Support Vector Regression Approach to Predict the Design Space for the Extraction Process of Pueraria lobata

Abstract
:1. Introduction
2. Results
2.1. Box–Behnken Design
2.2. QPM Analysis
2.3. SVR Analysis
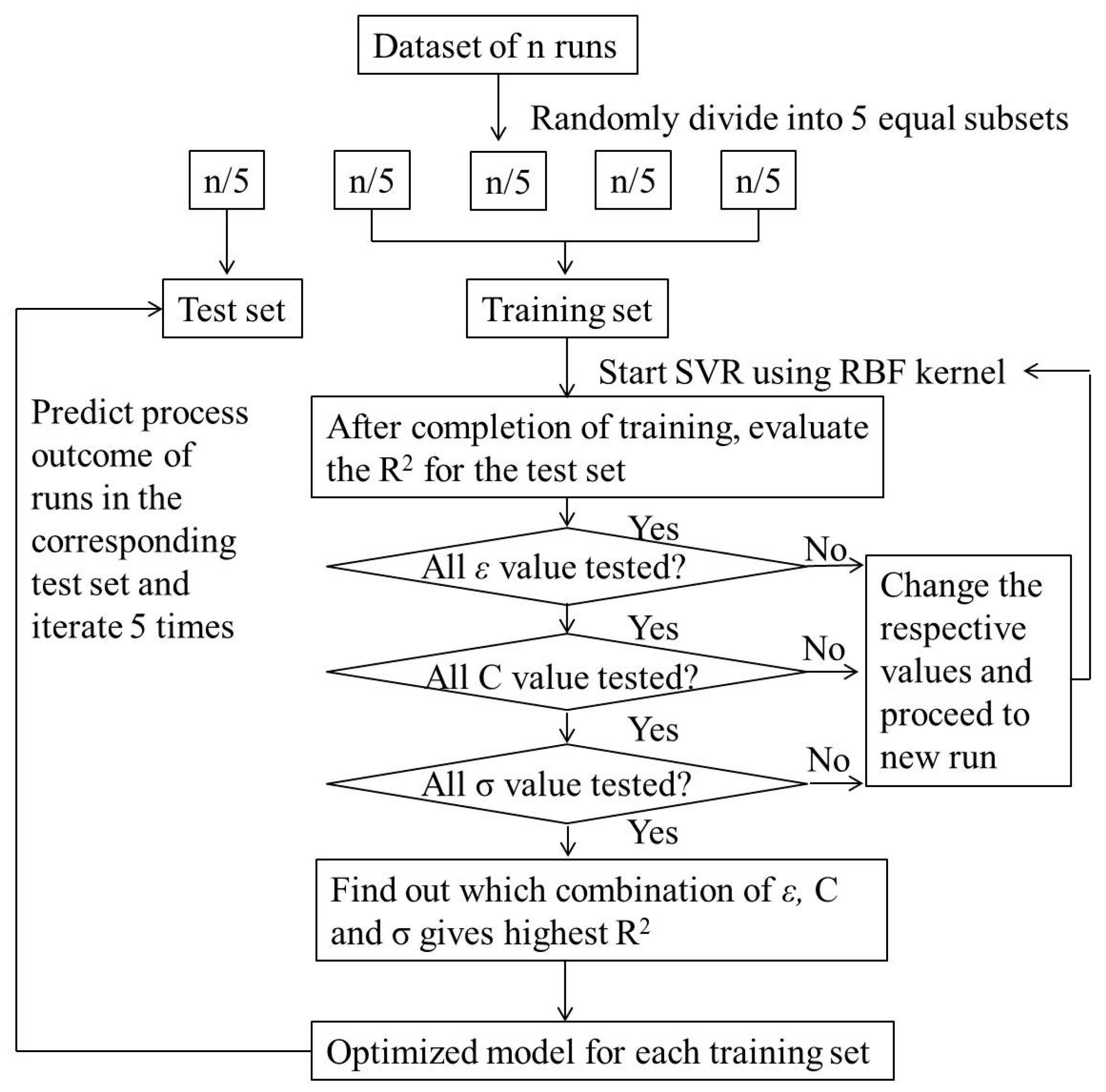
2.3.1. Parameter Optimization for SVR
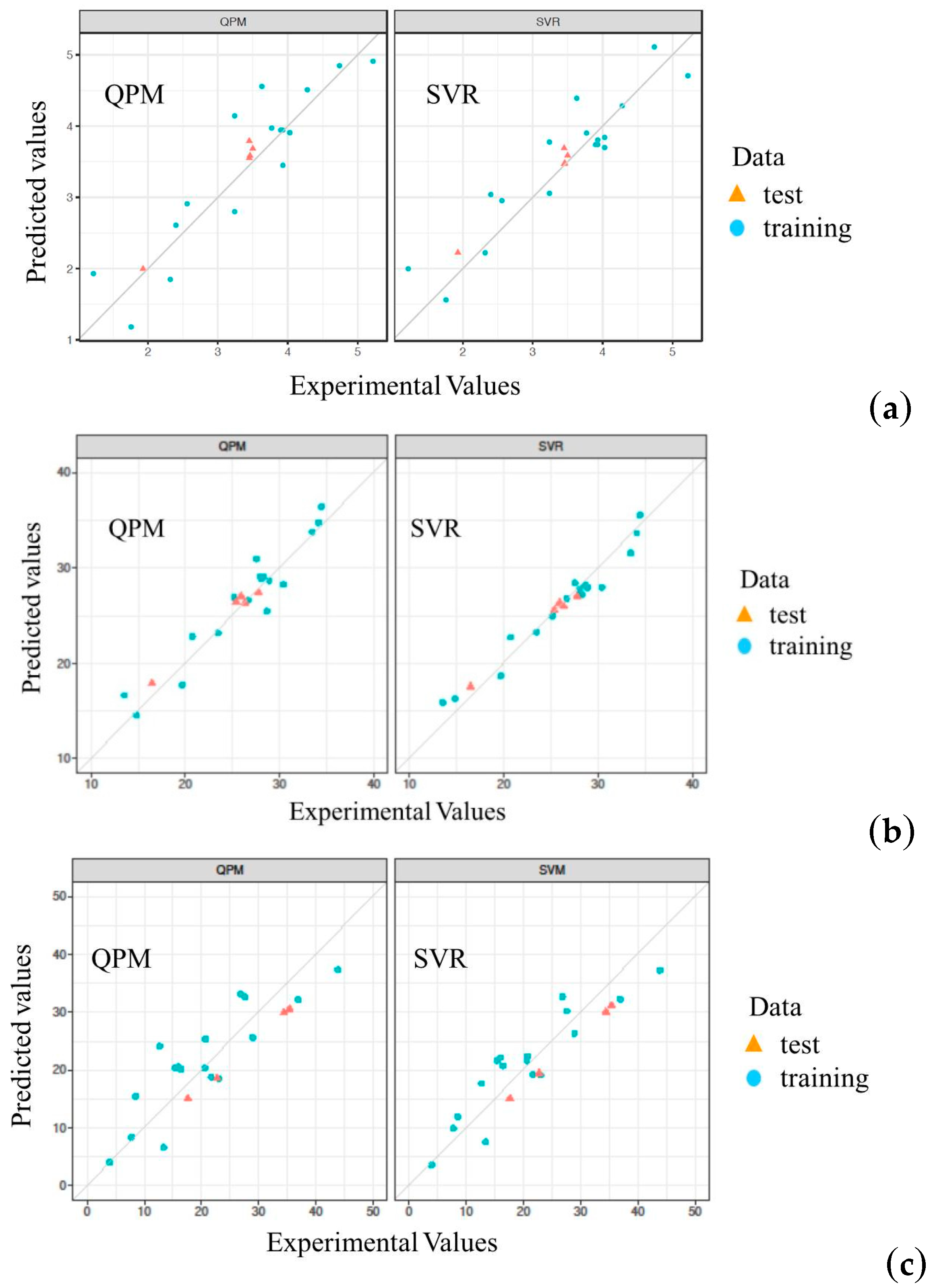
2.3.2. Evaluation of Models
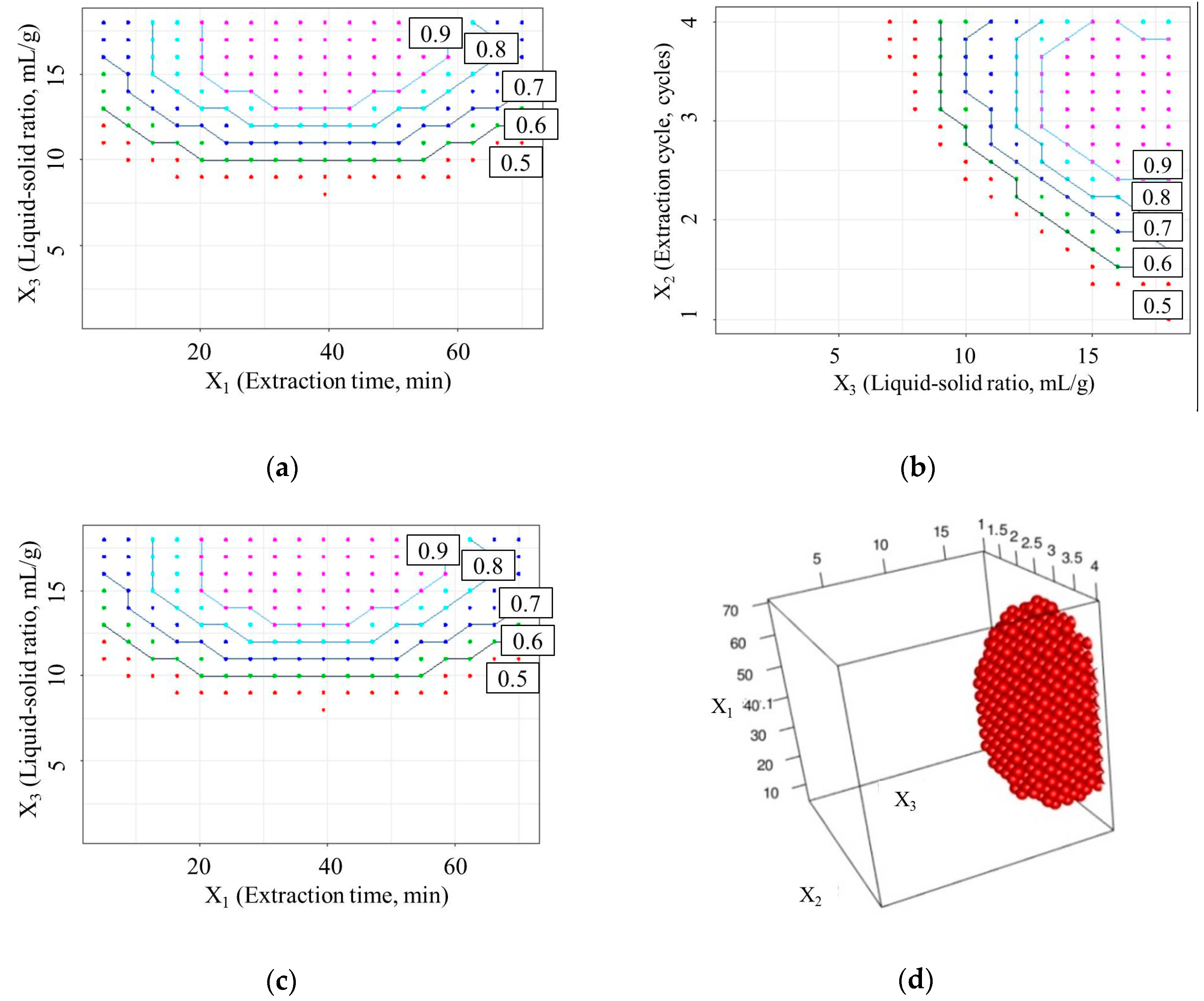
2.4. Design Space
3. Materials and Methods
3.1. Materials
3.2. Apparatus
3.3. Procedures
3.4. HPLC Analysis
3.5. UV Analysis
3.6. Establishment of Models
3.6.1. QPM
3.6.2. SVR
3.7. Optimization
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lee, J.H.; Jeon, Y.D.; Lee, Y.M.; Kim, D.K. The suppressive effect of puerarin on atopic dermatitis-like skin lesions through regulation of inflammatory mediators in vitro and in vivo. Biochem. Biophys. Res. Commun. 2018, 498, 707–714. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, T.; Tang, H.J.; Yu, F.N.; Michihara, S.; Uzawa, Y.; Zaima, N.; Moriyama, T.; Kawamura, Y. Kudzu (Pueraria lobata) vine ethanol extracts improve ovariectomy-induced bone loss in female mice. J. Agric. Food Chem. 2011, 59, 13230–13237. [Google Scholar] [CrossRef] [PubMed]
- Koirala, P.; Seong, S.H.; Jung, H.A.; Choi, J.S. Comparative molecular docking studies of lupeol and lupenone isolated from Pueraria lobata that inhibits BACE1: Probable remedies for Alzheimer’s disease. Asian Pac. J. Trop. Med. 2017, 10, 1117–1122. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Xu, L.Y.; Liang, T.; Li, Y.W.; Zhang, S.J.; Duan, X.Q. Puerarin mediates hepatoprotection against CCl4-induced hepatic fibrosis rats through attenuation of inflammation response and amelioration of metabolic function. Food Chem. Toxicol. 2013, 52, 69–75. [Google Scholar] [CrossRef] [PubMed]
