
Continual Reinforcement Learning for Quadruped Robot Locomotion



Abstract
:1. Introduction
- We introduce the concept of continual reinforcement learning for quadruped robot locomotion, addressing the limitations imposed by the lacking requirements of multi-task formulation.
- We propose a dynamic-architecture-based framework that enables continual learning, relieves the catastrophic forgetting in quadruped robot and improves complex locomotion capabilities. Then, we introduce the re-initialization and the entropy to help the robot maintain its plasticity.
- We present experimental results demonstrating the effectiveness of our approach in achieving robust and adaptive locomotion performance in dynamic environments.
2. Materials and Methods
2.1. Preliminary
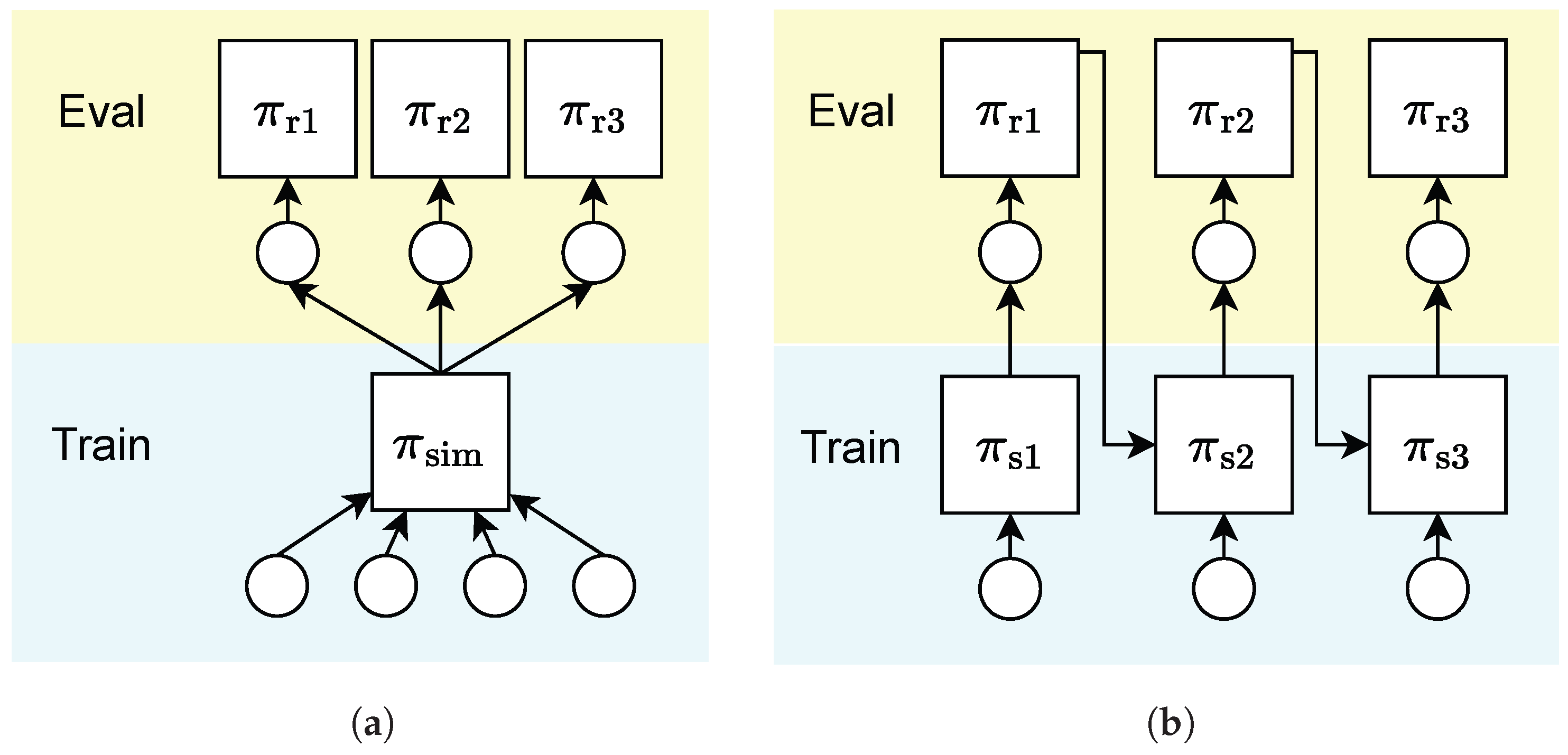
2.2. Continual Quadruped Robot Locomotion
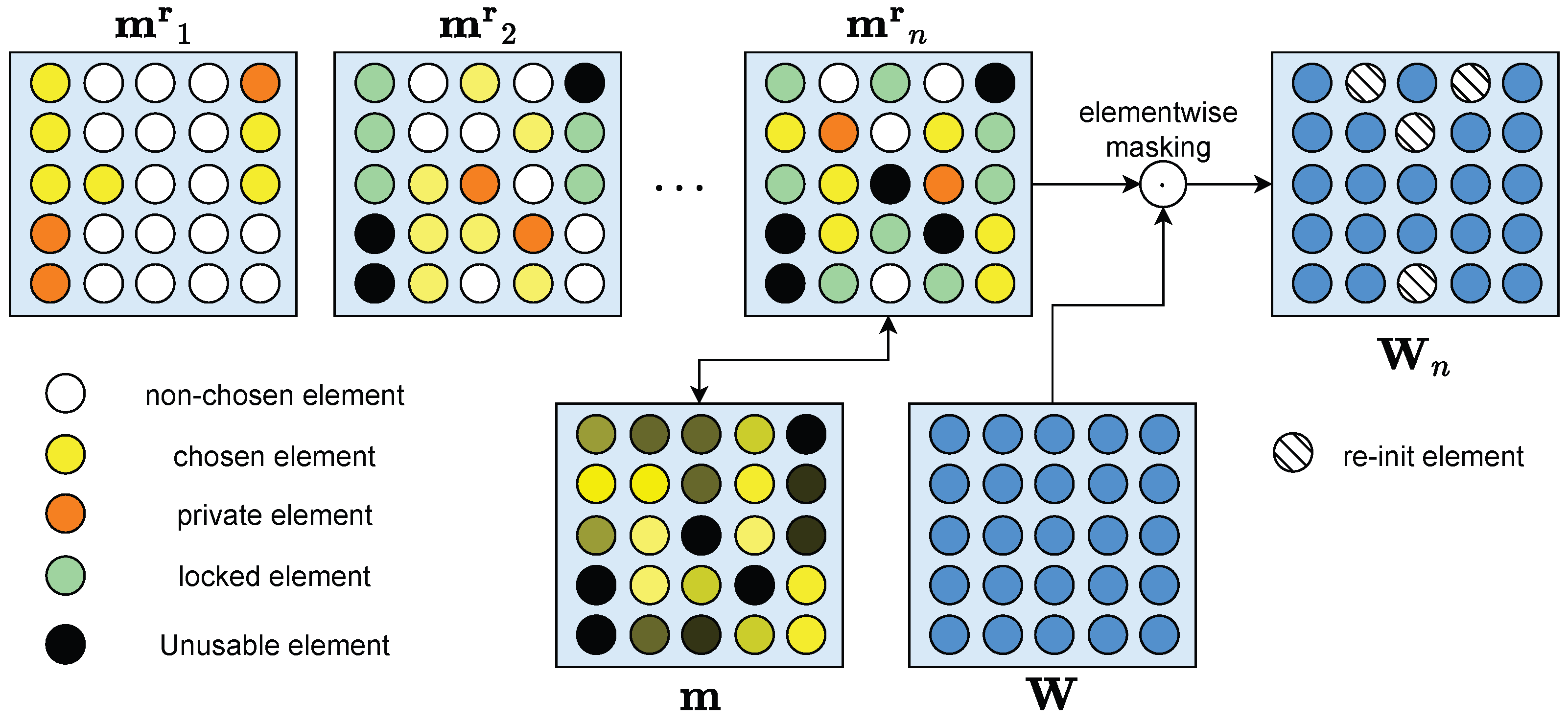
2.3. Catastrophic Forgetting and Piggyback
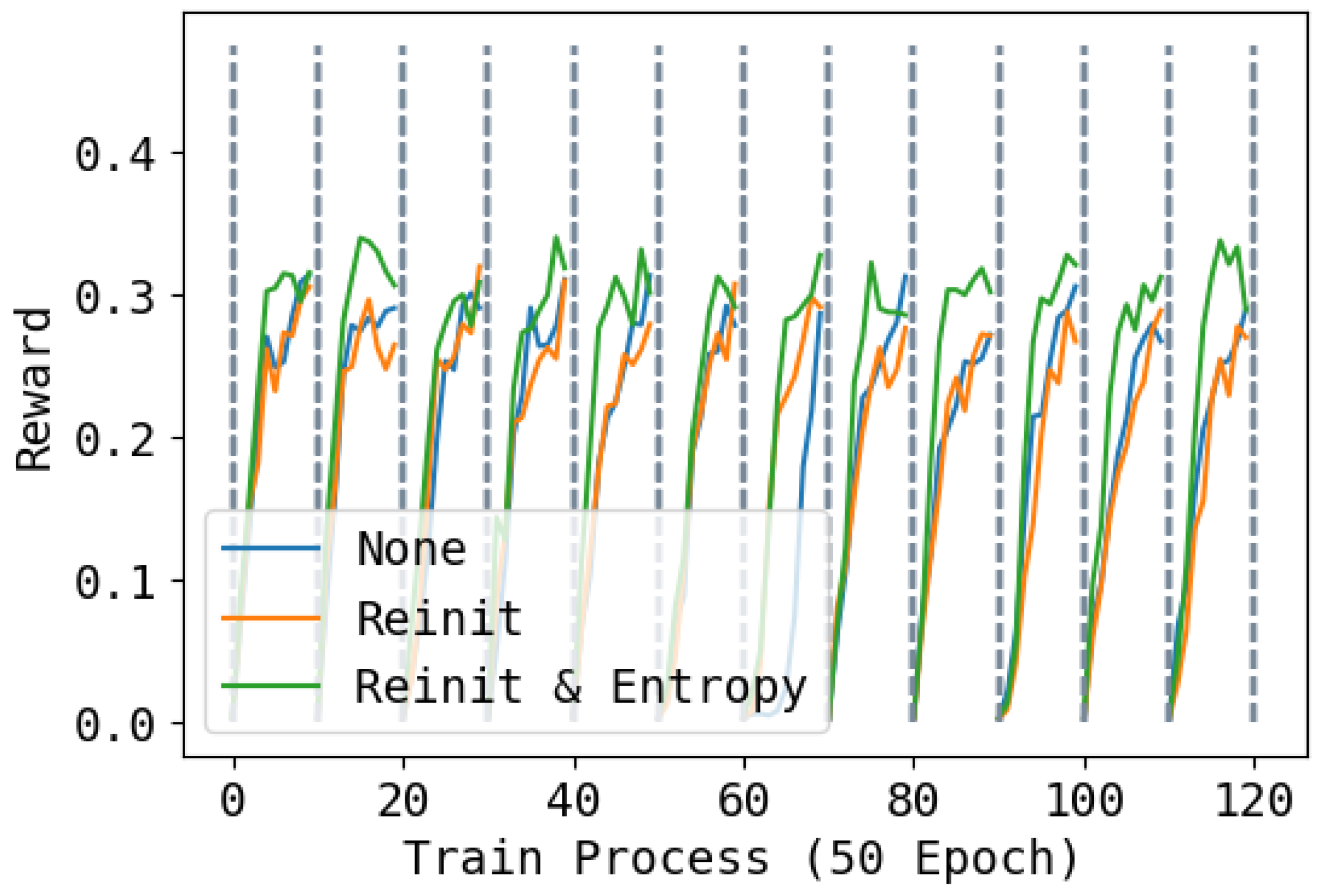
