Correcting Errors in Image Encryption Based on DNA Coding



Abstract
:
1. Introduction
2. Methods
2.1. DNA Coding
2.1.1. Sequences-Sequence Hamming Distance (SS)
2.1.2. Sequences-Complementarity Hamming Distance (SC)
2.1.3. GC Content
2.1.4. DNA Coding Rule
2.2. New DNA Coding Rule for Correcting Errors
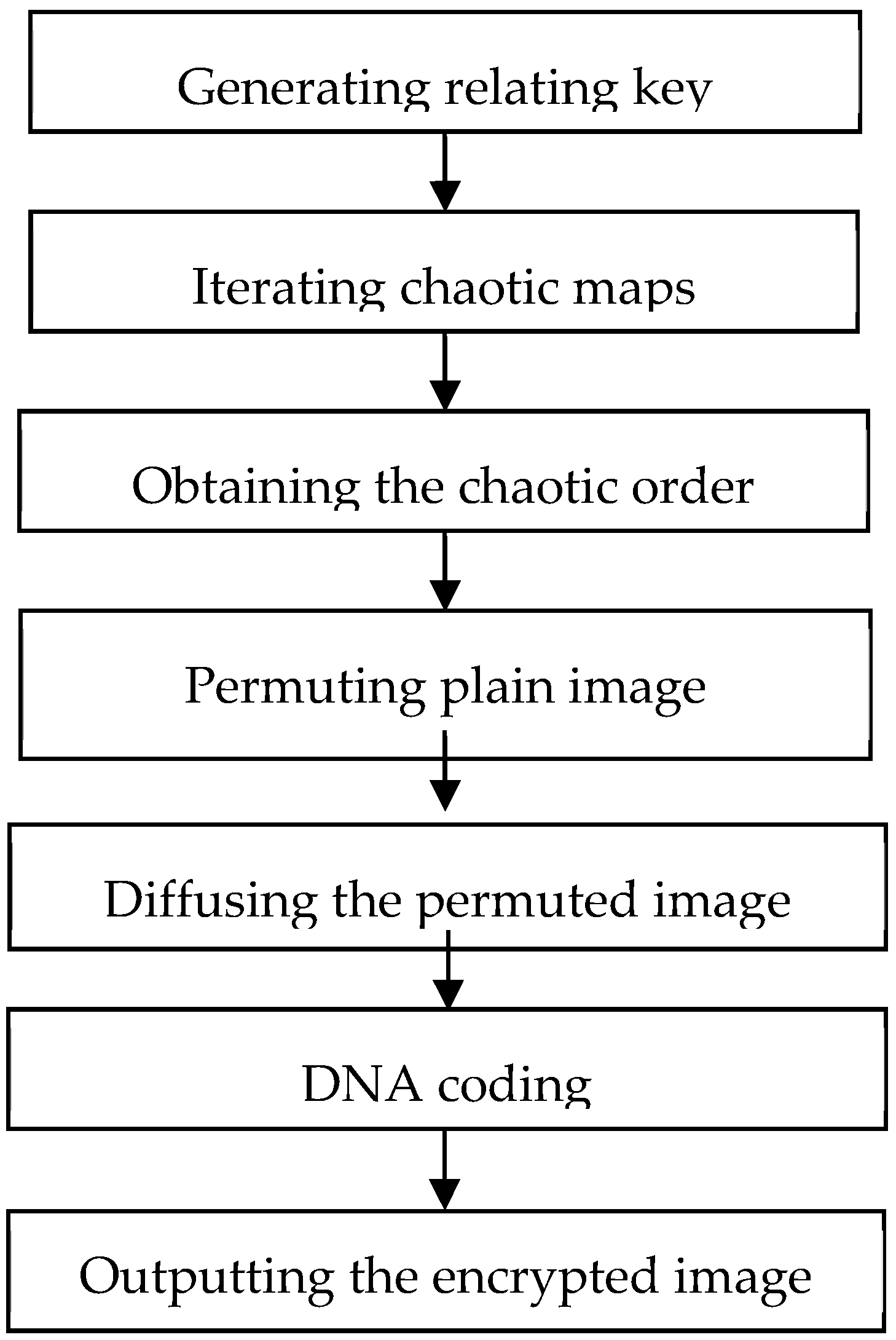
2.3. Process of Encrypting and Decrypting Image Based on DNA Coding
2.3.1. Encrypting Image
- Step 1.