- Cheung, D.W.S.; Koon, C.M.; Ng, C.F.; Leung, P.C.; Fung, K.P.; Poon, S.K.S.; Lau, C.B.S. The roots of Salvia miltiorrhiza (Danshen) and Pueraria lobata (Gegen) inhibit atherogenic events: A study of the combination effects of the 2-herb formula. J. Ethnopharmacol. 2012, 143, 859–866. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.F.; Li, X.; Lin, L.; Liang, S.T.; Yan, J. Puerarin inhibits non-small cell lung cancer cell growth via the induction of apoptosis. Oncol. Rep. 2018, 39, 1731–1738. [Google Scholar] [CrossRef] [PubMed]
- U.S. Department of Health and Human Services Food and Drug Administration. Guidance for Industry PAT-A Framework for Innovative Pharmaceutical Development, Manufacturing, and Quality Assurance. Available online: https://www.fda.gov/downloads/drugs/guidancecomplianceregulatoryinformation/guidances/ucm070305.pdf (accessed on 1 September 2004).
- ICH. ICH Harmonised Tripartite Guideline: Pharmaceutical Development Q8 (R2). Available online: http://www.ich.org/fileadmin/Public_Web_Site/ICH_Products/Guidelines/Quality/Q8_R1/Step4/Q8_R2_Guideline.pdf (accessed on 1 August 2009).
- Zhai, C.H.; Xuan, J.B.; Fan, H.L.; Zhao, T.F.; Jiang, J.L. The application of SVR model in the improvement of QbD: A case study of the extraction of podophyllotoxin. Drug Dev. Ind. Pharm. 2018, 44, 1506–1511. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.Q.; Wu, Z.F.; Ke, G.; Yang, M. An effective vacuum assisted extraction method for the optimization of labdane diterpenoids from Andrographis paniculata by response surface methodology. Molecules 2015, 20, 430–445. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Li, X.; Zhang, W.; Zhou, H.H. Comparison of nine statistical model based warfarin pharmacogenetic dosing algorithms using the racially diverse international warfarin pharmacogenetic consortium cohort database. PLoS ONE 2015, 10, e0135784. [Google Scholar] [CrossRef] [PubMed]
- Norioka, T.; Hayashi, Y.; Onuki, Y.; Andou, H.; Tsunashima, D.; Yamashita, K.; Takayama, K. A novel approach to establishing the design space for the oral formulation manufacturing process. Chem. Pharm. Bull. 2013, 61, 39–49. [Google Scholar] [CrossRef] [PubMed]
- Liang, Y.Z.; Xu, Q.S.; Li, H.D.; Cao, D.S. Support Vector Machines and Their Application in Chemistry and Biotechnology; CRC Press: New York, NY, USA, 2011; pp. 15–16. [Google Scholar]
- Jang, H.S.; Bae, K.Y.; Park, H.S.; Sung, D.K. Solar power prediction based on satellite images and support vector machine. IEEE Trans. Sustain. Energy 2016, 7, 1255–1263. [Google Scholar] [CrossRef]
- Yosipof, A.; Guedes, R.C.; Garcia-Sosa, A.T. Data mining and machine learning models for predicting drug likeness and their disease or organ category. Front. Chem. 2018, 6, e162. [Google Scholar] [CrossRef] [PubMed]
- Zhong, H.M.; Miao, C.Y.; Shen, Z.Q.; Feng, Y.H. Comparing the learning effectiveness of BP, ELM, I-ELM, and SVM for corporate credit ratings. Neurocomputing 2014, 128, 285–295. [Google Scholar] [CrossRef]