2.4. Loss of Plasticity and Re-Initialization
2.5. Sim to Real in Continual Learning
2.6. Compare to the Past Works
3. Results
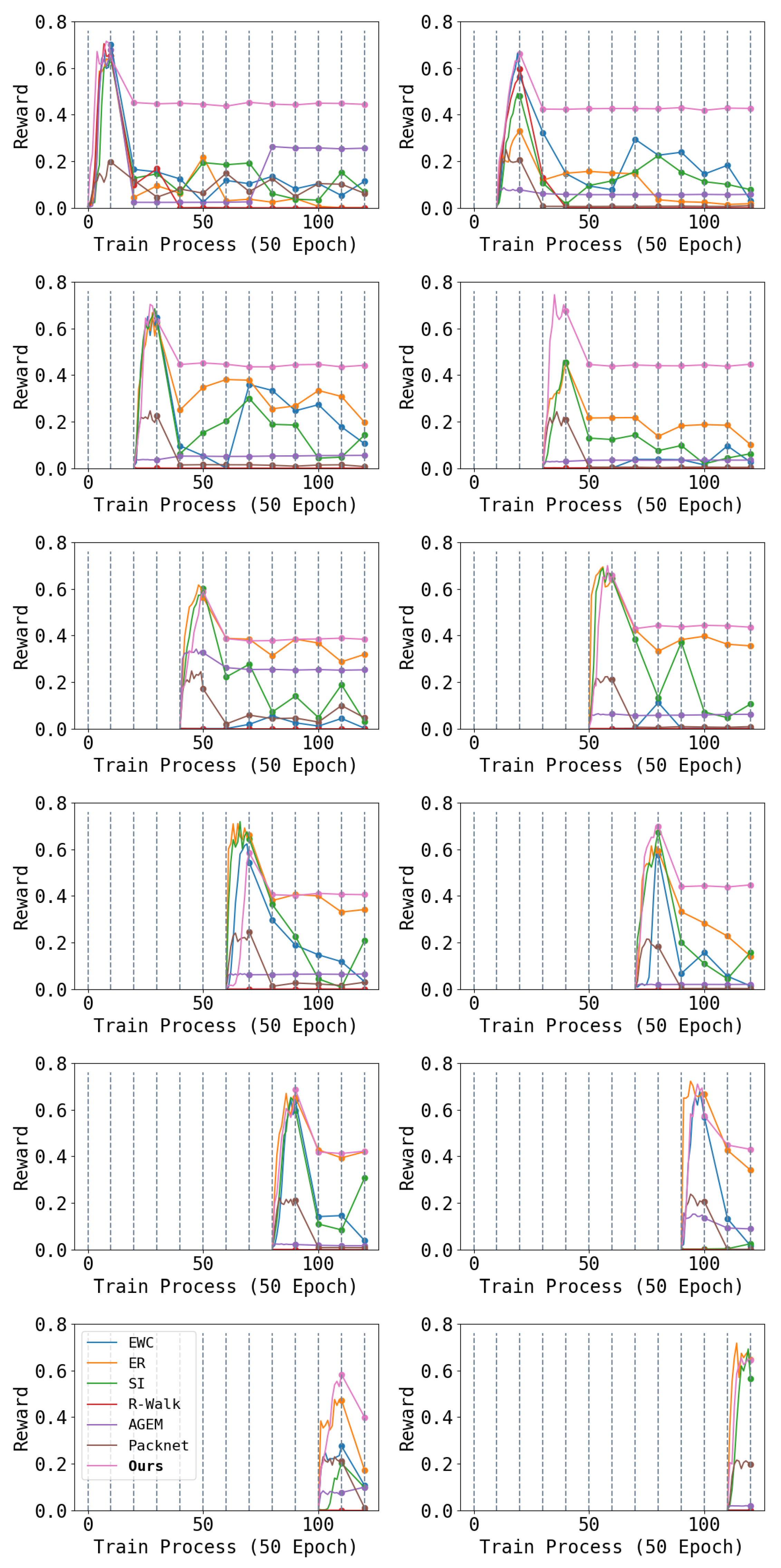
3.1. Compared Methods
- Experience Replay (ER) [12]: a basic rehearsal-based continual method that adds a behavior cloning term to the loss function of the policy network.