- The key with 16 elements is randomly generated as the initial key and the initial key is implemented XOR operation with every pixel value of the plain image. The result of XOR operation is regard as the relating key;
- Step 2.
- According to initial condition of logistic maps, namely two parameters , and two initial value , , the relating key is evenly dividing relating key into four parts. These logistic maps are to iterate for 100 times to get rid of the transient effect of chaotic systems;
- Step 3.
- The logistic maps are continuingly iterated base on the number of pixels, namely one map for the half number and the pseudorandom sequence consists of the logistic chaotic orbits;
- Step 4.
- In order to permute the plain image, the chaotic orbits are sorted in ascending order. This operation (permutation) only changes the location of pixels of plain image;
- Step 5.
- The XOR operation is implemented between the pixels of the permuted image and the pseudorandom sequence from the logistic maps. This operation (diffusion) only changes the value of pixels of digital image;
- Step 6.
- According to the new DNA coding rule, the encrypted image is encoded by DNA coding;
- Step 7.
- Outputting the encrypted image.
2.3.2. Decrypting Image
- Step 1.
- According to the same relating key, the chaotic maps are to iterate for 100 times to get rid of the transient effect;
- Step 2.
- The chaotic orbits are regenerated based on the same parameters and initial values as well as the encryption process;
- Step 3.
- Decoding the cipher image based on the DNA coding rule;
- Step 4.
- The XOR operation is implemented between the pixels of the cipher image and the pseudorandom sequence from the logistic maps and the permuted image is recovered;
- Step 5.
- According to the order of chaotic sequences, the plain image is recovered from the permuted image;
- Step 6.
- Outputting the plain image.
3. Experiment and Simulation
3.1. Key Sensitivity
- Step 1.
- Generating the key 123456789012345 and using this key to encrypt the test images;
- Step 2.
- Generating another key—123456789012346—with a slight difference and using this key to encrypt the same test image;
- Step 3.
- Calculating the difference between different cipher images.
3.2. Statistical Analysis
3.3. Differential Attack
4. Correcting Errors
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Chen, G.; Mao, Y.; Chui, C.K. A symmetric image encryption scheme based on 3D chaotic cat maps. Chaos Solitons Fractals 2004, 21, 749–761. [Google Scholar] [CrossRef]
- Wong, K.-W.; Kwok, B.S.-H.; Law, W.-S. A fast image encryption scheme based on chaotic standard map. Phys. Lett. A 2008, 372, 2645–2652. [Google Scholar] [CrossRef] [Green Version]
- Lian, S.; Sun, J.; Wang, Z. A block cipher based on a suitable use of the chaotic standard map. Chaos Solitons Fractals 2005, 26, 117–129. [Google Scholar] [CrossRef]
- Chang, W.L.; Guo, M.Y.; Ho, M.S.H. Fast parallel molecular algorithms for DNA-based computation: Factoring integers. IEEE Trans. Nanobiosci. 2005, 4, 149–163. [Google Scholar] [CrossRef]
- Zhang, W.; Yu, H.; Zhao, Y.L.; Zhu, Z.L. Image encryption based on three-dimensional bit matrix permutation. Signal Process. 2016, 118, 36–50. [Google Scholar] [CrossRef]
- Kulsoom, A.; Xiao, D.; Ur, R.A.; Abbas, S.A. An efficient and noise resistive selective image encryption scheme for gray images based on chaotic maps and DNA complementary rules. Multimedia Tools Appl. 2016, 75, 1–23. [Google Scholar] [CrossRef]