- Cai, C.Z.; Xiao, H.G.; Yuan, Q.F.; Liu, X.H.; Wen, Y.F. Function prediction for DNA-/RNA-binding proteins, GPCRs, and drug ADME-associated proteins by SVM. Protein Pept. Lett. 2008, 15, 463–468. [Google Scholar] [CrossRef] [PubMed]
- Eliasson, M.; Rannar, S.; Trygg, J. From data processing to multivariate validation-essential steps in extracting interpretable information from metabolomics data. Curr. Pharm. Biotechnol. 2011, 12, 996–1004. [Google Scholar] [CrossRef] [PubMed]
- Wong, K.H.; Li, G.Q.; Li, K.M.; Razmovski-Naumovski, V.; Chan, K. Optimisation of Pueraria isoflavonoids by response surface methodology using ultrasonic-assisted extraction. Food Chem. 2017, 231, 231–237. [Google Scholar] [CrossRef] [PubMed]
- Saeed, N.; Khan, M.R.; Shabbir, M. Antioxidant activity, total phenolic and total flavonoid contents of whole plant extracts Torilis leptophylla L. BMC Complement. Altern. Med. 2012, 12, 221. [Google Scholar] [CrossRef] [PubMed]
Sample Availability: RP samples and the reference compounds are available from the authors. |




{kind=link}
{kind=link}
{kind=link}
| No. | Factors | Response Variables | ||||
|---|---|---|---|---|---|---|
| X1 (min) | X2 (cycles) | X3 (mL/g) | Y1 (%) | Y2 (%) | Y3 (%) | |
| Training set | ||||||
| 1 | 35 | 3 | 5 | 3.93 | 28.64 | 16.00 |
| 2 | 35 | 3 | 15 | 5.22 | 34.11 | 43.86 |
| 3 | 10 | 3 | 10 | 3.63 | 27.53 | 28.95 |
| 4 | 35 | 2 | 10 | 4.03 | 28.06 | 16.40 |
| 5 | 60 | 3 | 10 | 4.74 | 34.44 | 26.82 |
| 6 | 35 | 2 | 10 | 3.90 | 27.97 | 20.60 |
| 7 | 35 | 1 | 5 | 1.22 | 13.52 | 39.20 |
| 8 | 10 | 2 | 15 | 3.24 | 25.18 | 27.57 |
| 9 | 60 | 2 | 5 | 3.24 | 26.67 | 13.37 |
| 10 | 10 | 1 | 10 | 1.76 | 14.82 | 7.73 |
| 11 | 35 | 2 | 10 | 3.93 | 28.25 | 15.41 |