- Averaged gradient episodic memory (AGEM) [13]: a method based on gradient episodic memory that uses only a batch of gradients to limit the policy update.
- Elastic weight consolidation (EWC) [14]: constraining changes to critical parameters by the Fisher information matrix.
- Riemannian Walk (R-Walk) [15]: a method adds a parameter importance score on the Riemannian manifold based on EWC.
- Synaptic Intelligence (SI) [16]: a method that constrain the changes after each optimization step.
- Packnet [17]: a method to sequentially “pack” multiple tasks into a single network by performing iterative pruning and network re-training.
3.2. Implementation Details
3.3. Experimental Environments
- Leg Crash: we set the output of different legs of the robot to zero for each task to simulate the situation where the leg crashes and cannot move.
- Leg Inversion: for each task, we invert the outputs of the neural network for one leg of the robot.
- Leg Noise: we add random Gaussian noise to the output of the robot. From the first task to the fourth task, we add the noise to the left front leg, the right front leg, the left rear leg, and the right rear leg.
4. Discussion
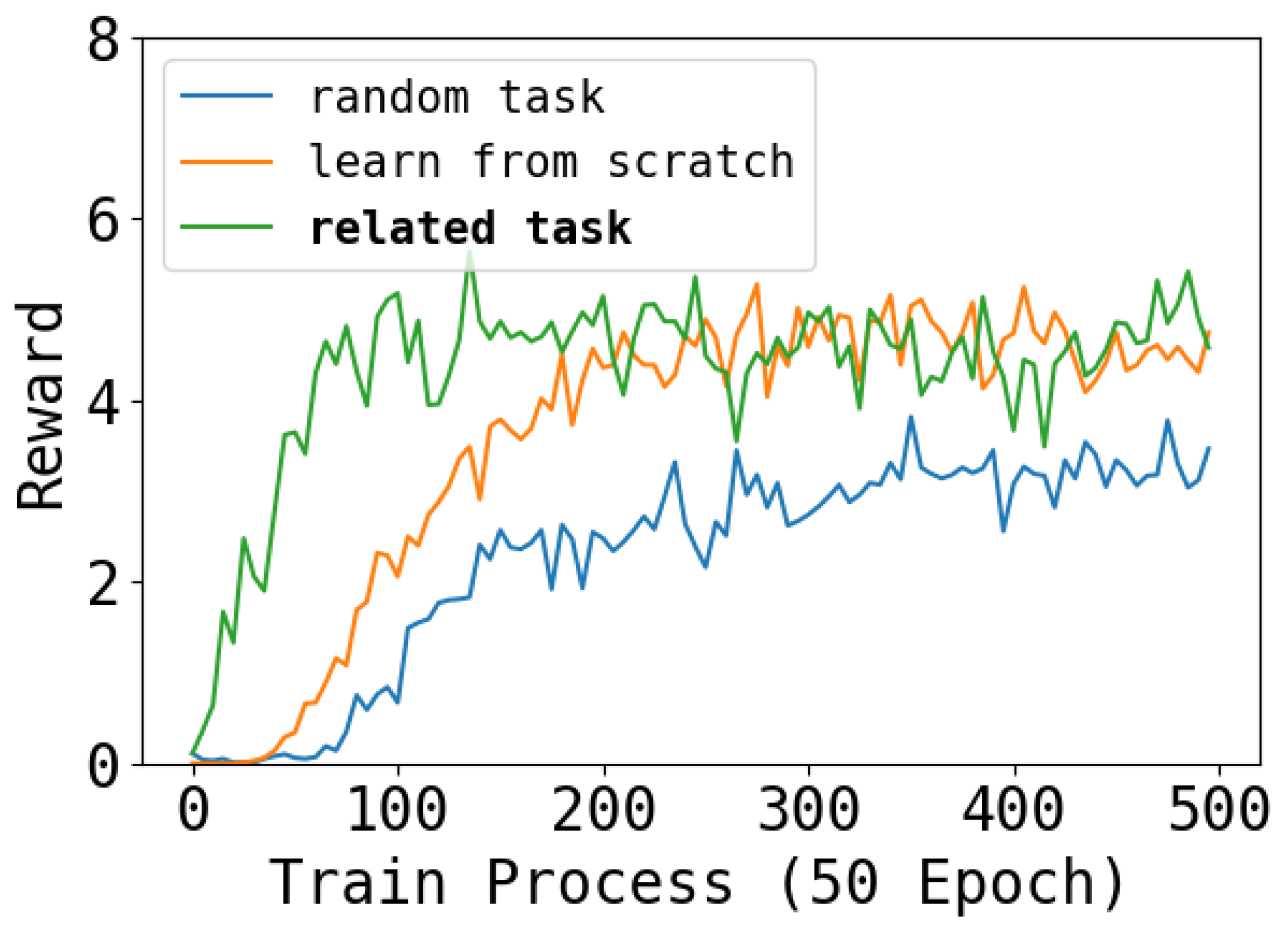
4.1. Episode Reward
4.2. Commands Tracking
4.3. Effect of Re-Initialization and Entropy
4.4. Forward Transfer
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zitkovich, B.; Yu, T.; Xu, S.; Xu, P.; Xiao, T.; Xia, F.; Wu, J.; Wohlhart, P.; Welker, S.; Wahid, A.; et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Proceedings of the 7th Annual Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023. [Google Scholar]
- Brohan, A.; Brown, N.; Carbajal, J.; Chebotar, Y.; Dabis, J.; Finn, C.; Gopalakrishnan, K.; Hausman, K.; Herzog, A.; Hsu, J.; et al. Rt-1: Robotics transformer for real-world control at scale. arXiv 2022, arXiv:2212.06817. [Google Scholar]
- Kang, Y.; Shi, D.; Liu, J.; He, L.; Wang, D. Beyond reward: Offline preference-guided policy optimization. arXiv 2023, arXiv:2305.16217. [Google Scholar]