- Zhang, Y.Q.; Wang, X.Y. A symmetric image encryption algorithm based on mixed linear-nonlinear coupled map lattice. Inf. Sci. 2014, 273, 329–351. [Google Scholar] [CrossRef]
- Wang, X.Y.; Zhang, H.L. A novel image encryption algorithm based on genetic recombination and hyper-chaotic systems. Nonlinear Dyn. 2016, 83, 333–346. [Google Scholar] [CrossRef]
- Zhang, Q.; Guo, L.; Wei, X.P. Image encryption using DNA addition combining with chaotic maps. Math. Comput. Model. 2010, 52, 2028–2035. [Google Scholar] [CrossRef]
- Liu, H.J.; Wang, X.Y.; Kadir, A. Image encryption using DNA complementary rule and chaotic maps. Appl. Soft Comput. 2012, 12, 1457–1466. [Google Scholar] [CrossRef]
- Wei, X.P.; Guo, L.; Zhang, Q.; Zhang, J.X.; Lian, S.G. A novel color image encryption algorithm based on DNA sequence operation and hyper-chaotic system. J. Syst. Softw. 2012, 85, 290–299. [Google Scholar] [CrossRef]
- Babaei, M. A novel text and image encryption method based on chaos theory and DNA computing. Nat. Comput. 2013, 12, 101–107. [Google Scholar] [CrossRef]
- Enayatifar, R.; Abdullah, A.H.; Isnin, I.F. Chaos-based image encryption using a hybrid genetic algorithm and a DNA sequence. Opt. Lasers Eng. 2014, 56, 83–93. [Google Scholar] [CrossRef]
- Ozkaynak, F.; Yavuz, S. Analysis and improvement of a novel image fusion encryption algorithm based on DNA sequence operation and hyper-chaotic system. Nonlinear Dyn. 2014, 78, 1311–1320. [Google Scholar] [CrossRef]
- Rehman, A.U.; Liao, X.F.; Kulsoom, A.; Abbas, S.A. Selective encryption for gray images based on chaos and DNA complementary rules. Multimedia Tools Appl. 2015, 74, 4655–4677. [Google Scholar] [CrossRef]
- Song, C.Y.; Qiao, Y.L. A Novel Image Encryption Algorithm Based on DNA Encoding and Spatiotemporal Chaos. Entropy 2015, 17, 6954–6968. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.J.; Kan, H.B.; Kurths, J. A new color image encryption scheme based on DNA sequences and multiple improved 1D chaotic maps. Appl. Soft Comput. 2015, 37, 24–39. [Google Scholar] [CrossRef]
- Wang, X.Y.; Zhu, X.Q.; Zhang, Y.Q. An Image Encryption Algorithm Based on Josephus Traversing and Mixed Chaotic Map. IEEE Access 2018, 6, 23733–23746. [Google Scholar] [CrossRef]
- Parvaz, R.; Zarebnia, M. A combination chaotic system and application in color image encryption. Opt. Laser Technol. 2018, 101, 30–41. [Google Scholar] [CrossRef] [Green Version]
- Adleman, L.M. Molecular computation of solutions to combinatorial problems. Science 1994, 266, 1021–1024. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, T.; Wang, E.K.; Dong, S.J. Potassium-Lead-Switched G-Quadruplexes: A New Class of DNA Logic Gates. J. Am. Chem. Soc. 2009, 131, 15082–15083. [Google Scholar] [CrossRef] [PubMed]
- Qian, L.; Winfree, E.; Bruck, J. Neural network computation with DNA strand displacement cascades. Nature 2011, 475, 368–372. [Google Scholar] [CrossRef] [PubMed]
- Scudellari, M. Inner Workings: DNA for data storage and computing. Proc. Natl. Acad. Sci. USA 2015, 112, 15771–15772. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, B.; Zhou, S.; Zheng, X.; Zhou, C.; Dong, J.; Zhao, L. Image watermarking using chaotic map and DNA coding. Opt.-Int. J. Light Electron Opt. 2015, 126, 4846–4851. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, B.; Wei, X.; Fang, X.; Zhou, C. DNA word set design based on minimum free energy. IEEE Trans. NanoBiosci. 2010, 9, 273–277. [Google Scholar] [CrossRef] [PubMed]
