



A Deep Neural Network Regularization Measure: The Class-Based Decorrelation Method

Abstract
:1. Introduction
2. Related Work
3. Class-Based Decorrelation Method
3.1. Theoretical Motivation
3.2. CDM Application in the Fully Connected Layer
3.3. CDM Application in Convolutional Layer
4. Experimental Section
4.1. Datasets
- MNIST: The MNIST dataset is a collection of handwritten digit images, totaling 70,000 grayscale images across 10 different classes. Each image is 28 pixels in height and 28 pixels in width. The training set comprises 60,000 images, while the test set contains 10,000 images.
- CIFAR-10: The CIFAR-10 dataset comprises 10 classes, with each class containing 6000 color images sized at 32 × 32 pixels and composed of RGB three-channel data. The training set encompasses 50,000 images, while the test set includes 10,000 images.
- Mini-ImageNet: The mini-ImageNet dataset consists of 50,000 training images and 10,000 testing images, evenly distributed across 100 classes. The images have a size of 84 × 84 × 3.
4.2. Network Frameworks
4.3. Effect on the Covariance Gap
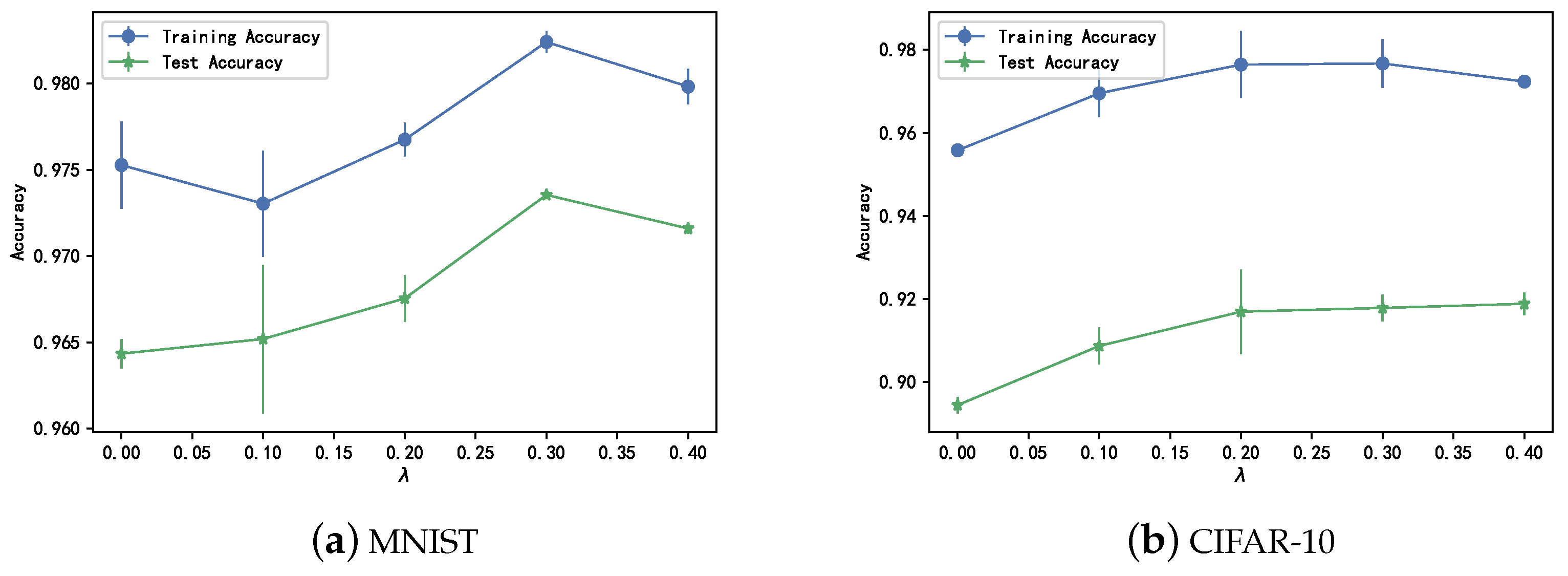
4.4. Hyperparameter
4.5. Experiment on Fully Connected Layer
4.6. Experiments on Convolutional Layer
4.7. Experiments with a Comparatively Small Training Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Martin, C.H.; Mahoney, M.W. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning. J. Mach. Learn. Res. 2021, 22, 7479–7551. [Google Scholar]
- Bartlett, P. The sample complexity of pattern classification with neural networks: The size of the weights is more important than the size of the network. IEEE Trans. Inf. Theory 1998, 44, 525–536. [Google Scholar] [CrossRef]
- Bartlett, P.L.; Mendelson, S. Rademacher and Gaussian complexities: Risk bounds and structural results. J. Mach. Learn. Res. 2002, 3, 463–482. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Willoughby, R.A. Solutions of Ill-Posed Problems (A. N. Tikhonov and V. Y. Arsenin). SIAM Rev. 1979, 21, 266–267. [Google Scholar] [CrossRef]
- Krogh, A.; Hertz, J. A simple weight decay can improve generalization. Adv. Neural Inf. Process. Syst. 1991, 4. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Neal, B.; Mittal, S.; Baratin, A.; Tantia, V.; Scicluna, M.; Lacoste-Julien, S.; Mitliagkas, I. A Modern Take on the Bias-Variance Tradeoff in Neural Networks. In Proceedings of the ICML 2019 Workshop on Identifying and Understanding Deep Learning Phenomena, Long Beach, CA, USA, 15 August 2019. [Google Scholar]
- Belkin, M.; Hsu, D.; Ma, S.; Mandal, S. Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proc. Natl. Acad. Sci. USA 2019, 116, 15849–15854. [Google Scholar] [CrossRef]
- Cogswell, M.; Ahmed, F.; Girshick, R.; Zitnick, L.; Batra, D. Reducing overfitting in deep networks by decorrelating representations. arXiv 2015, arXiv:1511.06068. [Google Scholar]
- Gu, S.; Hou, Y.; Zhang, L.; Zhang, Y. Regularizing Deep Neural Networks with an Ensemble-based Decorrelation Method. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 2177–2183. [Google Scholar]
- Yao, S.; Hou, Y.; Ge, L.; Hu, Z. Regularizing Deep Neural Networks by Ensemble-based Low-Level Sample-Variances Method. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1111–1120. [Google Scholar]