- Liu, J.; Zhang, H.; Zhuang, Z.; Kang, Y.; Wang, D.; Wang, B. Design from Policies: Conservative Test-Time Adaptation for Offline Policy Optimization. arXiv 2023, arXiv:2306.14479. [Google Scholar]
- Reed, S.; Zolna, K.; Parisotto, E.; Colmenarejo, S.G.; Novikov, A.; Barth-Maron, G.; Gimenez, M.; Sulsky, Y.; Kay, J.; Springenberg, J.T.; et al. A generalist agent. arXiv 2022, arXiv:2205.06175. [Google Scholar]
- Yang, R.; Xu, H.; Wu, Y.; Wang, X. Multi-task reinforcement learning with soft modularization. Adv. Neural Inf. Process. Syst. 2020, 33, 4767–4777. [Google Scholar]
- Mallya, A.; Davis, D.; Lazebnik, S. Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part IV; Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11208, pp. 72–88. [Google Scholar] [CrossRef]
- Kang, H.; Yoon, J.; Madjid, S.R.; Hwang, S.J.; Yoo, C.D. Forget-free Continual Learning with Soft-Winning SubNetworks. arXiv 2023, arXiv:2303.14962. [Google Scholar]
- Ramanujan, V.; Wortsman, M.; Kembhavi, A.; Farhadi, A.; Rastegari, M. What’s hidden in a randomly weighted neural network? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11893–11902. [Google Scholar]
- Zhang, H.; Yang, S.; Wang, D. A Real-World Quadrupedal Locomotion Benchmark for Offline Reinforcement Learning. arXiv 2023, arXiv:2309.16718. [Google Scholar]
- Van de Ven, G.M.; Tolias, A.S. Three scenarios for continual learning. arXiv 2019, arXiv:1904.07734. [Google Scholar]
- Rolnick, D.; Ahuja, A.; Schwarz, J.; Lillicrap, T.P.; Wayne, G. Experience Replay for Continual Learning. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 348–358. [Google Scholar]
- Chaudhry, A.; Ranzato, M.; Rohrbach, M.; Elhoseiny, M. Efficient Lifelong Learning with A-GEM. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Chaudhry, A.; Dokania, P.K.; Ajanthan, T.; Torr, P.H. Riemannian Walk for Incremental Learning: Understanding Forgetting and Intransigence. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 556–572. [Google Scholar]
- Zenke, F.; Poole, B.; Ganguli, S. Continual Learning Through Synaptic Intelligence. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 3987–3995. [Google Scholar]
