple fault diagnostic experiments and has a strong ability to adapt to different image samples, which also indicates that the method has strong robustness.
Finally, we also compared the training time of different deep learning fault diagnosis methods. From the results, we can see that the training time of the CNN diagnostic model proposed in this paper is relatively long, but it is still within the acceptable range. The differences between the training times of CBAM-CNN, DBN, and SAE compared with CNN may be caused by the number of parameters in the model, with models with fewer parameters taking relatively less time to train. Since CNN is more suitable for processing image data, the training time of CNN will be slightly shorter than 1D-CNN. However, the training time of the fault diagnosis model is affected by many factors, such as the optimization algorithm, data size and quantity, and hardware equipment. Therefore, the training time and diagnostic performance of diagnostic models need to be evaluated in combination with specific diagnostic tasks and experimental environments.























{kind=link}
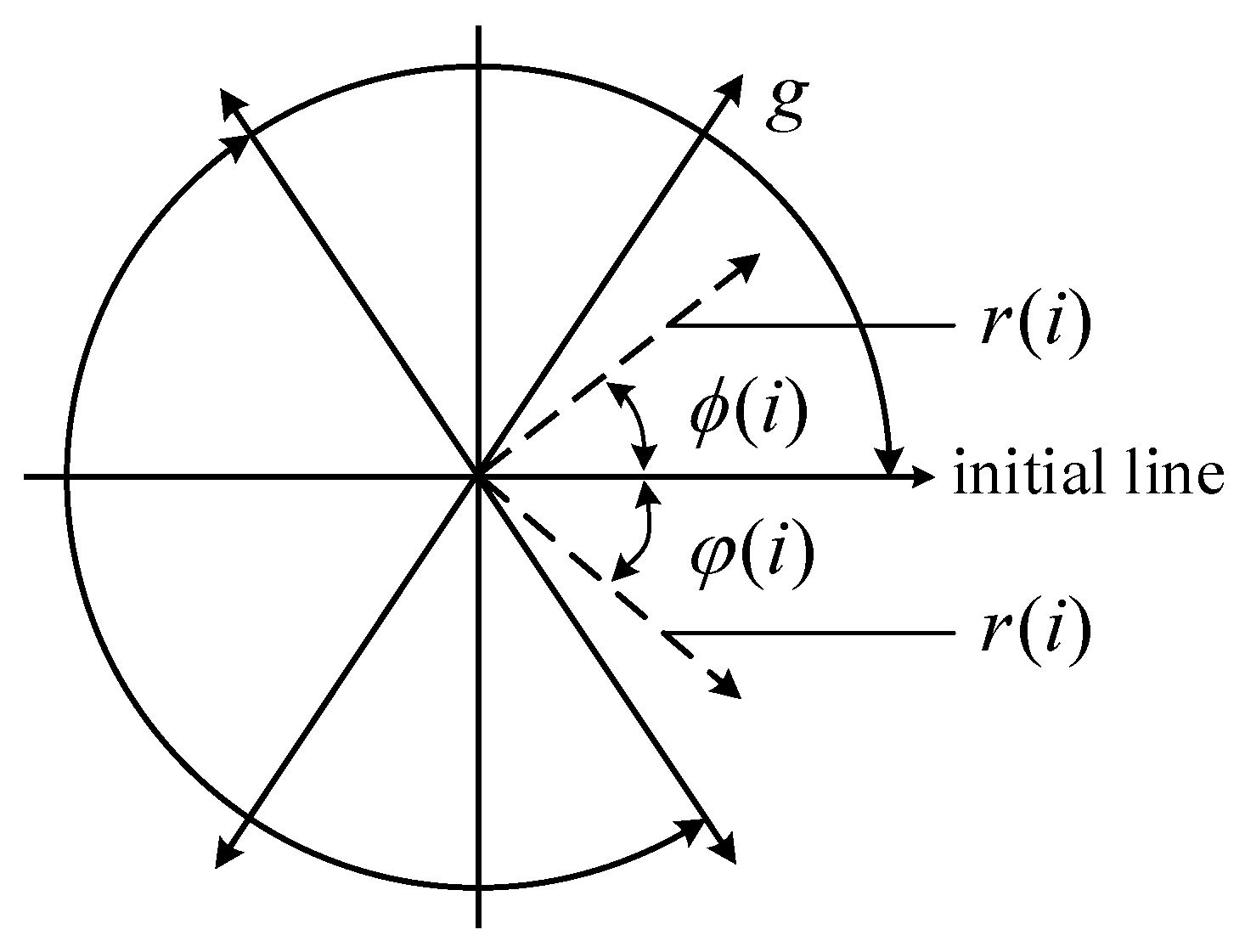{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}