- Achille, A.; Soatto, S. Emergence of invariance and disentanglement in deep representations. J. Mach. Learn. Res. 2018, 19, 1947–1980. [Google Scholar]
- Liu, Y.; Yao, X. Ensemble learning via negative correlation. Neural Netw. 1999, 12, 1399–1404. [Google Scholar] [CrossRef] [PubMed]
- Alhamdoosh, M.; Wang, D. Fast decorrelated neural network ensembles with random weights. Inf. Sci. 2014, 264, 104–117. [Google Scholar] [CrossRef]
- Wang, X.; Chen, H.; Tang, S.; Wu, Z.; Zhu, W. Disentangled representation learning. arXiv 2022, arXiv:2211.11695. [Google Scholar]
- Carbonneau, M.A.; Zaidi, J.; Boilard, J.; Gagnon, G. Measuring disentanglement: A review of metrics. arXiv 2020, arXiv:2012.09276. [Google Scholar] [CrossRef]
- Bian, Y.; Chen, H. When does diversity help generalization in classification ensembles? IEEE Trans. Cybern. 2021, 52, 9059–9075. [Google Scholar] [CrossRef]
- Ayinde, B.O.; Inanc, T.; Zurada, J.M. Regularizing deep neural networks by enhancing diversity in feature extraction. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2650–2661. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-vae: Learning basic visual concepts with a constrained variational framework. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Zhang, C.; Hou, Y.; Song, D.; Ge, L.; Yao, Y. Redundancy of Hidden Layers in Deep Learning: An Information Perspective. arXiv 2020, arXiv:2009.09161. [Google Scholar]
- Bartlett, P.; Maiorov, V.; Meir, R. Almost linear VC dimension bounds for piecewise polynomial networks. Adv. Neural Inf. Process. Syst. 1998, 11. [Google Scholar] [CrossRef]
- Bartlett, P.L.; Harvey, N.; Liaw, C.; Mehrabian, A. Nearly-tight VC-dimension and pseudodimension bounds for piecewise linear neural networks. J. Mach. Learn. Res. 2019, 20, 2285–2301. [Google Scholar]
- Yang, Y.; Yang, H.; Xiang, Y. Nearly Optimal VC-Dimension and Pseudo-Dimension Bounds for Deep Neural Network Derivatives. arXiv 2023, arXiv:2305.08466. [Google Scholar]
- Dziugaite, G.K.; Roy, D.M. Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data. arXiv 2017, arXiv:1703.11008. [Google Scholar]
- Neyshabur, B.; Bhojanapalli, S.; McAllester, D.; Srebro, N. Exploring generalization in deep learning. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Neyshabur, B.; Bhojanapalli, S.; Srebro, N. A pac-bayesian approach to spectrally-normalized margin bounds for neural networks. arXiv 2017, arXiv:1707.09564. [Google Scholar]
- Neyshabur, B.; Tomioka, R.; Srebro, N. Norm-based capacity control in neural networks. In Proceedings of the Conference on Learning Theory, PMLR, Paris, France, 3–6 July 2015; pp. 1376–1401. [Google Scholar]
- Bartlett, P.L.; Foster, D.J.; Telgarsky, M.J. Spectrally-normalized margin bounds for neural networks. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Arora, S.; Du, S.S.; Hu, W.; Li, Z.; Salakhutdinov, R.R.; Wang, R. On exact computation with an infinitely wide neural net. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Daniely, A.; Granot, E. Generalization bounds for neural networks via approximate description length. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Liang, T.; Poggio, T.; Rakhlin, A.; Stokes, J. Fisher-rao metric, geometry, and complexity of neural networks. In Proceedings of the The 22nd International Conference on Artificial Intelligence and Statistics, PMLR, Okinawa, Japan, 16–18 April 2019; pp. 888–896. [Google Scholar]