- Mallya, A.; Lazebnik, S. Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7765–7773. [Google Scholar]
- Gai, S.; Wang, D.; He, L. Offline Experience Replay for Continual Offline Reinforcement Learning. In Proceedings of the 26th European Conference on Artificial Intelligence, Kraków, Poland, 18 October 2023; pp. 772–779. [Google Scholar]
- Nahrendra, I.M.A.; Yu, B.; Myung, H. DreamWaQ: Learning Robust Quadrupedal Locomotion with Implicit Terrain Imagination via Deep Reinforcement Learning. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA 2023, London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 5078–5084. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Lyle, C.; Zheng, Z.; Nikishin, E.; Pires, B.Á.; Pascanu, R.; Dabney, W. Understanding Plasticity in Neural Networks. In Proceedings of the International Conference on Machine Learning, ICML 2023, Honolulu, HI, USA, 23–29 July 2023; Volume 202, pp. 23190–23211. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Equation | Weight |
|---|---|---|
| linear velocity tracking | ||
| angular velocity tracking | ||
| z velocity | ||
| roll-pitch velocity | ||
| orientation | ||
| joint limit violation | ||
| joint torques | ||
| joint accelerations | ||
| body height | ||
| feet clearance | ||
| thigh/calf collision | ||
| action smoothing |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gai, S.; Lyu, S.; Zhang, H.; Wang, D. Continual Reinforcement Learning for Quadruped Robot Locomotion. Entropy 2024, 26, 93. https://doi.org/10.3390/e26010093
Gai S, Lyu S, Zhang H, Wang D. Continual Reinforcement Learning for Quadruped Robot Locomotion. Entropy. 2024; 26(1):93. https://doi.org/10.3390/e26010093
Chicago/Turabian StyleGai, Sibo, Shangke Lyu, Hongyin Zhang, and Donglin Wang. 2024. "Continual Reinforcement Learning for Quadruped Robot Locomotion" Entropy 26, no. 1: 93. https://doi.org/10.3390/e26010093
APA StyleGai, S., Lyu, S., Zhang, H., & Wang, D. (2024). Continual Reinforcement Learning for Quadruped Robot Locomotion. Entropy, 26(1), 93. https://doi.org/10.3390/e26010093