| 12 | 60 | 1 | 10 | 2.40 | 23.47 | 12.66 |
| 13 | 35 | 2 | 10 | 4.03 | 30.40 | 23.03 |
| 14 | 60 | 2 | 15 | 4.28 | 33.46 | 36.94 |
| 15 | 35 | 2 | 10 | 3.77 | 28.90 | 21.69 |
| 16 | 10 | 2 | 5 | 2.32 | 19.67 | 8.46 |
| 17 | 35 | 1 | 15 | 2.56 | 20.74 | 20.70 |
| Test set | ||||||
| 1 | 25 | 2 | 10 | 3.50 | 25.92 | 22.70 |
| 2 | 30 | 2 | 8 | 3.45 | 25.37 | 17.62 |
| 3 | 15 | 2 | 15 | 3.46 | 26.35 | 34.41 |
| 4 | 20 | 2 | 15 | 3.45 | 27.78 | 35.40 |
| QPM | SVR | ||||||
|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAD | R2 | RMSE | MAD | ||
| Y1 | Training set | 0.985 | 0.127 | 0.111 | 0.983 | 0.132 | 0.077 |
| Test set | 0.903 | 0.191 | 0.164 | 0.918 | 0.175 | 0.133 | |
| Cross-validation | 0.802 | 0.457 | 0.366 | 0.846 | 0.403 | 0.329 | |
| Y2 | Training set | 0.988 | 0.641 | 0.514 | 0.982 | 0.789 | 0.596 |
| Test set | 0.944 | 0.946 | 0.797 | 0.975 | 0.636 | 0.559 | |
| Cross-validation | 0.908 | 1.795 | 1.429 | 0.954 | 1.272 | 1.031 | |
| Y3 | Training set | 0.964 | 1.906 | 1.56 | 0.961 | 2.005 | 1.646 |
| Test set | 0.706 | 4.12 | 4.02 | 0.765 | 3.683 | 3.606 | |
| Cross-validation | 0.724 | 5.311 | 4.567 | 0.821 | 4.281 | 3.834 | |
| QPM | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| C0 | X12 | X22 | X32 | X1X2 | X1X3 | X2X3 | X1 | X2 | X3 | ||
| Y1 | Regression coefficient | 0.751 | −1.524 | −1.674 | −1.124 | 2.157 | 3.859 | 2.237 | 0.470 | 0.120 | −0.050 |
| p-value | 0.014 * | 0.006 * | 0.003 * | 0.023 * | 0.275 | 0.771 | 0.903 | 0.003 * | 0.001 * | 0.003 * | |
| Y2 | Regression coefficient | 9.371 | −3.317 | −11.287 | −6.567 | 11.257 | 26.075 | 13.050 | −1.740 | 1.280 | −1.750 |