- Jiang, Y.; Neyshabur, B.; Mobahi, H.; Krishnan, D.; Bengio, S. Fantastic generalization measures and where to find them. arXiv 2019, arXiv:1912.02178. [Google Scholar]
- Kumar, A.; Sattigeri, P.; Balakrishnan, A. Variational inference of disentangled latent concepts from unlabeled observations. arXiv 2017, arXiv:1711.00848. [Google Scholar]
- Chen, R.T.; Li, X.; Grosse, R.B.; Duvenaud, D.K. Isolating sources of disentanglement in variational autoencoders. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; Le Cun, Y.; Fergus, R. Regularization of neural networks using dropconnect. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 17–19 June 2013; pp. 1058–1066. [Google Scholar]
- Bengio, Y.; Bergstra, J. Slow, decorrelated features for pretraining complex cell-like networks. Adv. Neural Inf. Process. Syst. 2009, 22. [Google Scholar]
- Bao, Y.; Jiang, H.; Dai, L.; Liu, C. Incoherent training of deep neural networks to de-correlate bottleneck features for speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway Township, NJ, USA; pp. 6980–6984. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning multiple layers of features from tiny images. In Handbook of Systemic Autoimmune Diseases; Univeristy of Toronto: Toronto, ON, Canada, 2009; Volume 1. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Zhang, Y.; Wang, C.; Deng, W. Relative uncertainty learning for facial expression recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 17616–17627. [Google Scholar]
- Zhang, Y.; Wang, C.; Ling, X.; Deng, W. Learn From All: Erasing Attention Consistency for Noisy Label Facial Expression Recognition. arXiv 2022, arXiv:cs.CV/2207.10299. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | 18-Layer (ResNet18) | 50-Layer (ResNet50) |
|---|---|---|
| Conv 1 | 7 × 7, 64, stride2 | |
| 3 × 3, maxpool, stride2 | ||
| Conv 2 | ||
| Conv3 | ||
| Conv4 | ||
| Conv5 | ||
| Last | average pool/D(1000), D(10)/D(100), softmax | |
| Method | MNIST | CIFAR-10 | ||||
|---|---|---|---|---|---|---|
| Train | Test | Train–Test | Train | Test | Train–Test | |
| None | ||||||
| Dropout | ||||||
| DeCov | ||||||
| EDM | ||||||
| CDM | ||||||
| Method | ResNet18 | ResNet50 | |||||
|---|---|---|---|---|---|---|---|
| Train | Test | Train–Test | Train | Test | Train–Test | ||
| None | |||||||
| Dropout | |||||||
| DeCov | |||||||
| EDM | |||||||
| CDM | |||||||
| Method | Inception | MobileNet | ||||
|---|---|---|---|---|---|---|
| Train | Test | Train–Test | Train | Test | Train–Test | |
| Before | ||||||
| After | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Liu, T.; Du, X. A Deep Neural Network Regularization Measure: The Class-Based Decorrelation Method. Entropy 2024, 26, 7. https://doi.org/10.3390/e26010007
Zhang C, Liu T, Du X. A Deep Neural Network Regularization Measure: The Class-Based Decorrelation Method. Entropy. 2024; 26(1):7. https://doi.org/10.3390/e26010007
Chicago/Turabian StyleZhang, Chenguang, Tian Liu, and Xuejiao Du. 2024. "A Deep Neural Network Regularization Measure: The Class-Based Decorrelation Method" Entropy 26, no. 1: 7. https://doi.org/10.3390/e26010007
APA StyleZhang, C., Liu, T., & Du, X. (2024). A Deep Neural Network Regularization Measure: The Class-Based Decorrelation Method. Entropy, 26(1), 7. https://doi.org/10.3390/e26010007