- Chai, X.L.; Chen, Y.R.; Broyde, L. A novel chaos-based image encryption algorithm using DNA sequence operations. Opt. Lasers Eng. 2017, 88, 197–213. [Google Scholar] [CrossRef]
- Wu, X.J.; Kurths, J.; Kan, H.B. A robust and lossless DNA encryption scheme for color images. Multimedia Tools Appl. 2018, 77, 12349–12376. [Google Scholar] [CrossRef]
- Marathe, A.; Condon, A.E.; Corn, R.M. On combinatorial DNA word design. J. Comput. Biol. 2001, 8, 201–219. [Google Scholar] [CrossRef] [PubMed]
- Shin, S.-Y.; Lee, I.-H.; Kim, D.; Zhang, B.-T. Multiobjective evolutionary optimization of DNA sequences for reliable DNA computing. IEEE Trans. Evol. Comput. 2005, 9, 143–158. [Google Scholar] [CrossRef]
- Hamming, R.W. Error detecting and error correcting codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, B.; Wei, X.P.; Zhou, C.J. A Novel Constraint for Thermodynamically Designing DNA Sequences. PLoS ONE 2013, 8. [Google Scholar] [CrossRef] [PubMed]
- Watson, J.D.; Crick, F.H.C. Molecular structure of nucleic acids—A structure for deoxyribose nucleic acid. Nature 1953, 171, 737–738. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Guo, L.; Wei, X.P. A novel image fusion encryption algorithm based on DNA sequence operation and hyper-chaotic system. Optik 2013, 124, 3596–3600. [Google Scholar] [CrossRef]
- Kracht, D.; Schober, S. Insertion and deletion correcting DNA barcodes based on watermarks. BMC Bioinform. 2015, 16, 50. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Zhang, Q.; Zhang, R.; Xu, C.X. Improved Lower Bounds for DNA Coding. J. Comput. Theor. Nanosci. 2010, 7, 638–641. [Google Scholar] [CrossRef]
- Su, X.; Li, W.; Hu, H. Cryptanalysis of a chaos-based image encryption scheme combining DNA coding and entropy. Multimedia Tools Appl. 2017, 76, 14021–14033. [Google Scholar] [CrossRef]
- Zhang, Y. Breaking a RGB image encryption algorithm based on DNA encoding and chaos map. Int. J. Inf. Secur. 2014, 1, 22–28. [Google Scholar]
- Liu, Y.; Tang, J.; Xie, T. Cryptanalyzing a RGB image encryption algorithm based on DNA encoding and chaos map. Opt. Laser Technol. 2014, 60, 111–115. [Google Scholar] [CrossRef] [Green Version]
- Kwok, H.; Tang, W.K.S. A fast image encryption system based on chaotic maps with finite precision representation. Chaos Solitons Fractals 2007, 32, 1518–1529. [Google Scholar] [CrossRef]
- Peng, J.; Zhang, D.; Liao, X. A digital image encryption algorithm based on hyper-chaotic cellular neural network. Fundam. Inf. 2009, 90, 269–282. [Google Scholar]
- Wang, B.; Zheng, X.; Zhou, S.; Zhou, C.; Wei, X.; Zhang, Q.; Che, C. Encrypting the compressed image by chaotic map and arithmetic coding. Opt.-Int. J. Light Electron Opt. 2014, 125, 6117–6122. [Google Scholar] [CrossRef]
- Wang, Y.; Wong, K.W.; Liao, X.; Chen, G. A new chaos-based fast image encryption algorithm. Appl. Soft Comput. 2011, 11, 514–522. [Google Scholar] [CrossRef]
- Gupta, K.; Silakari, S. Novel Approach for fast Compressed Hybrid color image Cryptosystem. Adv. Eng. Softw. 2012, 49, 29–42. [Google Scholar] [CrossRef]
- Yuan, S.; Deng, G.; Feng, Q.; Zheng, P.; Song, T. Multi-objective evolutionary algorithm based on decomposition for energy-aware scheduling in heterogeneous computing systems. J. Univ. Comput. Sci. 2017, 23, 636–651. [Google Scholar]