| p-value | 0.001 * | 0.132 | 0.001 * | 0.012 * | 0.413 | 0.542 | 0.41 | 0.003 * | 0.001 * | 0.001 * | |
| Y3 | Regression coefficient | 1.402 | 0.158 | −1.702 | 8.478 | 5.412 | 17.347 | 5.582 | −7.060 | 4.460 | 11.080 |
| p-value | 0.698 | 0.979 | 0.777 | 0.186 | 0.273 | 0.477 | 0.104 | 0.491 | 0.053 | 0.478 | |
| SVR | |||
|---|---|---|---|
| σ | C | ε | |
| Y1 | 2−4 | 22 | 2−6 |
| Y2 | 2−5 | 24 | 2−3 |
| Y3 | 2−4 | 25 | 2−3 |
| No. | Factors | Predicted D Value | Experimental D Value | ||
|---|---|---|---|---|---|
| X1 (min) | X2 (cycles) | X3 (mL/g) | |||
| 1 | 35 | 3 | 14 | 0.98 | 0.99 |
| 2 | 40 | 3 | 15 | 1.03 | 1.01 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Yang, Y.; Jiao, J.; Wu, Z.; Yang, M. Support Vector Regression Approach to Predict the Design Space for the Extraction Process of Pueraria lobata. Molecules 2018, 23, 2405. https://doi.org/10.3390/molecules23102405
Wang Y, Yang Y, Jiao J, Wu Z, Yang M. Support Vector Regression Approach to Predict the Design Space for the Extraction Process of Pueraria lobata. Molecules. 2018; 23(10):2405. https://doi.org/10.3390/molecules23102405
Chicago/Turabian StyleWang, Yaqi, Yuanzhen Yang, Jiaojiao Jiao, Zhenfeng Wu, and Ming Yang. 2018. "Support Vector Regression Approach to Predict the Design Space for the Extraction Process of Pueraria lobata" Molecules 23, no. 10: 2405. https://doi.org/10.3390/molecules23102405
APA StyleWang, Y., Yang, Y., Jiao, J., Wu, Z., & Yang, M. (2018). Support Vector Regression Approach to Predict the Design Space for the Extraction Process of Pueraria lobata. Molecules, 23(10), 2405. https://doi.org/10.3390/molecules23102405