- Wang, X.; Gong, F.; Zheng, P. On the computational power of spiking neural P systems with self-organization. Sci. Rep. 2016. [Google Scholar] [CrossRef] [PubMed]
- Song, T.; Wong, P.Z.D.M.; Wang, X. Design of logic gates using spiking neural p systems with homogeneous neurons and astrocytes-like control. Inf. Sci. 2016, 372, 380–391. [Google Scholar] [CrossRef]
- Song, T.; Rodríguez-Patón, A.; Zheng, P.; Zeng, X. Spiking neural p systems with colored spikes. IEEE Trans. Cognit. Dev. Syst. 2018. [Google Scholar] [CrossRef]
- Wang, X.; Zheng, P.; Ma, T.; Song, T. Computing with bacteria conjugation: Small universal systems. Moleculer 2018, 23, 1307. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Yuan, S.; Feng, L.; Guo, B.; Qin, J.; Xu, B.; Lollar, C.; Sun, D.; Zhou, H. Pore-Environment Engineering with Multiple Metal Sites in Rare-Earth Porphyrinic Metal-Organic Frameworks. Angew. Chem. 2018. [Google Scholar] [CrossRef]
- Zhang, M.; Xin, X.; Xiao, Z. A multi-aromatic hydrocarbon unit induced hydrophobic metal–organic framework for efficient C2/C1 hydrocarbon and oil/water separation. J. Mater. Chem. 2017, 5, 1168–1175. [Google Scholar] [CrossRef]
Sample Availability: Samples of the images and DNA sequences are available from the authors. |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| A | 01 | 01 | 00 | 00 | 10 | 10 | 11 | 11 |
| T | 10 | 10 | 11 | 11 | 01 | 01 | 00 | 00 |
| C | 00 | 11 | 01 | 10 | 00 | 11 | 01 | 10 |
| G | 11 | 00 | 10 | 01 | 11 | 00 | 10 | 01 |
| Pixel | DNA Coding | Pixel | DNA Coding | Pixel | DNA Coding | Pixel | DNA Coding | Pixel | DNA Coding |
|---|---|---|---|---|---|---|---|---|---|
| 0 | ATCATGCC | 1 | CTCGATCA | 2 | GCTCTTCT | 3 | AGTGGGAT | 4 | ACTCTCTG |
| 5 | AATCTGCG | 6 | ACTCACGT | 7 | CTTCCAAC | 8 | GCTTCTAG | 9 | TAGGAGGT |
| 10 | GATCGACT | 11 | TAACGCTG | 12 | TAAGCGGA | 13 | CTGTGATC | 14 | CCCTAATC |
| 15 | TGGAAGGA | 16 | TACTACCG | 17 | CTTATGGG | 18 | TCAGCAAG | 19 | CGACTTCT |
| 20 | AGTGTCGA | 21 | TGCGATTC | 22 | CAACGACA | 23 | GATCTGTC | 24 | GCCAACTA |
| 25 | ATGAGGGA | 26 | TAGAACGG | 27 | CCGTAACA | 28 | TAGACTGC | 29 | GCTGGATT |
| 30 | GTGAGTCA | 31 | TCATGGAC | 32 | ACCACTAC | 33 | TCCTAAGG | 34 | GGCTAAAG |
| 35 | CCAACTGA | 36 | TCGTCTTG | 37 | TTGGGAAC | 38 | AATAGCCC | 39 | CTGTCGAA |
| 40 | CCCCATAT | 41 | AACCTCTC | 42 | GGTTTACG | 43 | GCAGAAGA | 44 | TAGAGGAG |
| 45 | GAAAGGGA | 46 | ATCGACGA | 47 | GCAAGTAC | 48 | TCAGACAC | 49 | CTTGGTTG |
| Horizontal | Vertical | Diagonal | |
|---|---|---|---|
| Lena | 0.9727(0.0073) | 0.9481(0.0058) | 0.9250(−0.0091) |
| Cameraman | 0.9561(−0.0053) | 0.9213(−0.0062) | 0.9145(−0.0059) |
| Boat | 0.9334(0.0006) | 0.9249(0.0009) | 0.8891(−0.0002) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Xie, Y.; Zhou, S.; Zheng, X.; Zhou, C. Correcting Errors in Image Encryption Based on DNA Coding. Molecules 2018, 23, 1878. https://doi.org/10.3390/molecules23081878
Wang B, Xie Y, Zhou S, Zheng X, Zhou C. Correcting Errors in Image Encryption Based on DNA Coding. Molecules. 2018; 23(8):1878. https://doi.org/10.3390/molecules23081878
Chicago/Turabian StyleWang, Bin, Yingjie Xie, Shihua Zhou, Xuedong Zheng, and Changjun Zhou. 2018. "Correcting Errors in Image Encryption Based on DNA Coding" Molecules 23, no. 8: 1878. https://doi.org/10.3390/molecules23081878
APA StyleWang, B., Xie, Y., Zhou, S., Zheng, X., & Zhou, C. (2018). Correcting Errors in Image Encryption Based on DNA Coding. Molecules, 23(8), 1878. https://doi.org/10.3390/molecules23081878